如何自动维护全文索引和目录
介绍 (Introduction)
In a previous article entitled Hands on Full-Text Search in SQL Server, we had an overview on the Full-Text feature as it’s implemented in SQL Server. We saw how to create Full-Text indexes and that they were stored inside a container called a Full-Text catalog. We’ve also seen that, by design, this kind of index will generate a fragmentation.
在上一篇题为“在SQL Server中进行全文搜索动手”的文章中 ,我们对在SQL Server中实现的全文功能进行了概述。 我们看到了如何创建全文索引,以及如何将它们存储在称为全文目录的容器中。 我们还看到,根据设计,这种索引将产生碎片。
As a DBA, we should consider the maintenance of these indexes as well as classical indexes. The purpose of this article is to design a stored procedure that will be highly parameterizable and will take care of such maintenance.
作为DBA,我们应该考虑这些索引以及经典索引的维护。 本文的目的是设计一个可高度参数化的存储过程,并将进行此类维护。
问题形式化 (Problem formalization)
Problem summary
问题总结
We have a set of Full-Text enabled databases in which one or more Full-Text indexes are defined. As we know that Full-Text indexes will fragment, so we need to design a solution to maintain these indexes.
我们有一组启用了全文本的数据库,其中定义了一个或多个全文本索引。 我们知道全文索引会碎片化,因此我们需要设计一种解决方案来维护这些索引。
We desire that this solution takes all these indexes into account, no matter the database. We want to parameter the solution as much as possible so that we can easily change its behavior without changing the code.
我们希望无论数据库如何,该解决方案都应考虑所有这些索引。 我们希望尽可能多地参数化解决方案,以便我们可以轻松更改其行为而无需更改代码。
Available options
可用选项
As it’s well explained by Geoff Patterson in his stack exchange ticket entitled “Guidelines for full-text index maintenance”, there are two possible ways to maintain Full-Text indexes:
正如Geoff Patterson在题为“ 全文索引维护准则 ”的堆栈交换票中很好地解释的那样,有两种可能的方法来维护全文索引:
- Using DROP/CREATE pattern (we’ll call it index rebuild): we first drop the index than create it again.
This will remove fragmentation but there are a few cons to this solution:- The application will fail to query these indexes during the operation.
- It will take resources to read the entire table in order to create the index
- If there are unexpected cases faced by the solution, the CREATE statement might fail and we’d eventually be called on our cell phone at 2 AM…
- 使用DROP / CREATE模式(我们将其称为索引重建):首先删除索引,然后再次创建索引。
这将消除碎片,但是此解决方案有一些缺点:- 在操作过程中,应用程序将无法查询这些索引。
- 为了创建索引,将花费资源来读取整个表
- 如果解决方案遇到意外情况,则CREATE语句可能会失败,最终我们将在凌晨2点通过手机致电给我们…
- Using the REBUILD or REORGANIZE options of the ALTER FULLTEXT CATALOG statement. The advantage of this statement should let users query full-text indexes while running, but there is a price: depending on the amount of data that has to be treated, it can take some time to complete and hence introduce some undesired events including:
- Blocking or deadlocks.
- Transaction Log full error
- 使用ALTER FULLTEXT CATALOG语句的REBUILD或REORGANIZE选项。 此语句的优点是可以让用户在运行时查询全文索引,但是这样做有一个代价:根据要处理的数据量,它可能需要一些时间才能完成,因此会引入一些不良事件,包括:
- 阻塞或死锁。
- 事务日志已满错误
According to Microsoft’s documentation about the ALTER FULLTEXT CATALOG statement, the REORGANIZE option should be used as regular maintenance task as it will merge all the fragments created over time for an each Full-Text index to a single “container” (but it’s also a fragment). This operation is called a master merge. It’s represented in the figure below:
根据Microsoft有关ALTER FULLTEXT CATALOG语句的文档 , REORGANIZE选项应作为常规维护任务使用,因为它将随时间推移为每个全文索引创建的所有片段合并到单个“容器”中(但它也是一个片段) )。 此操作称为主合并 。 如下图所示:
At the same time, this option will optimize internal index and catalog structures.
同时,此选项将优化内部索引和目录结构。
Preferences between reorganization and rebuild for classical index also applies to Full-Text catalog. It’s highly preferable to perform reorganizations vs rebuilds because a Full-Text index rebuild will actually read base tables for all the indexes it contains and build a replacement catalog structure. This operation should be taken as last resort, when we made a change catalog option, to the configuration of the Full-Text Search feature like adding stop words, or whenever there is a doubt about the consistency of these indexes.
古典索引的重组和重建之间的首选项也适用于全文目录。 与重组相比,执行重组与重组是非常可取的,因为全文索引重建实际上将读取其包含的所有索引的基表并构建替换目录结构。 当我们进行了更改目录选项,配置全文搜索功能(例如添加停用词)或怀疑这些索引的一致性时,应将此操作作为最后的选择。
No matter the chosen option, the solution designed in this article to maintain our Full-Text indexes might be run:
无论选择哪个选项,都可以运行本文设计的用于维护全文索引的解决方案:
- regularly, like every night or every week, depending on user activity 定期(例如每晚或每周),具体取决于用户活动
- at a low usage period, so that the impact on user experience is minimal. 在较低的使用期限内,因此对用户体验的影响最小。
高级解决方案设计 (High-level solution design)
We will implement a stored procedure that will be able to perform either an index rebuild or catalog reorganization. We will call this stored procedure Maintenance.FullTextIndexOptimize. It will have a parameter called @MaintenanceMode that can be set to either ‘INDEX’ or ‘CATALOG’ in order to choose the way we want to maintain our Full-Text indexes. The default value for this parameter will be ‘CATALOG’.
我们将实现一个存储过程,该过程将能够执行索引重建或目录重组。 我们将这个存储过程称为Maintenance.FullTextIndexOptimize 。 它会有一个名为@MaintenanceMode的参数,可以将其设置为'INDEX'或'CATALOG' ,以选择我们想要维护全文索引的方式。 该参数的默认值为'CATALOG' 。
Plus, we could be able to run our procedure exclusively against a particular database, and for this reason why we will define a parameter called @DatabaseName defaulting to NULL, which means that all user databases have to be considered.
另外,我们可以只对特定数据库运行该过程,因此,为什么要定义一个名为@DatabaseName的参数,默认为NULL ,这意味着必须考虑所有用户数据库。
There is one more thing to discuss before diving into the implementation of this stored procedure: what will be the conditions that will make our stored procedure rebuild an index or reorganize a catalog?
在深入研究此存储过程的实现之前,还有另外一件事需要讨论:将使我们的存储过程重建索引或重新组织目录的条件是什么?
Unfortunately, recommendations from Microsoft about the subject are not easy to find, so we will take the guidelines from Geoff Patterson as basis for our work. These guidelines are about the first option, index rebuild. He says he made experiments running the exact same query using CONTAINSTABLE against a table that was populated over time and not defragmented. He empirically defined that if a Full-Text index suffers of 10% of fragmentation or more, it should be rebuilt for this query to keep an execution time below 500ms.
不幸的是,很难找到Microsoft关于该主题的建议,因此我们将以Geoff Patterson的指南为基础。 这些准则是关于第一种选择的索引重建。 他说,他做了实验,使用CONTAINSTABLE针对随时间推移而未进行碎片整理的表运行完全相同的查询。 他根据经验定义,如果全文索引遭受10%或更多的碎片,则应为该查询重建索引,以将执行时间保持在500毫秒以下。
For that reason, we will define a parameter to our stored procedure that we will call @FragmentationPctThresh4IndexRebuild that will be set to 10 by default.
因此,我们将为存储过程定义一个参数,该参数将调用@ FragmentationPctThresh4IndexRebuild ,默认情况下将其设置为10。
When we consider the size as a ratio, there is always the possible case when these 10% represents a lot of data. For that reason, we will also define a fixed length threshold that we will call @FragmentationMinSizeMb4IndexRebuild. It will empirically be set to 50.
当我们将大小视为比例时,总是有可能这10%代表大量数据。 因此,我们还将定义一个固定长度阈值,我们将其称为@ FragmentationMinSizeMb4IndexRebuild 。 根据经验它将设置为50。
Moreover, we could have a 90% fragmented index of 1 kb. Is it OK to let it remain like that or should we absolutely rebuild it? To me, it’s not that important and that’s the reason why the Maintenance.FullTextIndexOptimize stored procedure will also have a parameter called @MinIndexSizeMb. This parameter will tell the stored procedure not to rebuild indexes with size below its value, which will be 1 by default.
此外,我们可能有90%的1 kb碎片索引。 可以保留它还是可以的,还是我们应该完全重建它? 对我来说,这并不重要,这就是为什么Maintenance.FullTextIndexOptimize存储过程还将具有一个名为@MinIndexSizeMb的参数的原因 。 此参数将告诉存储过程不要重建大小小于其值(默认值为1)的索引。
While Geoff Patterson’s guidelines could be enough, there is another recommendation in this StackExchange question from another senior DBA, Kin, who says that he reorganizes his catalog whenever there are indexes with 30 to 50 fragments. That’s also a good point as we could imagine an index with low fragmentation ratio but high number of fragments. For that reason, we will add our last threshold parameter to the Maintenance.FullTextIndexOptimize stored procedure: @FragmentsCountThresh4IndexRebuild that will be set to 30 by default.
尽管Geoff Patterson的指南可能就足够了,但在另一个StackDB问题中 ,另一位高级DBA Kin 提出了另一项建议,他说,只要有30到50个片段的索引,他都会重新组织目录。 这也是一个好点,因为我们可以想象一个碎片率低但碎片数高的索引。 因此,我们将最后一个阈值参数添加到Maintenance.FullTextIndexOptimize存储过程: @ FragmentsCountThresh4IndexRebuild ,默认情况下将其设置为30。
To sum up, here are the cases when a Full-Text index should be considered for rebuild:
综上所述,在以下情况下,应考虑全文索引进行重建:
- When its size is above 1Mb and is 10% or more fragmented 当其大小大于1Mb并且碎片为10%或更多时
- When its size is above 1Mb and has a fragmented space of 50Mb or more. 当其大小大于1Mb且具有50Mb或更大的碎片空间时。
- When its size is above 1Mb and the index has 30 or more index fragments 当其大小大于1Mb并且索引具有30个或更多索引片段时
This ends up the definition for thresholds to use for Full-Text index rebuild option. We can now consider Full-Text catalog reorganization. We will keep it simple and say that whenever an index could be marked for the rebuild, this reorganization should occur.
这样就定义了用于全文索引重建选项的阈值。 现在,我们可以考虑全文目录重组。 我们将简单地说,只要可以为重建标记索引,就应该进行这种重组。
Now, these specific parameters are well defined, we can add more general parameters, which are:
现在,这些特定的参数已经定义好,我们可以添加更多常规参数,它们是:
- @UseParameterTable, a BIT parameter that tells the stored procedure, when set to 1, to read in a hard-coded parameter table. This option is let for future improvement and won’t be implemented at the moment.
- @UseParameterTable ,一个BIT参数,告诉存储过程(设置为1时)以读取硬编码的参数表。 此选项是为了将来的改进,目前不会实施。
- @WithLog, also a BIT parameter that tells the stored procedure, when set to 1, to log execution in a logging table.
- @WithLog ,也是BIT参数,它告诉存储过程(设置为1时)将执行记录到日志表中。
- @ReportOnly, still a BIT parameter to tells the stored procedure, when set to 1, to only return a report with the list of indexes or catalogs and the action that has to be done. It will be used extensively during development and can be used for monitoring.
- @ReportOnly ,仍然是一个BIT参数,用于告诉存储过程(设置为1时)仅返回包含索引或目录列表以及必须执行的操作的报告。 在开发过程中将广泛使用它,并可以用于监视。
- @Debug, which tells the stored procedure to display debug messages. A value of 0 means no debug message should be shown, a value of 1 will display debug messages and a value of 2 will display all the debug messages when @Debug is set to 1 plus the text of dynamic queries created and used during execution.
- @Debug ,它告诉存储过程显示调试消息。 值为0表示不显示调试消息,值为1时将显示调试消息,值为2时将@Debug设置为1加上执行期间创建和使用的动态查询的文本,将显示所有调试消息。
Now we have discussed about all the parameters that are used to define the Maintenance.FullTextIndexOptimize stored procedure, we can finally have a look at its interface:
现在,我们讨论了用于定义Maintenance.FullTextIndexOptimize存储过程的所有参数,我们终于可以看一下其接口了:
ALTER PROCEDURE [Maintenance].[FullTextIndexOptimize] (@MaintenanceMode VARCHAR(16) = 'CATALOG', @DatabaseName VARCHAR(256) = NULL,@FragmentationPctThresh4IndexRebuild INT = 10,@FragmentationMinSizeMb4IndexRebuild INT = 50,@FragmentsCountThresh4IndexRebuild INT = 30, @MinIndexSizeMb FLOAT = 1.0, @UseParameterTable BIT = 0,@WithLog BIT = 1,@ReportOnly BIT = 0,@Debug SMALLINT = 0
)Here is the high-level algorithm that we will use to implement the body of our stored procedure:
这是用于实现存储过程主体的高级算法:
解决方案实施 (Solution implementation)
In this section, we will review some key elements in the implementation such as its dependencies, the structure of temporary tables we will use and some queries we will use.
在本节中,我们将回顾实现中的一些关键元素,例如其依赖关系,我们将使用的临时表的结构以及我们将使用的一些查询。
An ZIP archive containing all resources to perform Full-Text Index maintenance can be found at the end of this article.
您可以在本文结尾处找到一个ZIP归档文件,其中包含执行全文索引维护的所有资源。
Dependencies
依存关系
In order to implement the [Maintenance].[FullTextIndexOptimize] stored procedure, we will take advantage of following database objects:
为了实现[Maintenance]。[FullTextIndexOptimize]存储过程,我们将利用以下数据库对象:
- [Common].[RunQueryAcrossDatabases] – a stored procedure that takes a T-SQL statement and execute it against a set of databases. It has a parameter @DbName_equals that we can use when use set a value to the @DatabaseName parameter of our FullTextIndexOptimize. It will be used in order to execute the T-SQL query that gets back Full-Text indexes details.
- [Common]。[RunQueryAcrossDatabases] –一种存储过程,采用T-SQL语句并针对一组数据库执行该语句。 它具有一个@DbName_equals参数,当我们使用它时,可以为FullTextIndexOptimize的@DatabaseName参数设置一个值。 它将用于执行返回全文索引详细信息的T-SQL查询。
- [Common].[CommandExecute] and its related table [Common].[CommandLog] – an adapted version of Ola Hallengren’s stored procedure and table with the same name. It will be used to execute and optionally log the action taken against either an index or a catalog.
- [Common]。[CommandExecute]及其相关表[Common]。[CommandLog] – Ola Hallengren的存储过程和具有相同名称的表的改编版本。 它将用于执行和可选地记录针对索引或目录采取的操作。
Temporary tables
临时表
For holding data related to Full-Text index
用于保存与全文索引相关的数据
The temporary table used to store data related to Full-Test indexes is called #FTidx and has been slightly discussed previously. Each record of this table will correspond to a Full-Text index and contain:
用于存储与完全测试索引相关的数据的临时表称为#FTidx,之前已稍作讨论。 该表的每个记录将对应一个全文本索引,并包含:
- The name of its corresponding catalog 对应目录的名称
- The number of index fragments 索引片段数
- The size of the fragmentation expressed in Mb 片段大小以Mb表示
- The ratio between fragmented space to total space expressed in percentage. 零散空间与总空间之间的比率以百分比表示。
- Whether a maintenance should be performed or not on that index 是否应该对该索引执行维护
- Whether the maintenance for that index succeeded or not 该索引的维护是否成功
- If the maintenance did not succeed, the error message that the FullTextIndexOptimize stored procedure got back during execution.
- 如果维护未成功, 则会在执行期间返回FullTextIndexOptimize存储过程的错误消息。
This means that the table has following creation statement:
这意味着该表具有以下创建语句:
CREATE TABLE #FTidx (EntryId INT IDENTITY(1,1) NOT NULL PRIMARY KEY,DatabaseName VARCHAR(256) NOT NULL,CatalogId INT NOT NULL,CatalogName VARCHAR(256) NOT NULL,BaseObjectId INT,BaseObjectName VARCHAR(1024),BaseIndexId INT,TotalSizeMb FLOAT NOT NULL,FragmentsCount INT,LargestFragmentSizeMb FLOAT,FragmentationSpaceMb FLOAT,FragmentationPct FLOAT,MarkedForIndexMaintenance BIT DEFAULT 0,StatementForDrop AS 'USE ' + QUOTENAME(DatabaseName) + ';' + CHAR(13) + CHAR(10) +'DROP FULLTEXT INDEX ON ' + BaseObjectName + ';',MaintenanceOutcome VARCHAR(32),MaintenanceLog VARCHAR(MAX)
);For holding data related to Full-Text catalogs
用于保存与全文目录有关的数据
While first this temporary table will be created no matter the value of the @MaintenanceMode parameter, the following table will only exist whenever the value for this parameter is CATALOG.
尽管无论@MaintenanceMode参数的值如何,都将首先创建此临时表,但仅当此参数的值为CATALOG时,才会存在下表。
It will store information about catalogs we can find in #FTidx temporary table. For each one, we will have the following columns:
它将存储有关在#FTidx临时表中可以找到的目录的信息。 对于每一行,我们将有以下几列:
- MarkedForCatalogMaintenance, which set to 1 means we need to reorganize catalog
- MarkedForCatalogMaintenance ,设置为1表示我们需要重新组织目录
- MaintenanceOutcome to tell whether the maintenance was successful or not
- 维护结果告知维护是否成功
- MaintenanceLog to keep track of error messages when the catalog maintenance did not succeed.
- 当目录维护失败时,使用MaintenanceLog跟踪错误消息。
Its creation statement is:
其创建语句为:
CREATE #FTcatalog (RecordId INT IDENTITY(1,1) NOT NULL PRIMARY KEY,DatabaseName VARCHAR(256) NOT NULL,CatalogName VARCHAR(256) NOT NULL,CatalogId INT,BaseObjectsCount INT,IndexesNeedingMaintenance INT,TotalSizeMb FLOAT,TotalFragmentsCount INT,TotalFragmentationSpaceMb FLOAT,MarkedForCatalogMaintenance BIT DEFAULT 0,MaintenanceOutcome VARCHAR(32),MaintenanceLog VARCHAR(MAX)
);Query to get back Full-Text index details
查询以获取全文索引详细信息
We will use an adapted version of the query discussed in the article “Hands on Full-Text Search in SQL Server”. As you may notice, this query will insert results into #FTidx temporary table.
我们将使用文章“ 在SQL Server中进行全文搜索动手 ”中讨论的查询的改编版本。 您可能会注意到,此查询会将结果插入#FTidx临时表中。
WITH FragmentationDetails
AS (SELECT table_id,COUNT(*) AS FragmentsCount,CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS IndexSizeMb,CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mbFROM sys.fulltext_index_fragmentsGROUP BY table_id
)
INSERT INTO #FTidx (DatabaseName,CatalogId,CatalogName,BaseObjectId,BaseObjectName,BaseIndexId,TotalSizeMb,FragmentsCount,LargestFragmentSizeMb,FragmentationSpaceMb,FragmentationPct
)
SELECT DB_NAME() AS DatabaseName,ftc.fulltext_catalog_id AS CatalogId, ftc.[name] AS CatalogName, fti.object_id AS BaseObjectId, QUOTENAME(OBJECT_SCHEMA_NAME(fti.object_id)) + '.' + QUOTENAME(OBJECT_NAME(fti.object_id)) AS BaseObjectName,unique_index_id,f.IndexSizeMb AS IndexSizeMb, f.FragmentsCount AS FragmentsCount, f.largest_fragment_mb AS IndexLargestFragmentMb,f.IndexSizeMb - f.largest_fragment_mb AS IndexFragmentationSpaceMb,CASEWHEN f.IndexSizeMb = 0 THEN 0ELSE 100.0 * (f.IndexSizeMb - f.largest_fragment_mb) / f.IndexSizeMbEND AS IndexFragmentationPct
FROM sys.fulltext_catalogs ftc
JOIN sys.fulltext_indexes fti
ON fti.fulltext_catalog_id = ftc.fulltext_catalog_id
JOIN FragmentationDetails fON f.table_id = fti.object_id
;This body of this query will be put in a variable called @tsql in the stored procedure then executed with [Common].[RunQueryAcrossDatabases] stored procedure discussed above.
该查询的主体将放置在存储过程中的@tsql变量中,然后使用上述[Common]。[RunQueryAcrossDatabases]存储过程执行。
Generating CREATE FULLTEXT INDEX statements
生成CREATE FULLTEXT INDEX语句
Now we have a query that allows us to get back information about existing Full-Text indexes into a temporary table called #FTidx, we could start a WHILE loop on the records of that table and try to generate the creation statement for each of them.
现在,我们有了一个查询,该查询使我们能够将有关现有全文索引的信息取回到名为#FTidx的临时表中,我们可以对该表的记录启动WHILE循环,并尝试为它们中的每一个生成创建语句。
If we take a look at the grammatical definition of the CREATE FULLTEXT INDEX statement, we can see what data we need to extract from database:
如果我们看一下CREATE FULLTEXT INDEX语句的语法定义 ,我们可以看到我们需要从数据库中提取哪些数据:
CREATE FULLTEXT INDEX ON table_name [ ( { column_name [ TYPE COLUMN type_column_name ] [ LANGUAGE language_term ] [ STATISTICAL_SEMANTICS ] } [ ,...n] ) ] KEY INDEX index_name [ ON <catalog_filegroup_option> ] [ WITH [ ( ] <with_option> [ ,...n] [ ) ] ]
[;]Amongst them, include:
其中包括:
- The name of the table on which the index is built 建立索引的表的名称
- The list of columns with some information. For instance, the language used in particular column. 具有一些信息的列的列表。 例如,特定列中使用的语言。
- The name of the primary key index of the table 表的主键索引的名称
- The name of the Full-Text catalog 全文目录的名称
Note
注意
In the version we will review now, some of the options of the CREATE FULLTEXT INDEX will remain to its default value like FILEGROUP settings. Feel free to modify the proposed solution if you need it.
在我们现在将审查的版本中, CREATE FULLTEXT INDEX的某些选项将保持其默认值,例如FILEGROUP设置。 如果需要,可以随意修改建议的解决方案。
So, now we know what we need to look for, let’s build a query that generates the statement to recreate a Full-Text index. The first part of the statement is pretty straight forwards as we already have everything stored in #FTidx temporary table:
因此,现在我们知道需要查找的内容,让我们构建一个查询,该查询生成用于重新创建全文本索引的语句。 该语句的第一部分非常简单,因为我们已经将所有内容存储在#FTidx临时表中:
SET @Statement4Create = 'USE ' + QUOTENAME(@CurDbName) + ';' + @LineFeed +'CREATE FULLTEXT INDEX ON ' + @CurObjectName + '(' + @LineFeed ;Where @CurDbName and @CurObjectName variables are set with the values from a record of #FTidx.
其中@CurDbName和@CurObjectName变量是使用#FTidx记录中的值设置的。
Now, we have to get back the list of columns which are used in a given index. To do so, we will query a set of system views and tables:
现在,我们必须获取给定索引中使用的列的列表。 为此,我们将查询一组系统视图和表:
- sys.fulltext_index_columns sys.fulltext_index_columns
- sys.columns (twice: once for the column on which the Full-Text index is based and once for the column that tells SQL Server what kind of document is stored in the first column) sys.columns (两次:一次用于全文索引所基于的列,一次用于告诉SQL Server第一列中存储哪种类型的文档的列)
We will use a dynamic version of following query:
我们将使用以下查询的动态版本:
--USE <YourDb>;
DECLARE @tsql NVARCHAR(MAX);
DECLARE @LineFeed CHAR(2) = CHAR(13) + CHAR(10);SELECT @tsql = CASE WHEN LEN(@tsql) = 0 OR @tsql IS NULLTHEN '' ELSE @tsql + ',' + @LineFeed END + ' ' + c.Name + ' TYPE COLUMN ' + refc.name + ' ' +' Language ' + CONVERT(VARCHAR(10),language_id)+' ' +CASE WHEN fic.statistical_semantics = 1 THEN 'STATISTICAL_SEMANTICS ' ELSE '' END
FROM sys.fulltext_index_columns fic
INNER JOIN sys.columns as c
ON c.object_id = fic.object_id
AND c.column_id = fic.column_id
INNER JOIN sys.columns as refc
ON refc.object_id = fic.object_id
AND refc.column_id = fic.type_column_id
WHERE fic.object_id = @CurObjectId-- SELECT @tsqlHere is a sample results for a given @CurObjectId:
这是给定@CurObjectId的示例结果:
Once it’s done for all columns, we can close the parenthesis and get back information about which key index has to be used and some options about the Full-Text index. We do so use a modified version of following script:
完成所有列后,我们可以关闭括号并获取有关必须使用哪个键索引以及有关全文索引的某些选项的信息。 我们使用以下脚本的修改版本:
--USE <YourDb>;
DECLARE @tsql NVARCHAR(MAX);
DECLARE @LineFeed CHAR(2) = CHAR(13) + CHAR(10);SELECT @tsql = 'KEY INDEX ' + idx.Name + @LineFeed +'ON ' + QUOTENAME(@CatalogName) + @LineFeed +'WITH CHANGE_TRACKING ' + fi.change_tracking_state_desc + @LineFeed +';' + @LineFeed
FROM sys.indexes idx
JOIN sys.fulltext_indexes fi
ON idx.object_id = fi.object_id
WHERE idx.object_id = @ObjectId
AND index_id = @IndexId
;SELECT @tsql ;And here is a sample of generated text:
这是生成的文本的示例:
Putting everything together, we’ll get a statement like following one:
将所有内容放在一起,我们将得到如下声明:
USE [Test_FT_Maintenance];
CREATE FULLTEXT INDEX ON [dbo].[DM_OBJECT]( OBJ_CONTENT TYPE COLUMN OBJ_IDX_DOCTYPE Language 0
)
KEY INDEX PK_DM_OBJECT ON [DM_FT]
WITH CHANGE_TRACKING AUTO
;Scheduling the maintenance with SQL Server Agent
使用SQL Server代理计划维护
Now we have a stored procedure that can be run for maintaining our Full-Text indexes for all our databases, it’s time to schedule it. And what’s best suited for that than the famous SQL Server Agent… Here are the steps you can follow to generate a SQL Server Agent Job called “[Maintenance] FullTextIndexOptimize”:
现在,我们可以运行一个存储过程,以维护我们所有数据库的全文索引,是时候对其进行调度了。 与著名SQL Server代理相比,最适合的方法是……您可以按照以下步骤生成名为“ [Maintenance] FullTextIndexOptimize”SQL Server代理作业:
- Connect to a SQL Server instance 连接到SQL Server实例
Go down to SQL Server Agent node, right-click and follow the path depicted in next screen capture:
转到“ SQL Server代理”节点,右键单击并遵循下一个屏幕截图中描述的路径:

Fill in general information then go to Steps
填写一般信息,然后转到步骤
In Steps page, click on “New” button
在“步骤”页面中,单击“新建”按钮
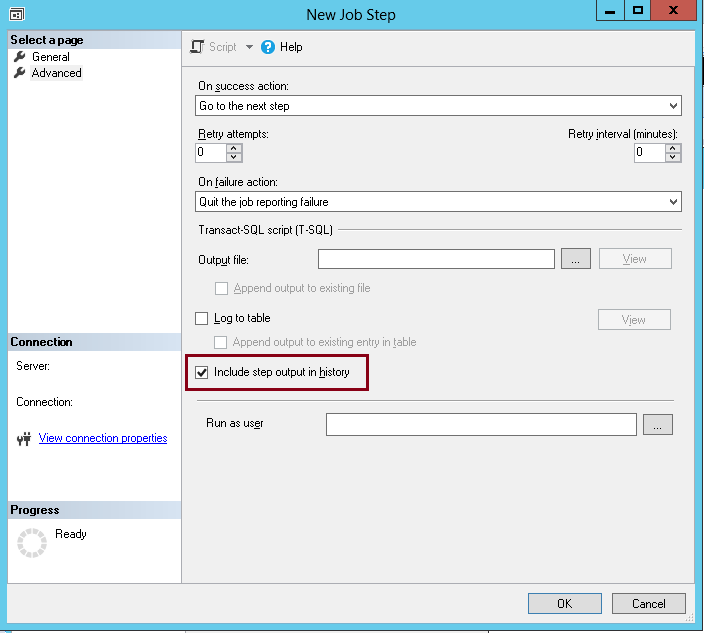
Fill fields in Task creation dialog. Don’t forget to select the “Include step output in history”. Once it’s done, click on the “OK” button
在“任务创建”对话框中填写字段。 不要忘记选择“在历史记录中包括步骤输出”。 完成后,单击“确定”按钮
- Add a schedule according to your prerequisites 根据您的先决条件添加时间表
Don’t forget to setup notifications for this job
别忘了为此作业设置通知
- Click OK and you are done 单击确定,完成
Previous article in this series
本系列的上一篇文章
- Hands on Full-Text Search in SQL Server在SQL Server中进行全文本搜索
资料下载 (Downloads)
- All scripts bundle 所有脚本包
翻译自: https://www.sqlshack.com/automatically-maintain-full-text-indexes-catalogs/
如何自动维护全文索引和目录相关推荐
- 让Win让Win XP自动维护系统 自动维护系统
Windows XP的日常维护是件既耗时又无聊的事情,如果Windows XP能够聪明一点,进行自动维护就好了.下面,就为大家介绍一种通过.inf文件让Windows XP进行自动维护的技巧,自动维护 ...
- 通过inf文件让Win XP实现自动维护 [可实现系统定时任务]
Windows XP的日常维护是件既耗时又无聊的事情,如果Windows XP能够聪明一点,进行自动维护就好了.下面,就为大家介绍一种通过.inf文件让Windows XP进行自动维护的技巧,自动维护 ...
- 自动维护Windows XP另辟蹊径
自动维护Windows XP另辟蹊径 作者: game.19xz 来源: 19xz.com Windows XP的日常维护是件既耗时又无聊的事情,如果Windows XP能够聪明一点,进行自动维护就好 ...
- markdown自动生成侧边栏TOC /目录
markdown自动生成侧边栏TOC /目录 模板地址 : https://github.com/huyande/MarkdownTemplate.git
- 分区表自动维护 mysql_Oracle 10g分区表的自动维护
oracle 10g分区表不支持自动化管理,一般都要手动创建分区,手动删除.今天给大家带来了一个自动化管理表空间的脚本. Oracle 10g分区表不支持自动化管理,一般都要手动创建分区,,手动删除. ...
- java前端目录_[Java教程]前端那点事儿——Tocify自动生成文档目录
[Java教程]前端那点事儿--Tocify自动生成文档目录 0 2016-06-29 22:00:07 今天偶然间看到文档服务器有一个动态目录功能,点击目录能跳转到指定的位置:窗口滑动也能自动更新目 ...
- Log4Net日志分类和自动维护
背景 在程序中,我们调试运行时信息,Log4Net是一个不错的解决方案.不知道是我用的不好,用到最后反而都不想看日志了.原因是因为我n个功能使用的默认的Logger来记录日志,这样以来,所有功能记录的 ...
- oracle 11g中的自动维护任务管理
因为人员紧缺,最近又忙着去搞性能优化的事情,有时候真的是不想再搞这个事情,只是没办法,我当前的绩效几乎取决于这个项目的最终成绩,所以不管是人的事还是事的事,都得去让他顺利推进. 前段时间发生还有几台服 ...
- ORACLE11G自动维护任务简析
ORACLE 11G 自动维护任务: 自动维护任务是一种按规则自动启动的数据库维护操作任务.比如自动收集为查询优化器使用的统计信息.自动维护任务按维护窗口自动运行.所谓自动维护窗口是按照预定义的间 ...
最新文章
- 数据结构与算法之字符凭拼接最低字典序和数据流中取中位数
- leetcode337. 打家劫舍 III(dfs)
- 阿里云centos 安装和配置 DokuWiki
- Vue SSR(Vue2 + Koa2 + Webpack4)配置指南
- 腾讯内测全新 Tim 3.0,支持微信登录;滴滴顺风车上线夜间服务;Angular 9.1 发布 | 极客头条...
- 李开复对谈硅谷传奇:杨致远敦促AI交产品,马尔科夫说无人车3年没戏
- 《C++编程——数据结构与程序设计方法》程序范例:影碟店(源代码)
- 《Kafka权威指南》读书笔记4 Kafka消费者
- linux下安装yum步骤
- Neo4j下载安装及使用
- 虚拟服务器软件 海光,海光校园虚拟服务器管理软件技术参数
- outlook统一签名模版设置
- FIBOS社区发起人 响马:一个“极客硬核老炮儿”是怎样的?
- 第三(关于set、file、args)
- C语言编程--根据麦克劳林公式计算任意角的正弦余弦
- NAOqi.Net(C#)MotionProxy类的一些函数用法(一)
- 这是一份普通的cpp答卷,可能有错
- 汇编-ASCⅡ码转二进制码
- WPF设备无关单位(DIU)
- 周期函数的导数周期(含证明)