zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗?
修改
val config = new Configuration() //以下代码表示只统计本机数据库上的数据,猜测问题可能出在这里 config.set("mongo.input.uri", "mongodb://127.0.0.1:27017/local.test") //统计结果输出到服务器上 config.set("mongo.output.uri", "mongodb://103.25.23.80:60013/test_hao.result") val mongoRDD = sc.newAPIHadoopRDD(config, classOf[com.mongodb.hadoop.MongoInputFormat], classOf[Object], classOf[BSONObject]) // Input contains tuples of (ObjectId, BSONObject) val countsRDD = mongoRDD.flatMap(arg => { var str = arg._2.get("type").toString str = str.toLowerCase().replaceAll("[.,!?\n]", " ") str.split(" ") }) .map(word => (word, 1)) .reduceByKey((a, b) => a + b) // Output contains tuples of (null, BSONObject) - ObjectId will be generated by Mongo driver if null val saveRDD = countsRDD.map((tuple) => { var bson = new BasicBSONObject() bson.put("word", tuple._1) bson.put("count", tuple._2.toString() ) (null, bson) }) // Only MongoOutputFormat and config are relevant saveRDD.saveAsNewAPIHadoopFile("file:///bogus", classOf[Any], classOf[Any], classOf[com.mongodb.hadoop.MongoOutputFormat[Any, Any]], config)
val mongoRDD = sc.newAPIHadoopRDD(config, classOf[com.mongodb.hadoop.MongoInputFormat], classOf[Object], classOf[BSONObject]) 这行代码表示这是由driver读取数据库,然后将符合条件的数据载入RDD,由于之前设置了是将127.0.0.1作为输入,也就是从driver的mongodb上读取数据。由于driver就在master上,所以读取的数据也自然就是master上的数据了。
默认情况下,Standalone的Spark集群是Master-Slaves架构的集群模式,由一台master来调度资源,这就和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。如何解决这个单点故障的问题呢?Spark提供了两种方案:基于文件系统的单点恢复(Single-Node Recovery with Local File system)和基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)。其中ZooKeeper是生产环境下的最佳选择。
ZooKeeper提供了一个Leader Election机制,利用这个机制你可以在集群中开启多个master并使它们都注册到ZooKeeper实例,ZooKeeper会管理使其中只有一个是Active的,其他的都是Standby的,Active状态的master可以提供服务,standby状态的则不可以。ZooKeeper保存了集群的状态信息,该信息包括所有的Worker,Driver 和Application。当Active的Master出现故障时,ZooKeeper会从其他standby的master中选举出一台,然后该新选举出来的master会恢复挂掉了的master的状态信息,之后该Master就可以正常提供调度服务。整个恢复过程只需要1到2分钟。需要注意的是,在这1到2分钟内,只会影响新程序的提交,那些在master崩溃时已经运行在集群中的程序并不会受影响。
下面我们就实战如何配置ZooKeeper下的spark HA。
注:
DT_大数据梦工厂(IMF传奇行动绝密课程)有所有大数据实战资料
更多私密内容,请关注微信公众号:DT_Spark
如果您对大数据Spark感兴趣,可以免费听由王家林老师每天晚上20:00开设的Spark永久免费公开课,地址YY房间号:68917580
spark集群搭建:https://zhuanlan.zhihu.com/p/20819281 http://www.cnblogs.com/shishanyuan/p/4699644.htmlhttp://www.cnblogs.com/kinglau/p/3794433.htmlhttp://www.cnblogs.com/tec-vegetables/p/3778358.htmlhttp://blog.csdn.net/laoyi_grace/article/details/6254743http://www.cnblogs.com/tina-smile/p/5045927.htmlhttp://edu.51cto.com/lesson/id-31786.html
没有hdfs,spark不能集群方式跑是吧?修改
另外 区分下YARN和HDFS YARN也不是必须依赖HDFS的
配置你每个节点上都存一份,或者放在 NFS 里。
数据你不从 HDFS 取就行了。
spark-standalone模式可以不启动hdfs跑吗 可以看看《为什么会有第一代大数据Hadoop和第二代大数据Spark?》这个视频,深刻讲解了spark和Hadoop的优缺点和hadoop和大数据的关系,观点一针见血,分析的入木三分
Hadoop中,hdfs已经算是大数据存储的标配了,mr基本已淘汰(即便用hive都改tez了)。
数据分析和挖掘,spark已经是趋势了。
Spark也能支持秒级的流式计算,但毫秒级的,还得用storm。
Hadoop还有个组件yarn,做资源管理调度的,spark可以运行在yarn上,也可以独立运行(还)有种方式是运行在mesos上。
应用场景: hadoop更擅长于离线批处理
spark更擅长于迭代处理。
但是 hadoop和spark的区别也在于 前者基于磁盘多次IO, 后者基于内存计算移动计算而非数据。需要注意的是hadoop和spark的Map / Reduce思想 以及其二者的shuffle过程。 我一直没有讲明白shuffle的过程。
Hadoop提供map和reduce算子,而spark提供了大量的transform和action算子,比Hadoop丰富。
提到大数据,就不能不提Hadoop和 Spark,那么作为大数据领域中的两座大山,它们到底是什么?各自又有什么魅力呢?
1. Hadoop ,Spark为何物?
Hadoop是http://Apache.org的一个项目
Spark是一个运算速度快如闪电的Apache项目
一种软件库和框架
可跨计算器集群对庞大数据集(大数据)进行分布式处理
大数据分析领域的重量级大数据平台
一种用于数据大规模处理的快速通用引擎
处理PB级别数据运算速度最快的开源工具
它有四个主要模块:
1) Hadoop Common
2) Hadoop分布式文件系统(HDFS)
3) Hadoop YARN
4) Hadoop MapReduce
Spark核心组件可以和其他一些高效的软件库无缝连接使用
这些软件库包括:
SparkSQL
Spark Streming
MLlib(机器学习专用)
GraphX
Spark是一种集群计算框架,意味着Hadoop vs Spark Spark VS MapReduce
2. Hadoop vs Spark使用难易度
随带易于使用的API,支持Scala(原生语言)、Java、Python和Spark SQL。Spark SQL非常类似于SQL 92,且有一种交互模式,可马上上手。
Hadoop MapReduce没有交互模式,有Hive和Pig等附加模块,采用者使用MapReduce更加容易。
Spark因易用性受到追捧
3. Hadoop vs Spark使用成本大比拼
MapReduce和Spark都是Apache项目,是开源免费软件产品
MapReduce使用常规数量的内存
Spark需要大量内存
需要速度更快的磁盘和大量磁盘空间来运行MapReduce
需要更多的系统,将磁盘输入/输出分布到多个系统上
使用常规数量的常规转速磁盘
不使用磁盘输入/输入用于处理,已使用的磁盘空间可以用于SAN或NAS
Spark系统的成本更高,但技术减少了数量,最终结果是系统成本较高,但是数量大大减少
4.Hadoop与Spark的特性
Ø 数据处理方式
Hadoop MapReduce使用批量处理
Spark使用内存处理
不断收集来自网站的信息,不需要这些数据具有实时性或近乎实时性
它在内存中处理一切数据,为来自多个来源的数据提供了近乎实时分析的功能
Hadoop MapReduce运行顺序:集群读取-执行操作-写回到集群-读取更新后的数据-执行下一个数据操作
Spark执行类似的操作,不过是在内存中一步执行:集群读取-执行操作-写回到集群
Ø 兼容性
在兼容性一点上,二者互相兼容,MapReduce通过JDBC和ODC兼容诸多数据源、文件格式和商业智能工具,Spark亦是如此。
Ø 容错性
MapReduce
Spark
使用TaskTracker节点,它为 JobTracker节点提供了心跳(heartbeat)
用弹性分布式数据集(RDD),它们是容错集合,里面的数据元素可执行并行操作,使RDD可以引用外部存储系统中的数据集,Spark可以用Hadoop支持的任何存储源创建RDD ,Spark的缓存也具有容错性。
Ø 可扩展性
MapReduce和Spark都可以使用HDFS来扩展
据目前所知,最大的Hadoop集群是42000个节点,可以说扩展无极限
最大的已知Spark集群是8000个节点,随着大数据增多,预计集群规模也会随之变大
Ø 安全性
Hadoop支持Kerberos身份验证
Spark的安全性弱一点,目前只支持通过共享密钥(密码验证)的身份验证
能够充分利用活动目录Kerberos和LDAP用于身份验证
在HDFS上运行Spark,它可以使用HDFS ACL和文件级权限
Hadoop分布式文件系统支持访问控制列表(ACL)和传统的文件权限模式,确保用户拥有正确的权限
Spark可以在YARN上运行,因而能够使用Kerberos身份验证
事实上,Hadoop vs Spark并没有真正的孰优孰劣,它们不是你死我活的关系,而是一种相互共生的关系,Spark帮助人们简化了处理大规模数据的步骤流程,而Hadoop又提供了Spark所没有的功能特性,可以说二者只有相辅相成,互利共生,才能够为企业、为团队提供更为有效的数据分析,为决策者提供更为有效的建议。
大数据不仅仅是大,它Bigger than big。如果是“大”,那么,多大才是大?PB?TB?
大数据的关键特性在于,区别于传统的统计学,它处理的对象是数据的整体,而不是“样本”。传统的统计学,都是根据样本来推测整体,免不了偏差——所以它有个概念叫做“显著”(Confidence),告诉你,我针对样本得出的结论,有多大把握对整体也是真的。
之所以会这样,因为过去计算机科学不发达,数据的采集和计算都是大问题,只能抽样。
现在不同了,数据的采集,存储,计算都不是问题,为什么还要抽样呢?因此,诞生了大数据概念,直接处理数据整体,而不是抽样。
有了上述铺垫,再举个栗子。如果回答PB是大,OK,10PB算大了吧?是不是大数据?是。OK,那我告诉你,这10PB来自阿里,但只是其已处理数据量的1/10。那么,现在它还是不是大数据?
对比一下,一个中小型网站,每天只有10G的数据,是不是大数据?可能不是?OK,但这已经是他全部的数据量了。
而Hadoop、Spark都是处理大数据的一种技术手段,Spark由于是在内存中计算,速度要更快一些。还有很多其它处理大数据的方式,技术没有最好只有最合适的。
2. Hadoop是大数据处理的开源软件,也是使用最广的。
3. Hadoop的计算过程,大量使用磁盘存储。Spark的计算,大量使用内存存储,所以Spark块。两者并行。
4. spark支持从Hadoop的hdfs做数据输入输出。
5. Hadoop 2.x支持Spark作为一个组件。
对于Spark,我从以下角度理解:
1. 是一种内存计算引擎,与MR是竞争关系,但效率比MR高。
2. 需要外部的资源调度系统来支持,可以跑在YARN上,也可以跑在Mesos上,当然可以用Standalone模式。
3. Spark核心计算引擎外围有若干数据分析组件,Spark SQL(SQL接口)、Spark Streaming(流计算)、MLlib(机器学习)、GraphX(图计算),“One Stack to rule them all”。
总体来说,Spark是跑在Hadoop上(依赖YARN和HDFS)的内存计算引擎,内置多种丰富组件,可以处理数据分析各个领域的问题。
大数据(Big Data)
大数据,官方定义是指那些数据量特别大、数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理。大数据的主要特点为数据量大(Volume),数据类别复杂(Variety),数据处理速度快(Velocity)和数据真实性高(Veracity),合起来被称为4V。
大数据中的数据量非常巨大,达到了PB级别。而且这庞大的数据之中,不仅仅包括结构化数据(如数字、符号等数据),还包括非结构化数据(如文本、图像、声音、视频等数据)。这使得大数据的存储,管理和处理很难利用传统的关系型数据库去完成。在大数据之中,有价值的信息往往深藏其中。这就需要对大数据的处理速度要非常快,才能短时间之内就能从大量的复杂数据之中获取到有价值的信息。在大数据的大量复杂的数据之中,通常不仅仅包含真实的数据,一些虚假的数据也混杂其中。这就需要在大数据的处理中将虚假的数据剔除,利用真实的数据来分析得出真实的结果。
大数据分析(Big Data Analysis)
大数据,表面上看就是大量复杂的数据,这些数据本身的价值并不高,但是对这些大量复杂的数据进行分析处理后,却能从中提炼出很有价值的信息。对大数据的分析,主要分为五个方面:可视化分析(Analytic Visualization)、数据挖掘算法(Date Mining Algorithms)、预测性分析能力(Predictive Analytic Capabilities)、语义引擎(Semantic Engines)和数据质量管理(Data Quality Management)。
可视化分析是普通消费者常常可以见到的一种大数据分析结果的表现形式,比如说百度制作的“百度地图春节人口迁徙大数据”就是典型的案例之一。可视化分析将大量复杂的数据自动转化成直观形象的图表,使其能够更加容易的被普通消费者所接受和理解。
数据挖掘算法是大数据分析的理论核心,其本质是一组根据算法事先定义好的数学公式,将收集到的数据作为参数变量带入其中,从而能够从大量复杂的数据中提取到有价值的信息。著名的“啤酒和尿布”的故事就是数据挖掘算法的经典案例。沃尔玛通过对啤酒和尿布购买数据的分析,挖掘出以前未知的两者间的联系,并利用这种联系,提升了商品的销量。亚马逊的推荐引擎和谷歌的广告系统都大量使用了数据挖掘算法。
预测性分析能力是大数据分析最重要的应用领域。从大量复杂的数据中挖掘出规律,建立起科学的事件模型,通过将新的数据带入模型,就可以预测未来的事件走向。预测性分析能力常常被应用在金融分析和科学研究领域,用于股票预测或气象预测等。
语义引擎是机器学习的成果之一。过去,计算机对用户输入内容的理解仅仅停留在字符阶段,不能很好的理解输入内容的意思,因此常常不能准确的了解用户的需求。通过对大量复杂的数据进行分析,让计算机从中自我学习,可以使计算机能够尽量精确的了解用户输入内容的意思,从而把握住用户的需求,提供更好的用户体验。苹果的Siri和谷歌的Google Now都采用了语义引擎。
数据质量管理是大数据在企业领域的重要应用。为了保证大数据分析结果的准确性,需要将大数据中不真实的数据剔除掉,保留最准确的数据。这就需要建立有效的数据质量管理系统,分析收集到的大量复杂的数据,挑选出真实有效的数据。
分布式计算(Distributed Computing)
对于如何处理大数据,计算机科学界有两大方向:第一个方向是集中式计算,就是通过不断增加处理器的数量来增强单个计算机的计算能力,从而提高处理数据的速度。第二个方向是分布式计算,就是把一组计算机通过网络相互连接组成分散系统,然后将需要处理的大量数据分散成多个部分,交由分散系统内的计算机组同时计算,最后将这些计算结果合并得到最终的结果。尽管分散系统内的单个计算机的计算能力不强,但是由于每个计算机只计算一部分数据,而且是多台计算机同时计算,所以就分散系统而言,处理数据的速度会远高于单个计算机。
过去,分布式计算理论比较复杂,技术实现比较困难,因此在处理大数据方面,集中式计算一直是主流解决方案。IBM的大型机就是集中式计算的典型硬件,很多银行和政府机构都用它处理大数据。不过,对于当时的互联网公司来说,IBM的大型机的价格过于昂贵。因此,互联网公司的把研究方向放在了可以使用在廉价计算机上的分布式计算上。
服务器集群(Server Cluster)
服务器集群是一种提升服务器整体计算能力的解决方案。它是由互相连接在一起的服务器群所组成的一个并行式或分布式系统。服务器集群中的服务器运行同一个计算任务。因此,从外部看,这群服务器表现为一台虚拟的服务器,对外提供统一的服务。
尽管单台服务器的运算能力有限,但是将成百上千的服务器组成服务器集群后,整个系统就具备了强大的运算能力,可以支持大数据分析的运算负荷。Google,Amazon,阿里巴巴的计算中心里的服务器集群都达到了5000台服务器的规模。
大数据的技术基础:MapReduce、Google File System和BigTable
2003年到2004年间,Google发表了MapReduce、GFS(Google File System)和BigTable三篇技术论文,提出了一套全新的分布式计算理论。
MapReduce是分布式计算框架,GFS(Google File System)是分布式文件系统,BigTable是基于Google File System的数据存储系统,这三大组件组成了Google的分布式计算模型。
Google的分布式计算模型相比于传统的分布式计算模型有三大优势:首先,它简化了传统的分布式计算理论,降低了技术实现的难度,可以进行实际的应用。其次,它可以应用在廉价的计算设备上,只需增加计算设备的数量就可以提升整体的计算能力,应用成本十分低廉。最后,它被Google应用在Google的计算中心,取得了很好的效果,有了实际应用的证明。
后来,各家互联网公司开始利用Google的分布式计算模型搭建自己的分布式计算系统,Google的这三篇论文也就成为了大数据时代的技术核心。
主流的三大分布式计算系统:Hadoop,Spark和Storm
由于Google没有开源Google分布式计算模型的技术实现,所以其他互联网公司只能根据Google三篇技术论文中的相关原理,搭建自己的分布式计算系统。
Yahoo的工程师Doug Cutting和Mike Cafarella在2005年合作开发了分布式计算系统Hadoop。后来,Hadoop被贡献给了Apache基金会,成为了Apache基金会的开源项目。Doug Cutting也成为Apache基金会的主席,主持Hadoop的开发工作。
Hadoop采用MapReduce分布式计算框架,并根据GFS开发了HDFS分布式文件系统,根据BigTable开发了HBase数据存储系统。尽管和Google内部使用的分布式计算系统原理相同,但是Hadoop在运算速度上依然达不到Google论文中的标准。
不过,Hadoop的开源特性使其成为分布式计算系统的事实上的国际标准。Yahoo,Facebook,Amazon以及国内的百度,阿里巴巴等众多互联网公司都以Hadoop为基础搭建自己的分布式计算系统。
Spark也是Apache基金会的开源项目,它由加州大学伯克利分校的实验室开发,是另外一种重要的分布式计算系统。它在Hadoop的基础上进行了一些架构上的改良。Spark与Hadoop最大的不同点在于,Hadoop使用硬盘来存储数据,而Spark使用内存来存储数据,因此Spark可以提供超过Hadoop100倍的运算速度。但是,由于内存断电后会丢失数据,Spark不能用于处理需要长期保存的数据。
Storm是Twitter主推的分布式计算系统,它由BackType团队开发,是Apache基金会的孵化项目。它在Hadoop的基础上提供了实时运算的特性,可以实时的处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。
Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。
spark采用RDD的分布式内存抽象,是一栈的大数据解决方案,包括spark core、spark streaming、spark sql、mllib,目的是不是补充hadoop 而是取而代之
还有一个比较关注的是spark的数据库,一个基于采样的数据库,可以在精度和效率上面权衡
Matei Zaharia's answer to Will Apache Spark ever overtake Apache Hadoop?
我自己的答案:
- 回答这类问题我们首先应该区分MapReduce,Apache Hadoop系统,和Hadoop生态圈
- MapReduce是和Spark并行的概念,两者都是计算引擎。两者的比较可以参见 Reynold Xin's answer to When is Hadoop MapReduce better than Spark? 。我倾向于这样总结:Spark通过lineage这个核心思想实现了基于内存的轻量的容错机制,取代了MR保守的硬盘数据冗余。
- Apache Hadoop系统其实就像一个操作系统。主要包含HDFS -相当于Linux下面的ext3,ext4,和Yarn - 相当于Linux下面的进程调度和内存分配模块。
- Hadoop生态圈包括Apache Hadoop以及更上层的应用。在Spark/MapReduce这一层计算引擎上面,还可以加Hive来做SQL,各种流处理应用,等等。比如Hive就有on MapReduce和on Spark两个版本。
- Spark不完全属于Hadoop生态圈,它也可以脱离Apache Hadoop。比如用红帽的Gluster FS做文件系统,Mesos做调度。但是从现在的情况来看它主要还是一个Hadoop应用。比如最近打破TeraSort纪录(Spark officially sets a new record in large-scale sorting)就是基于HDFS做的。
- 大数据这个概念就模糊多了。但我觉得最起码可以很安全的说 大部分的大数据应用运行在Hadoop生态圈里。
有什么关于 Spark 的书推荐?
Fei Dong | LinkedIn
Hadoop Spark学习小结[2014版]Hadoop
Hadoop社区依然发展迅速,2014年推出了2.3,2.4, 2.5 的社区版本,比如增强 Resource Manager HA, YARN Rest API, ACL on HDFS, 改进 HDFS 的 Web UI…
Hadoop Roadmap 根据我的观察,主要更新在Yarn,HDFS,而Mapreduce几乎停滞了,还有一些feature 属于安全,稳定可靠性一方面是比较稳定了,但也可以说是瓶颈了。
Apache Hadoop Project Members
这个是Hadoop project member and committee, 里面好多来自Hortonworks,也有不少国人上榜。
SparkSpark 介绍
Spark今年大放溢彩,Spark简单说就是内存计算(包含迭代式计算,DAG计算,流式计算 )框架,之前MapReduce因效率低下大家经常嘲笑,而Spark的出现让大家很清新。
Reynod 作为Spark核心开发者, 介绍Spark性能超Hadoop百倍,算法实现仅有其1/10或1/100
浅谈Apache Spark的6个发光点
Spark: Open Source Superstar Rewrites Future of Big Data
Spark is a really big deal for big data, and Cloudera gets it
其实起名字也很重要,Spark就占了先机,CTO说Where There’s Spark There’s Fire: The State of Apache Spark in 2014
Spark 起源
2010年Berkeley AMPLab,发表在hotcloud 是一个从学术界到工业界的成功典范,也吸引了顶级VC:Andreessen Horowitz的 注资
AMPLab这个实验室非常厉害,做大数据,云计算,跟工业界结合很紧密,之前就是他们做mesos,hadoop online, crowddb, Twitter,Linkedin等很多知名公司都喜欢从Berkeley找人,比如Twitter也专门开了门课程 Analyzing Big Data with Twitter 还有个BDAS (Bad Ass)引以为傲: The lab that created Spark wants to speed up everything, including cures for cancer
在2013年,这些大牛从Berkeley AMPLab出去成立了Databricks,半年就做了2次summit参会1000人,引无数Hadoop大佬尽折腰,大家看一下Summit的sponsor ,所有hadoop厂商全来了,并且各个技术公司也在巴结,cloudrea, hortonworks, mapr, datastax, yahoo, ooyala, 根据CTO说 Spark新增代码量活跃度今年远远超过了Hadoop本身,要推出商业化产品Cloud。
Spark人物
- Ion Stoica: Berkeley教授,AMPLab 领军
- Matei Zaharia: 天才,MIT助理教授
- Reynold Xin Apache Spark开源社区的主导人物之一。他在UC Berkeley AMPLab进行博士学业期间参与了Spark的开发,并在Spark之上编写了Shark和GraphX两个开源框架。他和AMPLab同僚共同创建了Databricks公司
- Andy Konwinski
- Haoyuan Li
- Patrick Wendell
- Xiangrui Meng
- Paco Nathan
- Lian Cheng
- Hossein Falaki
- Mosharaf Chowdhury
- Zongheng Yang
- Yin Huai
- Committers
Spark基本概念
- RDD——Resillient Distributed Dataset A Fault-Tolerant Abstraction for In-Memory Cluster Computing弹性分布式数据集。
- Operation——作用于RDD的各种操作分为transformation和action。
- Job——作业,一个JOB包含多个RDD及作用于相应RDD上的各种operation。
- Stage——一个作业分为多个阶段。
- Partition——数据分区, 一个RDD中的数据可以分成多个不同的区。
- DAG——Directed Acycle graph,有向无环图,反应RDD之间的依赖关系。
- Narrow dependency——窄依赖,子RDD依赖于父RDD中固定的data partition。
- Wide Dependency——宽依赖,子RDD对父RDD中的所有data partition都有依赖。
- Caching Managenment——缓存管理,对RDD的中间计算结果进行缓存管理以加快整 体的处理速度。
目前还有一些子项目,比如 Spark SQL, Spark Streaming, MLLib, Graphx 工业界也引起广泛兴趣,国内Taobao, baidu也开始使用:Powered by Spark
Apache Spark支持4种分布式部署方式,分别是Amazon EC2, standalone、spark on mesos和 spark on YARN 比如AWS
Spark Summit
2014 Summit
取代而非补充,Spark Summit 2014精彩回顾
拥抱Spark,机遇无限——Spark Summit 2013精彩回顾
Databricks Cloud Demo 今年最叫好的demo是Dtabricks Cloud, 把Twitter上面实时收集的数据做作为machine learning素材,用类似IPython notebook,可视化呈现惊艳,而搭建整个sampling系统就花了20分钟!
培训资料和视频
官方文档
Databricks Blog
Summit Training
Databricks upcoming training
Stanford Spark Class
CSDN Spark专栏
10月份还有个培训在湾区的培训,只不过3天就要1500刀,看来做个讲师也不错:)
第三方项目
- Web interactive UI on Hadoop/Spark
- Spark on cassandra
- Spark Cassandra Connector
- Calliope
- H2O + Spark
- Shark - Hive and SQL on top of Spark
- MLbase - Machine Learning research project on top of Spark
- BlinkDB - a massively parallel, approximate query engine built on top of Shark and Spark
- GraphX - a graph processing & analytics framework on top of Spark (GraphX has been merged into Spark 0.9)
- Apache Mesos - Cluster management system that supports running Spark
- Tachyon - In memory storage system that supports running Spark
- Apache MRQL - A query processing and optimization system for large-scale, distributed data analysis, built on top of Apache Hadoop, Hama, and Spark
- OpenDL - A deep learning algorithm library based on Spark framework. Just kick off.
- SparkR - R frontend for Spark
- Spark Job Server - REST interface for managing and submitting Spark jobs on the same cluster.
相关参考资料
Resilient Distributed Datasets
spark on yarn的技术挑战
Hive原理与不足
Impala/Hive现状分析与前景展望
Apache Hadoop: How does Impala compare to Shark
MapReduce:一个巨大的倒退
Google Dremel 原理 — 如何能3秒分析1PB
Isn’t Cloudera Impala doing the same job as Apache Drill incubator project?
Shark
Big Data Benchmark
How does Impala compare to Shark
EMC讲解Hawq SQL性能:左手Hive右手Impala
Shark, Spark SQL, Hive on Spark, and the future of SQL on Spark
Cloudera: Impala’s it for interactive SQL on Hadoop; everything else will move to Spark
Databricks – an interesting plan for Spark, Shark, and Spark SQL
Apache Storm vs Spark Streaming
Apache Spark源码走读
加州大学伯克利分校提出的mesos有哪些优缺点?
链接:https://www.zhihu.com/question/20043233/answer/52708295
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Docker Swarm与Apache Mesos的区别
summary:
Docker Swarm 是目前 Docker 社区原生支持的集群工具,它通过扩展 Docker API 力图让用户像使用单机 Docker API 一样来驱动整个集群;而 Mesos 是 Apache 基金会下的集群资源管理工具,它通过抽象主机的 CPU、内存、存储等计算资源来搭建一套高效、容错、弹性的分布式系统。
显然,这两者功能上有交集,网络上也有很多关于 Docker Swarm, Mesos 和 Kubernetes 之间区别的讨论,作为一个 Mesos 重度用户,最近也抽时间把玩了下 Docker Swarm。一路下来,Docker Swarm 给我的感觉首先是它特别简单、灵活,相较于 Mesos 而言, Docker Swarm 对集群的侵入性更小,从而资源损耗也更低;其次,我特别想强调的是目前看来,虽然它与 Mesos 之间功能有重叠,但是两者关注在不同的东西上了,所以拿这两者作比较没有多大意义。当然,未来这种情况可能会发生变化,这取决于社区的 roadmap 。下面我会从多个角度把 Docker Swarm 和 Mesos 进行比较。
============================我是分割线======================
Docker大火,我们公司也在使用Docker+Mesos,给出些自己的看法。
历史
先八卦一下Mesos的历史,其实Mesos并不是为Docker而生的,它产生的初衷是为spark做集群管理。而且,Mesos有自己的容器隔离,后来,随着Docker的崛起,Mesos就开始支持Docker容器了。再后来,google一哥们儿发了篇paper,对比google内部的borg(Omega?),Mesos和Yarn(是不是Yarn)三个集群管理工具的性能,大致结论就是Mesos跟google内部的集群管理工具有异曲同工之妙。有了Docker助力,再加上google的paper,大家就开始去尝试Mesos了。据我在网上搜罗的消息,国外的twitter,apple(用Mesos管理siri的集群),uber(uber的开发在Mesos的mail-list说他们已经使用Mesos有一段时间了,同时准备把更多的东西迁到Mesos集群上),国内的爱奇艺(视频转码),数人科技(敝公司)都已经或正在使用Mesos集群。
优点
- 资源管理策略Dominant Resource Fairness(DRF), 这是Mesos的核心,也是我们把Mesos比作分布式系统Kernel的根本原因。通俗讲,Mesos能够保证集群内的所有用户有平等的机会使用集群内的资源,这里的资源包括CPU,内存,磁盘等等。很多人拿Mesos跟k8s相比,我对k8s了解不深,但是,我认为这两者侧重点不同不能做比较,k8s只是负责容器编排而不是集群资源管理。不能因为都可以管理docker,我们就把它们混为一谈。
- 轻量级。相对于 Yarn,Mesos 只负责offer资源给framework,不负责调度资源。这样,理论上,我们可以让各种东西使用Mesos集群资源,而不像yarn只拘泥于hadoop,我们需要做的是开发调度器(mesos framework)。
- 提高分布式集群的资源利用率:这是一个 generic 的优点。从某些方面来说,所有的集群管理工具都是为了提高资源利用率。VM的出现,催生了IaaS;容器的出现,催生了k8s, Mesos等等。简单讲,同样多的资源,我们利用IaaS把它们拆成VM 与 利用k8s/Mesos把它们拆成容器,显然后者的资源利用率更高。(这里我没有讨论安全的问题,我们假设内部子网环境不需要考虑这个。)
缺点
- 门槛太高。只部署一套Mesos,你啥都干不了,为了使用它,你需要不同的mesos framework,像Marathon,chronos,spark等等。或者自己写framework来调度Mesos给的资源,这让大家望而却步。
- 目前对stateful service的支持不够。Mesos集群目前无法进行数据持久化。即将发布的0.23版本增加了persistent resource和dynamic reserver,数据持久化问题将得到改善。
- 脏活累活不会少。Team在使用Mesos前期很乐观,认为搞定了Mesos,我们的运维同学能轻松很多。然而,根本不是那么回事儿,集群节点的优化,磁盘,网络的设置,等等这些,Mesos是不会帮你干的。使用初期,运维的工作量不仅没有减轻,反而更重了。
- Mesos项目还在紧锣密鼓的开发中,很多功能还不完善。譬如,集群资源抢占还不支持。
R 如何解决R在大样本回归中,内存不足问题?
解决方案:用C,python,(julia?)
他们都是copy by reference。 B=A后内存只会多一个指针。而且他们对内存有更精确的控制,作并行运算的时候可以共享主要的数据。甚至你可以用或者自己实现运算不一定那么快但是需要内存少的算法。
偷懒的办法:既然是大样本,假设你的sample size 很大。那么可以取一个subsample(随机取一个子集,能放进内存就好)。 子集的结果和全部大样本的结果应该差别不大。因为回归的收敛速度还是挺快的么:)。
可不可以顺便问下,有没有什么可以auto variables selection的同时做time series的r package?
1. 随机采样200次,每一次采样20%的数据(当然200次和20%是我随便说的,你自己看情况定)
2. 给每个小样本作回归,这样你有200组参数
3. 取这200组参数的中位数作为解
1. 随机采样200次,每一次采样20%的数据(当然200次和20%是我随便说的,你自己看情况定)
2. 给每个小样本作回归,这样你有200组参数
3. 取这200组参数的中位数作为解
Michael Kane on Bigmemory
这个作者的一系列包,可以用shared memory来解决大数据集在R中的存储分析问题。当然SparkR在服务器上也是解决方法,但是应该对于单机个人用户big系列包应该是一个很好的解决方案。
同时请参考CRAN上的task view
CRAN Task View: High-Performance and Parallel Computing with R
中的Large memory and out-of-memory data一节,其中介绍了很多关于大数据集分析方法工具的软件包。
超超超大的樣本, 就在aws雲端開個Spark集群, 用SparkR, 賦予每個橫列(row)一個隨機數後grouping可以實現抽樣出數個子集, 把要用的模型套到MapReduce, 看不同子集所擬合的參數分佈
SparkR (R on Spark)
我给你个实际可行的方法就是,
租用Google或者Amazon的计算平台,对于新用户都有免费。比如我用Google,可以建一个虚拟机,用200G内存,总该满足你需求了。
当然,这是短期的,如果经常要处理大规模数据,确实R并不是很合适。
基于spark的深度学习怎么实现,具体应用实例?
Spark 貌似不支持直接支持 深度学习吧,你可以通过 deeplearning4j与Spark整合来支持。你也可以参考这个:https://github.com/sunbow1/SparkMLlibDeepLearnApache Spark项目于2009年诞生于伯克利大学的AMPLab实验室,当初的目的在于将内存内分析机制引入大规模数据集当中。在那个时候,Hadoop MapReduce的关注重点仍然放在那些本质上无法迭代的大规模数据管道身上。想在2009年以MapReduce为基础构建起分析模型实在是件费心费力而又进展缓慢的工作,因此AMPLab设计出Spark来帮助开发人员对大规模数据集执行交互分析、从而运行各类迭代工作负载——也就是对内存中的同一套或者多套数据集进行反复处理,其中最典型的就是机器学习算法。
Spark的意义并不在于取代Hadoop。正相反,它为那些高度迭代的工作负载提供了一套备用处理引擎。通过显著降低面向磁盘的写入强度,Spark任务通常能够在运行速度方面高出Hadoop MapReduce几个数量级。作为“寄生”在Hadoop集群当中的得力助手,Spark利用Hadoop数据层(HDFS、HBase等等)作为数据管道终端,从而实现原始数据读取以及最终结果存储。
编写Spark应用程序
作为由Scala语言编写的项目,Spark能够为数据处理流程提供一套统一化抽象层,这使其成为开发数据应用程序的绝佳环境。Spark在大多数情况下允许开发人员选择Scala、Java以及Python语言用于应用程序构建,当然对于那些最为前沿的层面、只有Scala能够实现大家的一切构想。
Spark当中的突出特性之一在于利用Scala或者Python控制台进行交互式工作。这意味着大家可以在尝试代码运行时,立即查看到其实际执行结果。这一特性非常适合调试工作——大家能够在无需进行编译的前提下变更其中的数值并再次处理——以及数据探索——这是一套典型的处理流程,由大量检查-显示-更新要素所构成。
Spark的核心数据结构是一套弹性分布式数据(简称RDD)集。在Spark当中,驱动程序被编写为一系列RDD转换机制,并附带与之相关的操作环节。顾名思义,所谓转换是指通过变更现有数据——例如根据某些特定指标对数据进行过滤——根据其创建出新的RDD。操作则随RDD自身同步执行。具体而言,操作内容可以是计算某种数据类型的实例数量或者将RDD保存在单一文件当中。
Spark的另一大优势在于允许使用者轻松将一套RDD共享给其它Spark项目。由于RDD的使用贯穿于整套Spark堆栈当中,因此大家能够随意将SQL、机器学习、流以及图形等元素掺杂在同一个程序之内。
熟悉各类其它函数型编程语言——例如LISP、Haskell或者F#——的开发人员会发现,除了API之外、自己能够非常轻松地掌握Spark编程方式。归功于Scala语言的出色收集系统,利用Spark Scala API编写的应用程序能够以干净而且简洁的面貌呈现在开发者面前。在对Spark编程工作进行调整时,我们主要需要考虑这套系统的分布式特性并了解何时需要对对象以及函数进行排序。
拥有其它程序语言,例如Java,知识背景的程序员则往往没办法快速适应Spark项目的函数编程范式。有鉴于此,企业可能会发现找到一位能够切实上手Spark(从这个角度讲,Hadoop也包含其中)的Scala与函数编程人员实在不是件容易的事。
<img src="https://pic2.zhimg.com/4b02ef9e99f644ee035f8f9b0ef30375_b.jpg" data-rawwidth="552" data-rawheight="295" class="origin_image zh-lightbox-thumb" width="552" data-original="https://pic2.zhimg.com/4b02ef9e99f644ee035f8f9b0ef30375_r.jpg">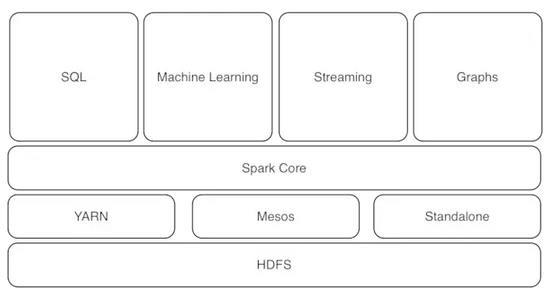
由于Spark的RDD能够实现跨系统共享,因此大家能够随意将SQL、机器学习、流以及图形等元素掺杂在同一个程序之内。
弹性分布式数据集
对于RDD的使用贯穿于整套堆栈当中,而这也成为Spark如此强大的根基之一。无论是从概念层面还是实施层面,RDD都显得非常简单; RDD类当中的大部分方法都在20行以内。而从核心角度看,RDD属于一套分布式记录集合,由某种形式的持久性存储作为依托并配备一系列转换机制。
RDD是不可变更的。我们无法对RDD进行修改,但却能够轻松利用不同数值创建新的RDD。这种不可变性算得上是分布式数据集的一大重要特性; 这意味着我们用不着担心其它线程或者进程在我们不知不觉中对RDD数值作出了变更——而这正是多线程编程领域的一个老大难问题。这同时意味着我们能够将RDD分发到整个集群当中加以执行,而不必担心该如何在各节点之间对RDD内容变更进行同步。
RDD不可变性在Spark应用程序的容错机制当中同样扮演着重要角色。由于每个RDD都保留有计算至当前数值的全部历史记录、而且其它进程无法对其作出变更,因此在某个节点丢失时对RDD进行重新计算就变得非常轻松——只需要返回原本的持久性数据分区,再根据不同节点重新推导计算即可。(Hadoop当中的大多数分区都具备跨节点持久性。)
RDD能够通过多种数据分区类型加以构成。在大多数情况下,RDD数据来自HDFS,也就是所谓“分区”的书面含义。不过RDD也可以由来自其它持久性存储机制的数据所构成,其中包括HBase、Cassandra、SQL数据库(通过JDBC)、Hive ORC(即经过优化的行列)文件乃至其它能够与Hadoop InputFormat API相对接的存储系统。无论RDD的实际来源如何,其运作机制都是完全相同的。
Spark转换机制的最后一项备注是:此类流程非常懒惰,也就是说直到某项操作要求将一条结果返回至驱动程序,否则此前整个过程不涉及任何计算环节。这样的特性在与Scala shell进行交互时显得意义重大。这是因为RDD在逐步转换的过程当中不会带来任何资源成本——直到需要执行实际操作。到这个时候,所有数值才需要进行计算,并将结果返回给用户。除此之外,由于RDD能够利用内存充当缓存机制,因此频繁使用计算结果也不会造成反复计算或者由此引发的资源消耗。
<img src="https://pic2.zhimg.com/8f99ad9074e249324a00e68e58939729_b.jpg" data-rawwidth="594" data-rawheight="119" class="origin_image zh-lightbox-thumb" width="594" data-original="https://pic2.zhimg.com/8f99ad9074e249324a00e68e58939729_r.jpg">
Spark转换机制非常懒惰,也就是说直到某项操作要求将一条结果返回至用户处,否则此前整个过程不涉及任何计算环节。
执行Spark应用程序
为了将一项Spark任务提交至集群,开发人员需要执行驱动程序并将其与集群管理器(也被称为cluster master)相对接。集群管理器会为该驱动程序提供一套持久性接口,这样同一款应用程序即可在任何受支持集群类型之上实现正常运行。
Spark项目目前支持专用Spark(独立)、Mesos以及YARN集群。运行在集群当中的每个驱动程序以各自独立的方式负责资源分配与任务调度工作。尽管以隔离方式进行应用程序交付,但这种架构往往令集群很难高效实现内存管理——也就是对于Spark而言最为宝贵的资源类型。多个高内存消耗任务在同时提交时,往往会瞬间将内存吞噬殆尽。尽管独立集群管理器能够实现简单的资源调度,但却只能做到跨应用程序FIFO(即先入先出)这种简单的程度,而且无法实现资源识别。
总体而言,Spark开发人员必须更倾向于裸机层面思维,而非利用像Hive或者Pig这样的高级应用程序将数据分析作为思考出发点。举例来说,由于驱动程序充当着调度任务的执行者,它需要最大程度与这些工作节点保持紧密距离、从而避免网络延迟对执行效果造成的负面影响。
驱动程序与集群管理器高可用性这两者都很重要。如果驱动程序停止工作,任务也将立即中止。而如果集群管理器出现故障,新的任务则无法被提交至其中,不过现有任务仍将继续保持执行。在Spark 1.1版本当中,主高可用性机制由独立Spark集群通过ZooKeeper实现,但驱动程序却缺乏与高可用性相关的保障措施。
将一套Spark集群当中的性能最大程度压榨出来更像是一种魔法甚至妖术,因为其中需要涉及对驱动程序、执行器、内存以及内核的自由组合及反复实验,同时根据特定集群管理器对CPU及内存使用率加以优化。目前关于此类运维任务的指导性文档还非常稀缺,而且大家可能需要与同事进行频繁沟通并深入阅读源代码来实现这一目标。
<img src="https://pic3.zhimg.com/6ede2e5d81161192c22ac8b1f77156f2_b.jpg" data-rawwidth="565" data-rawheight="262" class="origin_image zh-lightbox-thumb" width="565" data-original="https://pic3.zhimg.com/6ede2e5d81161192c22ac8b1f77156f2_r.jpg">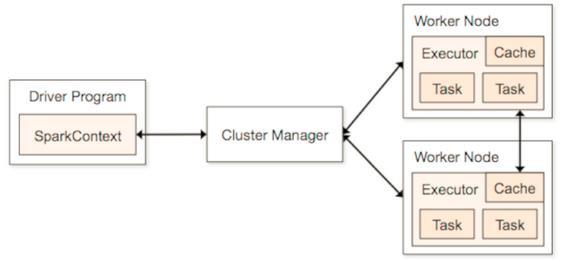
Spark应用程序架构。Spark目前可以被部署在Spark独立、YARN或者Mesos集群当中。请注意,运行在集群当中的每一个驱动程序都会以彼此独立的方式进行资源分配与任务调度。
监控与运维
每一款驱动程序都拥有自己的一套Web UI,通常为端口4040,其中显示所有实用性信息——包括当前运行任务、调度程度、执行器、阶段、内存与存储使用率、RDD等等。这套UI主要充当信息交付工具,而非针对Spark应用程序或者集群的管理方案。当然,这也是调试以及性能调整之前的基础性工具——我们需要了解的、与应用程序运行密切相关的几乎所有信息都能在这里找到。
虽然算是个不错的开始,但这套Web UI在细节方面仍然显得比较粗糙。举例来说,要想查看任务历史记录、我们需要导航到一台独立的历史服务器,除非大家所使用的是处于独立模式下的集群管理器。不过最大的缺点在于,这套Web UI缺少对于运维信息的管理与控制能力。启动与中止节点运行、查看节点运行状况以及其它一些集群层面的统计信息在这里一概无法实现。总体而言,Spark集群的运行仍然停留在命令行操作时代。
<img src="https://pic1.zhimg.com/83f3a05dcda66bc606bd256d1bbfcbb0_b.jpg" data-rawwidth="560" data-rawheight="411" class="origin_image zh-lightbox-thumb" width="560" data-original="https://pic1.zhimg.com/83f3a05dcda66bc606bd256d1bbfcbb0_r.jpg">
Spark的Web UI提供了与当前运行任务相关的丰富信息,但所有指向集群的管理操作则需要完全通过命令行来实现。
Spark对决Tez
事实上,Spark与Tez都采用有向无环图(简称DAG)执行方式,这两套框架之间的关系就如苹果与桔子般不分轩轾,而最大的差别在于其受众以及设计思路。即使如此,我发现很多IT部门仍然没能分清这两款框架间的差异所在。
Tez是一款应用程序框架,设计目的在于帮助开发人员编写出更为高效的多级MapReduce任务。举例来说,在Hive 0.13版本当中,HQL(即Hive查询语言)由语言编译器负责解析并作为Tez DAG进行渲染,即将数据流映射至处理节点处以实现高效执行。Tez DAG由应用程序以边缘到边缘、顶点到顶点的方式进行构建。用户则完全不需要了解Tez DAG的构建方式,甚至感受不到它的存在。
Spark与Tez之间的真正差异在于二者实现方式的不同。在Spark应用程序当中,同样的工作节点通过跨迭代实现重新使用,这就消除了JVM启动所带来的资源成本。Spark工作节点还能够对变量进行缓存处理,从而消除对数值进行跨迭代重新读取与重新计算的需要。正是借鉴着以上几大特征,Spark才能够在迭代编程当中如鱼得水、充分发力。而由此带来的缺点是,Spark应用程序会消耗大量集群资源、特别是在缓存过期的情况下。我们很难在集群运行着Spark的时候对资源进行优化。
尽管支持多级任务执行机制,Tez仍然不具备任何形式的缓存处理能力。虽然变量能够在一定程度上得到缓存处理,从而保证规划器在可能的情况下保证调度任务从同节点中的上一级处获取必要数值,但Tez当中仍然未能提供任何一种经过妥善规划的跨迭代或者变量广播机制。除此之外,Tez任务还需要反复启动JVM,而这会带来额外的资源开销。因此,Tez更适合处理那些规模极为庞大的数据集,在这种情况下启动时间只占整体任务处理周期的一小部分、几乎可以忽略不计。
在大多数情况下,Hadoop社区对此都拥有很好的移花接木式解决方案,而且其中最出色的部分机制已经能够作用于其它项目。举例来说,YARN-1197将允许Spark执行器以动态方式进行规模调整,这样它们就能够在合适的条件下将资源返还给集群。与之相似,Stinger.next将为Hive等传统Hadoop应用程序带来由跨查询缓存提供的巨大优势。
一整套集成化分析生态系统
Spark所采用的底层RDD抽象机制构建起整个Spark生态系统的核心数据结构。在机器学习(MLlib)、数据查询(Spark SQL)、图形分析(GraphX)以及流运行(Spark Streaming)等模块的共同支持下,开发人员能够以无缝化方式使用来自任意单一应用程序的库。
举例来说,开发人员可以根据HDFS当中的某个文件创建一个RDD,将该RDD转换为SchemaRDD、利用Spark SQL对其进行查询,而后将结果交付给MLlib库。最后,结果RDD可以被插入到Spark Streaming当中,从而充当消息交付机制的预测性模型。如果要在不使用Spark项目的情况下实现以上目标,大家需要使用多套库、对数据结构进行封包与转换,并投入大量时间与精力对其加以部署。总体而言,将三到上个在最初设计当中并未考虑过协作场景的应用程序整合在一起绝对不是正常人的脆弱心灵所能承受的沉重负担。
堆栈集成机制让Spark在交互式数据探索与同一数据集内的重复性函数应用领域拥有着不可替代的重要价值。机器学习正是Spark项目大展拳脚的理想场景,而在不同生态系统之间以透明方式实现RDD共享的特性更是大大简化了现代数据分析应用程序的编写与部署流程。
然而,这些优势的实现并非全无代价。在1.x系列版本当中,Spark系统在诸多细节上还显得相当粗糙。具体而言,缺乏安全性(Spark无法运行在Kerberised集群当中,也不具备任务控制功能)、缺乏企业级运维功能、说明文档质量糟糕,而且严苛的稀缺性技能要求意味着目前Spark仍然只适合早期实验性部署或者那些有能力满足大规模机器学习模型必需条件且愿意为其构建支付任何投入的大型企业。
到底应不应该部署Spark算是一个“仁者见仁,智者见智”的开放性议题。对于一部分组织而言,Spark这套速度极快的内存内分析引擎能够带来诸多优势,从而轻松为其带来理想的投资回报表现。但对于另一些组织来说,那些虽然速度相对较慢但却更为成熟的工具仍然是其不二之选,毕竟它们拥有适合企业需求的完善功能而且更容易找到有能力对其进行管理与控制的技术人员。
无论如何,我们都要承认Spark的积极意义。Spark项目将一系列创新型思维带入了大数据处理市场,并且表现出极为强劲的发展势头。随着其逐步成熟,可以肯定Spark将最终成为一支不容忽视的巨大力量。
<img src="https://pic2.zhimg.com/200ea9a38a8acce589b18f3ee9d00cd9_b.jpg" data-rawwidth="586" data-rawheight="128" class="origin_image zh-lightbox-thumb" width="586" data-original="https://pic2.zhimg.com/200ea9a38a8acce589b18f3ee9d00cd9_r.jpg">
Apache Spark 1.1.0 / Apache软件基金会
总结性描述
作为一套配备精妙API以实现数据处理应用程序创建目标的高速内存内分析引擎,Spark在迭代工作负载这类需要重复访问同一套或者多套数据集的领域——例如机器学习——表现出无可匹敌的竞争优势。
基于Apache 2.0许可的开源项目
优势
• 精妙且具备一致性保障的API帮助开发人员顺利构建起数据处理应用程序
• 支持Hadoop集群上的交互式查询与大规模数据集分析任务
• 在运行迭代工作负载时拥有高出Hadoop几个数量级的速度表现
• 能够以独立配置、YARN、Hadoop MapReduce或者Mesos等方式部署在Hadoop集群当中
• RDD(即弹性分布式数据集)能够在不同Spark项目之间顺利共享,从而允许用户将SQL、机器学习、流运行以及图形等元素掺杂在同一程序当中
• Web UI提供与Spark集群及当前运行任务相关的各类实用性信息
缺点
• 安全性不理想
• 说明文档质量糟糕
• 不具备集群资源管理能力
• 学习曲线不够友好
热爱大数据的话欢迎加我们信微:idacker
我被这东西快弄疯了…… 半年内版本升级到1.3了,依赖的hive还要0.13.1版本,人家hive都升级到1.1了。回头又要依赖hadoop的mapredue和yarn,还要2.4版本的,可是人家都升级到2.6了。
Spark SQL 到底怎么搭建起来?
别告诉我那你就用0.13.1的hive和2.4的hadoop啊,2.4的hadoop已经被官方抛弃了,连官方下载链接都没有,2.x的版本,最古老的链接也是2.5.2的。0.13.1的hive的确有,可是人家都1.1了啊,好多东西都变了啊,网上连教程都变了啊。
回头再说SparkSQL,他只是Spark的一个Module,可是却要依赖这么多,还要依赖Scala,还要特定2.10.4版本,还要依赖hive,hive要依赖yarn,mapreduce又是必须的……
在网上各种爬文,我都买了个DigitalOcean服务器来搜外文,结果搜到的也还是古老的,挥着零散的部署教程,就是要么只告诉你spark怎么部署,要么告诉你sparksql怎么用,要么告诉你hive怎么搭,然后各个版本还不能依赖到一起去…
做毕设都半年了,前期就是写sql代码来着,最后就靠这玩意来加速跑代码,结果死活搭不起来,去年弄了半个月,不行,今年这有弄了半个月,还不行……真是醉了……
求哪位大神快出现啊!!! T_T 我真是跪了…… 给我个从头到尾搭起 SparkSQL 的教程就行…… 么么哒……
链接:https://www.zhihu.com/question/29585524/answer/44883019
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
PS:补充一下这个是Python API,不是Scala的。
import os
import sys
import traceback
# Path for spark source folder
os.environ['SPARK_HOME']="/Users/jilu/Downloads/spark-1.3.0-bin-hadoop2.4"# Append pyspark to Python Path
sys.path.append("/Users/jilu/Downloads/spark-1.3.0-bin-hadoop2.4/python/")
sys.path.append("/Users/jilu/Downloads/spark-1.3.0-bin-hadoop2.4/python/lib/py4j-0.8.2.1-src.zip")# try to import needed models
try:from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql import SQLContext, Row
print ("Successfully imported Spark Modules")except ImportError as e:print ("Can not import Spark Modules {}".format(traceback.format_exc()))sys.exit(1)# config spark env
conf = SparkConf().setAppName("myApp").setMaster("local")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)您好,请问Spark用python通过jdbc读数据库数据您用过吗?我没有成功,但是Scala和Java可以通过jdbc读到数据。求助,谢谢!我也是用Scala,我记得Spark的数据输入输出那一块Python支持的不太好,除了RESTful和文件之外Python API不是没有就是有问题。你也可以使用Spark Standalone模式(文档https://spark.apache.org/docs/latest/spark-standalone.html),官方又启动脚本,直接帮你完成所有的部署,不需要Hadoop,不需要Hive,不需要MySQL
如果集群要nb的机器
***测试环境
用docker好些 机器损耗小 普通macmini都可以搭出hadoop/spark最小三节点集群
参考
使用docker打造spark集群
***生产环境
未来生产环境部署hadoop/spark到物理机 应该情景不多
多是云端的大数据处理paas例如azure的hdinsight
(当然云端也可以用docker)
节省成本 少维护 少硬件损耗(aws azure的数据流入流量都是不计费的)
尽快上算法/应用才是王道
spark在aws上已经能做到1tb数据-》1rmb成本了
基本大数据的运算量12tb 的spark运算成本是12rmb(节点无限伸缩)
按照这个成本 自建hadoop/spark集群的硬件意义不大
(这个百节点要上百万还有维护损耗
顶级国安或者军事金融部门的需求另说
当然如果有采购贪污需求的也另说
其它行业正经做事不用云处理大数据是傻蛋)
问题是大数据的场景何在
weblog 达到12tb/天的网站中国过不去10家
不好意思,我没有在quickstart VM上用过Spark SQL, 但是我在CDH5.1 的release note上看到这样的话
Spark SQL
Spark SQL, which deserves a blog post of its own, is a new Spark component that allows you to run SQL statements inside of a Spark application that manipulate and produce RDDs. Due to its immaturity and alpha component status, Cloudera does not currently offer commercial support for Spark SQL. **However, we bundle it with our distribution so that users can try it out.**
如果没有理解错的话,应该是CDH已经包含了,只是不提供官方支持。另外Spark 1.3 对Spark SQL有重大更新,引入了Data Frame RDD,以更好地支持结构化数据。
再补充一点,Spark 并不是一定要绑定Hadoop,如果你仅仅是学习用,不打算把数据放到HDFS上, 你从github上下一个最新版的spark,编译一下就可以了。
试用的话,直接下 sandbox虚拟机文件
hadoop,spark在虚拟机集群里跑还有性能上的优势吗?修改
反正最终都是服务器的内存和硬盘,我感觉用多线程,多进程的老方法,直接在服务器上跑,省去那些集群间的调度和网络io,是不是会更快一些?
小白不懂,求大侠相助
- 资源隔离。有些集群是专用的,比如给你三台设备只跑一个spark,那还算Ok。但在很多规模很小的团体中,在有限的硬件设备的情况下,又要跑spark,比如又要跑zookeeper、kafka等等,这个时候,我们希望它们之间是不会互相干扰的。假设你spark的配置没做好,内存占用太大了,你总不希望把你好端端zookeeper给影响得挂掉(躺枪_(:з」∠)_)。那么此时虚拟机或者容器技术可以对物理资源进行隔离,防止这种情况出现。
- 快速部署,简化配置。无论对于新手还是老手来说,干这行非常痛苦的一点是各种框架的配置和部署,大量重复工作,又不怎么需要动脑子。所以你当然希望有一种方式,直接把你已经配置好的环境保存下来,作为一个镜像,然后当集群要扩展了,比如又增加了一个物理设备,你希望在上面虚拟化成三台虚拟机,两台运行spark,一台运行zookeeper,那简单了,把spark的镜像copy两份,zookeeper的镜像copy一份,网络配置好,开起来,一切都是那么潇洒...
- 调度单元。更高级的应用中,数据平台向整个团体或者公众提供服务。用户A希望有资源运行自己的应用,用户B也希望运行自己的应用,无论从安全角度还是管理角度上来说你都不希望他们之间是混杂的,这时候虚拟机也是一种解决方案。如果做一个高级点的调度器,当感知到spark工作压力非常大的时候启动一个zk镜像,反之减少一个镜像……这些功能在有虚拟机进行隔离时都会简单很多很多。
随便想了几个理由,应该还有很多,虚拟化这方面的专家应该更有发言权,毕竟干分布式计算的也只是虚拟化技术的受益者之一。
问题中谈到了性能,当然虚拟化的引入比裸奔性能上一定会有影响,如果影响很大的话,在做架构设计的时候就要根据实际需求进行取舍;然而比如像container,docker等轻量级虚拟化技术的出现,使它对性能的影响被压缩到了一个很小的地步,对于大多数分布式系统来说,这点性能损耗并不会有太大的影响……然后你懂的……
更重要不要做虚拟化的原因是你的很多hadoop虚拟机很有可能其实是跑在一台物理服务器上的,那这台物理服务器宕机就会导致整个集群不可用。
另外,虚拟化也可能使用的是共享存储,那么这样会让hadoop内建的冗余机制变得毫无意义。
第三,虚拟化里,你无法划分正确的机架来让hadoop合理的分布数据块存放位置。
最后,虚拟化的网络是软件定义的,底层发生问题你很难对hadoop定位和排错。
这些才是不要用虚拟化最重要的原因,排除这些才谈到性能问题。
当然曾经也有人跟我抬杠,说一台服务器只做一个虚拟机不就好了吗?可问题是,你要这样做的话为什么不直接装hadoop,非要为了部署方便而白白浪费掉30%的性能呢。每三台服务器就会浪费掉一台物理机的计算能力,代价太大了,除非土豪的国企或政府,否则没人会这么干。
1. 性能的隔离是有必要的,不然就会相互干扰,单个物理节点下用多线(进)程的方式的确从直观上性能是比虚拟化后要好,但是虚拟机带来的好处就是,一个服务器上可以跑多个集群,这些虚拟机可以分属于不同的集群。你怎么在一台服务器上裸奔多个Spark集群呢?
2. 虚拟化技术作为云计算的基础,有其优势,它可以提供弹性资源服务,总体上是可以提高硬件使用率的,性能和资源使用率之间是存在一个tradeoff的。
3. 在按时间的计费模式下,像Spark这种对内存和CPU使用率较高的集群,部署到公有云中性价比较高。
另外一点,Hadoop部署到虚拟机集群中也已经有很多很多成熟的研究成功和工业产品,至于性能,据前Spark团队leader明风透露,阿里巴巴内部曾经试验过,大概性能损耗10%,这在大规模分布式系统中,和数据中心资源利用率比起来,应该不足为道。
其实要看你们公司想怎么搞了,要是这些机器就用来跑你的这个集群,那就裸奔试试看呗,不然的话,虚拟化还是有存在的必要的。
另外,传送门
[1]Three reasons you need to run Spark in the cloud
[2]Databricks Cloud: Making Big Data Easy
spark的关键在内存
虚拟机,没错,跑当然能跑,尤其作为测试环境,但是扯得蛋真的很疼,是真的很疼的那种
如果生产环境资源有限,spark可以放在vm中跑,只要载入数据时注意点; Hadoop就尽量在物理机上面跑吧,节点少点比n个vm都强太多
经验之谈,你在太平洋攒10台pc远比你买一台hp的2U跑虚拟机让Hadoop来得畅快
我们用的是hp的2U机器25块900gb硬盘物理机作为节点来跑的,酸爽
docker是最近很热的microservices的基础,很多产品级的服务都已经迁移的docker上了,所以docker可以说基本成熟了。另外docker容器对宿主机来说就是一个进程而已,内核级的开销很小,所以和创建一个虚拟机比,怎么会消耗更多内存呢?另外,对于学习目的的集群,稳定性真的这么重要吗?
我们用4核8G x86跑HDP镜像,在dock中启动6个container,两个namenode,四个datanode。基本上每次跑mapreduce都会失败,提示network refused,虚拟内存达到4个G。最后不得不destroy container再rebuild,导致hdfs上结果文件丢失,需要重新跑。每次执行都提心吊胆。最后,还是换成单机镜像了。。用 standalone 的方式跑不挺好,大部分人的机子跑不起 spark 的用standlone模式当然也可以,但是如果能模拟集群的运行状态,岂不是更好。毕竟真正的应用都是跑在集群上的。spark版本演进很快,用docker验证一个新版本,是非常方便的。它不会干扰你主机上跑的任何东西。1)学搭建用docker镜像意义不大 2)作为开发环境,你哪怕执行个 wordcount 无论数据多少,那速度,调试到你奔溃;不论 lxc 还是虚拟机,性能都强不过宿主机(更何况大部分人的开发机是 windows,先搭个 vbox ,再在上面搭个docker),spark 在哪跑更快,可想而知docker的好处一是你可以试错,spark新版本出来了,你可以跑跑看,不会影响你现有的环境。第二是你可以搭配其它docker,比如kafka,比如Nosql用。组成一个更接近生产系统的真实大数据环境。 我当然是装过才这么说的。单机处理能力摆在那里,根本不应该拿来跑完整的数据集,你可以采样以后跑。但是在单机上,我们要验证算法的正确性。所以模拟一个近生产系统的环境还是有必要的。 感觉目前在大集群管理系统中,应用docker做资源隔离容器(替代系统级进程或JVM进程)的要比用docker搭建集群更多些,因为docker本身的特性,使得支持docker容器的资源管理框架能够支持更多类型的应用(例如Web)。之前也看多不少hadoop on docker的文章、dockerfile,但实际上由于docker在文件系统上还是存在不足的,所以也鲜见实际应用的。在各种傻瓜式部署软件例如cdh、cloudera manager的帮助下,环境的搭建反而不那么困难。在生产环境docker on hadoop的意义应当远胜于hadoop on docker,不过对于初学者学习而言,或许算是一个不错的选择,足够直观简洁。个人浅见~承蒙各位捧场,给赞,我想把我的回答再澄清一下。首先,我想回答的问题是大数据学习者如何搭建一个学习环境。并不是如何搭建一个生产环境。实验和生产环境是有很大区别的。docker目前可能还不太适合用于生产环境,但是用于实验是绝对没有问题的,而且非常方便,搭建快速。github什么有很多例子,大家可以参考借鉴一下。
- 学会大数据框架应用开发;
- 学会大数据框架;
第一点相对简单,前面很多位都有回答,没有错,spark可以单机部署的,基本上主流框架都能单机部署,所以老老实实低头下载、编译、部署、coding、测试吧,多看文档和源码,多写代码,少看《xx天精通xx》之类的东西(不过可以参考玩玩,别当真就行)。
关于机器配置,其实也不用太夸张,这无非又是给自己的惰性找个借口罢了,主流能跑得动LOL的机器都能满足你基本的测试学习需要了,实在不行就壮士断腕放弃游戏直接把系统装成linux……所以关键还是你学习欲望是否强烈的问题。
当然其实也没有那么简单,大数据量和小数据量毕竟有本质上的区别,根本就是两个世界的东西,处理100M和100T数据的区别不只是时间长短、节点多少的问题,有些问题只有在大规模数据处理时才会遇到,能够解决好这类问题的人就很厉害了,也是这行门槛所在。
那么重点我想谈谈的是第二个情况:假设你想学好框架。
Hadoop 和Spark发展到了今天,都已经不仅仅是一个计算框架了,而使已经演化成了生态完整的系统,很多这个行业最优秀的程序员为它们做了贡献。赞美开源世界,这些代码对你都是Open的,那么就去阅读好了,带着目的的那种。比如你看到了spark standalone的任务提交流程代码,那么为什么它这么搞?能从中借鉴什么?假设哪天自己要设计一个别的分布式系统时是否能够参考?有什么优缺点?这些东西我认为在没有集群的情况下都是能够做的。
假设有这样的积累,当开始工作时,你放心:任何系统都会出现问题,当问题发生时对你来说应该一切都是脉络清晰的;任何系统都不可能满足所有需求,当新需求spark/hadoop或者其他什么的满足不了需求时需要重新开发或者改造时,你应该使思路活跃的,应该是能够直击问题关键点的。当然这些锻炼在没有集群和实际操作的情况下是很难做到的,但可以先做好准备。
我定义学好,在于系统的每个动作对你来说都是很清晰的,你知道它做这个动作的理由,它的实现方法,这个动作产生的影响,可能会出现问题的点……我比较笨,大概只能想到好好积累这一种手段……
如果你只是学习怎么用hadoop和spark单机跑就是了。如果你非要用cluster,去组一个就是了。这么多提供cloud服务的公司呢,也不贵。国内用阿里,国外Amazon的EC2和Google的GCP都行。 可能对vagrant docker完全不了解? 如果你只是学习怎么用hadoop和spark单机跑就是了。如果你非要用cluster,去组一个就是了。这么多提供cloud服务的公司呢,也不贵。国内用阿里,国外Amazon的EC2和Google的GCP都行。
链接:https://www.zhihu.com/question/37026972/answer/87828727
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
<img data-rawheight="632" data-rawwidth="1358" src="https://pic3.zhimg.com/fbdbae02c1b58ad2def6f8b3e5c339b6_b.png" class="origin_image zh-lightbox-thumb" width="1358" data-original="https://pic3.zhimg.com/fbdbae02c1b58ad2def6f8b3e5c339b6_r.png">
Spark安装非常简单,如需本地安装可以参考以下步骤。
1. 安装
1.1 安装前准备
安装Spark之前需要先安装Java,Scala及Python。
安装Java
实验楼环境中已经安装了JDK,这里打开桌面上的Xfce终端,执行查看Java版本:
<img data-rawheight="169" data-rawwidth="682" src="https://pic4.zhimg.com/f250ba5f3c6bd2dad21f19249b9209bb_b.jpg" class="origin_image zh-lightbox-thumb" width="682" data-original="https://pic4.zhimg.com/f250ba5f3c6bd2dad21f19249b9209bb_r.jpg">
可以看到实验楼的Java版本是1.8.0_60,满足Spark 1.5.1对Java版本的要求。
如果需要自己安装可以在Oracle的官网下载Java SE JDK,下载链接:Java SE - Downloads。
安装Scala
老版本的Spark安装前需要先装Scala,1.5.1版本可以无需这一步骤。但为了自己开发Scala程序调试的方便我们仍然安装一个最新版本2.11.7的Scala。
Scala官网下载地址:http://www.scala-lang.org/download/
<img data-rawheight="646" data-rawwidth="896" src="https://pic1.zhimg.com/aa486bad337fa300446c4d277e404880_b.jpg" class="origin_image zh-lightbox-thumb" width="896" data-original="https://pic1.zhimg.com/aa486bad337fa300446c4d277e404880_r.jpg">
由于官网速度很慢,我们预先上传到了实验楼内网,下载并解压到/opt/目录:
wget http://labfile.oss.aliyuncs.com/courses/456/scala-2.11.7.tgz
tar zxvf scala-2.11.7.tgz
sudo mv scala-2.11.7 /opt/
测试scala命令,并查看版本:
<img data-rawheight="125" data-rawwidth="695" src="https://pic1.zhimg.com/d92147fb9a9016ce1c91f09341f865d0_b.jpg" class="origin_image zh-lightbox-thumb" width="695" data-original="https://pic1.zhimg.com/d92147fb9a9016ce1c91f09341f865d0_r.jpg">
安装Python及IPython
安装执行命令:
sudo apt-get update
sudo apt-get install python ipython
实验楼中已经安装了Python及IPython,分别查看版本:
<img data-rawheight="165" data-rawwidth="402" src="https://pic1.zhimg.com/eaddcfc021a2e4440d65159ad48b2fb8_b.jpg" class="content_image" width="402">
1.2 Spark下载
课程中使用目前最新稳定版:Spark 1.5.1,官网上下载已经预编译好的Spark binary,直接解压即可。
Spark官方下载链接:Downloads | Apache Spark
下载页面中我们如下图选择Pre-build for Hadoop 2.6 and later并点击下载:
<img data-rawheight="752" data-rawwidth="968" src="https://pic2.zhimg.com/56200e96756095d44ee51667ca91fb3d_b.jpg" class="origin_image zh-lightbox-thumb" width="968" data-original="https://pic2.zhimg.com/56200e96756095d44ee51667ca91fb3d_r.jpg">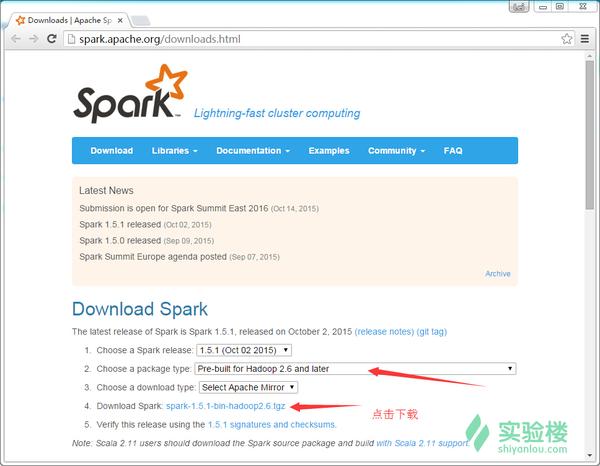
为了节约时间,我们选择从阿里云的镜像下载:
wget http://mirrors.aliyuncs.com/apache/spark/spark-1.5.1/spark-1.5.1-bin-hadoop2.6.tgz
大约268M大小,下载完成后解压并拷贝到/opt/目录:
tar zxvf spark-1.5.1-bin-hadoop2.6.tgz
sudo mv spark-1.5.1-bin-hadoop2.6 /opt/
进入到spark目录查看目录结构,本节实验中会用到bin/目录下的操作命令以及conf/目录下的配置文件。
1.3 配置路径与日志级别
为了避免每次都输入/opt/spark-1.5.1-bin-hadoop2.6这一串前缀,我们将必要的路径放到PATH环境变量中(实验楼用的是zsh,所以配置文件为~/.zshrc):
# 添加配置到zshrc
echo "export PATH=$PATH:/opt/spark-1.5.1-bin-hadoop2.6/bin" >> ~/.zshrc# 使zshrc起作用
source ~/.zshrc# 测试下spark-shell的位置是否可以找到
which spark-shell
我们进入到spark的配置目录/opt/spark-1.5.1-bin-hadoop2.6/conf进行配置:
# 进入配置目录
cd /opt/spark-1.5.1-bin-hadoop2.6/conf# 基于模板创建日志配置文件
cp log4j.properties.template log4j.properties# 使用vim或gedit编辑文件log4j.properties
# 修改log4j.rootCategory为WARN, console,可避免测试中输出太多信息
log4j.rootCategory=WARN, console# 基于模板创建配置文件
sudo cp spark-env.sh.template spark-env.sh# 使用vim或gedit编辑文件spark-env.sh
# 添加以下内容设置spark的环境变量
export SPARK_HOME=/opt/spark-1.5.1-bin-hadoop2.6
export SCALA_HOME=/opt/scala-2.11.7
spark-env.sh配置如图:
<img data-rawheight="542" data-rawwidth="842" src="https://pic1.zhimg.com/21e4cbc6a1aff91562f4883d1ee26c64_b.jpg" class="origin_image zh-lightbox-thumb" width="842" data-original="https://pic1.zhimg.com/21e4cbc6a1aff91562f4883d1ee26c64_r.jpg">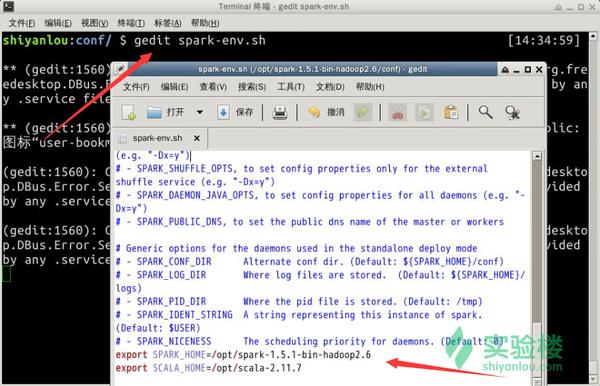
spark-env.sh脚本会在启动spark时加载,内容包含很多配置选项及说明,在以后的实验中会用到少部分,感兴趣可以仔细阅读这个文件的注释内容。
至此,Spark就已经安装好了,Spark安装很简单,依赖也很少。
后续几节介绍简单的Spark操作,为以后的实验做基础。
1.4 Spark-Shell
Spark-Shell是Spark自带的一个Scala交互Shell,可以以脚本方式进行交互式执行,类似直接用Python及其他脚本语言的Shell。
进入Spark-Shell只需要执行spark-shell即可:
spark-shell
进入到Spark-Shell后可以使用Ctrl D组合键退出Shell。
在Spark-Shell中我们可以使用scala的语法进行简单的测试,比如下图所示我们运行下面几个语句获得文件/etc/protocols的行数以及第一行的内容:
<img data-rawheight="227" data-rawwidth="828" src="https://pic4.zhimg.com/77a89194b89ada0f62ceba76bc79ba27_b.jpg" class="origin_image zh-lightbox-thumb" width="828" data-original="https://pic4.zhimg.com/77a89194b89ada0f62ceba76bc79ba27_r.jpg">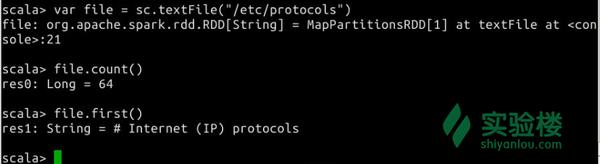
上面的操作中创建了一个RDD file,执行了两个简单的操作:
- count()获取RDD的行数
- first()获取第一行的内容
我们继续执行其他操作,比如查找有多少行含有tcp和udp字符串:
<img data-rawheight="85" data-rawwidth="443" src="https://pic3.zhimg.com/d6163829db2711205dc6c9f3b65754c6_b.jpg" class="origin_image zh-lightbox-thumb" width="443" data-original="https://pic3.zhimg.com/d6163829db2711205dc6c9f3b65754c6_r.jpg">
查看一共有多少个不同单词的方法,这里用到Mapreduce的思路:
<img data-rawheight="117" data-rawwidth="537" src="https://pic1.zhimg.com/099feaa44189110662b8b06ed7bacb38_b.jpg" class="origin_image zh-lightbox-thumb" width="537" data-original="https://pic1.zhimg.com/099feaa44189110662b8b06ed7bacb38_r.jpg">上面两步骤我们发现,/etc/protocols中各有一行含有tcp与udp字符串,并且一共有243个不同的单词。 上面两步骤我们发现,/etc/protocols中各有一行含有tcp与udp字符串,并且一共有243个不同的单词。
上面两步骤我们发现,/etc/protocols中各有一行含有tcp与udp字符串,并且一共有243个不同的单词。
上面每个语句的具体含义这里不展开,可以结合你阅读的文章进行理解,后续实验中会不断介绍。Scala的语法我们在后续实验中会单独学习,这里仅仅是提供一个简单的例子让大家对Spark运算有基本认识。
操作完成后,Ctrl D组合键退出Shell。
pyspark
pyspark类似spark-shell,是一个Python的交互Shell。
执行pyspark启动进入pyspark:
<img data-rawheight="381" data-rawwidth="825" src="https://pic4.zhimg.com/8978b30a85049daa08aa97e18e835a1b_b.jpg" class="origin_image zh-lightbox-thumb" width="825" data-original="https://pic4.zhimg.com/8978b30a85049daa08aa97e18e835a1b_r.jpg">
退出方法仍然是Ctrl D组合键。
也可以直接使用IPython,执行命令:IPYTHON=1 pyspark
<img data-rawheight="542" data-rawwidth="814" src="https://pic4.zhimg.com/c1e1ab057102281df1bf03289a9f8a1f_b.jpg" class="origin_image zh-lightbox-thumb" width="814" data-original="https://pic4.zhimg.com/c1e1ab057102281df1bf03289a9f8a1f_r.jpg">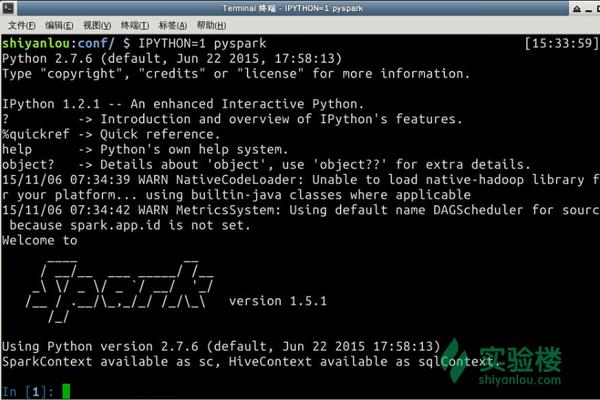
在pyspark中,我们可以用python语法执行spark-shell中的操作,比如下面几个语句获得文件/etc/protocols的行数以及第一行的内容:
<img data-rawheight="205" data-rawwidth="719" src="https://pic2.zhimg.com/52d8bf3f7d634742cd075bafe76f5b45_b.jpg" class="origin_image zh-lightbox-thumb" width="719" data-original="https://pic2.zhimg.com/52d8bf3f7d634742cd075bafe76f5b45_r.jpg">操作完成后,Ctrl D组合键退出Shell。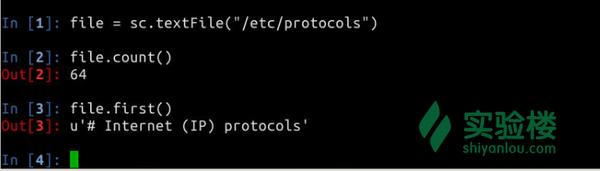 操作完成后,Ctrl D组合键退出Shell。
操作完成后,Ctrl D组合键退出Shell。
在后续的实验中我们将大量使用python和scala的交互式shell,可以及时的获得实验结果,实验重在理解原理,内容将很少涉及Java的内容,如果你对Java很熟悉可以参考后续的实验代码练习。
2. 启动spark服务
这一节我们将启动spark的master主节点和slave从节点,这里也会介绍spark单机模式和集群模式的部署区别。
2.1 启动主节点
执行下面几条命令启动主节点:
# 进入到spark目录
cd /opt/spark-1.5.1-bin-hadoop2.6# 启动主节点
./sbin/start-master.sh
没有报错的话表示master已经启动成功,master默认可以通过web访问http://localhost:8080,打开桌面上的firefox浏览器,访问该链接:
<img data-rawheight="478" data-rawwidth="892" src="https://pic1.zhimg.com/dfdae884d1f3eb085a2f375ddac9dc7c_b.jpg" class="origin_image zh-lightbox-thumb" width="892" data-original="https://pic1.zhimg.com/dfdae884d1f3eb085a2f375ddac9dc7c_r.jpg">
图中所示,master中暂时还没有一个worker,我们启动worker时需要master的参数,该参数已经在上图中标志出来:spark://7a1e9a46bf54:7077,请在执行后续命令时替换成你自己的参数。
2.2 启动从节点
执行下面的命令启动slave
./sbin/start-slave.sh spark://7a1e9a46bf54:7077
没有报错表示启动成功,再次刷新firefox浏览器页面可以看到下图所示新的worker已经添加:
<img data-rawheight="518" data-rawwidth="902" src="https://pic3.zhimg.com/6258e2fd44ffb967cb447176f6282f52_b.jpg" class="origin_image zh-lightbox-thumb" width="902" data-original="https://pic3.zhimg.com/6258e2fd44ffb967cb447176f6282f52_r.jpg">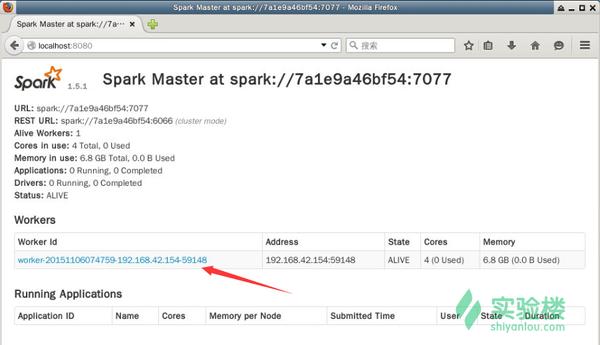
也可以用jps命令查看启动的服务,应该会列出Master和Slave。
2.3 测试实例
使用pyspark连接master再次进行上述的文件行数测试,如下图所示,注意把MASTER参数替换成你实验环境中的实际参数:
<img data-rawheight="541" data-rawwidth="836" src="https://pic4.zhimg.com/717c2fa05786782a0aa349e231aaf38f_b.jpg" class="origin_image zh-lightbox-thumb" width="836" data-original="https://pic4.zhimg.com/717c2fa05786782a0aa349e231aaf38f_r.jpg">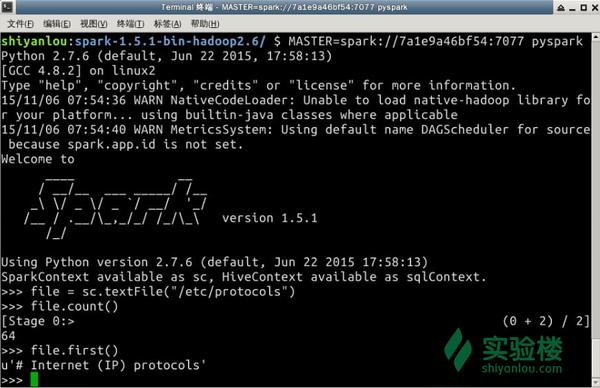
刷新master的web页面,可以看到新的Running Applications,如下图所示:
<img data-rawheight="527" data-rawwidth="899" src="https://pic2.zhimg.com/e53f109d1c461855ae02768a6bc37dc5_b.jpg" class="origin_image zh-lightbox-thumb" width="899" data-original="https://pic2.zhimg.com/e53f109d1c461855ae02768a6bc37dc5_r.jpg">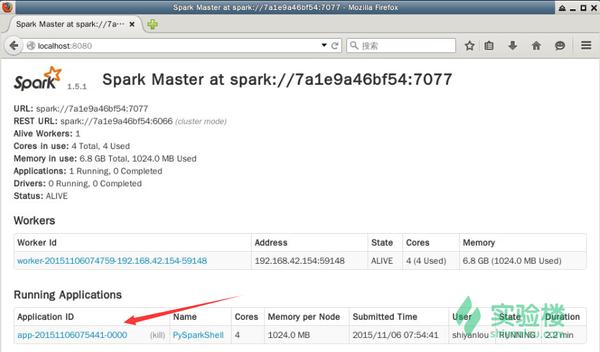
当退出pyspark时,这个application会移动到Completed Applications一栏。
可以自己点击页面中的Application和Workers的链接查看并了解相关信息。
2.4 停止服务
停止服务的脚本为sbin/stop-all.sh,运行时需要输入shiyanlou用户的密码,因为脚本中使用ssh远程对slave节点进行管理:
cd /opt/spark-1.5.1-bin-hadoop2.6
./sbin/stop-all.sh
2.5 集群部署
上面的步骤介绍了我们在单机状态Standalone Mode下部署的spark环境,如果要部署spark集群稍有区别:
- 主节点上配置spark,例如conf/spark-env.sh中的环境变量
- 主节点上配置conf/slaves,添加从节点的主机名,注意需要先把所有主机名输入到/etc/hosts避免无法解析
- 把配置好的spark目录拷贝到所有从节点,从节点上的目录路径与主节点一致,例如都设置为/opt/spark-1.5.1-bin-hadoop2.6
- 配置主节点到所有从节点的SSH无密码登录,使用ssh-keygen -t rsa和ssh-copy-id两个命令
- 启动spark集群,在主节点上执行sbin/start-all.sh
- 进入主节点的web界面查看所有worker是否成功启动
那些说单机的,谁都知道可以单机跑,但是,在单机和集群搭建一个可以使用的环境是完全不一样的,而且,有很多bug在单机环境下是无法触发的。所以很多时候你在单机上能跑的代码在集群上是会不断报错的。学习不是只是知道的就行。
我觉得有几个方面,可以给你参考:
1、你需要一个比较强劲的机器,内存/CPU要稍大一些,这些大数据的家伙都是吃资源的;
2、你可以选择采用虚拟化技术,比如VMware,VirtualBox,多跑几个linux,应该问题不大;
3、你还可以选择最近比较流行的Docker技术,很大程度上比虚拟化要便捷的多;
4、你还可以很土豪,买很多实体机,选择用Ambari搭建一个真实的hadoop环境,我觉得那样你会学得更快。
Sequence IQ, DataStax, Cloudera有很多已经build 好的Docker images. Dockerhub上可以搜一下
这不是一本入门书,主要是讲ML这一块。
但这本书并不难读,里面每一章都是实例,还提供数据源,
很方便动手实践,通过这些“非玩具”的例子可以更好的学习
使用spark。
第一个是Apache Spark源码剖析 (豆瓣),这本书虽然照抄源码,但是我觉得盯着电脑看源码比较累(摔~~~)
第二本是Spark大数据处理:技术、应用与性能优化 (豆瓣) ,貌似评价不好,但是适合入门使用
但是,如果想彻底搞明白的话还是建议阅读官方doc,几篇论文啃下来比较好。Introduction 翻译比较好的开发手册也可以参照一下
推荐 《深入理解SPARK:核心思想与源码分析》,此书适合Spark已经入门的读者阅读,对于热爱源码的人也是不错的选择,目前,此书是国内介绍Spark最全面的一本书,对于原理有深层次的解析。
本书共包括14章,每章的主要内容如下。
第1章回答了Spark为何是大数据处理平台的必然选择?Spark速度如此之快的原因是什么?Spark的理论基石是什么?Spark具体是如何仅仅使用一个技术堆栈解决多元化的大数据处理的需求的?
第2章回答了如何从零起步构建Hadoop集群?如何在Hadoop集群的基础上构建Spark集群?如何测试Spark集群?
第3章回答了如何在IDEA集成开发环境中开发并运行Spark程序?如何在IDA中开发Spark代码并进行测试?
第4章在细致解析RDD的基础上会动手实战RDD中的Transformation类型的RDD、Action类型的RDD,并伴有Spark API的综合实战案例。
第5章详细分析了Spark Standalone模式、Spark Yarn-Cluster模式、Spark-Client模式的设计和实现。
第6章首先介绍Spark内核,接着分享通过源码分析Spark内核及源码,细致解析Spark作业的全生命周期,最后分享Spark性能优化的内容。
. 第7章通过大约30个动手实践的案例循序渐进地展示Spark GraphX框架方方面面的功能和使用方法,并对Spark GraphX的源码进行解析。
第8章基于Spark SQL动手编程实践章节,从零起步,细致而深入地介绍了Spark SQL方方面面的内容。
第9章从快速入门机器学习开始,详细解析MLlib框架,通过对线性回归、聚类、协同过滤的算法解析、源码解析和案例实战,循序渐进地揭秘MLLib,最后通过对MLlib中Basic Statics、朴素贝叶斯算法、决策树的解析和实战,进一步提升掌握Spark机器学习的技能。
第10章细致解析了Tachyon这个分布式内存文件系统的架构设计、具体实现、部署以及Spark对Tachyon的使用等内容。
第11章循序渐进地介绍Spark Streaming的原理、源码和实战案例等内容。
第12章介绍了Spark多语言编程的特点,并通过代码实例循序渐进地介绍Spark多语言编程,最后通过一个综合实例来实践Spark多语言编程。
第13章从R语言的基础介绍和动手实战入手,介绍SparkR的使用和代码实战,助您快速上手R语言和Spark两大大数据处理的利器。
第14章循序渐进地介绍了Spark常见的问题及其调优方式。首先介绍Spark性能优化的14大问题及其解决方法,然后从内存优化、RDD分区、Spark对象和操作的性能调优等角度解决常见的性能调优问题,最后讲解Spark最佳实践方案。
第15章聚焦于Spark源码中的BlockManager、Cache和Checkpoint等核心源码解析,BlockManager、Cache和Checkpoint是每个Spark学习者都必须掌握的核心内容。本章循序渐进地解析了这三部分的源码,包括通过源码说明其用途、实现机制、内部细节和实际Spark生产环境下的最佳实践等,通过本章即可轻松驾驭BlockManager、Cache和Checkpoint,从而对Spark精髓的领悟也必将更上层楼!
附录主要是从Spark的角度来讲解Scala,以动手实战为核心,从零开始,循序渐进地讲解Scala函数式编程和面向对象编程。
【Spark大数据处理】动手写WordCount
王家林《Spark亚太研究院系列丛书——Spark实战高手之路 从零开始 》Spark亚太研究院系列丛书――Spark实战高手之路 从零开始
王家林《spark亚太研究院专刊》Spark专刊-Spark亚太研究院
王家林《spark亚太研究院中文文档翻译》【Spark亚太研究院 共享资料】Spark官方文档中文翻译
王家林spark亚太研究院出版图书《大数据Spark企业级实战》现货包邮 大数据Spark企业级实战 Spark亚太研究院 王家林【图片 价格 品牌 报价】
王家林《spark亚太研究院100期公益大讲堂》
搜索视频:spark亚太研究院
王家林spark亚太研究院线下课程地址Spark亚太研究院的在线课堂
王家林英语视频百度视频搜索_王家林英语
王家林的书籍王家林 - 商品搜索
王家林spark亚太峰会百度视频搜索_spark亚太峰会#pn=0
王家林移动互联网Android书籍王家林Android
王家林Hadoop视频从技术角度思考Hadoop到底是什么
王家林Scala视频熟练的掌握Scala语言【大数据Spark实战高手之路1】_51CTO学院
王家林spark视频百度视频搜索_王家林spark视频
1,《大数据不眠夜:Spark内核天机解密(共100讲)》:http://pan.baidu.com/s/1eQsHZAq
2,《Hadoop深入浅出实战经典》http://pan.baidu.com/s/1mgpfRPu
3,《Spark纯实战公益大讲坛》http://pan.baidu.com/s/1jGpNGwu
4,《Scala深入浅出实战经典》http://pan.baidu.com/s/1sjDWG25
5,《Docker公益大讲坛》http://pan.baidu.com/s/1kTpL8UF
6,《Spark亚太研究院Spark公益大讲堂》http://pan.baidu.com/s/1i30Ewsd
7,DT大数据梦工厂Spark、Scala、Hadoop的所有视频、PPT和代码在百度云网盘的链接:
百度云 网盘-Rocky_Android的分享
2,《Hadoop深入浅出实战经典》http://pan.baidu.com/s/1mgpfRPu
3,《Spark纯实战公益大讲坛》http://pan.baidu.com/s/1jGpNGwu
4,《Scala深入浅出实战经典》http://pan.baidu.com/s/1sjDWG25
5,《Docker公益大讲坛》http://pan.baidu.com/s/1kTpL8UF
6,《Spark亚太研究院Spark公益大讲堂》http://pan.baidu.com/s/1i30Ewsd
7,DT大数据梦工厂Spark、Scala、Hadoop的所有视频、PPT和代码在百度云网盘的链接:
百度云 网盘-Rocky_Android的分享
Amazon链接:Learning Spark: Lightning-Fast Big Data Analysis: Holden Karau, Andy Konwinski, Patrick Wendell, Matei Zaharia: 9781449358624: Amazon.com: Books
spark更新太快了,市面上书都是基于spark1.2以前的版本,而最新的1.4和以前的版本已经有了相当大的改变。尤其是dataframe,mllib,改动非常大。
如果是使用,本人推荐看spark各个版本的doc:Documentation更加合适,还有多看微博上国内的几个contributor在微博上关于spark的讨论。
如果要了解源码,可以跟进github上spark的repo:apache/spark · GitHub,从配置sbt,编译源码,尝试修改源码开始,多看PR:Pull Requests · apache/spark · GitHub。
由于spark正在发展,你可以找你感兴趣的紧跟其中一方面spark sql(包括sql parser,查询优化catalyst和逻辑和物理执行计划的表示,各个物理算子的实现),mlbase(各种机器学习算法的实现)或者graphx,集中了解某一方面的原理和详细的实现过程,我想这个是学习spark最大的价值。
后面的总结很到位,跟我想的一样。其实学习大数据之前,推荐学习《函数式编程思维》、《七周七并发模型》。基本原理一样了,就是分布式的实现了。
链接:https://www.zhihu.com/question/23655827/answer/64871458
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
注意!注意!推荐今年年初出版的一本书,作者都是Spark的主要贡献者:
Learning Spark: Lightning-Fast Big Data Analysis
http://www.amazon.com/Learning-Spark-Lightning-Fast-Data-Analysis/dp/1449358624/
这本书有这样几个特点:
- 可操作性强:安装好Spark后,就可以直接照着书中的例子进行实际操作,Learning by doing,比直接看Spark的论文来得要简单爽快。类似于初学Linux也不一定得先把操作系统原理学得彻彻底底了才开始动手;带着问题边干边学不断深入才会效率高。
- 实例充实:提供了Scala、Python、Java三种接口的操作代码,提供了诸如PageRank算法的实现,并在在How to的基础上加入了大量Why to的讨论,讨论如何在Spark分布式环境下实现更高效的计算,如何减少网络开销。github上也有作者提供的配套代码:databricks/learning-spark · GitHub
- 文字扼要:比官方文档(Spark Programming Guide)更深入地介绍代码作用原理,同时也不像普通外文教材一样废话连篇。例如这一句:“为分布式数据集选择正确的分区策略的重要性类似于为本地数据选择正确的数据结构。”让人思考良久。
翻译了其中我认为最重要的第四章,放在了这里,大家可以看一看:
CHAPTER 4: Working with Key/ValuePairs
百度云:OReilly.Learning.Spark.2015.1-CN-13-Chapter4.pdf_免费高速下载
截图1:
<img src="https://pic1.zhimg.com/4635f69fb4927245a2414db1f3f2ccb8_b.png" data-rawwidth="524" data-rawheight="785" class="origin_image zh-lightbox-thumb" width="524" data-original="https://pic1.zhimg.com/4635f69fb4927245a2414db1f3f2ccb8_r.png">
截图2:
<img src="https://pic2.zhimg.com/fa3024230728e7f3a99387545bd74559_b.png" data-rawwidth="517" data-rawheight="795" class="origin_image zh-lightbox-thumb" width="517" data-original="https://pic2.zhimg.com/fa3024230728e7f3a99387545bd74559_r.png">
=======下面是我的一些理解=========
Spark在尝试把函数式语言的模型,应用在了分布式的环境中。
我一直认为函数式语言是为了分布式/多核环境而生的,而且其设计历史之久远足以看出设计者的远见(额,这个远见可能只是巧合,还好我们除了图灵机外还有lambda演算)。我在大三时修习乔海燕老师的“函数式编程”这门课时,发现函数式语言很多特点在单机/单核上是浪费时间和浪费空间的操作,例如无副作用、不可变(immutable),我尤其不太理解为什么一个容器(例如List),改变其中一个元素,就需要生成一个新的不可变容器,这在命令式语言(例如C)的思路里是多么的浪费空间和时间。不过,不可变和无副作用却也带来了另外的好处:1)不可变:节约了多核和多线程访问临界区的锁资源;2)无副作用:节约了重复计算相同参数函数的资源。并且这种好处在硬件越来越廉价,更加趋向分布式/多核的环境中越发彰显优势。
Lisp和C语言是编程模型中的两座高山,其他语言都在这两座高山之间权衡折衷。
语言设计,这是计算机科学中最有美感和纯度的分支。另外感觉很热门的数据科学(数据挖掘/机器学习)只是统计学在计算机里面的实现,是个数学工程,或者是仿生学工程,它们也具有美感,却不够简单缺少纯度。
-----------------------------
其实,不建议使用这本书。这是一本缺少内容,又容易让你因为内容过期晕头转向的书。还是去阅读相关论文和Spark网页吧
Hadoop MapReduce只是函数式语言到分布式环境跨出的第一步。然而函数式语言包含了许多基础的先驱函数(Prelude Function),除了Map、Reduce,还有Filter、Fold、Sort、GroupBy、Join。而Spark就是函数式语言到分布式环境跨出的第二步,在分布式环境中实现并优化了这些函数。
函数式编程概念
可以参考问题“什么是函数式编程思维?”
1. 无副作用(no side effects)
2. 高阶函数(high-order function)
3. 闭包(closure)
4. 不可变(immutable)
5. 惰性计算(lazy evaluation)
6. 科里化(currying)
7. 模式匹配(pattern matching)
8. 后续(continuation)
9. monad
Spark相关论文
·An Architecture for Fast and General Data Processing on Large Clusters(PhD Disseration). M. Zaharia.
·Spark SQL: Relational Data Processing in Spark. Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, XiangruiMeng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, MateiZaharia. SIGMOD 2015. June 2015.
·GraphX: Unifying Data-Parallel and Graph-Parallel Analytics. Reynold S. Xin, Daniel Crankshaw, Ankur Dave, Joseph E. Gonzalez, Michael J. Franklin, Ion Stoica. OSDI 2014. October 2014.
·Discretized Streams: Fault-Tolerant Streaming Computation at Scale. MateiZaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica. SOSP 2013. November 2013.
·Shark: SQL and Rich Analytics at Scale. Reynold S. Xin, Joshua Rosen, MateiZaharia, Michael J. Franklin, Scott Shenker, Ion Stoica. SIGMOD 2013. June 2013.
·Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. MateiZaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica. HotCloud 2012. June 2012.
·Shark: Fast Data Analysis Using Coarse-grained Distributed Memory (demo). Cliff Engle, Antonio Lupher, Reynold S. Xin, MateiZaharia, Haoyuan Li, Scott Shenker, Ion Stoica. SIGMOD 2012. May 2012. Best Demo Award.
·Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. MateiZaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award.
·Spark: Cluster Computing with Working Sets. MateiZaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010.
官方文档
1. Spark Programming Guide
靠谱的书
1. Learning Spark: Lightning-Fast Big Data Analysis http://www.amazon.com/Learning-Spark-Lightning-Fast-Data-Analysis/dp/1449358624/
2. Fast Data Processing with Spark - Second Edition http://www.amazon.com/Fast-Data-Processing-Spark-Second/dp/178439257X/
作者链接
Matei Zaharia
链接:https://www.zhihu.com/question/23655827/answer/29611595
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Fei Dong | LinkedIn
<img src="https://pic3.zhimg.com/d13573f58390f67cf5a36414be3838ee_b.jpg" data-rawwidth="950" data-rawheight="694" class="origin_image zh-lightbox-thumb" width="950" data-original="https://pic3.zhimg.com/d13573f58390f67cf5a36414be3838ee_r.jpg">
Hadoop Spark学习小结[2014版]Hadoop
Hadoop社区依然发展迅速,2014年推出了2.3,2.4, 2.5 的社区版本,比如增强 Resource Manager HA, YARN Rest API, ACL on HDFS, 改进 HDFS 的 Web UI…
Hadoop Roadmap 根据我的观察,主要更新在Yarn,HDFS,而Mapreduce几乎停滞了,还有一些feature 属于安全,稳定可靠性一方面是比较稳定了,但也可以说是瓶颈了。
Apache Hadoop Project Members
这个是Hadoop project member and committee, 里面好多来自Hortonworks,也有不少国人上榜。
SparkSpark 介绍
Spark今年大放溢彩,Spark简单说就是内存计算(包含迭代式计算,DAG计算,流式计算 )框架,之前MapReduce因效率低下大家经常嘲笑,而Spark的出现让大家很清新。
Reynod 作为Spark核心开发者, 介绍Spark性能超Hadoop百倍,算法实现仅有其1/10或1/100
浅谈Apache Spark的6个发光点
Spark: Open Source Superstar Rewrites Future of Big Data
Spark is a really big deal for big data, and Cloudera gets it
其实起名字也很重要,Spark就占了先机,CTO说Where There’s Spark There’s Fire: The State of Apache Spark in 2014
Spark 起源
2010年Berkeley AMPLab,发表在hotcloud 是一个从学术界到工业界的成功典范,也吸引了顶级VC:Andreessen Horowitz的 注资
AMPLab这个实验室非常厉害,做大数据,云计算,跟工业界结合很紧密,之前就是他们做mesos,hadoop online, crowddb, Twitter,Linkedin等很多知名公司都喜欢从Berkeley找人,比如Twitter也专门开了门课程 Analyzing Big Data with Twitter 还有个BDAS (Bad Ass)引以为傲: The lab that created Spark wants to speed up everything, including cures for cancer
在2013年,这些大牛从Berkeley AMPLab出去成立了Databricks,半年就做了2次summit参会1000人,引无数Hadoop大佬尽折腰,大家看一下Summit的sponsor ,所有hadoop厂商全来了,并且各个技术公司也在巴结,cloudrea, hortonworks, mapr, datastax, yahoo, ooyala, 根据CTO说 Spark新增代码量活跃度今年远远超过了Hadoop本身,要推出商业化产品Cloud。
Spark人物
- Ion Stoica: Berkeley教授,AMPLab 领军
- Matei Zaharia: 天才,MIT助理教授
- Reynold Xin Apache Spark开源社区的主导人物之一。他在UC Berkeley AMPLab进行博士学业期间参与了Spark的开发,并在Spark之上编写了Shark和GraphX两个开源框架。他和AMPLab同僚共同创建了Databricks公司
- Andy Konwinski
- Haoyuan Li
- Patrick Wendell
- Xiangrui Meng
- Paco Nathan
- Lian Cheng
- Hossein Falaki
- Mosharaf Chowdhury
- Zongheng Yang
- Yin Huai
- Committers
Spark基本概念
- RDD——Resillient Distributed Dataset A Fault-Tolerant Abstraction for In-Memory Cluster Computing弹性分布式数据集。
- Operation——作用于RDD的各种操作分为transformation和action。
- Job——作业,一个JOB包含多个RDD及作用于相应RDD上的各种operation。
- Stage——一个作业分为多个阶段。
- Partition——数据分区, 一个RDD中的数据可以分成多个不同的区。
- DAG——Directed Acycle graph,有向无环图,反应RDD之间的依赖关系。
- Narrow dependency——窄依赖,子RDD依赖于父RDD中固定的data partition。
- Wide Dependency——宽依赖,子RDD对父RDD中的所有data partition都有依赖。
- Caching Managenment——缓存管理,对RDD的中间计算结果进行缓存管理以加快整 体的处理速度。
目前还有一些子项目,比如 Spark SQL, Spark Streaming, MLLib, Graphx 工业界也引起广泛兴趣,国内Taobao, baidu也开始使用:Powered by Spark
Apache Spark支持4种分布式部署方式,分别是Amazon EC2, standalone、spark on mesos和 spark on YARN 比如AWS
Spark Summit
2014 Summit
取代而非补充,Spark Summit 2014精彩回顾
拥抱Spark,机遇无限——Spark Summit 2013精彩回顾
Databricks Cloud Demo 今年最叫好的demo是Dtabricks Cloud, 把Twitter上面实时收集的数据做作为machine learning素材,用类似IPython notebook,可视化呈现惊艳,而搭建整个sampling系统就花了20分钟!
培训资料和视频
官方文档
Databricks Blog
Summit Training
Databricks upcoming training
Stanford Spark Class
CSDN Spark专栏
10月份还有个培训在湾区的培训,只不过3天就要1500刀,看来做个讲师也不错:)
第三方项目
- Web interactive UI on Hadoop/Spark
- Spark on cassandra
- Spark Cassandra Connector
- Calliope
- H2O + Spark
- Shark - Hive and SQL on top of Spark
- MLbase - Machine Learning research project on top of Spark
- BlinkDB - a massively parallel, approximate query engine built on top of Shark and Spark
- GraphX - a graph processing & analytics framework on top of Spark (GraphX has been merged into Spark 0.9)
- Apache Mesos - Cluster management system that supports running Spark
- Tachyon - In memory storage system that supports running Spark
- Apache MRQL - A query processing and optimization system for large-scale, distributed data analysis, built on top of Apache Hadoop, Hama, and Spark
- OpenDL - A deep learning algorithm library based on Spark framework. Just kick off.
- SparkR - R frontend for Spark
- Spark Job Server - REST interface for managing and submitting Spark jobs on the same cluster.
相关参考资料
Resilient Distributed Datasets
spark on yarn的技术挑战
Hive原理与不足
Impala/Hive现状分析与前景展望
Apache Hadoop: How does Impala compare to Shark
MapReduce:一个巨大的倒退
Google Dremel 原理 — 如何能3秒分析1PB
Isn’t Cloudera Impala doing the same job as Apache Drill incubator project?
Shark
Big Data Benchmark
How does Impala compare to Shark
EMC讲解Hawq SQL性能:左手Hive右手Impala
Shark, Spark SQL, Hive on Spark, and the future of SQL on Spark
Cloudera: Impala’s it for interactive SQL on Hadoop; everything else will move to Spark
Databricks – an interesting plan for Spark, Shark, and Spark SQL
Apache Storm vs Spark Streaming
Apache Spark源码走读
如何将手中 20 多台旧电脑,组建一台超级计算机?修改
2 前两年云计算开始火,自己的学校建立了云计算中心,偶然体验了一下觉得很刺激,但体验和远程登陆没有区别。
3 学校领导不满足我的计算机需求,反而说都给你 20 多台电脑了,还要新的?
4 听过一位两院院士的学术报告,听到了分布式计算的概念
5 听说 Google 机房和我的情况类似,采用旧的机器来分担服务器压力
问:我可否用这些破电脑来组建一台超级计算机,当然也不需要太强,做电设的软件不卡就行。
谢谢
1/ 计算能力
就是cpu的速度。我看了一篇文档说,第一代/第二代/第三代/第四代/core 处理器的性能相差不大,最主要是功耗有很大的降低。你现在拥有的p4是最傻的cpu,功耗大,流水线最长,计算速度慢,不支持硬件虚拟化,所以已经没有任何实际使用价值的
2/ 内存
内存大小是云计算的关键。一般一个节点怎么也得32g以上,512m的内存塞牙缝都不够
3/ 存储能力
目前云计算采用sata盘能有效降低运营成本,但是速度慢/可靠性低,因此要采用sata 6g的接口,并作底层的硬件raid. 我一般做RAID 10
BOINC(Berkeley Open Infrastructure for NetworkComputing,伯克利开放式网络计算平台)
玩这个
硬盘你有20个可以组一个磁盘阵列,速度飞快无比啊~不过功率和发热同样是可怕
不搞超算,搞分布式计算不行吗?
hadoop/spark集群
1. 你说道谷歌的集群,这20台机器配置来说搭个hadoop集群勉强可以,但只能跑点资源分发的程序(谷歌主要是用来跑爬虫,这个不需要实时,廉价pc你要求能多高?所以彻夜的爬数据才是他们的归宿),不适合科学计算,而且是离线的,响应速度也慢,再说资源多了(达到TB级别)效果才明显。
更不要提一般基于集群的程序都是要专门写的,当然您也可以下载个开源的Hadoop平台玩下。
建议题主还是把这20台旧机器卖了买个好点的服务器吧。
其次,你要弄的超级计算机,需要各个电脑的CPU之间能够协同工作,这样需要各台电脑之间有延迟很小带宽很大的连接。
所以,你做不了超级计算机,只能做出一些类似Web集群或者存储集群的东东。
对对对,我就是这个意思。学校组建的云计算中心,可以在我这一端申请cpu数量,内存大小,然后就像远程登录一样登陆到计算中心,用那里的matlab运算特别爽,当然,基于校园网11mb/s的极限速度。
那个是多重负载,不需要你操心。最前端有cache, 然后是DNS 负载,然后是http负载,在然后是message server,在在然后到http server, 在在在然后到application server,最后才到数据库。
其次,构建测试平台。你看看你要解决的问题是否可以被拆分多个任务,是否存在计算损耗。是否可以估算出计算成本。
再次,进行风险预估,看看这件事做了,技术上最大的风险是什么?增加了哪些难题?是否划得来?
然后,在动手。
唉,想当年没钱,用了接近100台PC,搞了个sun grid EDA计算农场,真的很惨呀!
才疏学浅,基于我目前对于超级计算机的需求是软需求,我的思路是在诸位大神的问答中,找到一个可行性(经济、时间)的方案,自己尝试着去探索,自己先爽,然后找朋友爽,最后在全校范围内吹牛逼。嘿嘿。
可是事实上,云你认为的云,到底应该给你怎么操作,你又会在上面做什么呢?我说的云都是大部分idc认可的云,狭义的云,其实就是一台虚拟出来的电脑而已,你可以做自己电脑做不到的一些事情,比如说储存,数据处理,用户交互。如果你觉得要广意来说,那么整个互联网都是云,云中的你向知乎的服务器发送了数据,知乎给你存起来了,难道不是云在操作吗。当然,你如果要说是分布计算才是云,那么多少台算一个云,难道你真的以为会有真的n台电脑为你一个人服务吗,还是说,要一台电脑服务n个人?
对!当年成都那个人造太阳,也就是20台P4的群集而已!ASUS的板子+3COM的交换,
不说别的,硬件:服务器+存储,就算测试用也得十来万吧,如果提供服务就慢慢乘10往上加;
软件…各大厂商都盯着呢,按核心收费,按功能模块收费,按服务收费,只要能收费的方法都被想绝了。
后面是各应用系统及数据库的迁移部署(说是零难度迁移,实际应用时大家都懂的,购买白金服务吧)、基础网络交换的设备更新(说不定要优化拓扑,继续购买服务)、操作员的培训(还是买服务),如果牵扯分/等级保护,还要重新评估信息系统安全性(郭嘉的服务,贵)。
为了省钱还是别弄这个了…申课题倒是可以考虑,只说技术优化别提节能减排…
对了,听说Google机房的服务器是批量定制的x86机器,从逻辑性能到物理硬件都高度标准化,所以纳入云平台管理不算太费力。题主提到的20台PC组一起,能不能实现云的部署真不好说,在怎么说,云也是个操作系统,也是挑硬件的。
主要是是看你的需求
- 如果是大数据处理,可以考虑使用hadoop
- 如果是做 存储,可以考虑ceph或者swift之类的云存储系统
- 估计他就是不知道需求。超级计算机也分计算还是存储还是啥别的目的的,楼主可能不是很清晰
下图是P4 3.0GHz CPU同其他目前常见的中高端CPU的计算性能比较(CPU Mark),就算你花了九牛二虎之力把这20多个CPU组装到一起,并且奇迹般地没有任何通讯开销和效率损失,这20多台计算机的计算能力也只有勉强达到一个i7-2600主机的水平。某宝告诉我这种主机目前大约价钱4000元。
<img src="https://pic4.zhimg.com/40ed9b3c2a9d6df569138f9cc0baf25b_b.jpg" data-rawwidth="520" data-rawheight="314" class="origin_image zh-lightbox-thumb" width="520" data-original="https://pic4.zhimg.com/40ed9b3c2a9d6df569138f9cc0baf25b_r.jpg">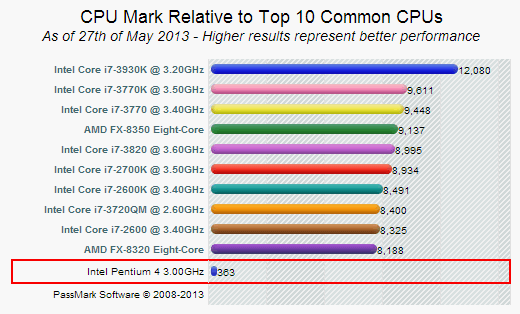
如果这种“超级计算机”是你追求的目标,或者你希望通过这样一个活动来提高自己对并行计算的认识,不妨玩玩。否则我能给的最好的建议就是——把所有机器放淘宝上一个200卖掉,赚到的5000元钱买一个性能强劲新的主机回来。
单任务也至少有5倍以上,比如100万PI计算,p4 2.0差不多80s,3.0差不多55-60s,据说玩死里超,超冒烟可以30s。i7的话10s不难达成,8s也早就有了,i7的极限我想6s应该是问题不大的。
你再想一下,i7最高是有6核的。
所以20倍问题不大。
最后,现在的四通道内存速度是p4时代的DDR2的10倍并非难事(但是内存不是瓶颈,根据跑分,四通道和三通道,双通道差距不大,但是和单通道差距较大),SSD硬盘速度过500都是常事,p4时期的机械硬盘基本上都是并口硬盘,我没记错当年是ATA-33,ATA-66,ATA-100,ATA-133一路升级过来的。sata-133的极限传输速度也只有133mb/s。
现在的计算机是当年的20倍,并非妄言。
你只需要:
1:用一个路由器把它们连在一起(不用太高速,反正这些电脑也很烂)。
2:每台电脑装个debian吧。应当只有一台装GUI就行。你不妨装Xfce或者LXDE桌面,比较省。
3:看看mpich的文档,把这些机器配上MPI的环境。
4:自己编MPI玩去吧!!
新闻链接里有详细说明:
制作者Tim Brom在自己的主页里给出了详细的制作方法,有兴趣的可以自己试着制作一下
相关连接:
http://www.calvin.edu/~adams/research/microwulf/
http://www.clustermonkey.net//content/view/211/1/
硬件清单
Microwulf: Hardware Manifest
链接:https://www.zhihu.com/question/21116669/answer/18864330
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
请不要嘲笑别人的想法,老外已经实现了四台电脑的计算集群,题主20台也应该是可以实现的。这个资料是英文,我找到了部分中文资料,粗略地浏览了一遍,应该是可以实现的,但是细节部分没看明白,求高人翻译资料。(不好意思,我刚才发现和@高超 的回答撞车了,不过,这些资料确实是在我没看他的资料之前自己搜索出来的,嘿嘿,大家就当他回答的补充好了)。知乎里的大神真多,呵呵,以后得好好看回答
资料地址如下 官方网址 Microwulf: A Personal, Portable Beowulf Cluster
中文翻译的资料地址如下【个人小超算】实战资料汇编
先上张图片震撼一下大家
<img data-rawheight="600" data-rawwidth="800" src="https://pic1.zhimg.com/65efd8304d9fda0155d7c416fc630bb4_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic1.zhimg.com/65efd8304d9fda0155d7c416fc630bb4_r.jpg"> <img data-rawheight="600" data-rawwidth="800" src="https://pic3.zhimg.com/36b1ffece1a83b536838cb4e9bab5cd2_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic3.zhimg.com/36b1ffece1a83b536838cb4e9bab5cd2_r.jpg">
<img data-rawheight="600" data-rawwidth="800" src="https://pic3.zhimg.com/36b1ffece1a83b536838cb4e9bab5cd2_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic3.zhimg.com/36b1ffece1a83b536838cb4e9bab5cd2_r.jpg"> <img data-rawheight="600" data-rawwidth="800" src="https://pic4.zhimg.com/0a60bf8a4aec5cb4604e40b71f2c38f7_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic4.zhimg.com/0a60bf8a4aec5cb4604e40b71f2c38f7_r.jpg">
<img data-rawheight="600" data-rawwidth="800" src="https://pic4.zhimg.com/0a60bf8a4aec5cb4604e40b71f2c38f7_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic4.zhimg.com/0a60bf8a4aec5cb4604e40b71f2c38f7_r.jpg"> <img data-rawheight="600" data-rawwidth="800" src="https://pic1.zhimg.com/7bf373350a01c13311ec57ba6f093524_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic1.zhimg.com/7bf373350a01c13311ec57ba6f093524_r.jpg">以下是我找到中文翻译资料,我是直接复制的,没能把图片等复制过来,大家就凑合看吧,也可以看上面那个中文资料的网站
<img data-rawheight="600" data-rawwidth="800" src="https://pic1.zhimg.com/7bf373350a01c13311ec57ba6f093524_b.jpg" class="origin_image zh-lightbox-thumb" width="800" data-original="https://pic1.zhimg.com/7bf373350a01c13311ec57ba6f093524_r.jpg">以下是我找到中文翻译资料,我是直接复制的,没能把图片等复制过来,大家就凑合看吧,也可以看上面那个中文资料的网站 以下是我找到中文翻译资料,我是直接复制的,没能把图片等复制过来,大家就凑合看吧,也可以看上面那个中文资料的网站
以下是我找到中文翻译资料,我是直接复制的,没能把图片等复制过来,大家就凑合看吧,也可以看上面那个中文资料的网站
个人电脑阵列
一、作者简介:
乔尔 亚当斯 (Joel Adams)是卡尔文学院(Calvin College)计算机科学(computer science)教授,1988年获得在匹次堡大学获得博士学位,主要研究超算的内部连接,是几本计算机编程教材的作者,两次获得Fulbright Scholar (毛里求斯1998, 冰岛 2005).
缇姆 布伦姆(Tim Brom)是卡耐基大学计算机科学的研究生,2007年五月在卡尔文学院获得计算机科学学士学位。
二、说明:
此小超算拥有超过260亿次的性能,价格少于2500美元,重量少于31磅,外观规格为11" x 12" x 17"——刚好够小,足够放在桌面上或者柜子里上,
更新:2007年8月1日,这个小超算已经可以用1256美元构建成,使得其性价比达到4.8美元/亿次——这样的话,可以增加更多的芯片,以提升性能,让其更接近21世纪初的超算性能。
此小超算是由卡尔文大学的计算机系统教授乔尔 亚当斯和助教 缇姆 布伦姆设计和构建。
下面是原文的目录,可点击查看:
- 设计
- 硬件信息
- 软件系统构建说明
- 效果图片
- 性能
- 计算效率
- 价格效率
- 功耗
- 新闻报道
- 相关系统
三、介绍
作为一个典型的超算用户,我需要到计算中心排队,而且要限定使用的计算资源。这个对于开发新的分布式软件来说,很麻烦。所以呢,我需要一个自己 的,我梦想中的小超算是可以小到放在我的桌面上,就像普通个人电脑一样。只需要普通的电源,不需要特殊的冷切装置就可以在室温下运行……
2006年末, 两个硬件发展,让我这个梦想接近了现实:
- 多核普及
- 千兆局域网相关硬件普及
结果呢,我就设想了一个小型的,4个节点,使用多核芯片,每个节点使用高速网线连接。
2006年秋天, 卡尔文学院计算机系给了我们一笔小钱——就是2500美元,去构建这么一个系统,我们当时设定的目标:
- 费用少于2500美元——这样一般人都能负担得起,可以促进普及。
- 足够小,适合放在我的桌面上,适合放到旅行箱里。
- 要够轻,可以手提,然后带到我的汽车里。
- 性能强劲,测试结果至少要200亿次:
- 用于个人研究,
- 用于我教授的高性能运算课程,
- 用于专业论坛讲授、高中讲演等,
- 只需要一根电源线,使用普通的120伏电源。
- 可在室温下运行。
据我们当时所知,已经有一些小型的超算,或者是性价比不错的超算出现,这些东西给了我们很好的参考:
- Little Fe
- The Ultimate Linux Lunchbox
下面是历年的性价比之王:
- 2005: Kronos
- 2003: KASY0
- 2002: Green Destiny
- 2001: The Stone Supercomputer
- 2000: KLAT2
- 2000: bunyip
- 1998: Avalon
在同一时间,还有其他更廉价或者是更具性价比的超算集群,不过这些记录都在2007年被改变了,最具性价比的就是下文介绍的小超算(2007年一月,9.41美元/亿次),而其记录半年后就被打破(2007年8月 4.784美元/亿次)。
架构设计:
个人小超算一般做法是使用多核芯片,集中安装到一个小的空间里,集中供电——嗯,如果能自己烧制主板,体积上应该可以做得更小——树莓派的主板体积很小,就是芯片不给力,所以需要那么多片才能达到2007年用普通电脑芯片实现的性能。
1960年代末,吉恩 庵达郝乐(Gene Amdahl)提出了一个设计准则,叫 "庵达赫乐法则"(Amdahl's Other Law),大意是:
为了兼容性考虑, 下面几个特性应该相同:
- 每片芯片的频率
- 每根内存大小
- 每处带宽
高性能计算一般有三个瓶颈:芯片运算速度,运算所需内存,吞吐带宽。本小超算里面,带宽主要是指网络带宽。我们预算是2500美元,在设定了每核内存量,每核的带宽之后,其中芯片运算速度当然是越快越好。
内部使用千兆网络(GigE),则意味着我们的带宽只有1Gbps,如果要更快的,可以使用比如Myrinet,不过那会超预算了,此处核心1吉赫兹+每核1吉B内存+1吉bps,嗯,看起来比较完美,哈哈。最终决定是2.0GHz的双核芯片,每核1GB内存
芯片,使用AMD Athlon 64 X2 3800 AM2+ CPUs. 2007年一月时每片价格$165 ,这种2.0GHz的双核芯片,是当时可以找到的性价比最好的。 (2007年8月就更便宜了,每片只有$65.00).
为了尽量减少体积,主板选用的是MSI Micro-ATX。此主板特点是小(9.6" by 8.2") ,并且有一个AM2 socket,可支持AMD的Athlon多核芯片。其实如果有条件的话,更应该做的是使用AMD的四核Athlon64 CPU替代这个双核,而这系统恰好还不用改。
To do so, we use motherboards with a smaller form-factor (like Little Fe) than the usual ATX size, and we space them using threaded rods (like this cluster) and scrap plexiglass, to minimize "packaging" costs.
By building a "double decker sandwich" of four microATX motherboards, each with a dual core CPU and 2 GB RAM (1 GB/core), we can build a 4-node, 8-core, 8GB multiprocessor small enough to fit on one's desktop, powerful enough to do useful work, and inexpensive enough that anyone can afford one.
此 主板上已经嵌有一个千兆网卡,还有一个PCI-e扩展插槽,在PCI-e插槽插入另一根网卡(41美元),用于平衡芯片运算速度和网络带宽。这样,四块主 板总共就有内嵌的4个网卡,外加PCI-e插槽的4张网卡,一共8个网络通道,用网线把它们都连接到8口路由器(100美元)上。
Our intent was to provide sufficient bandwidth for each core to have its own GigE channel, to make our system less imbalanced with respect to CPU speed (two x 2 GHz cores) and network bandwidth (two x 1 Gbps adaptors). This arrangement also let us experiment with channel bonding the two adaptors, experiment with HPL using various MPI libraries using one vs two NICs, experiment with using one adaptor for "computational" traffic and the other for "administrative/file-service" traffic, and so on.)
每块主板插了两根内存,共2G,这8G内存消耗了预算的40%!!
为了更小化,本小超算没有使用机箱,而是一个完全非封闭的外架,像Little Fe 和 这些集群,把主板直接安装到有机玻璃上面,然后用几根小铁杆撑起来,并连接成一立体状。——(这个架子一般的五金店应该可以制造,用导热性好的铝/铁当托盘,整机的热分布会好点,也有利于集中散热)
最底部是两片有机玻璃隔开的一个夹层,放着8口路由,光驱,还有250GB的硬盘。
结构图如下:
<img data-rawheight="311" data-rawwidth="452" src="https://pic2.zhimg.com/836f990c77a27c0c7fe90f4808eaabed_b.jpg" class="origin_image zh-lightbox-thumb" width="452" data-original="https://pic2.zhimg.com/836f990c77a27c0c7fe90f4808eaabed_r.jpg">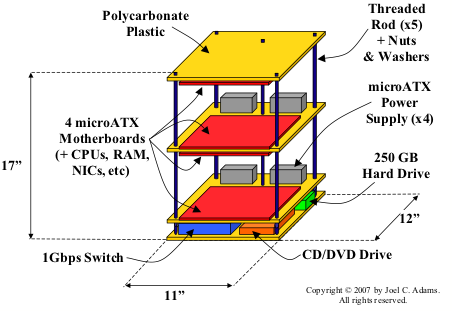
我们这小超算的硬件结构
如图所示,主板放在最顶层的下方,而中间层则两面都放主板,底层则上方放主板,这样做的目的是尽可能减少高度。
Since each of our four motherboards is facing another motherboard, which is upside-down with respect to it, the CPU/heatsink/fan assembly on one motherboard lines up with the PCI-e slots in the motherboard facing it. As we were putting a GigE NIC in one of these PCI-e slots, we adjusted the spacing between the Plexiglas pieces so as to leave a 0.5" gap between the top of the fan on the one motherboard and the top of the NIC on the opposing motherboard. 这样的结果就是每块主板间的间距为6",如图所示:
主板之间的距离
(说明:这些主板都有一个单独 PCI-e x16插槽,留给以后想提升性能的时候,可以插上一块GPU)
使用350瓦的电源供电(每块主板一个),使用双面胶固定在有机玻璃上,电源插座放在最上面的有机玻璃上,如图所示:
本小超算的电源和风扇
(此处用胶水固定硬盘、光驱、路由器)
最靠近夹层的底部主板作为“主节点”——主控主板,连接硬盘、光驱(可选)等,系统启动/关机/重启的时候也是从这个部分操作。其他的主板当作“分支节点”,使用PXE网络启动方式启动。
对最底部的主控主板做特殊设置,连接250GB硬盘,并且作为启动分区。插入光驱(主要是用于安装初始系统,现在都不需要了,直接用优盘做系统安装盘吧……)
插入另一块网卡10/100 NIC到PCI插槽中,用于连接外部网络。
顶部三个节点都是无硬盘的, and used NFS to export the space on the 250 GB drive to them。
下图显示了本小超算各个部分的连接关系(节点0为重心,连接了硬盘、光驱、以及连接外部的接口,内部中心为千兆路由,用于连接其他节点):
<img data-rawheight="134" data-rawwidth="420" src="https://pic3.zhimg.com/fe70dd27a5e704552c7b255a815845da_b.jpg" class="content_image" width="420">
说明:每个节点都有两条独立的通讯线路,连接自己和网络路由器。
With four CPUs blowing hot air into such a small volume, we thought we should keep the air moving through Microwulf. To accomplish this, we decided to purchase four Zalman 120mm case fans ($8 each) and grills ($1.50 each). Using scavenged twist-ties, we mounted two fans -- one for intake and one for exhaust -- on opposing sides of each pair of facing motherboards. This keeps air moving across the boards and NICs; Figure Five shows the two exhaust fans:
Figure Five: Two of Microwulf's (Exhaust) Fans
So far, this arrangement has worked very well: under load, the on-board temperature sensors report temperatures about 4 degrees above room temperature.
Last, we grounded each component (motherboards, hard drive, etc.) by wiring them to one of the power supplies.
系统使用的是有奔头(Ubuntu Linux).
开源通用信道(Open MPI)将自动识别每个节点的网络适配器,并让它们之间组成一个圆环型的信息交流系统。 To try to help Open MPI spread the load on both the sending and receiving side, we configured the on-board adaptors to be part of a 192.168.2.x subnet, and the PCI-e adaptors to be part of a 192.168.3.x subnet.
价格参考(2007年一月):
部件
产品名称
单价
数量
总价
主板 微星 K9N6PGM-F MicroATX $80.00 4 $320.00 芯片
威盛Athlon 64 X2 3800+ AM2 CPU $165.00 4 $660.00 内存 金士顿 DDR2-667 1GByte RAM $124.00 8 $992.00 电源 Echo Star 325W MicroATX Power Supply $19.00 4 $76.00 网卡 Intel PRO/1000 PT PCI-Express NIC (节点连接路由) $41.00 4 $164.00 网卡 Intel PRO/100 S PCI NIC (主控主板连接外部网络) $15.00 1 $15.00 路由器 Trendware TEG-S80TXE 8-port Gigabit Ethernet Switch $75.00 1 $75.00 硬盘 希捷7200转 250GB SATA硬盘 $92.00 1 $92.00 光驱 Liteon SHD-16S1S 16X $19.00 1 $19.00 冷切系统 Zalman ZM-F3 120mm Case Fans $8.00 4 $32.00 风扇 Generic NET12 Fan Grill (120mm) $1.50
+ shipping 4 $10.00 硬件支架 36" x 0.25" threaded rods $1.68 3 $5.00 硬件固定 Lots of 0.25" nuts and washers $10.00 机箱或外壳
12" x 11" 有机玻璃(是我们物理实验室的废品) $0.00 4 $0.00 总价
$2,470.00
非必须的硬件
部件
产品名称
单价
数量 总价 KVM Switch Linkskey LKV-S04ASK $50.00 1 $50.00 总价
$50.00
除了技术支持还有硬件加固 (购买自Lowes), 风扇和转接器购买自 newegg.com, 其他都购买自(量多有折扣,呵呵):
N F P Enterprises
1456 10 Mile Rd NE
Comstock Park, MI 49321-9666
(616) 887-7385
So we were able to keep the price for the whole system to just under $2,500. That's 8 cores with 8 GB of memory and 8 GigE NICs for under $2,500, or about $308.75 per core.
构建配置:
点击此处:软件系统构建说明,有详细的介绍文件下载——建议想自己构建的人下载下来,然后按照其说明,逐步完成。
细节是魔鬼
首先是选用哪个你牛叉发行版:曾经一度使用Gentoo,但后来觉得gentoo太消耗能量了(包括系统管理员的精力和系统的耗电),后来 试了试有奔头,一开始安装的桌面是6.10版本,其内核是2.6.17,但美中不足的是he on-board NIC的驱动需要到2.6.18才内置,所以一开始两个月,我们的小超算就用的7.04的测试版(内核是2.6.20),直到最后稳定版发行就换了稳定 版。
在其他三个计算节点上,安装的是有奔头的服务器版,因为它们不需要桌面功能。
也就是:有奔头桌面版+3个有奔头服务器版
我们也试过其他的集群管理软件:ROCKS, Oscar, 和 Warewulf.,但ROCKS和Oscar不支持无盘的节点。Warewulf工作良好,但因为本小超算实在太小,目前看不出其优势来。因为这篇论文,曾经想使用iSCSI。不过为了尽快让我们的集群运行起来,还是决定使用NFSroot,因为其配置非常简单,只需要修改/etc/initramfs.conf ,让其生成一个虚拟内存(initial ramdisk) that does NFSroot and then setting up DHCP/TFTP/PXELinux on the head node, as you would for any diskless boot situation.
We did configure the network adaptors differently: we gave each onboard NIC an address on a 192.168.2.x subnet, and gave each PCI-e NIC an address on a 192.168.3.x subnet. Then we routed the NFS traffic over the 192.168.2.x subnet, to try to separate "administrative" traffic from computational traffic. It turns out that OpenMPI will use both network interfaces (see below), so this served to spread communication across both NICs.
One of the problems we encountered is that the on-board NICs (Nvidia) present soem difficulties. After our record setting run (see the next section) we started to have trouble with the on-board NIC. After a little googling, we added the following option to the forcedeth module options:
forcedeth max_interrupt_work=35
The problem got better, but didn't go away. Originally we had the onboard Nvidia GigE adaptor mounting the storage. Unfortunately, when the Nvidia adaptor started to act up, it reset itself, killing the NFS mount and hanging the "compute" nodes. We're still working on fully resolving this problem, but it hasn't kept us from benchmarking Microwulf.
效果图:直接点击上面目录连接,可查看
性能表现:
所获得的性能表现
Once Microwulf was built and functioning it's fairly obvious that we wanted to find out how 'fast' it was. Fast can have many meanings, depending upon your definition. But since the HPL benchmark is the standard used for the Top500 list, we decided to use it as our first measure of performance. Yes, you can argue and disagree with us, but we needed to start somewhere.
We installed the development tools for Ubuntu (gcc-4.1.2) and then built both Open MPI and MPICH. Initially we used OpenMPI as our MPI library of choice and we had both GigE NICs configured (the on-board adaptor and the Intel PCI-e NIC that was in the x16 PCIe slot).
Then we built the GOTO BLAS library, and HPL, the High Performance Linpack benchmark.
The Goto BLAS library built fine, but when we tried to build HPL (which uses BLAS), we got a linking error indicating that someone had left a function named main() in a module named main.f in /usr/lib/libgfortranbegin.a. This conflicted with main() in HPL. Since a library should not need a main() function, we used ar to remove the offending module from /usr/lib/libgfortranbegin.a, after which everything built as expected.
Next, we started to experiment with the various parameters for running HPL - primarily problem size and process layout. We varied PxQ between {1x8, 2x4}, varied NB between {100, 120, 140, 160, 180, 200}, and used increasing values of N (problem size) until we ran out of memory. As an example of the tests we did, Figure Six below is a plot of the HPL performance in GFLOPS versus the problem size N.
Figure Six: Microwulf Results for HPL WR00R2R24 (NB=160)
For Figure Six we chose PxQ=2x4, NB=160, and varied N from a very small number up to 30,000. Notice that above N=10,000, Microwulf achieves 20 GLFOPS, and with N greater than 25,000, it exceeds 25 GFLOPS. Anything above N=30,000 produced "out of memory" errors.
We did achieve a peak performance of 26.25 GFLOPS. The theoretical peak performance for Microwulf is 32 GLFOPS. (Eight cores x 2 GHz x 2 double-precision units per core.) This means we have hit about 82% efficiency (which we find remarkable). Note that one of the reasons we asume that we achieved such a high efficiency is due to Open MPI, which will use both GigE interfaces. It will round-robin data transfers over the various interfaces unless you explicitly tell it to just use certain interfaces.
It's important to note that this performance occurred using the default system and Ethernet settings. In particular, we did not tweak any of Ethernet parameters mentioned in Doug Eadline and Jeff Layton's article on cluster optimization. We were basically using "out of the box" settings for these runs.
To assess how well our NICs were performing, Tim did some followup HPL runs, and used netpipe to gauge our NICs latency. Netpipe reported 16-20 usecs (microseconds) latency on the onboard NICs, and 20-25 usecs latency on the PCI-e NICs, which was lower (better) than we were expecting.
As a check on performance we also tried another experiment. We channel bonded the two GigE interfaces to produce, effectively, a single interface. We then used MPICH2 with the channel bonded interface and used the same HPL parameters we found to be good for Open-MPI. The best performance we achieved was 24.89 GLOPS (77.8% efficiency). So it looks like Open MPI and multiple interfaces beats MPICH2 and a bonded interface.
Another experiment we tried was to use Open MPI and just the PCI-e GigE NIC. Using the same set of HPL parameters we have been using we achieved a performance of 26.03 GFLOPS (81.3% efficiency). This is fairly close to the performance we obtained when using both interfaces. This suggests that the on-board NIC isn't doing as much work as we thought. We plan to investigate this more in the days ahead.
下面看看历年最强500超算里面的本小超算性能方面的排名:
- Nov. 1993: #6
- Nov. 1994: #12
- Nov. 1995: #31
- Nov. 1996: #60
- Nov. 1997: #122
- Nov. 1998: #275
- June 1999: #439
- Nov. 1999: 被踢出名单了
1993年11月,本小超算可以排名世界第6。1999年6月,排名为第439,相比于一般超算放在一个大大的机房里,而且需要众多芯片,这个4片、8芯的集群,只有11" x 12" x 17",能有如此表现,很不错了。
更进一步挖掘下这个列表:1993年11月的排名中,排在第五位的超算是用了512片核芯的Thinking Machines CM-5/512,运算速度达到300亿次。本小超算的4核相当于当年的512核啊,哈哈。
1996年11月,此小超算排在第60位,下一个是用了256片核芯的Cray T3D MC256-8,现在8核俄性能都超过11年前的256核了,此处还没说价格差异呢,T3D花费了上百万美元!
超算性能一般以每秒浮算次数(flops)来衡量。早期超算使用百万次来衡量,随着硬件飞跃,十亿次已经是很落后的指标了,现在都流行用万亿次,甚至千万亿次来表示了。
Early supercomputer performance was measured in megaflops (Mflops: 10
6
flops). Hardware advances increased subsequent supercomputers performance to gigaflops (Gflops: 10
9
flops). Today's massively parallel supercomputers are measured in teraflops (Tflops: 10
12
flops), and tomorrow's systems will be measured in petaflops (Pflops: 10
15
flops).
When discussing supercomputer performance, you must also distinguish between
- 峰值性能 --理论上最大的性能表现
- 测量性能 -- 用检测软件检测出来的性能表现
一般计算机生产商会标示峰值,但实际检测一般只有峰值的50%-60%左右。
另一个要注意的是精度,一般高性能运算都是用的双精度,所以不可混淆了单精度和双精度运算。
The standard benchmark (i.e., used by the top500.org supercomputer list) for measuring supercomputer performance is high performance Linpack (aka HPL), a program that exercises and reports a supercomputer's double-precision floating point performance. To install and run HPL, you must first install a version of the Basic Linear Algebra Subprograms (BLAS) libraries, since HPL depends on them.
In March 2007, we benchmarked Microwulf using HPL and Goto BLAS. After compiling and installing each package, we ran the standard, double-precision version of HPL, varying its parameter values as follows: We varied PxQ between {1x8, 2x4}; varied NB between {100, 120, 140, 160, 180, 200}; and used increasing values of N, starting with 1,000. For the following parameter values:
PxQ = 2x4; NB = 160; N = 30,000
HPL reported 26.25 Gflops on its WR00R2R4 operation. Microwulf also exceeded 26 Gflops on other operations, but 26.25 Gflops was our maximum.
在最强500超算中,1996年的Cray T3D-256也才达到253亿次,所以我们这个260亿次的性能,是足够用来做很多事情的了。
Since we benchmarked Microwulf, Advanced Clustering Technologies has published a convenient web-based calculator that removes much of the trial and error from tuning HPL.
性价比:
When you have measured a supercomputer's performance using HPL, and know its price, you can measure its cost efficiency by computing its price/performance ratio. By computing the number of dollars you are paying for each floating point operation (flop), you can compare one supercomputer's cost-efficiency against others.
With a price of just $2470 and performance of 26.25 Gflops, Microwulf's price/performance ratio (PPR) is $94.10/Gflop, or less than $0.10/Mflop! This makes Microwulf the first general-purpose Beowulf cluster to break the $100/Gflop (or $0.10/Mflop) threshold for measured double-precision floating point performance.
下面列表可作为参考,了解下这个性价比的意义:
- In 1976, the Cray-1 cost more than 8 million dollars and had a peak (theoretical maximum) performance of 250 Mflops, making its PPR more than $32,000/Mflop. Since peak performance exceeds measured performance, its PPR using measured performance (estimated at 160 Mflops) would be much higher.
- In 1985, the Cray-2 cost more than 17 million dollars and had a peak performance of 3.9 Gflops, making its PPR more than $4,350/Mflop ($4,358,974/Gflop).
- 1997年,打败西方象棋世界冠军卡斯帕罗夫的 IBM 深蓝。价格是5百万美元,性能是113.8亿次,其性价比是43936.7美元/亿次
- In 2003, the U. of Kentucky's Beowulf cluster KASY0 cost $39,454 to build, and produced 187.3 Gflops on the double-precision version of HPL, giving it a PPR of about $210/Gflop.
- Also in 2003, the University of Illinois at Urbana-Champaign's National Center for Supercomputing Applications built the PS 2 Cluster for about $50,000. No measured performance numbers are available; which isn't surprising, since the PS-2 has no hardware support for double precision floating point operations. This cluster's theoretical peak performance is about 500 Gflops (single-precision); however, one study showed that the PS-2's double-precision performance took over 17 times as long as its single-precision performance. Even using the inflated single-precision peak performance value, its PPR is more than $100/Gflop; it's measured double-precision performance is probably more than 17 times that.
- In 2004, Virginia Tech built System X, which cost 5.7 million dollars, and produced 12.25 Tflops of measured performance, giving it a PPR of about $465/Gflop.
- In 2007, Sun's Sparc Enterprice M9000 with a base price of $511,385, produced 1.03 Tflops of measured performance, making its PPR more than $496/Gflop. (The base price is for the 32 cpu model, the benchmark was run using a 64 cpu model, which is presumably more expensive.)
$9.41/亿次,我们的小超算可以说是超算里面性价比最好的一个了,不过呢,还没法提供千万亿次的运算,若有需要,或许可以突破这个价格限制,让性能方面获得更大的提升。
效能 - 世界记录 功耗:
以2007年一月的价格,本小超算用了2470美元,获得262.5亿次的运算速度,平均9.41美元/亿次。这个已经成为新的世界纪录了。
另外,节能方面的事情最近也比较敏感,性耗比(耗电量/性能)也需要测量下了,性耗比对集群是非常重要的,尤其是成片的集群(比如谷歌的服务器场)。本小超算我们测试了下,
- 待机需要消耗250瓦(平均30瓦每核),
- 运行是需要消耗450瓦,
算了下运行时的性耗比就是1.714瓦/亿次。
对比下其他的超算。
专门进行节能设计的超算Green Destiny 使用了非常节能的芯片,只需要较低的冷切,240核消耗了3.2千瓦,获得的运算性能是1010亿次,性耗比为3.1瓦/亿次。是我们这个自制的小超算的两倍哦!!!
Another interesting comparison is to the Orion Multisystems clusters. Orion is no longer around, but a few years ago they sold two commercial clusters: a 12-node desktop cluster (the DS-12) and a 96-node deskside cluster (the DS-96). Both machines used Transmeta CPUs. The DS-12 used 170W under load, and its performance was about 13.8 GFLOPS. This gives it a performance/power ratio of 12.31W/GLFOP (much better than Microwulf). The DS-96 consumed 1580W under load, with a performance of 109.4 GFLOPS. This gives it a performance/power ratio of 14.44W/GFLOP, which again beats Microwulf.
Another way to look at power consumption and price is to use the metric from Green 500. Their metric is MFLOPS/Watt (the bigger the number the better). Microwulf comes in at 58.33, the DS-12 is 81.18, and the deskside unit is 69.24. So using the Green 500 metric we can see that the Orion systems are more power efficient than Microwulf. But let's look a little deeper at the Orion systems.
The Orion systems look great at Watts/GFLOP and considering the age of the Transmeta chips, that is no small feat. But let's look at the price/performance metric. The DS-12 desktop model had a list price of about $10,000, giving it a price/performance ratio of $724/GFLOP. The DS-96 deskside unit had a list price of about $100,000, so it's price/performance is about $914/GFLOP. That is, while the Orion systems were much more power efficient, their price per GFLOP is much higher than that of Microwulf, making them much less cost efficient than Microwulf.
Since Microwulf is better than the Orion systems in price/performance, and the Orion systems are better than Microwulf in power/performance, let's try some experiments with metrics to see if we can find a useful way to combine the metrics. Ideally we'd like a single metric that encompasses a system's price, performance, and power usage. As an experiment, let's compute MFLOP/Watt/$. It may not be perfect, but at least it combines all 3 numbers into a single metric, by extending the Green 500 metric to include price. You want a large MFLOP/Watt to get the most processing power per unit of power as possible. We also want price to be as small as possible so that means we want the inverse of price to be as large as possible. This means that we want MFLOP/Watt/$ to be as large as possible. With this in mind, let's see how Microwulf and Orion did.
- Microwulf: 0.2362
- Orion DS-12: 0.00812
- Orion DS-96: 0.00069
From these numbers (even though they are quite small), Microwulf is almost 3 times better than the DS-12 and almost 35 times better than the DS-96 using this metric. We have no idea if this metric is truly meaningful but it give us something to ponder. It's basically the performance per unit power per unit cost. (OK, that's a little strange, but we think it could be a useful way to compare the overall efficiency of different systems.)
We might also compute the inverse of the MFLOP/Watt/$ metric: -- $/Watt/MFLOP -- where you want this number to be as small as possible. (You want price to be small and you want Watt/MFLOP to be small). So using this metric we can see the following:
- Microwulf: 144,083
- Orion DS-12: 811,764
- Orion DS-96: 6,924,050
This metric measures the price per unit power per unit performance. Comparing Microwulf to the Orion systems, we find that Microwulf is about 5.63 times better than the DS-12, and 48 times better than the DS-96. It's probably a good idea to stop here, before we drive ourselves nuts with metrics.
While most clusters publicize their performance data, Very few clusters publicize their power consumption data.
Some notable exceptions are:
- Green Destiny, an experimental blade cluster built at Los Alamos National Labs in 2002. Green Destiny was built expressly to minimze power consumption, using 240 Transmeta TM560 CPUs. Green Destiny consumed 3.2 kilowatts and produced 101 Gflops (on Linpack), yielding a power/performance ratio of 31 watts/Gflop. Microwulf's 17.14 watts/Gflop is much better.
- The (apparently defunct) Orion Multisystems DS-12 and DS-96 systems:
- The DS-12 "desktop" system consumed 170 watts under load, and produced 13.8 Gflops (Linpack), for a power/performance ratio of 12.31 watts/Gflop. (The DS-12's list price was about $10,000, making its price/performance ratio $724/Gflop.)
- The DS-96 "under desk" system consumed 1580 watts under load, and produced 109.4 Gflops (Linpack), for a power/performance ratio of 14.44 watts/Gflop. (The DS-96's list price was about $100,000, making its price/performance ratio about $914/Gflop.)
- 我们的小超算性价比上 远超这些商业机器,其性耗比也居于前流。
节能500超算名单,是基于最强500超算的(本小超算没有被列入,呵呵),排名按每瓦运算次数排列。我们的小超算是1.713瓦/亿次,换算如下:
1 / 17.14 W/Gflop * 1000 Mflops/Gflop= 58.34 Mflops/W
2007年8月,我们的小超算超越了节能500超算的第二位,Mare Nostrum (58.23 Mflops/W) -- 可惜啊,和排名第一BlueGene/L (112.24 Mflops/W)的距离有点远。
结论
此小超算用了4块芯片、8核集群,大小为11" x 12" x 17",适合放在桌面上,也适合打包放到飞机上运输。
除了小巧,HPL检测本超算有262.5亿次的运算性能,总花费是2470美元(2007年1月),性价比为9.41美元/亿次。
本小超算能有如此神力的原因是:
- 多核芯片已经普及:这样可以让系统变得更小。
- 内存大降价: 此小超算最贵的部分就是这个,不过价格一直在快速下降中,8G内存应该够用了吧??
- 千兆网卡已经普及:On-board GigE adaptors, inexpensive GigE NICs, and inexpensive GigE switches allow Microwulf to offer enough network bandwidth to avoid starving a parallel computation with respect to communication.
我们不打算保守我们的技术秘密,而是希望所有人都来尝试这玩玩,嗯,其实很多部件都是可以替换的。
比如,随着固态硬盘的降价,可以试试固态硬盘替换掉机械硬盘,看看对性能有何影响。
比如内存:因为内存降价,可以把内存换为2GB的,这样每核可以2GB内存。Recalling that HPL kept running out of memory when we increased N above 30,000, it would be interesting to see how many more FLOPS one could eke out with more RAM. The curve in Figure Six suggests that performance is beginning to plateau, but there still looks to be room for improvement there.
比如主板和芯片:此微星主板使用AM2插槽,这个插槽刚好支持威盛新的4核Athlon64芯片,这样就可以替换掉上文中的双核芯片,使得整个系统变成 16核,性能更加强劲。有兴趣的同学可以测测这么做的结果性能提升多少?性价比因此而产生的变化?千兆内部网的效能变化等……
等等……尤其是已经几年后的今天(2012),这个列表几乎可以全部替换掉了。
2007年8月配件价格:
各个部件的价格下降很快。芯片、内存、网络、硬盘等,都降了好多价格。2007年8月在 新蛋(Newegg) 中的价格:
部件
产品名称
单价
数量 总价 主板 微星K9N6PGM-F MicroATX$50.32 4 $201.28 芯片
威盛 Athlon 64 X2 3800+ AM2 CPU$65.00 4 $260.00 内存 Corsair DDR2-667 2 x 1GByte RAM $75.99 4 $303.96 电源
LOGISYS Computer PS350MA MicroATX 350W Power Supply$24.53 4 $98.12 网卡 Intel PRO/1000 PT PCI-Express NIC (节点连接路由) $34.99 4 $139.96 网卡
Intel PRO/100 S PCI NIC (主控主板连接外部网络) $15.30 1 $15.30 路由器
SMC SMCGS8 10/100/1000Mbps 8-port Unmanaged Gigabit Switch$47.52 1 $47.52 硬盘
希捷7200转 250GB SATA 硬盘$64.99 1 $64.99 光驱
Liteon SHD-16S1S 16X$23.831$23.83 制冷设备
Zalman ZM-F3 120mm Case Fans$14.98 4 $59.92 风扇 Generic NET12 Fan Grill (120mm)$6.48 4 $25.92 硬件支架 36" x 0.25" threaded rods $1.68 3 $5.00 硬件加固 Lots of 0.25" nuts and washers $10.00 机箱或外壳 12" x 11" 有机玻璃(来自物理实验室的废物) $0.00 4 $0.00 总价$1,255.80
(现在价格应该更低了!而且性能方面应该更强悍了!!!)
可见,2007年8月,这个性价比已经达到了4.784美元/亿次,突破5美元/亿次!!!!!
性耗比则保持不变。
如果融合价格、性能、功耗,则每百万次/瓦/美元为0.04645,是原来的小超算两倍。美元/瓦/百万次为 73,255,也是原来的两倍。
应用:
和其他超算一样,本小超算可以运行一些并行运算软件——需要特别设计,以利用系统的并行运算能力。
这些软件一般会使用 通用信道和并行虚拟机。这几个库提供了分布式计算的最基础功能,一是使得进程可以在网络间沟通和同步,二是提供了一个分布执行最后汇总的机制,使得程序可以被复制成多份,分别在各个节点上运行。
有很多应用软件已经可以在本小超算上使用,大部分是由特定领域的科学家写的,用于解决特定问题:
- CFD codes, an assortment of programs for computational fluid dynamics
- DPMTA, a tool for computing N-body interactions fastDNAml, a program for computing phylogenetic trees from DNA sequences
- Parallel finite element analysis (FEA) programs, including:
- Adventure, the ADVanced ENgineering analysis Tool for Ultra large REal world, a library of 20+ FEA modules
- deal.II, a C++ program library providing computational solutions for partial differential equations using adaptive finite elements
- DOUG, Domain decomposition On Unstructured Grids
- GeoFEM, a multi-purpose/multi-physics parallel finite element simulation/platform for solid earth
- ParaFEM, a general parallel finite element message passing libary
- Parallel FFTW, a program for computing fast Fourier transforms (FFT)
- GADGET, a cosmological N-body simulator
- GAMESS, a system for ab initio quantum chemistry computations
- GROMACS, a molecular dynamics program for modeling molecular interactions, especially those from biochemistry
- MDynaMix, a molecular dynamics program for simulating mixtures
- mpiBLAST, a program for comparing gene sequences
- NAMD, a molecular dynamics program for simulating large biomolecular systems
- NPB 2, the NASA Advanced Supercomputing Division's Parallel Benchmarks suite. These include:
- BT, a computational fluid dynamics simulation
- CG, a sparse linear system solver
- EP, an embarrassingly parallel floating point solver
- IS, a sorter for large lists of integers
- LU, a different CFD simulation
- MG, a 3D scalar Poisson-equation solver
- SP, yet another (different) CFD simulation
- ParMETIS, a library of operations on graphs, meshes, and sparse matrices
- PVM-POV, a ray-tracer/renderer
- SPECFEM3D, a global and regional seismic wave simulator
- TPM, a collisionless N-body (dark matter) simulator
这是我们使用小超算的领域:
- 给卡尔文大学的本科生做研究项目
- As a high performance computing resource for CS 374: High Performance Computing
- 正在做的事情:
- 给本地的高中学校也定制几个,以提升学生了解计算的兴趣
- 用于会议,作为一个个人超算的示例模型。
- When not being used for these tasks, Microwulf runs the client for Stanford's Folding@Home project, which helps researchers better understand protein folding, which in turn helps them the causes of (and hopefuly the cures for) genetic diseases. Excess CPU cycles on a Beowulf cluster like Microwulf can be devoted to pretty much any distributed computing project.
常见问题回答:
- Will Microwulf run [insert favorite program/game] faster?
Unless the program has been written specifically to run in parallel across a network (i.e., it has been written using a parallel library like message passing interface (MPI)), probably not.A normal computer with a multicore CPU is a shared memory multiprocessor, since programs/threads running on the different cores can communicate with one another through the memory each core shares with the others.
On a Beowulf cluster like Microwulf, each motherboard/CPU has its own local memory, so there is no common/shared memory through which programs running on the different CPUs can communicate. Instead, such programs communicate through the network, using a communication library like MPI. Since its memory is distributed among the cluster's CPUs, a cluster is a distributed memory multiprocessor.
Many companies only began writing their programs for shared-memory multiprocessors (i.e., using multithreading) in 2006 when dual core CPUs began to appear. Very few companies are writing programs for distributed memory multiprocessors (but there are some). So a game (or other program) will only run faster on Microwulf if it has been parallelized to run on a distributed multiprocessor.
- 可以使用视窗系统来驱动小超算么?
The key to making any cluster work is the availability of a software library that will in parallel run a copy of a program on each of the cluster's cores, and let those copies communicate across the network. The most commonly used library today is MPI.There are several versions of MPI available for Windows. (To find them, just google 'windows mpi'.) So you can build a cluster using Windows. But it will no longer be a Beowulf cluster, which, by definition, uses an open source operating system. Instead, it will be a Windows cluster.
Microsoft is very interested in high performance computing -- so interested, they have released a special version of Windows called Windows Compute Cluster Server (Windows CCS), specifically for building Windows clusters. It comes with all the software you need to build a Windows cluster, including MPI. If you are interested in building a Windows cluster, Windows CCS is your best bet.
- 我也要搞部小超算,可到哪里学习?
There are many websites that describe how. Here are a few of them:- Building a Beowulf System, by Jan Lindheim, provides a quick overview
- Jacek Radajewski and Douglas Eadline's HowTo provides a more detailed overview
- Kurt Swendson's HowTo provides step-by-step instructions for building a cluster using Redhat Linux and LAM-MPI
- Engineering a Beowulf-style Compute Cluster, by Robert Brown, is an online book on building Beowulf clusters, with lots of useful information.
- The Beowulf mailing list FAQ, by Don Becker, et al, is a list of answers to questions frequently posted to the Beowulf.org mailing list, which has a searchable Archive.
- Beowulf.org's Projects page provides a list of links to the first hundred or so Beowulf cluster project sites. Many of these sites provide information that is useful to someone building a Beowulf cluster.
- How did you mount the motherboards to the plexiglas?
Our vendor supplied screws and brass standoffs with our motherboards. The standoffs have a male/screw end, normally screwed into the case; and a female/nut end, to which the motherboard is screwed. To use these to mount the motherboards, we just had to:- drill holes in the plexiglass pieces in the same positions as the motherboard mounting holes;
- screw the brass standoffs into the holes in the plexiglass pieces; and
- screw the motherboards to the standoffs.
To prepare each plexiglass piece, we laid a motherboard on top of it and then used a marker to color the plexiglass through the motherboard's mounting holes. The only tricky parts are:
- one piece of plexiglass has motherboards on both its top and its bottom, so you have to mark both sides; and
- two motherboards hang upside down, and two sit right-side up, so you have to take that into account when marking the holes.
We used a red marker to mark the positions of the holes on motherboards facing up, and a blue marker to mark the positions of the holes on motherboards facing down.
With the plexiglass pieces marked, we took them to our campus machine shop and used a drill press to drill holes in each piece of plexiglass.
When all the motherboard holes were drilled, we stacked the plexiglass pieces as they would appear in Microwulf and drilled holes in their corners for the threaded rods.
We then screwed the standoffs into the plexiglass, taking care not to overtighten them. Being made of soft brass, they are very easy to shear off. If this happens to you, just take the piece of plexiglass back to the drill press and drill out the bit of brass screw that's in the hole. (Or, if this is the only one, you can just leave it there and use one fewer screws to mount the motherboard.)
With the standoffs in place, we then placed the motherboards on the standoffs, and used screws to secure them in place. That's it!
The only other detail worth mentioning is that before we screwed each motherboard tight to the standoffs, we chose one standoff on each motherboard to ground that motherboard against static. To do this grounding, we got some old phone wire, looped one end to the standoff, and then tightened the screw for that standoff. We then grounded each wire to one of the threaded rods, and grounded that threaded rod to one of the power supplies.
- 这小超算是商品么?可以卖么?
否,主要是因为我们都不懂商业。But we are trying to build an endowment to provide in-house funding for student projects like Microwulf, so if you've found this site to be useful, please consider making a (tax-deductible) donation to it:
CS Hardware Endowment FundDepartment of Computer ScienceCalvin College3201 Burton SEGrand Rapids, MI 49546谢啦!
某网友测试过评论如下
好多年前的事情了.....
不在于系统是ubuntu Linux
而问题的重点是:
你会组装机器 硬件组装; 会作系统优化配置, 会配置很多服务, 比如NFS(构建无盘系统),NIS, 构建用户信息, MPI(高斯可以不用这个并行环境), 网络优化, 几个机器之间通信能力的优化,
如果你仅仅是明白硬件, 而对于linux系统的水平只专注于3D桌面之类的桌面应用, 那么你要搞明白这套系统,
还是比较困难的。
我自己作过, 只不过是用的两台机器,也是无盘系统, 系统采用自己熟悉的RHEL, 5.3 ,
那位作者的组装说明, 适合管理过linux系统, 熟悉linux网络应用的人看,
没有涉及过网络管理, 网络应用的, 要作下去比较费劲的。
他写的只是一个方案, 不是具体的每一步的how-to,
谁有兴趣的可以试试!
这套无盘系统, 性能很大程度取决于你的磁盘性能!
注意,这套系统, 适合并
自己组建spark集群,硬件方面以及网络连接设备方面应该如何选择
测试环境好些吧
spark运算速度超快
生产环境适合云计算(aws azure数据流入流量都是免费的)
比hadoop处理同样数据能省很多机时和钱
spark如何实现一个快速的RDD中所有的元素相互计算?
在spark集群中需要实现每个元素与其他元素进行计算,比如
rdd = sc.parallelize(Array('a', 'b', 'c', 'd')),
那么需要相互计算的元素对为
(a, b), (a, c), (a, d), (b, c), (b, d), (c, d)
我知道可以先进行cartesian,然后filter一下,但是对于数据量特别大的时候(比如,10w个),这种方法貌似很慢,所以请问大家知道在spark中有什么好的解决方法呢?
Spark程序如何只输出最后结果,隐藏中间的输出???
由于spark的调试信息输出在stderr 可以在命令后面加上 2>/dev/null 去掉调试信息
把spark/conf/log4j.properties下的
log4j.rootCategory=【Warn】=> 【ERROR】
log4j.logger.org.spark-project.jetty=【Warn】=> 【ERROR】
头大,这几种框架是什么关系???我现在想对hdfs上的文件做分析,spark是基于hadoop吗?sparksql又是什么,独立的项目吗?可以搭建一个hadoop+spark的平台吗,比如说使用hadoop的hdfs,然后使用spark sql方式来查询分析数据???对了还有hive on spark
泻药,水平有限,就科普一下吧。Hadoop是最早的MapReduce框架和Google File System的开源实现,被作为大数据处理的主流处理技术已经10多年了,其主要组件包括了MapReduce(计算)和HDFS(存储),然后在这个基础上发展成了一个生态系统,包括HBase,Hive等等。大约在2012年加州伯克利的Matei等人在MapReduce思想的基础上提出了RDD模式对数据进行暂存,并实现了Spark的原始版本,然后一直发展到现在。二者从根源上讲是基于同一种MapReduce思想的,但是Spark能完成的计算任务多样化,同配置下在绝大多数场景下比Hadoop要快。二者并无直接关系。基于Spark的核心作业引擎,Matei等人又设计了Spark SQL,Spark Streaming和Spark MLib等框架用来提供对特定场景的作业的支持。Spark SQL是基于Spark的。但是Spark是支持从Hadoop HDFS读取数据然后进行处理的,也支持S3和Tachyon,所以二者并不是密不可分的关系。
此外,题主问出这种问题让我很震惊,这是在某度里度一下都可以解决的问题。上知乎前先自己去了解一下。
1、Hadoop提供存储和离线计算,分别是HDFS和MapReduce(当然还有个HBase,题主既然没说那么不提也罢)
2、Spark只是一种计算框架,和Hadoop对应起来就是里面的MapReduce这个角色,他的存储系统可以使HDFS或者S3等,和MapReduce不同的是Spark是基于内存计算的
3、SparkSQL只是Spark中的一个核心扩展,在SparkSQL中用户可以通过类似SQL语句对数据进行分析操作,相对比scala,sql可能能够给大部分人所接受= =
对于题主的问题:
Hadoop并不是一定要上Spark,Spark也并不一定要依赖于Hadoop,所以这两者不是强制一定要一起使用的,当然肯定也不会是“有你没我,有我没你”的关系,互补,互补!
SparkSQL肯定是和Spark有关系的了,父子关系嘛,他还有Mllib,Graphx,Spark Streaming这些兄弟呢。。
我猜题主的应该是测试型的数据集,上Spark玩看看吧,有时间也可以用MapReduce实现对比试试
通过对比的方式可以更加深刻的理解MapReduce和Spark RDD编程模型之间的优缺点
对于最后一个问题,完全可以。。
我很喜欢用python,用python处理数据是家常便饭,从事的工作涉及nlp,算法,推荐,数据挖掘,数据清洗,数据量级从几十k到几T不等,我来说说吧
百万级别数据是小数据,python处理起来不成问题,python处理数据还是有些问题的
Python处理大数据的劣势:
1. python线程有gil,通俗说就是多线程的时候只能在一个核上跑,浪费了多核服务器。在一种常见的场景下是要命的:并发单元之间有巨大的数据共享或者共用(例如大dict),多进程会导致内存吃紧,多线程则解决不了数据共享的问题,单独的写一个进程之间负责维护读写这个数据不仅效率不高而且麻烦
2. python执行效率不高,在处理大数据的时候,效率不高,这是真的,pypy(一个jit的python解释器,可以理解成脚本语言加速执行的东西)能够提高很大的速度,但是pypy不支持很多python经典的包,例如numpy(顺便给pypy做做广告,土豪可以捐赠一下PyPy - Call for donations)
3. 绝大部分的大公司,用java处理大数据不管是环境也好,积累也好,都会好很多
Python处理数据的优势(不是处理大数据):
1. 异常快捷的开发速度,代码量巨少
2. 丰富的数据处理包,不管正则也好,html解析啦,xml解析啦,用起来非常方便
3. 内部类型使用成本巨低,不需要额外怎么操作(java,c++用个map都很费劲)
4. 公司中,很大量的数据处理工作工作是不需要面对非常大的数据的
5. 巨大的数据不是语言所能解决的,需要处理数据的框架(hadoop, mpi。。。。)虽然小众,但是python还是有处理大数据的框架的,或者一些框架也支持python
6. 编码问题处理起来太太太方便了
综上所述:
1. python可以处理大数据
2. python处理大数据不一定是最优的选择
3. python和其他语言(公司主推的方式)并行使用是非常不错的选择
4. 因为开发速度,你如果经常处理数据,而且喜欢linux终端,而且经常处理不大的数据(100m一下),最好还是学一下python
python数据处理的包:
1. 自带正则包, 文本处理足够了
2. cElementTree, lxml 默认的xml速度在数据量过大的情况下不足
3. beautifulsoup 处理html
4. hadoop(可以用python) 并行处理,支持python写的map reduce,足够了, 顺便说一下阿里巴巴的odps,和hadoop一样的东西,支持python写的udf,嵌入到sql语句中
5. numpy, scipy, scikit-learn 数值计算,数据挖掘
6. dpark(搬楼上的答案)类似hadoop一样的东西
1,2,3,5是处理文本数据的利器(python不就处理文本数据方便嘛),4,6是并行计算的框架(大数据处理的效率在于良好的分布计算逻辑,而不是什么语言)
暂时就这些,最好说一个方向,否则不知道处理什么样的数据也不好推荐包,所以没有头绪从哪里开始介绍这些包
这要看具体的应用场景,从本质上来说,我们把问题分解为两个方面:
1、CPU密集型操作
即我们要计算的大数据,大部分时间都在做一些数据计算,比如求逆矩阵、向量相似度、在内存中分词等等,这种情况对语言的高效性非常依赖,Python做此类工作的时候必然性能低下。
2、IO密集型操作
假如大数据涉及到频繁的IO操作,比如从数据流中每次读取一行,然后不做什么复杂的计算,频繁的输入输出到文件系统,由于这些操作都是调用的操作系统接口,所以用什么语言已经不在重要了。
结论
用Python来做整个流程的框架,然后核心的CPU密集操作部分调用C函数,这样开发效率和性能都不错,但缺点是对团队的要求又高了(尤其涉及到Python+C的多线程操作)...所以...鱼与熊掌不可兼得。如果一定要兼得,必须得自己牛逼。
奥利根神棍
1:Numpy+Scipy+Numba
2:Pandas+NLTK
答主是不是都没用过。
我们公司每天处理数以P记的数据,有个并行grep的平台就是python做的。当初大概是考虑快速成型而不是极限速度,但是事实证明现在也跑得杠杠的。大数据很多时候并不考虑太多每个节点上的极限速度,当然速度是越快越好,但是再更高层次做优化(比如利用data locality减少传输,建索引快速join,做sample优化partition,用bloomfilter快速测试等等),把python换成C并不能很大程度上提升效率。
很多机器学习,神经网络,数据计算的算法已经存在几十年了,这些零零散散的工具多被C和Fortran实现,直到有人开始用Python把这些工具集合到一起,所以,表面上是在用Python的库,实际上是C和Fortran的程序,性能上也并无大的影响,如果你真的是大数据的话
使用python可以,但对速度要求较高的关键模块,还是要用C重写。
Python调用vtk库对面片数量我测试过是没有限制的好像,你所说的100万多数据是不是都是存入了python的list中,list是有上限限制的。如果不存入list,应该是没有渲染上限的。
求python在大数据环境下高效编程的方法。
在spark集群下,我对对原来scala程序进行python重写。对过亿行级数据进行数据清洗整合操作。从执行任务的时间来看,scala执行效率比python重写程序高好多倍。
什么叫处理? 100万的数据,如果只是传输的话,python和c/c++差不多;如果用来计算话题模型的话,python的速度为c/c++的1/10,内存消耗为10倍多。
使用Python调用vtk库对100万行的数据进行可视化,结果内存爆满,使用C++就没有问题,Python很占内存,不知道为什么……
Python clone of Spark, a MapReduce alike framework in Python
https://github.com/douban/dpark
组建spark集群(生成环境)如何选择硬件?修改
1、看过官方的一个文档:https://spark.apache.org/docs/1.2.0/hardware-provisioning.html
2、集群主要用于spark streaming 和 机器学习这块,在硬件选择上有哪些注意点?
3、是否有同学能够共享一个线上环境的配置。
首先推荐看一看新出炉的https://spark-summit.org/east-2015/
题主给出的官方文档已经说得很好了,我只是结合自己的经验补充一下:
首先估算数据量大小(总容量)、Spark作业复杂度(需要多少计算能力)、作业的Locality(是否容易缓存)、数据交换的流量(多少数据需要在不同节点交换)。另外也考虑一下实时性需求,比如一次作业能忍受多长时间出结果。
每个节点的CPU、Memory、Network要匹配上面作业的需求,换句话说别让一个成为短板。
从成本上看,使用平民级硬件更好。比如RAID就没必要用。但是生产系统,ECC是必须的。
可以超量部署一段时间,然后再减下来
Spark Streaming没玩过,不过从用Storm的经验看,CPU和Network更容易是瓶颈。
MLlib用的不多,如果数据集能放在内存中,CPU和Network是瓶颈。
如何利用spark快速计算笛卡尔积?修改
在在spark集群里面 需要计算a*b的笛卡尔积 a为一列
b为一列 我将a作为一个rdd b作为一个rdd 直接调用cartesian方法,当数据量比较大的时候计算非常的慢,看sparkUI shuffleread的数据量较大,想请教下有可能是哪里出了问题或者有什么更好的方法在分布式上处理计算笛卡尔积。
作者:连城
链接:https://www.zhihu.com/question/39680151/answer/86174606
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
可以试试用 DataFrame API。
笛卡尔积映射到 SQL/DataFrame 上就是一个不带 join 条件的 inner join。DataFrame API 相对于 RDD API 的好处在于整体执行引擎基于 Spark SQL 的 Catalyst optimizer,并且可以利用上 project Tungsten 引入的各种执行层面的优化。Spark 新近版本中无 join 条件的 inner join 被编译为 CartesianProduct 时采用的已经是 UnsafeCartesianRDD 了。
此外,如果是两个 DataFrame 中有一个显著小于另一个,可以考虑将小的 DataFrame 广播出去从而避免大量 shuffle。以下是 1.6 的 spark-shell 中的示例:
import org.apache.spark.sql.functions.broadcast
val large = sqlContext.range(5)
val small = sqlContext.range(2)
large.join(broadcast(small)).show()
+---+---+
| id| id|
+---+---+
| 0| 0|
| 0| 1|
| 1| 0|
| 1| 1|
| 2| 0|
| 2| 1|
| 3| 0|
| 3| 1|
| 4| 0|
| 4| 1|
+---+---+
十分感谢,一会试试dataframe API ,我们原来的环境是1.2.0才升级成了1.5.0 囧,[SPARK-6307][Core] Speed up RDD.cartesian by caching remotely received blocks by viirya · Pull Request #5572 · apache/spark · GitHub 根据这个jira单号 spark在处理笛卡尔集的时候如果是remote读过来的数据 是计算后会释放的导致做笛卡尔集反复的读取和,如果spark有部分小的问题,我看了下源代码很多类和方法都是private的,如果想要做一定的修复,只能修改源代码重新打包 测试,比较麻烦,这个方面我想问下 spark可以开放更多的东西给开发者吗。
这点比较纠结……开放 API 是相对谨慎的,因为一旦开放就要在长时间内保持向下兼容,一定程度上会束缚后期演化。所以只有比较成熟的 API 才会开放。
理解,当前来看想要维护spark的一些bug之类的,要么修改源代码,要么只能等待spark升级了:),总之多follow,多研究,感谢回答
弱弱的问一句 使用jdbc进行join的执行效率会比使用dataframe API的执行效率低么?
不是很明白意思诶,啥叫使用jdbc进行join
研究过相关课题,看到delta join的问题格外的亲切
更好的方法,看你问的是那一层面的优化了
spark本身研究不多,以前研究这个课题是基于hadoop
无条件情况计算量无法优化,因为计算量就是m*n这么多
大小表的情况,可以通过广播小表等方法优化
两个都是大表的情况,分布式计算模型中数据传输量可以优化,但是很有限
这是几年前研读论文的总结,现在说不定过时了,但希望对你有帮助
论文:https://github.com/effyroth/paper/blob/master/10487_080605_200915055%E6%9C%89%E5%AD%A6%E5%8F%B7.pdf
感谢回答,个人这段时间的思考是1.如果是分布式计算m*n,可以将相对较大的m,较小的n变成(m1+m2+m3..mx)*n,n遍成广播变量这样减少n的shuffle,同时并行计算笛卡尔集,或者将变换m1*n=(m11*n+m12*n+m13*n...+m1x*n)这样可以串行计算减少单次计算的数据量以减少集群单节点的压力。2.对于spark的话和我上面说的是对于spark计算cartesianjoin的话,本身的方法有瑕疵,而想要优化又只能修改源代码带来的不方便。3后面更多的思考是 怎么从业务逻辑本身去优化,减少m和n的数据量或者避免笛卡尔集的计算,毕竟随便1w*1w的笛卡尔集数据量是相当吓人的。
关于Spark:
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,
拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,
因此Spark能更 好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法
Spark与Hadoop的对比
Spark的中间数据放到内存中,对于迭代运算效率更高。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
Spark比Hadoop更通用。
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。
这些多种多样的数据集操作类型,给给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
不过由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
容错性。
在分布式数据集计算时通过checkpoint来实现容错,而checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错。
可用性。
Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性。
Spark与Hadoop的结合
Spark可以直接对HDFS进行数据的读写,同样支持Spark on YARN。Spark可以与MapReduce运行于同集群中,共享存储资源与计算,数据仓库Shark实现上借用Hive,几乎与Hive完全兼容。
Spark的适用场景
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速。Spark非常小巧玲珑,由加州伯克利大学AMP实验室的Matei为主的小团队所开发。使用的语言是Scala,项目的core部分的代码只有63个Scala文件,非常短小精悍。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为Mesos的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
Spark 集群计算架构
虽然 Spark 与 Hadoop 有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark 是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负载。为了优化这些类型的工作负载,Spark 引进了内存集群计算的概念,可在内存集群计算中将数据集缓存在内存中,以缩短访问延迟。
Spark 还引进了名为弹性分布式数据集(RDD) 的抽象。RDD 是分布在一组节点中的只读对象集合。这些集合是弹性的,如果数据集一部分丢失,则可以对它们进行重建。重建部分数据集的过程依赖于容错机制,该机制可以维护 "血统"(即允许基于数据衍生过程重建部分数据集的信息)。RDD 被表示为一个 Scala 对象,并且可以从文件中创建它;一个并行化的切片(遍布于节点之间);另一个 RDD 的转换形式;并且最终会彻底改变现有 RDD 的持久性,比如请求缓存在内存中。
Spark 中的应用程序称为驱动程序,这些驱动程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。与 Hadoop 类似,Spark 支持单节点集群或多节点集群。对于多节点操作,Spark 依赖于 Mesos 集群管理器。Mesos 为分布式应用程序的资源共享和隔离提供了一个有效平台。该设置充许 Spark 与 Hadoop 共存于节点的一个共享池中。
什么是Hive on Spark?修改
1.在Hive里设置hive.execution.engine=spark,然后在Hive CLI里执行查询Hive中的表。
2.在Spark程序中通过hiveContext.sql()查询Hive中的表。
这两种都是Hive on Spark吗?还是说有什么区别
Hive有两个execution backend, 一个是Tez, 另一个是MapReduce.
意思就是你的HiveQL语句的最终执行程序可以选择Tez或者MapReduce.
Hive On Spark: 其实就是多一个Spark作为execution backend的选择而已. 三者共生平行关系.
以下摘自Hive Official:
Here are the main motivations for enabling Hive to run on Spark:
1. Spark user benefits: This feature is very valuable to users who are already using Spark for other data processing and machine learning needs. Standardizing on one execution backend is convenient for operational management, and makes it easier to develop expertise to debug issues and make enhancements.
2. Greater Hive adoption: Following the previous point, this brings Hive into the Spark user base as a SQL on Hadoop option, further increasing Hive’s adoption.
3. Performance: Hive queries, especially those involving multiple reducer stages, will run faster, thus improving user experience as Tez does.
It is not a goal for the Spark execution backend to replace Tez or MapReduce. It is healthy for the Hive project for multiple backends to coexist. Users have a choice whether to use Tez, Spark or MapReduce. Each has different strengths depending on the use case. And the success of Hive does not completely depend on the success of either Tez or Spark.
你说的第二个是Spark On Hive:
可以理解为Hive外包了一层基于Spark的User Interface. 即通过Spark可以直接进行Hive的相关操作: Hive Table , Hive UDFs, HiveQL等均可正常使用无误.
这样已经有历史遗留问题的Hive的相关资料也可以通过SparkSQL继续使用.
如果是新的资料, 你想仍放在以Hive作为data warehouse的里面的话, 直接使用SparkSQL可以享用Spark针对RDD设计的相关优化, 会比Hive On Spark的效能更好.
所谓Hive on Spark只是Hive项目的一个新特性,和Spark项目的开发没啥关系。
针对你列的1和2的区别是:
1. 就是所谓的Hive on Spark,就是把hive执行引擎换成spark。众所周知的是这个engine还可以设置和成mr(MRv1时代)和tez(目前hive13默认用的引擎,性能更佳),所以目前新增的spark选项只是Hive把执行计划放到spark集群上运行而已。
2. 是Spark SQL的一个特性。就是可以把hive作为一个数据源,这样我除了textFile从HDFS直接读文件,还可以直接用HiveQL查询到RDD,这对于要获取保存在Hive表的数据太方便了。这个特性早就支持了,至少我在之前用Spark1.2的时候已经可以从Hive里导入数据啦,最新的1.5新增了更多接口,用起来更方便了。
所以,简单来说区别1是Hive调用Spark任务,2是Spark调用Hive任务。
1.Hive on Spark。主要是对mr的一种性能优化(并不是所有场景都更好)
2.这个只是把hive当数据源。和你在其它语言中访问Hive没有差别。
其实还有一种情况,在SparkSQL中访问底层的Hive存储。更像是Spark on Hive,但是其实也是当作数据源而已。但是由于被隐藏在SparkSQL的配置中,看起来会觉得结合更紧密。
前者 是交互式的,后者是 应用式的(本来想说 非交互式的,感觉还不够专业→_→)
关于Hadoop
官方文档是最重要的
----------------------------------
Hadoop: the definitive guide
Hadoop in action
这两本书还不错
----------------------------------
http://allthingshadoop.com
Coursera上有一门UCSD开设的Big Data的专项课程
总共分五个课程,第一节大数据导论主要介绍的是大数据,hadoop是啥,有什么作用等等背景。
第二节是Map Reduce,HDFS,Spark等等的设计框架,实现机制等等,每一周后面还会有一个在虚拟机上用hadoop完成的小作业。比较初级的map reduce任务等等。
第三节是HBase Hive PIG等等更细一点的设计框架,实现机制,也都有对应的小作业。
第四节是big data在机器学习里的应用。
第五节还没有开课。
每节课程都是4周,如果只是为了完成课程内容的话还是比较简单的,但是覆盖的范围挺广的,这个课程适合作为引导去深入的了解big data,不会教你怎么去搭环境等等具体的问题,主要是讲原理的,搭配官方文档和其他更细致的资料服用更佳。反正对我这种没有工程实践的学生来说对了解big data 帮助很大。
在coursera上直接搜big data就可以了
我只能弱弱的说一句。。课程费略贵。。
http://course.tuicool.com/course/tag/hadoop
zhihu spark集群,书籍,论文相关推荐
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark 序列化错误 集群提交时_【问题解决】本地提交任务到Spark集群报错:Initial job has not accepted any resources...
本地提交任务到Spark集群报错:Initial job has not accepted any resources 错误信息如下: 18/04/17 18:18:14 INFO TaskSched ...
- spark集群使用hanlp进行分布式分词操作说明
本篇分享一个使用hanlp分词的操作小案例,即在spark集群中使用hanlp完成分布式分词的操作,文章整理自[qq_33872191]的博客,感谢分享!以下为全文: 分两步: 第一步:实现han ...
- GIS+=地理信息+云计算技术——Spark集群部署
第一步:安装软件 Spark 1.5.4:wget http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2 ...
- Spark集群启动时worker节点启不起来
在spark集群中使用命令: sbin/start-all.sh 启动集群时报错: starting org.apache.spark.deploy.master.Master, logging to ...
- 实现Spark集群部署 这些公司都经历了什么?
咨询公司获得了客户关于Spark评价的 "实质性"调查.但这项技术尚未成熟,企业用户中关于Spark集群的产品相对较少.他说,"我们对这项技术很感兴趣,Spark是否转化 ...
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记 1.环境介绍 (1)操作系统RHEL6.2-64 (2)两个节点:spark1(192.168.232.147),spark2(192 ...
- spark 集群单词统计_最近Kafka这么火,聊一聊Kafka:Kafka与Spark的集成
Spark 编程模型 在Spark 中, 我们通过对分布式数据集的操作来表达计算意图 ,这些计算会自动在集群上 井行执行 这样的数据集被称为弹性分布式数据集 Resilient Distributed ...
- 学习笔记Spark(二)—— Spark集群的安装配置
一.我的软件环境 二.Spark集群拓扑 2.1.集群规模 192.168.128.10 master 1.5G ~2G内存.20G硬盘.NAT.1~2核 : 192.168.128.11 node1 ...
- 二、安装Spark集群
[一个很疑惑的问题]为什么我们一直在反复做一个操作:就是scp拷贝过来拷贝过去? [答案]这是为了将文件或目录的权限修改成hadoop所属组. 一. 下载Spark安装包并传给mster机器,使权限是 ...
最新文章
- 一个月入门Python爬虫,轻松爬取大规模数据
- ubuntu16.04 cuda9.0 cudnn Tensorflow GPU 1.10.0
- Centos7.x 安装 Supervisord
- CUDA性能优化----线程配置
- BMP图像文件格式分析附带图解
- 列车停站方案_高速铁路列车停站方案与运行图协同优化理论和方法
- 物质为何能在虚空粒子海中存在
- dsp31段最佳调音图_车载dsp功放调音小经验分享!dsp调音31段EQ调音图与皇帝位时间延迟调整...
- Remoting技术
- python爬虫--爬取网易云音乐评论
- 数学基础 - 第十一章 三角形
- 剑网3最新服务器哪个人多,狂欢夜178万剑网3玩家挤爆服务器 新赛季玩家自觉排队做任务...
- Powermill汽车件模具五轴数控CNC编程视频教程
- 音乐正版率关键数据缺失,网易云音乐IPO胜算几何?
- 电话号码查询系统(链式结构)
- 项立刚:国外品牌很可能输掉3G手机这一战役
- 错误 不存在从 “std::string“ 到 “LPCSTR“ 的适当转换函数
- asp.net动态设置CSS等
- win7计算机名改成大写,处置win7系统将word中的阿拉伯数字转换成大写数字的还原方案...
- 全自动打码软件与人工打码的区别