聚类分析(三)Mini Batch KMeans算法
在当前大数据的背景下,工程师们往往为了追求更短的计算时间,不得不在一定程度上减少算法本身的计算精度,我说的是在一定程度上,所以肯定不能只追求速度而不顾其它。在KMeans聚类中,为了降低计算时间,KMeans算法的变种Mini Batch KMeans算法应运而生。
Mini Batch KMeans算法是一种能尽量保持聚类准确性下但能大幅度降低计算时间的聚类模型,采用小批量的数据子集减少计算时间,同时仍试图优化目标函数,这里所谓的Mini Batch是指每次训练算法时随机抽取的数据子集,采用这些随机选取的数据进行训练,大大的减少了计算的时间,减少的KMeans算法的收敛时间,但要比标准算法略差一点,建议当样本量大于一万做聚类时,就需要考虑选用Mini Batch KMeans算法。
这种对时间优化的思路不仅应用在KMeans聚类,还广泛应用于梯度下降、深度网络等机器学习和深度学习算法。
在sklearn.cluster 中MiniBatchKMeans与KMeans方法的使用基本是一样的,为了便于比较,继续使用与我上一篇博客同样的数据集。
在MiniBatchKMeans中可配置的参数如下:
class sklearn.cluster.MiniBatchKMeans(n_clusters=8, init='kmeans++',max_iter=100, batch_size=100, verbose=0, compute_labels=True,random_state=None, tol=0.0, max_no_improvement=10, init_size=None,n_init=3, reassignment_ratio=0.01)通过参数batch_size可以设置Mini Batch的大小,这里默认值为100.
导入包
from sklearn.cluster import MiniBatchKMeans
import demo1
import numpy as np
import matplotlib.pyplot as plt画出数据的散点图和聚类中心的位置
def draw_pic(data_list):# 画出散点图for x in range(len(data_list)):plt.scatter(data_list[x][0], data_list[x][1], s=30, c='b', marker='.')def draw_cluster_centers(centers_mat):# 画出聚类中心for k in range(len(centers_mat)):plt.scatter(centers_mat[k][0], centers_mat[k][1], s=60, c='r', marker='D')执行程序,进行Mini Batch KMeans聚类,为了方便,对数据集的处理我调用了我上一篇博客中的数据矩阵处理函数。
if __name__ == '__main__':data_Set = demo1.file2matrix('testSet.txt', '\t')draw_pic(data_Set)k = 4 # 确定聚类中心的数目# 执行KMeans算法minibatchkmeans = MiniBatchKMeans(n_clusters=k, batch_size=50)minibatchkmeans.fit(np.mat(data_Set))draw_cluster_centers(minibatchkmeans.cluster_centers_)plt.show()最终得出结果:
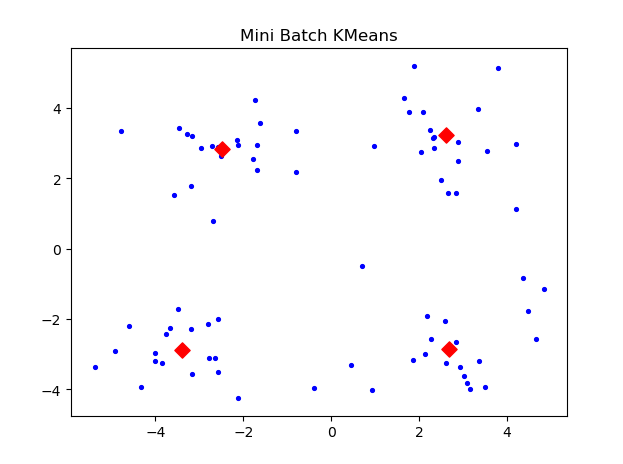
从结果来看,Mini Batch KMeans算法的聚类效果还是不错的,但我觉得这并不能说明什么问题,因为我的数据量太少了,以后有时间把爬虫技术弄熟练,再做一个数据量大的吧。
转载于:https://my.oschina.net/u/3888421/blog/2209122
聚类分析(三)Mini Batch KMeans算法相关推荐
- 机器学习算法之聚类算法拓展:Mini Batch K-Means算法
言归正传,先介绍一下 Mini Batch K-Means算法 Mini Batch K-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次训 练使用的数据集是在训练算法的时 ...
- scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
====================================================================== 本系列博客主要参考 Scikit-Learn 官方网站上的 ...
- 06 聚类算法 - 代码案例二 - K-Means算法和Mini Batch K-Means算法比较
03 聚类算法 - K-means聚类 04 聚类算法 - 代码案例一 - K-means聚类 05 聚类算法 - 二分K-Means.K-Means++.K-Means||.Canopy.Mini ...
- 机器学习算法之聚类算法拓展:K-Means和Mini Batch K-Means算法效果评估
聚类算法的衡量指标 混淆矩阵 均一性 完整性 V-measure 调整兰德系数(ARI) 调整互信息(AMI) 轮廓系数(Silhouette) import time import numpy as ...
- k中心点聚类算法伪代码_聚类算法之——K-Means、Canopy、Mini Batch K-Means
K-Means||算法 K-Means||算法是为了解决K-Means++算法缺点而产生的一种算法: 主要思路是改变每次遍历时候的取样规则,并非按照K-Means++算法每次遍历只获取一个样本,而是每 ...
- 【机器学习】无监督学习--(聚类)Mini Batch K-Means
1. Mini Batch K-Means概述 Mini-Batch-K-MEANS算法是K-Means算法的变种,采用小批次量的数据子集减少计算时间.这里所谓的小批量是指每次训练算法时所随机抽取的数 ...
- 数据挖掘-聚类分析(Python实现K-Means算法)
概念: 聚类分析(cluster analysis ):是一组将研究对象分为相对同质的群组(clusters)的统计分析技术.聚类分析也叫分类分析,或者数值分类.聚类的输入是一组未被标记的样本,聚类根 ...
- 机器学习sklearn19.0聚类算法——Kmeans算法
一.关于聚类及相似度.距离的知识点 二.k-means算法思想与流程 三.sklearn中对于kmeans算法的参数 四.代码示例以及应用的知识点简介 (1)make_blobs:聚类数据生成器 sk ...
- 机器学习:K-means算法基本原理及其变种
目录 1.1.K-means起源 1.2.K-means的意义 1.3.K-means的思想 1.4.K-means的算法流程 1.5.K-means的算法优缺点 2.1.轮廓系数 2.2.k值的确定 ...
最新文章
- 博客转向 github pages
- 终于有了属于自己的家,哈哈,很高兴~~
- I春秋——web Write up(三)
- AIX系统CPU监控与评估
- 联想u盘linux安装教程,联想笔记本用U盘安装 winXP系统教程
- 《流浪地球》 电影全集
- rfid 标签内存_智能仓库之RFID仓库管理中的条形码与电子标签应用-RFID仓库管理功能与特点-新导智能...
- 【转载】中国煤层气资源量
- 【原】常见CSS3属性对iosandroidwinphone的支持
- 盘点微软出品的神级小工具:无比实用~
- 计算机信息检索技术实质上是逻辑运算,在信息检索的实际过程中,如需要扩大检索范围时,如何调整检索策略...
- 麻省理工学院公开课:计算机科学及编程导论习题4下
- 同款蓝牙耳机为什么会串联_为什么蓝牙耳机不能两个同时使用
- linux vi把一个文件中的内容复制到另一个文件,vim - 将内容从一个文件复制并粘贴到vi中的另一个文件...
- 为什么要研究引起潜在大流行病的病原体?
- PostgreSQL在Linux和Windows安装和入门基础教程
- P2071 座位安排
- html 列表设置nth,html – 使用nth-child进行CSS编号
- java中enhancer试什么_Java Enhancer類代碼示例
- ubuntu16.04、2080Ti、Caffe从0开始安装