数据分析从零到精通第三课 python自动化和BI数据可视化实战
05 效率提升:如何通过邮件报表释放人力
本课时主要分享从零搭建数据邮件日报系统的方法,从而满足业务方的定期数据需求。希望通过本课时的介绍,你可以立刻在自己机器上实践定时邮件发送的任务。
邮件日报的业务场景
数据分析师日常工作会接到很多数据统计需求,其中有很多数据需求,都是周期性的固定数据指标。
举两个例子。
产品同学,需要跟踪自己某个新产品功能的每日核心指标,比如 UV、PV、留存等。
运营同学,每逢近期节日大促都需要在节日期间每天复盘前一天的销量情况。还需要知道进入活动页面的人数、浏览深度、加购物车量、下单量等。
对于这类周期性重复数据需求,最容易的解决方法就是:通过邮件数据日报系统发送数据报告解决。
互联网公司, 尤其是偏向重度经营类型的电商公司,对日报、周报、月报的依赖度往往很高,员工邮箱里都是来自各个业务线的日报、周报、月报。
一般来讲,大公司都会有完善的 OLAP 查询系统,并且可以设置周期性质数据处理任务。你只需要将脚本放到指定位置,然后设置每天几点几分执行,系统就会将执行结果保存到某个位置。这样数据就可以用于报表可视化或者通过邮件发送了。但是,很多中小型公司使用的 OLAP 系统没那么完善。可能这个系统不支持邮件发送数据结果。这时候,作为数据分析师,就有必要自己搭建一个简单的邮件日报系统了。一来可以让机器帮助自己干活儿,节约工作时间;二来业务方也能及时获得自己数据,提高合作效率。
下面,我来分享下如何基于 Linux 系统,搭建邮件日报工具。
搭建邮件日报实战
邮件日报的目的在于:在指定时间将数据处理的结果发送到指定邮箱。所以有两个需要注意的环节:第一,定时数据处理任务;第二,将数据处理结果发送到指定邮箱。
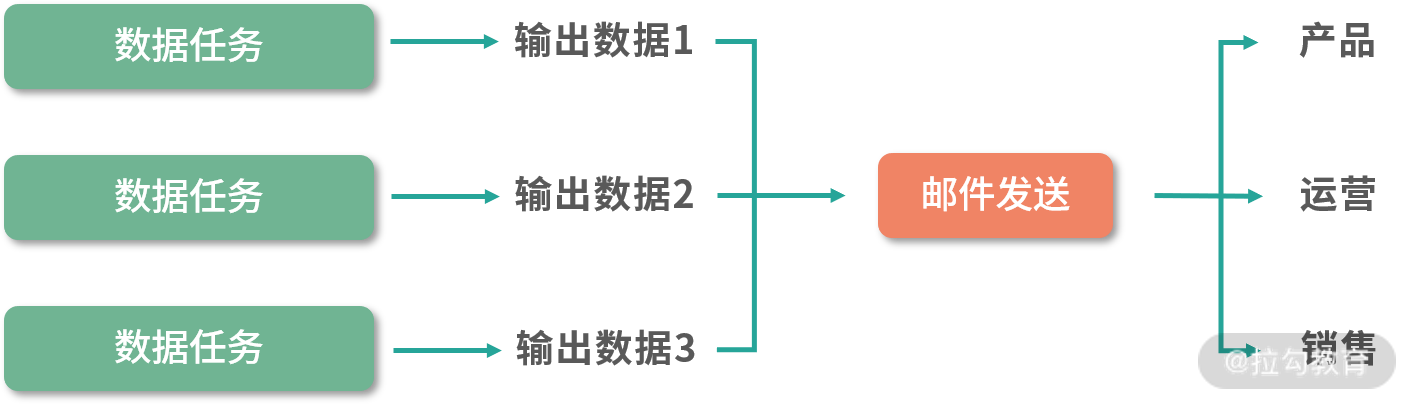
下面,我们就分开讲下这两部分内容。
定时数据处理任务
Linux 上运行定时任务的命令,我们在第一节课里有讲到,即:crontab 命令。具体使用方法可以参考这个命令。
我们简单回顾下 crontab 命令的用法:5 个星号表示设定周期执行的颗粒度,分别对应分钟、小时、天、月、周。
cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
举个例子:
# 每小时的第30分钟, 执行脚本
30 * * * * sh ~/data/your_run.sh
# 每天的凌晨3点30分, 执行脚本
30 3 * * * sh ~/data/your_run.sh
# 每个月第1天凌晨3点30分钟, 执行脚本
30 3 1 * * sh ~/data/your_run.sh
# 每周六凌晨3点第30分钟, 执行脚本
30 3 * * 5 sh ~/data/your_run.sh
定时任务简单、易用,是用机器解放人力重复劳动的典型应用。那么,现在已知,数据处理脚本及其输出的数据文件路径如下所示:
数据处理任务的 Shell 脚本,statistics_user_info.sh;
路径为:/home/data/statistics_user_info.sh。
随后我们通过 crontab 命令,设置每天凌晨3点运行上面的脚本。并将结果存放到下一级目录中: /home/data/res/out_${date}.csv 。
此后,每天生成一个带有日期的文件名:
3 * * * * sh /home/data/statistics_user_info.sh
这样,通过 crontab 命令,就可以定时处理数据任务了。将数据处理结果保存到自己使用的机器上,接下来只需要让该机器将运行的结果发送给指定邮箱就可以了。
下面,我们开始讲解如何通过脚本实现邮件发送。
邮件发送模块
实现邮件自动发送的方法有很多,不同 Linux 操作系统会有不同的邮件发送命令。
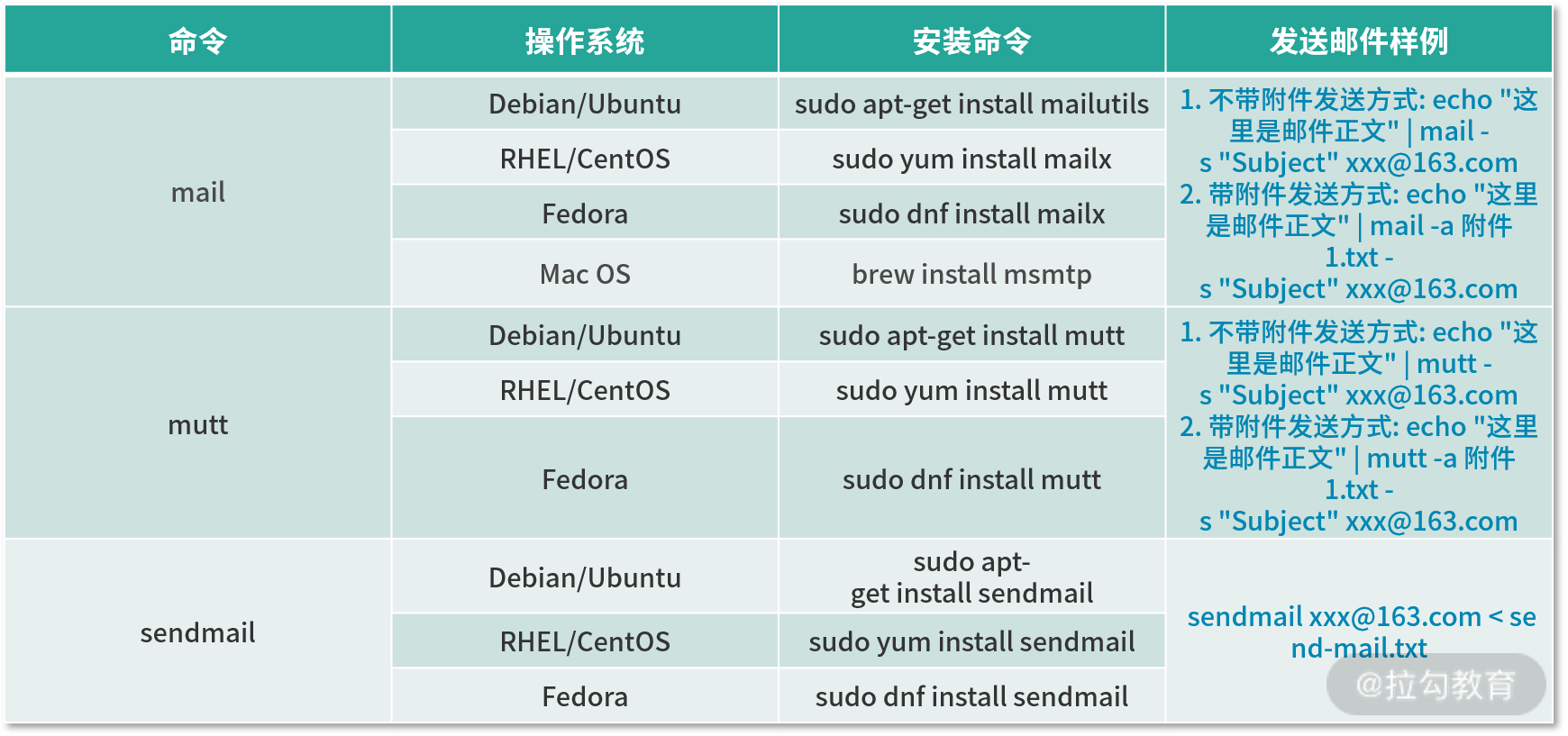
考虑到跨平台使用的因素,下面主要介绍下如何通过 Python 发送邮件。每个操作系统都可以安装 Python,使用起来非常方便。与此同时,Python 还是数据处理神器。我们可以直接用 Python 将数据处理成业务方希望看到的结果,然后使用 Python 自带的邮件模块,配置发送信息,将数据发送给指定邮箱。
Python 编写邮件发送程序
发送邮件的协议为 SMTP ,即:Simple Mail Transfer Protocol 简单邮件传输协议。该协议只能用来发送邮件,不能用来接收邮件。大部分邮件发送服务器均支持 SMTP,Python 也可以通过内置的 Smtplib 包来完成邮件发送。
下面,我们以 163 邮箱为例,使用 Python 一步步实现邮件发送功能。
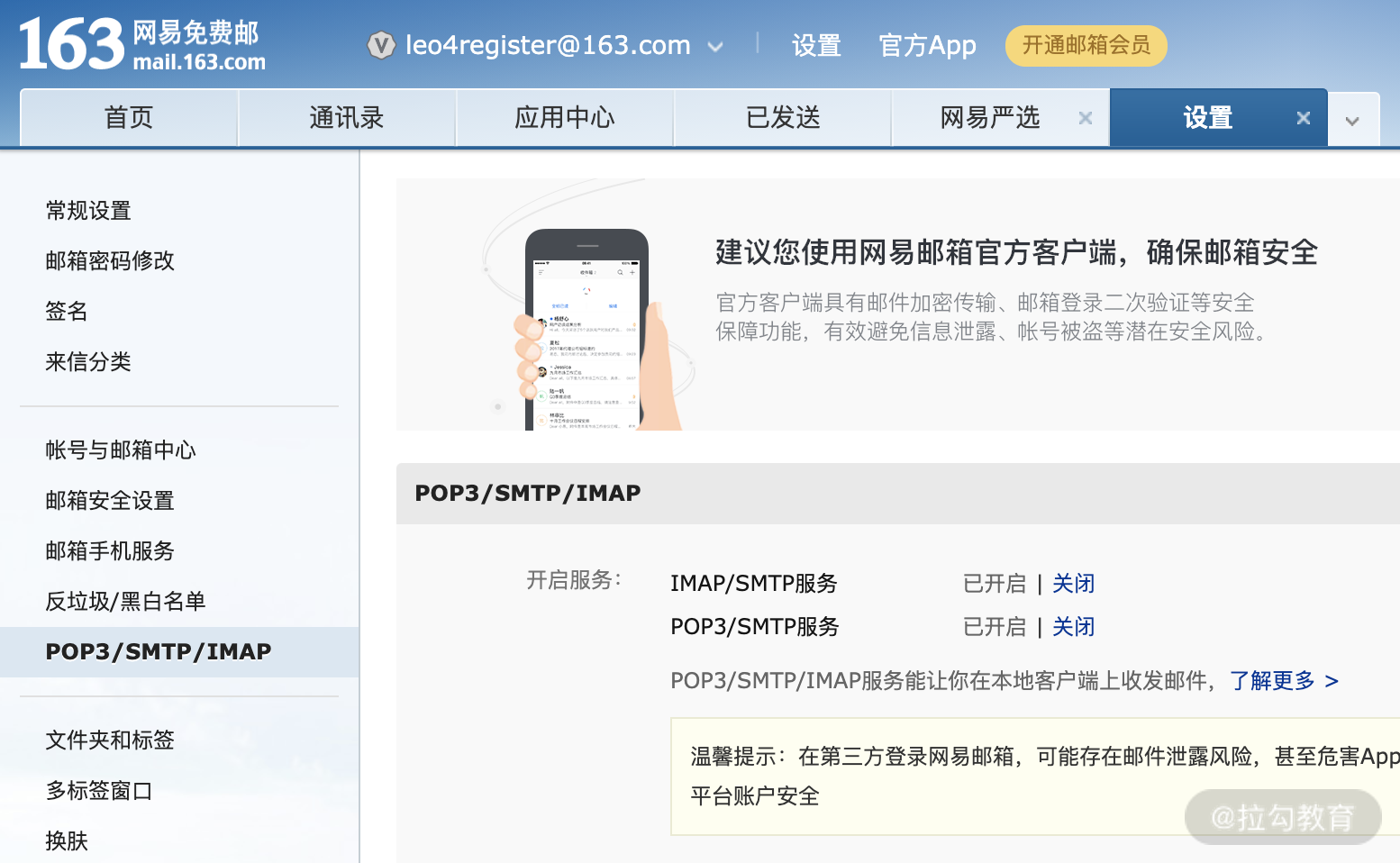
第一步:登录用来发送邮件的 163 邮箱,进入邮箱设置页面,开启 SMTP,注意在开启过程中可能会让你发送手机验证码。如下图:
第二步:编写 Python 程序如下。
# 下面编写 发送邮件正文的Python 脚本 send.py
# 两个函数, 第一个基础功能发送邮件, 只包含正文, 第二个发送带有附件的邮件, 并抄送对应邮件地址
# -*- coding: UTF-8 -*-
import smtplib
from email.header import Header
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
import datetime
import time
import codecs
# 第三方 SMTP 服务
host_smtp = “smtp.163.com” # SMTP服务器
username = “xxx@163.com” # 发信人的邮箱地址
password = “*************” # 163授权密码,非个人登录密码, 这样保护个人邮箱密码不暴露
from_mail = ‘xxx@163.com’ # 发件人的邮箱
to_mail_list = [‘xxx1@163.com’,‘xxx2@163.com’] # 接收邮件地址list
content = ‘数据邮件日报’
title = ‘产品核心指标日报’ # 邮件主题
file_name = ‘/home/data/data.csv’ # 邮件附件的文件路径
# 含正文但不含附件的邮件发送函数
def sendEmail():
message = MIMEText(content, ‘java’, ‘utf-8’) # 内容, 格式, 编码
message[‘From’] = “{}”.format(from_mail)
message[‘To’] = “,”.join(to_mail_list)
message[‘Subject’] = title
try:
smtpObj = smtplib.SMTP_SSL(host_smtp, 465) # 启用SSL发信, 端口一般是465
smtpObj.login(username, password) # 登录验证
smtpObj.sendmail(from_mail, to_mail_list, message.as_string()) # 发送
print(“邮件成功发送!”)
except smtplib.SMTPException as e:
print(e)
# 含正文同时含附件的邮件发送函数
def sendEmailWithFile():
msg = MIMEMultipart()
att = MIMEText(codecs.open(file_name, ‘rb’,‘utf-8’).read().encode(“gb2312”,‘ignore’), ‘base64’, ‘gb2312’) #增加附件,用gb2312编码,使得用Windows打开中文不乱码
att[‘content-type’] = ‘application/octet-stream’
att[‘content-disposition’] = ‘attachment;filename=“data_report.csv”’
msg.attach(att)
mail_body = MIMEText(content, ‘java’, ‘utf-8’) # 邮件正文格式设置: 内容, 格式, 编码
msg.attach(mail_body)
msg[‘From’] = “{}”.format(from_mail)
msg[‘To’] = “,”.join(to_mail_list)
msg[‘Cc’]=‘xxxx@163.com’ # 不支持多重抄送
msg[‘subject’] = title + u’日报:发送于’+str(datetime.date.today())
try:
smtpObj = smtplib.SMTP_SSL(host_smtp, 465) # 启用SSL发信, 端口一般是465
smtpObj.login(username, password) # 登录验证
smtpObj.sendmail(from_mail, to_mail_list, msg.as_string()) # 发送
print(“邮件(包含附件)已成功发送!”)
except smtplib.SMTPException as e:
print(e)
if name == ‘main’:
# 发送含正文但不含附件的邮件
sendEmail()
# 发送含正文同时含附件的邮件
sendEmailWithFile()
正常情况下, 按照上面代码运行 Python 脚本,send.py 会返回一下执行成功信息。
# 运行下面命令, 如果成功, 会返回两行信息
python send.py
邮件成功发送!
邮件(包含附件)已成功发送!
下面是我使用自己 163 邮箱发送的结果:
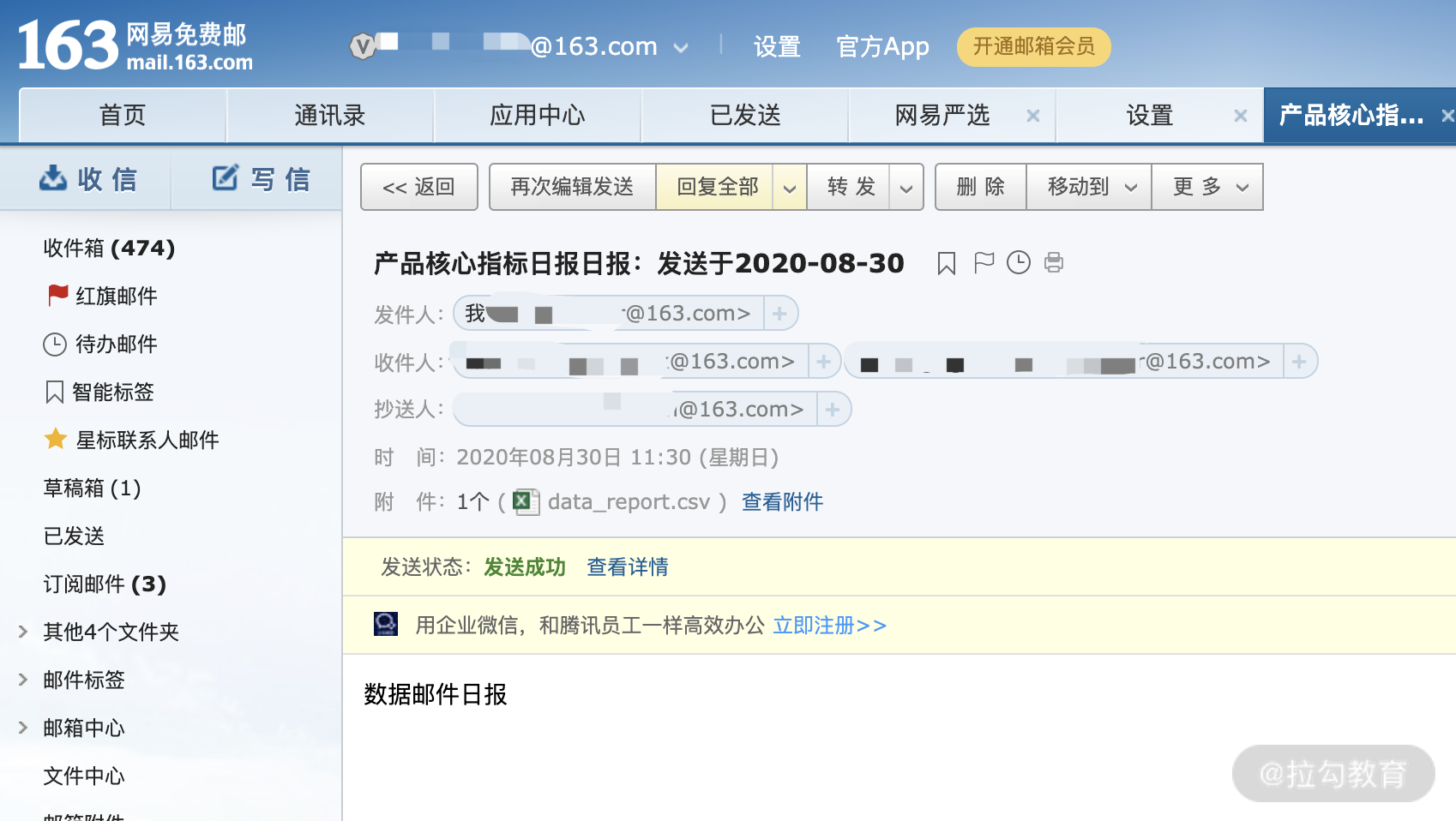
常见问题
在使用上面进行邮件发送过程中,通常可能会遇到两类问题:
第一, 权限问题,即邮箱的用户名及其密码不匹配问题;
第二,被邮件服务器反垃圾特征识别为垃圾邮件,发送失败。
下面是问题对应的错误提示及解决方案。
权限问题:错误提示1: (535, 'Error: authentication failed')。
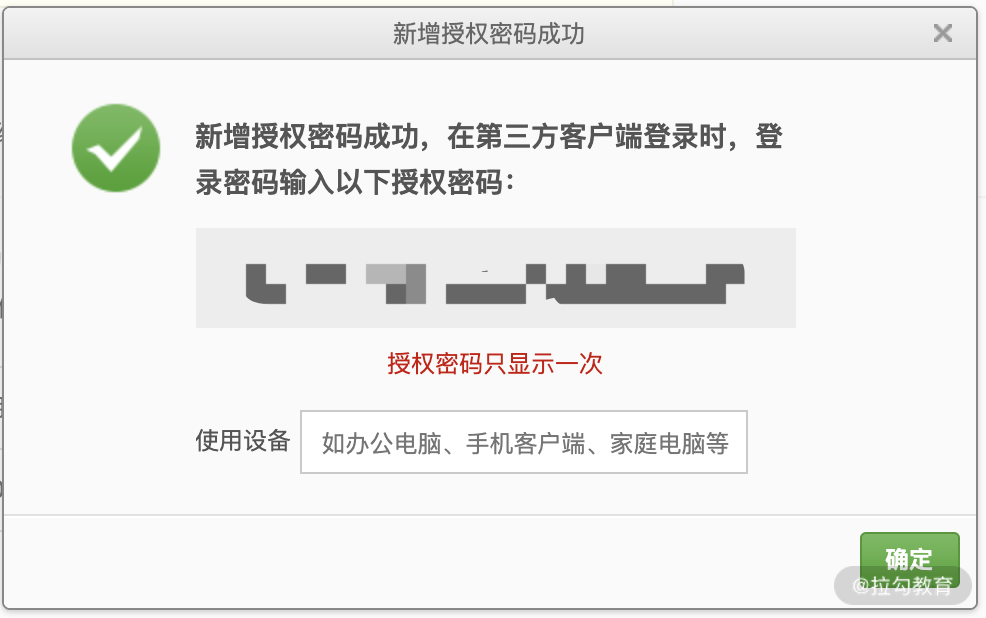
解决方法:开启邮件 SMTP 的时候,163 邮箱系统会给出一个随机密码(如下图),用该密码替换在 Python 代码里的对应账号的密码即可。
![]()

错误提示2: 554, DT:SPM 163 smtp1,GdxpCgCnr2ftu0dfOAc+Ag--.63S2。
原因:550 DT:SPM 邮件正文被识别为垃圾邮件。
处理这种情况的方法是:换其他邮箱发送,或调整邮件内容。
上面经哥给你介绍的是最基础邮件日报工具的搭建。简单来说,第一步,将数据处理任务模板化,然后设置定时任务,每天固定时间运行,并将数据结果保持到某路径下。第二步,使用 Python 编写的邮件发送工具,将生成的文件,发送到指定邮箱地址。
邮件日报升级
一般来讲,如果只是临时几个日报,用这种办法解决是没有问题的。你可以直接拷贝我上面代码, 修改下用户名和密码,以及自己本地发送文件路径就可以正常使用。
但问题是,如果整个公司各个业务线都需要日报,这时候以上所说的工具虽然也可以使用,但维护成本就会比较大,增加一个收件人得需要找到对应的 Python 脚本来修改。这时候,将之前的工具改成一个带有信息管理界面的邮件发送系统,维护起来会更容易一些。它开发量也不大。只需要把收件人、发送文件路径抽象出来,放到 Web 界面上即可。如果再升级,还可以增加不同的日报任务管理,如数据任务调度、数据依赖、数据重跑、数据回刷等。如此完善后的工具,就是大部分大厂公司都会拥有的大数据计算平台系统。
当然,大数据任务调度系统还是需要一定开发和维护的工作量,它的使用对象可能是整个公司的研发、数据、产品、运营等,作为公司级别的数据生产工具,考虑的问题就会很多。大数据任务调度系统包括以下。
基础功能:包括任务调度周期设置、数据源依赖设置、任务依赖、数据回刷、数据结果输出方式等。
权限管理:整个公司的数据都在上面,不同部门不同业务线表权限需要严格管理。
计算资源分配按部门分别集群资源,相同部门再拆分不同小组。
平台可用性发现问题必须立刻修复,不然会影响整个公司数据及其业务。
上面从数据日报的邮箱定时发送的小工具,最后延伸到大厂内部的大数据任务调度系统,其实核心点都是为了让数据运转得更高效,让更多人更方便地获得数据价值。
总结
本课时主要介绍了如何使用 Linux 处理定时数据任务,以及如何使用 Python 进行邮件发送,解决日常数据处理过程中常见的数据日报、周报、月报的刚需,是一种典型的通过机器来释放人力的一种解决方案。尤其是数据人员在公司的数量远远小于产品和运营同学的数量,在有限的人力条件下,很容易被业务方的数据需求将自己的工作时间吃满,将重复的业务需求抽象化,并予以工具上的支持,可以在有限的人力下,一定程度上来满足各个业务方各种数据上的迫切需求。
非常感谢你能学习到这里,希望本课时能一定程度上解放你工作中遇到的各种报表的日常任务。
06 BI 平台:如何进行报表可视化开发
今天给你分享的内容是如何科学地搭建可视化数据报表。希望通过这一课时的学习,让你了解到以下两点:
如何科学地搭建可视化数据报表;
BI 平台生产报表中遇到的主要问题及解决方案。
我们先看下 BI 的百科定义:
Business Intelligence(BI),又称商业智慧或商务智能。通常指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术等进行数据分析以实现商业价值。
BI 作为一个工具,是用来处理企业中现有数据,并将其转换成知识、分析和结论的。在此基础上,它辅助业务或者决策者作出正确且明智的决定,包含了从数据仓库到分析型系统。
以上定义很好地概况了 BI 的功能和价值。互联网公司一般提到 BI 平台,业务方最直接的反应是数据报表。虽然这个比较片面,但也能理解。因为业务方只接触到报表这一层,而不关心生成报表的过程。下面,一起看下数据报表是如何生产的。
如何搭建可视化报表
报表是企业核心业务的数据指标化体现,是帮助业务制定决策最具体、最有效的工具。报表的使用方包括数据分析师、产品经理、运营同学、市场人员、销售及公司高层等。其中,数据分析师既是报表的深度参与订制人员,又是报表的深度使用者。
指标体系搭建
首先,数据报表依赖指标体系地搭建。报表通过将相互联系的指标组织到一起,使我们可以通过一定数据分析方法,很快发现业务当前可能存在的问题。搭建指标体系主要关注以下方面。
明确解决的问题。
异常波动归因。比如:收入下降原因定位。遇到这个问题,首先通过已有报表拆解数据指标下降原因。从新老用户、不同场景、不同行业或产品线等要素出发,进行拆解归因。
数据策略监控。比如:在促进新用户留存策略上线前和上线后,对比、统计新用户留存变化及不同场景新留存变化等要素。
基础指标定义。
如:低活跃用户、高活用户应当如何定义?流失用户又应当如何定义?
这需要我们明确统计口径表达业务含义以及其合理性。比如,将 30 天内活跃 5 天的用户定义为低活用户。这样划分的原因是否合理?如果产品本身是一个低频使用的工具性产品,那么以 5 天来定义未必合理。这需要我们根据业务实际情况来具体确定。
数据维度划分。
用户画像的标签,比如年龄、性别、收入等级。
产品分类,即不同产品线的分类,还包括不同产品线的不同渠道入口的订单数据。
数据体系的目的是监控具体场景下用户的需求是否得到满足,以及被满足的原因可能来自哪些渠道或者运营策略。产品、运营等业务方同学,每天依赖报表来总结之前工作,并开启下一步工作。
数据报表生产
简单的数据报表可能一小时就能完成,复杂的数据报表可能需要一个数仓团队搭配数据分析师耗时几周时间才能完成。报表的生产非常依赖 BI 数据平台建设,而你需要了解数据从底层日志一步步完成清洗、加工,最后到报表呈现的整个过程。
BI 平台 = 数据仓库+报表/OLAP 服务。 因此数据报表的顺利生产,从根本上还是数据仓库建设和业务指标的构建。
首先,数据仓库建设。数据仓库建设中最重要的一个环节是数据分层。将数据从底层到最终报表呈现的过程,划分成不同的数据层。从而,让不同数据层中每一层都有自己的作用域,方便使用和数据定位。在我们有了完备的数据仓库后,业务方的需求就会变得简单很多。大部分新的指标,都可以从中间层的数据表中寻求数据简单加工来满足。
最后,实现数据的可视化,主要是前端可视化,这会有很多成熟的开源或付费方案供我们选择。
下面以搭建短视频 BI 平台为例,来了解数据报表生产的过程,报表包括核心用户指标,如日活、留存、观看时长、互动行为。
我们来看一下有关数据分层设计。
ODS 层,主要是各业务线的日志收集。它包括不同端的用户互动行为日志(App、小程序等)。
DWD 层,针对 ODS 清洗和主题汇总。它过滤异常数据,保留数据明细,清洗一个用户一天维度的明细表。将用户发送短视频、对短视频转评赞、观看时长、关注行为等数据加工到一张表内。
DWS 层,将用户在 App 内所有行为汇聚到一张表中。比如,点赞数、评论数、短视频数等。
应用层,将 DWS 层数据表,再汇聚进入最终的业务指标表中。比如,每日平台点赞总量、评论总量等,之后经过简单 SQL 查询,返回数据到报表呈现。
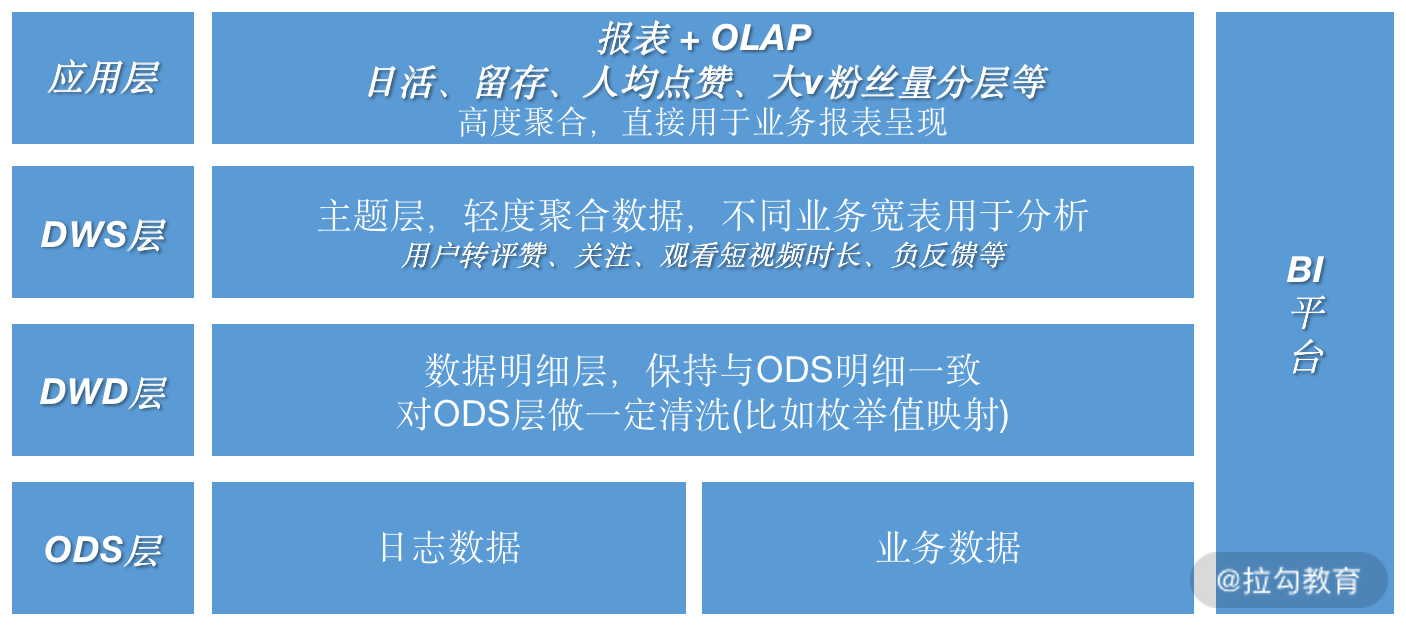
如上图,ODS、DWD 数据量比较大,一般存放到 HDFS 中;应用层数据量相对较少,可以放到 MySQL 中;而 DWS 根据实际情况,如果每天量级有百万级,建议保存到 HDFS 中。
通过以上信息我们可以看出,BI 平台搭建看似比较简单,但实际从底层日志到报表生产的实现过程中,会遇到很多问题。只有合理的解决这些问题,BI 平台才能发挥数据决策的作用。
下面,我们重点介绍下,建设 BI 平台过程中遇到的问题。
报表生产的主要问题
近几年在不同的公司工作,发现遇到 BI 平台的问题是类似的。问题主要分两类,一类是工程上的问题,一类是指标上的问题。下面我们展开讲下这两类问题:
数据工程问题
工程上主要问题分四大类,即:数据准确性问题、数据分层问题、数据及时生产问题、错误数据的修复问题。这四项看似都是十分基础的工作,但能做好却非常不容易。
数据准确问题。
数据准确统计并呈现,看似理所当然,但实际有很多场景会影响到数据准确性。简单举例, 数据采集缺失引起数据量比实际少,数据重复上报引起数据量比实际多......这些问题都是数据准确问题引发的。
数据分层问题。
数据分层是组建数据仓库的重要环节。如果设计不好,数据挖掘成本会严重增加。可能表现在以下两点。
数据重复开发。一旦数据重复开发,一些简单指标都要从底层开始重复计算。数据量大、每次关联表多、计算复杂,最终影响报表生产。
一张宽表数据源非常多。如果依赖上游数据源改变,不能快速定位影响下游数据表的范围,修复成本会很大。
数据延迟。
现在互联网公司数据量越来越大,业务越来越复杂,造成数据延迟的原因也变得更多了。主要原因有以下四点。
原始日志上报生成时间的延迟,造成后续所有数据任务向后延迟。
大宽表依赖数据表多,依赖数据生产链路长。有时会因为其依赖的某一张表没有及时生产,造成最终数据延迟。
因为数据量大、数据倾斜等原因,增加数据任务时长。这时需要优化计算任务或者更换新的计算引擎。
集群计算资源临时不足,造成数据生产大面积 delay。
数据回刷。
数据报表的生产会由于各种原因,需要回刷数据。比如以下两种情况:
修改或新增指标计算口径,需要回刷到某个日期开始至今的数据;
某数据源超过 24 小时没有生产,造成下游所依赖的数据源都没有生产。
以上描述的是数据工程主要遇到的几类问题,它们直接影响报表生成准确性和效率。
数据准确性,要依赖数据上的基础测试和监控报警,对应日志上突然的降低或者增高。针对不同情况,及时发送报警邮件或短信。
针对数据延迟,可以采用优化计算任务方式。 或者底层用 Spark 任务代替 Hive 任务。如果是计算资源严重不足,则需要通过扩展集群机器来解决。
上面这些工程问题的解决,主要依赖于公司数据仓库部门同学们的努力。而有些问题,可能要协同其他部门业务同学一起才能彻底解决。
数据指标问题
数据指标作为 BI 平台最基础的组成部分,是业务方和数据分析师接触最多的点。很多指标也是业务方、数据分析、数据仓库一同完成的。
也正是因为参与方比较多,如果没有系统的数据建设体系,数据指标及报表开发过程中会出现很多的问题。下面我选了几个很多企业都会遇到的数据指标问题为你讲解:
指标脱离业务,华而不实。
出现这种情况,大概率是负责人在对业务不熟悉的情况下,按照自己“认为”的方向开发数据指标,或者直接抄第三方平台上的指标(如友盟、神策等)。举个例子,有些第三方平台工具会灌入一些简单的测试样例,把用户浏览路径做得很酷炫。可真正使用的时候,能用到的并不多。这时候,如果 BI 平台负责人自己认为这个是一个标配功能,一定要上线。结果是业务方对该功能使用次数极少,反而是漏斗转化等基础数据使用的比较多。这是因为,用户浏览路径已经被很多代产品经理优化过了,目前相对稳定。业务方也经过多次新路径引导尝试,发现效果提升非常微小。事实上,业务方当前更希望通过挖掘新的数据策略来提升平台业务。比如:针对不同用户展现不同品类商品来提升 CTR(点击率)和 CVR(转化率)。因此比之华而不实的用户浏览路径,我们不如多花精力在实际使用较多的 CTR 和 CVR 这里。
相同指标,口径各异。
指标名称一样,口径不同,会增大报表使用成本。
实例 1:新用户定义。 报表 A 显示当天注册的用户为新用户,报表 B 显示 7 天内注册的用户为新用户。
实例 2:视频互动量定义。 视频互动行为有很多种,对于视频自动播放是否统计为互动行为,不同业务要求不同。可能业务 A 要求对于视频自动播放超过 5 秒,则计入互动,而业务 B 则对于自动播放均不统计为互动。
以上两个例子,会让不同业务方在使用 BI 报表进行工作汇报时,产生很大的数据分歧。如果双方都说数据来自 BI 平台报表,那我们无疑会增加解释成本。
报表繁多维护难。
数仓或者数分同学,经常会接到业务方的临时报表需求,比如:
A 同学只关心某行业的收入情况,想了解该行业的新老用户订单数据报表。
B 同学只关心某垂直频道用户核心行为指标,同时要求添加周环比功能。
C 同学每周工作周报数据,不想每次花时间统计,要求单独开发一个报表满足周报模板。
D 同学......
E 同学......
随着业务同学思维地发散,报表也变得越来越臃肿。这就导致如果报表容易出现问题,需要占用不少人力成本来跟进维护。
所以,数据指标作为业务中最直接接触的环节。一定要将有限的人力投入到贴近业务生产数据的指标上。不要花哨只求实用。基础数据指标要跟业务方一同做好统一规划,尽量减少相同指标不同口径的发生。
最后,对于频繁的临时报表需求。最好可以提供常用宽表,提供 OLAP 服务。这样就通过可视化拖曳的方式,让业务方通过使用 OLAP 工具,从而满足灵活的数据报表的需求。
总结
对于现在的企业,用数据洞察监控核心业务的报表越来越重要。数据分析师作为离业务最近的数据人员,既是数据报表的使用者,也在数据报表生产中发挥着非常重要的作用。
本课程简单介绍了 BI 平台上的数据报表生产过程,以及如何处理生产报表过程中遇到的问题,非常感谢你的学习,有问题可以随时留言问我,下课时我们再见。
07 实战演练:一小时搭建可视化 BI 数据平台
你好,我是取经儿。上节课主要向你简单介绍了 BI 平台。这节经哥来一篇实战课程,手把手教你如何快速搭建可视化 BI 平台。本节课我会分三部分来描述平台搭建过程:
BI 平台的主要组成部分;
开源 BI 平台 Superset 本机搭建;
导入的练习数据库:Employees。
希望在学习完这一课时后,你可以学会自己一步一步搭建一个 BI 平台。
下面进入第一部分的介绍。
BI 平台主要组成部分
上节课我们讲到过,BI 平台将企业数据加工后转化为业务指标,从而辅助企业决策。可以简单理解为BI = 数据仓库 + 报表。概括起来就是将用户数据采集并放入数据仓库后,经过层层加工清洗放到报表中呈现。其中,数据仓库会涉及数据分层,包括 ODS 原始数据层,DWD 数据明细层和 DWS 数据汇聚层。最后形成的业务指标,一般会放到 MySQL 等关系数据库中,然后再从关系数据库中提取数据到前端进行报表呈现。下面这张图,表现的就是数据由日志流向 HDFS 再流至 MySQL 数据库,直至 Web 端的呈现过程。

报表的呈现形式可以是表格也可以是图形,包括折线图、柱状图、饼图等。所以,BI 平台需要拥有一个可操作的可视化界面(一般是 Web 网站)。我们可以从 MySQL 数据库中提取已经统计好的业务指标数据。此外 BI 平台还需要具备基础的用户权限管理功能,该功能的目的是给不同的业务人员分配不同的报表可读权限。一般业务人员只能看到操作化界面,不需要看到数据仓库里加工数据的流程。以上,你可以看到 BI 平台主要元素是用于存放指标数据的数据库,以及用于呈现数据的前端可视化界面。
下面,我们进入第二部分,开源 BI 平台 Superset 的本机搭建。
开源 BI 平台 Superset 搭建
Superset 是 Airbnb 开源的轻量级 BI 平台工具。它有着以下优势和特点:
第一,功能强大:
可以支持接入多种数据库,包括 MySQL、Druid、Hive 等;
报表权限功能配置简单,可以设置用户、角色,一个用户可以有多个角色权限;
报表制作简单,可以通过编写 SQL 生成报表。
第二,部署简单。操作时,在安装完配套的数据库环境后,剩下的基本上使用一键部署即可。
下面我们正式开始实战操作。这里经哥主要介绍 MacOS 和 Linux 环境下的 Superset 安装步骤。
我们先简单了解一下主要的步骤:
安装 Python 3.7;
安装 Virtualenv;
创建 Python 虚拟环境;
安装 MySQL;
安装 Superset 并设置对应数据库和用户密码。
其中,前四步为安装 Superset 的环境,即安装 Superset 依赖的 Python 环境和数据库 MySQL。第五步才开始真正安装 Superset。经过以上五步操作,Superset 部署完成,就可以启动使用了。
下面展开细讲每个步骤的具体执行过程。
安装 Python 3.7
现在新版 Superset 是依赖 Python 3 运行的。所以我们需要先安装 Python 3 以上的版本。你可以参考下面命令进行安装:
1.Linux 系统安装 Python 3.7。
# 如果 Linux 系统是 CentOS,那么运行下面命令,先安装依赖包
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make
# 下载 Python 3.7.4 版本
wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz
# 解压
tar -xvf Python-3.7.4.tgz
# 安装
cd Python-3.7.4
./configure
make&&make install
# 关于报错和解决
执行完make&&make install之后,可能会出现这种报错:
“ModuleNotFound:No module named ‘_ctypes’”
解决:
1. yum install libffi-devel -y
2. make&&make install
2.MacOS 系统安装 Python 3.7。
MacOS 预安装了 Python 2.7。我们可以从 Python 网站安装最新版本的 Python 3.7。
找到页面下载对应版本的 Python 3.7。我们按照安装其他 MacOS App 的方法,一步一步按提示完成安装。
安装完成后,再使用 Vim 编辑文件 .bash_profile,新增下面代码。这一步的目的是将 Python 3.7 加入系统环境变量中。之后在命令行只需要输入 Python 3 即可快速启动。
# Setting PATH for Python 3.7
PATH="/Library/Frameworks/Python.framework/Versions/3.7/bin:${PATH}"
export PATH
安装 Virtualenv
安装命令,可以使用以下代码:
pip3 install virtualenv
随后创建 Python 虚拟环境。
# 创建独立 Python 运行环境
mkdir mypy
cd mypy
# 参数--no-site-packages,已经安装到系统 Python 环境中第三方包不会复制过来
virtualenv --no-site-packages venv3
# 打印信息如下,说明创建独立 Python 环境成功
Using base prefix '/usr'
New python executable in /root/data/mypy/venv3/bin/python3
Also creating executable in /root/data/mypy/venv3/bin/python
Please make sure you remove any previous custom paths from your /root/.pydistutils.cfg file.
Installing setuptools, pip, wheel...
done.
# 新建 Python 环境被放到 venv3 目录,用 source 进入该环境:
source venv3/bin/activate
# 可以设置快捷键,即:
echo "alias venv3='source /root/data/mypy/venv3/bin/activate'" >> ~/.bashrc/
source ~/.bashrc
之后直接输入 venv3,即可进入虚拟 Python 环境中。接下来我们把 Superset 安装到这个虚拟环境中。
CentOS 安装 MySQL。
安装可以尝试使用两种方法:
第一种, CentOS 直接安装 MySQL。但 MySQL 官网源下载特别慢,建议放弃。
第二种,修改安装源为腾讯云软件源。再进行安装,这时速度可以迅速提升。
腾讯云软件源加速软件包下载和更新。
腾讯云软件源网站。
修改腾讯云软件源并安装的步骤如下:
# 安装 MySQL 步骤:
# 修改腾讯云软件源,执行创建文件 /etc/yum.repos.d/mysql-community.repo ,并写入如下内容:
[mysql]
name = MySQL
baseurl = http://mirrors.cloud.tencent.com/mysql/yum/mysql57-community-el7
gpgcheck=0
enabled=1
# 然后执行:
yum clean all
# 再执行:
yum install mysql-client mysql-server
# 最后安装完后,设置开机启动
systemctl start mysqld
systemctl enable mysqld
systemctl daemon-reload
安装完后,需要修改初始密码,然后添加用户。
修改 root本地登录密码+添加用户
# 1. 查看初始密码
grep 'temporary password' /var/log/mysqld.log
# 2. 连接 MySQL, 输入下面代码, 回车后输入上面密码
mysql -uroot -p
# 3. 修改密码, 密码为: MyPwdForTest!!
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '上面的密码';
安装 Superset
第一步,进入 Python 虚拟环境,即进入上面新建的 Python 虚拟环境 venv3。进入方式,直接输入 venv3 回车即可。
[root@centos ~]# venv3
(venv3) [root@centos ~]# which python
/root/data/mypy/venv3/bin/python
(venv3) [root@centos ~]# python
Python 3.7.4 (default, Nov 16 2019, 19:42:25)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
第二步,使用 pip 安装 Superset。安装源使用阿里镜像速度会快很多。
pip install apache-superset -i https://mirrors.aliyun.com/pypi/simple
第三步,我们用 MySQL 管理 Superset 源数据。这时候,需要创建一个数据库,随后新建MySQL 用户并赋予其对该数据库增删改查的权限。
# 新建数据库名称为 Superset,并赋予用户 testuser 增删改查权限
create database superset
create user 'testuser'@'%' identified by 'Byourpwdtest!';
grant all privileges on superset.* to 'testuser'@'%' ;
flush privileges;
第四步,修改配置。
# 打开已安装的 Superset 配置文件
vim /root/data/mypy/venv3/lib/python3.7/site-packages/superset/config.py
注释掉默认的下面行:
SQLALCHEMY_DATABASE_URI = "sqlite:///" + os.path.join(DATA_DIR, "superset.db")
然后新增下面行。
SQLALCHEMY_DATABASE_URI = 'mysql://testuser:Byourpwdtest!@localhost/superset?charset=utf8'
第五步,创建一个管理员用户,并建⽴管理员账号和密码。
# 输入下面代码
export FLASK_APP=superset
flask fab create-admin
# 返回结果,按提示输入用户名和密码
Username [admin]: qujinger
User first name [admin]: qu
User last name [user]: jinger
Email [admin@fab.org]: haha@163.com
Password:
Repeat for confirmation:
logging was configured successfully
第六步,初始化数据库。
superset db upgrade
superset init
第七步,启动服务。
superset run
导入练习数据库
很多刷题网站或者 SQL 教程,使用的数据库都是 employees.db。下面我们从官网下载并导入该数据库到 MySQL。然后使用 Superset 链接上该数据库并使其可视化。
第一步,下载:employees.db。可以选择 employees-db-full-1.0.6 下载,解压需要包含 SQL 文件和 Dump文件。
第二步,登录 MySQL。
mysql -uroot -p
第三步,登录成功后,输入 source employees.sql 并回车。
注意:这里 employees.sql 必须为绝对路径。可以先 cd 到解压后的 employee 文件下,再登 MySQL 进行处理。
mysql> source employees.sql
第四步,新建 MySQL 用户。并授予新用户对该数据库查询权限。
create user 'testuser2'@'%' identified by 'Cyourpwdtest!';
grant select privileges on employees.* to 'testuser2'@'%' ;
flush privileges;
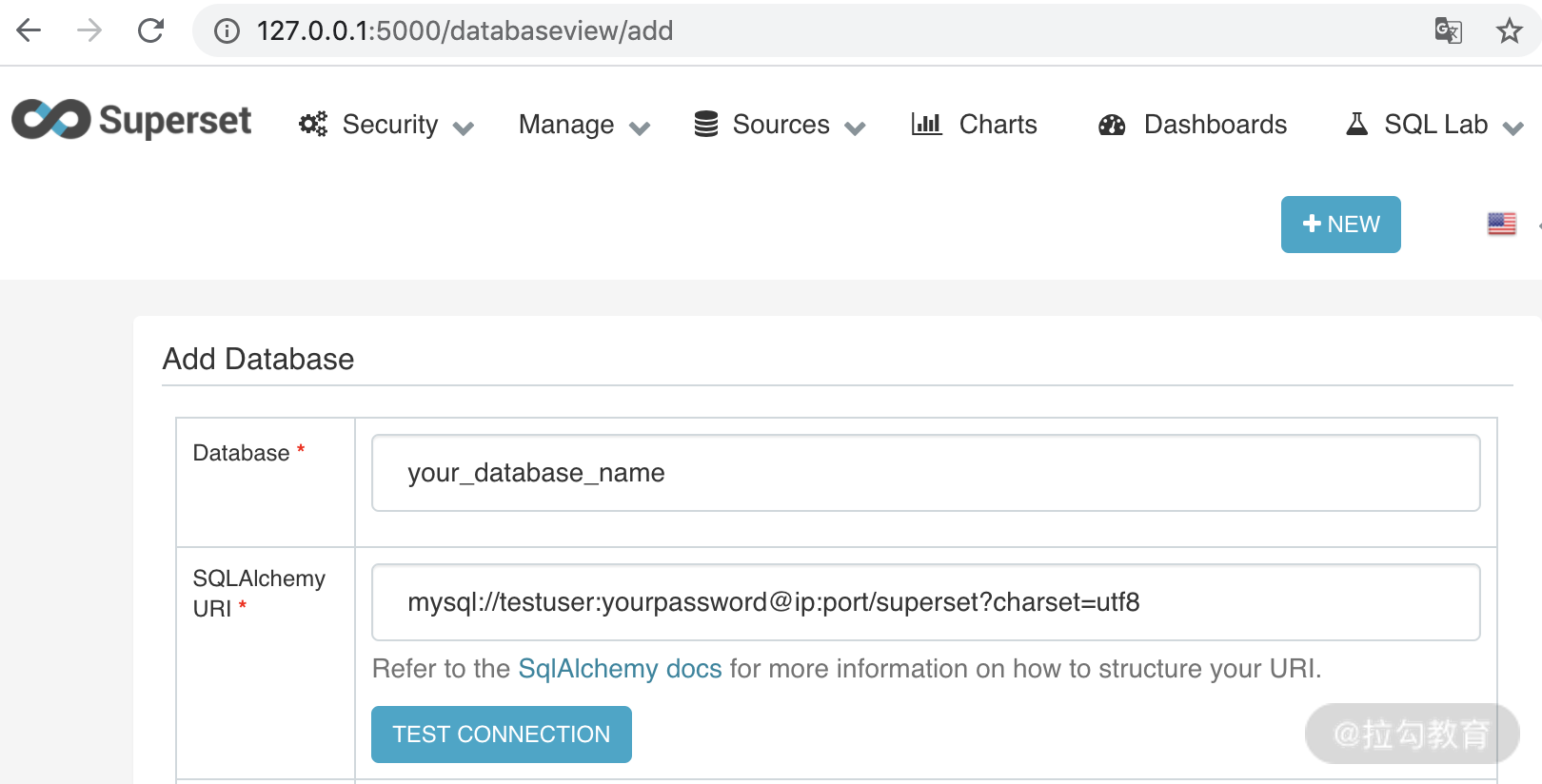
第五步,在 Superset 中配置该数据库源。截图如下:
第六步,在 Superset 中的 SQL Lab 访问该数据库。
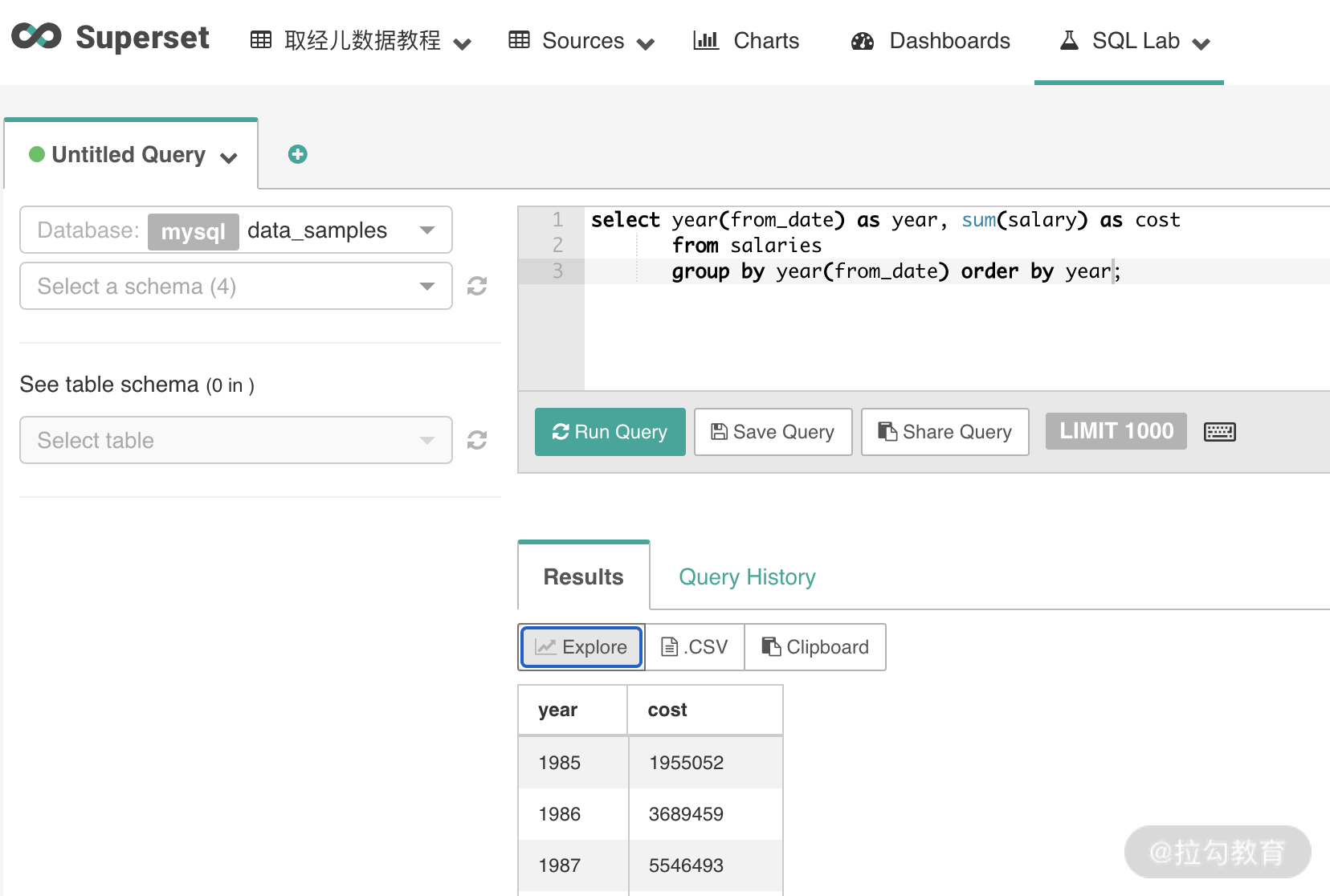
第七步,通过编写 SQL 查询数据库 employees 数据,并可视化展示。比如我们这里展示不同初始年份的员工数分布,SQL 脚本如下:
select year(from_date) as year, sum(salary) as cost
from salaries
group by year(from_date) order by year;
第八步,将上面查询结果制作可视化报表。点击 Explore,选择柱状图,保存并新建报表名。最后结果如下图:
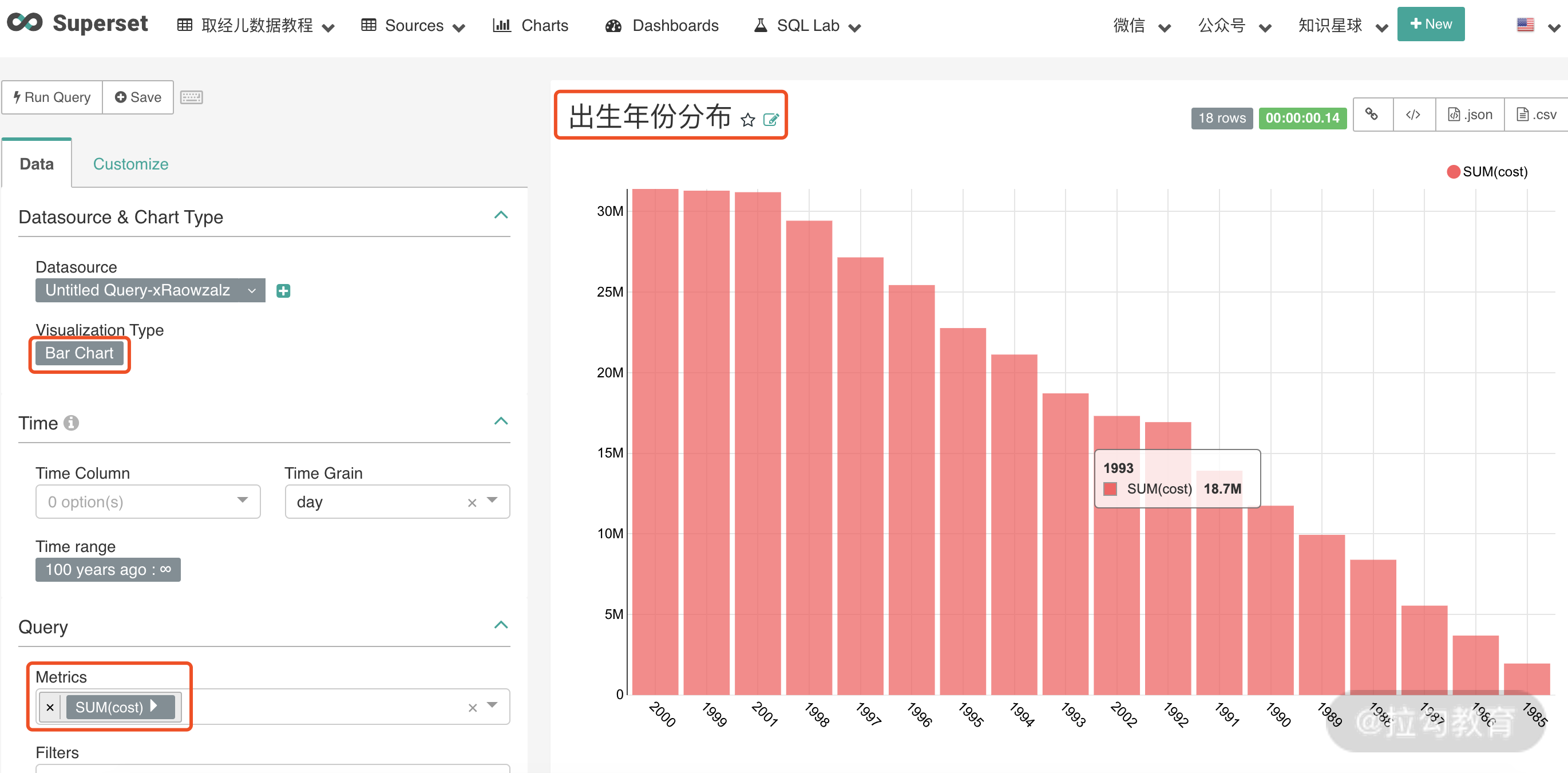
现在 BI 平台已经搭建完毕,数据库也已经连接上了。你只需要在 SQL Lab 中进行查询并完成报表构建即可。之后你可以将精力主要集中在对于业务的理解和分析上,并生成对业务有指导价值的数据报表,来赋能业务增长。
总结
通过这次课程,我们主要学习了如何在本地快速搭建 BI 平台,并接入练习数据库辅助进行搭建学习。希望你能动手实践下,在自己电脑搭建 BI 平台。既为自己创造了一个数据学习平台,同时也能深入了解 BI 平台的主要构成和运行原理。
非常感谢你的学习,有关 BI 平台搭建的问题,可以在留言区留言。也欢迎关注经哥的公众号:数据民工来取经儿提问留言。让我们共同学习,共同进步。
数据分析从零到精通第三课 python自动化和BI数据可视化实战相关推荐
- tableau三轴合并_《Tableau数据可视化实战》——1.12节合并不同数据源-阿里云开发者社区...
本节书摘来自华章社区<Tableau数据可视化实战>一书中的第1章,第1.12节合并不同数据源,作者(美)Ashutosh Nandeshwar,更多章节内容可以访问云栖社区"华 ...
- 数据分析从零到精通第七课 快速面试与入职
22 提高效率:数据分析师知识构成及管理 这一节为你分享一些数据分析师良好的工作习惯,希望能帮助你在工作中提高工作效率.请跟我认真学习下面 6 个数据分析师应该养成的工作习惯. 1. 整理通用和常用代 ...
- 数据分析从零到精通第四课 在产品需求、开发、运营和迭代中进行数据分析
08 数据平台:本机部署大数据平台工具及使用 你好,我是取经儿.上一课时我带你学习了快速搭建 BI 平台来构建报表.本课时我将手把手教你在本地电脑安装离线大数据处理工具 Hive.Hive 也是数据分 ...
- 数据分析从零到精通第六课 流量转换、效率宣传牌和量化模型
19 商业变现:流量的商业闭环分析 你好,我是取经儿.今天给大家分享流量的商业变现,希望通过这篇课程让大家提升对流量的认知. 我们分三部分来认识流量的商业价值. 什么是流量? 流量的变现方式有哪些? ...
- Excel数据分析从入门到精通(三)函数进阶-52个Excel函数之清洗类函数
Excel数据分析从入门到精通(三)函数进阶-52个Excel函数 1.清洗类函数-left 函数含义 函数使用 2.清洗类函数-right 函数含义 函数使用 3.清洗类函数-MID 函数含义 函数 ...
- 免疫组库数据分析(三):免疫组库数据可视化
免疫组库数据分析(三):免疫组库数据可视化 前言 在系列文章第二篇<免疫组库数据分析(二):Excel 分析免疫组库数据>中,分析了免疫组库中V基因.J基因.V-J组合的使用频率.在氨基酸 ...
- QCA三天写论文!模糊集数据校准实战
QCA三天写论文!模糊集数据校准实战
- 《Microsoft Power BI数据可视化与数据分析》之超市运营数据分析
14.3.1 各省份销售额柱形图 在"字段"窗格中,将"销售额"字段拖到画布上的空白区域,然后将"省/自治区"字段拖动到"可视化 ...
- python与excel做数据可视化-python做可视化数据分析,究竟怎么样?
Python做可视化数据分析也是可以的,只是对比起来专业的可视化工具有些得不应手,做出来的图可能不太美观.Python用来处理数据,用来分析绝对可以.我觉得想要可视化可以使用专门的可视化工具. 不过, ...
最新文章
- mui 根据 json 数据动态创建列表
- mysql多大_mysql的innodb表到底占用多大的空间?
- 原创:纯手工打造CSS像素画--笨笨熊系列图标
- bzoj 1026: [SCOI2009]windy数 数位DP算法笔记
- wp_terms分类信息表—WordPress数据库研究(2.6.2版本)#8
- 7-4 求链式线性表的倒数第K项(最佳解法)(List容器)
- python连接数据库并编写调用函数_Python使用pyodbc访问数据库操作方法详解
- TypeError: cannot convert the series to <class ‘float‘>问题解决
- 华为周跃峰:揭秘“关于GaussDB数据库的五大谎言”
- 进程已结束,退出代码-1073740791 (0xC0000409)
- 再见python你好go语言_再见,Python!你好,Go语言
- android中的所有activity间动画跳转
- 在线预览doc,docx文档
- Win2008 r2 远程桌面授权已过期的解决办法
- c语言编写生日蛋糕图案大全图片,漂亮的多层蛋糕图案大全:多层生日蛋糕图片大全...
- PROTECT MODEL的创建过程
- 游戏服务器 linux windows,游戏服务器用windows还是linux的系统好?
- 工程职业伦理_Mooc_2019_期末考试参考答案
- 倩女幽魂显示连接不上服务器,倩女幽魂手游闪退进不去 倩女幽魂手游连不上解决方法...
- 假设有一个双字X=12345678H,编程完成将此双字逻辑左移4位,并将移位后的双字存到双字变量Y中。