Scala HandBook
目录[-]
- 1. Scala有多cool
- 1.1. 速度!
- 1.2. 易用的数据结构
- 1.3. OOP+FP
- 1.4. 动态+静态
- 1.5. DSL
- 1.6. 够复杂
- 1.7. 够有趣
- 1.8. 开发社区
- 2. lang
- 2.1. 和Java的异同
- 2.1.1. 语法
- 2.1.2. 库
- 2.2. 变量
- 2.2.1. 保留字
- 2.2.2. 变量标识
- 2.2.3. 变量定义
- 2.2.3.1 val, var
- 2.2.3.2 花样定义
- 2.2.3.3 lazy, val, def的区别
- 2.3. 基本类型
- 2.3.1. Int
- 2.3.2. Char
- 2.4. BigInt
- 2.5. 字符串
- 2.5.1. 类型转换
- 2.5.2. StringBuilder
- 2.5.3. 文本格式化
- 2.6. Null, None, Nil, Nothing
- 2.7. ==和eq
- 2.8. Option[T]
- 2.8.1. 概念
- 2.8.2. 使用
- 2.8.3. 例子
- 2.9. 区分<-,=>,->
- 2.10. match..case(switch)
- 2.10.1. 和switch..case的区别
- 2.10.2. 匹配数据类型
- 2.10.3. 命令行参数解析例子
- 2.10.4. 使用case的递归函数
- 2.10.5. 变量匹配
- 2.10.6. case..if条件匹配
- 2.11. try..catch..finally
- 2.12. require
- 2.13. main方法
- 2.13.1. Application
- 2.14. package, import
- 2.14.1. import
- 2.14.2. package
- 2.14.3. 包对象
- 2.15. if..else
- 2.16. 循环操作
- 2.16.1. for
- 2.16.1. for .. yield
- 2.16.2. foreach
- 2.16.3. forall
- 2.16.4. reduceLeft
- 2.16.5. foldLeft scanLeft
- 2.16.6. scanLeft
- 2.16.7. take drop splitAt
- 2.16.8. takeWhile, dropWhile, span
- 2.16.9. break、continue
- 2.17. 操作符重载
- 2.18. 系统定义scala._
- 2.19. implicit隐式转换
- 2.19.1. 类型转换
- 2.19.2. 例子:阶乘n!
- 2.19.3. 例子:cout
- 2.19.4. 例子:定义?:
- 2.19.5. 已有Object加新方法
- 2.20. type做alias
- 2.21. 泛型
- 2.21.1. 函数中的泛型:
- 2.21.2. 类中的泛型:
- 2.21.3. 泛型qsort例子
- 2.21.4. 泛型add例子
- 2.21.5. 泛型定义type
- 2.21.6. @specialized
- 2.22. 枚举Enum
- 3. FP
- 3.1. 函数
- 3.1.1. 函数定义
- 3.1.2. 映射式定义
- 3.1.3. 特殊函数名 + - * /
- 3.1.4. 缺省参数、命名参数
- 3.1.5. 函数调用
- 3.1.6. 匿名函数
- 3.1.7. 偏函数
- 3.1.8. “_”匿名参数
- 3.1.9. 变长参数 *
- 3.1.10. lazy参数
- 3.2. 函数式编程
- 3.2.1. 风格
- 3.2.2. 函数作为参数
- 3.2.3. 函数作为返回值
- 3.2.4. Curry化
- 3.2.5. 递归
- 3.2.6. 尾-递归
- 4. OOP
- 4.1. 类class
- 4.1.1. 定义
- 4.1.2. 构造方法
- 4.1.3. override
- 4.1.4. object单例对象
- 4.1.5. 静态方法
- 4.1.6. case class(条件类)
- 4.1.7. case object(条件单例对象)
- 4.1.8. 枚举
- 4.1.9. 属性和Bean
- 4.1.10. 反射
- 4.2. trait超级接口
- 4.2.1. trait使用
- 4.2.2. mixin
- 4.3. 协变和逆变(co-|contra-)variance
- 4.3.1. 概念
- 4.3.2. 类型上下界
- 4.3.3. 协变、逆变结合上下界
- 5. util包
- 5.1. 架构
- 5.2. 集合Array,List,Tuple
- 5.2.1. 定义和初始化
- 5.2.1.1 Array
- 5.2.1.2 List
- 5.2.1.3 Vector
- 5.2.1.4 Tuple
- 5.2.1.5 Range
- 5.2.1.6 Stream
- 5.2.1.7 Stack Queue
- 5.2.2. 使用(map, flatMap, filter, exists等)
- 5.2.2.1 map
- 5.2.2.2 filter filterNot
- 5.2.2.3 partition span splitAt groupBy
- 5.2.2.4 foreach
- 5.2.2.5 exists
- 5.2.2.6 find
- 5.2.2.7 sorted sortWith sortBy
- 5.2.2.8 distinct
- 5.2.2.9 flatMap
- 5.2.2.10 indices,zipWithIndex
- 5.2.2.11 take drop splitAt
- 5.2.2.12 count
- 5.2.2.13 updated patch
- 5.2.2.14 reverse reverseMap
- 5.2.2.15 contains startsWith endWith
- 5.2.2.16 集合运算
- 5.2.2.17 殊途同归
- 5.2.2.18 其他
- 5.2.3. 数组元素定位
- 5.2.4. view
- 5.2.5. 和Java集合间的转换(scalaj)
- 5.3. Map
- 5.3.1. 定义Map
- 5.3.2. 不可变Map(缺省)
- 5.3.3. 可变Map
- 5.3.4. Java的HashMap
- 5.3.5. 读取所有元素
- 5.3.6. 多值Map
- 5.4. Set
- 5.4.1. 定义
- 5.4.2. 逻辑运算
- 5.4.3. 可变BitSet
- 5.5. Iterator
- 5.6. Paralllel collection
- 6. io
- 6.1. 文件I/O
- 6.1.1. 读文件
- 6.1.2. 写文件
- 6.1.3. 复制文件
- 6.1.4. 全目录扫描
- 6.2. 网络I/O
- 7. actor
- 7.1. actor模型
- 7.2. 多核计算
- 7.3. Actor用法
- 7.4. 方式1:接受receive
- 7.5. 方式2:接受react, loop
- 7.6. REPL接受消息
- 7.7. actor最佳实践
- 7.7.1. 不阻塞actor
- 7.7.2. actor之间用且仅用消息来通讯
- 7.7.3. 采用不可变消息
- 7.7.4. 让消息自说明
- 7.8. 不同jvm间的消息访问
- 7.9. STM
- 8. misc
- 8.1. xml
- 8.1.1. 生成
- 8.1.2. xml文件
- 8.1.3. 读取:
- 8.1.4. 访问属性
- 8.1.5. 格式化输出
- 8.2. json
- 8.3. Configgy
- 8.4. 正则表达式regex
- 8.5. GUI
- 8.5.1. java方式
- 8.5.2. scala方式
- 9. 附录
- 9.1. stackoverflow的scala教程
- 9.2. ProjectEuler
- 9.3. Scala问答
- 9.4. rosettacode
- 9.5. 编译、mvn、SBT
- 9.6. Scala水平划分
- 9.7. Scala适合的领域
- 9.8. Twitter的Scala School
Scala的向后兼容性没有Java那么谨慎,2.8+相对于2.7有很大变化,本文档针对2.8+
这只是份简单的笔记,本不应敝履自珍,但手痒难耐还是写点废话在前面。
若能给同样对Scala感兴趣的IT人一些帮助,本人必感欣慰。
4.3. 协变和逆变(co-|contra-)variance
1. Scala有多cool
“Put productivity & creativity back in the hands of developers”
Scala is a tour de force of language design.
1.1. 速度!
Java的运行速度
——基于JVM,和Java运行速度相当。看看Ruby、Perl、Python对大项目运行效率的无奈,就知道有个好的编译器(Scalac)和运行时(JVM)是多么美好。
Python/Ruby的编程速度
——有更多的内建库和数据结构,编程就更快,Scala在完全继承Java和.NET的标准库的基础上,还扩展了更丰富有用的函数库。看看C++、D、Go等语言库的发展情况(不是匮乏就是混乱),就知道从头创建如Java、.NET这般庞大全面的类库并非易事;
类库和运行速度有关系吗?——很大程度上有,众多专家已经在类库中准备了充分优化的稳定算法,Scala对Java Collection算法进行直接包装或者直接调用,如果没有丰富的类库,你在项目周期内免不了摘抄一些不一定靠谱的算法和功能代码,这些代码极有可能在运行时给你带来麻烦。使用类库算法,不用担忧自造轮子的运行效率。
Scala是静态语言,Scalac和Javac是同一作者,编译成.class后运行于JVM平台,近20年那么多大公司投入进行的优化也不是白搭。对于大部分的应用来说,使用Scala不用再顾虑运行速度,它可能不是最快,但至少逼近Java,而不像Groovy、JRuby、Jython那般与Java有高达数十倍的效率差距。
1.2. 易用的数据结构
List-Map-Tuple及其丰富特性支持让你解决数据结构问题时游刃有余。
List(1,31,4,3,53,4,234) filter (10<) filter (100>) // List(31, 53)
val (a,b) = List(1, 31,4,3,53,4,234) partition (10>) // a=List(1,4,3,4), b=List(31,53,234)
def info(p:Person) = (name, age, email) // info._1, info._2, info._3
1.3. OOP+FP
l 适当地选用OOP或者FP,能够使表达相对另一种更加清晰准确。
l 实际可见的生产力在于:一个应用中的部分代码尤其是高知识凝聚的代码如数学函数和设计模式,一般来说不会自己编写,而是会来自于现成的Java库,或者其他语言,或者伪代码。我们可以很容易地把过程语言、面向对象语言、函数式语言中的代码“翻译”成Scala代码。试想如果我们要把Haskell或者Lisp的某个尾递归算法翻译成Java代码,还得多花点时间;而要把C++的代码翻译成Hashkell,同样也不简单。Scala的混血性给我们的实际使用提供了便利。
l 语言特色能够塑造编程者的思维: C++也能使用抽象基类设计多重继承,但Java的接口引导你走得更远;Java也能设计类型安全的静态方法(final static),但Scala鼓励你这样做并逐步从OOP到达FP的彼岸,而且来去自如。
1.4. 动态+静态
Scala虽然是一门彻头彻底的静态语言,但又具备了现代动态语言的很多方便和灵活:
l 不需要冗余的类型声明
l 可以在已有类上增加新方法(implicit转换和Dynamic trait)
l 可以把不继承共同父类的不同类型对象传到方法中
l 可以做静态语言的Refactoring
l 不用象动态语言那样测试代码比业务代码还多
l 代码自动完成(REPL和IDE)
l 编译静态语言的性能
l Read-Eval-Print Loop交互解释器(注:Linux下的用户体验远好于Windows下)
1.5. DSL
Scala可以把xml/html处理、数学公式表达、SQL查询等包装的更优雅、更合理,为使用者提供更好的API。这也使Scala的程序也更可读,从而更易于维护。
1.6. 够复杂
不同的思考模式:Java是先写后想,Scala是先想后写(其实FP大都如此)。
Scala相比于Java,可能达不到10倍的代码精简;但读Scala代码的效率一般只有Java的1/10——可见Java是一门没有多少特例的简单语言,而Scala则不然。
你不要指望把Scala作为初学者的第一门编程语言,这门语言甚至不是初级程序员能够掌控的——换句话说,能够读懂和写Scala代码,说明你是一个不折不扣的资深程序员,或者更准确一点,是资深Java程序员。
|
|
|
|
|
ð |
|
简单的Java(Morse码,定型的玩具车) |
复杂的Scala(智能机,乐高积木) |






1.7. 够有趣
还看这句话:“Put productivity & creativity back in the hands of developers”。其实不仅限于Scala,对于所有的编程语言来说,一门语言是否“好玩”有趣,能否激起创作欲,才是最关键的,这比语言风格、运行速度、工具支持、社区文化都来得重要。
回想我使用过的语言,C、C++,只有在学习“图形学”课程做作业的时候给我“好玩”和编程过瘾的感觉;VB、Delphi、Lotus Script/Formular、JavaScript,重来没有给过我“好玩”的感觉,而Java是在之前很长一段时间内让我觉得最“好玩”的语言,用它编游戏、做模式识别的作业、做产品……,乐在其中。但是Java也许久没有再给我这种编程过瘾的感觉了。之前发现Groovy的时候,我以为又找到一门好玩的语言了,但我一段时间使用之后,发现不是我的菜(Perl、Python、Ruby也如此);我不是说那些我不觉得好玩的语言不好,有其他很多人觉得他们非常“好玩”,并且用它们创建了无数杀手级的、伟大的、有用的程序。
有些人对一门语言会玩一辈子,就像Lisp、Haskell和Smalltalk的拥趸;而有些人会不断寻找下一个玩意儿,就像原来玩Java的一些人发现更好玩的Ruby和Python之后,倒戈狂喷Java,力挺后者;Groovy/Grails的玩家在很短的时间里面,写了无数的扩展和Plugin应用;学习Scala,能很多好玩的地方,能用它有激情地去写一些振奋人心的应用出来!
1.8. 开发社区
Scala开发/用户社区气氛良好,基本都是资深开发者以及有一定经验的用户,不会碰到太弱智的事(提问、争吵),除了语言和工具开源免费,最权威和最好的书也都是免费的(包括Lift社区)
2. lang
2.1. 和Java的异同
2.1.1. 语法
|
Java++:增加的语法 |
Java--:删减的语法 |
|
纯OO |
静态成员 |
|
操作符重载 |
原生数据类型 |
|
closure |
break、continue |
|
使用trait进行mixin组合 |
接口 |
|
existential type(_) |
通配符List<?>, import pkg.*; |
|
抽象类型 (type T) |
原始类型 class C1<T> {...} |
|
模式匹配 |
enum枚举 |
existential type——和Java互操作时进行对应
Iterator<? extends Component> --> Iterator[T] { type T <: Component }或者Iterator[_]
2.1.2. 库
def using[T <: { def close() }] (res:T)(block:T=>Unit) = {
try { block(res) } finally { if(res!=null) res.close }}
using (new BufferedReader(new FileReader(path))) { f=> println(f.readLine) }
val f = new BufferedReader(new FileReader(path)
try { println(f.readLine) } finally { if (f!=null) f.close }
2.2. 变量
2.2.1. 保留字
finally for if implicit import
match new null object override
package private protected requires return
Scala调用Java的方法时,会碰到有Scala的保留字,如Thread.yield()
这在Scala中是非法的,专门有个解决办法,写成: Thread.`yield`()
2.2.2. 变量标识
这些标识在Java中是非法的,在Scala中是合法的,可以当作函数名使用,使接口更加DSL:
2.2.3. 变量定义
2.2.3.1 val, var
var 可变,可重新赋值,赋值为"_"表示缺省值(0, false, null),例如:
val 不可变,相当于const/final,但如果val为数组或者List,val的元素可以赋值;
提示:向函数式风格推进的一个方式,就是尝试不用任何var来定义变量。
2.2.3.2 花样定义
val (x,y) = (10, "hello") // 同时定义多个变量,注意:val x,y=10,"hello" 是错误的
val x::y = List(1,2,3,4) // x = 1, y = List(2,3,4)
val List(a,b,c) = List(1,2,3) // a = 1, b = 2, c = 3
val Array(a, b, _, _, c @ _*) = Array(1, 2, 3, 4, 5, 6, 7) // 也可以用List,Seq
c // Array(5, 6, 7), _*匹配0个到多个
val regex = "(\\d+)/(\\d+)/(\\d+)".r
val regex(year, month, day) = "2010/1/13"
2.2.3.3 lazy, val, def的区别
|
val |
定义时就一次求值完成,保持不变 |
val f = 10+20 // 30 |
|
lazy |
定义时不求值,第一次使用时完成求值,保持不变 |
lazy f = 10+20 // <lazy> f // 30 |
|
def |
定义时不求值,每次使用时都重新求值 |
def f = 10+20 // 30 def t = System. currentTimeMillis // 每次不一样 |
scala> val f1 = System.currentTimeMillis
f1: Long = 1279682740376 // 马上求值
res94: Long = 1279682740376 // 之后保持不变
scala> lazy val f2 = System.currentTimeMillis
scala> System.currentTimeMillis
res96: Long = 1279682766545 // 第一次使用时求值,注意:6545 > 4297
res97: Long = 1279682766545 // 之后保持不变
scala> def f3 = System.currentTimeMillis
res98: Long = 1279682784478 // 每次求值
res99: Long = 1279682785352 // 每次求值
2.3. 基本类型
尽量使用大写形式: Int, Long, Double, Byte, Short, Char, Float, Double, Boolean
编译时Scala自动对应到Java原始类型,提高运行效率。Unit对应java的void
用 asInstanseOf[T]方法来强制转换类型:
def i = 10.asInstanceOf[Double] // i: Double = 10.0
List('A','B','C').map(c=>(c+32).asInstanceOf[Char]) // List('a','b','c')
用isInstanceOf[T]方法来判断类型:
val b = 10.isInstanceOf[Int] // true
而在match ... case 中可以直接判断而不用此方法。
用Any统一了原生类型和引用类型。

2.3.1. Int
2.3.2. Char
在String上做循环,其实就是对String中的每一个Char做操作,如:
"12345" map (toInt) // (49,50,51,52,53)
('a' to 'f') map (_.toString*3) // (aaa, bbb, ccc, ddd, eee, fff)
2.4. BigInt
可以表示很大的整数:
BigInt(10000000000000000000000000) // 报错
BigInt("10000000000000000000000000") // scala.math.BigInt = 10000000000000000000000000
例如:
def fac(n:Int):BigInt = if (n==0) 1 else fac(n-1)*n
fac(1000)
或者写成:
def fac2(n:Int) = ((1:BigInt) to n).product
// res1: BigInt = 9332621544394415268169923885626670049071596826438......000000000000000000
2.5. 字符串
"..." 或者 """...""""
println("""|Welcome to Ultamix 3000.
|Type "HELP" for help.""".stripMargin)
输出:
Welcome to Ultamix 3000.
Type "HELP" for help.
scala中,字符串除了可以+,也可以*
"abc" * 3 // "abcabcabc"
"abc" * 0 // ""
例子:
"google".reverse // "elgoog"
"abc".reverse.reverse=="abc" // true
例子:
"Hello" map (_.toUpper) // 相当于 "Hello".toUpperCase
2.5.1. 类型转换
"101".toInt // 101,无需 Integer.parseInt("101");
List("1","2","3") map (_.toInt) // List(1,2,3)
List("1","2","3") map Integer.parseInt // List(1,2,3)
2.5.2. StringBuilder
2.5.3. 文本格式化
使用java.text.MessageFormat.format:
val msg = java.text.MessageFormat.format(
"At {1,time} on {1,date}, there was {2} on planet {0}.",
"Hoth", new java.util.Date(), "a disturbance in the Force")
At 17:50:34 on 2010-7-20, there was a disturbance in the Force on planet Hoth.
"my name is %s, age is %d." format ("james", 30) // my name is james, age is 30.
"%s-%d:%1$s is %2$d." format ("james", 30) // james-30:james is 30.
"%2$d age's man %1$s: %2$d" format ("james", 30) // 30 age's man james: 30
2.6. Null, None, Nil, Nothing
|
Null |
Trait,其唯一实例为null,是AnyRef的子类,*不是* AnyVal的子类 |
|
Nothing |
Trait,所有类型(包括AnyRef和AnyVal)的子类,没有实例 |
|
None |
Option的两个子类之一,另一个是Some,用于安全的函数返回值 |
|
Unit |
无返回值的函数的类型,和java的void对应 |
|
Nil |
长度为0的List |
2.7. ==和eq
Scala的==很智能,他知道对于数值类型要调用Java中的==,ref类型要调用Java的equals()
"hello"=="Hello".toLowerCase()
在java中为false,在scala中为true
Scala的==总是内容对比
|
基本类型Int,Double, |
比值 |
|
其他类型 |
相当于A.equals(B) |
eq才是引用对比
例如:
val s1,s2 = "hello"
val s3 = new String("hello")
s1==s2 // true
s1 eq s2 // true
s1==s3 // true 值相同
s1 eq s3 // false 不是同一个引用
2.8. Option[T]
2.8.1. 概念
l Option[T]可以是任意类型或者空,但一旦声明类型就不能改变;
l Option[T]可完美替代Java中的null,可以是Some[T]或者None;
l Option实现了map, flatMap, and filter 接口,允许在 'for'循环里使用它;
|
没有Option的日子 |
现在 |
|
def find(id:Long):Person = ... |
def find(id:Long):Option[Person] = ... |
|
返回Person或者null |
返回Some[Person]或者None |
|
返回null不特殊处理会抛:NullPointerExceptions |
返回值直接getOrElse或者列表操作 |
|
类比:Java的Stringx.split返回null |
类比:Java的Stringx.split返回new String[0] |
|
结论:函数永远不要返回null值,如果输入有问题或者抛异常,返回Option[T] |
|
没有Option的日子 |
现在 |
|
def blank(s:String) = if (s==null) false else { s.toList.forall(_.isWhitespace) } |
def blank(s:String) = Option(s).toList.forall( _.forall(_.isWhitespace)) |
|
结论:尽可能地不要浪费代码去检测输入,包装成Option[T]来统一处理 |
2.8.2. 使用
def p(map:Map[Int,Int]) = println(map(3))
def p(map:Map[Int,Int]) = println(map get 3 getOrElse "...")
2.8.3. 例子
Map((1,100),(2,200),(3,300)) get(k) match {
"not found"
}
}
def main(args : Array[String]) : Unit = {
println(m(1)) // 100
println(m(2)) // 200
println(m(3)) // 300
println(m(4)) // "not found"
println(m(-1)) // "not found"
}
例子2:
val l = List(Some(100), None, Some(200), Some(120), None)
for (Some(s) <- l) yield s // List(100, 200, 120)
或
l flatMap (x=>x) // List(100, 200, 120)
例子3: Option结合flatMap
def toint(s:String) =
try { Some(Integer.parseInt(s)) } catch { case e:Exception => None }
List("123", "12a", "45") flatMap toint // List(123, 45)
List("123", "12a", "45") map toint // List(Some(123), None, Some(45))
2.9. 区分<-,=>,->
|
<- |
for (i <- 0 until 100) |
用于for循环, 符号∈的象形 |
|
=> |
List(1,2,3).map(x=> x*x) ((i:Int)=>i*i)(5) // 25 |
用于匿名函数,相当于Ruby的 |x|,Groovy的{x-> x*x} 也可用在import中定义别名:import javax.swing.{JFrame=>jf} |
|
-> |
Map(1->"a",2->"b") |
用于Map初始化, 也可以不用->而写成 Map((1,"a"),(2,"b")) |
2.10. match..case(switch)
2.10.1. 和switch..case的区别
case "a" | "b" => ... // 这个比较好
每个case..=>结束不用写break了,_相当于default
2.10.2. 匹配数据类型
match 可以很简单地匹配数据类型(不需要isInstanceOf[T]):
2.10.3. 命令行参数解析例子
/** Basic command line parsing. */
object Main {
var verbose = false // 记录标识,以便能同时对-h和-v做出响应
def main(args: Array[String]) {
for (a <- args) a match {
case "-h" | "-help" =>
println("Usage: scala Main [-help|-verbose]")
case "-v" | "-verbose" =>
verbose = true
case x => // 这里x是临时变量
println("Unknown option: '" + x + "'")
}
if (verbose) println("How are you today?")
}
}
2.10.4. 使用case的递归函数
def fac(n:Int):Int = n match {
写法3(使用尾递归):
}
fac(5,1) // 120
写法4(reduceLeft+!):
def fac(n:Int) = 1 to n reduceLeft(_*_)
implicit def foo(n:Int) = new { def ! = fac(n) }
5! // 120
写法5:(最简洁高效)
def fac(n:Int) = (1:BigInt) to n product
fac(5) // 120
2.10.5. 变量匹配
常量匹配很简单,即case后跟的都是常量;
变量匹配需要注意,case后跟的是match里面的临时变量,而不是其他变量名:
3 match {
case i => println("i=" + i) // 这里i是模式变量(临时变量),就是3
}
val a = 10
20 match { case a => 1 } // 1, a是模式变量,不是10
为了使用变量a,必须用`a`:
20 match { case `a` => 1; case b => -1 } // -1,`a`是变量10
或者用大写的变量:
val A = 10
20 match { case A => 1; case b => -1 } // -1,大写A是变量10
2.10.6. case..if条件匹配
写法1:
(1 to 20) foreach { case x if (x % 15 == 0) => printf("%2d:15n\n",x) case x if (x % 3 == 0) => printf("%2d:3n\n",x) case x if (x % 5 == 0) => printf("%2d:5n\n",x) case x => printf("%2d\n",x) }
写法2:
(1 to 20) map (x=> (x%3,x%5) match {
case (0,0) => printf("%2d:15n\n",x)
case (0,_) => printf("%2d:3n\n",x)
case (_,0) => printf("%2d:5n\n",x)
case (_,_) => printf("%2d\n",x)
})
2.11. try..catch..finally
var f = openFile()
try {
f = new FileReader("input.txt")
} catch {
case ex: FileNotFoundException => // Handle missing file
case ex: IOException => // Handle other I/O error
} finally {
f.close()
}
2.12. require
def f(n:Int) = { require(n!=0); 1.0/n }
def f(n:Int) = { require(n!=0, "n can't be zero"); 1.0/n }
f(0)
// java.lang.IllegalArgumentException: requirement failed: n can't be zero
2.13. main方法
Scala的main方法(包括所有类似java的static方法)必须定义在一个object内:
object Test1 {
def main(args: Array[String]) {
println("hello world")
}
}
编译:
fsc Test1.scala // 常驻内存编译服务器,第一次转载之后比scalac快
运行:
scala Test1.scala // 方式1,没有输出
scala -cp e:\scala\lib\scala-library.jar Test1 // 方式2,慢
java -cp e:\scala\lib\scala-library.jar Test1 // 方式3,快
如果文件不是utf8编码,执行需要使用.scala文件的编码,如:
scala -encoding gbk test.scala
2.13.1. Application
object app1 extends Application {
2.14. package, import
2.14.1. import
可以格式 “import javax.swing.{JFrame=>jf}”来声明类型的别名。
l import java.util.{List, Map}
l import java.util._, java.io._
由于Scala的package可以是相对路径下定义,有可能命名冲突,可以用:
2.14.2. package
package com.wr3 { // C# 和Ruby的方式,也可以改用Java的方式
// import java.nio._ // "*" 是scala的正常函数名,所以用_
def m1() { println("c1.m1()") }
def main(args: Array[String]) {
2.14.3. 包对象
Scala2.8+支持包对象(package object),除了和2.8之前一样可以有下级的object和class,还可以直接有下级变量和函数,例如:
-------------------------------- foo.scala
def main(args:Array[String]):Unit = printf("%s", p0.p1.b)
--------------------------------
2.15. if..else
没有java的:
b = (x>y) ? 100 : -1
就用:
if (x>y) 100 else -1
2.16. 循环操作
|
map |
m->m |
|
flatMap |
m->n |
|
indices |
m->m |
|
foreach |
m->Unit |
|
for (... if ...) yield |
m->n |
|
collect { case ... if ... => ... } |
m->n |
|
filter, filterNot |
m->n |
|
take |
m->n |
|
takeWhile |
m->n |
|
forall |
m->1 (true|false) |
|
reduceLeft, foldLeft |
m->1 |
|
scanLeft |
m->m+1 |
|
exists |
m->1 (true|false) |
|
find |
m->1 (或者None) |
|
count |
m->1 |
|
span, partition |
m->2 |
2.16.1. for
for(i<-1 to 10; j=i*i) println(j)
for (i <- 0 to n) foo(i) // 包含n,即Range(0,1,2,...,n,n+1)
for (i <- 0 until n) foo(i) // 不包含n,即Range(0,1,2,3,...,n)
for (n<-List(1,2,3,4) if n%2==1) yield n*n // List(1, 9)
for (n<-Array(1,2,3,4) if n%2==1) yield n*n // Array(1, 9)
var s = 0; for (i <- 0 until 100) { s += i } // s = 4950
List(1,2,3,4).filter(_%2==1).map(n => n*n)
for(i<-0 to 5; j<-0 to 2) yield i+j
// Vector(0, 1, 2, 1, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5 , 6, 5, 6, 7)
def triangle(n: Int) = for { x <- 1 to 21 y <- x to 21 z <- y to 21 if x * x + y * y == z * z } yield (x, y, z)
// Vector((3,4,5), (5,12,13), (6,8,10), (8,15,17), (9,12,15), (12,16,20))
2.16.1. for .. yield
for (e<-List(1,2,3)) yield (e*e) // List(1,4,9)
for {e<-List(1,2,3)} yield { e*e } // List(1,4,9)
for {e<-List(1,2,3)} yield e*e // List(1,4,9)
for (e<-List(1,2,3)) { yield e*e } // 语法错误,yield不能在任何括号内
2.16.2. foreach
1 to (11,2) // 1,3,5,7,9,11 步长为2
val r = (1 to 10 by 4) // (1,5,9), r.start=r.first=1; r.end=10, r.last=9
2.16.3. forall
"所有都符合"——相当于 A1 && A2 && A3 && ... && Ai && ... && An
(-1 to 3) forall (0<) // false
def isPrime(n:Int) = 2 until n forall (n%_!=0)
for (i<-1 to 100 if isPrime(i)) println(i)
(2 to 20) partition (isPrime _) // (2,3,5,7,11,13,17,19), (4,6,8,9,10,12,14,15,16,18,20)
(2 to 20) partition (BigInt(_) isProbablePrime(10))
// 注:isProbablePrime(c)中c越大,是质数的概率越高,10对应概率:1 - 1/(2**10) = 0.999
2.16.4. reduceLeft
reduceLeft 方法首先应用于前两个元素,然后再应用于第一次应用的结果和接下去的一个元素,等等,直至整个列表。例如
def fac(n: Int) = 1 to n reduceLeft(_*_)
List(2,4,6).reduceLeft(_+_) // 12
相当于:
((2+4)+6)
取max:
List(1,4,9,6,7).reduceLeft( (x,y)=> if (x>y) x else y ) // 9
或者简化为:
List(1,4,9,6,7).reduceLeft(_ max _) // 9
相当于:
((((1 max 4) max 9) max 6) max 7)
2.16.5. foldLeft scanLeft
def sum(L: List[Int]): Int = {
def sum(L: Seq[Int]) = L.foldLeft(0)((a, b) => a + b)
def sum(L: Seq[Int]) = L.foldLeft(0)(_ + _)
def sum(L: List[Int]) = (0/:L){_ + _}
def multiply(L: Seq[Int]) = L.foldLeft(1)(_ * _)
multiply(Seq(1,2,3,4,5)) // 120
2.16.6. scanLeft
List(1,2,3,4,5).scanLeft(0)(_+_) // (0,1,3,6,10,15)
(0,(0+1),(0+1+2),(0+1+2+3),(0+1+2+3+4),(0+1+2+3+4+5))
List(1,2,3,4,5).scanLeft(1)(_*_) // (1,2,6,24,120)
(1, 1*1, 1*1*2, 1*1*2*3, 1*1*2*3*4, 1*1*2*3*4*5)
l (z /: List(a, b, c))(op) 相当于 op(op(op(z, a), b), c)
l (List(a, b, c) :\ z) (op) equals op(a, op(b, op(c, z)))
2.16.7. take drop splitAt
1 to 10 by 2 take 3 // Range(1, 3, 5)
1 to 10 by 2 drop 3 // Range(7, 9)
1 to 10 by 2 splitAt 2 // (Range(1, 3),Range(5, 7, 9))
def prime(n:Int) = (! ((2 to math.sqrt(n).toInt) exists (i=> n%i==0)))
2.16.8. takeWhile, dropWhile, span
|
takeWhile (...) |
等价于:while (...) { take } |
|
dropWhile (...) |
等价于:while (...) { drop } |
|
span (...) |
等价于:while (...) { take; drop } |
1 to 10 takeWhile (_<5) // (1,2,3,4)
10 to (1,-1) takeWhile(_>6) // (10,9,8,7)
1 to 10 takeWhile (n=>n*n<25) // (1, 2, 3, 4)
val rt = (1 to 10).takeWhile(e=> {sum=sum+e;sum<30}) // Range(1, 2, 3, 4, 5, 6, 7)
注意:takeWhile中的函数要返回Boolean,sum<30要放在最后;
1 to 10 dropWhile (_<5) // (5,6,7,8,9,10)
1 to 10 dropWhile (n=>n*n<25) // (5,6,7,8,9,10)
1 to 10 span (_<5) // ((1,2,3,4),(5,6,7,8)
List(1,0,1,0) span (_>0) // ((1), (0,1,0))
List(1,0,1,0) partition (_>0) // ((1,1),(0,0))
2.16.9. break、continue
Scala中没有break和continue语法!需要break得加辅助boolean变量,或者用库(continue没有).
var i=0; val rt = for(e<-('a' to 'z') if {i=i+1;i<=10}) printf("%d:%s\n",i,e)
('a' to 'z').slice(0,10).foreach(println)
var (n,sum)=(0,0); for(i<-0 to 100 if (sum+i<1000)) { n=i; sum+=i }
import scala.util.control.Breaks._
for(e<-1 to 10) { val e2 = e*e; if (e2>10) break; println(e) }
2.17. 操作符重载
注意:其实Scala没有操作符,更谈不上操作符重载;+-/*都是方法名,如1+2其实是(1).+(2)
object operator {
class complex(val i:Int, val j:Int) { // val 是必须的
def + (c2: complex) = {
new complex (i+c2.i, j+c2.j)
}
override def toString() = { "(" + i + "," + j + ")" }
}
def main(args:Array[String]) = {
val c1 = new complex(3, 10)
val c2 = new complex(5, 70)
printf("%s + %s = %s", c1, c2, c1+c2)
}
}
编译:fsc operator.scala
运行:java operator // (3,10) + (5,70) = (8,80)
2.18. 系统定义scala._
scala._自动加载,只有发生类名冲突时才需要带上scala.包名。
|
scala.AnyValue |
所有基本类型的根 |
Int,Char,Boolean,Double,Unit |
|
scala.AnyRef |
所有引用类型的根 |
相当于java的java.lang.Object |
|
scala.Null |
所有引用类型的子类 |
|
|
scala.Nothing |
所有全部类型的子类 |
|
|
scala.List |
不可变的List |
scala特色的不可变List |
|
scala.Int |
scala中可以用int作为别名 |
Double,Float等类似 |
2.19. implicit隐式转换
用途:
l 把一种object类型安全地自动转换成另一种object类型;
l 不改动已有class设计即可添加新的方法;
2.19.1. 类型转换
implicit def foo(s:String):Int = Integer.parseInt(s) // 需要时把String->Int
add("100",8) // 108, 先把"100"隐式转换为100
2.19.2. 例子:阶乘n!
def factorial(x: Int) = 1 to n reduceLeft(_*_)
implicit def m2(n:Int) = new m1(n) // 隐式转换,即在需要时把n转换为new m1(n)
implicit def m2(n:Int) = new { def ! = factorial(n) }
printf("%d! = %s\n", n, (n!)) // n! 相当于 new m1(n).!()
2.19.3. 例子:cout
implicit def foo(p:PrintStream) = new C1(p)
System.out<<"hello"<<" world"<<endl
2.19.4. 例子:定义?:
implicit def elvisOperator[T](alt: T) = new {
def ?:[A >: T](pred: A) = if (pred == null) alt else pred
}
(null ?: 0).asInstanceOf[Int] // 0
2.19.5. 已有Object加新方法
implicit def foo1[T](list: List[T]) = new {
def join(s:String) = list.mkString(s)
def main(args : Array[String]) : Unit = {
Console println List(1,2,3,4,5).join(" - ") // " 1 - 2 - 3 - 4 – 5"
编译器发现List没有join(String)方法,就发查找代码中有没有定义在implicit def xx(List)内的 join(String)方法,如果有就调用这个。
def pow(n:Int, m:Int):Int = if (m==0) 1 else n*pow(n,m-1)
implicit def foo(n:Int) = new {
implicit def foo(n:Int) = new { def next = n+1 }
2.20. type做alias
相当于C语言的类型定义typedef,建立新的数据类型名(别名);在一个函数中用到同名类时可以起不同的别名
例如:
type JDate = java.util.Date
type SDate = java.sql.Date
val d1 = new JDate() // 相当于 val d = new java.util.Date()
val d2 = new SDate() // 相当于 val d = new java.sql.Date()
注意:type也可以做泛型
2.21. 泛型
2.21.1. 函数中的泛型:
def foo[T](a:T) = println("value is " + a)
foo("hello") // "value is hello"
2.21.2. 类中的泛型:
private var v:T = _ // 初始值为T类型的缺省值
new C1[String].set("hello").get // "hello"
2.21.3. 泛型qsort例子
def qsort[T <% Ordered[T]](a:List[T]): List[T] = if (a.size<=1) a else {
qsort(a.filter(m>)) ++ a.filter(m==) ++ qsort(a.filter(m<))
val a = List(1, 3, 6, 2, 0, 9, 8, 7, 2)
val b = List(1.0, 3.3, 6.2, 6.3, 0, 9.5, 8.7, 7.3, 2.2)
List(1, 3, 6, 2, 0, 9, 8, 7, 2) sortWith(_<_)
List(1.0, 3.3, 6.2, 6.3, 0, 9.5, 8.7, 7.3, 2.2).sortWith(_<_)
2.21.4. 泛型add例子
def add[T](x:T, y:T)(implicit n:Numeric[T]) = {
n.plus(x,y) // 或者用 import n._; x + y
def max2[T](x:T, y:T)(implicit n:Numeric[T]) = {
2.21.5. 泛型定义type
def m2(e1:List[Int]) = new C2 {
Console println m1(10) // 10
Console println m2(List(1,2,3,4,5)).len // 5
注意:type也可以做数据类型的alias,类似C语言中的typedef
2.21.6. @specialized
def test[@specialized(Int,Double) T](x:T) = x match { case i:Int => "int"; case _ => "other" }
没有@specialized之前,是编译成Object的代码;用了@specialized,变成IntTest(),DoubleTest(),...
编译后的文件尺寸扩充了,但性能也强了,不用box,unbox了
2.22. 枚举Enum
Scala没有在语言层面定义Enumeration,而是在库中实现:
例子1:
object Color extends Enumeration {
type Color = Value
val RED, GREEN, BLUE, WHITE, BLACK = Value
}
Color.RED // Color.Value = RED
import Color._
val colorful = Color.values filterNot (e=> e==WHITE || e==BLACK)
colorful foreach println // RED\nGREEN\nBLUE
例子2:
object Color extends Enumeration {
val RED = Value("红色")
val GREEN = Value("绿色")
val BLUE = Value("蓝色")
val WHITE = Value("黑")
val BLASK = Value("白")
}
Color.RED // Color.Value = 红色
import Color._
val colorful = Color.values filterNot (List("黑","白") contains _.toString)
colorful foreach println //红色\n绿色\n蓝色
3. FP
3.1. 函数
函数的地位和一般的变量是同等的,可以作为函数的参数,可以作为返回值。
传入函数的任何输入是只读的,比如一个字符串,不会被改变,只会返回一个新的字符串。
Java里面的一个问题就是很多只用到一次的private方法,没有和使用它的方法紧密结合;Scala可以在函数里面定义函数,很好地解决了这个问题。
3.1.1. 函数定义
函数和方法一般用def定义;也可以用val定义匿名函数,或者定义函数别名。
val m1 = (x:Int)=> x*x // ()是必须的
val m2 = {x:Int=> x*x} // 不用(), 用{}
不需要返回值的函数,可以使用def f() {...},永远返回Unit(即使使用了return),即:
def f() {...} 等价于 def f():Unit = {...}
def f() { return "hello world" }
需要返回值的函数,用 def f() = {...} 或者 def f = {...}
def f = { "hello world" } // f是匿名函数 {"hello world"}的别名
|
def f() { return .. } |
调用:f, f()皆可 |
始终返回:Unit |
|
def f() = ... |
调用:f, f()皆可 |
返回Unit或者值 |
|
def f = ... |
调用:f |
返回Unit或者值 |
提示:函数式风格——尽量编写有返回值的函数; 尽量简短(函数体不使用{...})
3.1.2. 映射式定义
一种特殊的定义:映射式定义(直接相当于数学中的映射关系);
其实也可以看成是没有参数的函数,返回一个匿名函数;调用的时候是调用这个返回的匿名函数。
例子1:
def f:Int=>Double = { // 请看做 def f: (Int=>Double) = {...}
case 1 => 0.1
case 2 => 0.2
case _ => 0.0
}
f(1) // 0.1
f(3) // 0.0
例子2:
def m:Option[User]=>User = {
case Some(x) => x
case None => null
}
m(o).getOrElse("none...")
例子3:(多->1)
def m:(Int,Int)=>Int = _+_
m(2,3) // 5
例子4:
def m:Int=>Int = 30+ // 相当于30+_,如果唯一的"_"在最后,可以省略
m(5) // 35
3.1.3. 特殊函数名 + - * /
注:unary :一元的,单一元素的, 单一构成的 。发音:【`ju: ne ri】
!true, 相当于:(true).unary_! // false
3.1.4. 缺省参数、命名参数
|
一般函数调用 |
命名函数调用 |
|
sendEmail( "jon.pretty@example.com", List("recipient@example.com"), "Test email", b, Nil, Nil, Nil) |
sendEmail( body = b, subject = "Test email", to = List("recipient@example.com"), from = "jon.pretty@example.com", attachments = List(file1, file2) ) |
def join(a:List[String], s:String="-") = { a.mkString(s) }
join(List("a","b","c")) // a-b-c
join(List("a","b","c"), ":") // a:b:c
join(s=":",a=List("a","b","c")) // a:b:c
3.1.5. 函数调用
def f(s: String = "default") = { s }
"hello world" toUpperCase // "HELLO WORLD"
"hello world" substring 5 // "world"
Console print 10 // 但不能写 print 10,只能print(10),省略Console.
"hello world" substring (0, 5) // "hello"
def main(args: Array[String]) = {
val ii = this m 15 // 等同于 m(15), this 不能省略
提示:这种调用方法最大的用途在于操作符重载,以及阅读性强的DSL。
Console println "hello world" // 省略Console则报错
3.1.6. 匿名函数
l 无返回值: ((命名参数列表)=>Unit)(参数列表)
((i:Int, j:Int) => i+j)(3, 4) // 7
(10*)(2) // 20, 相当于 ((x:Int)=>10*x)(2)
(10+)(2) // 12, 相当于 ((x:Int)=>10+x)(2)
(List("a","b","c") mkString)("=") // a=b=c
( ()=> {println("hello"); 20*10} )()
List(1,2,3,4).map(m) // List(1, 4, 9, 16)
def times3(m: ()=> Unit) = { m();m();m() }
times3 ( ()=> println("hello world") )
def times3(m: =>Unit) = { m;m;m } // 参见“lazy参数”
times3 ( println("hello world") )
3.1.7. 偏函数
用下划线代替1+个参数的函数叫偏函数(partially applied function),如:
def sum(a:Int,b:Int,c:Int) = a+b+c
val p2 = sum(10,_:Int,20) // 正确
(sum(_:Int,2,_:Int))(1,3) // 6
从上面可以看出,partial函数是一个正常函数中抽出来的一部分(参数不全),故称为partial函数。
3.1.8. “_”匿名参数
_:匿名函数中的匿名参数,同Groovy的it一样,groovy: 3.times { print it };但也有差别:
|
Groovy |
Scala |
|
|
同 |
print({it*10}(5)) // 50 |
((_:Int)*10)(5) // 50 强类型语言,必须标明类型为Int |
|
不同 |
def a = {it*it}(5) // 25 两个it完全一样 |
((_:Int)*(_:Int))(5,5) // 25 ((it:Int)=>it*it)(5) // 25 不能用:((_:Int)*(_:Int))(5) 两个_不一样,表示2个不同参数 |
注意:多个下划线指代多个参数,而不是单个参数的重复使用。第一个下划线代表第一个参数,第二个下划线代表第二个,第三个……,如此类推。
int add(int i, int j) { return i+j; }
((i:Int, j:Int) => i+j)(3, 4) // 7
"Hello".exists(_.isUpper) // true
例子2:
def sum(x:Int,y:Int,z:Int) = x+y+z
val sum1 = sum _
val sum2 = sum(1000,_:Int,100)
sum1(1,2,3) // 6
sum2(5) // 1105
如果_在最后,还可以省略
1 to 5 foreach println
1 to 5 map (10*)
1 to 5 map (*10) // 错误!_不在最后不能省
3.1.9. 变长参数 *
def sum(ns:Int*, s:String) = ... // 错误
def sum(ns:Int*) = ns.reduceLeft(_+_)
def m(args:Any*) = args foreach println
scala> m(3,3.14,"hello",List(1,2,3))
3.1.10. lazy参数
|
一般参数 |
lazy参数 |
|
def f1(x: Long) = { val (a,b) = (x,x) println("a="+a+",b="+b) } |
def f2(x: =>Long) = { val (a,b) = (x,x) println("a="+a+",b="+b) } |
|
f1(System.nanoTime) // a=140857176658355,b=140857176658355 |
f2(System.nanoTime) // a=140880226786534,b=140880226787666 |
|
一般参数 |
lazy参数 |
|
def times3(m: Unit) = { m;m;m } |
def times3(m: =>Unit) = { m;m;m } |
|
times3 ( println("hello world") ) // 打印1次 |
times3 ( println("hello world") ) // 打印3次 |
|
一般参数 |
lazy参数 |
|
def f(x:Int m: Unit) = { print(x*x); m } |
def f(x:Int, m: =>Unit) = { print(x*x); m } |
|
f(3,println("end")) // 先执行m,输出:"end\n9" |
f(3,println("end")) // lazy执行m,输出 “9end” |
def loop2 (cond: =>Boolean)(body: =>Unit): Unit =
if (cond) { body; loop2(cond)(body) }
var i=0; loop2 (i<3) (i+=1) // i=3
var i=0; loop2 {i<3} {i+=1} // i=3
def loop3 (body: =>Unit): foo = new foo(body)
def until(cond: =>Boolean) { body; if(!cond) until(cond) }
loop3 { i+=1; println(i) } until (i>3)
3.2. 函数式编程
3.2.1. 风格
|
非函数式 |
函数式 |
|
var s = "" if (args.length>0) s = args[0] |
val s = if (args.length>0) args[0] else "" |
|
def gcd(a0:Int,b0:Int) = { var a = a0; var b = b0 while(a!=0) { val t = a a = a % b b = t } return b } |
求a,b的最大公约数,所有的while循环基本都可以被替代: def gcd(a:Int,b:Int) = if (b==0) a else gcd(b, a % b) |
函数要短,可以试着所有的函数体都没有 {...} 包围,一旦出现,尽量分解
|
非函数式 |
函数式 |
|
for(i<-1 to 3; j<-1 to 3) { print(i*j + " "); if (j==3) println } |
def f(n:Int) = 1 to 3 map (_*n) mkString " " 1 to 3 map f mkString "\n" |
3.2.2. 函数作为参数
def f(x:Int, y:Int, m:(Int, Int)=>Int) = m(x,y)
f(3,4, (x,y)=>scala.math.sqrt(x*x+y*y)) // 5
def f(x:Int, y:Int, m: =>Unit) = { println(x*y); m } // 参见“lazy参数”
f(100+) // 105, 100+是匿名函数 ((x:Int)=>100+x)的简写
3.2.3. 函数作为返回值
def f(s:String):(Int => String) = { n:Int=> s * n }
f("*") // res32: (Int) => String = <function1>
f("*")(10) // 相当于先得到f("*")的返回值函数,再用该返回值函数调用一个参数
3.2.4. Curry化
def sum(a:Int, b:Int) = { a + b } // sum(1, 2) = 3
def sum(a:Int)(b:Int) = { a + b } // sum(1)(2) = 3
def sum(a:Int) = { (b:Int)=> a + b } // sum(1)(2) = 3
// 调用方式二:val t1 = sum(10); val t2 = t1(20)
3.2.5. 递归
其一是很多数学关系、逻辑关系本身就是递归描述(Hanoi、Fib)的;
|
递归出口 |
即递归的终止条件 比如0!=1, fib(1)=fib(2)=1, index==1000 |
|
递归体 |
即和前面或后面的值之间的关系 比如n! = n*(n-1)!, fib(n)=fib(n-2)+fib(n-1) |
如计算2^100, scala.math.pow(2,2000)越界,可用递归
def pow(n:BigInt, m:BigInt):BigInt = if (m==0) 1 else pow(n,m-1)*n
|
a(from) |
b(via) |
c(to) |
|
= --- 1 === ===== --- n-1 ======= --- n |
||
|
======= --- n |
= --- 1 === ===== --- n-1 |
|
|
= --- 1 === ===== --- n-1 |
======= --- n |
|
|
= --- 1 === ===== --- n-1 ======= --- n |
def move(n:Int, a:Int, b:Int, c:Int) = {
if (n==1) println("%s to %s" format (a, c)) else {
move(n-1, a,c,b); move(1,a,b,c); move(n-1,b,a,c) }}
def gcd(n:Int, m:Int):Int = if(m==0) n else gcd(m, n%m)
解法:迈出第一步有两种方法,第一步后就是N-1和N-2的走法了
def step(n:Int):Int = if (n<=2) n else step(n-1)+step(n-2)
def step(n:Int):Int = n match { case 1=>1; case 2=>2; case 3=>4;
case _ =>step(n-1)+step(n-2)+step(n-3) }
3.2.6. 尾-递归
tail-recursive会被优化成循环,所以没有堆栈溢出的问题。
def nn1(n:Int):BigInt = if (n==0) 1 else nn1(n-1)*n
println(nn1(1000)) // 4023...000
def nn2(n:Int, rt:BigInt):BigInt = if (n==0) rt else nn2(n-1, rt*n)
println(nn2(1000,1)) // 40...8896
println(nn2(10000,1)) // 2846...000
def nn3(n:Int):BigInt = nn2(n,1)
|
线性递归 |
尾递归 |
|
nn1(5) |
nn2(5, 1) |
|
不算,直到递归到一个确定的值后,又从这个具体值向后计算;更耗资源,每次重复的调用都使得调用链条不断加长. 系统使用栈进行数据保存和恢复 |
每递归一次就算出相应的结果。 |
|
不能优化成循环 |
可以优化成循环 |
def prime(n:Int) = 2 to math.sqrt(n).toInt forall (n%_!=0)
def next(p:Int) = p+1 to 2*p find prime get
def f(p:Int, i:Int):Int = if (i==10001) p else f(next(p), i+1)
def f2(p:Int):Stream[Int] = p #:: f2(next(p))
f2(2).take(10001).last // 104743
def fib2(n1:BigInt, n2:BigInt, i:Int, n:Int):BigInt =
if (i==n) n1 else fib2(n2, n1+n2, i+1, n)
def fib(n:Int) = fib2(1,1,0,n)
fib(100-1) // 第100个fib数=354224848179261915075
4. OOP
4.1. 类class
4.1.1. 定义
println(u.name + ", " + u.age) // "qh, 30"
//定义
class Person(ln : String, fn : String, s : Person = null) {
def lastName = ln; // 用def定义后才是属性,ln,fn,s不可见
def firstName = fn;
def spouse = s;
def introduction() : String =
return ("Hi, " + firstName + " " + lastName) +
(if (spouse != null) " and spouse, " + spouse.firstName + " " + spouse.lastName + "."
else ".");
}
// 调用
new Person("aa","bb", new Person("cc","dd")).introduction();
4.1.2. 构造方法
class c1(x:String) // 等同于:class c1(private var x:String)
o1.x // 报错,因为是private的,定义成 class c1(var x:String) 才能这样用
class c1(name:String, age:Int) { // (1)直接在类定义处
def this() { this("anonymous", 20) } // (2)用this定义
def m1() = { printf("%s=%d\n", name, age) }
def main(args:Array[String]) = {
class c2(name:String, age:Int, female:Boolean=false)
override def toString = { name + "," + age + "," + female }
4.1.3. override
不同于Java的使用 @Override,或者直接使用相同名字覆盖父类方法。
override def toString = { name + "," + age + "," + female }
4.1.4. object单例对象
|
Java |
Scala |
|
public class User { private String name; private User(String name) { this.name=name; } public static User instance(String name) { return new User(name) } } |
object User { var name:String = _ def apply(name:String){this.name=name; this} override def toString = "name: " + name } 调用: val u = User("qh") // "name: qh" |
4.1.5. 静态方法
Scala没有静态方法,类似静态方法的函数定义在object中:
def left(s0:String, s:String) = ...
直接调用Stringx.left(s0, s),或者 Stringx left (s0, s)
def fac(n: Int) = 1 to n reduceLeft (_ * _)
implicit def foo(n: Int) = new { def ! = fac(n) }
--------- ImportMain.scala
import ImportSub._
object ImportMain {
def main(args : Array[String]) : Unit = {
println(5!) // 调用ImportSub中定义的implicit函数
}
}
4.1.6. case class(条件类)
case class Person(name:String, age:Int)
l 新建类实例不用new Person(..),直接用Person("qh",20)
l 自动定义好getXX方法,Person("qh",20).name // "qh"
l 提供默认的toString(), Person("qh",20) // "Person(qh,20)"
case class Man(power:Int) extends Person
case class Woman(beauty:Int, from:String) extends Person
val w2 = w1.copy(from="usa") // Woman(100,"usa")
case Man(x) => "man's power:" + x
case Woman(x,y) => y + " beauty:" + x
f(Man(100)) // man's power:100
f(Woman(90, "china")) // china beauty:90
case class C1(var s: String, var ops: Int) {
def >>= (f: (String=>String)) = {
val C1(res, ops) = C1("ab", 0) >>= (_ * 3) >>= (_ drop 3)
// res="ab"->"ababab"->"bab", ops=0-> 0+1+1->2
val p = ("qh",20) // p._1 = "qh", p._2 = 20;好处是简洁,但无意义
case class person(name:String, age:Int)
val p = person("qh",20) // p.name = "qh", p.age = 20; 好处是有名字,自说明,可读性强
<item priority = "high">Clean the hose</item>
<item priority = "medium">Wash the dishes</item>
<item priority = "medium">Buy more soap</item>
(todo "housework"
(item (priority high) "Clean the house")
(item (priority medium) "Wash the dishes")
(item (priority medium) "Buy more soap"))
Scala的版本:
case class item(priority:String, s:String)
case class todo(name:String, items:List[item])
todo (name="housework",
items=item("high","Clean the house")::
item("medium","Wash the dishes")::
item("medium","Buy more soap")::Nil)
4.1.7. case object(条件单例对象)
4.1.8. 枚举
enum fruits { apple, banana, cherry }
sealed abstract class Fruits // sealed类似于java的final
case object Apple extends Fruits
case object Banana extends Fruits
case object Cherry extends Fruits
4.1.9. 属性和Bean
var name = "anonymous" // var定义的是r/w的属性
@reflect.BeanProperty var name = "anonymous"
}
val o2 = new c2
o2.name = "qh" // 也可以直接存取
o2.name // "qh"
o2.setName("james") // 增加了set/get方法
o2.getName() // "james"
4.1.10. 反射
Scala没有太特别的反射机制,使用java的即可,不过Scala在match..case中可以匹配类型:
相关还有isInstanceOf[T], asInstanceOf[T]
"hello".getClass.getMethods.map(_.getName).toList.sortWith(_<_).mkString(", ")
classOf[String] // 相当于java中的String.class
"aaa".isInstanceOf[String] // true
4.2. trait超级接口
注:trait [treit] n.特征,特点,特性
和Java的Interface类似,但可以定义实体方法,而非仅仅方法定义
trait可以看作有方法实现和字段的interface;代表一类事物的特性;
比如
Tom,可能是Engine 和Son两个trait的混合;
Sunny可能Sales、Son和Father三个trait的混合;
当在运行时往Son里面增加方法或者字段的时候,Tom和Sunny都得到增加的特性。
4.2.1. trait使用
class c1 extends Runnable {...}
2个接口(或一个继承一个接口),用with而不是implements如下:
class c1 extends c0 with Runnable {
class c1 extends t1 with t2 with t3 {...}
4.2.2. mixin
private var children:List[Child] = Nil
def add(child:Child) = child :: children
class Man1(name:String) extends Human with Dad // 静态mixin
class Man2(name:String) extends Human // 先不具备Dad trait
val m2$ = new Man2("james") with Dad // 动态mixin
4.3. 协变和逆变(co-|contra-)variance
4.3.1. 概念
Function[A, B]和Function[-A, +B]的区别图示:
|
|
|
|
Function[A,B] |
Function[-A,+B] |


|
trait Queue[T] {} |
非变 |
|
trait Queue[+T] {} |
协变 如果S extends A (S为子类型,A为父类型), 则Queue[S]为子类型,Queue[A]为父类型 S <: A => Queue[S] <: Queue[A] |
|
trait Queue[-T] {} |
逆变 如果S extends A (S为子类型,A为父类型) 则Queue[S]为父类型,Queue[A]为子类型,和协变互逆 S <: A => Queue[S] >: Queue[A] |
4.3.2. 类型上下界
|
<% |
foo[T <% Ordered[T]](...) 关系较弱:T能够隐式转换为Ordered[T] |
|
<: |
foo[T <: Ordered[T]](...) 关系较强:T必须是Ordered[T]的子类型,即T的类型范围小于Ordered[T],Ordered[T]为上界 |
|
>: |
foo[T >: A](...) 关系较强:T必须是A的父类型,即Tde类型范围大于A,A为下界 |
4.3.3. 协变、逆变结合上下界
|
trait c1[+T] { def m[K >: T](x:K) = x } |
trait c1[-T] { def m[K <: T](x:K) = x } |
|
object c2 extends c1[Int] c2.m(3) // 3 c2.m(3.0) // 3.0 c2.m("abc") // "abc" |
object c2 extends c1[Int] c2.m(3) // 3 c2.m(3.0) // 报错 c2.m("abc") // 报错 |
val v1:T1[java.lang.Integer] = new T1(100)
val v2:T1[java.lang.Integer] = v1
val v3:T1[java.lang.Number] = v1 // 报错
val v1:T1[java.lang.Integer] = new T1(100)
val v2:T1[java.lang.Integer] = v1
val v3:T1[java.lang.Number] = v1 // 合法
val v4:T1[java.lang.Integer] = v3 //非法
val v1:T1[java.lang.Number] = new T1(100)
val v2:T1[java.lang.Number] = v1
val v3:T1[java.lang.Integer] = v1 // 合法
val v4:T1[java.lang.Number] = v3 // 非法
5. util包
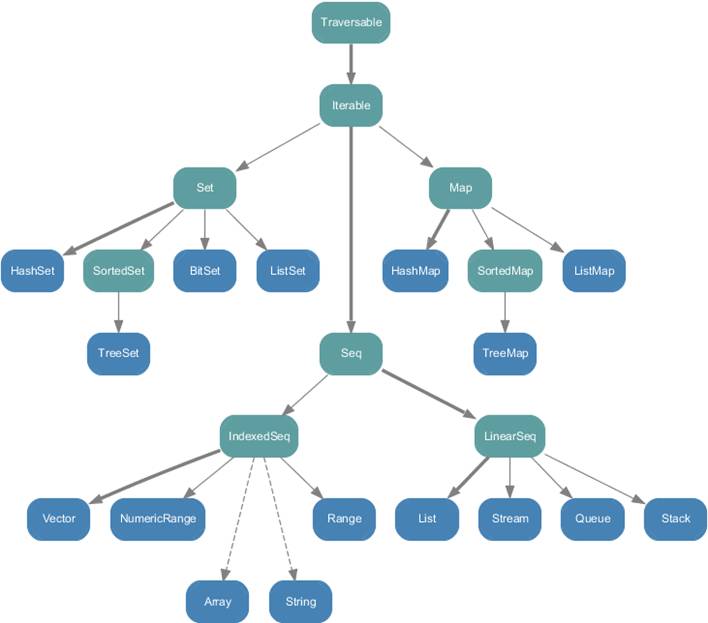
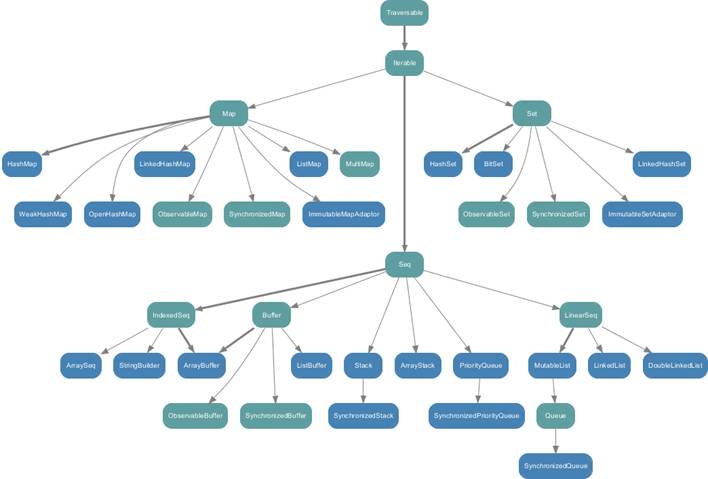
5.1. 架构
http://www.scala-lang.org/docu/files/collections-api/collections.html
scala.collection.immutable
scala.collection.mutable
|
不可变(collection.immutable._) |
可变(collection.mutable._) |
|
Array |
ArrayBuffer |
|
List |
ListBuffer |
|
String |
StringBuilder |
|
/ |
LinkedList, DoubleLinkedList |
|
List |
MutableList |
|
/ |
Queue |
|
Array |
ArraySeq |
|
Stack |
Stack |
|
HashMap HashSet |
HashMap HashSet |
|
ArrayStack |
5.2. 集合Array,List,Tuple
|
Array |
长度固定 |
元素可变 |
确定长度,后赋值; |
|
List |
长度固定 |
元素不可变 |
|
|
Tuple |
长度固定 |
元素不可变 |
常用于有多个返回值的函数;或者多个变量的同时定义 |
Scala 2.8中,3者的元素都可以混合不同的类型(转化为Any类型);
Scala 2.7中,Array、List都不能混合类型,只有Tuple可以;
5.2.1. 定义和初始化
5.2.1.1 Array
val list1 = new Array[String](0) // Array()
val list2 = new Array[String](3) // Array(null, null, null)
val list3:Array[String] = new Array(3) // // Array(null, null, null)
val list1 = Array("a","b","c","d") // 相当于Array.apply("a","b","c","d")
val aa: Array[Any] = Array(1, 2)
val aa: Array[_] = Array(1, 2)
val ab = collection.mutable.ArrayBuffer[Int]()
ab ++= List(9,11) // ArrayBuffer(1, 3, 5, 7, 9, 11)
ab toArray // Array (1, 3, 5, 7, 9, 11)
5.2.1.2 List
val list:List[Int] = List(1,3,4,5,6) // 或者 List(1 to 6:_*)
val list1 = List("a","b","c","d") // 或者 List('a' to 'd':_*) map (_.toString)
val list2 = "a"::"b"::"c"::Nil // Nil是必须的
val list3 = "begin" :: list2 // list2不变,只能加在头,不能加在尾
val list4 = list2 ++ "end" ++ Nil
val list4 = list2 ::: "end" :: Nil // 相当于 list2 ::: List("end")
当 import java.util._ 之后会产生冲突,需要指明包
val lb = scala.collection.mutable.ListBuffer(1,2,3)
lb.append(4) // ListBuffer(1, 2, 3, 4)
val head::body = List(4,"a","b","c","d")
// body: List[Any] = List(a, b, c, d)
List.fill(10)(2) // List(2, 2, 2, 2, 2, 2, 2, 2, 2, 2)
Array.fill(10)(2) // Array(2, 2, 2, 2, 2, 2, 2, 2, 2, 2)
List.fill(10)(scala.util.Random.nextPrintableChar)
// List(?, =, ^, L, p, <, \, 4, 0, !)
List.fill(10)(scala.util.Random.nextInt(101))
// List(80, 45, 26, 75, 24, 72, 96, 88, 86, 15)
val lb = collection.mutable.ListBuffer[Int]()
lb ++= List(9,11) // ListBuffer(1, 3, 5, 7, 9, 11)
lb.toList // List(1, 3, 5, 7, 9, 11)
5.2.1.3 Vector
Scala2.8为了提高list的随机存取效率而引入的新集合类型(而list存取前部的元素快,越往后越慢)。
val v2 = 0 +: v :+ 10 :+ 20 // Vector(0, 10, 20), Vector 那一边始终有":"
v2 updated (1,100) // Vector(0, 100, 20)
IndexSeq(1,2,3) // Vector(1, 2, 3)
5.2.1.4 Tuple
var t2 = ("a", 123, 3.14, new Date())
5.2.1.5 Range
('0' to '9') ++ ('A' to 'Z') // (0,1,..,9,A,B,...,Z)
Vector(1 to 5: _*) // Vector(1,2,3,4,5)
5.2.1.6 Stream
Stream相当于lazy List,避免在中间过程中生成不必要的集合。
val st = 1 #:: 2 #:: 3 #:: Stream.empty // Stream(1, ?)
def fib(a: Int, b: Int): Stream[Int] = a #:: fib(b, a+b)
val fibs = fib(1, 1).take(7).toList // List(1, 1, 2, 3, 5, 8, 13)
1 to 10 map (n=> 1.0*fn(n)/fn(n+1)) // Vector(0.5, 0.666, ..., 0.618)
Range (1,50000000).filter (_ % 13==0)(1) // 26, 但很慢,需要大量内存
Stream.range(1,50000000).filter(_%13==0)(1) // 26,很快,只计算最终结果需要的内容
第一个版本在filter后生成一个中间collection,size=50000000/13;而后者不生成此中间collection,只计算到26即可。
(1 to 100).map(i=> i*3+7).filter(i=> (i%10)==0).sum // map和filter生成两个中间collection
(1 to 100).toStream.map(i=> i*3+7).filter(i=> (i%10)==0).sum
5.2.1.7 Stack Queue
val s = collection.immutable.Stack()
val s2 = s.push(10,20,30) // Stack(30, 20, 10)
val ms = collection.mutable.Stack()
ms.push(1,3,5).push(7) // Stack(7, 5, 3, 1)
ms.pop // 7, ms = Stack(5,3,1)
val q = collection.immutable.Queue() // 也可指定类型 Queue[Int]()
val q2 = q.enqueue(0).enqueue(List(10,20,30)) // Queue(0, 10, 20, 30)
q2.dequeue._2 // Queue(10, 20, 30)
val mq = collection.mutable.Queue[Int]()
mq ++= List(7,9) // Queue(1, 3, 5, 7, 9)
mq dequeue // 1, mq= Queue(3, 5, 7, 9)
5.2.2. 使用(map, flatMap, filter, exists等)
5.2.2.1 map
val list3 = Array("a", 123, 3.14, new Date())
List("a","b","c").map(s=> s.toUpperCase()) // 方式1
List("a","b","c").map(_.toUpperCase()) // 方式2, 类似于Groovy的it
// = List(A, B, C)
5.2.2.2 filter filterNot
List(1,2,3,4,5).filter(_%2==0) // List(2, 4)
也可以写成:
for (x<-List(1,2,3,4,5) if x%2==0) yield x
List(1,2,3,4,5).filterNot(_%2==0) // List(1, 3, 5)
5.2.2.3 partition span splitAt groupBy
注:val (a,b) = List(1,2,3,4,5).partition(_%2==0) // (List(2,4), List(1,3,5))
可把Collection分成:满足条件的一组,其他的另一组。
和partition相似的是span,但有不同:
List(1,9,2,4,5).span(_<3) // (List(1),List(9, 2, 4, 5)),碰到不符合就结束
List(1,9,2,4,5).partition(_<3) // (List(1, 2),List(9, 4, 5)),扫描所有
List(1,3,5,7,9) splitAt 2 // (List(1, 3),List(5, 7, 9))
List(1,3,5,7,9) groupBy (5<) // Map((true,List(7, 9)), (false,List(1, 3, 5)))
5.2.2.4 foreach
打印:
Array("a","b","c","d").foreach(printf("[%s].",_))
// [a].[b].[c].[d].
5.2.2.5 exists
// 集合中是否存在符合条件的元素
List(1,2,3,4,5).exists(_%3==0) // true
5.2.2.6 find
返回序列中符合条件的第一个。
例子:查找整数的第一个因子(最小因子、质数)
def fac1(n:Int) = if (n>= -1 && n<=1) n else (2 to n.abs) find (n%_==0) get
5.2.2.7 sorted sortWith sortBy
例子(排序):
List(1,3,2,0,5,9,7).sorted // List(0, 1, 2, 3, 5, 7, 9)
List(1,3,2,0,5,9,7).sortWith(_>_) // List(9, 7, 5, 3, 2, 1, 0)
List("abc", "cb", "defe", "z").sortBy(_.size) // List(z, cb, abc, defe)
List((1,'c'), (1,'b'), (2,'a')) .sortBy(_._2) // List((2,a), (1,b), (1,c))
5.2.2.8 distinct
例子:(去除List中的重复元素)
def uniq[T](l:List[T]) = l.distinct
uniq(List(1,2,3,2,1)) // List(1,2,3)
5.2.2.9 flatMap
flatMap的作用:把多层次的数据结构“平面化”,并去除空元素(如None)。
可用于:得到xml等树形结构的所有节点名称,去除None等
例子1a:(两个List做乘法)
List(1,2,3) * List(10,20,30) = List(10, 20, 30, 20, 40, 60, 30, 60, 90)
val (a,b) = (List(1,2,3), List(10,20,30))
a flatMap (i=> b map (j=> i*j))
等同于:
for (i<-a; i<-b) yield i*j // 这个写法更清晰
例子1b:
如果不用flatMap而是用map,结果就是:
a map (i=> b map (j=> i*j)) // List(List(10, 20, 30), List(20, 40, 60), List(30, 60, 90))
等同于:
for (i<-a) yield { for (j<-b) yield i*j } // 不如上面的清晰
例子2:
List("abc","def") flatMap (_.toList) // List(a, b, c, d, e, f)
而
List("abc","def") map (_.toList) // List(List(a, b, c), List(d, e, f))
例子3:flatMap结合Option
def toint(s:String) =
try { Some(Integer.parseInt(s)) } catch { case e:Exception => None }
List("123", "12a", "45") flatMap toint // List(123, 45)
List("123", "12a", "45") map toint // List(Some(123), None, Some(45))
5.2.2.10 indices,zipWithIndex
得到indices:
val a = List(100,200,300)
a indices // (0,1,2)
a zipWithIndex // ((100,0), (200,1), (300,2))
(a indices) zip a // ((0,100), (1,200), (2,300))
截取一部分,相当于String的substring
List(100,200,300,400,500) slice (2,4) // (300,400), 取l(2), l(3)
5.2.2.11 take drop splitAt
List(1,3,5,7) take 2 // List(1,3)
List(1,3,5,7) drop 2 // List(5,7)
5.2.2.12 count
满足条件的元素数目:
例如1000内质数的个数:
def prime(n:Int) = if (n<2) false else 2 to math.sqrt(n).toInt forall (n%_!=0)
1 to 1000 count prime // 168
5.2.2.13 updated patch
对于immutable的数据结构,使用updated返回一个新的copy:
val v1 = List(1,2,3,4)
v1.updated(3,10) // List(1, 2, 3, 10), v1还是List(1, 2, 3, 4)
对于可变的数据结构,直接更改:
val mseq = scala.collection.mutable.ArraySeq(1, 2, 4, 6)
mseq(3) = 10 // mseq = ArraySeq(1, 2, 4, 10)
批量替换,返回新的copy:
val v1 = List(1,2,3,4,5)
val v2 = List(10,20,30)
v1 patch (0, v2, 3) // List(10,20,30,4,5), 但v1,v2不变
5.2.2.14 reverse reverseMap
1 to 5 reverse // Range(5, 4, 3, 2, 1)
"james".reverse.reverse // "james"
reverseMap就是revese + map
1 to 5 reverseMap (10*) // Vector(50, 40, 30, 20, 10)
相当于:
(1 to 5 reverse) map (10*)
5.2.2.15 contains startsWith endWith
1 to 5 contains 3 // true, 后一个参数是1个元素
1 to 5 containsSlice (2 to 4) // true, 后一个参数是1个集合
(1 to 5) startsWith (1 to 3) // true 后一个参数是1个集合
(1 to 5) endsWith (4 to 5)
(List(1,2,3) corresponds List(4,5,6)) (_<_) // true,长度相同且每个对应项符合判断条件
5.2.2.16 集合运算
List(1,2,3,4) intersect List(4,3,6) // 交集 = List(3, 4)
List(1,2,3,4) diff List(4,3,6) // A-B = List(1, 2)
List(1,2,3,4) union List(4,3,6) // A+B = List(1, 2, 3, 4, 4, 3, 6)
// 相当于
List(1,2,3,4) ++ List(4,3,6) // A+B = List(1, 2, 3, 4, 4, 3, 6)
5.2.2.17 殊途同归
例子:得到 (4, 16, 36, 64, 100)
写法1:
(1 to 10) filter (_%2==0) map (x=>x*x)
写法2:
for(x<-1 to 10 if x%2==0) yield x*x
写法3:
(1 to 10) collect { case x if x%2==0 => x*x }
5.2.2.18 其他
对其他语言去重感兴趣,可看看:
http://rosettacode.org/wiki/Remove_duplicate_elements
5.2.3. 数组元素定位
统一使用(),而不是[],()就是apply()的简写,a(i)===a.apply(i)
val a = Array(100,200,300) // a(0)=100, a(1)=200, a(3)=300
a(0)=10 // Array(10, 200, 300),相当于a.update(0, 10)
// list(0)=="a", list(1)=="b", list(2)=="c"
val t1 = ("a","b","c") // t1._1="a", t1._2="b", t1._3="c"
5.2.4. view
在某类型的集合对象上调用view方法,得到相同类型的集合,但所有的transform函数都是lazy的,从该view返回调用force方法。
v map (1+) map (2*) // Vector(4, 6, 8, 10, 12, 14, 16, 18, 20, 22)
v.view map (1+) map (2*) force
((1 to 1000000000) view).take(3).force // Vector(1,2,3)
Stream.range(1,1000000000).take(3).force // Stream(1, 2, 3)
5.2.5. 和Java集合间的转换(scalaj)
方案一:Java的List<T>很容易通过List.toArray转换到Array,和Scala中的Array是等价的,可使用map、filter等。
方案二:使用第三方的scalaj扩展包(需自行下载设置classpath)
val a1 = new java.util.ArrayList[Int]
a1.add(100); a1.add(200); a1.add(300)
a2 map (e=>e.asInstanceOf[Int]) map(2*) filter (300>)
//采用scalaj(http://github.com/scalaj/scalaj-collection)
import scalaj.collection.Imports._
Map(1 -> "a", 2 -> "b", 3 -> "c").asJava
// scalaj还可以在java的collection上使用foreach (目前除foreach外,还不支持filter、map)
//Java to Scala
Java类型 |
转换方法 |
java.lang.Comparable[A] |
#asScala: scala.math.Ordered[A] |
java.util.Comparator[A] |
#asScala: scala.math.Ordering[A] |
java.util.Enumeration[A] |
#asScala: scala.collection.Iterator[A] #foreach(A => Unit): Unit |
java.util.Iterator[A] |
#asScala: scala.collection.Iterator[A] #foreach(A => Unit): Unit |
java.lang.Iterable[A] |
#asScala: scala.collection.Iterable[A] #foreach(A => Unit): Unit |
java.util.List[A] |
#asScala: scala.collection.Seq[A] #asScalaMutable: scala.collection.mutable.Seq[A] |
java.util.Set[A] |
#asScala: scala.collection.Set[A] #asScalaMutable: scala.collection.mutable.Set[A] |
java.util.Map[A, B] |
#asScala: scala.collection.Map[A, B] #asScalaMutable: scala.collection.mutable.Map[A, B] #foreach(((A, B)) => Unit): Unit |
java.util.Dictionary[A, B] |
#asScala: scala.collection.mutable.Map[A, B] #foreach(((A, B)) => Unit): Unit |
// Scala to Java
Scala类型 |
转换方法 |
scala.math.Ordered[A] |
#asJava: java.util.Comparable[A] |
scala.math.Ordering[A] |
#asJava: java.util.Comparator[A] |
scala.collection.Iterator[A] |
#asJava: java.util.Iterator[A] #asJavaEnumeration: java.util.Enumeration[A] |
scala.collection.Iterable[A] |
#asJava: java.lang.Iterable[A] |
scala.collection.Seq[A] |
#asJava: java.util.List[A] |
scala.collection.mutable.Seq[A] |
#asJava: java.util.List[A] |
scala.collection.mutable.Buffer[A] |
#asJava: java.util.List[A] |
scala.collection.Set[A] |
#asJava: java.util.Set[A] |
scala.collection.mutable.Set[A] |
#asJava: java.util.Set[A] |
scala.collection.Map[A, B] |
#asJava: java.util.Map[A, B] |
scala.collection.mutable.Map[A, B] |
#asJava: java.util.Map[A, B] #asJavaDictionary: java.util.Dictionary[A, B] |
5.3. Map
5.3.1. 定义Map
val m = Map(1->100, 2->200) ++ Map(3->300) // Map((1,100), (2,200), (3,300))
List(1,2,3).zip(List(100,200,300)).toMap // Map((1,100), (2,200), (3,300))
注解:zip有“拉拉链”的意思,就是把两排链扣完全对应扣合在一起,非常形象。
5.3.2. 不可变Map(缺省)
val m3 = Map(1->100, 2->200, 3->300)
val m1:Map[Int,String] = Map(1->"a",2->"b")
注:如果import java.util._后发生冲突,可指明:scala.collection.immutable.Map
// m3(1)=100, m3(2)=200, m3(3)=300
// m3.get(1)=Some(100), m3.get(3)=Some(300), m3.get(4)=None
val v = m3.get(4).getOrElse(-1) // -1
Map本身不可改变,即使定义为var,update也是返回一个新的不可变Map:
val m5 = m4(1)=1000 // m4还是 1->100, m5:1->1000
m4 += (2->200) // m4指向新的(1->100,2->200), (1->100)应该被回收
Map(1->100,2->200) + (3->300, 4->400) // Map((1,100), (2,200), (3,300), (4,400))
Map(1->100,2->200,3->300) - (2,3) // Map((1,100))
Map(1->100,2->200,3->300) -- List(2,3) // Map((1,100))
Map(1->100,2->200) ++ Map(3->300) // Map((1,100), (2,200), (3,300))
5.3.3. 可变Map
val map = scala.collection.mutable.Map[String, Any]()
// map("k2")=="v2", map.get("k2")==Some("v2"), map.get("k3")==None
val mm = collection.mutable.Map(1->100,2->200,3->300)
mm getOrElseUpdate (3,-1) // 300, mm不变
mm getOrElseUpdate (4,-1) // 300, mm= Map((2,200), (4,-1), (1,100), (3,300))
val mm = collection.mutable.Map(1->100,2->200,3->300)
mm -= 1 // Map((2,200), (3,300))
mm += (1->100,2->200,3->300) // Map((2,200), (1,100), (3,300))
mm --= List(1,2) // Map((3,300))
mm remove 1 // Some(300), mm=Map()
mm.retain((x,y) => x>1) // mm = Map((2,200), (3,300))
mm transform ((x,y)=> 0) // mm = Map((2,0), (1,0), (3,0))
mm transform ((x,y)=> x*10) // Map((2,20), (1,10), (3,30))
mm transform ((x,y)=> y+3) // Map((2,23), (1,13), (3,33))
5.3.4. Java的HashMap
val m1:java.util.Map[Int, String] = new java.util.HashMap
5.3.5. 读取所有元素
上面说过,Map(1->100,2->200,3->300) 和 Map((1,100),(2,200),(3,300))的写法是一样的,可见Map中的每一个entry都是一个Tuple,所以:
for(e<-map) println(e._1 + ": " + e._2)
map.foreach(e=>println(e._1 + ": " + e._2))
for ((k,v)<-map) println(k + ": " + v)
map filter (e=>e._1>1) // Map((2,200), (3,300))
map filterKeys (_>1) // Map((2,200), (3,300))
map.map(e=>(e._1*10, e._2)) // Map(10->100,20->200,30->300)
map map (e=>e._2) // List(100, 200, 300)
2 to 100 flatMap map.get // (200,300) 只有key=2,3有值
5.3.6. 多值Map
结合Map和Tuple,很容易实现一个key对应的value是组合值的数据结构:
val m = Map(1->("james",20), 2->("qh",30), 3->("qiu", 40))
for( (k,(v1,v2)) <- m ) printf("%d: (%s,%d)\n", k, v1, v2)
5.4. Set
注:BitSet(collection.immutable.BitSet)和Set类似,但操作更快
5.4.1. 定义
var s = Set(1,2,3,4,5) // scala.collection.immutable.Set
var s2 = Set[Int]() // scala.collection.immutable.Set[Int]
Set(1,2,3).empty // Set() 全部删除
Set(1,2,3) ++ Set(2,3,4) // Set(1, 2, 3, 4)
Set(1,2,3) -- Set(2,3,4) // Set(1)
5.4.2. 逻辑运算
|
运算 |
例子 |
|
交集 |
Set(1,2,3) & Set(2,3,4) // Set(2,3) Set(1,2,3) intersect Set(2,3,4) |
|
并集 |
Set(1,2,3) | Set(2,3,4) // Set(1,2,3,4) Set(1,2,3) union Set(2,3,4) // Set(1,2,3,4) |
|
差集 |
Set(1,2,3) &~ Set(2,3,4) // Set(1) Set(1,2,3) diff Set(2 ,3,4) // Set(1) |
5.4.3. 可变BitSet
val bs = collection.mutable.BitSet()
bs += (1,3,5) // BitSet(1, 5, 3)
bs ++= List(7,9) // BitSet(1, 9, 7, 5, 3)
5.5. Iterator
Iterator不属于集合类型,只是逐个存取集合中元素的方法:
val it = Iterator(1,3,5,7) // Iterator[Int] = non-empty iterator
it foreach println // 1 3 5 7
it foreach println // 无输出
三种常用的使用模式:
// 1、使用while
val it = Iterator(1,3,5,7)
while(it.hasNext) println(it.next)
// 2、使用for
for(e<- Iterator(1,3,5,7)) println(e)
// 3、使用foreach
Iterator(1,3,5,7) foreach println
Iterator也可以使用map的方法:
Iterator(1,3,5,7) map (10*) toList // List(10, 30, 50, 70)
Iterator(1,3,5,7) dropWhile (5>) toList // List(5,7)
由于Iterator用一次后就消失了,如果要用两次,需要toList或者使用duplicate:
val (a,b) = Iterator(1,3,5,7) duplicate // a = b = non-empty iterator
又如:
val it = Iterator(1,3,5,7)
val (a,b) = it duplicate
// 在使用a、b前,不能使用it,否则a、b都不可用了。
a toList // List(1,3,5,7)
b toList // List(1,3,5,7)
// 此时it也不可用了
5.6. Paralllel collection
Scala 2.9+引入:
(1 to 10).par foreach println
多运行几次,注意打印顺序会有不同
6. io
6.1. 文件I/O
6.1.1. 读文件
Source.fromFile("cn.scala","utf8").mkString
Source.fromFile(new java.io.File("cn.scala")).getLines().foreach(println)
6.1.2. 写文件
import java.io._, java.nio.channels._, java.nio._
val f = new FileOutputStream("o.txt").getChannel
f write ByteBuffer.wrap("a little bit long ...".getBytes)
var out = new java.io.FileWriter("./out.txt") // FileWriter("./out.txt", true) 为追加模式
6.1.3. 复制文件
val in = new FileInputStream("in").getChannel
val out = new FileOutputStream("out").getChannel
in transferTo (0, in.size, out)
6.1.4. 全目录扫描
def child = new Iterable[File] {
def elements = if (file.isDirectory) file.listFiles.elements else Iterator.empty
Seq.singleton(file) ++ child.flatMap(i=> new Dir(i).scan)
implicit def foo(f:File) = new Dir(f)
Console println new File(".").getCanonicalPath
val list = file.scan // File对象隐形转换成Dir对象
6.2. 网络I/O
import java.net.{URL, URLEncoder} import scala.io.Source.fromURL
fromURL(new URL("http://qh.appspot.com")).mkString
或者指定编码:
fromURL(new URL("http://qh.appspot.com"))(io.Codec.UTF8).mkString
7. actor
http://www.scala-lang.org/docu/files/actors-api/actors_api_guide.html#
Scala中处理并发,有很多选择:
l actor消息模型,类似Erlang,首选,Lift和akka也实现了自己的actor模型。
l Thread、Runnable
l java.util.concurennt
l 3rd并发框架如Netty,Mina
7.1. actor模型
|
Java内置线程模型 |
Scala actor模型 |
|
“共享数据-锁”模型(share data and lock) |
share nothing |
|
每个object有一个monitor,监视多线程对共享数据的访问 |
不共享数据,actor之间通过message通讯 |
|
加锁的代码段用synchronized标识 |
|
|
死锁问题 |
|
|
每个线程内部是顺序执行的 |
每个actor内部是顺序执行的 |
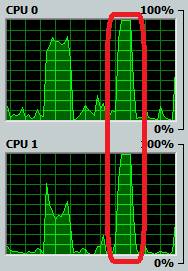
7.2. 多核计算
对比如下的算法:
|
def perfect(n:Int) = n==(1 until n filter (n%_==0) sum) val n = 33550336 // 串行计算 n to n+10 foreach (i=>println(perfect(i))) |
def perfect(n:Int) = n==(1 until n filter (n%_==0) sum) val n = 33550336 // 并行计算 class T1(n:Int) extends Thread { override def run(){println(perfect(n))}} n to n+10 foreach (i=>new T1(i).start) |
|
耗时:8297 |
耗时:5134 |
|
|
|
|
单线程串行计算,不能很好发挥多核优势 |
多线程并行计算,平均分配到多核,更快 |

上面是Java的写法,也可以用Scala的actor写法:
Scala写法1:
import actors.Actor,actors.Actor._
class A1 extends Actor {
def act { react { case n:Int=>println(perfect(n)) }}}
n to n+10 foreach (i=>{ (new A1).start ! i})
Scala写法2:
val aa = Array.fill(11)(actor { react { case n:Int=>println(perfect(n)) }})
n to n+10 foreach (i=>aa(i-n) ! i)
或者:
n to n+10 foreach (i=> actor { react { case n:Int=>println(perfect(n)) }} ! i)
7.3. Actor用法
Scala会建立一个线程池共所有Actor来使用。receive模型是Actor从池中取一个线程一直使用;react模型是Actor从池中取一个线程用完给其他Actor用
实现方式1:
import scala.actors._
object Actor1 extends Actor { // 或者class
// 实现线程
def act() { react { case _ =>println("ok"); exit} }
}
//发送消息:
Actor1.start ! 1001 // 必须调用start
实现方式2:
import scala.actors.Actor._
val a2 = actor { react { case _ =>println("ok") } } // 马上启动
//发送消息:
a2 ! "message" // 不必调用start
提示:
|
! |
发送异步消息,没有返回值。 |
|
!? |
发送同步消息,等待返回值。(会阻塞发送消息语句所在的线程) |
|
!! |
发送异步消息,返回值是 Future[Any]。 |
|
? |
不带参数。查看 mailbox 中的下一条消息。 |
7.4. 方式1:接受receive
特点:要反复处理消息,receive外层用while(..)
import actors.Actor, actors.Actor._
val a1 = Actor.actor {
var work = true
while(work) {
receive { // 接受消息, 或者用receiveWith(1000)
case msg:String => println("a1: " + msg)
case x:Int => work = false; println("a1 stop: " + x)
}
}
}
a1 ! "hello" // "a1: hello"
a1 ! "world" // "a1: world"
a1 ! -1 // "a1 stop: -1"
a1 ! "no response :("
7.5. 方式2:接受react, loop
特点:
l 从不返回
l 要反复执行消息处理,react外层用loop,不能用while(..);
l 通过复用线程,比receive更高效,应尽可能使用react
import actors.Actor, Actor._
val a1 = Actor.actor {
react {
case x:Int => println("a1 stop: " + x)
case msg:String => println("a1: " + msg); act()
}
}
a1 ! "hello" // "a1: hello"
a1 ! "world" // "a1: world"
a1 ! -1 // "a1 stop: -1"
a1 ! "no response :("
如果不用退出的线程,可使用loop改写如下:
val a1 = Actor.actor {
loop {
react {
case x:Int => println("a1 stop: " + x); exit()
case msg:String => println("a1: " + msg)
}
}
}
7.6. REPL接受消息
scala> self ! "hello"
scala> self.receive { case x => x }
scala> self.receiveWithin(1000) { case x => x }
7.7. actor最佳实践
7.7.1. 不阻塞actor
actor不应由于处理某条消息而阻塞,可以调用helper-actor处理耗时操作(helper actor虽然是阻塞的,但由于不接受消息所以没问题),以便actor接着处理下一条消息
-----------------------------------------
import actors._, actors.Actor._
case n: Int => Thread.sleep(time)
1 to 5 foreach { mainActor1 ! _ } // 5秒钟后打印完数字
val mainActor2: Actor = actor {
case n: Int => actor { Thread.sleep(time); mainActor2 ! "wakeup" }
1 to 5 foreach { mainActor2 ! _ } // 马上打印数字; 1秒钟后打印5个wakeup
-----------------------------------------
7.7.2. actor之间用且仅用消息来通讯
actor模型让我们写多线程程序时只用关注各个独立的单线程程序(actor),他们之间通过消息来通讯。例如,如果BadActor中有一个GoodActor的引用:
class BadActor(a:GoodActor) extends Actor {...}
7.7.3. 采用不可变消息
总结:大部分时候使用不可变对象很方便,不可变对象是并行系统的曙光,它们是易使用、低风险的线程安全对象。当你将来要设计一个和并行相关的程序时,无论是否使用actor,都应该尽量使用不可变的数据结构。
7.7.4. 让消息自说明
对每一种消息创建一个对应的case class,而不是使用上面的tuple数据结构。虽然这种包装在很多情况下并非必须,但该做法能使actor程序易于理解,例如:
// 不易理解,因为传递的是个一般的字符串,很难指出那个actor来响应这个消息
lookerUpper ! ("www.scala-lang.org", self)
// 改为如下,则指出只有react能处理LoopupIP的actor来处理:
case class LookupIP(hostname: String, requester: Actor)
lookerUpper ! LookupIP("www.scala-lang.org", self)
7.8. 不同jvm间的消息访问
服务器端:
object ActorServer extends Application {
import actors.Actor, actors.Actor._, actors.remote.RemoteActor
Actor.actor { // 创建并启动一个 actor
// 当前 actor 监听的端口: 3000
RemoteActor.alive(3000)
// 在 3000 端口注册本 actor,取名为 server1。
// 第一个参数为 actor 的标识,它以单引号开头,是 Scala 中的 Symbol 量,
// Symbol 量和字符串相似,但 Symbol 相等是基于字符串比较的。
// self 指代当前 actor (注意此处不能用 this)
RemoteActor.register('server1, Actor.self)
// 收到消息后的响应
loop {
Actor.react {case msg =>
println("server1 get: " + msg)
}
}
}
}
客户端:
object ActorClient extends Application {
import actors.Actor, actors.remote.Node, actors.remote.RemoteActor
Actor.actor {
// 取得一个节点(ip:port 唯一标识一个节点)
// Node 是个 case class,所以不需要 new
val node = Node("127.0.0.1", 3000)
// 取得节点对应的 actor 代理对象
val remoteActor = RemoteActor.select(node, 'server1)
// 现在 remoteActor 就和普通的 actor 一样,可以向它发送消息了!
println("-- begin to send message")
remoteActor ! "ActorClient的消息"
println("-- end")
}
}
7.9. STM
http://nbronson.github.com/scala-stm/
a lightweight Software Transactional Memory for Scala, inspired by the STMs in Haskell and Clojure.
Cheat-Sheet:
importscala.concurrent.stm._
valx=Ref(0)// allocate a Ref[Int]
valy=Ref.make[String]()// type-specific default
valz=x.single// Ref.View[Int]
atomic{implicittxn=>
vali=x()// read
y()="x was "+i// write
valeq=atomic{implicittxn=>// nested atomic
x()==z()// both Ref and Ref.View can be used inside atomic
}
assert(eq)
y.set(y.get+", long-form access")
}
// only Ref.View can be used outside atomic
println("y was '"+y.single()+"'")
println("z was "+z())
atomic{implicittxn=>
y()=y()+", first alternative"
if(xgetWith{_>0})// read via a function
retry// try alternatives or block
}orAtomic{implicittxn=>
y()=y()+", second alternative"
}
valprev=z.swap(10)// atomic swap
valsuccess=z.compareAndSet(10,11)// atomic compare-and-set
z.transform{_max20}// atomic transformation
valpre=y.single.getAndTransform{_.toUpperCase}
valpost=y.single.transformAndGet{_.filterNot{_==' '}}8. misc
8.1. xml
8.1.1. 生成
Scala原生支持xml,就如同Java支持String一样,这就让生成xml和xhtml很简单优雅:
val html = <html>name={name}, age="{age}"</html> toString
// <html>name=james, age="10"</html>
val html = <html><head><title>{myTitle}</title></head><body>{"hello world"}</boty></html>
val x = <r>{(1 to 5).map(i => <e>{i}</e>)}</r>
// <r><e>1</e><e>2</e><e>3</e><e>4</e><e>5</e></r>
val x0 = <users><user name="qh"/></users>
val <users>{u}</users> = x0 // u: scala.xml.Node = <user name="qh"></user>
8.1.2. xml文件
xml.XML.saveFull("foo.xml", node, "UTF-8",
xmlDecl: Boolean, doctype : DocType)
8.1.3. 读取:
val x = <r>{(1 to 5).map(i => <e>{i}</e>)}</r>
// <r><e>1</e><e>2</e><e>3</e><e>4</e><e>5</e></r>
(x \ "e") map (_.text.toInt) // List(1, 2, 3, 4, 5)
<user name="qh"><age>20</age></user>
<user name="james"><age>30</age></user>
(x0 \ "user") // <user name="qh"><age>20</age></user>, <user name="james"><age>30</age></user>)
(x0 \ "user" \ "age") // (<age>20</age>, <age>30</age>)
(x0 \\ "age") // 所有下级:(<age>20</age>, <age>30</age>)
(x0 \ "_") 所有
8.1.4. 访问属性
val x = <uu><u name="qh" /><u name="james" /><u name="qiu" /></uu>
(x \ "u" \\ "@name") foreach println // "qh\njames\nqiu"
8.1.5. 格式化输出
val pp = new xml.PrettyPrinter(80, 4) // 行宽 80,缩进为 4
8.2. json
Scala-json
8.3. Configgy
http://www.lag.net/configgy/
简单配置及logging:
----------------------------
log {
filename = "/var/log/pingd.log"
roll = "daily"
level = "debug"
}
hostname = "pingd.example.com"
port = 3000
----------------------------
val conf = net.lag.configgy.Configgy.configure("/etc/pingd.conf").config
val hostname = conf.getString("hostname", "localhost")
val port = conf.getInt("port", 3000)
8.4. 正则表达式regex
例子1:完全匹配
//将字符串转为scala.util.matching.Regex
val pattern = "^[a-z0-9._%\\-+]+@(?:[a-z0-9\\-]+\\.)+[a-z]{2,4}$"
val emailRegex = pattern.r // 或者 new scala.util.matching.Regex(pattern)
//emailRegex.pattern=>java.util.regex.Pattern 使用java的Pattern
emailRegex.pattern.matcher("tt@16.cn").matches // true
例子2:查找匹配部分
val p = "[0-9]+".r
p.findAllIn("2 ad 12ab ab21 23").toList // List(2, 12, 21, 23)
p.findFirstMatchIn("abc123xyz").get // scala.util.matching.Regex.Match = 123
更多例子如下:
定义:
val r1 = "(\\d+) lines".r // syntactic sugarval r2 = """(\d+) lines""".r // using triple-quotes to preserve backslashes
或者
import scala.util.matching.Regex val r3 = new Regex("(\\d+) lines") // standardval r4 = new Regex("""(\d+) lines""", "lines") // with named groups
search和replace(java.lang.String的方法):
"99 lines" matches "(\\d+) lines" // true
"99 Lines" matches "(\\d+) lines" // false
"99 lines" replace ("99", "98") // "98 lines"
"99 lines lines" replaceAll ("l", "L") // 99 Lines Lines
search(regex的方法):
"\\d+".r findFirstIn "99 lines" // Some(99)
"\\w+".r findAllIn "99 lines" // iterator(长度为2)
"\\s+".r findPrefixOf "99 lines" // None
"\\s+".r findPrefixOf " 99 lines" // Some( )
val r4 = new Regex("""(\d+) lines""", "g1") // with named groups
r4 findFirstMatchIn "99 lines-a" // Some(99 lines)
r4 findPrefixMatchOf "99 lines-a" // Some(99 lines)
val b = (r4 findFirstMatchIn "99 lines").get.group("g1") // "99"
match(regex的方法):
val r1 = "(\\d+) lines".r
val r4 = new Regex("""(\d+) lines""", "g1")
val Some(b) = r4 findPrefixOf "99 lines" // "99 lines" for { line <- """|99 lines-a |99 lines |pass |98 lines-c""".stripMargin.lines } line match { case r1(n) => println("Has " + n + " Lines.") // "Has 99 Lines."
case _ => }
for (matched <- "(\\w+)".r findAllIn "99 lines" matchData)
println("Matched from " + matched.start + " to " + matched.end)
输出:
Matched from 0 to 2
Matched from 3 to 8
replace(regex的方法):
val r2 = """(\d+) lines""".r // using triple-quotes to preserve backslashes
r2 replaceFirstIn ("99 lines-a", "aaa") // "aaa-a"
r2 replaceAllIn ("99 lines-a, 98 lines-b", "bbb") // "bbb-a, bbb-b"
其他:使用正则表达式定义变量
val regex = "(\\d+)/(\\d+)/(\\d+)".r
val regex(year, month, day) = "2010/1/13"
// year: String = 2010
// month: String = 1
// day: String = 13
8.5. GUI
8.5.1. java方式
import javax.swing.JFrame var jf = new JFrame("Hello!") jf.setSize(800, 600) jf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE) jf.setVisible(true)
8.5.2. scala方式
object Swing1 extends SimpleGUIApplication { // scala2.7
def top = new MainFrame { // 必须实现top方法
val label = new Label("hello world cn中文")
layout(label) = BorderPanel.Position.Center
9. 附录
9.1. stackoverflow的scala教程
解答一些实际问题:
http://stackoverflow.com/tags/scala/info
9.2. ProjectEuler
数学+编程答题:
http://projecteuler.net/index.php?section=problems
对上面问题的Haskell解答参考:
http://www.haskell.org/haskellwiki/Euler_problems
对上面问题的Python解答参考:
http://www.s-anand.net/euler.html
对上面问题的Scala解答参考:
http://pavelfatin.com/scala-for-project-euler/
9.3. Scala问答
http://stackoverflow.com/questions/tagged/scala+list
9.4. rosettacode
http://rosettacode.org/wiki/Category:Scala (各种语言解题汇编)
9.5. 编译、mvn、SBT
见“Maven 学习笔记”中的4、SBT
Scala中类似于ant和maven的东西,配置文件使用.scala,交互模式下使用,可以自定编译和测试。
和vim/emacs/textmate等结合进行增量开发。
结合mvn和sbt,可以利用mvn eclipse:eclipse来产生.project和.classpath,利用sbt的不间断编译运行,步骤:
l 运行maven命令(看mvnh.bat)创建目录./prj1/结构:
mvn archetype:create -DgroupId=jamesqiu -DartifactId=prj1 -DpackageName=test
------- ---------- ----------
项目在仓库中的唯一标识 跟目录名及jar名 包名
l 运行sbt
问及name就填和mvn的packageName一样(“test”)
问及organization就填和mvn的groupId一样(“jamesqiu”)
问及scala version就填2.8.0
l 运行mvn eclipse:eclipse生成eclipse项目文件
l 运行sbt
sbt ~compile 进行增量编译;
sbt ~run 进行增量编译运行,有多个可执行类时需要手工选择。
9.6. Scala水平划分
来源:http://www.scala-lang.org/node/8610 (Martin Odersky)
|
应用开发者 |
库开发者 |
|
Level A1: Beginning application programmer · Java-like statements and expressions: standard operators, method calls, conditionals, loops, try/catch
· for-expressions |
|
|
Level A2: Intermediate application programmer · Pattern matching · Trait composition · Recursion, in particular tail recursion · XML literals |
Level L1: Junior library designer · Type parameters · Traits · Lazy vals · Control abstraction, currying · By-name parameters |
|
Level A3: Expert application programmer · Folds, i.e. methods such as foldLeft, foldRight · Streams and other lazy data structures · Actors · Combinator parsers |
Level L2: Senior library designer · Variance annotations · Existential types (e.g., to interface with Java wildcards) · Self type annotations and the cake pattern for dependency injection · Structural types (aka static duck typing) · Defining map/flatmap/withFilter for new kinds of for-expressions · Extractors |
|
Level L3: Expert library designer · Early initializers · Abstract types · Implicit definitions · Higher-kinded types |
9.7. Scala适合的领域
http://goodstuff.im/scala-use-is-less-good-than-java-use-for-at-l by David Pollak
小结:
l Scala更适合real-time, distributed, concurrent的应用,而不是ORM、CRUD应用(尽管有Squeryl);
l 大部分的应用还是ORM和CRUD,与其推销Scala到5万个项目里只成功20%,还不如推荐到5千个合适项目里成功80%;
l 你的公司已高端人才为主,推荐Scala;以堆人力为主,还是Java吧;
转载于:https://www.cnblogs.com/scala/p/3637969.html
Scala HandBook相关推荐
- hadoop,spark,scala,flink 大数据分布式系统汇总
20220314 https://shimo.im/docs/YcPW8YY3T6dT86dV/read 尚硅谷大数据文档资料 iceberg相当于对hive的读写,starrocks相当于对mysq ...
- 2021年大数据常用语言Scala(三十八):scala高级用法 隐式转换和隐式参数
目录 隐式转换和隐式参数 隐式转换 自动导入隐式转换方法 隐式转换的时机 隐式参数 隐式转换和隐式参数 隐式转换和隐式参数是scala非常有特色的功能,也是Java等其他编程语言没有的功能.我们可以很 ...
- 2021年大数据常用语言Scala(三十七):scala高级用法 高阶函数用法
目录 高阶函数用法 作为值的函数 匿名函数 柯里化(多参数列表) 闭包 高阶函数用法 Scala 混合了面向对象和函数式的特性,在函数式编程语言中,函数是"头等公民",它和Int. ...
- 2021年大数据常用语言Scala(三十六):scala高级用法 泛型
目录 泛型 定义一个泛型方法 定义一个泛型类 上下界 协变.逆变.非变 非变 协变 逆变 泛型 scala和Java一样,类和特质.方法都可以支持泛型.我们在学习集合的时候,一般都会涉及到泛型. sc ...
- 2021年大数据常用语言Scala(三十五):scala高级用法 提取器(Extractor)
目录 提取器(Extractor) 定义提取器 提取器(Extractor) 我们之前已经使用过scala中非常强大的模式匹配功能了,通过模式匹配,我们可以快速匹配样例类中的成员变量.例如: // ...
- 2021年大数据常用语言Scala(三十四):scala高级用法 异常处理
目录 异常处理 捕获异常 抛出异常 异常处理 Scala中 无需在方法上声明异常 来看看下面一段代码. def main(args: Array[String]): Unit = {val i = 1 ...
- 2021年大数据常用语言Scala(三十一):scala面向对象 特质(trait)
目录 特质(trait) 作为接口使用 定义具体的方法 定义具体方法和抽象方法 定义具体的字段和抽象的字段 实例对象混入trait trait调用链 trait的构造机制 trait继承class 特 ...
- 2021年大数据常用语言Scala(二十九):scala面向对象 单例对象
目录 单例对象 定义object - 掌握 伴生对象 - 掌握 apply方法 - 掌握 main方法 单例对象 Scala中没有static关键字,但是它支持静态 如果要定义静态的东西,统统定义到o ...
- 2021年大数据常用语言Scala(二十八):scala面向对象 MAVEN依赖和类
目录 scala面向对象 MAVEN依赖 类 - 掌握 创建类和对象 - 掌握 getter/setter - 了解 类的构造器 - 掌握 scala面向对象 MAVEN依赖 <?xml ver ...
- 2021年大数据常用语言Scala(二十七):函数式编程 聚合操作
目录 聚合操作 聚合 reduce 定义 案例 折叠 fold 定义 案例 聚合操作 聚合操作,可以将一个列表中的数据合并为一个.这种操作经常用来统计分析中 聚合 reduce reduce表示 ...
最新文章
- Python 函数学习
- 使用javascript模拟常见数据结构(二)
- 人大选博士的3个标准
- SAP 没有QM02权限的情况下如何为一个质量通知单单据上传附件?
- vue-music(1)音乐播发器 项目开发记录
- Windows10局域网内共享资源(你没有权限访问 或者 账号或者密码错误)
- Hungtingdon road surgery
- python中 s是什么意思_python – “S”在同情中意味着什么
- 学生渐进片add如何给_渐进镜片的说明与镜架选择
- 干货!全网最全一套目标检测、卷积神经网络和OpenCV学习资料(教程/PPT/代码)...
- 【C++笔记】文件操作
- oracle 常用语句2
- 教你正确设置CrossOver的Wine配置(一)
- jsplumb流程图demo
- SolidWorks二次开发经验总结
- PLC编程实例(一) 基本电路
- Excel 宏编程的常用代码
- 公司-人人网:人人网
- python应用内部审计_基于大数据技术提升内部审计质量的路径
- Windows10插了耳机电脑还是外放