Amazon Personalize:帮助释放精益数字业务的高级推荐解决方案的功能
By Gerd Wittchen
盖德·维琴
推荐解决方案的动机 (Motivation for recommendation solutions)
Rapid changes in customer behaviour requires businesses to adapt at an ever increasing pace. The recent changes to our work and personal life has forced entire nations to work remotely and do all non essential shopping online. With every challenge in business there is opportunity on the other side.
客户行为的快速变化要求企业以不断提高的速度适应。 我们工作和个人生活的最新变化迫使整个国家进行远程工作,并进行所有非必需的在线购物。 面对业务中的每一项挑战,另一边都有机会。
According to a techcrunch.com report, US e-commerce sales went up by 49% in April, in comparison with the baseline period in early March. This subsequently led to a flood of digital campaigns and initiatives fighting for attention.
根据techcrunch.com的报告,与3月初的基准时期相比,4月份美国的电子商务销售额增长了49%。 随后导致大量的数字运动和倡议在争取关注。
We think that businesses who want to stay relevant in such a competitive environment must understand how to best add value to their customers and more importantly, respect their time.
我们认为,想要在竞争激烈的环境中保持联系的企业必须了解如何最大程度地为其客户增加价值,更重要的是,尊重他们的时间。
In a rapidly changing environment it is critical for an organisation to develop situational awareness, which feeds into a business adjustment process. The adjustment process in this context, is the time an organisation or business requires to react to change in their underlying market condition.
在瞬息万变的环境中,对于组织而言,发展态势感知至关重要,这会影响到业务调整流程。 在这种情况下,调整过程是组织或企业需要对其基本市场状况的变化做出React的时间。
One example of an adjustment process framework is the OODA Loop (Observe, Orient, Decide, Act) which was developed by John Boyd — a military strategist whose theories are now widely applied in law enforcement and business.
调整过程框架的一个例子是OODA循环 (观察,东方,决定,行为),该理论是由军事战略家约翰·博伊德(John Boyd)开发的,其理论现已广泛应用于执法和商业领域。
Boyd suggests that each and every one of our decision-making processes run in a recurring cycle of Observe — Orient — Decide — Act. An individual or business who is capable of operating in this cycle quickly — observing, orientating and deciding rapidly to reach an action decision with ease — is able to ‘get inside’ another’s cycle to gain a strategic advantage.
博伊德建议,我们的每个决策过程都应遵循“观察-东方-决定-行动”的周期性循环。 能够快速地在此周期中进行操作的个人或企业-观察,定向和快速做出轻松地做出行动决定的决定-能够“融入”另一个人的周期中以获得战略优势。
面向企业的OODA Loop (OODA Loop for businesses)
观察 (Observe)
The entire process begins with the observation of data from the world, environment and situation. Situational awareness for a business means to establish a baseline for their customers through methods such as market analysis and research.
整个过程始于观察来自世界,环境和情况的数据。 企业的态势感知意味着通过市场分析和研究等方法为客户建立基准。
东方 (Orient)
This is the moment that we take in all the information garnered during the observation phase and begin to process it. Typically in the form of dashboards and reports to support the business analysis. Within larger organisations, this information tends to be distributed across different systems. Here we typically see the biggest divergence on how quick a business can produce those reports and metrics to keep up with trend changes.
这是我们吸收在观察阶段获得的所有信息并开始处理它的时刻。 通常以仪表板和报告的形式来支持业务分析。 在较大的组织中,此信息往往分布在不同的系统中。 在这里,我们通常会看到最大的差异,即企业能够多快地生成这些报告和指标以跟上趋势变化的步伐。
决定 (Decide)
Decide will be the outcome of — and is entirely reliant on — your orienting phase. If your orientation is lacking information or is using inaccurate information, a potential decision might be ineffective or worse working against its purpose. The idea here is to derive an hypothesis on how to best react to the situation. Knowing the likely outcomes of certain practices and decisions can have overlap onto others. It is important that the outcomes of your previous experience and your orienting phase gets you as close to an accurate prediction of your future actions and impacts as possible.
决定将是您的定向阶段的结果,并且完全取决于该阶段。 如果您的方向缺少信息或使用的信息不正确,则潜在的决策可能无效或不利于达成目标。 这里的想法是得出关于如何对情况做出最佳React的假设。 知道某些做法和决定的可能结果可能与其他做法重叠。 重要的是,您先前的经验和导向阶段的结果将使您尽可能地准确地预测未来的行为和影响。
法案 (Act)
Act is the final part of the OODA Loop. However, as it is a cycle, any information which you gather from the results of your actions can be used to restart the analytical process. This would include making changes to your business strategy and starting the observation phase again.
Act是OODA Loop的最后一部分。 但是,由于这是一个循环,您从操作结果中收集的任何信息都可以用于重新启动分析过程。 这将包括更改您的业务策略并再次开始观察阶段。
加快循环 (Speeding up the loop)
For businesses, an efficient loop can allow them to gain a competitive advantage over others in the market. If you’re thinking faster than them, you will be better than them.
对于企业而言,有效的循环可以使他们获得与市场上其他企业相比的竞争优势。 如果您比他们想的要快,那您将比他们更好。
If organisations are automating the collection and analysis of observations, it allows them to build powerful capability to surface relevant products/content to customers. This makes recommender systems a key component of all successful online business. From e-commerce, streaming and news to online advertising, recommender systems are today’s automated OODA loops.
如果组织要自动收集和分析观察结果,则可以使组织建立强大的功能来向客户展示相关产品/内容。 这使得推荐系统成为所有成功在线业务的关键组成部分。 从电子商务,流媒体和新闻到在线广告,推荐系统是当今的自动化OODA循环。
推荐系统 (Recommender systems)
On a general level, recommender systems are algorithms that predict relevant items to users.
一般而言,推荐系统是一种可以预测与用户相关项目的算法。
Recommender systems are critical for certain online industries and are worth high rewards to large corporations such a netflix.
推荐系统对于某些在线行业至关重要,对于诸如netflix这样的大公司来说,值得推荐。
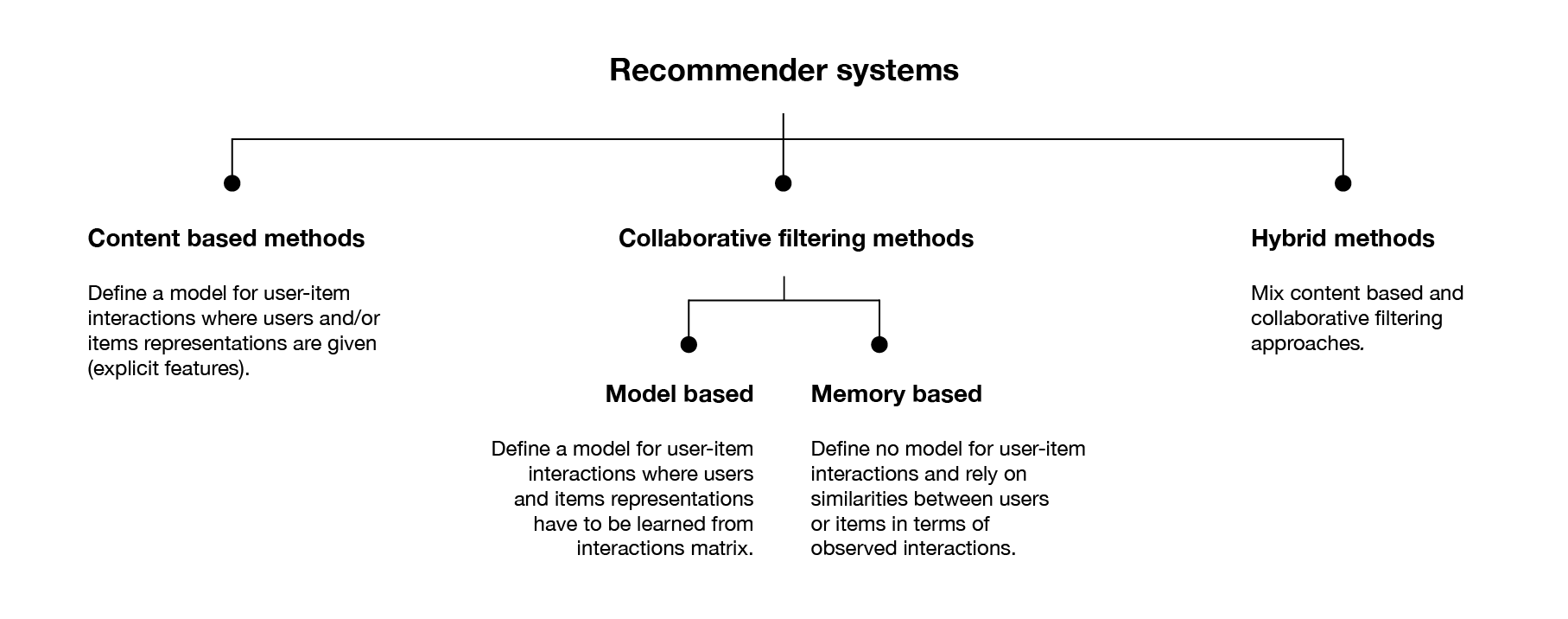
On a high level, there are two classes of recommender systems — collaborative filtering methods and content based methods.
在较高级别上,有两类推荐系统:协作过滤方法和基于内容的方法。
协同过滤方法 (Collaborative filtering methods)
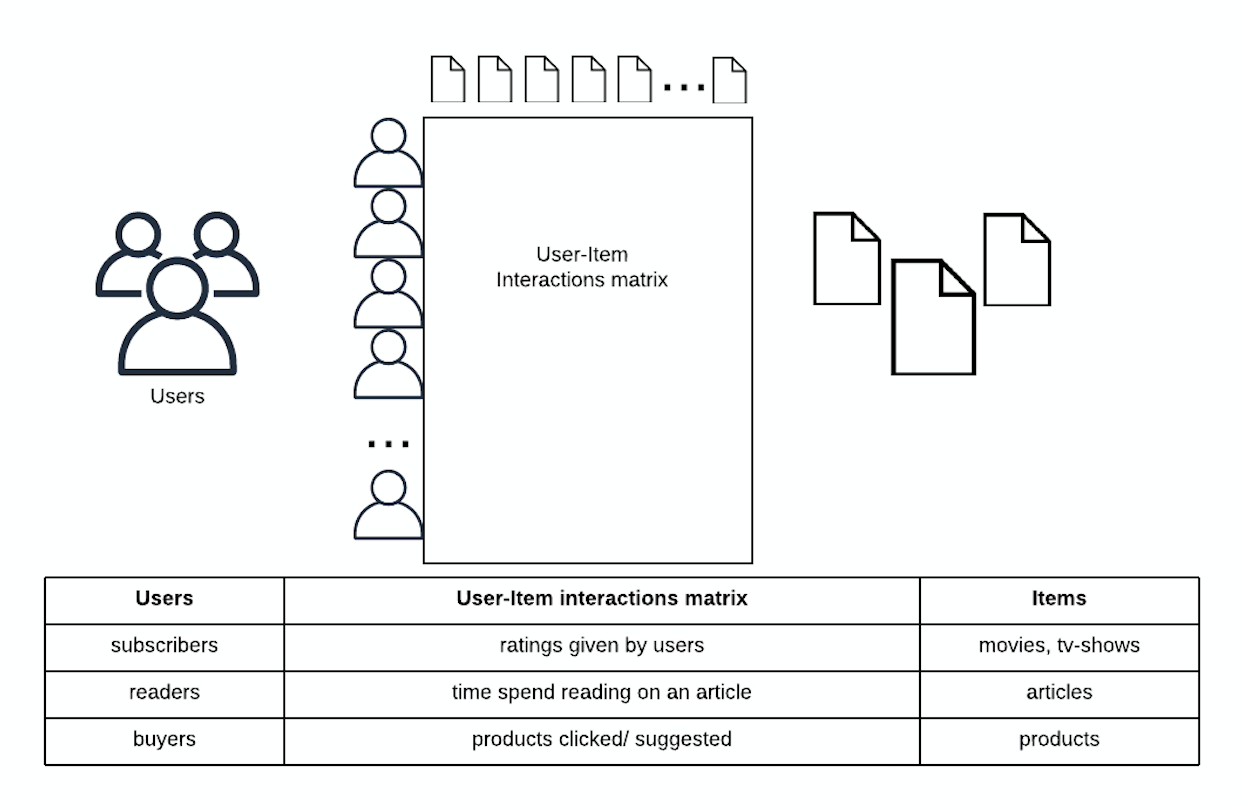
Collaborative filtering methods for recommender systems are based solely on the past interactions recorded between the users and items in order to produce new recommendations. Those interactions are typically stored in a user-item interactions matrix.
推荐系统的协作过滤方法仅基于用户和项目之间记录的过去交互,才能产生新的推荐。 这些交互通常存储在用户项交互矩阵中。
The main idea is that past user-item interactions are sufficient to detect similar users and/or similar items and make predictions based on these estimated relationships.
主要思想是,过去的用户-项目交互足以检测相似的用户和/或相似的项目,并基于这些估计的关系进行预测。
Collaborative filtering can be distinguished into two main categories — memory based approach and model based approach.
协作过滤可以分为两大类:基于内存的方法和基于模型的方法。
基于内存的方法 (Memory based approach)
Memory basedcollaborative filtering again splits into two subcategories — user-to-user or item-to-item — based recommendations.
基于内存的协作筛选再次分为基于用户对用户或项目对项目的两个子类别。
User-to-user collaborative filtering: Users who are similar to you also liked…
用户到用户的协作过滤:与您相似的用户也喜欢…
Item-to-item collaborative filtering: Users who liked this item also liked…
逐项协作过滤:喜欢此项目的用户也喜欢…
The main idea is that we are not learning any parameter using gradient descent (or any other optimisation algorithm). Similar users or items are calculated only by using distance metrics such as Cosine Similarity or Pearson Correlation Coefficients, which are based on arithmetic operations.
主要思想是我们不会使用梯度下降(或任何其他优化算法)来学习任何参数。 仅通过使用基于算术运算的距离度量(例如余弦相似度或Pearson相关系数)来计算相似的用户或项目。
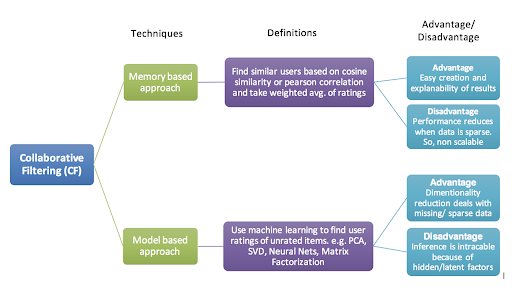
基于模型的方法 (Model based approach)
Model based collaborative filtering is developed using machine learning algorithms to build a representation of the information. Predications are then generated using the trained models, rather than distance metrics used in the memory based approach.
使用机器学习算法开发基于模型的协作过滤,以构建信息的表示形式。 然后使用经过训练的模型而不是基于内存的方法中使用的距离度量来生成预测。
The main advantage of collaborative filtering approaches is that they require no information about users or items, so they can be used in many situations. These algorithms improve with the number of interactions recorded over time (increased dataset).
协作过滤方法的主要优点是它们不需要有关用户或项目的信息,因此可以在许多情况下使用。 随着时间的推移,这些算法随着交互记录的数量而增加(数据集增加)。
The biggest disadvantage of collaborative filtering is that they only learn from past data points and hence suffer from the cold start problem. It’s impossible to recommend anything new (new content, new items) and challenging for items with few user interactions. In those cases, the recommender systems typically use fallback strategies such as random recommendations or most popular items.
协作过滤的最大缺点是,它们只能从过去的数据点中学习,因此会遇到冷启动问题 。 对于几乎没有用户交互的项目,不可能推荐新的东西(新内容,新项目),也很难提出建议。 在那些情况下,推荐系统通常使用备用策略,例如随机推荐或最受欢迎的商品。
基于内容的方法 (Content based methods)
On the other hand, content based methods use additional features and information about the users or items to learn from a model. A feature in this context simply means information about a user or item. If we consider typical user features such as age, gender or other personal information, we can learn the relationships between user details and their preferences.
另一方面,基于内容的方法使用其他功能和有关用户或项目的信息以从模型中学习。 在此上下文中,功能仅表示有关用户或项目的信息。 如果我们考虑典型的用户功能(例如年龄,性别或其他个人信息),则可以了解用户详细信息与其偏好之间的关系。
The same is true for additional item characteristics which help to understand commonalities or differences between items.
对于有助于理解项目之间的共性或差异的其他项目特征,也是如此。

The main idea is building a model (representation) which explains user behaviour (interactions) using additional features data.
主要思想是构建一个模型(表示形式),该模型使用其他要素数据来解释用户行为(交互)。
Content based methods are less vulnerable to the cold start problem because they can use similarities in user/item characteristics to infer recommendations. This limits the cold start problems to only new users/items which also have new (unknown) features. Using a model to predict the recommendation has a cost which is described as a bias-variance tradeoff.
基于内容的方法较不容易受到冷启动问题的影响,因为它们可以使用用户/项目特征的相似性来推断推荐。 这将冷启动问题限制为仅具有新功能(未知)的新用户/项目。 使用模型来预测推荐具有成本,该成本被描述为偏差方差折衷 。
Without explicitly explaining the implications of bias and variance, it can be understood as the compromise between model complexity and data volume. This usually requires more effort in carefully fine tuning your models.
在没有明确解释偏差和方差的含义的情况下,可以将其理解为模型复杂性和数据量之间的折衷。 这通常需要更多的精力来仔细地微调模型。
混合方式 (Hybrid approach)
The hybrid approach is a combination of collaborative filtering and the content based approach. One way to archive those systems is to simply have two models and then mix the recommendations from both to ensure a more robust recommendation system. The second more sophisticated way is to combine both approaches — this is often done using machine learning concepts such as neural networks.
混合方法是协作过滤和基于内容的方法的组合。 归档这些系统的一种方法是简单地拥有两个模型,然后混合来自两个模型的推荐以确保更强大的推荐系统。 第二种更复杂的方法是将两种方法结合起来-通常使用机器学习概念(例如神经网络)来完成。
亚马逊个性化 (Amazon Personalize)
AWS realised that many customers were struggling to build recommendation systems on top of their own customer data. So, they focused on solving a very common, but complex problem for their customers.
AWS意识到许多客户都在努力根据自己的客户数据构建推荐系统。 因此,他们专注于为客户解决一个非常普遍但复杂的问题。
Amazon Personalize allows developers with no prior machine learning experience to easily build sophisticated personalisation capabilities into their applications, using machine learning technology by leveraging Amazon’s experience.
Amazon Personalize允许没有先前机器学习经验的开发人员利用机器学习技术,通过利用Amazon的经验,轻松地在其应用程序中构建复杂的个性化功能。
Amazon Personalize supports collaborative filtering, the content based approach and a very powerful hybrid approach using hierarchical recurrent neural networks.
Amazon Personalize支持协作过滤,基于内容的方法以及使用分层递归神经网络的非常强大的混合方法。
Amazon Personalize试图解决什么? (What is Amazon Personalize trying to solve?)
AWS realized that the end-to-end workflow for developing and deploying recommendation systems is a challenging process. If recommendation systems are built from scratch, it typically requires experts and a higher level technical maturity from an organisation to successfully deploy recommendation models in production.
AWS意识到,用于开发和部署推荐系统的端到端工作流程是一个具有挑战性的过程。 如果推荐系统是从头开始构建的,则通常需要专家和组织的更高技术成熟度才能在生产中成功部署推荐模型。
Amazon Personalize identifies a typical development workflow to build highly capable recommender systems. Whilst the focus is on ease of use and abstraction of complexity, the model configuration itself allows expert level access and control of model parameters. From our research so far at DiUS, we’ve found that this flexibility has great potential, whereby as ML practitioners working with our customers, we will be able to leverage the more managed aspects for some use cases but then break away and implement something more bespoke for others.
Amazon Personalize确定了典型的开发工作流程,以构建功能强大的推荐系统。 虽然重点是易用性和复杂性的抽象,但是模型配置本身允许专家级访问和控制模型参数。 从我们在DiUS的迄今为止的研究中,我们发现这种灵活性具有巨大的潜力,借此,随着ML从业人员与客户合作,我们将能够在某些用例中利用更多可管理的方面,但随后会放弃并实现更多的功能。为他人定制。
Here are a few examples of how personalization could be used in applications:
以下是一些有关如何在应用程序中使用个性化的示例:
Personalized recommendations
个性化推荐
- Product and content recommendations tailored to a user’s profile (preferences).针对用户个人资料(首选项)量身定制的产品和内容推荐。
Personalized search
个性化搜索
- Search results consider each user’s preferences.搜索结果考虑每个用户的偏好。
- Intent to surface products that are relevant to the individual.意图显示与个人相关的产品。
Personalized notifications
个性化通知
- Promotions based on a user’s behaviour.基于用户行为的促销。
- Select the most appropriate mobile app notification to send based on a user’s location, buying habits and discount amounts.根据用户的位置,购买习惯和折扣金额,选择最合适的移动应用通知进行发送。
您能多快启动并运行? (How quickly could you get up and running?)
The answer to that question…it depends!
这个问题的答案…… 取决于!
Setting up the required AWS resources and uploading some data can be done in a couple of hours. Training models takes time, which is proportional to the amount of data provided. However, it can also be achieved within the same day. We’ve found that deploying an Amazon Personalize endpoint and testing the recommendation on top of a successful model can be done in minutes!
设置所需的AWS资源并上传一些数据可以在几个小时内完成。 训练模型所花费的时间与提供的数据量成正比。 但是,也可以在同一天内完成。 我们发现,可以在几分钟内完成部署Amazon Personalize终端并在成功的模型之上测试建议的过程!
However, we’ve also learned that finding and using the right data for your recommendation solution is an entirely different problem.
但是,我们还了解到,为建议解决方案寻找和使用正确的数据是一个完全不同的问题。
The timeframe will be largely impacted by organisational data readiness. Which means easy access to data exports and high quality datasets. Getting data (repeatedly) in a clean format can take anywhere from a day up to weeks.
时间范围将在很大程度上受组织数据准备就绪的影响。 这意味着轻松访问数据导出和高质量数据集。 (重复)以干净的格式获取数据可能需要一天到几周的时间。
技术概念 (Technical concepts)
This is a basic overview of the key technical concepts. For more of the technical detail, you might like to refer to the official Amazon Personalize documentation.
这是关键技术概念的基本概述。 有关更多技术细节,您可能希望参考官方的Amazon Personalize文档 。
工作流程概述 (Workflow overview)
Amazon Personalize can be considered as a complete solution to build an advanced recommender system which includes the entire lifecycle of a recommendation system.
Amazon Personalize可被视为构建高级推荐系统的完整解决方案,其中包括推荐系统的整个生命周期。
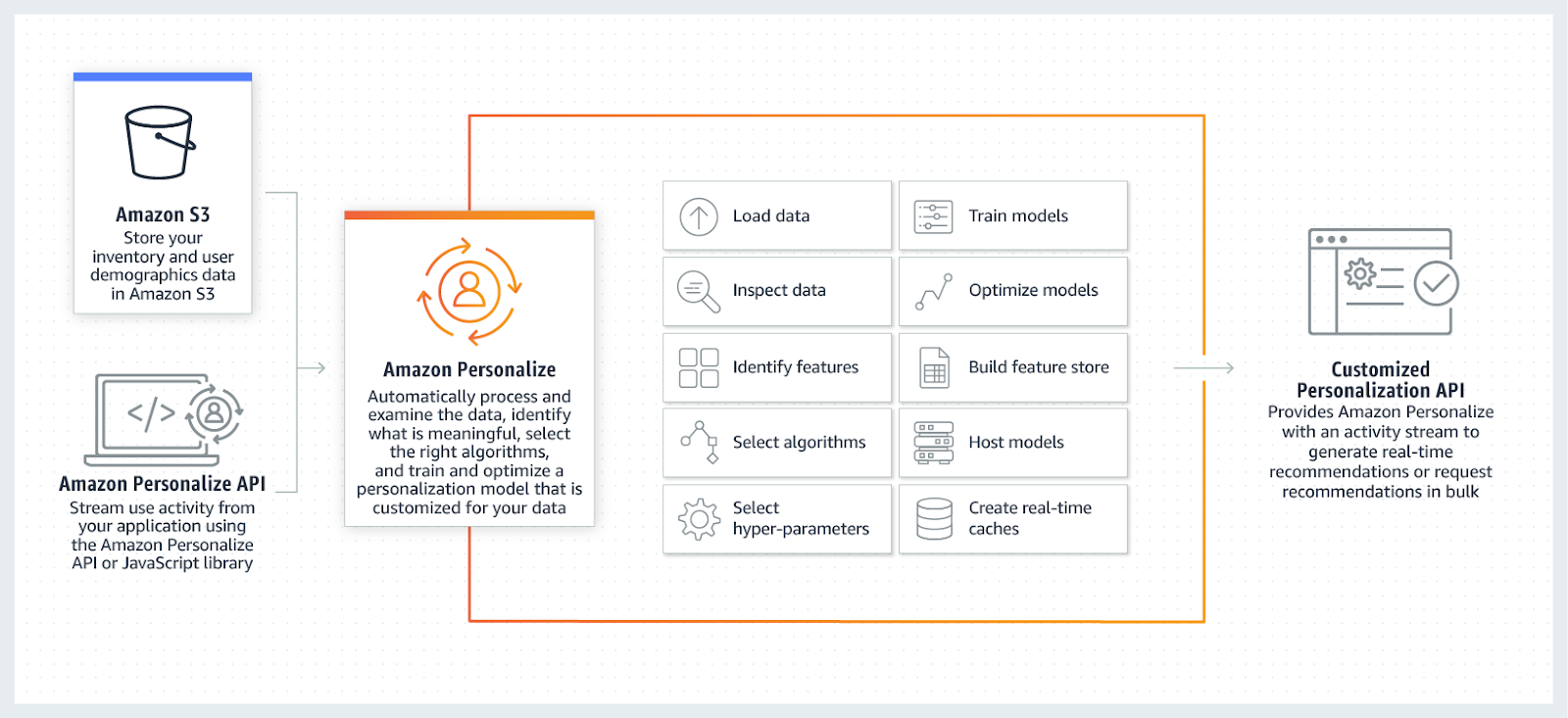
The above image — from the AWS website — lists the activities involved in setting up a workflow.
上面的图片(来自AWS网站)列出了设置工作流程所涉及的活动。
Typically, there are three main activities involved.
通常,涉及三个主要活动。
1. Data preparation
1.数据准备
- Identifying a suitable dataset识别合适的数据集
- Removing incorrect or augmenting missing data points删除不正确或增加丢失的数据点
- Exporting data in required format以所需格式导出数据
- Defining a dataset schema定义数据集架构
2. Model training
2.模型训练
- Selecting the appropriate solution (algorithm)选择适当的解决方案(算法)
- Model configuration型号配置
- Model training模型训练
- Model evaluation模型评估
3. Model deployment
3.模型部署
- Creating a model endpoint (API access to predictions)创建模型端点(对预测的API访问)

Datasets and dataset groups
数据集和数据集组
Each model is dependent on the dataset group which contains the individual dataset. You can build multiple models against the same dataset and select the best option.
每个模型都取决于包含单个数据集的数据集组。 您可以针对同一数据集构建多个模型,然后选择最佳选项。
- Relationship between dataset / solution and campaigns数据集/解决方案与活动之间的关系
Interaction dataset
互动数据集
- Record of interactions between user and items with a timestamp记录带有时间戳的用户和项目之间的交互
User dataset
用户数据集
- User specific details such as age, gender, address etc. User_ID used to map back to interactions用户特定的详细信息,例如年龄,性别,地址等。User_ID用于映射回交互
Items dataset
项目数据集
- Items details such as genre, preis, description etc. Item_ID used to map back to interaction dataset项目详细信息,例如类型,风格,描述等。Item_ID用于映射回交互数据集
For more information see Amazon Personalize documentation.
有关更多信息,请参阅Amazon Personalize文档 。
数据集架构 (Dataset schema)
Amazon Personalize is guiding the data selection process by requiring the data to conform with a predefined schema. Schemas are defined as JSON structures and will be versioned by Amazon Personalize. Each dataset schema has mandatory files which have to match the CSV column names. The mandatory fields help to map common user and item data so the model training can convert them accordingly.
Amazon Personalize通过要求数据符合预定义的架构来指导数据选择过程。 模式定义为JSON结构,并将由Amazon Personalize进行版本控制。 每个数据集模式都有必填文件,这些文件必须与CSV列名匹配。 必填字段有助于映射普通用户和商品数据,以便模型训练可以相应地转换它们。
Each dataset has some reserved keywords which you would typically use in the context of a recommendation scenario.
每个数据集都有一些保留的关键字 ,您通常会在推荐方案的上下文中使用这些保留的关键字 。
The key takeaway from the schema concept is that while there is some flexibility in defining your own schema, Amazon Personalize is asking users to convert/map data to their predefined schema. This helps users to guide data selection and also puts focus on what’s important. If you define additional fields in your user/item data, you have to decide if that data is categorical or quantitative.
模式概念的关键之处在于,尽管在定义自己的模式方面具有一定的灵活性,但Amazon Personalize要求用户将数据转换/映射到其预定义模式。 这可以帮助用户指导数据选择,也可以将重点放在重要的方面。 如果在用户/项目数据中定义其他字段,则必须确定该数据是分类数据还是定量数据。
Categorical variables represent types of data which may be divided into groups. Whereas quantitative variables represent numbers which implies ordering (e.g. integer or float).
分类变量表示可以分为几组的数据类型。 定量变量代表暗示排序的数字(例如整数或浮点数)。
食谱(又名算法) (Recipes (aka algorithms))
Amazon Personalize is offering a mixture of collaborative filtering and content based algorithms — named recipes — which can be categorised into three classes.
Amazon Personalize提供了协作式过滤和基于内容的算法(称为食谱)的混合,可以分为三类。
用户个性化食谱 (User Personalization Recipes)
Predict which item a user will most likely interact:
预测用户最有可能互动的项目:
HRNN is a hierarchical recurrent neural network (hybrid approach)
HRNN是分层递归神经网络(混合方法)
- HRNN人力资源网络
- HRNN with metadata (user/item dataset)带有元数据的HRNN(用户/项目数据集)
- HRNN coldstart aware modelHRNN冷启动感知模型
Popularity-Count Recipe
人气计数食谱
- Most popular items based on interaction count基于互动次数的最受欢迎商品
Personalized-Ranking Recipe (collaborative filtering)
个性化排名食谱 (协作过滤)
Product and content recommendations tailored to a user’s profile
根据用户个人资料量身定制的产品和内容推荐
HRNN a hierarchical recurrent neural network
HRNN分层递归神经网络
- filter and rerank results筛选并重新排序结果
Related Items Recipe
相关项目食谱
SIMS Recipe (collaborative filtering)
SIMS食谱(协作过滤)
- Item-to-item similarities (SIMS)项到项相似性(SIMS)
The documentation is straightforward on how to select a recipe for training a model. Amazon Personalize is following good practice by selecting sensible default configurations, but also allowing the user to go deep into tuning their models.
该文档直接介绍了如何选择用于训练模型的配方。 Amazon Personalize通过选择合理的默认配置来遵循良好做法,而且还允许用户深入调整模型。
超参数 (Hyperparameter)
Model configuration parameters are also referred to as Hyperparameter. Those values are estimated without actually using any real data. Sometimes they are also referred to as ‘good guesses’.
模型配置参数也称为超参数。 这些值是在没有实际使用任何实际数据的情况下估算的。 有时,它们也被称为“好的猜测”。
Amazon Personalize is offering an automatic tuning of these hyperparameters. Which is essentially a grid search for parameters to find the most successful configuration, this however is abstracted from the user as an optional step. Again, we like the fact that this is available but only as required given the problem at hand.
Amazon Personalize提供了这些超参数的自动调整。 从本质上讲,这是对参数进行网格搜索以找到最成功的配置,但是,这是作为可选步骤从用户中抽象出来的。 再次,我们喜欢这样一个事实,即只有在考虑到手头的问题时才需要这样做。
解决方案(模型培训) (Solutions (model training))
A solution version is the term Amazon Personalize uses for a trained machine learning model.
解决方案版本是术语Amazon Personalize用于受过训练的机器学习模型。
The creation of a solution requires the user to select one of the recipe’s, as well as provide the required dataset and their corresponding schemas.
解决方案的创建需要用户选择配方之一,并提供所需的数据集及其相应的模式。
模型评估 (Model evaluation)
Amazon Personalize supports various numerical metrics to measure the model performance.
Amazon Personalize支持各种数值指标来衡量模型的性能。
Depending on the choice of recipe (algorithm) certain metrics will be generated. We are just looking at two types of metrics, however if you would like more detail, you can refer to the documentation.
根据配方(算法)的选择,将生成某些指标。 我们仅研究两种类型的指标,但是,如果您想了解更多详细信息,可以参考文档 。
precision_at_K — Is the total relevant items divided by total recommended items.
precision_at_K-相关项目总数除以建议项目总数。
normalized_discounted_cumulative_gain_at_K — Considers positional effects by applying inverse logarithmic weights based on the positions of relevant items, normalised by the largest possible scores from ideal recommendations.
normalized_discounted_cumulative_gain_at_K-通过根据相关项目的位置应用对数权重来考虑位置效应,并根据理想建议中的最大可能得分对其进行归一化。
From our experience, recommendation is a challenging problem and typically those models have a relatively low accuracy on an individual predictions scale, however because we typically get many more opportunities to recommend, a small increase can have big impact.
根据我们的经验,推荐是一个具有挑战性的问题,通常这些模型在单个预测范围内的准确性较低,但是,由于我们通常会获得更多的推荐机会,因此少量增加可能会产生重大影响。
广告活动(模型部署) (Campaigns (model deployment))
The creation of a campaign is packaging your solution together with some wrapping code into a HTTP endpoint. This all is done automatically by Amazon Personalize. The user has to simply select a solution model and minimum expected Transaction-per-minute TPS.
一个运动的创建与某些封装代码成HTTP端点一起打包的解决方案。 这一切由Amazon Personalize自动完成。 用户只需选择解决方案模型和最低的每分钟预期TPS交易量即可。
Model predictions are available via HTTP or AWS SDK and can be either a single recommendation or batch predictions.
模型预测可通过HTTP或AWS开发工具包获得,可以是单个建议或批量预测。
结论 (Conclusion)
We are now observing the rapid change in consumer behaviour in real time due a drastic impact on our environment. We were looking at the OODA Loop framework on how organisations have to analyse and react to those underlying changes.
由于对环境的巨大影响,我们现在正在实时观察消费者行为的快速变化。 我们正在研究OODA Loop框架,以了解组织如何分析和响应那些潜在的变化。
We think that powerful recommender systems are one way for organisations to reduce their OODA loop and react quickly to rapid changes. Looking at the types of recommender systems,
我们认为,强大的推荐系统是组织减少OODA循环并快速响应快速变化的一种方法。 查看推荐系统的类型,
collaborative filtering and content based approaches helped to understand what challenges we have to solve.
协作式过滤和基于内容的方法有助于了解我们必须解决的挑战。
Amazon Personalize is a new contender in the recommendation market and has some advantages for existing Amazon cloud customers since most of their data is already in the cloud. It’s using a state-of-the-art recommendation algorithm that addresses cold start problem.
Amazon Personalize是推荐市场中的新竞争者,并且对现有的Amazon云客户具有一些优势,因为他们的大多数数据已经在云中。 它使用最新的推荐算法来解决冷启动问题 。
Amazon Personalize is trying to provide easier access to the complex world of custom recommendation systems (trained on your own customer data).
Amazon Personalize试图提供对复杂的自定义推荐系统世界(以您自己的客户数据进行培训)的访问。
Part 2 of this blog post will look into the challenges you might face when building on top of Amazon Personalize and how to automate the entire process.
这篇博客文章的第2部分将探讨在Amazon Personalize之上构建时可能面临的挑战,以及如何使整个过程自动化。
翻译自: https://medium.com/dius/amazon-personalize-helping-unlock-the-power-of-advanced-recommendation-solutions-for-the-lean-5931efb4f9cf
http://www.taodudu.cc/news/show-997527.html
相关文章:
- 西雅图治安_数据科学家对西雅图住宿业务的分析
- 创意产品 分析_使用联合分析来发展创意
- 多层感知机 深度神经网络_使用深度神经网络和合同感知损失的能源产量预测...
- 使用Matplotlib Numpy Pandas构想泰坦尼克号高潮
- pca数学推导_PCA背后的统计和数学概念
- 鼠标移动到ul图片会摆动_我们可以从摆动时序分析中学到的三件事
- 神经网络 卷积神经网络_如何愚弄神经网络?
- 如何在Pandas中使用Excel文件
- tableau使用_使用Tableau升级Kaplan-Meier曲线
- numpy 线性代数_数据科学家的线性代数—用NumPy解释
- 数据eda_银行数据EDA:逐步
- Bigmart数据集销售预测
- dt决策树_决策树:构建DT的分步方法
- 已知两点坐标拾取怎么操作_已知的操作员学习-第3部分
- 特征工程之特征选择_特征工程与特征选择
- 熊猫tv新功能介绍_熊猫简单介绍
- matlab界area_Matlab的数据科学界
- hdf5文件和csv的区别_使用HDF5文件并创建CSV文件
- 机器学习常用模型:决策树_fairmodels:让我们与有偏见的机器学习模型作斗争
- 100米队伍,从队伍后到前_我们的队伍
- mongodb数据可视化_使用MongoDB实时可视化开放数据
- Python:在Pandas数据框中查找缺失值
- Tableau Desktop认证:为什么要关心以及如何通过
- js值的拷贝和值的引用_到达P值的底部:直观的解释
- struts实现分页_在TensorFlow中实现点Struts
- 钉钉设置jira机器人_这是当您机器学习JIRA票证时发生的事情
- 小程序点击地图气泡获取气泡_气泡上的气泡
- PopTheBubble —测量媒体偏差的产品创意
- 面向Tableau开发人员的Python简要介绍(第3部分)
- pymc3使用_使用PyMC3了解飞机事故趋势
Amazon Personalize:帮助释放精益数字业务的高级推荐解决方案的功能相关推荐
- 【观察】亚马逊云科技:从“三驾马车”到“四措并举”,释放中国数字经济新动能...
2021年,在亚马逊云科技中国峰会上,亚马逊云科技宣布以"全球优势,植根本地"的全新中国战略,和"5+1+1"的优势能力打造中国业务的"三驾马车&qu ...
- 浅谈精益数字化工厂(Lean Digital Factory, LDF)
一. 精益四原则 智能工厂的能力往往体现在收集数据,智能工厂的成败则绝对取决于从数据利用的角度描绘愿景的能力 (理解和分析数据→找寻数据价值→预测未来事件→优化决策),但如何用更全面的方法去捕捉数字化 ...
- 【工赋开发者社区】面向智能制造全价值链的精益数字孪生体
导读 当前,世界主要国家都在科技发展的新机遇中大力推动制造业产业创新,在这样的背景下德国提出了"工业4.0"概念,美国发布了先进制造业国家战略计划,我国也确定了以智能制造为核心建设 ...
- Amazon Personalize 个性化效果评估,从准确性到多样性、新颖性和偶然性
背景 Amazon Personalize 是一种机器学习服务,Amazon Personalize 使开发人员可以通过 Amazon.com 使用的机器学习 (ML) 技术来构建应用程序,从而提供实 ...
- 面向智能制造全价值链的精益数字孪生体
当前,世界主要国家都在科技发展的新机遇中大力推动制造业产业创新,在这样的背景下德国提出了"工业4.0"概念,美国发布了先进制造业国家战略计划,我国也确定了以智能制造为核心建设制造强 ...
- 使用 Amazon Personalize 快速搭建推荐服务
Amazon Personalize 是亚马逊云科技完全托管的服务.Amazon Personalize 将 Amazon.com 二十多年机器学习的应用经验集成到服务当中,并且可以根据用户数据进一步 ...
- 年度全球十大突破性技术公布;华为发布数字能源零碳网络解决方案 | 美通企业日报...
今日看点:<麻省理工科技评论>评选年度全球十大突破性技术.华为发布数字能源零碳网络解决方案,OPPO.斯普奥汀.浪潮.神州泰岳亮相MWC上海.轩尼诗成为NBA首个全球烈酒合作伙伴.乐高集团 ...
- 爱尔兰拥抱数字货币和互联网金融解决方案
忘掉硅谷,忘掉褚格洲.有一个新的区块链和数字货币中心出现在爱尔兰的绿宝石岛.事实上,都柏林有公司支持,在数字货币和数字账本环境下有教育及工业基础设施. 爱尔兰不断出现新的技术创新,也是迅速壮大的互联网 ...
- 趣学python3(2)-添加以数字文字形式使用下划线的功能,以提高可读性
添加以数字文字形式使用下划线的功能,以提高可读性 x=2_111_222 y=0x_fff_6da print(x) print(y) 2111222 16774874
最新文章
- foxmail使用技巧
- PYTHON——TCPUDP:Socket实现远程执行命令
- ref out param 区别
- Python之路番外(第二篇):PYTHON基本数据类型和小知识点
- SAP ABAP SM50事务码和Hybris Commerce的线程管理器
- 百万个小油馕跨越3000公里来支援!西安加油!
- sublime text 2 解决错误 [Decode error - output not utf-8]
- HTML和CSS实现品优购首页
- 【深度优先搜索】网格类问题:牛客网:机器人的运动范围
- java8 时间加一秒_都9012了,Java8中的日期时间API你还没有掌握?
- DNA甲基化可实现转座因子驱动的基因组扩增
- Python实现学生管理系统(功能全面)
- python可视化迷宫求解_如何用 Python 制作一个迷宫游戏
- ZOJ Yukari's Birthday
- pytorch教程 聊天机器人(详细注释attentionrnn输入输出shape等知识点...
- Wi-Fi智能插座拆解:如何实现远程开关
- 稀疏特征(稀疏矩阵)
- 基于keras的seq2seq中英文翻译实现
- 创意编程——随机(扩散限制聚集DLA)
- 360wifi linux ad hoc,Ad Hoc模式无线局域网搭建