高斯过程分类和高斯过程回归_高斯过程回归建模入门
高斯过程分类和高斯过程回归
Gaussian processing (GP) is quite a useful technique that enables a non-parametric Bayesian approach to modeling. It has wide applicability in areas such as regression, classification, optimization, etc. The goal of this article is to introduce the theoretical aspects of GP and provide a simple example in regression problems.
高斯处理(GP)是一项非常有用的技术,可以采用非参数贝叶斯方法进行建模。 它在回归,分类,优化等领域具有广泛的适用性。本文的目的是介绍GP的理论方面,并为回归问题提供一个简单的示例。
Multivariate Gaussian distribution
多元高斯分布
We first need to do a refresher on multivariate Gaussian distribution, which is what GP is based on. A multivariate Gaussian distribution can be fully defined by its mean vector and covariance matrix
我们首先需要对多元高斯分布进行复习,这是GP所基于的。 多元高斯分布可以通过其均值向量和协方差矩阵完全定义
There are two important properties of Gaussian distributions that make later GP calculations possible: marginalization and conditioning.
高斯分布的两个重要属性使后来的GP计算成为可能:边际化和条件化。
Marginalization
边际化
With a joint Gaussian distribution, this can be written as,
使用联合高斯分布,可以写成:
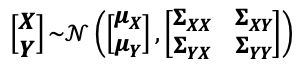
We can retrieve a subset of the multivariate distribution via marginalization. For example, we can marginalize out the random variable Y, with the resulting X random variable expressed as follows,
我们可以通过边际化获取多元分布的子集。 例如,我们可以将随机变量Y边缘化,结果X随机变量表示如下,
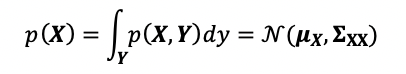
Note that the marginalized distribution is also a Gaussian distribution.
注意,边缘分布也是高斯分布。
Conditioning
调理
Another important operation is conditioning, which describes the probability of a random variable given the presence of another random variable. This operation enables Bayesian inference, as we will show later, in deriving the predictions given the observed data.
另一个重要的操作是调节,它描述了在存在另一个随机变量的情况下一个随机变量的概率。 正如我们将在后面展示的那样,此操作启用贝叶斯推理,从而在给定观测数据的情况下得出预测。
With conditioning, you can derive for example,
通过调节,您可以得出例如
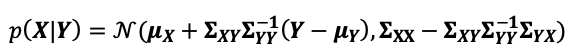
Like the marginalization, the conditioned distribution is also a Gaussian distribution. This allows the results to be expressed in closed form and is tractable.
像边缘化一样,条件分布也是高斯分布。 这允许结果以封闭形式表示并且易于处理。
Gaussian process
高斯过程
We can draw parallels between a multivariate Gaussian distribution and a Gaussian process. A Gaussian process (GP) is fully defined by its mean function and covariance function (aka kernel),
我们可以在多元高斯分布和高斯过程之间得出相似之处。 高斯过程(GP)由其均值函数和协方差函数(即内核)完全定义,
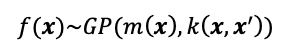
GP can be thought of as an infinite dimensional multivariate Gaussian. This is actually what we mean by GP as being non-parametric — because there are an infinite number of parameters. The mean function, m(x), describes the mean of any given data point x, and the kernel, k(x,x’), describes the relationship between any given two data points x1 and x2.
GP可以被视为无穷维多元高斯。 实际上,这就是我们所说的GP是非参数的-因为有无限数量的参数。 平均值函数m(x)描述任何给定数据点x的平均值,而内核k(x,x')描述任何给定的两个数据点x1和x2之间的关系。
As such, GP describes a distribution over possible functions. So when you sample from a GP, you get a single function. In contrast, when you sample from a Gaussian distribution, you get a single data point.
因此,GP描述了可能功能的分布。 因此,当您从GP采样时,您将获得一个功能。 相反,当从高斯分布中采样时,您将获得一个数据点。
Gaussian process regression
高斯过程回归
We can bring together the above concepts about marginalization and conditioning and GP to regression. In a traditional regression model, we infer a single function, Y=f(X). In Gaussian process regression (GPR), we place a Gaussian process over f(X). When we don’t have any training data and only define the kernel, we are effectively defining a prior distribution of f(X). We will use the notation f for f(X) below. Usually we assume a mean of zero, so all together this means,
我们可以将关于边际化和条件以及GP回归的上述概念组合在一起。 在传统的回归模型中,我们推导单个函数Y = f( X ) 。 在高斯过程回归(GPR)中,我们将高斯过程放在f( X )上。 当我们没有任何训练数据而仅定义内核时,我们实际上是在定义f( X )的先验分布。 我们将在下面的f ( X )中使用符号f 。 通常情况下,我们假设均值为零,所以所有这些都意味着,
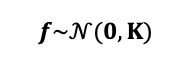
The kernel K chosen (e.g. periodic, linear, radial basis function) describes the general shapes of the functions. The same way when you choose a first-order vs second-order equation, you’d expect different function shapes of e.g. a linear function vs a parabolic function.
所选的核K (例如,周期,线性,径向基函数)描述了函数的一般形状。 选择一阶方程与二阶方程时,采用相同的方式,您会期望不同的函数形状,例如线性函数与抛物线函数。
When we have observed data (e.g. training data, X) and data points where we want to estimate (e.g. test data, X*), we again place a Gaussian prior over f (for f(X)) and f* (for f(X*)), yielding a joint distribution,
当我们观察到数据(例如训练数据X )和要估计的数据点(例如测试数据X * )时,我们再次将高斯优先于f (对于f( X ) )和f * (对于f ( X * ) ),产生联合分布,
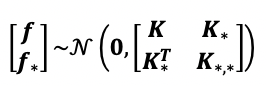
The objective here is we want to know what is f* for some set of x values (X*) given we have observed data (X and its corresponding f). This is effectively conditioning, and in other words it is asking to derive the posterior probability of the function values, p(f*|f,X,X*). This is also how we can make predictions — to calculate the posterior conditioned on the observed data and test data points.
这里的目标是我们想知道给定的一组x值( X * )的f *是多少 我们已经观察到了数据( X及其对应的f )。 这是有效的条件,换句话说,它要求导出函数值p ( f * | f , X , X * )的后验概率。 这也是我们进行预测的方式-计算以观察到的数据和测试数据点为条件的后验。
Adding noise
增加噪音
The functions described above are noiseless, meaning we have perfect confidence in our observed data points. In the real world, this is not the case and we expect to have some noise in our observations. In the traditional regression models, this can be modeled as,
上述功能无噪音,这意味着我们对观察到的数据点具有完全的信心。 在现实世界中,情况并非如此,我们希望观察中会出现一些噪音。 在传统的回归模型中,可以将其建模为:
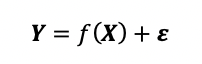
where ε~N(0, σ² I). The ε is the noise term and follows a Gaussian distribution. In GPR, we place the Gaussian prior onto f(X) just like before, so f(X)~GP(0,K) and y(X)~GP(0, K+σ² I). With the observed data, the joint probability is very similar to before, except now with the added noise term to the observed data,
其中,ε〜N(0,σ²I)。 ε是噪声项,遵循高斯分布。 在GPR中,我们放置高斯先验到F(X)之前一样,因此f(X)〜GP(0,K)和y(X)〜GP(0,K +σ²I)。 对于观察到的数据,联合概率与以前非常相似,只是现在在观察到的数据中添加了噪声项,
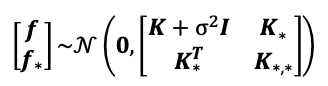
Likewise, we can perform inference by calculating the posterior conditioned on f*, X, and X*.
同样,我们可以通过计算以f * , X和X *为条件的后验条件来进行推断。
GPR using scikit-learn
使用scikit-learn进行GPR
There are multiple packages available for Gaussian process modeling (some are more general Bayesian modeling packages): GPy, GPflow, GPyTorch, PyStan, PyMC3, tensorflow probability, and scikit-learn. For simplicity, we will illustrate here an example using the scikit-learn package on a sample dataset.
有多种可用于高斯过程建模的软件包(有些是更通用的贝叶斯建模软件包):GPy,GPflow,GPyTorch,PyStan,PyMC3,张量流概率和scikit-learn。 为了简单起见,我们将在示例数据集上使用scikit-learn包说明一个示例。
We will use the example Boston dataset from scikit-learn. First we will load and do a simple 80/20 split of the data into train and test sets.
我们将使用来自scikit-learn的示例波士顿数据集。 首先,我们将数据加载并进行简单的80/20拆分,将其分为训练集和测试集。
We will use the GaussianProcessRegressor package and define a kernel. Here we will try a radial-basis function kernel with noise and an offset. The hyperparameters for the kernel are suggested values and these will be optimized during fitting.
我们将使用GaussianProcessRegressor包并定义一个内核。 在这里,我们将尝试一个带有噪声和偏移量的径向基函数内核。 内核的超参数为建议值,这些参数将在拟合过程中进行优化。
You can view the fitted model with model.kernel_. We can now also plot and see our predicted versus actual,
您可以使用model.kernel_查看拟合的模型。 现在,我们还可以绘制并查看我们的预测值与实际值,
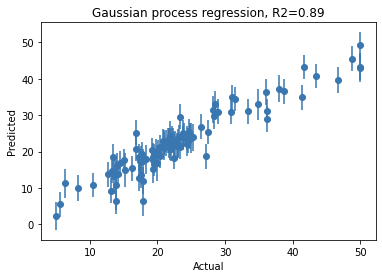
Note that you can get similar performance with other machine learning models such as random forest regressor, etc. However, the key benefit from GPR is that for each given test data point, the predicted value naturally comes with confidence intervals. So not only do you know your model performance, but you know what is the uncertainty associated with each prediction.
请注意,您可以在其他机器学习模型(例如随机森林回归器等)上获得类似的性能。但是,GPR的主要好处是对于每个给定的测试数据点,预测值自然带有置信区间。 因此,您不仅知道模型的性能,而且知道与每个预测相关的不确定性是什么。
This is a high-level overview of GP and GPR. We won’t go into details of the kernels here. But by adopting different kernels, you can incorporate your prior assumptions about the data into your model. With the simple example with scikit-learn, we hope to provide some inspirations in seeing how GPR is useful and you can quickly get started to incorporate some form of Bayesian modeling as part of your machine learning toolbox!
这是GP和GPR的高级概述。 我们在这里不会详细介绍内核。 但是,通过采用不同的内核,您可以将有关数据的先前假设合并到模型中。 通过scikit-learn的简单示例,我们希望对GPR的有用性有所启发,并且您可以很快开始将某种形式的贝叶斯建模纳入机器学习工具箱!
Some other useful resources/posts about GP
有关GP的其他一些有用的资源/帖子
翻译自: https://towardsdatascience.com/getting-started-with-gaussian-process-regression-modeling-47e7982b534d
高斯过程分类和高斯过程回归
http://www.taodudu.cc/news/show-2261506.html
相关文章:
- 如何推导高斯过程回归以及深层高斯过程详解
- 高斯过程回归python_高斯过程回归在pythony中的实现(n个样本,n个目标)
- 高斯过程回归(GPR)
- 高斯过程回归(Gaussian process regression)原理详解及python代码实战
- 高斯过程回归(输出学习法!)
- java版 高斯过程,三维高斯过程回归
- 高斯过程回归python_GPR(高斯过程回归)详细推导
- 高斯过程回归GPR
- 高斯过程回归(Gaussian Process Regression)
- 快速入门高斯过程(Gaussian process)回归预测
- 合并两个有序链表-递归
- java-合并两个有序链表
- Java合并两个有序链表
- 递归:合并两个有序链表
- 合并两个有序链表-c语言
- 数据结构 将两个有序的链表合并为一个新链表
- java 合并两个有序链表
- 合并两个有序链表js
- LeetCode-21. 合并两个有序链表_JavaScript
- 【LeetCode】21. 合并两个有序链表
- 【力扣】合并两个有序链表
- Java链表-合并两个有序链表
- 链表---合并两个有序链表
- 数据结构合并两个有序链表
- 合并两个有序链表(Java)
- 将两个有序链表合并
- Python合并两个有序链表
- java解决合并两个有序链表问题
- 【算法】合并两个有序链表
- 合并两个有序链表-python
高斯过程分类和高斯过程回归_高斯过程回归建模入门相关推荐
- 逻辑斯蒂回归 逻辑回归_逻辑回归简介
逻辑斯蒂回归 逻辑回归 Logistic regression is a classification algorithm, which is pretty popular in some commu ...
- spark java 逻辑回归_逻辑回归分类技术分享,使用Java和Spark区分垃圾邮件
原标题:逻辑回归分类技术分享,使用Java和Spark区分垃圾邮件 由于最近的工作原因,小鸟很久没给大家分享技术了.今天小鸟就给大家介绍一种比较火的机器学习算法,逻辑回归分类算法. 回归是一种监督式学 ...
- 优化 回归_使用回归优化产品价格
优化 回归 应用数据科学 (Applied data science) Price and quantity are two fundamental measures that determine t ...
- orange实现逻辑回归_逻辑回归模型
引入:广义线性模型 上节讲到了一个简单的线性回归模型: 在实际的模型中,我们可以假设线性模型的预测值逼近 而非Y,即: 若 为单调可微函数,则: 上式即被称为广义线性模型 简介 逻辑回归模型可以看做是 ...
- 逻辑斯蒂回归_逻辑回归 - 3 逻辑回归模型
1 逻辑斯蒂回归模型 二项逻辑斯蒂回归模型是一种分类模型,由条件概率分布 表示,形式为参数化的逻辑斯蒂分布,这里随机变量 取值为实数,随机变量 取值为1或-1. 对于给定的输入实例 ,按照上面式可以求 ...
- orange实现逻辑回归_逻辑回归算法的原理及实现(LR)
Logistic回归虽然名字叫"回归",但却是一种分类学习方法.使用场景大概有两个:第一用来预测,第二寻找因变量的影响因素.逻辑回归(Logistic Regression, LR ...
- python逻辑回归_逻辑回归:使用Python的简化方法
逻辑回归的目标是什么? 在逻辑回归中,我们希望根据一个或多个自变量(X)对因变量(Y)进行建模.这是一种分类方法.此算法用于分类的因变量.Y使用一个函数建模,该函数为X的所有值提供0到1之间的输出.在 ...
- python支持向量机回归_支持向量机回归的Scikitlearn网格搜索
我正在学习交叉验证网格搜索,并遇到了这个youtube playlist,教程也作为ipython笔记本上传到了github.我试图在同时搜索多个参数部分重新创建代码,但我使用的不是knn,而是支持向 ...
- 贝叶斯岭回归(BayesianRidge)、自动关联决策回归、高斯过程、核函数、及高斯回归、高斯过程分类
贝叶斯岭回归(BayesianRidge).自动关联决策回归.高斯过程.核函数.及高斯回归.高斯过程分类 目录
- rbf核函数_高斯过程回归础(使用GPy和模拟函数数据集)
为什么要了解高斯过程呢?因为不了解高斯过程就不能聊贝叶斯优化. 假设有这么一个函数: .现在有训练的数据y和一堆X.然后来了一个新的X让你用既有的数据去预测者个新的X所对应的y. 高斯过程(回归)的思 ...
最新文章
- Linux命令行与命令
- 爱了爱了!0.052 秒打开 100GB 数据,这个Python开源库火爆了!
- 今天已经算一下过来有一个礼拜了,还是感觉是在熬日子似的
- 黑马在线教育项目---15-16、datatables插件
- 关闭rdlc报表打印预览后,关闭客户端,抛出异常“发生了应用程序级的异常 将退出”...
- 铅笔道区块链实验班_你们抢着要的道地药材,必须用上区块链了
- 微信php签名验证_微信公众平台安全模式消息体签名及加解密PHP代码示例
- 保护数据库安全十七招
- 误差平方和用python_用Python学分析 - 单因素方差分析
- 传统Tier1“大象转身”:不够快?你永远没有机会
- 易基因|靶基因DNA甲基化测序(Target-BS)
- CF855G Harry Vs Voldemort 题解
- ice服务器修复指令,ICEEXT0.67指令中英文说明[翻译]
- [ 网络协议篇 ] IGP 详解之 OSPF 详解(三)--- OSPF协议报文 链路状态通告 详解
- 一文解决关于建立时间和保持时间的困惑
- B. Boboniu Plays Chess(手速)
- css加空格的方法,css如何加空格
- 适用于大规模数据排序(归并排序、快速排序)
- python提取word目录_python批量提取word内信息
- sqlite3和tkinter结合使用案例编程