别忽视分布式系统这六大“暗流”
任何事物都有两面性。你只有了解了分布式系统背后的“暗流涌动”现象是什么,才能避免掉到“坑”里去。
暗流的含义是流动的地下水,是潜伏在“深层”的,我们往往过度地沉迷于表面的美好,而忽略了它。在分布式系统当中,最容易被我们忽略的是下面这六大“暗流”:
- 网络并不是可靠的
- 不同节点之间的通信是存在延迟的
- 带宽是有上限的
- 分布式并不直接意味着是“敏捷开发”了
- 数据由一份冗余成多份后如何保持一致
- 整个系统的不同部分可能是异构的
为了让你有更深刻的理解,我们来分别深入认识一下。
网络并不是可靠的
你应该明白,分布式系统中不同节点间的通信是基于网络的。网络使得它们连接起来共同协作。
然而,光缆被挖断的事件相信你也看到过不是一两次了。除此之外,网卡异常、交换机故障、遭受恶意攻击等导致的网络拥塞、网络中断、报文丢失的种种迹象皆意味着网络随时可能无法正常运作,是不可靠的。
此时,需要在你的系统设计中,尽可能地考虑到:当前节点所依赖的其他节点由于各种原因无法与之正常通信时,该如何保证其依然能够提供部分或者完整的服务。这个概念在软件领域被定义为“鲁棒性”。
不同节点之间的通信是存在延迟的
网络连接的是处于不同物理位置上的节点,学过物理和数学你的应该明白,两点之间是存在“距离”的,而我们的分布式系统需要在这个距离之上进行数据的传递,本质上就是物质的传递。同时应该你也知道,物质的运动速度不会超过光速。所以,不同节点之间的通信是需要经过一段时间的,也就意味着会存在延迟。具体的延迟是由所用的传输介质、节点当前的负载大小所决定的。另外,不容被忽视是为了通讯所做的额外工作也是耗时的,而且还不小,下图的橙色部分就是为了两个远程节点的通讯额外做的事情。
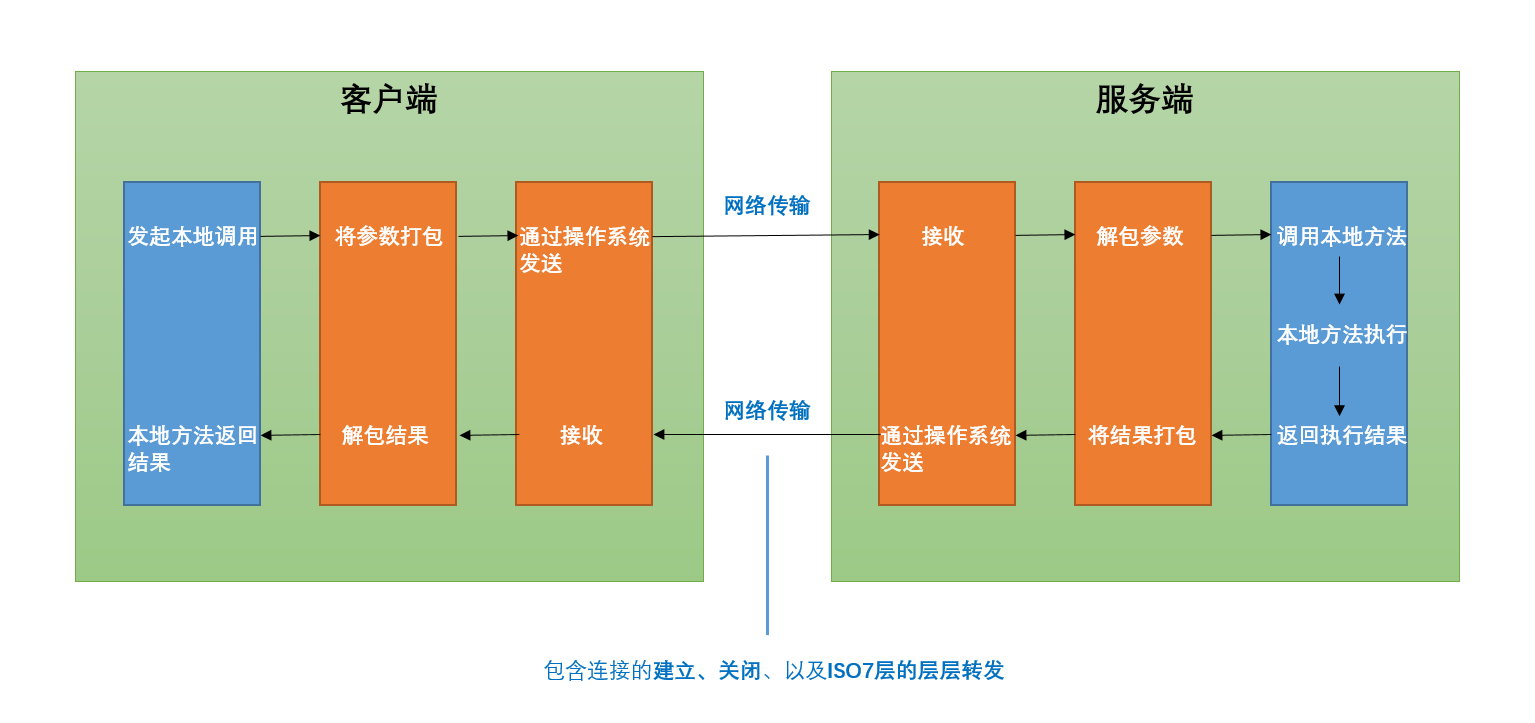
所以我们不能以调用本地方法一样的认知去理解远程调用(RPC)。在目前的技术环境下,CPU的运算能力长期保持高速增长,因此两个节点间通讯的大部分场景中,延迟的耗时总是大于目标节点进行逻辑运算的耗时。
由此可得,并不是将一个集中式系统拆分得越散,系统就越快。当中存在的延迟,不容忽视。如果是基于提速为目的的拆分,至少是满足下面这样的条件的。
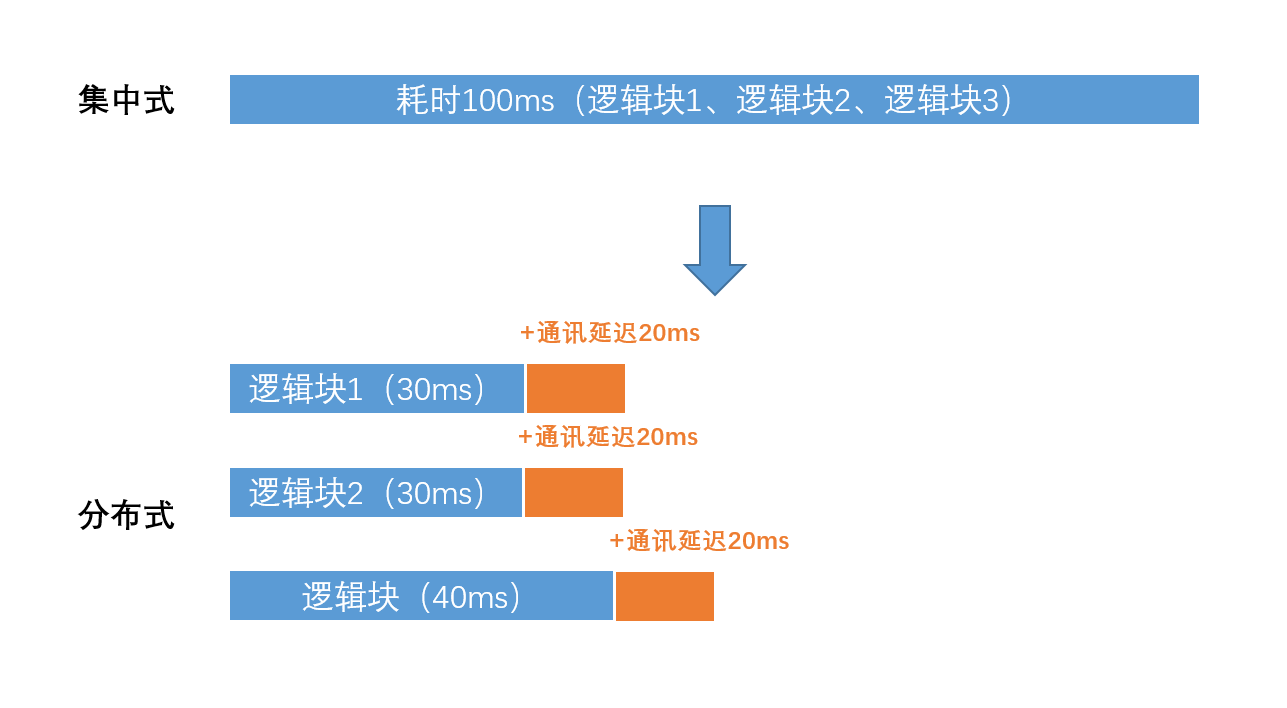
因为如果无法并行处理,反而会更慢,就像下面这样。

关于这点,我们还需要慎重考虑是否有必要进行“同步”的RPC调用,以及尽量的降低调用次数等。这就是为什么我们说,循环调用不如一次批量调用,反复调用不如调用一次做进程内缓存,同步调用比如异步调用的道理。
带宽是有上限的
这个点,我相信你是知道的,因为当你通过QQ、钉钉之类的工具传输或者下载一个大文件时候,就发现它是存在上限的,这个上限是根据你的网络带宽大小决定的。但是,为什么你还是有可能会掉入这个陷阱里呢?这往往由于你对所传输的数据的大小和频率没有充分的认识,导致了你觉得达到上限是一个很久远的事情,不用考虑它。
举个例子,你的网络都是基于100M带宽标准搭建的。那么此时如果每一秒会产生10240次数据传输,平均每个数据包大小是10KB,我们来看下是否会遇到瓶颈。
100M带宽的理论传输速率是12.5MB/秒。那么现在每一秒需要传输:10240次/秒 * 10KB = 100MB/秒。很明显,带宽远远不够了。
关于带宽上限,你需要明白这几点。
实际环境中的传输速率大小,是由服务商所提供的带宽大小,以及网卡、网卡、交换机、路由器所支持的传输速率中的最小值决定的。
内网与外网传输速率是不同的,一般都是内网大于外网。因为服务商所提供的带宽成本更高。
同一个局域网内的节点是公用外网出入口的,所以尽可能的缩小在外网传输的数据,以降低占用“独木桥”外网的空间。
分布式并不直接意味着是“敏捷”了
可能你曾经有过这样的想法,当在规模较大的集中式系统中工作的时候,每次和许多人在一个代码库里提交代码,老是遇到冲突、排队等待上游模块先开发等等。这时你会想,如果改造成分布式系统,这些问题都没了,工作效率高多了。
答案是否定的,在前两篇文章中也有提到一些。拆分后需要做的额外工作如果没做好,可能会导致不是更快,而是更慢。最典型的现象如:
- 发布更麻烦了。原先虽然开发麻烦,但是发布简单啊,哪怕用最原始的方式:编译一次,登上服务器,复制黏贴,秒秒钟搞定。而现在需要发布10个、20个、几十个,再这样操作很明显要把人逼疯。
- 排查问题更难了。原本出了问题,不是在程序就是在数据库。现在还得判断在哪个程序,哪个数据库,是不是要抓狂?
关于这点,你需要秉持着工欲善其事必先利其器的思想。将建设协作相关的辅助性工作与分布式系统同时进行。比如:监控告警系统、配置中心、服务发现,以及批量部署、持续集成,甚至DevOps等。
数据由一份冗余成多份后如何保持一致
这点其实是由于前面提到的网络因素产生的连带效应。
当遇到数据库压力增大,响应开始变慢的时候,你可能会很容易想到,让DBA来做个主从啊。但是,由于网络不可靠、存在延迟、带宽有上限这一系列因素。所以,这个看似只是Copy一下工作,需要我们花大量的精力去解决如何保证在使用不同副本上的数据的时候,都是符合应有的预期的。
关于这点,业界已经研究了几十年,同时得出了许多具有指导意义的理论和思想。你需要充分的理解这些,并且能够识别出合适的运用场景,就可以解决这个问题。这个概念在软件领域被定义为「数据一致性」。
整个系统的不同部分可能是异构的
先来看下「异构」的定义:
形容一个包含或者组成“异构网络”的产品,所谓的“异构网络”通常指不同厂家的产品所组成的网络。
比如,可以是装有不同操作系统的服务器、不同的数据库产品、用不同的语言开发的产品等等。我们所处的整个全球互联网就是“异构”的。
在系统初期,同类技术下的差异往往不太被关注。但是随着分布式系统规模的逐渐扩大,在进入到成熟期的过程中,往往不可避免的会使系统成为异构的,有主动的,也有被动的。
- 被动的。往往需要引入一些新的技术栈或者解决方案来解决当前的问题,因为很多时候不会有资源,也没有必要去“重复造每一个轮子”。
- 主动的。由于规模效应的影响越来越大,某些技术更适合在特定场景下发挥,因此能够降低同等压力下对资源的消耗,就可以明显的降低成本。
关于这点,你要思考如何通过专制的方式进行标准化,来屏蔽这些差异带来的复杂度影响,使得有更多的精力投入到有价值的地方去。专制的特点是“约束”效果,标准化通过专制来进行可以降低许多为了方便而妥协问题。比如每个节点都通过统一的远程调用(RPC)中间件来做“连接”,就将如何连接异构节点的问题交由这个中间件来全权负责,而不是不同的团队各自实现一套。
总结
这次我们深入讲解了分布式系统当中常见的一些“暗流”,而上面列举的这些只能说是最常见的一些典型。在后续的文章中你会跟着我一起发现更多类似的“坑”,让我们一起来寻找避开它们的方式吧。
希望你能时刻保持警惕之心,带着没有“完美方案”的心态在分布式系统中前行。
从下一篇文章起,将正式开始讲解做好分布式系统需要掌握的一个个核心要点,我会力争尽可能的深入浅出,让你能够深刻理解每个要点的作用,如何用好它,以及最佳实践等等。
思考题
你在平时的项目开发中有遇到过哪些“坑”吗?可以在下方评论框给我们留言。
延伸阅读:分布式系统系列文章
第一篇:《拨云见日看什么是分布式系统?》
第二篇:《详解分布式系统本质:“分治”和“冗余”》
别忽视分布式系统这六大“暗流”相关推荐
- Java架构-别忽视分布式系统这六大“暗流”
任何事物都有两面性.你只有了解了分布式系统背后的"暗流涌动"现象是什么,才能避免掉到"坑"里去. 暗流的含义是流动的地下水,是潜伏在"深层" ...
- 在一个成熟的分布式系统中 如何下手做高可用?
对于企业来说,随着规模越来越大,整个系统中存在越来越多的子系统,每个子系统又被多个其他子系统依赖或者依赖于其他子系统.大部分系统在走到这一步的过程中,大概率会发生这样的场景:作为某个子系统的负责人或者 ...
- 跨进程通信,到底用长连接还是短连接
一个完整的软件系统大多数情况下是由多个进程共同协作进行的,哪怕它们在同一台服务器上.所以,进程之间如何进行高效的通信至关重要. 单个应用程序+单个数据库这套基础开发套餐我相信每个人都经历过,甚至在初期 ...
- 细数参加区块链技术及应用峰会(BTA)·中国的六大理由
作为新一代颠覆性的应用,区块链技术已成为当下最火热的话题,全球竞相发展区块链技术.为了进一步的探究区块链技术的本质.发展趋势.行业应用.政策与投资,以及技术背后深藏的区块链思维等,区块链技术及应用峰会 ...
- 千万级流量的大型分布式系统架构设计
本文是学习大型分布式网站架构的技术总结.对架构一个高性能.高可用.可伸缩及可扩展的分布式网站进行了概要性描述,并给出一个架构参考.文中一部分为读书笔记,一部分是个人经验总结,对大型分布式网站架构有较好 ...
- 照抄不翻车:抗住千万流量的大型分布式系统架构设计
作者介绍 烂猪皮,十余年工作经验,曾在 Google 等外企工作过几年,精通 Java.分布式架构.微服务架构以及数据库,最近正在研究大数据以及区块链,希望能突破到更高的境界. 本文是学习大型分布式网 ...
- 干货丨浅析分布式系统(经典长文,值得收藏)
导读 我们常常会听说,某个互联网应用的服务器端系统多么牛逼,比如QQ.微信.淘宝.那么,一个互联网应用的服务器端系统,到底牛逼在什么地方?为什么海量的用户访问,会让一个服务器端系统变得更复杂?本文就是 ...
- 深度报告:芯片设计EDA 2.0时代,三大路径搞定六大挑战
编辑:智东西内参 EDA是Electronic Design Automation的缩写,几十年来成为芯片设计模块.工具.流程的代称.从仿真.综合到版图,从前端到后端,从模拟到数字再到混合设计,以及工 ...
- 分布式系统之CAP理论
一.CAP起源 CAP原本是一个猜想,2000年PODC大会的时候大牛Brewer提出的,他认为在设计一个大规模可扩放的网络服务时候会遇到三个特性:一致性(consistency).可用性(Avail ...
最新文章
- android wear无法启用,android-wear – 无法创建Android虚拟设备,“没有为此目标安装系统映像”...
- python基于百度接口的语音识别_Python基于百度接口的语音识别
- wxWidgets:wxStringBufferLength类用法
- 【论文阅读】Learning Traffic as Images: A Deep Convolutional ... [将交通作为图像学习: 用于大规模交通网络速度预测的深度卷积神经网络](1)
- (十)python3 只需3小时带你轻松入门——模块与包
- 深度学习中的损失函数总结以及Center Loss函数笔记
- linux 实现共享内存同步
- 常用测试用例设计方法
- 周根项《一分钟速算》全集播放amp;下载地址
- HTML5---canvas 指针时钟-clock
- 孙式无极桩站桩要领--林泰年
- 东北大学《传输原理》随堂练习
- js中常用的Math函数方法
- html 图片转换成word,在Word中通过把编辑的图片另存为HTML文件实现转换图片
- 常见测试工具总结:LR、Selenium
- 懒惰程序员的百宝箱:提升工作效率的七大神器
- STM32WB55使用————Zigbee信息收发
- pc使用qq for android,腾讯QQ for Pad Android版
- 计算机控制器安装方法,win7正确安装3D视频控制器的两种方法介绍
- UiPath流程设计器介绍
热门文章
- mysql怎么判断2个时间戳为同一天_php如何判断两个时间戳是一天
- 循环神经网络_小孩都看得懂的循环神经网络
- windows系统vbs脚本 恶搞将系统搞崩 死机 以及解决
- android中自适应布局教程,Android实现自适应正方形GridView
- python海龟图画龙珠_DeepOps的Python小笔记-天池龙珠计划-Python训练营-Task 02:DAY5
- 字符串当id用 转换成json对象
- python多进程编程实例_[python] Python多进程编程技术实例分析
- 调用某个按钮事件_高级UI晋升之触摸事件分发机制(一)
- 中科院分区2020_2020年中科院分区升级版出炉,材料化学物理类一区期刊115本!...
- excel筛选排序从小到大_excel筛选怎么用教程 重复数据多个条件筛选功能教学