用深度学习做命名实体识别(四)——模型训练
通过本文你将了解如何训练一个人名、地址、组织、公司、产品、时间,共6个实体的命名实体识别模型。
准备训练样本
下面的链接中提供了已经用brat标注好的数据文件以及brat的配置文件,因为标注内容较多放到brat里加载会比较慢,所以拆分成了10份,每份包括3000多条样本数据,将这10份文件和相应的配置文件放到brat目录/data/project路径下,然后就可以从浏览器访问文件内容以及相应的标注情况了。
链接:https://pan.baidu.com/s/1-wjQnvCSrbhor9x3GD6WSA
提取码:99z3
如果你还不知道什么是brat,或还不清楚如何使用brat,强烈建议先阅读前两篇文章《用深度学习做命名实体识别(二):文本标注工具brat》、《用深度学习做命名实体识别(三):文本数据标注过程》。
标注数据虽然有了,但是还不能满足我们的训练要求,因为我们需要根据ann和txt,将其转成训练所需的数据格式,格式如下:

可以看到,每一行一个字符,字符后面跟上空格,然后跟上该字符的标注, 每个样本之间用空行分隔。
另外,也可以看到这里采用的是BIO的标注方式:
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- O,即Other,表示其他,用于标记无关字符
转换代码如下:
# -*- coding: utf-8 -*-"""
数据格式转化
"""
import codecs
import os__author__ = '程序员一一涤生'tag_dic = {"时间": "TIME","地点": "LOCATION","人名": "PERSON_NAME","组织名": "ORG_NAME","公司名": "COMPANY_NAME","产品名": "PRODUCT_NAME"}# 转换成可训练的格式,最后以"END O"结尾
def from_ann2dic(r_ann_path, r_txt_path, w_path):q_dic = {}print("开始读取文件:%s" % r_ann_path)with codecs.open(r_ann_path, "r", encoding="utf-8") as f:line = f.readline()line = line.strip("\n\r")while line != "":line_arr = line.split()print(line_arr)cls = tag_dic[line_arr[1]]start_index = int(line_arr[2])end_index = int(line_arr[3])length = end_index - start_indexfor r in range(length):if r == 0:q_dic[start_index] = ("B-%s" % cls)else:q_dic[start_index + r] = ("I-%s" % cls)line = f.readline()line = line.strip("\n\r")print("开始读取文件:%s" % r_txt_path)with codecs.open(r_txt_path, "r", encoding="utf-8") as f:content_str = f.read()# content_str = content_str.replace("\n", "").replace("\r", "").replace("//", "\n")print("开始写入文本%s" % w_path)with codecs.open(w_path, "w", encoding="utf-8") as w:for i, str in enumerate(content_str):if str is " " or str == "" or str == "\n" or str == "\r":print("===============")elif str == "/":if i == len(content_str) - len("//") + 1: # 表示到达末尾# w.write("\n")break# 连续六个字符首尾都是/,则表示换一行elif content_str[i + len("//") - 1] == "/" and content_str[i + len("//") - 2] == "/" and \content_str[i + len("//") - 3] == "/" and content_str[i + len("//") - 4] == "/" and \content_str[i + len("//") - 5] == "/":w.write("\n")i += len("//")else:if i in q_dic:tag = q_dic[i]else:tag = "O" # 大写字母Ow.write('%s %s\n' % (str, tag))w.write('%s\n' % "END O")# 去除空行
def drop_null_row(r_path, w_path):q_list = []with codecs.open(r_path, "r", encoding="utf-8") as f:line = f.readline()line = line.strip("\n\r")while line != "END O":if line != "":q_list.append(line)line = f.readline()line = line.strip("\n\r")with codecs.open(w_path, "w", encoding="utf-8") as w:for i, line in enumerate(q_list):w.write('%s\n' % line)# 生成train.txt、dev.txt、test.txt
# 除8,9-new.txt分别用于dev和test外,剩下的合并成train.txt
def rw0(data_root_dir, w_path):if os.path.exists(w_path):os.remove(w_path)for file in os.listdir(data_root_dir):path = os.path.join(data_root_dir, file)if file.endswith("8-new.txt"):# 重命名为dev.txtos.rename(path, os.path.join(data_root_dir, "dev.txt"))continueif file.endswith("9-new.txt"):# 重命名为test.txtos.rename(path, os.path.join(data_root_dir, "test.txt"))continueq_list = []print("开始读取文件:%s" % file)with codecs.open(path, "r", encoding="utf-8") as f:line = f.readline()line = line.strip("\n\r")while line != "END O":q_list.append(line)line = f.readline()line = line.strip("\n\r")print("开始写入文本%s" % w_path)with codecs.open(w_path, "a", encoding="utf-8") as f:for item in q_list:if item.__contains__('\ufeff1'):print("===============")f.write('%s\n' % item)if __name__ == '__main__':data_dir = "datas"for file in os.listdir(data_dir):if file.find(".") == -1:continuefile_name = file[0:file.find(".")]r_ann_path = os.path.join(data_dir, "%s.ann" % file_name)r_txt_path = os.path.join(data_dir, "%s.txt" % file_name)w_path = "%s/new/%s-new.txt" % (data_dir, file_name)from_ann2dic(r_ann_path, r_txt_path, w_path)# 生成train.txt、dev.txt、test.txtrw0("%s/new" % data_dir, "%s/new/train.txt" % data_dir)注意把该代码文件和datas目录放在一级,然后把从云盘下载的10个标注数据文件放在datas目录下,然后再执行上面的代码,执行完成后,会在datas/new目录下生成一些文件,我们要的是其中的train、dev、test三个txt文件。
ok,到此我们的训练数据就准备好了,接下来我们需要准备预训练模型。
准备预训练模型
使用预训练模型做微调的训练方式称为迁移学习,不太明白什么意思也没关系,只要知道这样做可以让我们的训练收敛的更快,并且可以使得在较少的训练样本上训练也能得到不错的效果。这里我们将使用目前最好的自然语言表征模型之一的bert的中文预训练模型。如果你还不清楚bert,也没关系,这里你只要知道使用bert可以得到比word2vec(词向量)更好的表征即可。
bert在中文维基百科上预训练的模型下载地址:
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
下载下来,解压后会看到如下几个文件:
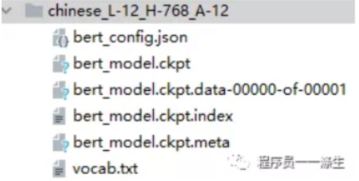
这里我们已经将bert_model.ckpt.data-00000-of-00001文件复制一份,命名为bert_model.ckpt,所以多了一个bert_model.ckpt文件。因为不这样做的话,后续的训练会报错,找不到ckpt。
以上工作都完成后,就可以进入训练环节了。
准备训练环境
强烈建议使用GPU来训练,否则你会疯的。关于GPU环境的搭建可以参考这篇文章《如何在阿里云租一台GPU服务器做深度学习?》。
训练
本文的模型训练参考的是github上一个开源的项目,该项目是基于bert+crf算法来训练命名实体模型的,比基于lstm+crf的项目的效果要好,下面是该项目的地址:
https://github.com/macanv/BERT-BiLSTM-CRF-NER
笔者基于该项目做了一些代码修改,修改的目的如下:
- 原来的项目是采用install的方式直接将项目安装到你的python虚拟环境下,然后通过命令行执行训练,笔者直接调整了源代码,为了可以基于源代码执行一些调试;
- 原来的项目训练的时候几乎没有日志信息,修改后的项目可以看到训练日志;
- 原来的项目只能在训练结束后输出评估结果,修改后的项目可以让评估脱离训练过程独立进行。
修改后的项目地址:
链接:https://pan.baidu.com/s/1Bht_-K9i-7WUbXdvG4sdpg
提取码:sibq
修改后的项目下载下来解压后,需要做3件事情:
- 将之前下载的bert预训练模型chinese_L-12_H-768_A-12目录以及目录中的文件放到项目的models目录下。
- 将之前准备的train、dev、test三个文件放到person_data目录下。
- 为该项目新建一个python的虚拟环境,然后安装所需要的依赖包,关于需要哪些依赖包,项目中的requirement.txt是这么描述的:
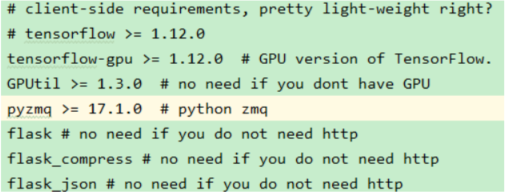
tensorflow的安装,因为我们是在GPU上训练,所以只需要安装tensorflow-gpu,笔者安装的是tensorflow1.13.1版本,因为笔者的CUDA版本是10.0。
接下来,执行以下命令进行训练:
nohup python bert_lstm_ner.py -max_seq_length 500 -batch_size 2 -learning_rate 2e-5 -num_train_epochs 3.0 -filter_adam_var True -verbose -data_dir person_data -output_dir output -init_checkpoint models/chinese_L-12_H-768_A-12/bert_model.ckpt -bert_config_file models/chinese_L-12_H-768_A-12/bert_config.json -vocab_file models/chinese_L-12_H-768_A-12/vocab.txt >log.out 2>&1 &
让我们对命令中的参数做一些解释:
- nohup
使用nohup命令,可以保证在命令窗口被关闭,或远程链接中断的情况下,不影响远端python程序的执行。python程序执行过程中的日志信息会保存在当前文件夹下的log.out文件中。 - max_seq_length
每个样本的最大长度,不能超过512。如果你的某些样本超过了这个长度,需要截断。截断代码可以使用项目根路径下的data_process.py文件。 - batch_size
每次送到模型进行训练的样本数量。一般是2幂次方。如果你的GPU显存够大,可以尝试增大batch_size。 - learning_rate
初始学习率,用于调整模型的学习速度,过大过小都不好。刚开始训练时:学习率以 0.01 ~ 0.001 为宜。接近训练结束:学习速率的衰减应该在100倍以上。这里因为我们采用的是迁移学习,由于预模型本身已经在原始数据集上收敛,此时学习率应该设置的较小,所以这里设置成0.00002。 - num_train_epochs
每次用完所有样本后,记为一个epoch。这里是指设置多少个epoch后训练结束。 - filter_adam_var
保存训练模型的时候是否过滤掉Adam的参数,默认为False。设置为True可以减小模型的大小。 - verbose
加上该参数就会打开tensorflow的日志。 - data_dir
train、dev、test数据所在的目录。 - output_dir
模型输出目录。 - init_checkpoint
预训练模型的路径,这里我们使用了bert的中文预训练模型。 - bert_config_file
bert模型的配置文件所在路径。 - vocab_file
bert的词汇表文件路径。
开始训练后,通过以下命令查看训练过程的日志信息:
tail -f log.out
下图截取自训练结束后的部分输出日志:

可以看到评估损失值降到了0.04862。
训练会持续3个多小时(在一块Nvidia Geforce RTX2060 GPU上),结束后,会看到对test.txt样本进行测试的结果:
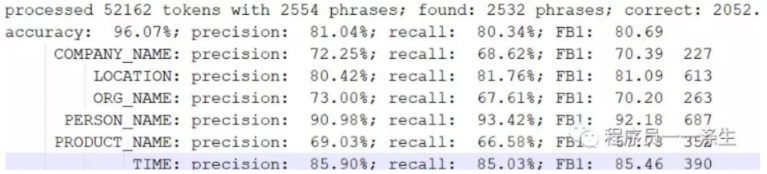
测试
每训练500步,程序会在output目录下保存一个模型文件,我们可以通过修改output目录下的checkpoint文件来指定要用来测试的模型文件。
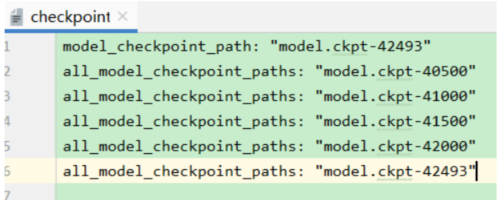
然后执行如下命令来对test.txt中的内容进行测试(注意bert_lstm_ner-test.py中的配置要和训练时指定的参数配置一致):
python bert_lstm_ner-test.py
测试输出的结果和上面训练完成后输出的结果的格式是一样的。如果你按照本文的步骤,完整的走到这里了,那么你已经有了一个可以识别 人名、地址、组织、公司、产品、时间,共6个实体的命名实体识别模型,下一篇文章《用深度学习做命名实体识别(五):模型使用》将介绍如何使用这个模型来提供一个rest风格的实体识别接口,对该接口传入一个句子参数,接口会返回句子中的人名、地址、组织、公司、产品、时间信息。
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O,88~
名句分享
勿以小恶弃人大美,勿以小怨忘人大恩。——曾国藩
为您推荐
pycharm2019和idea2019版永久激活
手把手教你用深度学习做物体检测(一): 快速感受物体检测的酷炫
本博客内容来自公众号“程序员一一涤生”,欢迎扫码关注 o(∩_∩)o
转载于:https://www.cnblogs.com/anai/p/11492956.html
用深度学习做命名实体识别(四)——模型训练相关推荐
- 用深度学习做命名实体识别(五)-模型使用
通过本文,你将了解如何基于训练好的模型,来编写一个rest风格的命名实体提取接口,传入一个句子,接口会提取出句子中的人名.地址.组织.公司.产品.时间信息并返回. 核心模块entity_extract ...
- 用深度学习做命名实体识别(二):文本标注工具brat
本篇文章,将带你一步步的安装文本标注工具brat. brat是一个文本标注工具,可以标注实体,事件.关系.属性等,只支持在linux下安装,其使用需要webserver,官方给出的教程使用的是Apac ...
- NLP入门(五)用深度学习实现命名实体识别(NER)
前言 在文章:NLP入门(四)命名实体识别(NER)中,笔者介绍了两个实现命名实体识别的工具--NLTK和Stanford NLP.在本文中,我们将会学习到如何使用深度学习工具来自己一步步地实现N ...
- 基于深度学习的命名实体识别研究综述——论文研读
基于深度学习的命名实体识别研究综述 摘要: 0引言 1基于深度学习的命名实体识别方法 1.1基于卷积神经网络的命名实体识别方法 1.2基于循环神经网络的命名实体识别方法 1.3基于Transforme ...
- 超详综述 | 基于深度学习的命名实体识别
©PaperWeekly 原创 · 作者|马敏博 单位|西南交通大学硕士生 研究方向|命名实体识别 论文名称:A Survey on Deep Learning for Named Entity Re ...
- 一文详解深度学习在命名实体识别(NER)中的应用
近几年来,基于神经网络的深度学习方法在计算机视觉.语音识别等领域取得了巨大成功,另外在自然语言处理领域也取得了不少进展.在NLP的关键性基础任务-命名实体识别(Named Entity Recogni ...
- bilstmcrf词性标注_深度学习--biLSTM_CRF 命名实体识别
前文 中文分词.词性标注.命名实体识别是自然语言理解中,基础性的工作,同时也是非常重要的工作.在很多NLP的项目中,工作开始之前都要经过这三者中的一到多项工作的处理.在深度学习中,有一种模型可以同时胜 ...
- 手把手教你用深度学习做物体检测(三):模型训练
本篇文章旨在快速试验使用yolov3算法训练出自己的物体检测模型,所以会重过程而轻原理,当然,原理是非常重要的,只是原理会安排在后续文章中专门进行介绍.所以如果本文中有些地方你有原理方面的疑惑,也没关 ...
- 自然语言处理(NLP)之用深度学习实现命名实体识别(NER)
几乎所有的NLP都依赖一个强大的语料库,本项目实现NER的语料库如下(文件名为train.txt,一共42000行,这里只展示前15行,可以在文章最后的Github地址下载该语料库): played ...
最新文章
- Visual Studio 2017创建XAML文件
- arm920T与arm926的区别[转载]
- Python2和Python3中raise Exception
- lucene教程--全文检索技术详解
- 查看CentOS的系统版本(亲测)
- css grid布局_如何使用CSS Grid重新创建Medium的文章布局
- 『飞秋』Html.Label的缺陷及补救办法
- oracle数据库表excel文件位置,Excel数据导入到oracle数据库表方法
- 苹果暖场之后 华为P30系列正式发布!你的“望远镜”手机终于来了
- eclipse-注释
- jvm第五节-性能调优工具使用
- 10 行代码解决漏斗转换计算之性能优化
- android下拉刷新完全解析,教你如何一分钟实现下拉刷新功能,高仿京东下拉刷新,轻松上手!...
- python卡尔曼滤波_卡尔曼滤波+单目标追踪+python-opencv
- 流畅的Python(1)- 一摞Python风格的纸牌
- CDR插件开发之Addon插件006 - 初体验:通过C#代码用外挂方式操作CDR中的对象
- python知识点大全-2
- 牛牛的猜球游戏(前缀和+逆交换)
- html简介框架模板,html框架布局后台模板.doc
- 谷歌浏览器Chrome无法搜索Google的解决办法