spark集群详细搭建过程及遇到的问题解决(三)
上篇文章中讲完了如何配置免密码登录的问题,现在讲述下,三个节点的环境配置过程。
所需要的hadoop-2.7.3.tar.gz 、 jdk-7u79-linux-x64.tar.gz 、 scala-2.11.6.tgz 、 spark-2.0.1-bin-hadoop2.7.tgz 可以点击这里获取,资源存放在百度云盘。
首先需要在三个节点中分别创建spark目录
master节点、worker1节点、worker2节点同时执行:下面以master节点为例,部分操作worker1与worker2不需要执行,不需要worker1,worker2执行的将给出注释,请仔细看清。
spark@master:~/.ssh$ cd ..
spark@master:~$ mkdir spark
注意所创建的spark目录属于spark用户,hadoop组
spark@master:~$ cd spark/在这里要介绍一个工具winSCP,功能是能够在windows 与ubuntu 之间传递文件,之所以不推荐使用lrzsz包中的rz 进行传递是因为rz只能够传递比较小的文件,对于大的文件,使用这个将会传递失败,有趣的是可以使用命令sudo rz 进行传递,但是,当上传之后,你可以看到所上传的文件所属的用户将变成了root,这将会导致后面配置的错误。因此,必须使用winSCP进行传递。winSCP也在刚才的百度云盘中。
上图显示了winSCP工具界面,根据自己的文件目录进行上传,或者可以直接拖
依次对上传的包进行解压,注意:在worker1和worker2中只需上传jdk-7u79-linux-x64.tar.gz 、 scala-2.11.6.tgz ,而在master中则要全部上传四个文件
spark@master:~/spark$ tar -zxvf hadoop-2.7.3 #只在master节点执行spark@master:~/spark$ tar -zxvf jdk-7u79-linux-x64.tar.gz #三个节点都要执行spark@master:~/spark$ tar -zxvf scala-2.11.6.tgz #三个节点都要执行spark@master:~/spark$ tar -zxvf spark-2.0.1-bin-hadoop2.7.tgz #只在master节点执行解压之后,为方便调用,建立软连接
spark@master:~/spark$ ln -s hadoop-2.7.3 hadoop #只在master节点执行
spark@master:~/spark$ ln -s jdk1.7.0_79/ jdk #三个节点都要执行
spark@master:~/spark$ ln -s scala-2.11.6 scala #三个节点都要执行
spark@master:~/spark$ ln -s spark-2.0.1-bin-hadoop2.7 spark #只在master节点执行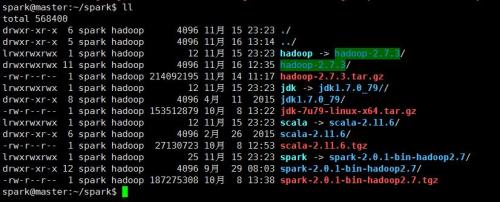
切换到root下进行环境配置
spark@master:~/spark$ sudo su
[sudo] password for spark:
root@master:/home/spark/spark# vim /etc/profile在文件最底部添加:
export JAVA_HOME=/home/spark/spark/jdk #三个节点都要添加
export SCALA_HOME=/home/spark/spark/scala #三个节点都要添加
export HADOOP_HOME=/home/spark/spark/hadoop #三个节点都要添加
export SPARK_HOME=/home/spark/spark/spark #三个节点都要添加export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin保存,使其生效,并退回到spark用户
root@master:/home/spark/spark# source /etc/profile
root@master:/home/spark/spark# exit
exit
spark@master:~/spark$至此可以查看下java环境,scala,hadoop 环境是否已经安装成功
spark@master:~/spark$ java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)java环境已经配置成功
spark@master:~/spark$ scala -version
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLscala已经配置成功
至此上述是三个节点同时执行的。
接下来,master节点上的配置
spark@master:~/spark$ hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /home/spark/spark/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jarhadoop环境成功
接下来开始配置hadoop
spark@master:~/spark$ cd hadoop/etc/hadoop/
spark@master:~/spark/hadoop/etc/hadoop$ vim slaves删除里面内容,并添加一下内容:
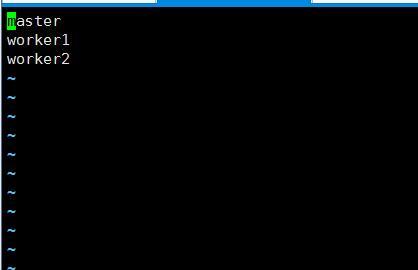
保存即可
依照下述命令进行文件的更改
spark@master:~/spark/hadoop/etc/hadoop$ vim hadoop-env.sh添加或更改文件中相关的变量,本人在这个地方踩了不少坑,如果不添加,会在后面报错。


添加完毕后,记得保存。
spark@master:~/spark/hadoop/etc/hadoop$ vim core-site.xml添加内容到
<configuration>内容</configuration>
内容如下:
<property><name>fs.default.name</name><value>hdfs://master:9000</value><description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description></property><property><name>hadoop.tmp.dir</name><value>/home/spark/spark/hadoop/tmp</value><description>A base for other temporary directories.</description></property>
spark@master:~/spark/hadoop/etc/hadoop$ vim hdfs-site.xml添加内容到
<configuration>内容</configuration>
内容如下:
<property><name>dfs.replication</name><value>3</value><description>Default block replication.The actual number of replications can be specified when the file iscreated.The default is used if replication is not specified in create time.</description></property>
spark@master:~/spark/hadoop/etc/hadoop$ vim yarn-site.xml添加内容到
<configuration>内容</configuration>
内容如下:
<property><name>yarn.resourcemanager.hostname</name><value>master</value> </property> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property>
spark@master:~/spark/hadoop/etc/hadoop$ vim mapred-site.xml
spark@master:~/spark/hadoop/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml添加内容到
<configuration>内容</configuration>
内容如下: 然后执行cp mapred-site.xml.template mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value><description>The runtime framework for executing MapReduce jobs.Can be one of local, classic or yarn.默认是local,适合单机</description></property>
spark@master:~/spark/hadoop/etc/hadoop$ vim yarn-site.xml
添加内容到
<configuration>内容</configuration>
内容如下:
<property><name>yarn.resourcemanager.hostname</name><value>master</value> </property> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property>
spark@master:~/spark/hadoop/etc/hadoop$ vim yarn-env.sh添加以下内容在文件中地开始
export JAVA_HOME=/home/spark/spark/jdk export YARN_PID_DIR=/home/spark/spark/hadoop/tmp/pid
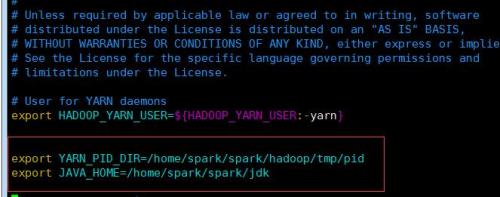
保存文件,注意有些hadoop参考可能会提前将 /home/spark/spark/hadoop/tmp 文件夹建好,但在此版本中不需要提前创建,,因为在hadoop初始化时,会自动创建,若是提前创建,则有可能会在启动hadoop集群时报错!
切换到worker1节点中
执行
spark@worker1:~/spark$ scp -r spark@master:/home/spark/spark/hadoop ./hadoop注意:./hadoop,代表将master中spark用户下的/home/spark/spark/hadoop复制为hadoop,此名称要跟之前在/etc/profile中设置的hadoop环境变量名称一致。
在worker1中做下测试。
spark@worker1:~/spark$ hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /home/spark/spark/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar显示成功
切换到worker2节点中
spark@worker2:~/spark$ scp -r spark@master:/home/spark/spark/hadoop ./hadoop在worker2下做下测试。
spark@worker2:~/spark$ hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /home/spark/spark/hadoop/share/hadoop/common/hadoop-common-2.7.3.jar显示成功
初始化hadoop集群
spark@master:~/spark/hadoop/etc/hadoop$ hadoop namenode -format
若红色方框中的status为0则代表初始化成功,若为1,则为失败
启动集群
spark@master:~/spark/hadoop/etc/hadoop$ $HADOOP_HOME/sbin/start-all.sh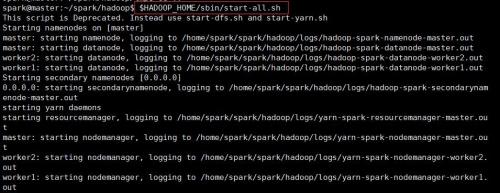
然后在浏览器中输入 http://master_ip:50070/ master_ip代表master的ip地址端口号为50070
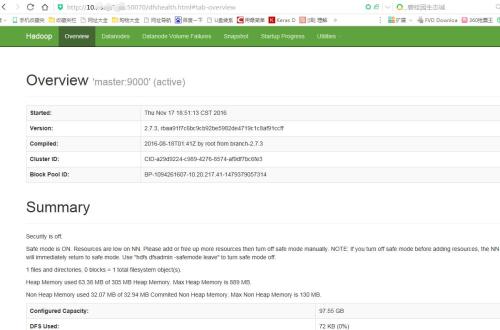
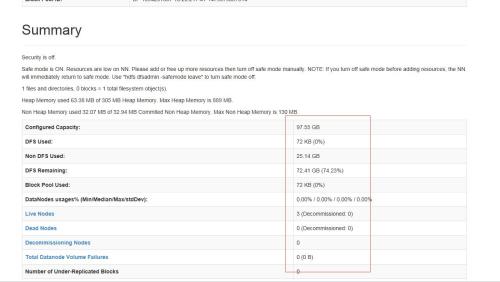
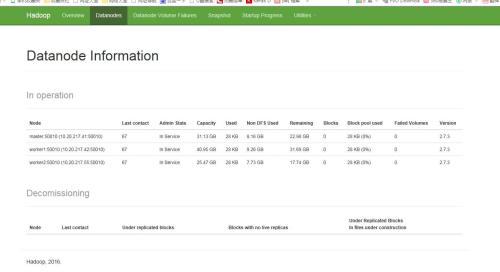
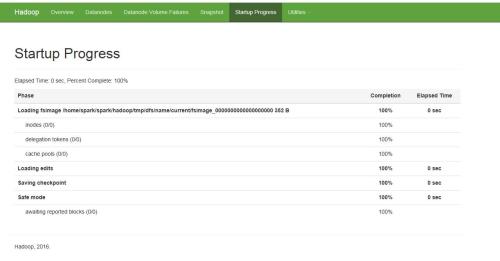
至此,hadoop集群已全部安装完毕。
我们将在下一篇文章中,进一步安装spark集群。。。。
转载于:https://blog.51cto.com/lefteva/1874033
spark集群详细搭建过程及遇到的问题解决(三)相关推荐
- spark集群详细搭建过程及遇到的问题解决(四)
在spark集群详细搭建过程及遇到的问题解决(三)中,我们将讲述了hadoop的安装过程,在本文中将主要讲述spark的安装配置过程. spark@master:~/spark$ cd hadoop ...
- spark集群详细搭建过程及遇到的问题解决(一)
注:其中也参考了网上的许多教程,但很多网上的教程在配置过程中,会出很多错误,在解决的过程中,做出了总结. 此文是针对小白.如有不对,请大神们指教.... 配置环境系统:Ubuntu16.04 配置版本 ...
- Spark集群环境搭建(standalone模式)
Spark集群环境搭建(standalone模式) 1. 实验室名称: 2. 实验项目名称: 3. 实验学时: 4. 实验原理: 5. 实验目的: 6. 实验内容: 7. 实验器材(设备.虚拟机名称) ...
- 【网址收藏】k8s高可用集群详细搭建步骤
https://github.com/opsnull/follow-me-install-kubernetes-cluster
- spark 广播变量大数据_大数据处理 | Spark集群搭建及基本使用
点击蓝字关注我 前面用了一篇文章详细的介绍了集群HDFS文件系统的搭建,HDFS文件系统只是一个用于存储数据的系统,它主要是用来服务于大数据计算框架,例如MapReduce.Spark,本文就接着上一 ...
- Spark学习之spark集群搭建
(推广一下自己的个人主页 zicesun.com) 本文讲介绍如何搭建spark集群. 搭建spark集群需要进行一下几件事情: 集群配置ssh无秘登录 java jdk1.8 scala-2.11. ...
- docker下,极速搭建spark集群(含hdfs集群)
搭建spark和hdfs的集群环境会消耗一些时间和精力,处于学习和开发阶段的同学关注的是spark应用的开发,他们希望整个环境能快速搭建好,从而尽快投入编码和调试,今天咱们就借助docker,极速搭建 ...
- 基于Hadoop集群的Spark集群搭建
基于Hadoop集群的Spark集群搭建 注:Spark需要依赖scala,因此需要先安装scala 一. 简单叙述一下scala的安装 (1)下载scala软件安装包,上传到集群 (2)建立一个用于 ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
最新文章
- qt LNK2019 无法解析的外部符号
- 【Python之旅】第二篇(三):基于列表处理的购物清单程序
- React和Vue的Chrome扩展工具安装
- eNet 软件发布要求多多
- 字符串转整数,不使用任何C语言库函数
- linux强制获得锁,Linux中的两种文件锁——协同锁与强制锁
- java实现上传寸照并剪裁,给寸照换背景_用java处置图片(jpg,png,gif.)的背景颜色
- ADS8332芯片驱动程序
- 2017-2018-1 《程序设计与数据结构》课程总结
- MyEclipse中如何修改项目的编码格式
- 006 以太坊Mist安装部署
- 3D电影、游戏里的角色是怎么制作的?
- python爬携程_用python selenium抓取携程信息
- 记录一下如何运行MDX文件
- 【积跬步以至千里】如何查看浏览器保存的密码
- 股市跷跷板—债券基金
- 2022-2028全球双斜齿轮行业调研及趋势分析报告
- 为什么育润可舒粉能调节血糖和改善便秘?
- Android 软键盘 弹出,默认隐藏,强制隐藏,自动变大写等
- Java实现远程桌面连接
热门文章
- 手机利用python访问电脑文件_黑客教程,一行python命令让手机读取电脑文件!
- 发生生成错误是否继续并运行上次的成功生成_JavaScript 是如何运行的?
- access数据类型百度百科_Day 7 基本数据类型
- 华尔街英语学习软件_华尔街英语核心课程功能升级 让学员学习之旅更高效
- 服务号idbase64_微信公众号-上传图片顺便转base64
- redis -cli command not found_记一次 Linux 服务器 redis 漏洞分析
- oracle会话超时,Oracle EBS控制会话时间及超时
- Spring Web Flow 入门demo(二)与业务结合 附源码
- Web前端之移动端课程开发之06.bootstrap
- 算法是怎样决定你的职业生涯的