Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记
1.环境介绍
(1)操作系统RHEL6.2-64
(2)两个节点:spark1(192.168.232.147),spark2(192.168.232.152)
(3)两个节点上都装好了Hadoop 2.2集群
2.安装Zookeeper
(1)下载Zookeeper:http://apache.claz.org/zookeeper ... keeper-3.4.5.tar.gz
(2)解压到/root/install/目录下
(3)创建两个目录,一个是数据目录,一个日志目录

(4)配置:进到conf目录下,把zoo_sample.cfg修改成zoo.cfg(这一步是必须的,否则zookeeper不认识zoo_sample.cfg),并添加如下内容
- dataDir=/root/install/zookeeper-3.4.5/data
- dataLogDir=/root/install/zookeeper-3.4.5/logs
- server.1=spark1:2888:3888
- server.2=spark2:2888:3888
复制代码
(5)在/root/install/zookeeper-3.4.5/data目录下创建myid文件,并在里面写1
- cd /root/install/zookeeper-3.4.5/data
- echo 1>myid
复制代码
(6)把/root/install/zookeeper-3.4.5整个目录复制到其他节点
- scp -r /root/install/zookeeper-3.4.5 root@spark2:/root/install/
复制代码
(7)登录到spark2节点,修改myid文件里的值,将其修改为2
- cd /root/install/zookeeper-3.4.5/data
- echo 2>myid
复制代码
(8)在spark1,spark2两个节点上分别启动zookeeper
- cd /root/install/zookeeper-3.4.5
- bin/zkServer.sh start
复制代码
(9)查看进程进否成在
- [root@spark2 zookeeper-3.4.5]# bin/zkServer.sh start
- JMX enabled by default
- Using config: /root/install/zookeeper-3.4.5/bin/../conf/zoo.cfg
- Starting zookeeper ... STARTED
- [root@spark2 zookeeper-3.4.5]# jps
- 2490 Jps
- 2479 QuorumPeerMain
复制代码
3.配置Spark的HA
(1)进到spark的配置目录,在spark-env.sh修改如下
- export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=spark1:2181,spark2:2181 -Dspark.deploy.zookeeper.dir=/spark"
- export JAVA_HOME=/root/install/jdk1.7.0_21
- #export SPARK_MASTER_IP=spark1
- #export SPARK_MASTER_PORT=7077
- export SPARK_WORKER_CORES=1
- export SPARK_WORKER_INSTANCES=1
- export SPARK_WORKER_MEMORY=1g
复制代码
(2)把这个配置文件分发到各个节点上去
- scp spark-env.sh root@spark2:/root/install/spark-1.0/conf/
复制代码
(3)启动spark集群
- [root@spark1 spark-1.0]# sbin/start-all.sh
- starting org.apache.spark.deploy.master.Master, logging to /root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-spark1.out
- spark1: starting org.apache.spark.deploy.worker.Worker, logging to /root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark1.out
- spark2: starting org.apache.spark.deploy.worker.Worker, logging to /root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark2.out
复制代码
(4)进到spark2(192.168.232.152)节点,把start-master.sh 启动,当spark1(192.168.232.147)挂掉时,spark2顶替当master
- [root@spark2 spark-1.0]# sbin/start-master.sh
- starting org.apache.spark.deploy.master.Master, logging to /root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-spark2.out
复制代码
(5)查看spark1和spark2上运行的哪些进程
- [root@spark1 spark-1.0]# jps
- 5797 Worker
- 5676 Master
- 6287 Jps
- 2602 QuorumPeerMain
- [root@spark2 spark-1.0]# jps
- 2479 QuorumPeerMain
- 5750 Jps
- 5534 Worker
- 5635 Master
复制代码
4.测试HA是否生效
(1)先查看一下两个节点的运行情况,现在spark1运行了master,spark2是待命状态
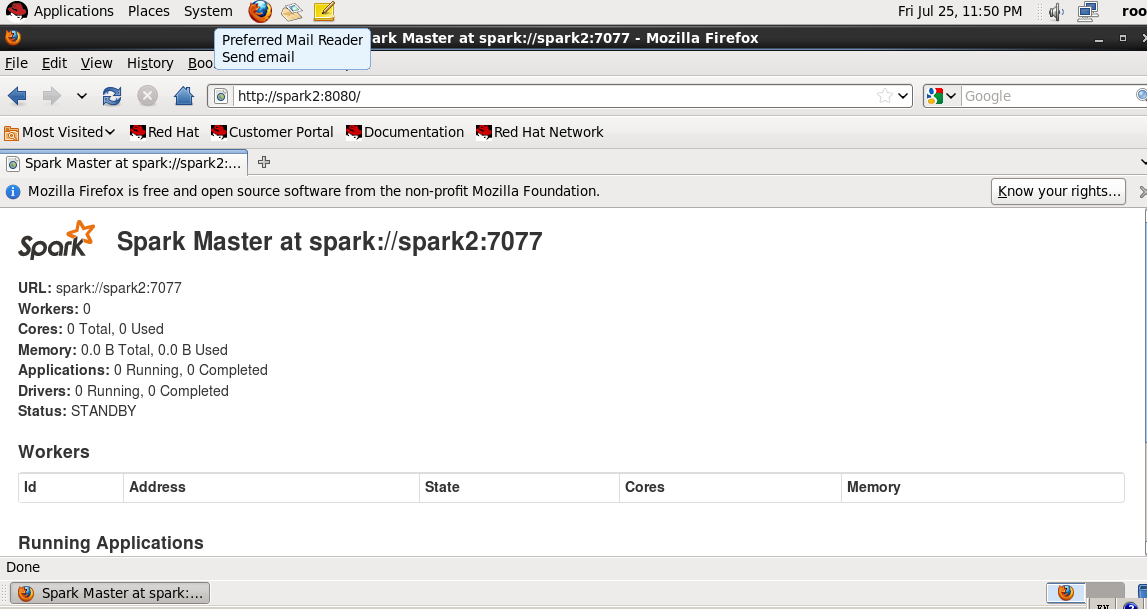
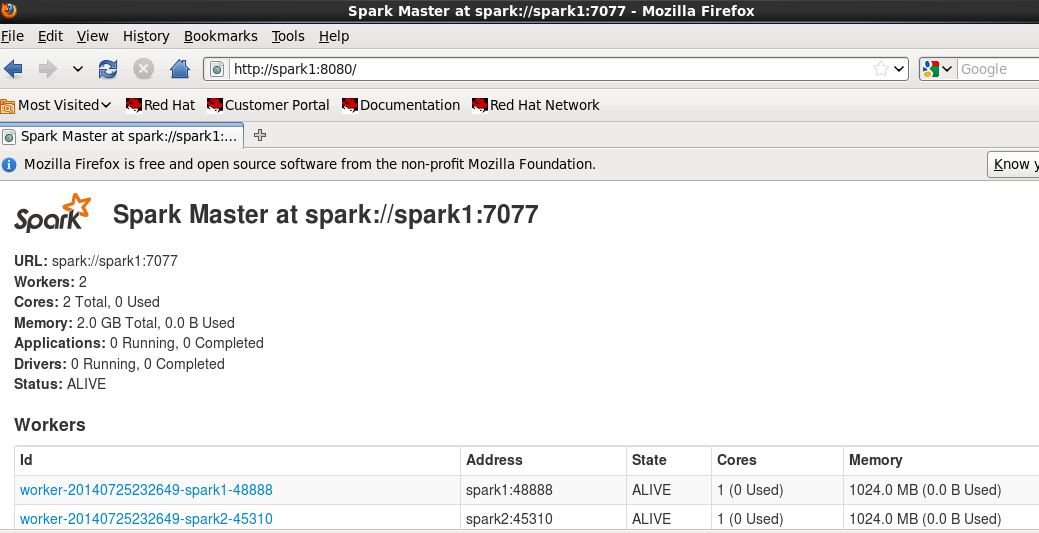
(2)在spark1上把master服务停掉
- [root@spark1 spark-1.0]# sbin/stop-master.sh
- stopping org.apache.spark.deploy.master.Master
- [root@spark1 spark-1.0]# jps
- 5797 Worker
- 6373 Jps
- 2602 QuorumPeerMain
复制代码
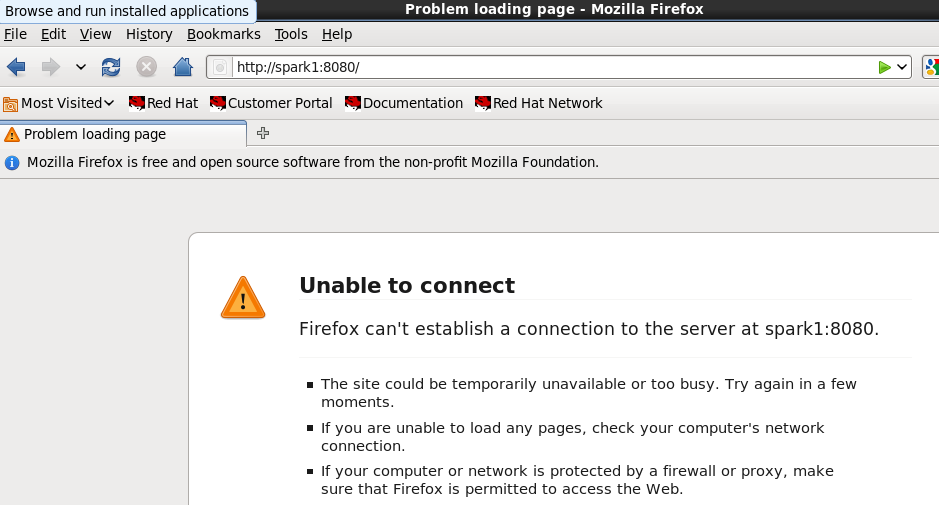
(3)用浏览器访问master的8080端口,看是否还活着。以下可以看出,master已经挂掉
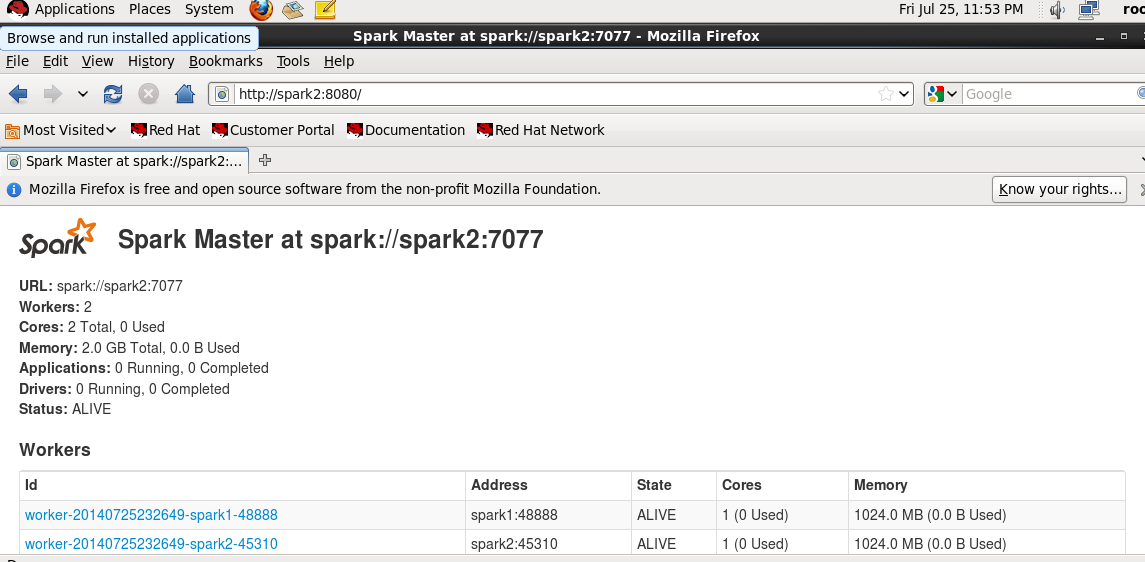
(4)再用浏览器访问查看spark2的状态,从下图看出,spark2已经被切换当master了
Spark集群基于Zookeeper的HA搭建部署笔记(转)相关推荐
- 从0开始搭建基于Zookeeper的Spark集群
完全从0搭建Spark集群 备注:这个步骤,只适合用root来搭建,正式环境下应该要有权限类的东西后面另外再进行实验写教程 1.安装各个软件,设置环境变量(每种软件需自己单独下载) export JA ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- Windows家庭版下基于Docker的hadoop、Spark集群搭建
Windows家庭版下基于Docker的hadoop.Spark集群搭建 目录 Windows家庭版下基于Docker的hadoop.Spark集群搭建 1.实验目的 2.实验平台 3.实验内容和要求 ...
- 基于Hadoop集群的Spark集群搭建
基于Hadoop集群的Spark集群搭建 注:Spark需要依赖scala,因此需要先安装scala 一. 简单叙述一下scala的安装 (1)下载scala软件安装包,上传到集群 (2)建立一个用于 ...
- Spark集群中HA环境搭建
1.环境介绍 (1)操作系统ubuntu16.4.0 (2)两个节点:spark1(192.168.232.147),spark2(192.168.232.152) (生产环境下一般配置3台) (3) ...
- Hadoop集群+Spark集群搭建基于VMware虚拟机教程+安装运行Docker
Hadoop集群+Spark集群搭建+安装运行Docker 目录 一.准备工作 二.在虚拟机上安装CentOS 7 三.hdfs的环境准备 四.hdfs配置文件的修改 五.克隆(复制虚拟机) 六.制作 ...
- Hadoop/Spark集群搭建图文全攻略
Hadoop/Spark集群搭建图文全攻略 一.安装VMware 二.创建Linux虚拟机 三.CentOS-7安装 四.Linux系统环境配置 五.其他配置 六.虚拟机克隆 七.jdk安装 八.Zo ...
- Spark-----Spark 与 Hadoop 对比,Spark 集群搭建与示例运行,RDD算子简单入门
目录 一.Spark 概述 1.1. Spark是什么 1.2. Spark的特点(优点) 1.3. Spark组件 1.4. Spark和Hadoop的异同 二.Spark 集群搭建 2.1. Sp ...
- 基于Hadoop安装spark集群
基于Hadoop的spark环境搭建 已有环境情况 Hadoop HA Java 软件版本 Hadoop 2.7.2 Java 1.8.0_301 Scala 2.11.8 Spark 2.1.0 下 ...
最新文章
- 湖北职称计算机考试报名时间2016,湖北2016年下半年职称计算机考试报名时间延长通知...
- ListView上拉加载,下拉刷新 PullToRefresh的使用
- rpm方式在centos7中安装mysql
- ts高仿C#的List、Dictionary
- 移动前端开发和 Web 前端开发的区别
- 美团外卖uml流程图_以美团外卖为例,浅析业务流程图和页面流程图
- python怎么输入一个数-Python中实现输入一个整数的案例
- 基于网络爬虫技术的网络新闻分析
- eMTC是什么技术?
- 【扯皮系列】一篇与众不同的 String、StringBuilder 和 StringBuffer 详解
- c++_设计一个 Studnet(学生)类
- 网络安全运维工程师数据库的核心能力有什么?
- 凯迪拉克5月软文-V设计
- 《国产操作系统之银河麒麟》银河麒麟服务器操作系统引导过程
- 第三届计算机网络安全与软件工程国际学术会议(CNSSE 2023)
- 「云安全」 什么是云访问安全代理(CASB )?
- 滴滴拼车变绿:下沉、烧钱、焦虑
- htcvr设备计算机配置,HTCVive电脑配置介绍
- 文件上传工具类FileUploadUtils
- 计算机二级11成绩查询时间,2020计算机二级考试成绩查询时间
热门文章
- 对C语言main函数中argc和argv[]的理解
- Centos安装postgreSQL
- spring,springmvc,mybatis基本整合(一)--xml文件配置方式(1)
- 软件测试技术lab2——Selenium上机实验
- 社会主义基本经济规律是经济效益规律
- 2016年中国程序员职业薪酬报告
- 给ADAS泼冷水?不,是客观评价
- Error:No resource identifier found for attribute 'appComponentFactory' in packag
- DDoS高防(国际)子产品发布,替代原本在DDoS高防IP中的海外线路。
- 建立项目的webpack简单配置