计算机组成原理笔记(王道考研) 第二章:数据的表示和运算2
内容基于中国大学MOOC的2023考研计算机组成原理课程所做的笔记。
感谢LY,他帮我做了一部分笔记。由于听的时间不一样,第四章前的内容看起来可能稍显啰嗦,后面会记得简略一些。
西电的计算机组织与体系结构课讲法和王道考研的课不太一样,要应付校内考试建议还是跟着老师学比较好。以下是20年西电计科院车向泉老师这门课的录播下载链接(请勿将录像上传到B站等网站!!):
链接:https://pan.baidu.com/s/1bFs3ajhy8ZcbHopS9izGsw
提取码:fdez
期中考试占20分,一般只考前两章内容,期末考试占60分,一般前两章内容不考,考察内容一般考前的复习课都会讲清楚,请务必认真听复习课。
其他各章节的链接如下:
计算机组成原理笔记(王道考研) 第一章:计算机系统概述
计算机组成原理笔记(王道考研) 第二章:数据的表示和运算1
计算机组成原理笔记(王道考研) 第二章:数据的表示和运算2
计算机组成原理笔记(王道考研) 第三章:存储系统
计算机组成原理笔记(王道考研) 第四章:指令系统
计算机组成原理笔记(王道考研) 第五章:中央处理器
计算机组成原理笔记(王道考研) 第六章:总线
计算机组成原理笔记(王道考研) 第七章:输入输出系统
其他各科笔记汇总
定点数原码乘法运算
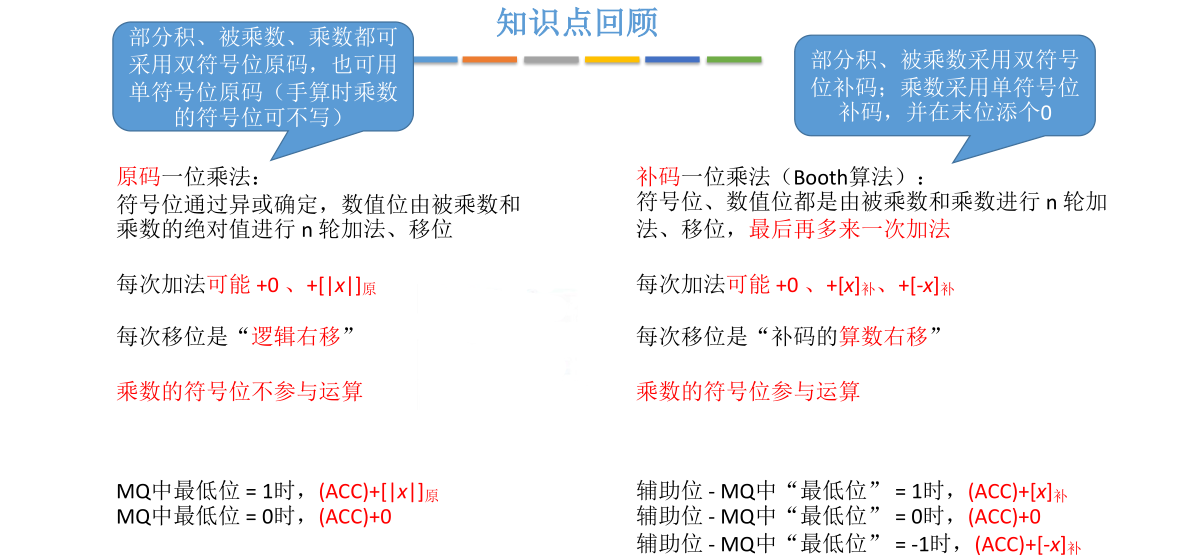
手算乘法(二进制与十进制)
模拟手算乘法的过程此处略过不记。注意理解为什么在写每一位乘得的结果的时候都要错位地写在一起


现在已经模拟了手算的思想,接下来尝试用机器来实现乘法
刚才还有一些没有考虑到的问题。第一,这个例子里是用两个正的小数相乘,但是实际的数字肯定有正负之分,所以符号位应该如何处理?
第二个问题是两个五位的定点小数相乘之后的结果有可能到达9位之多,几乎翻了一倍。如果计算机的机器字长本来就只有5位,也就是每个寄存器只能存放5位的数据,我们最终得到的乘积已经超出了一个寄存器所能保存的容量。这个问题又要如何处理?
第三个问题,刚才这个例子中乘数的每一位和被乘数相乘所得的位积都要保存下来最后再统一相加,也就是把这4个数分别保存在4个寄存器里最后再统一相加。显然这种方式是不可行的,这又该如何处理?
原码一位乘法

之前已经探讨了两个正数原码相乘如何计算。可以沿用之前的思路符号位单独处理,处理的方式很简单,把两个数的符号位进行异或运算就可以确定它们的乘积是正是负。然后用被乘数和乘数的绝对值来进行乘法运算,这样就转换成了我们之前提到的正数乘以正数的乘法思想
接下来看这两个绝对值的相乘如何用机器来实现
先回忆一下运算器的组成,运算器里面有ACC,MQ和X这三个必不可少的寄存器。当我们进行乘法运算的时候ACC内存放乘积的高位,而MQ里存放乘数和乘积的低位,X存放被乘数

下面来深挖一下背后运算的过程
首先X通用寄存器里面存放被乘数,被乘数就是x的绝对值的原码,符号位为0,后边为1101。MQ里面存放乘数,乘数是y的绝对值的原码,也就是0,1011。最后ACC里面存放乘积的高位。什么叫乘积的高位和乘积的低位后面会有体现,这里只需要知道在进行乘法运算之前要把ACC清零即可
现在对比手算乘法,刚开始计算乘数的最低位和被乘数的位积。而现在乘数存在MQ里面,这里把最低位涂成更深的灰色,更深的灰色这一位就是当前要参与运算的一个位
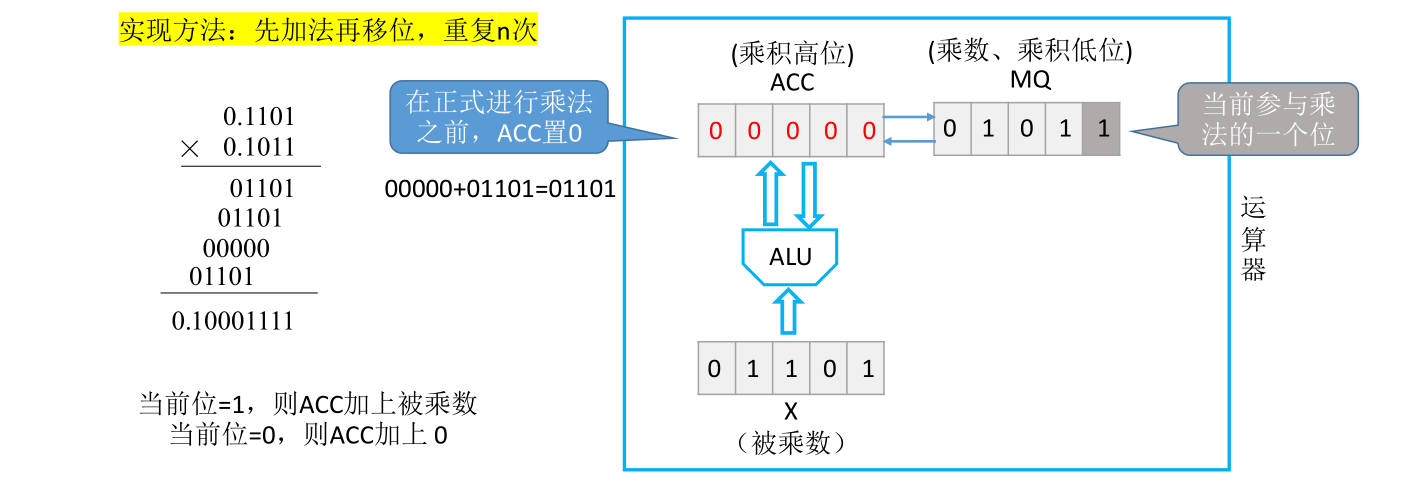
如果当前参与运算的位等于1,那需要让ACC的值加上被乘数,而如果当前位为0,那么ACC什么也不加。目前来看要参与运算的位等于1,所以让ACC里面的值和被乘数进行相加,这个过程由ALU算术逻辑单元里的加法电路完成。这两个数相加的结果是0,1101,相加的结果会被放到ACC寄存器里面,相当于把第一个位积算出来了

接下来要计算第二个位积。由于第二个位积和第一个位积进行相加的时候需要有一个错位,所以计算机的处理方式是让ACC和MQ里面的数据统一逻辑右移一位,ACC的最低位会被移到MQ的最高位。这样接下来进行加法操作时就相当于是让下一个位积和之前得到的位积进行错位相加

接下来要计算的是次低位和被乘数的位积,由于之前的右移乘数的次低位此时来到了MQ的最低位置。接下来同样用MQ的最后这一位进行位积的运算。后面位积的处理方法也都是类似的
结合之前手算的过程理解为什么每次要进行一个加法和一个移位



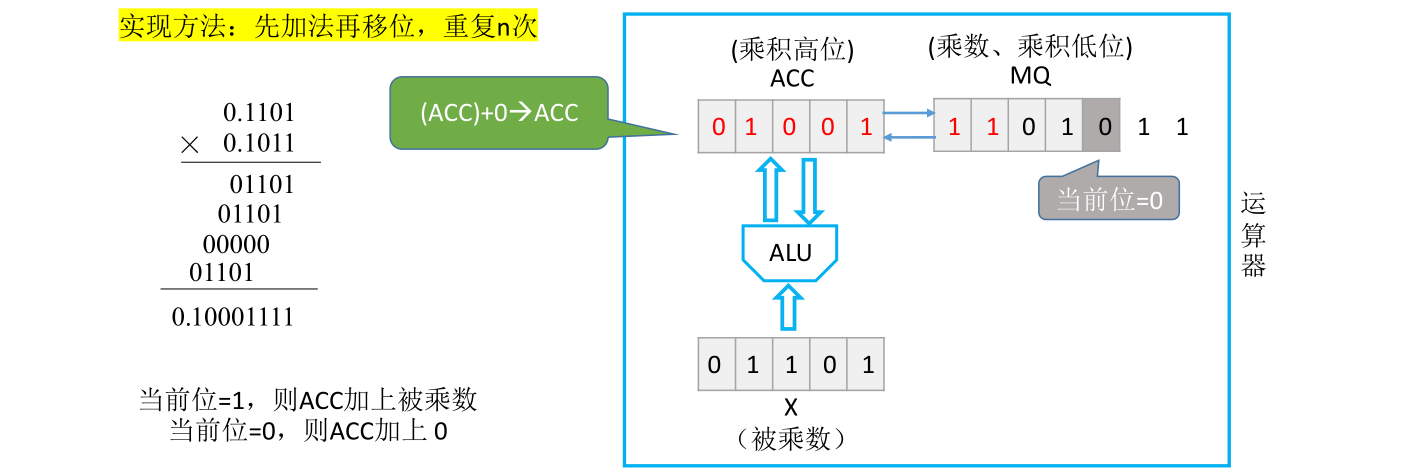
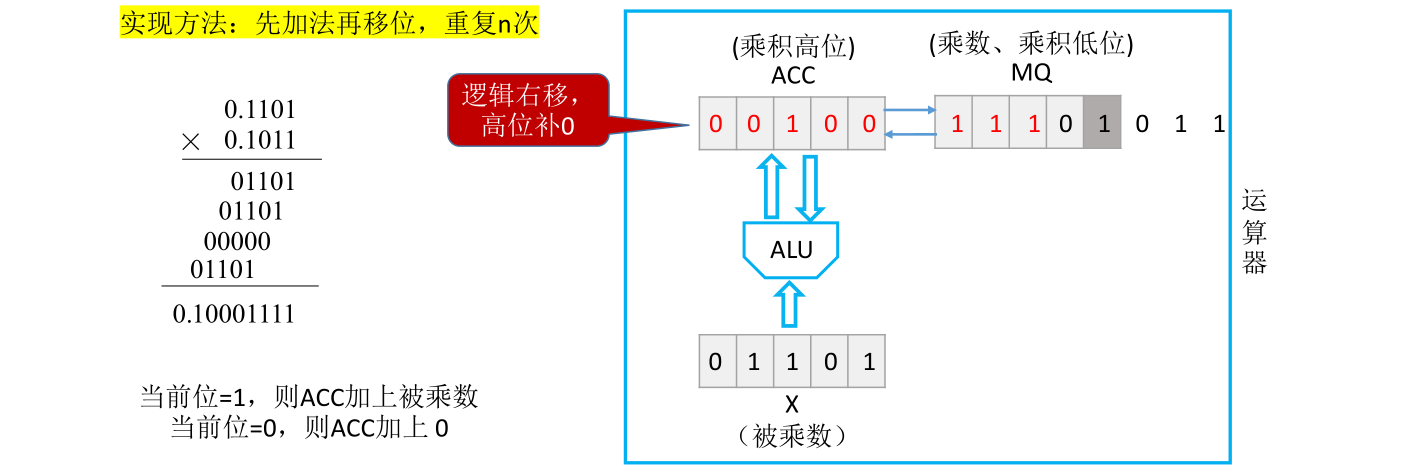
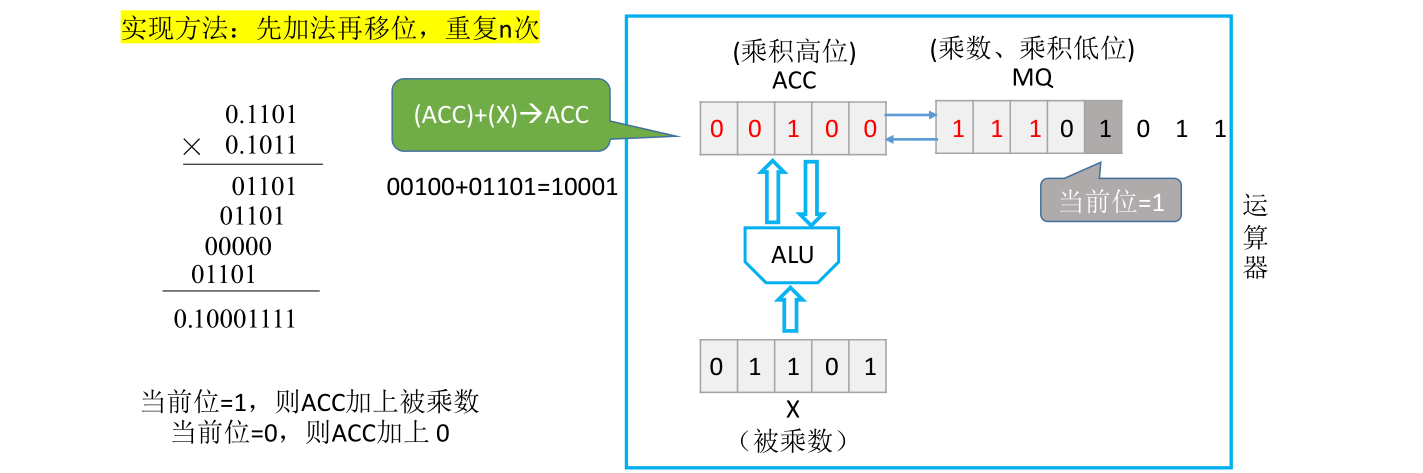

此时MQ的最后一位是0,但是这个0不需要参与位积的运算,因为这个0是原本乘数的符号位。所以在数值位有n位的情况下,只需要重复n次加法和移位就可以得到最终结果。定点小数的小数点隐含在符号位后面,所以x和y绝对值相乘的结果就是0.10001111,这和手算得到的结果一致
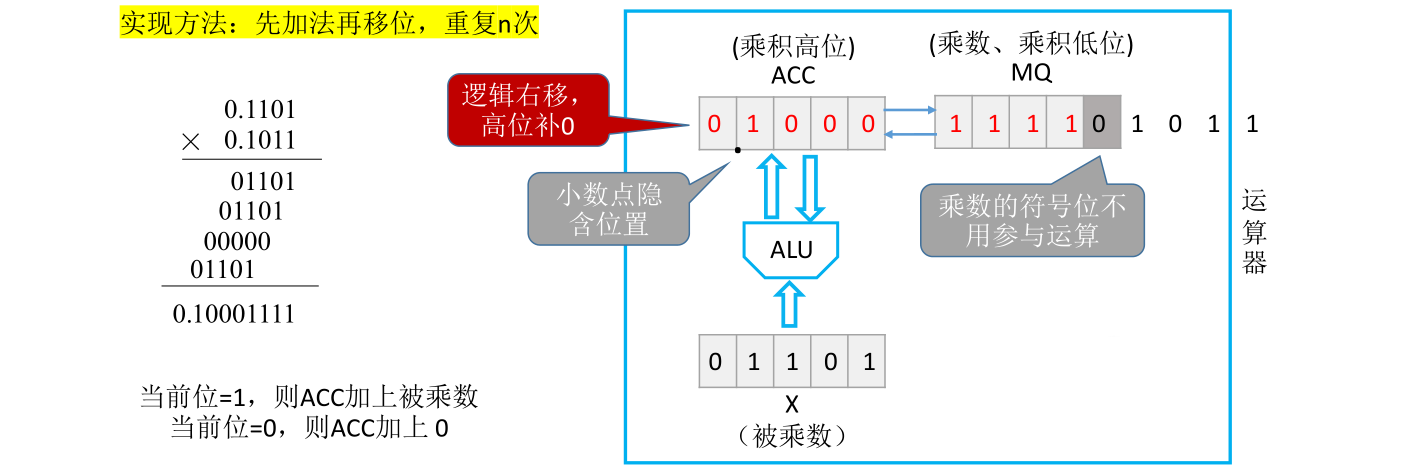
经过之前的操作得到的其实是x和y的绝对值的乘积。最后还需要根据x和y的符号位异或的结果修改这个符号位
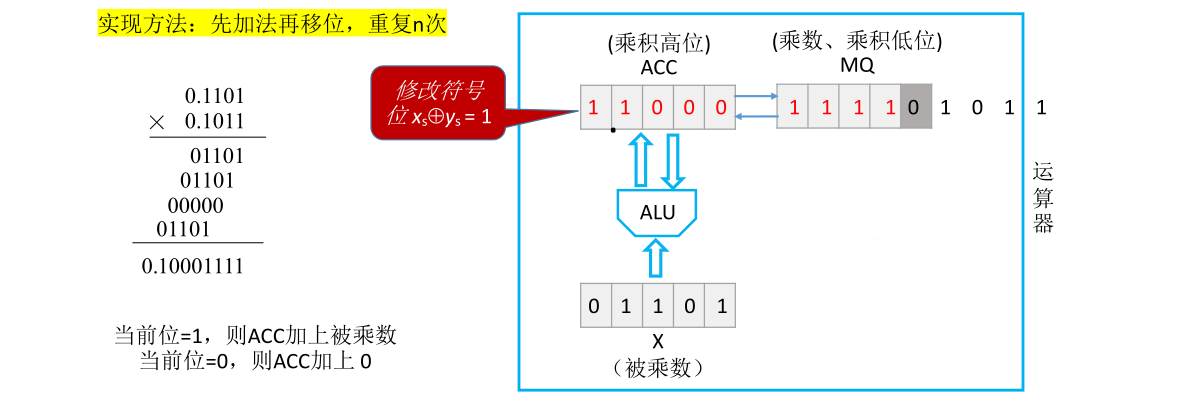
这样就得到了x和y的乘积
现在就能理解为什么说ACC里面存储的是乘积的高位,而MQ里面最终会存储乘积的低位了。至于为什么叫原码的一位乘法是因为每次参与运算的都只有一个位
还有一种更快的乘法实现方式原码的二位乘法,每次有两个位参与运算。这里就不拓展了
原码一位乘法(手算模拟)
刚才是用机器的方式来一步步模拟,接下来看做题时应该如何描述乘法的规则
计算x和y的乘积,数值部分是通过绝对值相乘来进行运算的。这里被乘数和乘数用双符号位的形式进行描述,但是事实上使用单符号位也不会出错。不过由于补码的乘法一定要使用双符号位,所以为了方便记忆,在做原码乘法的时候也可以把被乘数写成双符号位的形式保持和补码的统一

这一小节中使用小数的原码乘法作为例子,其实两个整数的乘法实现也是类似的,只需要把这个小数点改成逗号就可以。另外两个小数相乘最终得到的结果小数点固定在符号位后边,而如果算的是两个整数的乘法,最终小数点固定的位置不同
定点数补码乘法操作
补码一位乘法
原码的一位乘法和补码的一位乘法的区别见下图。此处略过不记
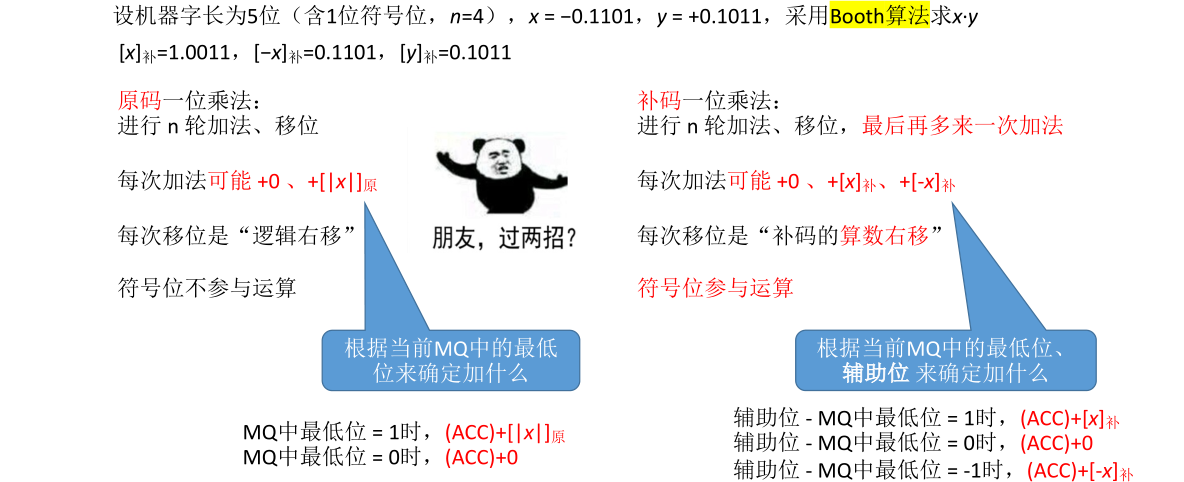
接下来看补码乘法运算的硬件构成和原码有什么不一样。把MQ寄存器的容量扩展一位,用新扩展的这一位来存储辅助位。该辅助位初始为0,之后每一轮会进行一次右移,而右移操作会导致原有的辅助位被丢弃,之前MQ参与乘运算的这一位会变成辅助位
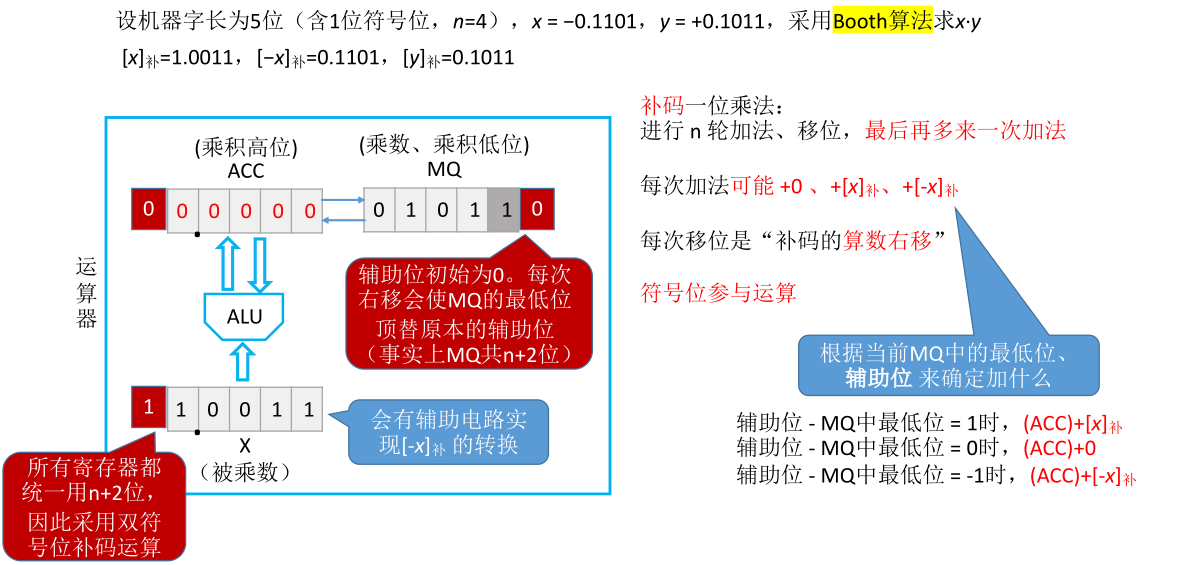
由于MQ里新增一个位,所以它总共有n+2位。CPU里面所有寄存器的长度一般都是统一的,所以由于MQ多增加了一位,因此ACC和X这些寄存器也会多增加一位。多增加的这一位可以用来表示双符号位的补码
另外需要注意的是在原码的乘法当中刚开始是在X和MQ中存入被乘数和乘数的绝对值,而这里是把完整的补码直接存入。被乘数采用双符号位的补码,而乘数采用单符号位的补码,因为MQ的最后一位会用来存放辅助位
由于之后每一轮的加法有可能加上x的补码,也就是直接加上通用寄存器里的值,也有可能加上-x的补码。为了实现x的补码到-x补码的快速转换,一般来说会设置专门的辅助电路来完成
补码一位乘法(手算模拟)

定点数原码除法运算
手算除法(二进制与十进制)
模拟手算除法的过程此处略过不记。注意理解除法竖式为什么要错位相减的原因:所谓的余数是目前所剩余的还需要拼凑的部分,每次上一个商其实就是想要尽可能的接近当前剩余的余数但是又不超过这个余数


接下来看如何把这种手算的思想用机器来实现
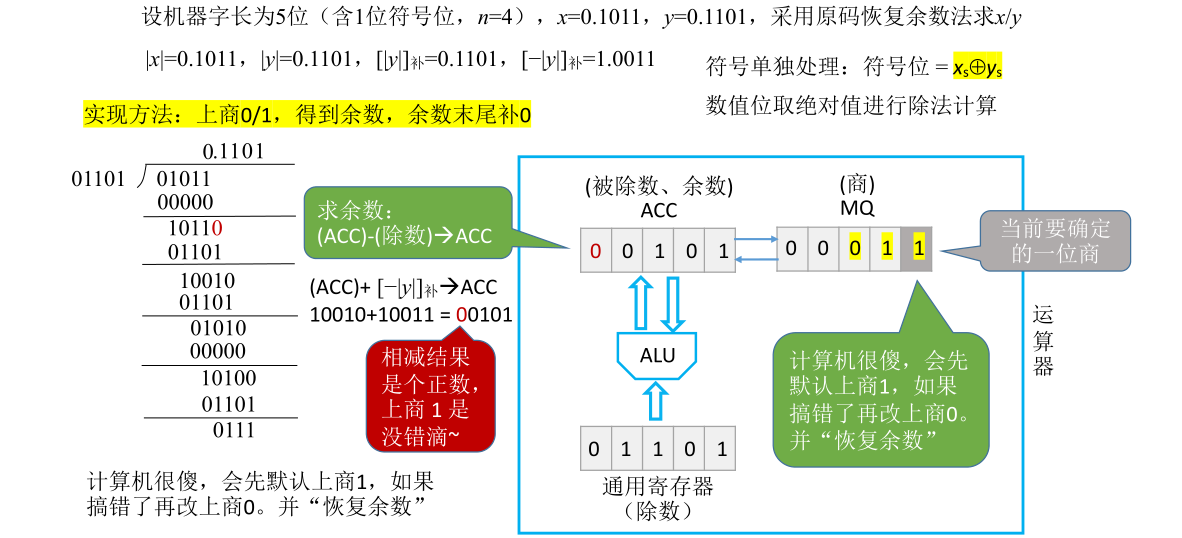
原码除法:恢复余数法
先来回忆一下运算器的组成。可以看见如果此时进行的是除法运算,ACC寄存器用于存取被除数和余数,MQ用于存储商,X存储除数

之前探讨的除法是计算两个正数,对于原码的除法来说被除数和除数有可能是正的,也有可能是负的,最终乘积的正负性会用一个单独的异或运算来确定,即把被除数和除数的符号位进行异或就可以确定最终的商应该是正是负。而商的实际数值用被除数和除数的绝对值进行除法计算,这样就可以转换成之前讨论的两个正数相除的形式
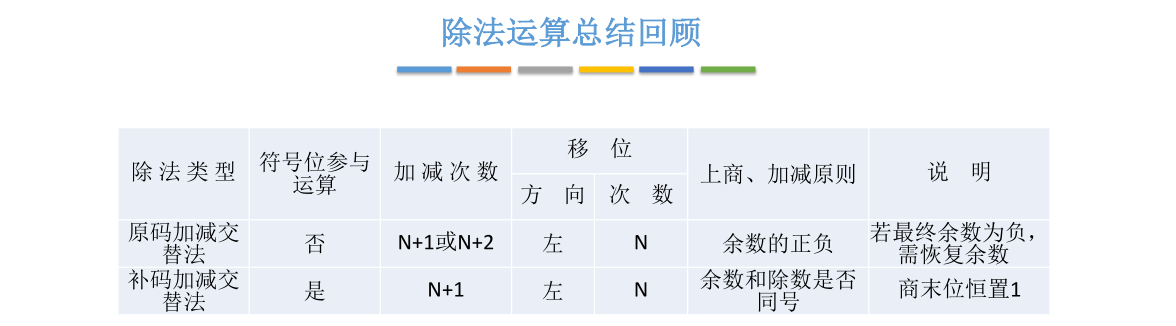
现在先忽略符号位的处理。x/y先写出x和y绝对值的原码表示,然后需要写出除数y的绝对值的补码,还有y的绝对值取负的补码(为什么这么做等下会解释)
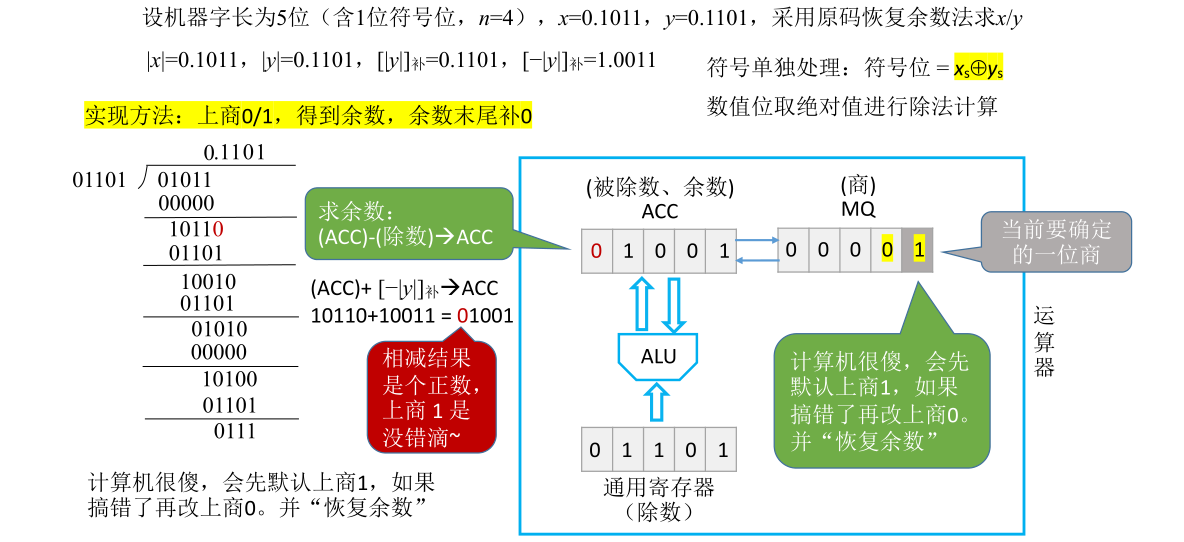
刚开始ACC里面存储被除数x的值01011,X里面会存储除数y的值01101,MQ里面存储最终的商。刚开始会把MQ全部置为0。MQ的最后一位被涂成深灰色,这一位就是当前要确定的一位商
之前手算时每一位的商到底取0/1是通过当前剩余的部分余数和除数的大小关系来确定的,这一步是心算的。对于运算器来说其实就是判断ACC里面保存的数和X里面保存的除数到底谁更大。如果ACC里面保存的更大,那么就应该商1,如果ACC里面保存的更小,就应该商0
这是一种比较理想的处理方式,但是事实上计算机并不会比较谁更大谁更小而是先默认上商1
如果这一次上商1,就意味着需要把ACC当中存储的数与X当中存储的数进行相减操作,再把相减的结果放到ACC里面。因为每一次上商1其实就是把余数减掉除数,要实现余数减掉除数就相当于要让余数加上这个除数负值的补码
这就是为什么之前要写出除数负值的补码的原因

此时要确定的是第一位商,第一位商用手算的方式知道本来是应该要上0的,但计算机会默认此时应该上1。基于之前的推论,如果这一次商要上1,就需要用ACC里面保留的被除数(也可以把它看成当前的余数)减掉除数的值,也就是加上除数负值的补码,然后再把减法操作的结果放回ACC中。这一次余数-除数的结果为11110
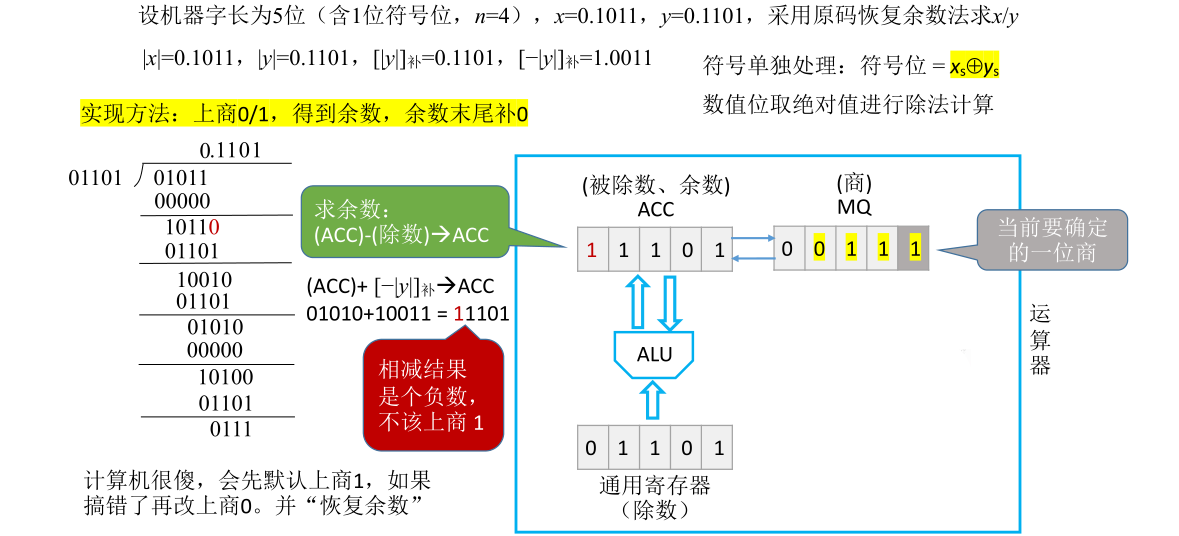
这个加法是由ALU完成的,ACC和X里面的值送到ALU,ALU里面的加法器做完加法后会把加的结果送回ACC,把ACC里面的内容覆盖。经过这一步操作ACC里面的值会被更新为11110。由于结果是个负数,说明之前的余数比除数更小,所以之前不应该上1,运算器检测到符号位为1就知道之前上商1做错了,应该把商从1改为0


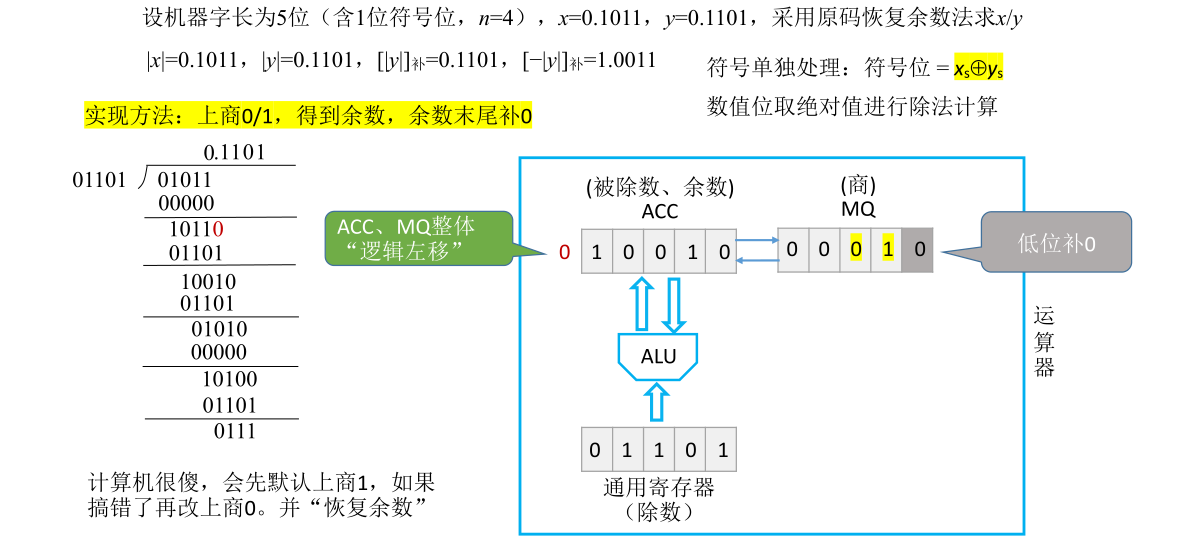
既然现在应该商0而不是商1,之前用余数减掉除数得到的值就是错误的,本来不应该减掉除数而应该是减掉全0也就是什么都不减,所以必须把ACC里面的数恢复原样。之前是减了一个除数,要把它恢复原样就要把除数加回去。运算器会在之前相减结果的基础上加上除数,把这两个数相加的结果再次送回ACC里面把ACC的内容覆盖,这样ACC里面就可以恢复成原本该有的余数也就是商0得到的余数
这就是为什么这种方法叫恢复余数法的原因,计算机最开始会默认商1,而商1得到的余数有可能是错误的,如果发现商错了,改成商0需要把余数恢复原样然后才可以进行接下来的运算
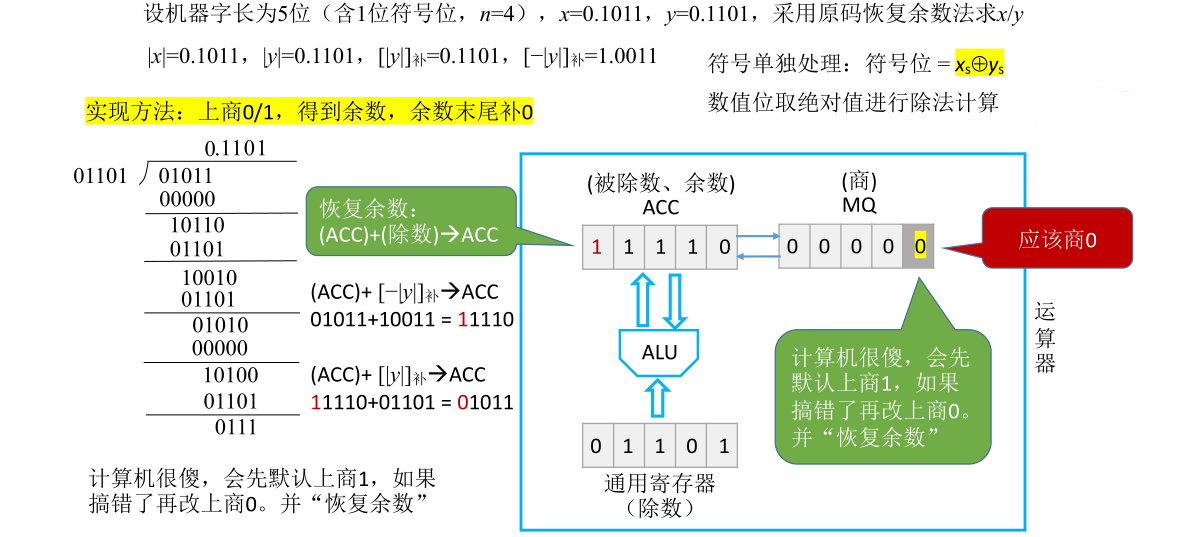

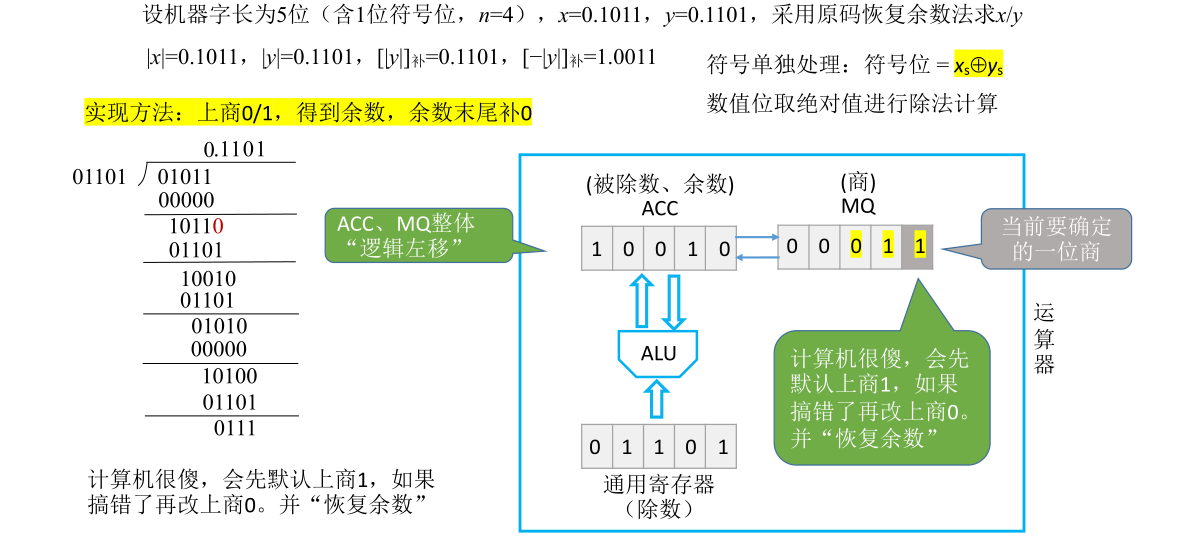
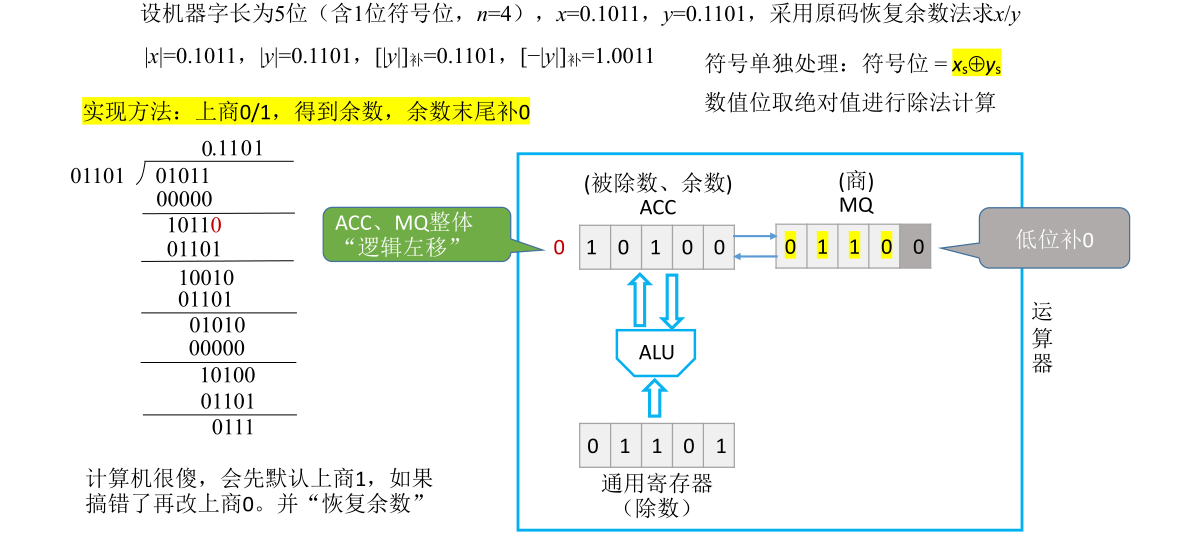
恢复了余数之后相当于已经完成商0并且相减的工作,这次相减得到的结果是01011五位余数。接下来在确定下一位商时,这一位的商乘以除数所得到的结果要和之前的余数进行错位相减,需要把首部的0去掉然后在末尾补0,这用硬件实现的方式是把ACC和MQ里的内容统一逻辑左移一位,也就是把MQ的最高位左移移到ACC的末位,然后ACC里面每一位都往前移,原本最高位的0会被丢弃。由于是逻辑左移,MQ里面空出的低位会用0补上
这样就模拟出了手算得到第二个余数的步骤,接下来就可以确定下一位的商应该商多少
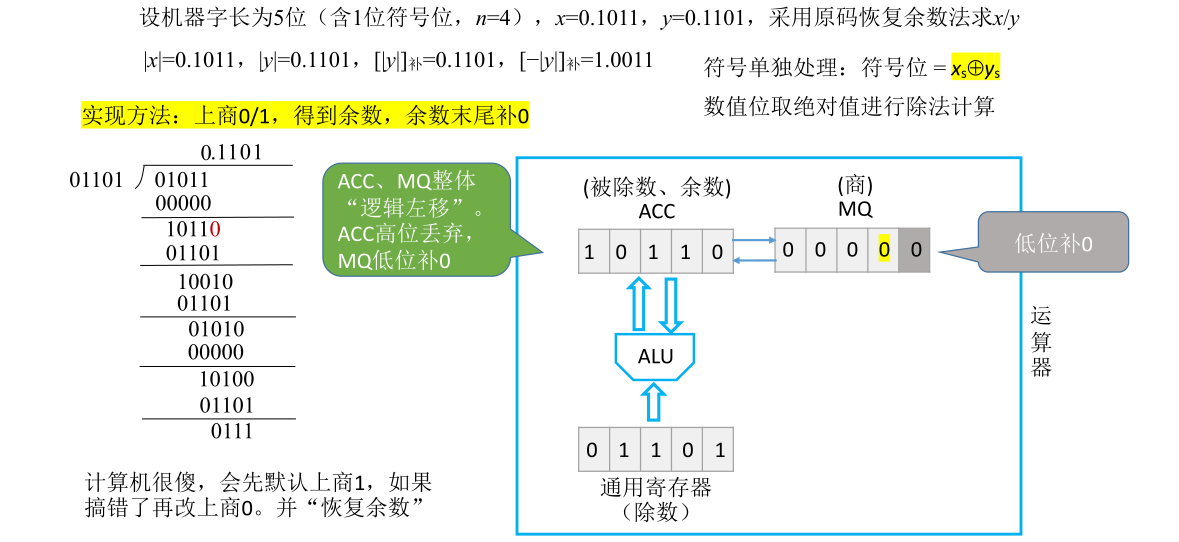
后面的过程都是类似的,重复以上过程直到求出5位的商为止(假定机器字长为5位)。此处具体过程的说明略过不记

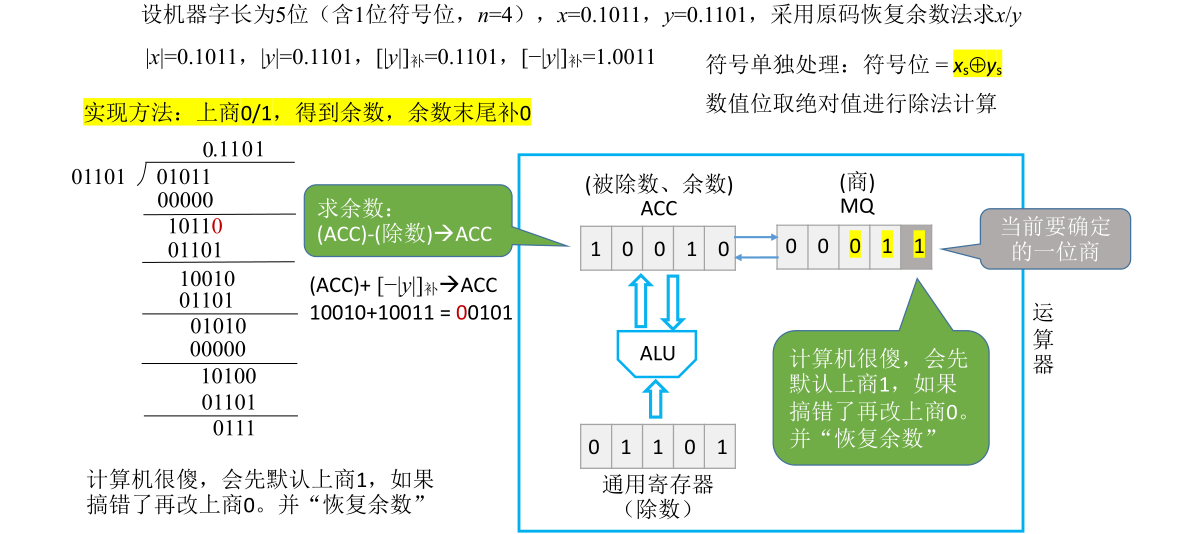





原码除法:恢复余数法(手算)
如果用手算模拟则如下

左移是为了上商,因此最后一次上商后无需左移
能不能不恢复余数,简化中间过程呢?优化思路如下,具体说明此处略过不记,其实就是合并中间步骤

基于这种思路的原码除法称为加减交替法,又叫不恢复余数法
原码除法:加减交替法
加减交替法就是把恢复余数法当余数为负时的中间的步骤统一为更简单的操作,是对恢复余数法的一种优化。原码的加减交替法符号位也要单独确定
最后还需要注意如果最后一步得到的余数是负值,同样需要把这个余数恢复原样,也就是加上除数的绝对值。所以虽然加减交替法又称为不恢复余数法,但是在最后这一步如果发现余数为负,最后这一步同样也需要恢复余数
具体的过程说明此处略过不记


在这里探讨的是定点小数的除法运算。由于是定点小数,最终得到的商肯定也只能是一个定点小数而不能是一个整数。因此在定点数的除法运算当中会规定被除数一定要小于除数,因为被除数如果大于除数则最终商的结果肯定要大于1,而定点小数无法表示大于1这样一个范围。那么硬件怎么检查被除数和除数的大小关系?
其实就是通过第一步的商来确定的。正常情况下第一步减除数所得到的除数一定要是一个负值,如果第一步得到的就是一个正值也就是要商1则说明被除数要比除数更大。此时硬件电路就会检测出这个问题并且直接停止除法运算,这种除法是没办法用定点小数表示的
定点数补码除法运算
补码的除法运算和原码除法的加减交替法有很多类似的地方,二者可以对比学习。在原码的加减交替法当中,第一步一定是用被除数-除数的绝对值得到新的余数,然后接下来每一步根据当前余数的正负性来确定应该商0还是商1,是进行加法还是减法。符号位单独确定,不直接参与运算

与原码的加减交替法相比,补码的加减交替法会让符号位也参与运算并且被除数/余数,除数采用双符号位表示。注意下面除数是个负数,但写的并不是除数的绝对值的补码,这点和原码的加减交替法是不一样的,因为会让符号位也直接参与到运算里面
下面来看一下具体的执行步骤
在原码的加减交替法当中第一步一定是用被除数减掉除数绝对值的补码,但是在补码的加减交替法当中第一步需要根据被除数和除数是否同号来判断应该进行加还是减
之后每当得到一个余数之后,就通过判断余数和除数是否同号来确定商1还是商0,余数左移一位后是减去除数还是加上除数
注意在补码的加减交替法当中,最后这一位的商会进行特殊处理恒置为1。这么做的好处是省事,并且末尾恒置为1带来的误差也不会超过2−n2^{-n}2−n。在原码的加减交替法当中如果最后这个余数的正负性有问题可能还需要恢复余数。但是在补码的除法当中最后这一步恒置为1,除法运算到此结束,不需要再管最后的这个余数是否要恢复的问题,这样硬件电路的设计相应更方便
具体为什么可以结合每一位的位权来思考

C语言中的强制类型转换
本节探讨C语言中的那些定点整数是如何进行强制类型转换的
注意C语言当中的定点整数,比如intintint,short,long都是用补码的形式存储的。而unsigned关键字则意味着这个定点整数是一个无符号数
具体的类型转换规则见下图,此处略过不记

数据的存储和排列
大小端模式
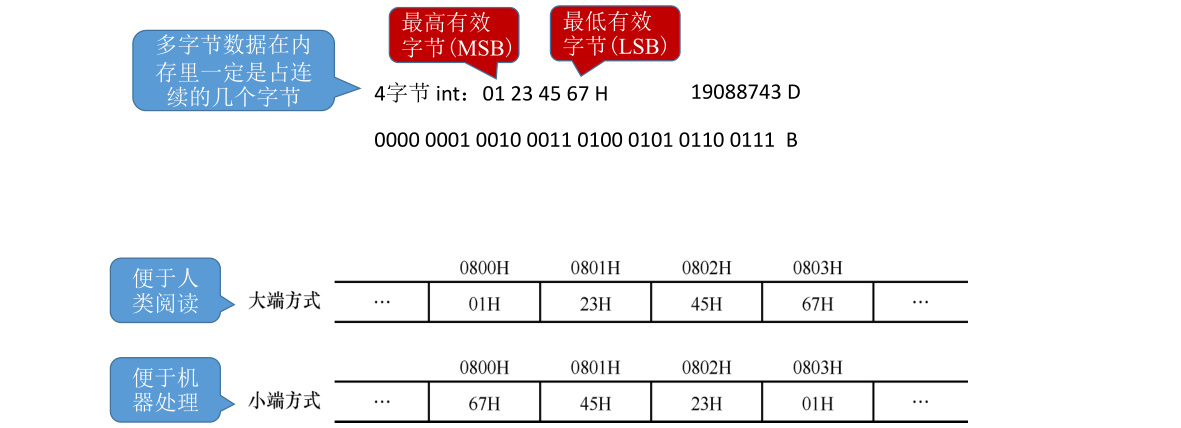
小端方式更便于机器处理,因为机器在处理时通常也是按照内存地址递增的次序来读取这个多字节数据里边的每个字节或者每个字的,小端模式会先读入最低有效字节再读入最高有效字节,这么做是有好处的,例如如果CPU每次只能处理8位二进制的加法运算,那么对两个intintint型变量进行加法操作时显然应该先从它的最低有效字节进行加法然后再加次低位的字节,如果使用小端方式来存储那么计算机首先从内存里读入的就是最应该先被处理的字节
边界对齐

现代计算机都是按字节编址的,也就是说无论要访问的是字,半字还是字节最终肯定要转换成相应的字节地址,转换方法就是逻辑左移
每次访存只能读/写1个字,并且这里所指的1个字就是上图中的一整行,不能跨行读取。基于这种特性,计算机会采取数据边界对齐方式或者边界不对齐方式
举个例子,在C语言里面char型变量刚好占1个字节,而short型变量占2个字节,intintint型变量占4个字节。如果现在定义了一个结构体,包含3个char型变量、3个short型变量和1个intintint型变量。在存储了刚开始的3个char型变量之后,最开始的这一个字还会剩下1个字节的空间,但是接下来要存储的short型变量必须占0.5个字也就是2个字节。如果采用边界不对齐的方式,可以把这个short型变量分两部分存储在上下两字,基于之前讲的访存特性,当要读出这个short型变量时必须进行两次访存。只有把这两个字的内容都读入然后把最末尾和最开头的字节进行拼接才可以得到short型变量的完整表示。而如果采用边界对齐的方式存储,一行最后只剩一个字节存不下半字的数据就会把这一个字节浪费掉,虽然空间上有浪费,但是当要读入这个short型变量时只需要进行一次访存就可以了,因为这个变量的所有数据都是存放在这一整个字里面的
浮点数的表示

之前几节学习了定点数(包括定点整数和定点小数)如何在计算机里表示,从这一小节开始学习浮点数在计算机里的表示与运算
定点数可表示的数字范围有限,但我们不能无限制地增加数据的长度,如何在位数不变的情况下增加数据表示范围?
计算机里的浮点数和科学计数法的思想是相通的。使用科学计数法来表示一个数时底数10是不会变的,既然这个底数一定是10固定不变,采用科学计数法记录这个数字时不记录10也可以
下图中左边蓝色的部分叫阶码,表示这是10的多少次方。阶码由阶符和阶码的数值部分组成,阶符为正表示要把小数点往后移,阶符为负表示要把小数点往前移,阶码的数值部分指明了小数点要移动多少位。右边绿色的部分叫尾数,尾数同样有正负号,这个符号表示了整个数值的正负性,后边的数字则被称为尾数的数值部分,该部分越短科学计数法能表示的数字精度越低
这是我们熟悉的十进制科学计数法,下面来看在计算机里二进制的浮点数是什么原理
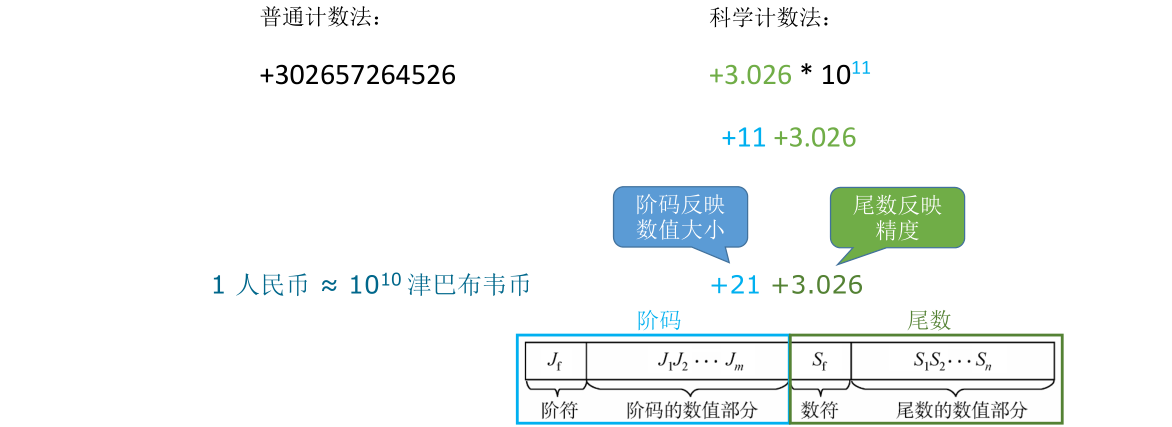
浮点数的表示
以前学习的二进制的定点数小数点位置是固定不变的。比如用定点数表示的小数一般来说会默认小数点固定在符号位的后面,定点整数会默认小数点固定在数值位的最后面。而浮点数小数点的位置是会浮动的,具体浮动多少看阶码到底是多少
阶码的底通常为2,但是取2i2^i2i也可以,这有点类似于十进制里阶码的底数通常取10,但是也可以取100,1000等
阶码的位数是固定的,它的值也只能表示某个范围的数,而阶码的范围也就反映了浮点数的表示范围

上图中如果采用1B的存储空间来存储b这个浮点数的话,阶码占3位但是尾数部分占6位,最后这个1存不下只能把它抛弃掉,而这会降低精度。能不能把浮点数的表示进行优化,在存储空间不变的情况下尽可能的多保留它的精度呢?这就是浮点数尾数的规格化问题
浮点数尾数的规格化
直接见下图说明即可,此处具体讲解略过不记
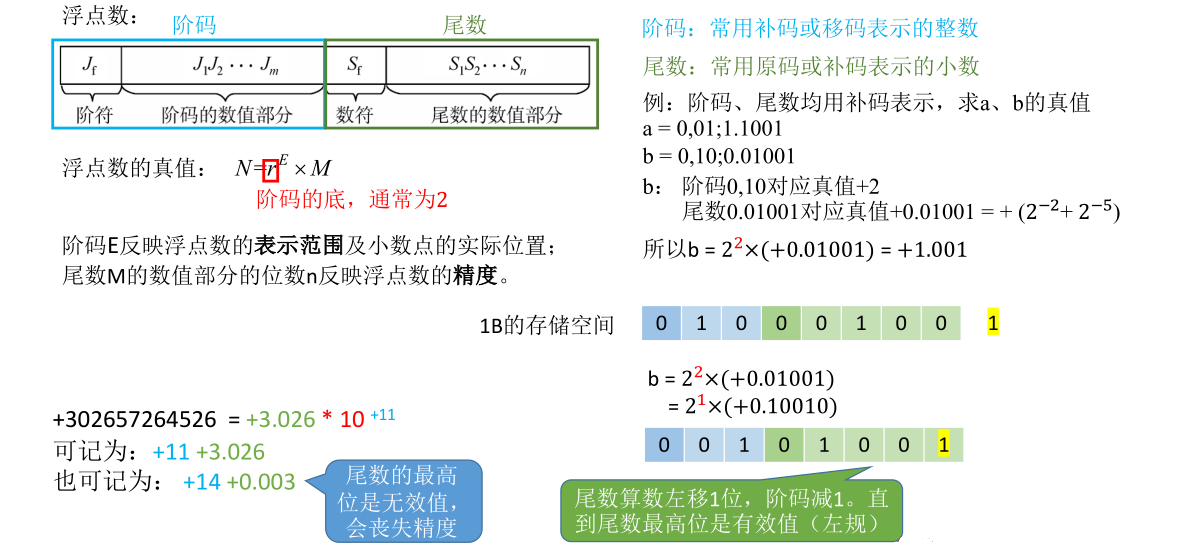

规格化浮点数的特点
直接见下图说明即可,此处具体讲解略过不记
这里需要注意的是如果用补码表示尾数,并且这个尾数是负数时为了让计算机处理起来方便会规定数值位的最高位必须是0。只有满足这样的规律用补码表示的尾数才是规格化的
总之这里想要强调的是尾数采用原码表示还是补码表示会影响到规格化的规则

浮点数的表示范围考研不考,此处略过不记
浮点数标准IEEE 754
上一小节中学习了浮点数的基本构成和原理,浮点数大致上由阶码和尾数这两个部分组成。如果不能确定一个统一的规则来决定阶码占多少位,尾数占多少位,各自采用原码、补码还是移码来表示,在计算机之间进行数据传输就可能产生一些解析方面的困难和问题
先复习一下移码的定义,移码只能用于表示整数,而浮点数的阶码也只需要用整数来表示

之前这种方式能够简单快速地理解移码和补码之间的联系。但是移码本身另有定义,这里引入偏置值的定义。除了2n−12^{n-1}2n−1,偏置值也可以取别的值


注意上图中当偏置值取127D且真值取-128时,偏置值的绝对值比-128的绝对值要更小,这时加法操作要怎么做?
由于移码的位数只有8位,所以所有的加减运算在背后都默认会进行mod28mod2^8mod28。当在mod28mod2^8mod28这个条件下进行加减法时可以在原有的基础上再加上282^828(即100000000)。加上这样一个值之后整体的减法得到的结果是不会变的
接下来正式学习IEEE 754标准所规定的浮点数格式
IEEE 754 标准
C语言里的float/double/longdoublefloat/double/long\quad doublefloat/double/longdouble型变量就分别遵循了该标准里的短浮点数,长浮点数,临时浮点数的要求

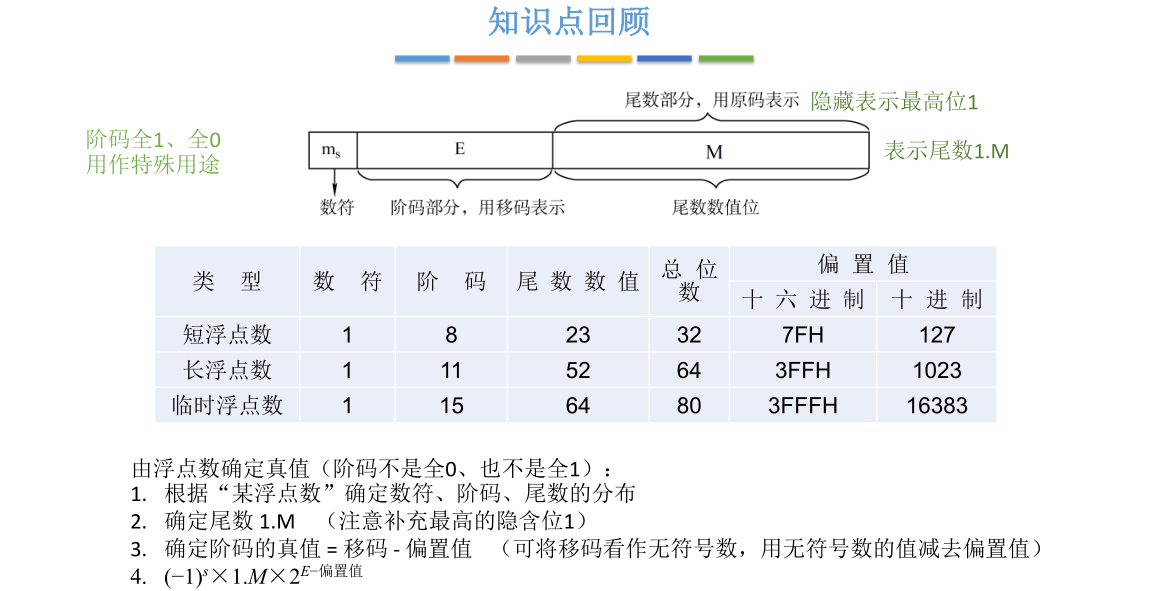
之前说过对于一个尾数用原码表示的浮点数会希望第一个有效数值位为1,也就是所谓浮点数规格化的问题。那可以干脆默认在这一部分尾数之前隐含了一个最高位的1,这样就免去了必须要规格化的步骤。所以虽然短浮点数的尾数只有23位,但是事实上有效位有24位,因为默认前面隐含了一个1,1.M才是这个尾数真正表示的数值
另外上页讲过8位的移码可以表示的范围应该是-128$\sim127。但是当偏置值为127时,−128和−127的移码表示会比较特殊,一个是全1一个是全0。在IEEE754标准中会把阶码全1和全0这两个状态用作特殊用途,所以8位的阶码正常真值范围只会取到−126127。但是当偏置值为127时,-128和-127的移码表示会比较特殊,一个是全1一个是全0。在IEEE754标准中会把阶码全1和全0这两个状态用作特殊用途,所以8位的阶码正常真值范围只会取到-126127。但是当偏置值为127时,−128和−127的移码表示会比较特殊,一个是全1一个是全0。在IEEE754标准中会把阶码全1和全0这两个状态用作特殊用途,所以8位的阶码正常真值范围只会取到−126\sim$127
下面举了两个例子,此处具体讲解略过不记


接下来再探讨IEEE 754单精度浮点型能表示的最小和最大绝对值,对于双精度浮点型的最小和最大绝对值也可以用一样的方法分析,只不过尾数和阶码的最大值和最小值发生了一些改变而已,原理都是类似的。直接见下图说明即可,此处具体讲解略过不记。注意尾数最高部分隐含了一个1

若要表示的数绝对值还要小,就要用到阶码全1和全0两个状态
对于单精度浮点数来说阶码总共占8个bitbitbit,如果把它看作是无符号数,则能表示范围0∼2550\sim2550∼255。无符号数0刚好对应二进制全0,无符号数255刚好对应全1,所以刨除全0和全1这两个状态,当阶码部分的值处于小于254大于等于1的区间时才是之前所探讨的正常区间
当然这里对阶码的解读是把它看作是无符号数,并不是说它的真值落在这个区间,这不要混淆
当阶码不是这两种特殊状态时,用之前提到的这种方式就可以确定这个单精度浮点数的真值是多少,否则就要特殊处理。直接见下图说明即可,此处具体讲解略过不记

这一小节介绍了IEEE 754标准所规定的短浮点数,长浮点数和临时浮点数的基本结构。上面举的例子主要基于短浮点数,而长浮点数和临时浮点数的分析方法也是一样的,只不过阶码和尾数数值这些部分的比特位发生了变化
无论是哪种类型的浮点数都要记住尾数部分用原码表示,同时会规定正常情况下在高位会隐含一个1,也就是在尾数的前面加一个小数点再加一个1,这1.M才是尾数真实的值。另外阶码部分采用移码表示,只不过这个地方的移码偏置值为2n−1−12^{n-1}-12n−1−1而不是2n−12^{n-1}2n−1。只有确定了偏置值为多少,才能确定阶码真值是多少。确定阶码真值的方法是把移码看作无符号数,用无符号数的值减去偏置值。确定了阶码的真值,然后在尾数前面补一个1,最后再结合数符位所反映的正负性就可以确定整个浮点数的真值是多少。而阶码全1和全0会用作一些特殊的用途
浮点数加减运算 强制类型转换
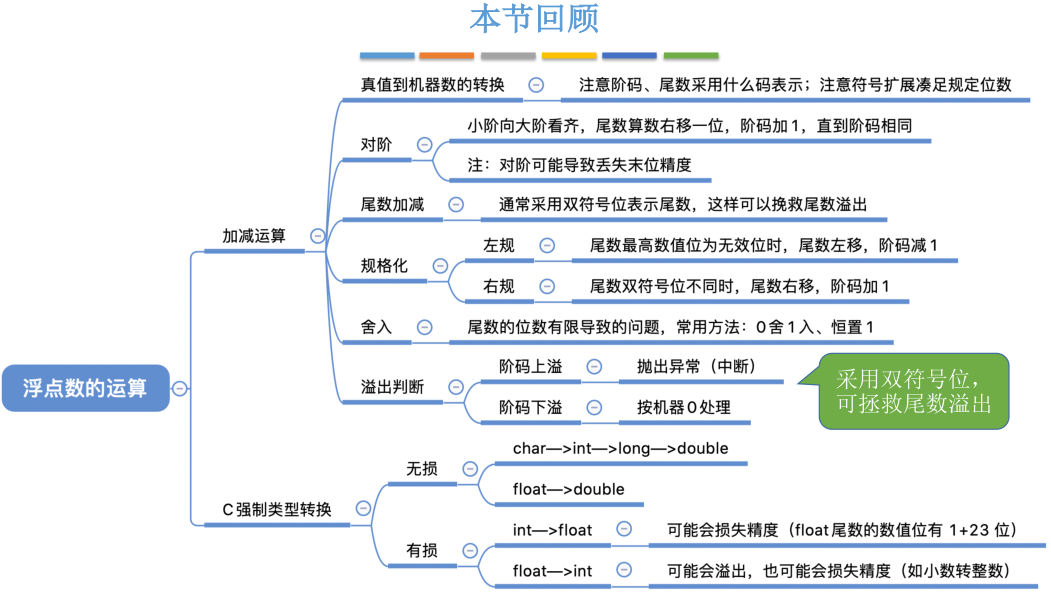
浮点数的加减运算
下图解释了基于十进制科学计数法的对阶,尾数加减,规格化,舍入,判溢出这几个步骤所要做的事情。接下来要介绍的浮点数加减运算的这些步骤和科学计数法都是相通的。直接见下图说明即可,此处具体讲解略过不记

之所以让阶数更小的向阶数更大的对齐,是因为方便用计算机处理尾数。计算机内部尾数是定点小数,小数点的位置固定不变,占在计算机硬件的角度,如果让阶数更高的向阶数更低的对齐,也就是把9.85211×10129.85211\times 10^{12}9.85211×1012变成985.211×1010985.211\times 10^{10}985.211×1010,小数点的前面会有好几个有效值,想让小数点固定在好几个有效位后面是很难实现的,不太容易用计算机处理。而如果让阶数更小的向阶数更大的对齐,只需要做算术右移就可以,计算机硬件做这种处理很简单
接下来看二进制浮点数加减运算的例子,直接见下图说明即可,此处具体讲解略过不记


这题介绍的浮点数尾数部分显然并不会隐含最高位1,所以这里需要把尾数转变成0.XXX…的格式,后面对尾数进行长度扩展时定点小数的补码在末尾添0
计算机如何判断谁的阶数更小?只需要把两个数的阶数进行相减操作
尾数加减后两个双符号位不一样,说明尾数发生了溢出,只不过这个溢出是可以拯救的。结合之前的二进制真值表示,X-Y经过之前的对阶和尾数相减操作得到尾数的值已经大于1,由于定点小数无法表示大于1的值,所以这里发生了溢出
尾数采用双符号位补码的一个好处就是可以通过右规操作拯救刚才的溢出,算术右移时高位补多少具体得看双符号位的更高位,因为双符号位的更高位表示正确的符号
进行算术右移时抛弃了一个最低位的0,并不会对整个浮点数的精度造成任何影响,所以这个例子不需要考虑舍入的问题
溢出判断时判断阶码是否越界,阶码采用双符号位补码,所以只需要判断阶码两个符号位是否相同
接下来再看一个需要舍入的例子
浮点数的加减运算 - 舍入

有的计算机可能会把浮点数的尾数部分单独拆出去计算(24bit$\to32bit),算完了经过舍入(32bit32bit),算完了经过舍入(32bit32bit),算完了经过舍入(32bit\to$24bit)再拼回浮点数
进行规格化和舍入之后会导致阶码的值发生改变,如果阶码的值超出上限就说明发生了上溢,而如果阶码的值低于它所能表示的下限就发生下溢。下溢直接当作机器数0,并不会当作错误处理,而上溢必须抛出系统异常或者中断
强制类型转换
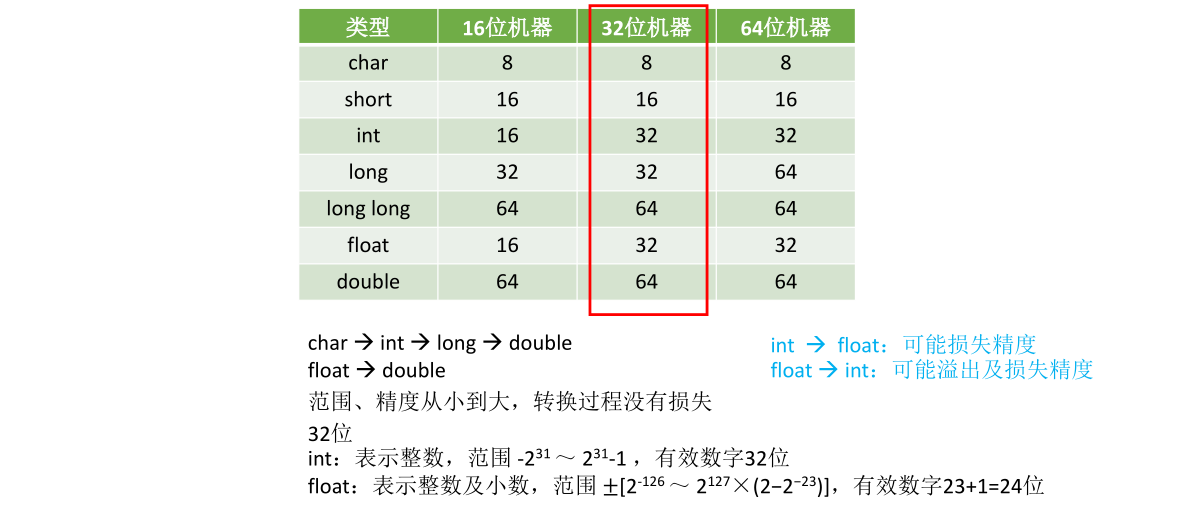
在C语言里经常会遇到上述数据类型,当机器字长,系统的位数不一样时,各种变量的比特位也会呈现出一些区别。现在使用的电脑一般都是64位机器,但是由于大部分教材编写的时间较早,所以考试考察强制类型转换时通常会按照32位机器的变量长度考察。最关键的区别是intintint型和long,在32位的情况下long型也是占32位,而double双精度浮点一定是64位,64=1(符号) +11(阶码) + 52(尾数),这52位尾数再加上一个隐含的1,实际double类型可以表示的尾数有效数值位应该是53bit
所以若按照char→int→long→double,float→doublechar\to int\to long\to double,float\to doublechar→int→long→double,float→double这样的方式来进行强制类型转换都是无损转换,数据的精度不会丢失,数据的表示范围也不会缩小
char→intchar\to intchar→int很简单,因为char可以理解为一个8位的整数,而intintint是32位的整数,long型和intintint型一样也是32位的整数,所以前面这几步char→int→longchar\to int\to longchar→int→long都是无损的转换
再看long→doublelong\to doublelong→double,long型这里默认是32位,而double型的尾数实际有53位,53位尾数肯定能表示32位数所能表示的任何一个精度,所以由32位的long型转变为double型由于double型的尾数更长,精度不会丢失
float→doublefloat\to doublefloat→double不会损失精度,float型的尾数是1+23位,double型的尾数是1+52位,显然精度不会丢失。另外double型的阶码是11位,而float型的阶码是8位,所以float型能表示的数double型肯定能表示
再看常考的32位intintint型向float型转换。intintint型变量表示的是一个定点整数,为1(符号位)+31(有效数值位),而float型变量为1(符号位)+8(阶码)+23(尾数),23位尾数之前还会有一个隐含的1,所以float型变量的尾数实际有效数值应该是24位
显然用24位不能表达31位所能表达的精度,故intintint型转float型肯定会有精度的损失。考虑到float型的8位阶码所能表示的数的范围肯定比int型大,所以intintint向float转化只会损失精度而数字范围不可能溢出,、
而float型向intintint型转化则可能溢出及损失精度,发生溢出很好理解,因为float型所能表示的范围已经超出了intintint型所能表示的范围。float型变量可能表示一个小数,如0.000111,这个小数在转变为intintint型变量的时候会把末位全部截断也就是转变成整数的0,这种情况下float型转intintint型就会有精度的损失
如果题目告诉你long型变量占64个位,那么long型向double型转化就会有精度的损失,53位的尾数肯定不能表示64位所能表示的精度
计算机组成原理笔记(王道考研) 第二章:数据的表示和运算2相关推荐
- 第二章 数据的表示和运算 2.1.6 循环冗余校验码/CRC码 [计算机组成原理笔记]
第二章 数据的表示和运算 2.1.6 循环冗余校验码/CRC码 本笔记参考书目: 计算机组成原理(第六版.立体化教材)白中英.戴志涛 2021王道计算机组成原理视频公开课 本节重点: 循环冗余校验码/ ...
- 第二章 数据的表示和运算 2.1.5 汉明(海明)校验码 [计算机组成原理笔记]
第二章 数据的表示和运算 2.1.5 汉明(海明)校验码 本笔记参考书目: 计算机组成原理(第六版.立体化教材)白中英.戴志涛 2021王道计算机组成原理视频公开课 本节重点: 海明(Hamming) ...
- 第二章 数据的表示和运算 2.1.4 奇偶校验 [计算机组成原理笔记]
第二章 数据的表示和运算 2.1.4 奇偶校验 本笔记参考书目: 计算机组成原理(第六版.立体化教材)白中英.戴志涛 2021王道计算机组成原理视频公开课 本节重点: 奇偶校验的方法/原理 码距和检/ ...
- 第二章 数据的表示和运算 2.1.3 字符与字符串 [计算机组成原理笔记]
第二章 数据的表示和运算 2.1.3 字符与字符串 本笔记参考书目: 计算机组成原理(第六版.立体化教材)白中英.戴志涛 2021王道计算机组成原理视频公开课 本节重点: ASCII码/汉字编码 字符 ...
- 第二章 数据的表示和运算 2.1.2 BCD码 [计算机组成原理笔记]
第二章 数据的表示和运算 2.1.2 BCD码 本笔记参考书目: 计算机组成原理(第六版.立体化教材)白中英.戴志涛 2021王道计算机组成原理视频公开课 本节重点: 8421/2421/余3码 转载 ...
- 第二章 数据的表示和运算 2.1.1 进位计数制 [计算机组成原理笔记]
第二章 数据的表示和运算 2.1.1 进位计数制 本笔记参考书目: 计算机组成原理(第六版.立体化教材)白中英.戴志涛 2021王道计算机组成原理视频公开课 本节重点: 二进制 <-> 八 ...
- 计算机组成原理ppt免费,计算机组成原理(白中英)第二章1.ppt
计算机组成原理(白中英)第二章1.ppt (8页) 本资源提供全文预览,点击全文预览即可全文预览,如果喜欢文档就下载吧,查找使用更方便哦! 15.9 积分 第二章 运算方法和运算器 2.1 数据与文 ...
- 王道计算机组成原理课代表 - 考研计算机 第二章 数据的表示和运算 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 计算机组成 知识点的理解的总结.希望对新一届的计算机考研人提供帮助!!! 关于对 数据的表示和运算 章节知识点总结的十分全面,涵括了 ...
- (王道计算机组成原理)第二章数据的表示和运算-第二节7:定点数除法运算(原码/补码一位除法)
王道考研复习指导获取:密码7281 专栏目录首页:[专栏必读]王道考研408计算机组成原理万字笔记.题目题型总结.注意事项.目录导航和思维导图 文章目录 一:除法运算基本思想 二:原码一位除法:恢复余 ...
- 计算机组成原理 第二章 数据的表示与运算
第二章主要是一些有关计算机内部的计算的知识,还包括计算机数据的存储,重点在于计算的方法. 2.1数制与编码 计算机内采用二进制进行编码,这样做的原因有: ①二进制只有0和1两种状态,正好与计算机内的高 ...
最新文章
- java selenium (十四) 处理Iframe 中的元素
- 第五章 文件和目录管理
- Js - Dom原生对象和jQuery对象的联系、区别、相互转换
- 信息系统项目管理师-学习方法、重难点、10大知识领域笔记
- python3.4编程_求教python3.4的编程问题
- 大学生学编程系列」第五篇:自学编程需要多久才能找到工作?
- 创业产品经理需要懂技术吗?
- 如何通过VC的 CHttpFile 抓取网页内容
- K8s中Pod健康检查源代码分析
- CentOS7下使用yum安装MariaDB
- python之验证身份证号合法性的库:id_validator
- sourcetree克隆一直不成功_Git神器| SourceTree安装使用教程
- 【记录】C++中的类成员调用
- 循环控制语句转换为汇编
- C语言 static静态变量
- 05 库的简单操作
- 宝塔 python项目管理器2.0 部署django项目 uwsgi
- 写代码不严谨,我就不配当程序员?
- linux jdk下载并安装
- 华为鸿蒙wifi认证,鸿蒙 WiFi操作,热点连接
热门文章
- ECCV 2022 Oral | 无需微调即可泛化!RegAD:少样本异常检测新框架
- 如何获得FLV视频下载地址并下载
- matlab ode45例子,matlab的ode45
- 1.488Mpps是如何计算出来的
- vue引入echarts中国地图 Cannot read properties of undefined (reading ‘echarts‘) at eval (webpack-inter
- 端口碰撞Port Knocking和单数据包授权SPA
- Python生成透明背景图片
- 关于linux下UART串口编程的困惑
- ONOS(Open Network Operating System) from ONF
- 2019届高三理科数学选择填空整理