spark笔记spark优化
基本概念(Basic Concepts)
RDD - resillient distributed dataset 弹性分布式数据集
Operation - 作用于RDD的各种操作分为transformation和action
Job - 作业,一个JOB包含多个RDD及作用于相应RDD上的各种operation
Stage - 一个作业分为多个阶段
Partition - 数据分区, 一个RDD中的数据可以分成多个不同的区
DAG - Directed Acycle graph, 有向无环图,反应RDD之间的依赖关系
Narrow dependency - 窄依赖,子RDD依赖于父RDD中固定的data partition
Wide Dependency - 宽依赖,子RDD对父RDD中的所有data partition都有依赖
Caching Managenment -- 缓存管理,对RDD的中间计算结果进行缓存管理以加快整体的处理速度
编程模型(Programming Model)
RDD是只读的数据分区集合,注意是数据集。
作用于RDD上的Operation分为transformantion和action。 经Transformation处理之后,数据集中的内容会发生更改,由数据集A转换成为数据集B;而经Action处理之后,数据集中的内容会被归约为一个具体的数值。
只有当RDD上有action时,该RDD及其父RDD上的所有operation才会被提交到cluster中真正的被执行。
从代码到动态运行,涉及到的组件如下图所示。
演示代码
val sc = new SparkContext("Spark://...", "MyJob", home, jars)
val file = sc.textFile("hdfs://...")
val errors = file.filter(_.contains("ERROR"))
errors.cache()
errors.count()
运行态(Runtime view)
不管什么样的静态模型,其在动态运行的时候无外乎由进程,线程组成。
用Spark的术语来说,static view称为dataset view,而dynamic view称为parition view. 关系如图所示
在Spark中的task可以对应于线程,worker是一个个的进程,worker由driver来进行管理。
那么问题来了,这一个个的task是如何从RDD演变过来的呢?下节将详细回答这个问题。
部署(Deployment view)
当有Action作用于某RDD时,该action会作为一个job被提交。
在提交的过程中,DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG。
每一个JOB被分为多个stage,划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,避免多个stage之间的消息传递开销。
当stage被提交之后,由taskscheduler来根据stage来计算所需要的task,并将task提交到对应的worker.
Spark支持以下几种部署模式1)standalone 2)Mesos 3) yarn. 这些部署模式将作为taskscheduler的初始化入参。
RDD接口(RDD Interface)
RDD由以下几个主要部分组成
- partitions -- partition集合,一个RDD中有多少data partition
- dependencies -- RDD依赖关系
- compute(parition) -- 对于给定的数据集,需要作哪些计算
- preferredLocations -- 对于data partition的位置偏好
- partitioner -- 对于计算出来的数据结果如何分发
缓存机制(caching)
RDD的中间计算结果可以被缓存起来,缓存先选Memory,如果Memory不够的话,将会被写入到磁盘中。
根据LRU(last-recent update)来决定哪先内容继续保存在内存,哪些保存到磁盘。
容错性(Fault-tolerant)
从最初始的RDD到衍生出来的最后一个RDD,中间要经过一系列的处理。那么如何处理中间环节出现错误的场景呢?
Spark提供的解决方案是只对失效的data partition进行事件重演,而无须对整个数据全集进行事件重演,这样可以大大加快场景恢复的开销。
RDD又是如何知道自己的data partition的number该是多少?如果是hdfs文件,那么hdfs文件的block将会成为一个重要的计算依据。
集群管理(cluster management)
task运行在cluster之上,除了spark自身提供的standalone部署模式之外,spark还内在支持yarn和mesos.
Yarn来负责计算资源的调度和监控,根据监控结果来重启失效的task或者是重新distributed task一旦有新的node加入cluster的话。
这一部分的内容需要参考yarn的文档。
小结
在源码阅读时,需要重点把握以下两大主线。
- 静态view 即 RDD, transformation and action
- 动态view 即 life of a job, 每一个job又分为多个stage,每一个stage中可以包含多个rdd及其transformation,这些stage又是如何映射成为task被distributed到cluster中
JOB的生成和运行
job生成的简单流程如下
- 首先应用程序创建SparkContext的实例,如实例为sc
- 利用SparkContext的实例来创建生成RDD
- 经过一连串的transformation操作,原始的RDD转换成为其它类型的RDD
- 当action作用于转换之后RDD时,会调用SparkContext的runJob方法
- sc.runJob的调用是后面一连串反应的起点,关键性的跃变就发生在此处
调用路径大致如下
- sc.runJob->dagScheduler.runJob->submitJob
- DAGScheduler::submitJob会创建JobSummitted的event发送给内嵌类eventProcessActor
- eventProcessActor在接收到JobSubmmitted之后调用processEvent处理函数
- job到stage的转换,生成finalStage并提交运行,关键是调用submitStage
- 在submitStage中会计算stage之间的依赖关系,依赖关系分为宽依赖和窄依赖两种
- 如果计算中发现当前的stage没有任何依赖或者所有的依赖都已经准备完毕,则提交task
- 提交task是调用函数submitMissingTasks来完成
- task真正运行在哪个worker上面是由TaskScheduler来管理,也就是上面的submitMissingTasks会调用TaskScheduler::submitTasks
- TaskSchedulerImpl中会根据Spark的当前运行模式来创建相应的backend,如果是在单机运行则创建LocalBackend
- LocalBackend收到TaskSchedulerImpl传递进来的ReceiveOffers事件
- receiveOffers->executor.launchTask->TaskRunner.run
代码片段executor.lauchTask
def launchTask(context: ExecutorBackend, taskId: Long, serializedTask: ByteBuffer) {val tr = new TaskRunner(context, taskId, serializedTask)runningTasks.put(taskId, tr)threadPool.execute(tr)}RDD的转换过程
还是以最简单的wordcount为例说明rdd的转换过程
sc.textFile("README.md").flatMap(line=>line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
上述一行简短的代码其实发生了很复杂的RDD转换,下面仔细解释每一步的转换过程和转换结果
步骤1:val rawFile = sc.textFile("README.md")
textFile先是生成hadoopRDD,然后再通过map操作生成MappedRDD,如果在spark-shell中执行上述语句,得到的结果可以证明所做的分析
scala> sc.textFile("README.md")
14/04/23 13:11:48 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
14/04/23 13:11:48 INFO MemoryStore: ensureFreeSpace(119741) called with curMem=0, maxMem=311387750
14/04/23 13:11:48 INFO MemoryStore: Block broadcast_0 stored as values to memory (estimated size 116.9 KB, free 296.8 MB)
14/04/23 13:11:48 DEBUG BlockManager: Put block broadcast_0 locally took 277 ms
14/04/23 13:11:48 DEBUG BlockManager: Put for block broadcast_0 without replication took 281 ms
res0: org.apache.spark.rdd.RDD[String] = MappedRDD[1] at textFile at :13
步骤2: val splittedText = rawFile.flatMap(line => line.split(" "))
flatMap将原来的MappedRDD转换成为FlatMappedRDD
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = new FlatMappedRDD(this, sc.clean(f))
步骤3:val wordCount = splittedText.map(word => (word, 1))
利用word生成相应的键值对,上一步的FlatMappedRDD被转换成为MappedRDD
步骤4:val reduceJob = wordCount.reduceByKey(_ + _),这一步最复杂
步骤2,3中使用到的operation全部定义在RDD.scala中,而这里使用到的reduceByKey却在RDD.scala中见不到踪迹。reduceByKey的定义出现在源文件PairRDDFunctions.scala
细心的你一定会问reduceByKey不是MappedRDD的属性和方法啊,怎么能被MappedRDD调用呢?其实这背后发生了一个隐式的转换,该转换将MappedRDD转换成为PairRDDFunctions
implicit def rddToPairRDDFunctions[K: ClassTag, V: ClassTag](rdd: RDD[(K, V)]) =new PairRDDFunctions(rdd)
这种隐式的转换是scala的一个语法特征,如果想知道的更多,请用关键字"scala implicit method"进行查询,会有不少的文章对此进行详尽的介绍。
接下来再看一看reduceByKey的定义
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = {reduceByKey(defaultPartitioner(self), func)}def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = {combineByKey[V]((v: V) => v, func, func, partitioner)}def combineByKey[C](createCombiner: V => C,mergeValue: (C, V) => C,mergeCombiners: (C, C) => C,partitioner: Partitioner,mapSideCombine: Boolean = true,serializerClass: String = null): RDD[(K, C)] = {if (getKeyClass().isArray) {if (mapSideCombine) {throw new SparkException("Cannot use map-side combining with array keys.")}if (partitioner.isInstanceOf[HashPartitioner]) {throw new SparkException("Default partitioner cannot partition array keys.")}}val aggregator = new Aggregator[K, V, C](createCombiner, mergeValue, mergeCombiners)if (self.partitioner == Some(partitioner)) {self.mapPartitionsWithContext((context, iter) => {new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))}, preservesPartitioning = true)} else if (mapSideCombine) {val combined = self.mapPartitionsWithContext((context, iter) => {aggregator.combineValuesByKey(iter, context)}, preservesPartitioning = true)val partitioned = new ShuffledRDD[K, C, (K, C)](combined, partitioner).setSerializer(serializerClass)partitioned.mapPartitionsWithContext((context, iter) => {new InterruptibleIterator(context, aggregator.combineCombinersByKey(iter, context))}, preservesPartitioning = true)} else {// Don't apply map-side combiner.val values = new ShuffledRDD[K, V, (K, V)](self, partitioner).setSerializer(serializerClass)values.mapPartitionsWithContext((context, iter) => {new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))}, preservesPartitioning = true)}}
reduceByKey最终会调用combineByKey, 在这个函数中PairedRDDFunctions会被转换成为ShuffleRDD,当调用mapPartitionsWithContext之后,shuffleRDD被转换成为MapPartitionsRDD
Log输出能证明我们的分析
res1: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[8] at reduceByKey at :13
RDD转换小结
小结一下整个RDD转换过程
HadoopRDD->MappedRDD->FlatMappedRDD->MappedRDD->PairRDDFunctions->ShuffleRDD->MapPartitionsRDD
整个转换过程好长啊,这一切的转换都发生在任务提交之前。
运行过程分析
数据集操作分类
在对任务运行过程中的函数调用关系进行分析之前,我们也来探讨一个偏理论的东西,作用于RDD之上的Transformantion为什么会是这个样子?
对这个问题的解答和数学搭上关系了,从理论抽象的角度来说,任务处理都可归结为“input->processing->output"。input和output对应于数据集dataset.
在此基础上作一下简单的分类
- one-one 一个dataset在转换之后还是一个dataset,而且dataset的size不变,如map
- one-one 一个dataset在转换之后还是一个dataset,但size发生更改,这种更改有两种可能:扩大或缩小,如flatMap是size增大的操作,而subtract是size变小的操作
- many-one 多个dataset合并为一个dataset,如combine, join
- one-many 一个dataset分裂为多个dataset, 如groupBy
Task运行期的函数调用
task的提交过程参考本系列中的第二篇文章。本节主要讲解当task在运行期间是如何一步步调用到作用于RDD上的各个operation
- TaskRunner.run
- Task.run
- Task.runTask (Task是一个基类,有两个子类,分别为ShuffleMapTask和ResultTask)
- RDD.iterator
- RDD.computeOrReadCheckpoint
- RDD.compute
- RDD.computeOrReadCheckpoint
- RDD.iterator
- Task.runTask (Task是一个基类,有两个子类,分别为ShuffleMapTask和ResultTask)
- Task.run
或许当看到RDD.compute函数定义时,还是觉着f没有被调用,以MappedRDD的compute定义为例
override def compute(split: Partition, context: TaskContext) = firstParent[T].iterator(split, context).map(f)
注意,这里最容易产生错觉的地方就是map函数,这里的map不是RDD中的map,而是scala中定义的iterator的成员函数map, 请自行参考http://www.scala-lang.org/api/2.10.4/index.html#scala.collection.Iterator
堆栈输出
80 at org.apache.spark.rdd.HadoopRDD.getJobConf(HadoopRDD.scala:111)81 at org.apache.spark.rdd.HadoopRDD$$anon$1.(HadoopRDD.scala:154)82 at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:149)83 at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:64)84 at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:241)85 at org.apache.spark.rdd.RDD.iterator(RDD.scala:232)86 at org.apache.spark.rdd.MappedRDD.compute(MappedRDD.scala:31)87 at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:241)88 at org.apache.spark.rdd.RDD.iterator(RDD.scala:232)89 at org.apache.spark.rdd.FlatMappedRDD.compute(FlatMappedRDD.scala:33)90 at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:241)91 at org.apache.spark.rdd.RDD.iterator(RDD.scala:232)92 at org.apache.spark.rdd.MappedRDD.compute(MappedRDD.scala:31)93 at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:241)94 at org.apache.spark.rdd.RDD.iterator(RDD.scala:232)95 at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:34)96 at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:241)97 at org.apache.spark.rdd.RDD.iterator(RDD.scala:232)98 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:161)99 at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:102)
100 at org.apache.spark.scheduler.Task.run(Task.scala:53)
101 at org.apache.spark.executor.Executor$TaskRunner$$anonfun$run$1.apply$mcV$sp(Executor.scala:211)
ResultTask
compute的计算过程对于ShuffleMapTask比较复杂,绕的圈圈比较多,对于ResultTask就直接许多。
override def runTask(context: TaskContext): U = {metrics = Some(context.taskMetrics)try {func(context, rdd.iterator(split, context))} finally {context.executeOnCompleteCallbacks()}}
计算结果的传递
上面的分析知道,wordcount这个job在最终提交之后,被DAGScheduler分为两个stage,第一个Stage是shuffleMapTask,第二个Stage是ResultTask.
那么ShuffleMapTask的计算结果是如何被ResultTask取得的呢?这个过程简述如下
- ShffuleMapTask将计算的状态(注意不是具体的数据)包装为MapStatus返回给DAGScheduler
- DAGScheduler将MapStatus保存到MapOutputTrackerMaster中
- ResultTask在执行到ShuffleRDD时会调用BlockStoreShuffleFetcher的fetch方法去获取数据
- 第一件事就是咨询MapOutputTrackerMaster所要取的数据的location
- 根据返回的结果调用BlockManager.getMultiple获取真正的数据
BlockStoreShuffleFetcher的fetch函数伪码
val blockManager = SparkEnv.get.blockManagerval startTime = System.currentTimeMillisval statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId)logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format(shuffleId, reduceId, System.currentTimeMillis - startTime))val blockFetcherItr = blockManager.getMultiple(blocksByAddress, serializer)val itr = blockFetcherItr.flatMap(unpackBlock)
注意上述代码中的getServerStatuses及getMultiple,一个是询问数据的位置,一个是去获取真正的数据。
DStream实时流数据处理
流数据的特点
与一般的文件(即内容已经固定)型数据源相比,所谓的流数据拥有如下的特点
- 数据一直处在变化中
- 数据无法回退
- 数据一直源源不断的涌进
DStream
如果要用一句话来概括Spark Streaming的处理思路的话,那就是"将连续的数据持久化,离散化,然后进行批量处理"。
让我们来仔细分析一下这么作的原因。
- 数据持久化 将从网络上接收到的数据先暂时存储下来,为事件处理出错时的事件重演提供可能,
- 离散化 数据源源不断的涌进,永远没有一个尽头,就像周星驰的喜剧中所说“崇拜之情如黄河之水绵绵不绝,一发而不可收拾”。既然不能穷尽,那么就将其按时间分片。比如采用一分钟为时间间隔,那么在连续的一分钟内收集到的数据集中存储在一起。
- 批量处理 将持久化下来的数据分批进行处理,处理机制套用之前的RDD模式
DStream可以说是对RDD的又一层封装。如果打开DStream.scala和RDD.scala,可以发现几乎RDD上的所有operation在DStream中都有相应的定义。
作用于DStream上的operation分成两类
- Transformation
- Output 表示将输出结果,目前支持的有print, saveAsObjectFiles, saveAsTextFiles, saveAsHadoopFiles
DStreamGraph
有输入就要有输出,如果没有输出,则前面所做的所有动作全部没有意义,那么如何将这些输入和输出绑定起来呢?这个问题的解决就依赖于DStreamGraph,DStreamGraph记录输入的Stream和输出的Stream。
private val inputStreams = new ArrayBuffer[InputDStream[_]]()private val outputStreams = new ArrayBuffer[DStream[_]]()var rememberDuration: Duration = nullvar checkpointInProgress = false
outputStreams中的元素是在有Output类型的Operation作用于DStream上时自动添加到DStreamGraph中的。
outputStream区别于inputStream一个重要的地方就是会重载generateJob.
初始化流程

StreamingContext
StreamingContext是Spark Streaming初始化的入口点,主要的功能是根据入参来生成JobScheduler
设定InputStream
如果流数据源来自于socket,则使用socketStream。如果数据源来自于不断变化着的文件,则可使用fileStream
提交运行
StreamingContext.start()
数据处理
以socketStream为例,数据来自于socket。
SocketInputDstream启动一个线程,该线程使用receive函数来接收数据
def receive() { var socket: Socket = null try { logInfo("Connecting to " + host + ":" + port) socket = new Socket(host, port) logInfo("Connected to " + host + ":" + port) val iterator = bytesToObjects(socket.getInputStream()) while(!isStopped && iterator.hasNext) { store(iterator.next) } logInfo("Stopped receiving") restart("Retrying connecting to " + host + ":" + port) } catch { case e: java.net.ConnectException => restart("Error connecting to " + host + ":" + port, e) case t: Throwable => restart("Error receiving data", t) } finally { if (socket != null) { socket.close() logInfo("Closed socket to " + host + ":" + port) } } }
}
接收到的数据会被先存储起来,存储最终会调用到BlockManager.scala中的函数,那么BlockManager是如何被传递到StreamingContext的呢?利用SparkEnv传入的,注意StreamingContext构造函数的入参。
处理定时器
数据的存储有是被socket触发的。那么已经存储的数据被真正的处理又是被什么触发的呢?
记得在初始化StreamingContext的时候,我们指定了一个时间参数,那么用这个参数会构造相应的重复定时器,一旦定时器超时,调用generateJobs函数。
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds, longTime => eventActor ! GenerateJobs(new Time(longTime)), "JobGenerator")事件处理函数
/** Processes all events */ private def processEvent(event: JobGeneratorEvent) { logDebug("Got event " + event) event match { case GenerateJobs(time) => generateJobs(time) case ClearMetadata(time) => clearMetadata(time) case DoCheckpoint(time) => doCheckpoint(time) case ClearCheckpointData(time) => clearCheckpointData(time) } }
generteJobs
private def generateJobs(time: Time) { SparkEnv.set(ssc.env) Try(graph.generateJobs(time)) match { case Success(jobs) => val receivedBlockInfo = graph.getReceiverInputStreams.map { stream => val streamId = stream.id val receivedBlockInfo = stream.getReceivedBlockInfo(time) (streamId, receivedBlockInfo) }.toMap jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfo)) case Failure(e) => jobScheduler.reportError("Error generating jobs for time " + time, e) } eventActor ! DoCheckpoint(time) }
generateJobs->generateJob一路下去会调用到Job.run,在job.run中调用sc.runJob,在具体调用路径就不一一列出。
private class JobHandler(job: Job) extends Runnable {def run() {eventActor ! JobStarted(job)job.run()eventActor ! JobCompleted(job)}}
DStream.generateJob函数中定义了jobFunc,也就是在job.run()中使用到的jobFunc
private[streaming] def generateJob(time: Time): Option[Job] = {getOrCompute(time) match {case Some(rdd) => {val jobFunc = () => {val emptyFunc = { (iterator: Iterator[T]) => {} }context.sparkContext.runJob(rdd, emptyFunc)}Some(new Job(time, jobFunc))}case None => None}}
在这个流程中,DStreamGraph起到非常关键的作用,非常类似于TridentStorm中的graph.
在generateJob过程中,DStream会通过调用compute函数生成相应的RDD,SparkContext则是将基于RDD的抽象转换成为多个stage,而执行。
StreamingContext中一个重要的转换就是DStream到RDD的转换,而SparkContext中一个重要的转换是RDD到Stage及Task的转换。在这两个不同的抽象类中,要注意其中getOrCompute和compute函数的实现。
存储子系统分析
存储子系统概览

上图是Spark存储子系统中几个主要模块的关系示意图,现简要说明如下
- CacheManager RDD在进行计算的时候,通过CacheManager来获取数据,并通过CacheManager来存储计算结果
- BlockManager CacheManager在进行数据读取和存取的时候主要是依赖BlockManager接口来操作,BlockManager决定数据是从内存(MemoryStore)还是从磁盘(DiskStore)中获取
- MemoryStore 负责将数据保存在内存或从内存读取
- DiskStore 负责将数据写入磁盘或从磁盘读入
- BlockManagerWorker 数据写入本地的MemoryStore或DiskStore是一个同步操作,为了容错还需要将数据复制到别的计算结点,以防止数据丢失的时候还能够恢复,数据复制的操作是异步完成,由BlockManagerWorker来处理这一部分事情
- ConnectionManager 负责与其它计算结点建立连接,并负责数据的发送和接收
- BlockManagerMaster 注意该模块只运行在Driver Application所在的Executor,功能是负责记录下所有BlockIds存储在哪个SlaveWorker上,比如RDD Task运行在机器A,所需要的BlockId为3,但在机器A上没有BlockId为3的数值,这个时候Slave worker需要通过BlockManager向BlockManagerMaster询问数据存储的位置,然后再通过ConnectionManager去获取,具体参看“数据远程获取一节”
支持的操作
由于BlockManager起到实际的存储管控作用,所以在讲支持的操作的时候,以BlockManager中的public api为例
- put 数据写入
- get 数据读取
- remoteRDD 数据删除,一旦整个job完成,所有的中间计算结果都可以删除
启动过程分析
上述的各个模块由SparkEnv来创建,创建过程在SparkEnv.create中完成
val blockManagerMaster = new BlockManagerMaster(registerOrLookup("BlockManagerMaster",new BlockManagerMasterActor(isLocal, conf)), conf)val blockManager = new BlockManager(executorId, actorSystem, blockManagerMaster, serializer, conf)val connectionManager = blockManager.connectionManagerval broadcastManager = new BroadcastManager(isDriver, conf)val cacheManager = new CacheManager(blockManager)
这段代码容易让人疑惑,看起来像是在所有的cluster node上都创建了BlockManagerMasterActor,其实不然,仔细看registerOrLookup函数的实现。如果当前节点是driver则创建这个actor,否则建立到driver的连接。
def registerOrLookup(name: String, newActor: => Actor): ActorRef = {if (isDriver) {logInfo("Registering " + name)actorSystem.actorOf(Props(newActor), name = name)} else {val driverHost: String = conf.get("spark.driver.host", "localhost")val driverPort: Int = conf.getInt("spark.driver.port", 7077)Utils.checkHost(driverHost, "Expected hostname")val url = s"akka.tcp://spark@$driverHost:$driverPort/user/$name"val timeout = AkkaUtils.lookupTimeout(conf)logInfo(s"Connecting to $name: $url")Await.result(actorSystem.actorSelection(url).resolveOne(timeout), timeout)}}
初始化过程中一个主要的动作就是BlockManager需要向BlockManagerMaster发起注册
数据写入过程分析

数据写入的简要流程
- RDD.iterator是与storage子系统交互的入口
- CacheManager.getOrCompute调用BlockManager的put接口来写入数据
- 数据优先写入到MemoryStore即内存,如果MemoryStore中的数据已满则将最近使用次数不频繁的数据写入到磁盘
- 通知BlockManagerMaster有新的数据写入,在BlockManagerMaster中保存元数据
- 将写入的数据与其它slave worker进行同步,一般来说在本机写入的数据,都会另先一台机器来进行数据的备份,即replicanumber=1
序列化与否
写入的具体内容可以是序列化之后的bytes也可以是没有序列化的value. 此处有一个对scala的语法中Either, Left, Right关键字的理解。
数据读取过程分析
def get(blockId: BlockId): Option[Iterator[Any]] = {val local = getLocal(blockId)if (local.isDefined) {logInfo("Found block %s locally".format(blockId))return local}val remote = getRemote(blockId)if (remote.isDefined) {logInfo("Found block %s remotely".format(blockId))return remote}None}
本地读取
首先在查询本机的MemoryStore和DiskStore中是否有所需要的block数据存在,如果没有则发起远程数据获取。
远程读取
远程获取调用路径, getRemote->doGetRemote, 在doGetRemote中最主要的就是调用BlockManagerWorker.syncGetBlock来从远程获得数据
def syncGetBlock(msg: GetBlock, toConnManagerId: ConnectionManagerId): ByteBuffer = {val blockManager = blockManagerWorker.blockManagerval connectionManager = blockManager.connectionManagerval blockMessage = BlockMessage.fromGetBlock(msg)val blockMessageArray = new BlockMessageArray(blockMessage)val responseMessage = connectionManager.sendMessageReliablySync(toConnManagerId, blockMessageArray.toBufferMessage)responseMessage match {case Some(message) => {val bufferMessage = message.asInstanceOf[BufferMessage]logDebug("Response message received " + bufferMessage)BlockMessageArray.fromBufferMessage(bufferMessage).foreach(blockMessage => {logDebug("Found " + blockMessage)return blockMessage.getData})}case None => logDebug("No response message received")}null}
上述这段代码中最有意思的莫过于sendMessageReliablySync,远程数据读取毫无疑问是一个异步i/o操作,这里的代码怎么写起来就像是在进行同步的操作一样呢。也就是说如何知道对方发送回来响应的呢?
别急,继续去看看sendMessageReliablySync的定义
def sendMessageReliably(connectionManagerId: ConnectionManagerId, message: Message): Future[Option[Message]] = {val promise = Promise[Option[Message]]val status = new MessageStatus(message, connectionManagerId, s => promise.success(s.ackMessage))messageStatuses.synchronized {messageStatuses += ((message.id, status))}sendMessage(connectionManagerId, message)promise.future}
要是我说秘密在这里,你肯定会说我在扯淡,但确实在此处。注意到关键字Promise和Future没。
如果这个future执行完毕,返回s.ackMessage。我们再看看这个ackMessage是在什么地方被写入的呢。看一看ConnectionManager.handleMessage中的代码片段
case bufferMessage: BufferMessage => {if (authEnabled) {val res = handleAuthentication(connection, bufferMessage)if (res == true) {// message was security negotiation so skip the restlogDebug("After handleAuth result was true, returning")return}}if (bufferMessage.hasAckId) {val sentMessageStatus = messageStatuses.synchronized {messageStatuses.get(bufferMessage.ackId) match {case Some(status) => {messageStatuses -= bufferMessage.ackIdstatus}case None => {throw new Exception("Could not find reference for received ack message " +message.id)null}}}sentMessageStatus.synchronized {sentMessageStatus.ackMessage = Some(message)sentMessageStatus.attempted = truesentMessageStatus.acked = truesentMessageStaus.markDone()}
注意,此处的所调用的sentMessageStatus.markDone就会调用在sendMessageReliablySync中定义的promise.Success. 不妨看看MessageStatus的定义。
class MessageStatus(val message: Message,val connectionManagerId: ConnectionManagerId,completionHandler: MessageStatus => Unit) {var ackMessage: Option[Message] = Nonevar attempted = falsevar acked = falsedef markDone() { completionHandler(this) }}
我想至此调用关系搞清楚了,scala中的Future和Promise理解起来还有有点费劲。
TachyonStore
在Spark的最新源码中,Storage子系统引入了TachyonStore. TachyonStore是在内存中实现了hdfs文件系统的接口,主要目的就是尽可能的利用内存来作为数据持久层,避免过多的磁盘读写操作。
有关该模块的功能介绍,可以参考http://www.meetup.com/spark-users/events/117307472/
Standalone部署方式分析
没有HA的Standalone运行模式
先从比较简单的说起,所谓的没有ha是指master节点没有ha。
组成cluster的两大元素即Master和Worker。slave worker可以有1到多个,这些worker都处于active状态。
Driver Application可以运行在Cluster之内,也可以在cluster之外运行,先从简单的讲起即Driver Application独立于Cluster。那么这样的整体框架如下图所示,由driver,master和多个slave worker来共同组成整个的运行环境。

执行顺序
步骤1 运行master
$SPARK_HOME/sbin/start_master.sh
在start_master.sh中最关键的一句就是
"$sbin"/spark-daemon.sh start org.apache.spark.deploy.master.Master 1 --ip $SPARK_MASTER_IP --port $SPARK_MASTER_PORT --webui-port $SPARK_MASTER_WEBUI_PORT
检测Master的jvm进程
root 23438 1 67 22:57 pts/0 00:00:05 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Dspark.akka.logLifecycleEvents=true -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip localhost --port 7077 --webui-port 8080
Master的日志在$SPARK_HOME/logs目录下
步骤2 运行worker,可以启动多个
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost:7077
worker运行时,需要注册到指定的master url,这里就是spark://localhost:7077.
Master侧收到RegisterWorker通知,其处理代码如下
case RegisterWorker(id, workerHost, workerPort, cores, memory, workerUiPort, publicAddress) =>{logInfo("Registering worker %s:%d with %d cores, %s RAM".format(workerHost, workerPort, cores, Utils.megabytesToString(memory)))if (state == RecoveryState.STANDBY) {// ignore, don't send response} else if (idToWorker.contains(id)) {sender ! RegisterWorkerFailed("Duplicate worker ID")} else {val worker = new WorkerInfo(id, workerHost, workerPort, cores, memory,sender, workerUiPort, publicAddress)if (registerWorker(worker)) {persistenceEngine.addWorker(worker)sender ! RegisteredWorker(masterUrl, masterWebUiUrl)schedule()} else {val workerAddress = worker.actor.path.addresslogWarning("Worker registration failed. Attempted to re-register worker at same " +"address: " + workerAddress)sender ! RegisterWorkerFailed("Attempted to re-register worker at same address: "+ workerAddress)}}}
步骤3 运行Spark-shell
MASTER=spark://localhost:7077 $SPARK_HOME/bin/spark-shell
spark-shell属于application,有关appliation的运行日志存储在$SPARK_HOME/works目录下
spark-shell作为application,在Master侧其处理的分支是RegisterApplication,具体处理代码如下。
case RegisterApplication(description) => {if (state == RecoveryState.STANDBY) {// ignore, don't send response} else {logInfo("Registering app " + description.name)val app = createApplication(description, sender)registerApplication(app)logInfo("Registered app " + description.name + " with ID " + app.id)persistenceEngine.addApplication(app)sender ! RegisteredApplication(app.id, masterUrl)schedule()}}
每当有新的application注册到master,master都要调度schedule函数将application发送到相应的worker,在对应的worker启动相应的ExecutorBackend. 具体代码请参考Master.scala中的schedule函数,代码就不再列出。
步骤4 结果检测
/opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Dspark.akka.logLifecycleEvents=true -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip localhost --port 7077 --webui-port 8080
root 23752 23745 21 23:00 pts/0 00:00:25 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.repl.Main
root 23986 23938 25 23:02 pts/2 00:00:03 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Dspark.akka.logLifecycleEvents=true -Djava.library.path= -Xms512m -Xmx512m org.apache.spark.deploy.worker.Worker spark://localhost:7077
root 24047 23986 34 23:02 pts/2 00:00:04 /opt/java/bin/java -cp :/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar -Xms512M -Xmx512M org.apache.spark.executor.CoarseGrainedExecutorBackend akka.tcp://spark@localhost:40053/user/CoarseGrainedScheduler 0 localhost 4 akka.tcp://sparkWorker@localhost:53568/user/Worker app-20140511230059-0000
从运行的进程之间的关系可以看出,worker和master之间的连接建立完毕之后,如果有新的driver application连接上master,master会要求worker启动相应的ExecutorBackend进程。此后若有什么Task需要运行,则会运行在这些Executor之上。可以从以下的日志信息得出此结论,当然看源码亦可。
14/05/11 23:02:36 INFO Worker: Asked to launch executor app-20140511230059-0000/0 for Spark shell
14/05/11 23:02:36 INFO ExecutorRunner: Launch command: "/opt/java/bin/java" "-cp" ":/root/working/spark-0.9.1-bin-hadoop2/conf:/root/working/spark-0.9.1-bin-hadoop2/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar" "-Xms512M" "-Xmx512M" "org.apache.spark.executor.CoarseGrainedExecutorBackend" "akka.tcp://spark@localhost:40053/user/CoarseGrainedScheduler" "0" "localhost" "4" "akka.tcp://sparkWorker@localhost:53568/user/Worker" "app-20140511230059-0000"
worker中启动exectuor的相关源码见worker中的receive函数,相关代码如下
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>if (masterUrl != activeMasterUrl) {logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")} else {try {logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))val manager = new ExecutorRunner(appId, execId, appDesc, cores_, memory_,self, workerId, host,appDesc.sparkHome.map(userSparkHome => new File(userSparkHome)).getOrElse(sparkHome),workDir, akkaUrl, ExecutorState.RUNNING)executors(appId + "/" + execId) = managermanager.start()coresUsed += cores_memoryUsed += memory_masterLock.synchronized {master ! ExecutorStateChanged(appId, execId, manager.state, None, None)}} catch {case e: Exception => {logError("Failed to launch exector %s/%d for %s".format(appId, execId, appDesc.name))if (executors.contains(appId + "/" + execId)) {executors(appId + "/" + execId).kill()executors -= appId + "/" + execId}masterLock.synchronized {master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED, None, None)}}}}
关于standalone的部署,需要详细研究的源码文件如下所列。
- deploy/master/Master.scala
- deploy/worker/worker.scala
- executor/CoarseGrainedExecutorBackend.scala
查看进程之间的父子关系,请用"pstree"
使用下图来小结单Master的部署情况。

类的动态加载和反射
在谈部署Driver到Cluster上之前,我们先回顾一下java的一大特性“类的动态加载和反射机制”。本人不是一直写java代码出身,所以好多东西都是边用边学,难免挂一漏万。
所谓的反射,其实就是要解决在运行期实现类的动态加载。
来个简单的例子
package test;public class Demo {public Demo() {System.out.println("Hi!");}@SuppressWarnings("unchecked")public static void main(String[] args) throws Exception {Class clazz = Class.forName("test.Demo");Demo demo = (Demo) clazz.newInstance();}
}
谈到这里,就自然想到了一个面试题,“谈一谈Class.forName和ClassLoader.loadClass的区别"。说到面试,我总是很没有信心,面试官都很屌的, :)。
装载:通过累的全限定名获取二进制字节流,将二进制字节流转换成方法区中的运行时数据结构,在内存中生成Java.lang.class对象; 链接:执行下面的校验、准备和解析步骤,其中解析步骤是可以选择的; 校验:检查导入类或接口的二进制数据的正确性;(文件格式验证,元数据验证,字节码验证,符号引用验证) 准备:给类的静态变量分配并初始化存储空间; 解析:将常量池中的符号引用转成直接引用; 初始化:激活类的静态变量的初始化Java代码和静态Java代码块,并初始化程序员设置的变量值。
Class.forName(className)方法,内部实际调用的方法是 Class.forName(className,true,classloader);第2个boolean参数表示类是否需要初始化, Class.forName(className)默认是需要初始化。一旦初始化,就会触发目标对象的 static块代码执行,static参数也也会被再次初始化。ClassLoader.loadClass(className)方法,内部实际调用的方法是 ClassLoader.loadClass(className,false);第2个 boolean参数,表示目标对象是否进行链接,false表示不进行链接,由上面介绍可以,不进行链接意味着不进行包括初始化等一些列步骤,那么静态块和静态对象就不会得到执行
在cluster中运行Driver Application
上一节之所以写到类的动态加载与反射都是为了谈这一节的内容奠定基础。
将Driver application部署到Cluster中,启动的时序大体如下图所示。

- 首先启动Master,然后启动Worker
- 使用”deploy.Client"将Driver Application提交到Cluster中
./bin/spark-class org.apache.spark.deploy.Client launch[client-options] \\[application-options]
- Master在收到RegisterDriver的请求之后,会发送LaunchDriver给worker,要求worker启动一个Driver的jvm process
- Driver Application在新生成的JVM进程中运行开始时会注册到master中,发送RegisterApplication给Master
- Master发送LaunchExecutor给Worker,要求Worker启动执行ExecutorBackend的JVM Process
- 一当ExecutorBackend启动完毕,Driver Application就可以将任务提交到ExecutorBackend上面执行,即LaunchTask指令
提交侧的代码,详见deploy/Client.scala
driverArgs.cmd match {case "launch" =>// TODO: We could add an env variable here and intercept it in `sc.addJar` that would// truncate filesystem paths similar to what YARN does. For now, we just require// people call `addJar` assuming the jar is in the same directory.val env = Map[String, String]()System.getenv().foreach{case (k, v) => env(k) = v}val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"val classPathConf = "spark.driver.extraClassPath"val classPathEntries = sys.props.get(classPathConf).toSeq.flatMap { cp =>cp.split(java.io.File.pathSeparator)}val libraryPathConf = "spark.driver.extraLibraryPath"val libraryPathEntries = sys.props.get(libraryPathConf).toSeq.flatMap { cp =>cp.split(java.io.File.pathSeparator)}val javaOptionsConf = "spark.driver.extraJavaOptions"val javaOpts = sys.props.get(javaOptionsConf)val command = new Command(mainClass, Seq("{{WORKER_URL}}", driverArgs.mainClass) ++driverArgs.driverOptions, env, classPathEntries, libraryPathEntries, javaOpts)val driverDescription = new DriverDescription(driverArgs.jarUrl,driverArgs.memory,driverArgs.cores,driverArgs.supervise,command)masterActor ! RequestSubmitDriver(driverDescription)
接收侧
从Deploy.client发送出来的消息被谁接收呢?答案比较明显,那就是Master。 Master.scala中的receive函数有专门针对RequestSubmitDriver的处理,具体代码如下
case RequestSubmitDriver(description) => {if (state != RecoveryState.ALIVE) {val msg = s"Can only accept driver submissions in ALIVE state. Current state: $state."sender ! SubmitDriverResponse(false, None, msg)} else {logInfo("Driver submitted " + description.command.mainClass)val driver = createDriver(description)persistenceEngine.addDriver(driver)waitingDrivers += driverdrivers.add(driver)schedule()// TODO: It might be good to instead have the submission client poll the master to determine// the current status of the driver. For now it's simply "fire and forget".sender ! SubmitDriverResponse(true, Some(driver.id),s"Driver successfully submitted as ${driver.id}")}}
SparkEnv
SparkEnv对于整个Spark的任务来说非常关键,不同的role在创建SparkEnv时传入的参数是不相同的,如Driver和Executor则存在重要区别。
在Executor.scala中,创建SparkEnv的代码如下所示
private val env = {if (!isLocal) {val _env = SparkEnv.create(conf, executorId, slaveHostname, 0,isDriver = false, isLocal = false)SparkEnv.set(_env)_env.metricsSystem.registerSource(executorSource)_env} else {SparkEnv.get}}
Driver Application则会创建SparkContext,在SparkContext创建过程中,比较重要的一步就是生成SparkEnv,其代码如下
private[spark] val env = SparkEnv.create(conf,"",conf.get("spark.driver.host"),conf.get("spark.driver.port").toInt,isDriver = true,isLocal = isLocal,listenerBus = listenerBus)SparkEnv.set(env)
Standalone模式下HA的实现
Spark在standalone模式下利用zookeeper来实现了HA机制,这里所说的HA是专门针对Master节点的,因为上面所有的分析可以看出Master是整个cluster中唯一可能出现单点失效的节点。
采用zookeeper之后,整个cluster的组成如下图所示。

为了使用zookeeper,Master在启动的时候需要指定如下的参数,修改conf/spark-env.sh, SPARK_DAEMON_JAVA_OPTS中添加如下选项。
| System property | Meaning |
| spark.deploy.recoveryMode | Set to ZOOKEEPER to enable standby Master recovery mode (default: NONE). |
| spark.deploy.zookeeper.url | The ZooKeeper cluster url (e.g., 192.168.1.100:2181,192.168.1.101:2181). |
| spark.deploy.zookeeper.dir | The directory in ZooKeeper to store recovery state (default: /spark). |
实现HA的原理
zookeeper提供了一个Leader Election机制,利用这个机制,可以实现HA功能,具体请参考zookeeper recipes
在Spark中没有直接使用zookeeper的api,而是使用了curator,curator对zookeeper做了相应的封装,在使用上更为友好。
Spark on Yarn
Spark Standalone部署模式回顾

上图是Spark Standalone Cluster中计算模块的简要示意,从中可以看出整个Cluster主要由四种不同的JVM组成
- Master 负责管理整个Cluster,Driver Application和Worker都需要注册到Master
- Worker 负责某一个node上计算资源的管理,如启动相应的Executor
- Executor RDD中每一个Stage的具体执行是在Executor上完成
- Driver Application driver中的schedulerbackend会因为部署模式的不同而不同
换个角度来说,Master对资源的管理是在进程级别,而SchedulerBackend则是在线程的级别。
启动时序图

YARN的基本架构和工作流程

YARN的基本架构如上图所示,由三大功能模块组成,分别是1) RM (ResourceManager) 2) NM (Node Manager) 3) AM(Application Master)
作业提交
- 用户通过Client向ResourceManager提交Application, ResourceManager根据用户请求分配合适的Container,然后在指定的NodeManager上运行Container以启动ApplicationMaster
- ApplicationMaster启动完成后,向ResourceManager注册自己
- 对于用户的Task,ApplicationMaster需要首先跟ResourceManager进行协商以获取运行用户Task所需要的Container,在获取成功后,ApplicationMaster将任务发送给指定的NodeManager
- NodeManager启动相应的Container,并运行用户Task
实例
上述说了一大堆,说白了在编写YARN Application时,主要是实现Client和ApplicatonMaster。实例请参考github上的simple-yarn-app.
Spark on Yarn
结合Spark Standalone的部署模式和YARN编程模型的要求,做了一张表来显示Spark Standalone和Spark on Yarn的对比。
| Standalone | YARN | Notes |
|---|---|---|
| Client | Client | standalone请参考spark.deploy目录 |
| Master | ApplicationMaster | |
| Worker | ExecutorRunnable | |
| Scheduler | YarnClusterScheduler | |
| SchedulerBackend | YarnClusterSchedulerBackend |
作上述表格的目的就是要搞清楚为什么需要做这些更改,与之前Standalone模式间的对应关系是什么。代码走读时,分析的重点是ApplicationMaster, YarnClusterSchedulerBackend和YarnClusterScheduler

一般来说,在Client中会显示的指定启动ApplicationMaster的类名,如下面的代码所示
ContainerLaunchContext amContainer =Records.newRecord(ContainerLaunchContext.class);amContainer.setCommands(Collections.singletonList("$JAVA_HOME/bin/java" +" -Xmx256M" +" com.hortonworks.simpleyarnapp.ApplicationMaster" +" " + command +" " + String.valueOf(n) +" 1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout" +" 2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr"));
但在yarn.Client中并没有直接指定ApplicationMaster的类名,是通过ClientArguments进行了封装,真正指定启动类的名称的地方在ClientArguments中。构造函数中指定了amClass的默认值是org.apache.spark.deploy.yarn.ApplicationMaster
实例说明
将SparkPi部署到Yarn上,下述是具体指令。
$ SPARK_JAR=./assembly/target/scala-2.10/spark-assembly-0.9.1-hadoop2.0.5-alpha.jar \./bin/spark-class org.apache.spark.deploy.yarn.Client \--jar examples/target/scala-2.10/spark-examples-assembly-0.9.1.jar \--class org.apache.spark.examples.SparkPi \--args yarn-standalone \--num-workers 3 \--master-memory 4g \--worker-memory 2g \--worker-cores 1
从输出的日志可以看出, Client在提交的时候,AM指定的是org.apache.spark.deploy.yarn.ApplicationMaster
13/12/29 23:33:25 INFO Client: Command for starting the Spark ApplicationMaster: $JAVA_HOME/bin/java -server -Xmx4096m -Djava.io.tmpdir=$PWD/tmp org.apache.spark.deploy.yarn.ApplicationMaster --class org.apache.spark.examples.SparkPi --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar --args 'yarn-standalone' --worker-memory 2048 --worker-cores 1 --num-workers 3 1> /stdout 2> /stderrSpark源码编译
准备
我的编译机器上安装的Linux是archlinux,并安装后如下软件
- scala 2.11
- maven
- git
下载源码
第一步当然是将github上的源码下载下来
git clone https://github.com/apache/spark.git
源码编译
不是直接用maven也不是直接用sbt,而是使用spark中自带的编译脚本make-distribution.sh
export SCALA_HOME=/usr/share/scala
cd $SPARK_HOME
./make-distribution.sh
如果一切顺利,会在$SPARK_HOME/assembly/target/scala-2.10目录下生成目标文件,比如
assembly/target/scala-2.10/spark-assembly-1.0.0-SNAPSHOT-hadoop1.0.4.jar
使用sbt编译
之前使用sbt编译一直会失败的主要原因就在于有些jar文件因为GFW的原因而访问不了。解决之道当然是添加代理才行。
代理的添加有下面几种方式,具体哪种好用,一一尝试吧,对于最新的spark。使用如下指令即可。
export http_proxy=http://proxy-server:port
方法二,设置JAVA_OPTS
JAVA_OPTS="-Dhttp.proxyServer=proxy-server -Dhttp.proxyPort=portNumber"
运行测试用例
既然能够顺利的编译出jar文件,那么肯定也改动两行代码来试试效果,如果知道自己的发动生效没有呢,运行测试用例是最好的办法了。
假设已经修改了$SPARK_HOME/core下的某些源码,重新编译的话,使用如下指令
export SCALA_HOME=/usr/share/scala
mvn package -DskipTests
假设当前在$SPARK_HOME/core目录下,想要运行一下RandomSamplerSuite这个测试用例集合,使用以下指令即可。
export SPARK_LOCAL_IP=127.0.0.1
export SPARK_MASTER_IP=127.0.0.1
mvn -Dsuites=org.apache.spark.util.random.RandomSamplerSuite test在yarn上运行SparkPi
下载spark
下载spark for hadoop2的版本
运行SparkPi
继续以hduser身份运行,最主要的一点就是设置YARN_CONF_DIR或HADOOP_CONF_DIR环境变量
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_JAR=./assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar \
./bin/spark-class org.apache.spark.deploy.yarn.Client \
--jar ./examples/target/scala-2.10/spark-examples_2.10-assembly-0.9.1.jar \
--class org.apache.spark.examples.JavaSparkPi \
--args yarn-standalone \
--num-workers 1 \
--master-memory 512m \
--worker-memory 512m \
--worker-cores 1
检查运行结果
运行结果保存在相关application的stdout目录,使用以下指令可以找到
cd $HADOOP_HOME
find . -name "*stdout"
假设找到的文件为./logs/userlogs/application_1400479924971_0002/container_1400479924971_0002_01_000001/stdout,使用cat可以看到结果
cat ./logs/userlogs/application_1400479924971_0002/container_1400479924971_0002_01_000001/stdout
Pi is roughly 3.14028应用举例
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
import sqlContext._
case class Person(name: String, age: Int)
val person = sc.textFile("examples/src/main/resources/people.txt").map(_.split(" ")).map(p => Person(p(0), p(1).trim.toInt))
person.registerAsTable("person")
val teenagers = sql("SELECT name, age FROM person WHERE age >= 13 and age <= 19")
teenagers.map(t => "name:" + t(0)).collect().foreach(println)
上述代码的逻辑非常清晰,就是将存在于person.txt中年龄界于13到19岁的年轻人名字打印出来。
SQL通用执行过程
SQL的组成部分
SQL语句大家都很熟悉,那么有没有仔细想过其有几大部分组成呢?可能你会说,”这还用问,不就是“select * from tablex where f1=?”,有什么好想吗?“
还是先来看看再说吧,说不定有些新的思维在里面呢?

上图是对最简单的sql语句的重新标注,SELECT表示是一种具体的操作,即查询数据,”f1,f2,f3"表示返回的结果,tableX是数据源,condition部分是查询条件。有没有发觉SQL表达式中的顺序与常见的RDD处理逻辑其在表达的顺序上有差异。还是继续用图来表示不同吧。
SQL语句在分析执行过程中会经历下图所示的几个步骤
- 语法解析
- 操作绑定
- 优化执行策略
- 交付执行
语法解析
语法解析之后,会形成一棵语法树,如下图所示。树中的每个节点是执行的rule,整棵树称之为执行策略。
策略优化
形成上述的执行策略树还只是第一步,因为这个执行策略可以进行优化,所谓的优化就是对树中节点进行合并或是进行顺序上的调整。
以大家熟悉的join操作为例,下图给出一个join优化的示例。A JOIN B等同于B JOIN A,但是顺序的调整可能给执行的性能带来极大的影响,下图就是调整前后的对比图。
再举一例,一般来说尽可能的先实施聚合操作(Aggregate)然后再join
小结
上述一大通分析,希望达到的目的就两个。
- 语法解析之后生成一个执行策略树
- 执行策略树可以优化,优化的过程就是对树中节点进行合并或者顺序调整
有关SQL查询分析优化的具体过程,强烈推荐参考query optimizer deep dive系列文章
SQL在spark中的实现
有了上述内容的铺垫,想必你已经意识到Spark如果要很好的支持sql,势必也要完成,解析,优化,执行的三大过程。
整个SQL部分的代码,其大致分类如下图所示

- SqlParser生成LogicPlan Tree
- Analyzer和Optimizer将各种rule作用于LogicalPlan Tree
- 最终优化生成的LogicalPlan生成Spark RDD
- 最后将生成的RDD交由Spark执行
阶段1:生成LogicalPlan
在sql中引入了一种新的RDD,即SchemaRDD
且看SchemaRDD的构造函数
class SchemaRDD(@transient val sqlContext: SQLContext,@transient protected[spark] val logicalPlan: LogicalPlan)
构造函数中总共两入参一为SparkContext,另一个LogicalPlan。LogicalPlan又是如何生成的呢?
要回答这个问题,不得不回到整个问题的入口点sql函数,sql函数的定义如下
def sql(sqlText: String): SchemaRDD = {val result = new SchemaRDD(this, parseSql(sqlText))result.queryExecution.toRddresult}
parseSql(sqlText)负责生成LogicalPlan,parseSql就是SqlParser的一个实例。
SqlParser这一部分的代码要理解起来关键是要搞清楚StandardTokenParsers的调用规则,里面有一大堆的符号,如果不理解是什么意思,估计很难理清头绪。
由于apply函数可以不被显示调用,所以parseSql(sqlText)一句其实会隐式的调用SqlParser中的apply函数
def apply(input: String): LogicalPlan = {phrase(query)(new lexical.Scanner(input)) match {case Success(r, x) => rcase x => sys.error(x.toString)}}
最最最让人蛋疼的一行代码就是phrase(query)(new lexical.Scanner(input))这里了,翻译过来就是如果输入的input字符串符合Lexical中定义的规则,则继续使用query处理。
看一下query的定义是什么
protected lazy val query: Parser[LogicalPlan] =select * (UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) } |UNION ~ opt(DISTINCT) ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }) | insert
到了这里终于看到有LogicalPlan了,也就是说将普通的string转换成LogicalPlan在这里发生了。
query这段代码同时说明,在目前的spark sql中仅支持select和insert两种操作,至于delete, update暂不支持。
注:即便是到现在,估计你和当初一样对于SqlParser的使用还是一头雾水,不要紧,请参考ref[3]和[4]中的内容,至于那些稀奇古怪的符号到底是什么意思,请参考ref[5].
阶段2:QueryExecution
第一阶段,将string转换成为logicalplan tree,第二阶段将各种规则作用于LogicalPlan。
在第一阶段中展示的代码,哪一句会触发优化规则呢?是sql函数中的"result.queryExecution.toRdd",此处的queryExecution就是QueryExecution。这里又涉及到scala的一个语法糖问题。QueryExecution是一个抽象类,但却看到了下述的代码
protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =new this.QueryExecution { val logical = plan }
怎么可以创建抽象类的实例?我的世界坍塌了,呵呵。不要紧张,这在scala的世界是允许的,只不过scala是隐含的创建了一个QueryExecution的子类并初始化而已,java里的原则还是对的,人家背后有猫腻。
Ok,轮到阶段2中最重要的角色QueryExecution闪亮登场了
protected abstract class QueryExecution {def logical: LogicalPlanlazy val analyzed = analyzer(logical)lazy val optimizedPlan = optimizer(analyzed)lazy val sparkPlan = planner(optimizedPlan).next()lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)/** Internal version of the RDD. Avoids copies and has no schema */lazy val toRdd: RDD[Row] = executedPlan.execute()protected def stringOrError[A](f: => A): String =try f.toString catch { case e: Throwable => e.toString }def simpleString: String = stringOrError(executedPlan)override def toString: String =s"""== Logical Plan ==|${stringOrError(analyzed)}|== Optimized Logical Plan ==|${stringOrError(optimizedPlan)}|== Physical Plan ==|${stringOrError(executedPlan)}""".stripMargin.trimdef debugExec() = DebugQuery(executedPlan).execute().collect()}
三大步
- lazy val analyzed = analyzer(logical)
- lazy val optimizedPlan = optimizer(analyzed)
- lazy val sparkPlan = planner(optimizedPlan).next()
无论analyzer还是optimizer,它们都是RuleExecutor的子类,
RuleExecutor的默认处理函数是apply,对所有的子类都是一样的,RuleExecutor的apply函数定义如下,
def apply(plan: TreeType): TreeType = {var curPlan = planbatches.foreach { batch =>val batchStartPlan = curPlanvar iteration = 1var lastPlan = curPlanvar continue = true// Run until fix point (or the max number of iterations as specified in the strategy.while (continue) {curPlan = batch.rules.foldLeft(curPlan) {case (plan, rule) =>val result = rule(plan)if (!result.fastEquals(plan)) {logger.trace(s"""|=== Applying Rule ${rule.ruleName} ===|${sideBySide(plan.treeString, result.treeString).mkString("\n")}""".stripMargin)}result}iteration += 1if (iteration > batch.strategy.maxIterations) {logger.info(s"Max iterations ($iteration) reached for batch ${batch.name}")continue = false}if (curPlan.fastEquals(lastPlan)) {logger.trace(s"Fixed point reached for batch ${batch.name} after $iteration iterations.")continue = false}lastPlan = curPlan}if (!batchStartPlan.fastEquals(curPlan)) {logger.debug(s"""|=== Result of Batch ${batch.name} ===|${sideBySide(plan.treeString, curPlan.treeString).mkString("\n")}""".stripMargin)} else {logger.trace(s"Batch ${batch.name} has no effect.")}}curPlan}
对于RuleExecutor的子类来说,最主要的是定义自己的batches,来看analyzer中的batches是如何定义的
val batches: Seq[Batch] = Seq(Batch("MultiInstanceRelations", Once,NewRelationInstances),Batch("CaseInsensitiveAttributeReferences", Once,(if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*),Batch("Resolution", fixedPoint,ResolveReferences ::ResolveRelations ::NewRelationInstances ::ImplicitGenerate ::StarExpansion ::ResolveFunctions ::GlobalAggregates ::typeCoercionRules :_*),Batch("AnalysisOperators", fixedPoint,EliminateAnalysisOperators))
batch中定义了一系列的规则,这里再次出现语法糖问题。“如何理解::这个操作符”? ::表示cons的意思,即连接生成一个list.
Batch构造函数中需要指定一系列的Rule,像ResolveReferences就是Rule,有关Rule的代码就不一一分析了。
阶段3:LogicalPlan转换成Physical Plan
在阶段3最主要的代码就两行
- lazy val executePlan: SparkPlan = prepareForExecution(sparkPlan)
- lazy val toRdd: RDD[Row] = executedPlan.execute()
与LogicalPlan不同,SparkPlan最重要的区别就是有execute函数
针对Sparkplan的具体实现,又要分成UnaryNode, LeafNode和BinaryNode,简要来说即单目运算符操作,叶子结点,双目运算符操作。每个子类的具体实现可以自行参考源码。
阶段4: 触发RDD执行
RDD被触发真正执行的过程在看了前面几篇文章之后想来难不住你来,所有的所有都在这一行代码。
teenagers.map(p => "name:"+p(0)).foreach(println)
如果真的不明白,建议回头再读一下Spark Job的执行过程分析。
Hive on Spark运行环境搭建
安装概览
整体的安装过程分为以下几步
- 搭建Hadoop集群 (整个cluster由3台机器组成,一台作为Master,另两台作为Slave)
- 编译Spark 1.0,使其支持Hadoop 2.4.0和Hive
- 运行Hive on Spark的测试用例 (Spark和Hadoop Namenode运行在同一台机器)
Hadoop集群搭建
创建虚拟机
创建基于kvm的虚拟机,利用libvirt提供的图形管理界面,创建3台虚拟机,非常方便。内存和ip地址分配如下
- master 2G 192.168.122.102
- slave1 4G 192.168.122.103
- slave2 4G 192.168.122.104
在虚拟机上安装os的过程就略过了,我使用的是arch linux,os安装完成之后,确保以下软件也已经安装
- jdk
- openssh
创建用户组和用户
在每台机器上创建名为hadoop的用户组,添加名为hduser的用户,具体bash命令如下所示
groupadd hadoop
useradd -b /home -m -g hadoop hduser
passwd hduser
无密码登录
在启动slave机器上的datanode或nodemanager的时候需要输入用户名密码,为了避免每次都要输入密码,可以利用如下指令创建无密码登录。注意是从master到slave机器的单向无密码。
cd $HOME/.ssh
ssh-keygen -t dsa
将id_dsa.pub复制为authorized_keys,然后上传到slave1和slave2中的$HOME/.ssh目录
cp id_dsa.pub authorized_keys
#确保在slave1和slave2机器中,hduser的$HOME目录下已经创建好了.ssh目录
scp authorized_keys slave1:$HOME/.ssh
scp authorized_keys slave2:$HOME/.ssh
更改每台机器上的/etc/hosts
在组成集群的master, slave1和slave2中,向/etc/hosts文件添加如下内容
192.168.122.102 master
192.168.122.103 slave1
192.168.122.104 slave2
如果更改完成之后,可以在master上执行ssh slave1来进行测试,如果没有输入密码的过程就直接登录入slave1就说明上述的配置成功。
下载hadoop 2.4.0
以hduser身份登录master,执行如下指令
cd /home/hduser
wget http://mirror.esocc.com/apache/hadoop/common/hadoop-2.4.0/hadoop-2.4.0.tar.gz
mkdir yarn
tar zvxf hadoop-2.4.0.tar.gz -C yarn
修改hadoop配置文件
添加如下内容到.bashrc
export HADOOP_HOME=/home/hduser/yarn/hadoop-2.4.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
修改$HADOOP_HOME/libexec/hadoop-config.sh
在hadoop-config.sh文件开头处添加如下内容
export JAVA_HOME=/opt/java
$HADOOP_CONF_DIR/yarn-env.sh
在yarn-env.sh开头添加如下内容
export JAVA_HOME=/opt/java
export HADOOP_HOME=/home/hduser/yarn/hadoop-2.4.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
xml配置文件修改
文件1: $HADOOP_CONF_DIR/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.default.name</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/hduser/yarn/hadoop-2.4.0/tmp</value></property>
</configuration>
文件2: $HADOOP_CONF_DIR/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.permissions</name><value>false</value></property></configuration>
文件3: $HADOOP_CONF_DIR/mapred-site.xml
<?xml version="1.0"?>
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
文件4: $HADOOP_CONF_DIR/yarn-site.xml
<?xml version="1.0"?><configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8025</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.address</name><value>master:8040</value></property></configuration>
文件5: $HADOOP_CONF_DIR/slaves
在文件中添加如下内容
slave1
slave2
创建tmp目录
在$HADOOP_HOME下创建tmp目录
mkdir $HADOOP_HOME/tmp
复制yarn目录到slave1和slave2
刚才所作的配置文件更改发生在master机器上,将整个更改过的内容全部复制到slave1和slave2。
for target in slave1 slave2
do scp -r yarn $target:~/scp $HOME/.bashrc $target:~/
done
批量处理是不是很爽
格式化namenode
在master机器上对namenode进行格式化
bin/hadoop namenode -format
启动cluster集群
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemons.sh start datanode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemons.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
注意: daemon.sh表示只在本机运行,daemons.sh表示在所有的cluster节点上运行。
验证hadoop集群安装正确与否
跑一个wordcount示例,具体步骤不再列出,可参考本系列中的第11篇
编译Spark 1.0
Spark的编译还是很简单的,所有失败的原因大部分可以归结于所依赖的jar包无法正常下载。
为了让Spark 1.0支持hadoop 2.4.0和hive,请使用如下指令编译
SPARK_HADOOP_VERSION=2.4.0 SPARK_YARN=true SPARK_HIVE=true sbt/sbt assembly
如果一切顺利将会在assembly目录下生成 spark-assembly-1.0.0-SNAPSHOT-hadoop2.4.0.jar
创建运行包
编译之后整个$SPARK_HOME目录下所有的文件体积还是很大的,大概有两个多G。有哪些是运行的时候真正需要的呢,下面将会列出这些目录和文件。
- $SPARK_HOME/bin
- $SPARK_HOME/sbin
- $SPARK_HOME/lib_managed
- $SPARK_HOME/conf
- $SPARK_HOME/assembly/target/scala-2.10
将上述目录的内容复制到/tmp/spark-dist,然后创建压缩包
mkdir /tmp/spark-dist
for i in $SPARK_HOME/{bin,sbin,lib_managed,conf,assembly/target/scala-2.10}
do cp -r $i /tmp/spark-dist
done
cd /tmp/
tar czvf spark-1.0-dist.tar.gz spark-dist
上传运行包到master机器
将生成的运行包上传到master(192.168.122.102)
scp spark-1.0-dist.tar.gz hduser@192.168.122.102:~/
运行hive on spark测试用例
经过上述重重折磨,终于到了最为紧张的时刻了。
以hduser身份登录master机,解压spark-1.0-dist.tar.gz
#after login into the master as hduser
tar zxvf spark-1.0-dist.tar.gz
cd spark-dist
更改conf/spark-env.sh
export SPARK_LOCAL_IP=127.0.0.1
export SPARK_MASTER_IP=127.0.0.1
运行最简单的example
用bin/spark-shell指令启动shell之后,运行如下scala代码
val sc: SparkContext // An existing SparkContext.
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)// Importing the SQL context gives access to all the public SQL functions and implicit conversions.
import hiveContext._hql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
hql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")// Queries are expressed in HiveQL
hql("FROM src SELECT key, value").collect().foreach(println)
如果一切顺利,最后一句hql会返回key及value
数据模型(Data Model)
Hive所有的数据都存在HDFS中,在Hive中有以下几种数据模型
- Tables(表) table和关系型数据库中的表是相对应的,每个表都有一个对应的hdfs目录,表中的数据经序列化后存储在该目录,Hive同时支持表中的数据存储在其它类型的文件系统中,如NFS或本地文件系统
- 分区(Partitions) Hive中的分区起到的作用有点类似于RDBMS中的索引功能,每个Partition都有一个对应的目录,这样在查询的时候,可以减少数据规模
- 桶(buckets) 即使将数据按分区之后,每个分区的规模有可能还是很大,这个时候,按照关键字的hash结果将数据分成多个buckets,每个bucket对应于一个文件
Query Language
HiveQL是Hive支持的类似于SQL的查询语言。HiveQL大体可以分成下面两种类型
- DDL(data definition language) 比如创建数据库(create database),创建表(create table),数据库和表的删除
- DML(data manipulation language) 数据的添加,查询
- UDF(user defined function) Hive还支持用户自定义查询函数
Hive architecture
hive的整体框架图如下图所示

由上图可以看出,Hive的整体架构可以分成以下几大部分
- 用户接口 支持CLI, JDBC和Web UI
- Driver Driver负责将用户指令翻译转换成为相应的MapReduce Job
- MetaStore 元数据存储仓库,像数据库和表的定义这些内容就属于元数据这个范畴,默认使用的是Derby存储引擎
HiveQL执行过程
HiveQL的执行过程如下所述
- parser 将HiveQL解析为相应的语法树
- Semantic Analyser 语义分析
- Logical Plan Generating 生成相应的LogicalPlan
- Query Plan Generating
- Optimizer
最终生成MapReduce的Job,交付给Hadoop的MapReduce计算框架具体运行。
Hive实例
最好的学习就是实战,Hive这一小节还是以一个具体的例子来结束吧。
前提条件是已经安装好hadoop,具体安装可以参考源码走读11或走读9
step 1: 创建warehouse
warehouse用来存储raw data
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
step 2: 启动hive cli
$ export HIVE_HOME=<hive-install-dir>
$ $HIVE_HOME/bin/hive
step 3: 创建表
创建表,首先将schema数据写入到metastore,另一件事情就是在warehouse目录下创建相应的子目录,该子目录以表的名称命名
CREATE TABLE u_data (userid INT,movieid INT,rating INT,unixtime STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
step 4: 导入数据
导入的数据会存储在step 3中创建的表目录下
LOAD DATA LOCAL INPATH '/u.data'
OVERWRITE INTO TABLE u_data;
step 5: 查询
SELECT COUNT(*) FROM u_data;
hiveql on Spark
Q: 上一章节花了大量的篇幅介绍了hive由来,框架及hiveql执行过程。那这些东西跟我们标题中所称的hive on spark有什么关系呢?
Ans: Hive的整体解决方案很不错,但有一些地方还值得改进,其中之一就是“从查询提交到结果返回需要相当长的时间,查询耗时太长”。之所以查询时间很长,一个主要的原因就是因为Hive原生是基于MapReduce的,哪有没有办法提高呢。您一定想到了,“不是生成MapReduce Job,而是生成Spark Job”, 充分利用Spark的快速执行能力来缩短HiveQl的响应时间。
下图是Spark 1.0中所支持的lib库,SQL是其唯一新添加的lib库,可见SQL在Spark 1.0中的地位之重要。

HiveContext
HiveContext是Spark提供的用户接口,HiveContext继承自SqlContext。
让我们回顾一下,SqlContext中牵涉到的类及其间的关系如下图所示,具体分析过程参见本系列中的源码走读之11。
既然是继承自SqlContext,那么我们将普通sql与hiveql分析执行步骤做一个对比,可以得到下图。

有了上述的比较,就能抓住源码分析时需要把握的几个关键点
- Entrypoint HiveContext.scala
- QueryExecution HiveContext.scala
- parser HiveQl.scala
- optimizer
数据
使用到的数据有两种
- Schema Data 像数据库的定义和表的结构,这些都存储在MetaStore中
- Raw data 即要分析的文件本身
Entrypoint
hiveql是整个的入口点,而hql是hiveql的缩写形式。
def hiveql(hqlQuery: String): SchemaRDD = {val result = new SchemaRDD(this, HiveQl.parseSql(hqlQuery))// We force query optimization to happen right away instead of letting it happen lazily like// when using the query DSL. This is so DDL commands behave as expected. This is only// generates the RDD lineage for DML queries, but does not perform any execution.result.queryExecution.toRddresult}
上述hiveql的定义与sql的定义几乎一模一样,唯一的不同是sql中使用parseSql的结果作为SchemaRDD的入参而hiveql中使用HiveQl.parseSql作为SchemaRdd的入参
HiveQL, parser
parseSql的函数定义如代码所示,解析过程中将指令分成两大类
- nativecommand 非select语句,这类语句的特点是执行时间不会因为条件的不同而有很大的差异,基本上都能在较短的时间内完成
- 非nativecommand 主要是select语句
def parseSql(sql: String): LogicalPlan = {try {if (sql.toLowerCase.startsWith("set")) {NativeCommand(sql)} else if (sql.toLowerCase.startsWith("add jar")) {AddJar(sql.drop(8))} else if (sql.toLowerCase.startsWith("add file")) {AddFile(sql.drop(9))} else if (sql.startsWith("dfs")) {DfsCommand(sql)} else if (sql.startsWith("source")) {SourceCommand(sql.split(" ").toSeq match { case Seq("source", filePath) => filePath })} else if (sql.startsWith("!")) {ShellCommand(sql.drop(1))} else {val tree = getAst(sql)if (nativeCommands contains tree.getText) {NativeCommand(sql)} else {nodeToPlan(tree) match {case NativePlaceholder => NativeCommand(sql)case other => other}}}} catch {case e: Exception => throw new ParseException(sql, e)case e: NotImplementedError => sys.error(s"""|Unsupported language features in query: $sql|${dumpTree(getAst(sql))}""".stripMargin)}}
哪些指令是nativecommand呢,答案在HiveQl.scala中的nativeCommands变量,列表很长,代码就不一一列出。
对于非nativeCommand,最重要的解析函数就是nodeToPlan
toRdd
Spark对HiveQL所做的优化主要体现在Query相关的操作,其它的依然使用Hive的原生执行引擎。
在logicalPlan到physicalPlan的转换过程中,toRdd最关键的元素
override lazy val toRdd: RDD[Row] =analyzed match {case NativeCommand(cmd) =>val output = runSqlHive(cmd)if (output.size == 0) {emptyResult} else {val asRows = output.map(r => new GenericRow(r.split("\t").asInstanceOf[Array[Any]]))sparkContext.parallelize(asRows, 1)}case _ =>executedPlan.execute().map(_.copy())}
native command的执行流程
由于native command是一些非耗时的操作,直接使用Hive中原有的exeucte engine来执行即可。这些command的执行示意图如下

analyzer
HiveTypeCoercion
val typeCoercionRules =List(PropagateTypes, ConvertNaNs, WidenTypes, PromoteStrings, BooleanComparisons, BooleanCasts,StringToIntegralCasts, FunctionArgumentConversion)
optimizer
PreInsertionCasts存在的目的就是确保在数据插入执行之前,相应的表已经存在。
override lazy val optimizedPlan =optimizer(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))此处要注意的是catalog的用途,catalog是HiveMetastoreCatalog的实例。
HiveMetastoreCatalog是Spark中对Hive Metastore访问的wrapper。HiveMetastoreCatalog通过调用相应的Hive Api可以获得数据库中的表及表的分区,也可以创建新的表和分区。

HiveMetastoreCatalog
HiveMetastoreCatalog中会通过hive client来访问metastore中的元数据,使用了大量的Hive Api。其中包括了广为人知的deSer library。
以CreateTable函数为例说明对Hive Library的依赖。
def createTable(databaseName: String,tableName: String,schema: Seq[Attribute],allowExisting: Boolean = false): Unit = {val table = new Table(databaseName, tableName)val hiveSchema =schema.map(attr => new FieldSchema(attr.name, toMetastoreType(attr.dataType), ""))table.setFields(hiveSchema)val sd = new StorageDescriptor()table.getTTable.setSd(sd)sd.setCols(hiveSchema)// TODO: THESE ARE ALL DEFAULTS, WE NEED TO PARSE / UNDERSTAND the output specs.sd.setCompressed(false)sd.setParameters(Map[String, String]())sd.setInputFormat("org.apache.hadoop.mapred.TextInputFormat")sd.setOutputFormat("org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat")val serDeInfo = new SerDeInfo()serDeInfo.setName(tableName)serDeInfo.setSerializationLib("org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe")serDeInfo.setParameters(Map[String, String]())sd.setSerdeInfo(serDeInfo)try client.createTable(table) catch {case e: org.apache.hadoop.hive.ql.metadata.HiveExceptionif e.getCause.isInstanceOf[org.apache.hadoop.hive.metastore.api.AlreadyExistsException] &&allowExisting => // Do nothing.}}
实验
结合源码,我们再对一个简单的例子作下说明。
可能你会想,既然spark也支持hql,那么我原先用hive cli创建的数据库和表用spark能不能访问到呢?答案或许会让你很纳闷,“在默认的配置下是不行的”。为什么?
Hive中的meta data采用的存储引擎是Derby,该存储引擎只能有一个访问用户。同一时刻只能有一个人访问,即便以同一用户登录访问也不行。针对这个局限,解决方法就是将metastore存储在mysql或者其它可以多用户访问的数据库中。
具体实例
- 创建表
- 导入数据
- 查询
- 删除表
在启动spark-shell之前,需要先设置环境变量HIVE_HOME和HADOOP_HOME.
启动spark-shell之后,执行如下代码
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)// Importing the SQL context gives access to all the public SQL functions and implicit conversions.
import hiveContext._hql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
hql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")// Queries are expressed in HiveQL
hql("FROM src SELECT key, value").collect().foreach(println)
hql("drop table src")
create操作会在/user/hive/warehouse/目录下创建src目录,可以用以下指令来验证
$$HADOOP_HOME/bin/hdfs dfs -ls /user/hive/warehouse/
drop表的时候,不仅metastore中相应的记录被删除,而且原始数据raw file本身也会被删除,即在warehouse目录下对应某个表的目录会被整体删除掉。
上述的create, load及query操作对metastore和raw data的影响可以用下图的表示

hive-site.xml
如果想对hive默认的配置作修改,可以使用hive-site.xml。
具体步骤如下
- 在$SPARK_HOME/conf目录下创建hive-site.xml
- 根据需要,添写相应的配置项的值,可以这样做,将$HIVE_HOME/conf目录下的hive-default.xml复制到$SPARK_HOME/conf,然后重命名为hive-site.xml
Sql新功能预告
为了进一步提升sql的执行速度,在Spark开发团队在发布完1.0之后,会通过codegen的方法来提升执行速度。codegen有点类似于jvm中的jit技术。充分利用了scala语言的特性。
前景分析
Spark目前还缺乏一个非常有影响力的应用,也就通常所说的killer application。SQL是Spark在寻找killer application方面所做的一个积极尝试,也是目前Spark上最有热度的一个话题,但通过优化Hive执行速度来吸引潜在Spark用户,该突破方向选择正确与否还有待市场证明。
Hive除了在执行速度上为人诟病之外,还有一个最大的问题就是多用户访问的问题,相较第一个问题,第二个问题来得更为致命。无论是Facebook在Hive之后推出的Presto还是Cloudera推出的Impala都是针对第二问题提出的解决方案,目前都已经取得的了巨大优势。
Graphx实现剖析
图论简介
图的组成
离散数学中非常重要的一个部分就是图论,下面是一个无向连通图

顶点(vertex)
上图中的A,B,C,D,E称为图的顶点。
边
顶点与顶点之间的连线称之为边。
图的数学表示
读大学的时候,一直没有想明白为什么要学劳什子的线性代数。直到这两天看《数学之美》一书时,才发觉,线性代数在一些计算机应用领域,那简直就是不可或缺啊。
我们比较容易理解的平面几何和立体几何(一个是二维,一个是三维),而线性代数解决的其实是一个高维问题,由于无法直觉的感受到,所以很难。如果想比较通俗的理解一下数学为什么有这么多的分支及其内在关联,强烈推荐读一下《数学桥 对高等数学的一次观赏之旅》。
在数学中,用什么来表示图呢,答案就是线性代数里面的矩阵,想想看,图的关联矩阵,图的邻接矩阵。总之就是矩阵啦,线性代数一下子有用了。下面是一个具体的例子。


图的并行化处理
刚才说到图可以用矩阵来表示,图的并行化问题在某种程度上就被转化为矩阵运算的并行化问题。
那么以矩阵的乘法为例,看看其是否可以并行化处理。
以矩阵 A X B 为例,说明并行化处理过程。

将上述的矩阵A和B划分为四个部分,如下图所示

首次对齐之后

子矩阵相乘

相乘之后,A的子矩阵左移,B的子矩阵上移

计算结果合并

图的并行化处理框架,从Pregel说起
上一节的重点有两点
- 图用矩阵来表示,对图的运算就是矩阵的运算
- 矩阵乘法运算可以并行化,动态演示其并行化的原理
你说ok,我明白了。哪有没有一种合适的并行化处理框架可以用来进行图的计算呢,那你肯定想到了MapReduce。
MapReduce尽管也是一个不错的并行化处理框架,但在图计算方面,有许多缺点,主要是计算的中间过程需要存储到硬盘,效率很低。
Google针对图的并行处理,专门提出了一个了不起的框架Pregel。其执行时的动态视图如下所示。
Pregel有如下优点
- 级联可扩性好 scalability
- 容错性强
- 能够很好的表示各种图的常用算法
Pregel的计算模型
计算模型如下图所示,重要的有三个
- 作用于每个顶点的处理逻辑 vertexProgram
- 消息发送,用于相邻节点间的通讯 sendMessage
- 消息合并逻辑 messageCombining

Pregel在Spark中的实现
非常感谢你能坚持看到现在,这篇博客内容很多,有点难。我想还是上一幅图将其内在逻辑整一下再继续说下去。

该图要表示的意思是这样的,Graphx利用了Spark这样了一个并行处理框架来实现了图上的一些可并行化执行的算法。
本篇博客要表达的意思就是上面加红的这句话,请诸位看官仔细理解。
- 算法是否能够并行化与Spark本身无关
- 算法并行化与否的本身,需要通过数学来证明
- 已经证明的可并行化算法,利用Spark来实现会是一个错的选择,因为Graphx支持pregel的图计算模型
Graphx中的重要概念
Graph
毫无疑问,图本身是graphx中一个非常重要的概念。
成员变量
graph中重要的成员变量分别为
- vertices
- edges
- triplets
为什么要引入triplets呢,主要是和Pregel这个计算模型相关,在triplets中,同时记录着edge和vertex. 具体代码就不罗列了。
成员函数
函数分成几大类
- 对所有顶点或边的操作,但不改变图结构本身,如mapEdges, mapVertices
- 子图,类似于集合操作中的filter subGraph
- 图的分割,即paritition操作,这个对于Spark计算来说,很关键,正是因为有了不同的Partition,才有了并行处理的可能, 不同的PartitionStrategy,其收益不同。最容易想到的就是利用Hash来将整个图分成多个区域。
- outerJoinVertices 顶点的外连接操作
图的运算和操作 GraphOps
图的常用算法是集中抽象到GraphOps这个类中,在Graph里作了隐式转换,将Graph转换为GraphOps
implicit def graphToGraphOps[VD: ClassTag, ED: ClassTag](g: Graph[VD, ED]): GraphOps[VD, ED] = g.ops
支持的操作如下
- collectNeighborIds
- collectNeighbors
- collectEdges
- joinVertices
- filter
- pickRandomVertex
- pregel
- pageRank
- staticPageRank
- connectedComponents
- triangleCount
- stronglyConnectedComponents
RDD
RDD是Spark体系的核心,那么Graphx中引入了哪些新的RDD呢,有俩,分别为
- VertexRDD
- EdgeRDD
较之EdgeRdd,VertexRDD更为重要,其上的操作也很多,主要集中于Vertex之上属性的合并,说到合并就不得不扯到关系代数和集合论,所以在VertexRdd中能看到许多类似于sql中的术语,如
- leftJoin
- innerJoin
至于leftJoin, innerJoin, outerJoin的区别,建议谷歌一下,不再赘述。
Graphx场景分析
图的存储和加载
在进行数学计算的时候,图用线性代数中的矩阵来表示,那么如何进行存储呢?
学数据结构的时候,老师肯定说过好多的办法,不再啰嗦了。
不过在大数据的环境下,如果图很巨大,表示顶点和边的数据不足以放在一个文件中怎么办? 用HDFS
加载的时候,一台机器的内存不足以容下怎么办? 延迟加载,在真正需要数据时,将数据分发到不同机器中,采用级联方式。
一般来说,我们会将所有与顶点相关的内容保存在一个文件中vertexFile,所有与边相关的信息保存在另一个文件中edgeFile。
生成某一个具体的图时,用edge就可以表示图中顶点的关联关系,同时图的结构也表示出来了。
GraphLoader
graphLoader是graphx中专门用于图的加载和生成,最重要的函数就是edgeListFile,定义如下。
def edgeListFile(sc: SparkContext,path: String,canonicalOrientation: Boolean = false,minEdgePartitions: Int = 1,edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[Int, Int] ={val startTime = System.currentTimeMillis// Parse the edge data table directly into edge partitionsval lines = sc.textFile(path, minEdgePartitions).coalesce(minEdgePartitions)val edges = lines.mapPartitionsWithIndex { (pid, iter) =>val builder = new EdgePartitionBuilder[Int, Int]iter.foreach { line =>if (!line.isEmpty && line(0) != '#') {val lineArray = line.split("\\s+")if (lineArray.length < 2) {logWarning("Invalid line: " + line)}val srcId = lineArray(0).toLongval dstId = lineArray(1).toLongif (canonicalOrientation && srcId > dstId) {builder.add(dstId, srcId, 1)} else {builder.add(srcId, dstId, 1)}}}Iterator((pid, builder.toEdgePartition))}.persist(edgeStorageLevel).setName("GraphLoader.edgeListFile - edges (%s)".format(path))edges.count()logInfo("It took %d ms to load the edges".format(System.currentTimeMillis - startTime))GraphImpl.fromEdgePartitions(edges, defaultVertexAttr = 1, edgeStorageLevel = edgeStorageLevel,vertexStorageLevel = vertexStorageLevel)} // end of edgeListFile
应用举例之PageRank
什么是PageRank
PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。它由Larry Page 和 Sergey Brin在20世纪90年代后期发明。PageRank实现了将链接价值概念作为排名因素。
PageRank将对页面的链接看成投票,指示了重要性。
pageRank的核心思想
”在互联网上,如果一个网页被很多其它网页所链接,说明它受到普遍的承认和依赖,那么它的排名就很高。“ (摘自数学之美第10章)
你说这也太简单了吧,不是跟没说一个样吗,怎么用数学来表示呢?
呵呵,起初我也这么想的,后来多看了几遍之后,明白了一点点。分析步骤用文字表述如下,
- 网页和网页之间的关系用图来表示
- 网页A和网页B之间的连接关系表示任意一个用户从网页A到转到网页B的可能性(概率)
- 所有网页的排名用一维向量来B来表示
所有网页之间的连接用矩阵A来表示,所有网页排名用B来表示。

pageRank如何进行并行化
好了,上面的数学阐述说明了“网页排名的计算可以最终抽象为矩阵相乘”,而在开始的时候已经证明过矩阵相乘可以并行化处理。
理论研究结束了,接下来的就是工程实现了,借用Pregel模型,PageRank中定义的各主要函数分别如下。
vertexProgram
def vertexProgram(id: VertexId, attr: (Double, Double), msgSum: Double): (Double, Double) = {val (oldPR, lastDelta) = attrval newPR = oldPR + (1.0 - resetProb) * msgSum(newPR, newPR - oldPR)}
sendMessage
def sendMessage(edge: EdgeTriplet[(Double, Double), Double]) = {if (edge.srcAttr._2 > tol) {Iterator((edge.dstId, edge.srcAttr._2 * edge.attr))} else {Iterator.empty}}
messageCombiner
def messageCombiner(a: Double, b: Double): Double = a + b
一点点启示

通过pageRank这个例子,我们能够搞清楚如何将平素学习的数学理论用以解决实际问题。
“学习的东西总是有价值的,至于用的上用不上,全靠造化了”
完整代码
// Connect to the Spark cluster
val sc = new SparkContext("spark://master.amplab.org", "research")
// Load my user data and parse into tuples of user id and attribute list
val users = (sc.textFile("graphx/data/users.txt").map(line => line.split(",")).map( parts => (parts.head.toLong, parts.tail) ))
// Parse the edge data which is already in userId -> userId format
val followerGraph = GraphLoader.edgeListFile(sc, "graphx/data/followers.txt")
// Attach the user attributes
val graph = followerGraph.outerJoinVertices(users) {case (uid, deg, Some(attrList)) => attrList// Some users may not have attributes so we set them as emptycase (uid, deg, None) => Array.empty[String]
}
// Restrict the graph to users with usernames and names
val subgraph = graph.subgraph(vpred = (vid, attr) => attr.size == 2)
// Compute the PageRank
val pagerankGraph = subgraph.pageRank(0.001)
// Get the attributes of the top pagerank users
val userInfoWithPageRank = subgraph.outerJoinVertices(pagerankGraph.vertices) {case (uid, attrList, Some(pr)) => (pr, attrList.toList)case (uid, attrList, None) => (0.0, attrList.toList)
}println(userInfoWithPageRank.vertices.top(5)(Ordering.by(_._2._1)).mkString("\n"))
小结
本篇讲来讲去就在强调一个问题,Spark是一个分布式并行计算框架。能不能用Spark,其实大体取决于问题的数学模型本身,如果可以并行化处理,则用之,切不可削足适履。
另一个用张图来总结一下提到的数学知识吧。

下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的。
基本概念和原则
首先,要搞清楚Spark的几个基本概念和原则,否则系统的性能调优无从谈起:
- 每一台host上面可以并行N个worker,每一个worker下面可以并行M个executor,task们会被分配到executor上面 去执行。Stage指的是一组并行运行的task,stage内部是不能出现shuffle的,因为shuffle的就像篱笆一样阻止了并行task的运 行,遇到shuffle就意味着到了stage的边界。
- CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很 常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时 候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来 增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。
- partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。 在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行 map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片 的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个 partition参数来显式控制具体的分片数量。
- 上面这两条原理上看起来很简单,但是却非常重要,根据硬件和任务的情况选择不同的取值。想要取一个放之四海而皆准的配置是不现实的。看这样几个例 子:(1)实践中跑的EMR Spark job,有的特别慢,查看CPU利用率很低,我们就尝试减少每个executor占用CPU core的数量,增加并行的executor数量,同时配合增加分片,整体上增加了CPU的利用率,加快数据处理速度。(2)发现某job很容易发生内存 溢出,我们就增大分片数量,从而减少了每片数据的规模,同时还减少并行的executor数量,这样相同的内存资源分配给数量更少的executor,相 当于增加了每个task的内存分配,这样运行速度可能慢了些,但是总比OOM强。(3)数据量特别少,有大量的小文件生成,就减少文件分片,没必要创建那 么多task,这种情况,如果只是最原始的input比较小,一般都能被注意到;但是,如果是在运算过程中,比如应用某个reduceBy或者某个 filter以后,数据大量减少,这种低效情况就很少被留意到。
- 最后再补充一点,随着参数和配置的变化,性能的瓶颈是变化的,在分析问题的时候不要忘记。例如在每台机器上部署的executor数量增加的时 候,性能一开始是增加的,同时也观察到CPU的平均使用率在增加;但是随着单台机器上的executor越来越多,性能下降了,因为随着executor 的数量增加,被分配到每个executor的内存数量减小,在内存里直接操作的越来越少,spill over到磁盘上的数据越来越多,自然性能就变差了。
下面给这样一个直观的例子,当前总的cpu利用率并不高:
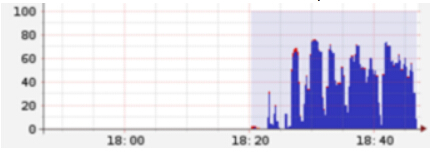
但是经过根据上述原则的的调整之后,可以显著发现cpu总利用率增加了:
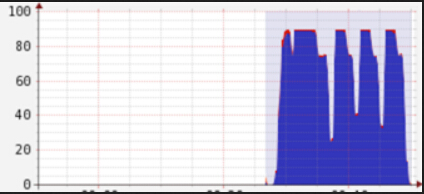
其次,涉及性能调优我们经常要改配置,在Spark里面有三种常见的配置方式,虽然有些参数的配置是可以互相替代,但是作为最佳实践,还是需要遵循不同的情形下使用不同的配置:
- 设置环境变量,这种方式主要用于和环境、硬件相关的配置;
- 命令行参数,这种方式主要用于不同次的运行会发生变化的参数,用双横线开头;
- 代码里面(比如Scala)显式设置(SparkConf对象),这种配置通常是application级别的配置,一般不改变。
举一个配置的具体例子。slave、worker和executor之间的比例调整。我们经常需要调整并行的executor的数量,那么简单说有两种方式:
- 1. 每个worker内始终跑一个executor,但是调整单台slave上并行的worker的数量。比如,SPARK_WORKER_INSTANCES可以设置每个slave的worker的数量,但是在改变这个参数的时候,比如改成2,一定要相应设置SPARK_WORKER_CORES的值,让每个worker使用原有一半的core,这样才能让两个worker一同工作;
- 2. 每台slave内始终只部署一个worker,但是worker内部署多个executor。我们是在YARN框架下采用这个调整来实现executor数量改变的,一种典型办法是,一个host只跑一个worker,然后配置spark.executor.cores为host上CPU core的N分之一,同时也设置spark.executor.memory为host上分配给Spark计算内存的N分之一,这样这个host上就能够启动N个executor。
有的配置在不同的MR框架/工具下是不一样的,比如YARN下有的参数的默认取值就不同,这点需要注意。
明确这些基础的事情以后,再来一项一项看性能调优的要点。
内存
Memory Tuning,Java对象会占用原始数据2~5倍甚至更多的空间。最好的检测对象内存消耗的办法就是创建RDD,然后放到cache里面去,然后在UI 上面看storage的变化;当然也可以使用SizeEstimator来估算。使用-XX:+UseCompressedOops选项可以压缩指针(8 字节变成4字节)。在调用collect等等API的时候也要小心——大块数据往内存拷贝的时候心里要清楚。内存要留一些给操作系统,比如20%,这里面 也包括了OS的buffer cache,如果预留得太少了,会见到这样的错误:
“Required executor memory (235520+23552 MB) is above the max threshold (241664 MB) of this cluster! Please increase the value of ‘yarn.scheduler.maximum-allocation-mb’.”
或者干脆就没有这样的错误,但是依然有因为内存不足导致的问题,有的会有警告,比如这个:
“16/01/13 23:54:48 WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory”
有的时候连这样的日志都见不到,而是见到一些不清楚原因的executor丢失信息:
“Exception in thread “main” org.apache.spark.SparkException: Job aborted due to stage failure: Task 12 in stage 17.0 failed 4 times, most recent failure: Lost task 12.3 in stage 17.0 (TID 1257, ip-10-184-192-56.ec2.internal): ExecutorLostFailure (executor 79 lost)”
Reduce Task的内存使用。在某些情况下reduce task特别消耗内存,比如当shuffle出现的时候,比如sortByKey、groupByKey、reduceByKey和join等,要在内存 里面建立一个巨大的hash table。其中一个解决办法是增大level of parallelism,这样每个task的输入规模就相应减小。另外,注意shuffle的内存上限设置,有时候有足够的内存,但是shuffle内存 不够的话,性能也是上不去的。我们在有大量数据join等操作的时候,shuffle的内存上限经常配置到executor的50%。
注意原始input的大小,有很多操作始终都是需要某类全集数据在内存里面完成的,那么并非拼命增加parallelism和partition的 值就可以把内存占用减得非常小的。我们遇到过某些性能低下甚至OOM的问题,是改变这两个参数所难以缓解的。但是可以通过增加每台机器的内存,或者增加机 器的数量都可以直接或间接增加内存总量来解决。
在选择EC2机器类型的时候,要明确瓶颈(可以借由测试来明确),比如我们遇到的情况就是使用r3.8 xlarge和c3.8 xlarge选择的问题,运算能力相当,前者比后者贵50%,但是内存是后者的5倍。
另外,有一些RDD的API,比如cache,persist,都会把数据强制放到内存里面,如果并不明确这样做带来的好处,就不要用它们。
CPU
Level of Parallelism。指定它以后,在进行reduce类型操作的时候,默认partition的数量就被指定了。这个参数在实际工程中通常是必不可少的,一般都要根据input和每个executor内存的大小来确定。设置level of parallelism或者属性spark.default.parallelism来改变并行级别,通常来说,每一个CPU核可以分配2~3个task。
CPU core的访问模式是共享还是独占。即CPU核是被同一host上的executor共享还是瓜分并独占。比如,一台机器上共有32个CPU core的资源,同时部署了两个executor,总内存是50G,那么一种方式是配置spark.executor.cores为 16,spark.executor.memory为20G,这样由于内存的限制,这台机器上会部署两个executor,每个都使用20G内存,并且各 使用“独占”的16个CPU core资源;而在内存资源不变的前提下,也可以让这两个executor“共享”这32个core。根据我的测试,独占模式的性能要略好与共享模式。
GC调优。打印GC信息:-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps。要记得默认60%的executor内存可以被用来作为RDD的缓存,因此只有40%的内存可以被用来作为对象创建的空间, 这一点可以通过设置spark.storage.memoryFraction改变。如果有很多小对象创建,但是这些对象在不完全GC的过程中就可以回 收,那么增大Eden区会有一定帮助。如果有任务从HDFS拷贝数据,内存消耗有一个简单的估算公式——比如HDFS的block size是64MB,工作区内有4个task拷贝数据,而解压缩一个block要增大3倍大小,那么估算内存消耗就是:4*3*64MB。另外,工作中遇 到过这样的一个问题:GC默认情况下有一个限制,默认是GC时间不能超过2%的CPU时间,但是如果大量对象创建(在Spark里很容易出现,代码模式就 是一个RDD转下一个RDD),就会导致大量的GC时间,从而出现“OutOfMemoryError: GC overhead limit exceeded”,对于这个,可以通过设置-XX:-UseGCOverheadLimit关掉它。
序列化和传输
Data Serialization,默认使用的是Java Serialization,这个程序员最熟悉,但是性能、空间表现都比较差。还有一个选项是Kryo Serialization,更快,压缩率也更高,但是并非支持任意类的序列化。在Spark UI上能够看到序列化占用总时间开销的比例,如果这个比例高的话可以考虑优化内存使用和序列化。
Broadcasting Large Variables。在task使用静态大对象的时候,可以把它broadcast出去。Spark会打印序列化后的大小,通常来说如果它超过20KB就值得这么做。有一种常见情形是,一个大表join一个小表,把小表broadcast后,大表的数据就不需要在各个node之间疯跑,安安静静地呆在本地等小表broadcast过来就好了。
Data Locality。数据和代码要放到一起才能处理,通常代码总比数据要小一些,因此把代码送到各处会更快。Data Locality是数据和处理的代码在屋里空间上接近的程度:PROCESS_LOCAL(同一个JVM)、NODE_LOCAL(同一个node,比如 数据在HDFS上,但是和代码在同一个node)、NO_PREF、RACK_LOCAL(不在同一个server,但在同一个机架)、ANY。当然优先 级从高到低,但是如果在空闲的executor上面没有未处理数据了,那么就有两个选择:
- (1)要么等如今繁忙的CPU闲下来处理尽可能“本地”的数据,
- (2)要么就不等直接启动task去处理相对远程的数据。
默认当这种情况发生Spark会等一会儿(spark.locality),即策略(1),如果繁忙的CPU停不下来,就会执行策略(2)。
代码里对大对象的引用。在task里面引用大对象的时候要小心,因为它会随着task序列化到每个节点上去,引发性能问题。只要序列化的过程不抛出 异常,引用对象序列化的问题事实上很少被人重视。如果,这个大对象确实是需要的,那么就不如干脆把它变成RDD好了。绝大多数时候,对于大对象的序列化行 为,是不知不觉发生的,或者说是预期之外的,比如在我们的项目中有这样一段代码:
- rdd.map(r => {
- println(BackfillTypeIndex)
- })
其实呢,它等价于这样:
- rdd.map(r => {
- println(this.BackfillTypeIndex)
- })
不要小看了这个this,有时候它的序列化是非常大的开销。
对于这样的问题,一种最直接的解决方法就是:
- val dereferencedVariable = this.BackfillTypeIndex
- rdd.map(r => println(dereferencedVariable)) // "this" is not serialized
相关地,注解@transient用来标识某变量不要被序列化,这对于将大对象从序列化的陷阱中排除掉是很有用的。另外,注意class之间的继承层级关系,有时候一个小的case class可能来自一棵大树。
文件读写
文件存储和读取的优化。比如对于一些case而言,如果只需要某几列,使用rcfile和parquet这样的格式会大大减少文件读取成本。再有就 是存储文件到S3上或者HDFS上,可以根据情况选择更合适的格式,比如压缩率更高的格式。另外,特别是对于shuffle特别多的情况,考虑留下一定量 的额外内存给操作系统作为操作系统的buffer cache,比如总共50G的内存,JVM最多分配到40G多一点。
文件分片。比如在S3上面就支持文件以分片形式存放,后缀是partXX。使用coalesce方法来设置分成多少片,这个调整成并行级别或者其整 数倍可以提高读写性能。但是太高太低都不好,太低了没法充分利用S3并行读写的能力,太高了则是小文件太多,预处理、合并、连接建立等等都是时间开销啊, 读写还容易超过throttle。
任务
Spark的Speculation。通过设置spark.speculation等几个相关选项,可以让Spark在发现某些task执行特别慢的时候,可以在不等待完成的情况下被重新执行,最后相同的task只要有一个执行完了,那么最快执行完的那个结果就会被采纳。
减少Shuffle。其实Spark的计算往往很快,但是大量开销都花在网络和IO上面,而shuffle就是一个典型。举个例子,如果(k, v1) join (k, v2) => (k, v3),那么,这种情况其实Spark是优化得非常好的,因为需要join的都在一个node的一个partition里面,join很快完成,结果也是 在同一个node(这一系列操作可以被放在同一个stage里面)。但是如果数据结构被设计为(obj1) join (obj2) => (obj3),而其中的join条件为obj1.column1 == obj2.column1,这个时候往往就被迫shuffle了,因为不再有同一个key使得数据在同一个node上的强保证。在一定要shuffle的情况下,尽可能减少shuffle前的数据规模,比如这个避免groupByKey的例子。下面这个比较的图片来自Spark Summit 2013的一个演讲,讲的是同一件事情:

Repartition。运算过程中数据量时大时小,选择合适的partition数量关系重大,如果太多partition就导致有很多小任务和空任务产生;如果太少则导致运算资源没法充分利用,必要时候可以使用repartition来调整,不过它也不是没有代价的,其中一个最主要代价就是shuffle。 再有一个常见问题是数据大小差异太大,这种情况主要是数据的partition的key其实取值并不均匀造成的(默认使用 HashPartitioner),需要改进这一点,比如重写hash算法。测试的时候想知道partition的数量可以调用 rdd.partitions().size()获知。
Task时间分布。关注Spark UI,在Stage的详情页面上,可以看得到shuffle写的总开销,GC时间,当前方法栈,还有task的时间花费。如果你发现task的时间花费分 布太散,就是说有的花费时间很长,有的很短,这就说明计算分布不均,需要重新审视数据分片、key的hash、task内部的计算逻辑等等,瓶颈出现在耗 时长的task上面。

重用资源。有的资源申请开销巨大,而且往往相当有限,比如建立连接,可以考虑在partition建立的时候就创建好(比如使用mapPartition方法),这样对于每个partition内的每个元素的操作,就只要重用这个连接就好了,不需要重新建立连接。
开发调优
调优概述
Spark性能优化的第一步,就是要在开发Spark作业的过程中注意和应用一些性能优化的基本原则。开发调优,就是要让大家了解以下一些 Spark基本开发原则,包括:RDD lineage设计、算子的合理使用、特殊操作的优化等。在开发过程中,时时刻刻都应该注意以上原则,并将这些原则根据具体的业务以及实际的应用场景,灵 活地运用到自己的Spark作业中。
原则一:避免创建重复的RDD
通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD;接着对这个RDD执行某 个算子操作,然后得到下一个RDD;以此类推,循环往复,直到计算出最终我们需要的结果。在这个过程中,多个RDD会通过不同的算子操作(比如map、 reduce等)串起来,这个“RDD串”,就是RDD lineage,也就是“RDD的血缘关系链”。
我们在开发过程中要注意:对于同一份数据,只应该创建一个RDD,不能创建多个RDD来代表同一份数据。
一些Spark初学者在刚开始开发Spark作业时,或者是有经验的工程师在开发RDD lineage极其冗长的Spark作业时,可能会忘了自己之前对于某一份数据已经创建过一个RDD了,从而导致对于同一份数据,创建了多个RDD。这就 意味着,我们的Spark作业会进行多次重复计算来创建多个代表相同数据的RDD,进而增加了作业的性能开销。
一个简单的例子
- // 需要对名为“hello.txt”的HDFS文件进行一次map操作,再进行一次reduce操作。也就是说,需要对一份数据执行两次算子操作。
- // 错误的做法:对于同一份数据执行多次算子操作时,创建多个RDD。
- // 这里执行了两次textFile方法,针对同一个HDFS文件,创建了两个RDD出来,然后分别对每个RDD都执行了一个算子操作。
- // 这种情况下,Spark需要从HDFS上两次加载hello.txt文件的内容,并创建两个单独的RDD;第二次加载HDFS文件以及创建RDD的性能开销,很明显是白白浪费掉的。
- val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
- rdd1.map(...)
- val rdd2 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
- rdd2.reduce(...)
- // 正确的用法:对于一份数据执行多次算子操作时,只使用一个RDD。
- // 这种写法很明显比上一种写法要好多了,因为我们对于同一份数据只创建了一个RDD,然后对这一个RDD执行了多次算子操作。
- // 但是要注意到这里为止优化还没有结束,由于rdd1被执行了两次算子操作,第二次执行reduce操作的时候,还会再次从源头处重新计算一次rdd1的数据,因此还是会有重复计算的性能开销。
- // 要彻底解决这个问题,必须结合“原则三:对多次使用的RDD进行持久化”,才能保证一个RDD被多次使用时只被计算一次。
- val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt")
- rdd1.map(...)
- rdd1.reduce(...)
原则二:尽可能复用同一个RDD
除了要避免在开发过程中对一份完全相同的数据创建多个RDD之外,在对不同的数据执行算子操作时还要尽可能地复用一个RDD。比如说,有一个RDD 的数据格式是key-value类型的,另一个是单value类型的,这两个RDD的value数据是完全一样的。那么此时我们可以只使用key- value类型的那个RDD,因为其中已经包含了另一个的数据。对于类似这种多个RDD的数据有重叠或者包含的情况,我们应该尽量复用一个RDD,这样可 以尽可能地减少RDD的数量,从而尽可能减少算子执行的次数。
一个简单的例子
- // 错误的做法。
- // 有一个<Long, String>格式的RDD,即rdd1。
- // 接着由于业务需要,对rdd1执行了一个map操作,创建了一个rdd2,而rdd2中的数据仅仅是rdd1中的value值而已,也就是说,rdd2是rdd1的子集。
- JavaPairRDD<Long, String> rdd1 = ...
- JavaRDD rdd2 = rdd1.map(...)
- // 分别对rdd1和rdd2执行了不同的算子操作。
- rdd1.reduceByKey(...)
- rdd2.map(...)
- // 正确的做法。
- // 上面这个case中,其实rdd1和rdd2的区别无非就是数据格式不同而已,rdd2的数据完全就是rdd1的子集而已,却创建了两个rdd,并对两个rdd都执行了一次算子操作。
- // 此时会因为对rdd1执行map算子来创建rdd2,而多执行一次算子操作,进而增加性能开销。
- // 其实在这种情况下完全可以复用同一个RDD。
- // 我们可以使用rdd1,既做reduceByKey操作,也做map操作。
- // 在进行第二个map操作时,只使用每个数据的tuple._2,也就是rdd1中的value值,即可。
- JavaPairRDD<Long, String> rdd1 = ...
- rdd1.reduceByKey(...)
- rdd1.map(tuple._2...)
- // 第二种方式相较于第一种方式而言,很明显减少了一次rdd2的计算开销。
- // 但是到这里为止,优化还没有结束,对rdd1我们还是执行了两次算子操作,rdd1实际上还是会被计算两次。
- // 因此还需要配合“原则三:对多次使用的RDD进行持久化”进行使用,才能保证一个RDD被多次使用时只被计算一次。
原则三:对多次使用的RDD进行持久化
当你在Spark代码中多次对一个RDD做了算子操作后,恭喜,你已经实现Spark作业第一步的优化了,也就是尽可能复用RDD。此时就该在这个基础之上,进行第二步优化了,也就是要保证对一个RDD执行多次算子操作时,这个RDD本身仅仅被计算一次。
Spark中对于一个RDD执行多次算子的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。
因此对于这种情况,我们的建议是:对多次使用的RDD进行持久化。此时Spark就会根据你的持久化策略,将RDD中的数据保存到内存或者磁盘中。 以后每次对这个RDD进行算子操作时,都会直接从内存或磁盘中提取持久化的RDD数据,然后执行算子,而不会从源头处重新计算一遍这个RDD,再执行算子 操作。
对多次使用的RDD进行持久化的代码示例
- // 如果要对一个RDD进行持久化,只要对这个RDD调用cache()和persist()即可。
- // 正确的做法。
- // cache()方法表示:使用非序列化的方式将RDD中的数据全部尝试持久化到内存中。
- // 此时再对rdd1执行两次算子操作时,只有在第一次执行map算子时,才会将这个rdd1从源头处计算一次。
- // 第二次执行reduce算子时,就会直接从内存中提取数据进行计算,不会重复计算一个rdd。
- val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").cache()
- rdd1.map(...)
- rdd1.reduce(...)
- // persist()方法表示:手动选择持久化级别,并使用指定的方式进行持久化。
- // 比如说,StorageLevel.MEMORY_AND_DISK_SER表示,内存充足时优先持久化到内存中,内存不充足时持久化到磁盘文件中。
- // 而且其中的_SER后缀表示,使用序列化的方式来保存RDD数据,此时RDD中的每个partition都会序列化成一个大的字节数组,然后再持久化到内存或磁盘中。
- // 序列化的方式可以减少持久化的数据对内存/磁盘的占用量,进而避免内存被持久化数据占用过多,从而发生频繁GC。
- val rdd1 = sc.textFile("hdfs://192.168.0.1:9000/hello.txt").persist(StorageLevel.MEMORY_AND_DISK_SER)
- rdd1.map(...)
- rdd1.reduce(...)
对于persist()方法而言,我们可以根据不同的业务场景选择不同的持久化级别。
Spark的持久化级别
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子 操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化 机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有 副本的话,就只能将这些数据从源头处重新计算一遍了。 |
如何选择一种最合适的持久化策略
- 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为 不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能 也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的, 如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化 后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来 的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中 的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为 既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓 存在内存中,内存缓存不下才会写入磁盘。
- 通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次 所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用 性,否则不建议使用。
原则四:尽量避免使用shuffle类算子
如果有可能的话,要尽量避免使用shuffle类算子。因为Spark作业运行过程中,最消耗性能的地方就是shuffle过程。shuffle过 程,简单来说,就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join等操作。比如reduceByKey、join等算 子,都会触发shuffle操作。
shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key。 而且相同key都拉取到同一个节点进行聚合操作时,还有可能会因为一个节点上处理的key过多,导致内存不够存放,进而溢写到磁盘文件中。因此在 shuffle过程中,可能会发生大量的磁盘文件读写的IO操作,以及数据的网络传输操作。磁盘IO和网络数据传输也是shuffle性能较差的主要原 因。
因此在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行 shuffle的算子,尽量使用map类的非shuffle算子。这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可 以大大减少性能开销。
Broadcast与map进行join代码示例
- // 传统的join操作会导致shuffle操作。
- // 因为两个RDD中,相同的key都需要通过网络拉取到一个节点上,由一个task进行join操作。
- val rdd3 = rdd1.join(rdd2)
- // Broadcast+map的join操作,不会导致shuffle操作。
- // 使用Broadcast将一个数据量较小的RDD作为广播变量。
- val rdd2Data = rdd2.collect()
- val rdd2DataBroadcast = sc.broadcast(rdd2Data)
- // 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。
- // 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的,那么就判定可以进行join。
- // 此时就可以根据自己需要的方式,将rdd1当前数据与rdd2中可以连接的数据,拼接在一起(String或Tuple)。
- val rdd3 = rdd1.map(rdd2DataBroadcast...)
- // 注意,以上操作,建议仅仅在rdd2的数据量比较少(比如几百M,或者一两G)的情况下使用。
- // 因为每个Executor的内存中,都会驻留一份rdd2的全量数据。
原则五:使用map-side预聚合的shuffle操作
如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。
所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。 map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就 会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者 aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义 的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来 说比较差。
比如如下两幅图,就是典型的例子,分别基于reduceByKey和groupByKey进行单词计数。其中第一张图是groupByKey的原理 图,可以看到,没有进行任何本地聚合时,所有数据都会在集群节点之间传输;第二张图是reduceByKey的原理图,可以看到,每个节点本地的相同 key数据,都进行了预聚合,然后才传输到其他节点上进行全局聚合。
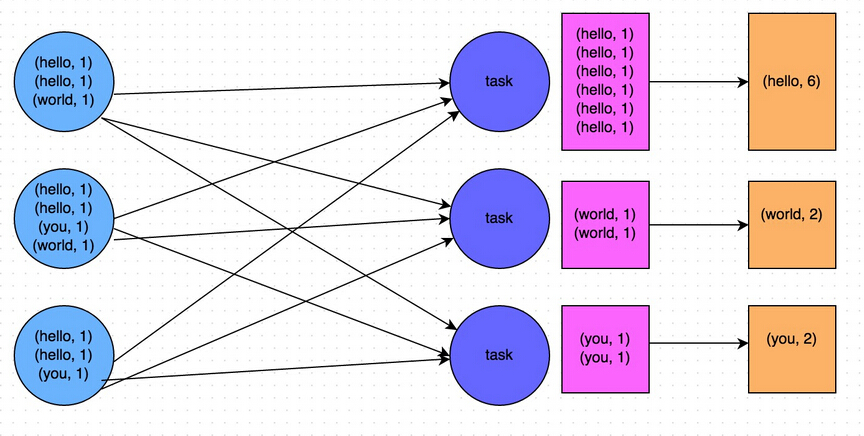
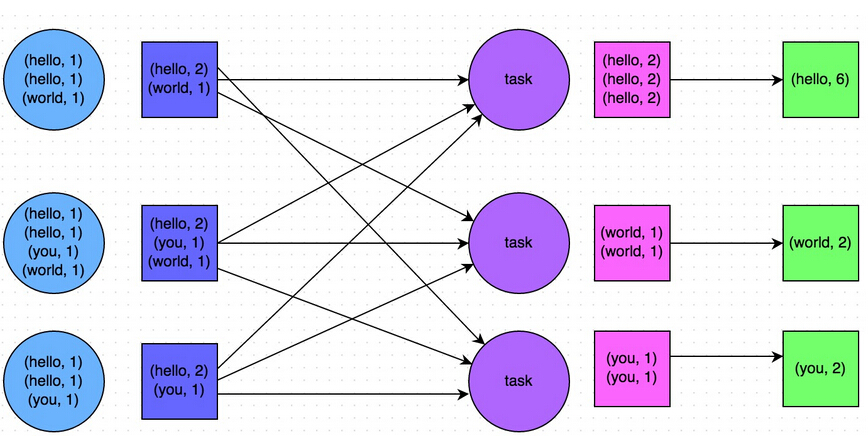
原则六:使用高性能的算子
除了shuffle相关的算子有优化原则之外,其他的算子也都有着相应的优化原则。
使用reduceByKey/aggregateByKey替代groupByKey
详情见“原则五:使用map-side预聚合的shuffle操作”。
使用mapPartitions替代普通map
mapPartitions类的算子,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。 但是有的时候,使用mapPartitions会出现OOM(内存溢出)的问题。因为单次函数调用就要处理掉一个partition所有的数据,如果内存 不够,垃圾回收时是无法回收掉太多对象的,很可能出现OOM异常。所以使用这类操作时要慎重!
使用foreachPartitions替代foreach
原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数 据。在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。比如在foreach函数中,将RDD中所有数据写 MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数 据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个 partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于1万条左右的数据量写MySQL,性能可 以提升30%以上。
使用filter之后进行coalesce操作
通常对一个RDD执行filter算子过滤掉RDD中较多数据后(比如30%以上的数据),建议使用coalesce算子,手动减少RDD的 partition数量,将RDD中的数据压缩到更少的partition中去。因为filter之后,RDD的每个partition中都会有很多数据 被过滤掉,此时如果照常进行后续的计算,其实每个task处理的partition中的数据量并不是很多,有一点资源浪费,而且此时处理的task越多, 可能速度反而越慢。因此用coalesce减少partition数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即 可处理完所有的partition。在某些场景下,对于性能的提升会有一定的帮助。
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
repartitionAndSortWithinPartitions是Spark官网推荐的一个算子,官方建议,如果需要在 repartition重分区之后,还要进行排序,建议直接使用repartitionAndSortWithinPartitions算子。因为该算子 可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高 的。
原则七:广播大变量
有时在开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提升性能。
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如 果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频 繁GC,都会极大地影响性能。
因此对于上述情况,如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播后的变量,会保证每个Executor的内存 中,只驻留一份变量副本,而Executor中的task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减 少网络传输的性能开销,并减少对Executor内存的占用开销,降低GC的频率。
广播大变量的代码示例
- // 以下代码在算子函数中,使用了外部的变量。
- // 此时没有做任何特殊操作,每个task都会有一份list1的副本。
- val list1 = ...
- rdd1.map(list1...)
- // 以下代码将list1封装成了Broadcast类型的广播变量。
- // 在算子函数中,使用广播变量时,首先会判断当前task所在Executor内存中,是否有变量副本。
- // 如果有则直接使用;如果没有则从Driver或者其他Executor节点上远程拉取一份放到本地Executor内存中。
- // 每个Executor内存中,就只会驻留一份广播变量副本。
- val list1 = ...
- val list1Broadcast = sc.broadcast(list1)
- rdd1.map(list1Broadcast...)
原则八:使用Kryo优化序列化性能
在Spark中,主要有三个地方涉及到了序列化:
- 在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见“原则七:广播大变量”中的讲解)。
- 将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
- 使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机 制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介 绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所 有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
以下是使用Kryo的代码示例,我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等):
- // 创建SparkConf对象。
- val conf = new SparkConf().setMaster(...).setAppName(...)
- // 设置序列化器为KryoSerializer。
- conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
- // 注册要序列化的自定义类型。
- conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
原则九:优化数据结构
Java中,有三种类型比较耗费内存:
- 对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
- 字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
- 集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来封装集合元素,比如Map.Entry。
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用,从而降低GC频率,提升性能。
但是在笔者的编码实践中发现,要做到该原则其实并不容易。因为我们同时要考虑到代码的可维护性,如果一个代码中,完全没有任何对象抽象,全部是字符 串拼接的方式,那么对于后续的代码维护和修改,无疑是一场巨大的灾难。同理,如果所有操作都基于数组实现,而不使用HashMap、LinkedList 等集合类型,那么对于我们的编码难度以及代码可维护性,也是一个极大的挑战。因此笔者建议,在可能以及合适的情况下,使用占用内存较少的数据结构,但是前 提是要保证代码的可维护性。
资源调优
调优概述
在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多 Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参数,最后就只能胡乱设置,甚至压根儿不设置。资源参数设置的不合理,可能会导致没 有充分利用集群资源,作业运行会极其缓慢;或者设置的资源过大,队列没有足够的资源来提供,进而导致各种异常。总之,无论是哪种情况,都会导致Spark 作业的运行效率低下,甚至根本无法运行。因此我们必须对Spark作业的资源使用原理有一个清晰的认识,并知道在Spark作业运行过程中,有哪些资源参 数是可以设置的,以及如何设置合适的参数值。
Spark作业基本运行原理
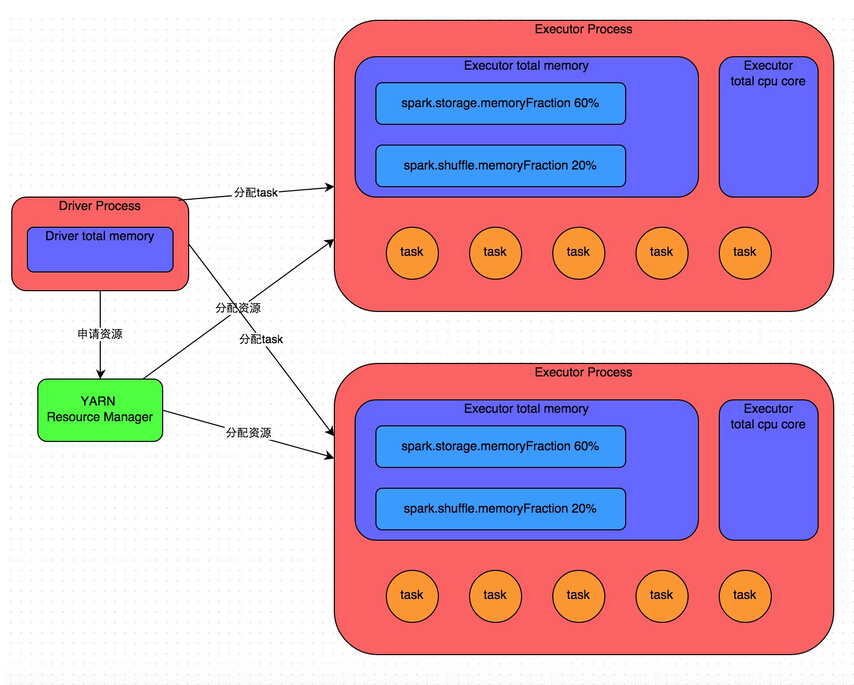
详细原理见上图。我们使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模 式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。Driver进程本身会根据我们设置的参数,占 有一定数量的内存和CPU core。而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,美团•大众点评使用的是YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里 的资源指的就是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor 进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码 分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执 行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage 的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的 task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的 结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、 join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个 stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个 stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作 (比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让 task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是 让RDD持久化时使用,默认占Executor总内存的60%。
task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。如果 CPU core数量比较充足,而且分配到的task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些task线程。
以上就是Spark作业的基本运行原理的说明,大家可以结合上图来理解。理解作业基本原理,是我们进行资源参数调优的基本前提。
资源参数调优
了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各 个使用资源的地方,通过调节各种参数,来优化资源使用的效率,从而提升Spark作业的执行性能。以下参数就是Spark中主要的资源参数,每个参数都对 应着作业运行原理中的某个部分,我们同时也给出了一个调优的参考值。
num-executors
- 参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集 群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少 量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
- 参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
- 参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
- 参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可 以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总 内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的 总内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
- 参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
- 参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
- 参数说明:该参数用于设置Driver进程的内存。
- 参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
- 参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
- 参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致 Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的 Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90% 的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num- executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
spark.storage.memoryFraction
- 参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
- 参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够 缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适 当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
spark.shuffle.memoryFraction
- 参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor 内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了 这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
- 参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作 的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着 task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
资源参数的调优,没有一个固定的值,需要同学们根据自己的实际情况(包括Spark作业中的shuffle操作数量、RDD持久化操作数量以及spark web ui中显示的作业gc情况),同时参考本篇文章中给出的原理以及调优建议,合理地设置上述参数。
资源参数参考示例
以下是一份spark-submit命令的示例,大家可以参考一下,并根据自己的实际情况进行调节:
- ./bin/spark-submit \
- --master yarn-cluster \
- --num-executors 100 \
- --executor-memory 6G \
- --executor-cores 4 \
- --driver-memory 1G \
- --conf spark.default.parallelism=1000 \
- --conf spark.storage.memoryFraction=0.5 \
- --conf spark.shuffle.memoryFraction=0.3 \
数据倾斜调优
调优概述
有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
数据倾斜发生时的现象
- 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。
- 原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
数据倾斜发生的原理
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行 聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万 条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。因此,整 个Spark作业的运行进度是由运行时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致内存溢出。
下图就是一个很清晰的例子:hello这个key,在三个节点上对应了总共7条数据,这些数据都会被拉取到同一个task中进行处理;而world 和you这两个key分别才对应1条数据,所以另外两个task只要分别处理1条数据即可。此时第一个task的运行时间可能是另外两个task的7倍, 而整个stage的运行速度也由运行最慢的那个task所决定。
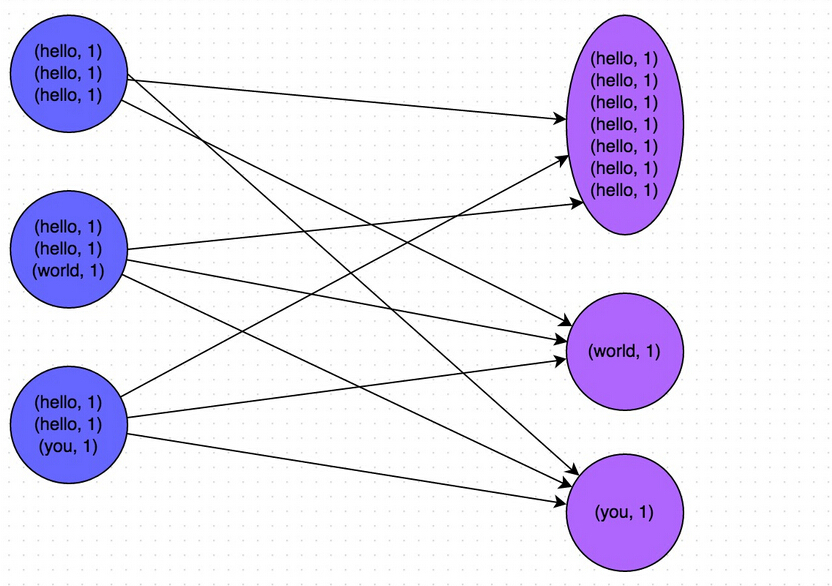
如何定位导致数据倾斜的代码
数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、 groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时, 可能就是你的代码中使用了这些算子中的某一个所导致的。
某个task执行特别慢的情况
首先要看的,就是数据倾斜发生在第几个stage中。
如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到当前运行到了第几个stage;如果是用yarn- cluster模式提交,则可以通过Spark Web UI来查看当前运行到了第几个stage。此外,无论是使用yarn-client模式还是yarn-cluster模式,我们都可以在Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
比如下图中,倒数第三列显示了每个task的运行时间。明显可以看到,有的task运行特别快,只需要几秒钟就可以运行完;而有的task运行特别 慢,需要几分钟才能运行完,此时单从运行时间上看就已经能够确定发生数据倾斜了。此外,倒数第一列显示了每个task处理的数据量,明显可以看到,运行时 间特别短的task只需要处理几百KB的数据即可,而运行时间特别长的task需要处理几千KB的数据,处理的数据量差了10倍。此时更加能够确定是发生 了数据倾斜。
知道数据倾斜发生在哪一个stage之后,接着我们就需要根据stage划分原理,推算出来发生倾斜的那个stage对应代码中的哪一部分,这部分 代码中肯定会有一个shuffle类算子。精准推算stage与代码的对应关系,需要对Spark的源码有深入的理解,这里我们可以介绍一个相对简单实用 的推算方法:只要看到Spark代码中出现了一个shuffle类算子或者是Spark SQL的SQL语句中出现了会导致shuffle的语句(比如group by语句),那么就可以判定,以那个地方为界限划分出了前后两个stage。
这里我们就以Spark最基础的入门程序——单词计数来举例,如何用最简单的方法大致推算出一个stage对应的代码。如下示例,在整个代码中,只 有一个reduceByKey是会发生shuffle的算子,因此就可以认为,以这个算子为界限,会划分出前后两个stage。
- stage0,主要是执行从textFile到map操作,以及执行shuffle write操作。shuffle write操作,我们可以简单理解为对pairs RDD中的数据进行分区操作,每个task处理的数据中,相同的key会写入同一个磁盘文件内。
- stage1,主要是执行从reduceByKey到collect操作,stage1的各个task一开始运行,就会首先执行shuffle read操作。执行shuffle read操作的task,会从stage0的各个task所在节点拉取属于自己处理的那些key,然后对同一个key进行全局性的聚合或join等操作, 在这里就是对key的value值进行累加。stage1在执行完reduceByKey算子之后,就计算出了最终的wordCounts RDD,然后会执行collect算子,将所有数据拉取到Driver上,供我们遍历和打印输出。
- val conf = new SparkConf()
- val sc = new SparkContext(conf)
- val lines = sc.textFile("hdfs://...")
- val words = lines.flatMap(_.split(" "))
- val pairs = words.map((_, 1))
- val wordCounts = pairs.reduceByKey(_ + _)
- wordCounts.collect().foreach(println(_))
通过对单词计数程序的分析,希望能够让大家了解最基本的stage划分的原理,以及stage划分后shuffle操作是如何在两个stage的边 界处执行的。然后我们就知道如何快速定位出发生数据倾斜的stage对应代码的哪一个部分了。比如我们在Spark Web UI或者本地log中发现,stage1的某几个task执行得特别慢,判定stage1出现了数据倾斜,那么就可以回到代码中定位出stage1主要包 括了reduceByKey这个shuffle类算子,此时基本就可以确定是由educeByKey算子导致的数据倾斜问题。比如某个单词出现了100万 次,其他单词才出现10次,那么stage1的某个task就要处理100万数据,整个stage的速度就会被这个task拖慢。
某个task莫名其妙内存溢出的情况
这种情况下去定位出问题的代码就比较容易了。我们建议直接看yarn-client模式下本地log的异常栈,或者是通过YARN查看yarn- cluster模式下的log中的异常栈。一般来说,通过异常栈信息就可以定位到你的代码中哪一行发生了内存溢出。然后在那行代码附近找找,一般也会有 shuffle类算子,此时很可能就是这个算子导致了数据倾斜。
但是大家要注意的是,不能单纯靠偶然的内存溢出就判定发生了数据倾斜。因为自己编写的代码的bug,以及偶然出现的数据异常,也可能会导致内存溢 出。因此还是要按照上面所讲的方法,通过Spark Web UI查看报错的那个stage的各个task的运行时间以及分配的数据量,才能确定是否是由于数据倾斜才导致了这次内存溢出。
查看导致数据倾斜的key的数据分布情况
知道了数据倾斜发生在哪里之后,通常需要分析一下那个执行了shuffle操作并且导致了数据倾斜的RDD/Hive表,查看一下其中key的分布 情况。这主要是为之后选择哪一种技术方案提供依据。针对不同的key分布与不同的shuffle算子组合起来的各种情况,可能需要选择不同的技术方案来解 决。
此时根据你执行操作的情况不同,可以有很多种查看key分布的方式:
- 如果是Spark SQL中的group by、join语句导致的数据倾斜,那么就查询一下SQL中使用的表的key分布情况。
- 如果是对Spark RDD执行shuffle算子导致的数据倾斜,那么可以在Spark作业中加入查看key分布的代码,比如RDD.countByKey()。然后对统计 出来的各个key出现的次数,collect/take到客户端打印一下,就可以看到key的分布情况。
举例来说,对于上面所说的单词计数程序,如果确定了是stage1的reduceByKey算子导致了数据倾斜,那么就应该看看进行 reduceByKey操作的RDD中的key分布情况,在这个例子中指的就是pairs RDD。如下示例,我们可以先对pairs采样10%的样本数据,然后使用countByKey算子统计出每个key出现的次数,最后在客户端遍历和打印 样本数据中各个key的出现次数。
- val sampledPairs = pairs.sample(false, 0.1)
- val sampledWordCounts = sampledPairs.countByKey()
- sampledWordCounts.foreach(println(_))
数据倾斜的解决方案
解决方案一:使用Hive ETL预处理数据
方案适用场景:导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀(比如某个key对应了100万数据,其他key才对应了10条数据),而且业务场景需要频繁使用Spark对Hive表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:此时可以评估一下,是否可以通过Hive来进行数据预处理(即通过Hive ETL预先对数据按照key进行聚合,或者是预先和其他表进行join),然后在Spark作业中针对的数据源就不是原来的Hive表了,而是预处理后的 Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在Spark作业中也就不需要使用原先的shuffle类算子执行这类操作了。
方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在Spark中执行shuffle类算子,那么 肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以Hive ETL中进行group by或者join等shuffle操作时,还是会出现数据倾斜,导致Hive ETL的速度很慢。我们只是把数据倾斜的发生提前到了Hive ETL中,避免Spark程序发生数据倾斜而已。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
方案缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
方案实践经验:在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的 场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
项目实践经验:在美团·点评的交互式用户行为分析系统中使用了这种方案,该系统主要是允许用户通过Java Web系统提交数据分析统计任务,后端通过Java提交Spark作业进行数据分析统计。要求Spark作业速度必须要快,尽量在10分钟以内,否则速度 太慢,用户体验会很差。所以我们将有些Spark作业的shuffle操作提前到了Hive ETL中,从而让Spark直接使用预处理的Hive中间表,尽可能地减少Spark的shuffle操作,大幅度提升了性能,将部分作业的性能提升了6 倍以上。
解决方案二:过滤少数导致倾斜的key
方案适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
方案实现思路:如果我们判断那少数几个数据量特别多的key,对作业的执行和计算结果不是特别重要的话,那么干 脆就直接过滤掉那少数几个key。比如,在Spark SQL中可以使用where子句过滤掉这些key或者在Spark Core中对RDD执行filter算子过滤掉这些key。如果需要每次作业执行时,动态判定哪些key的数据量最多然后再进行过滤,那么可以使用 sample算子对RDD进行采样,然后计算出每个key的数量,取数据量最多的key过滤掉即可。
方案实现原理:将导致数据倾斜的key给过滤掉之后,这些key就不会参与计算了,自然不可能产生数据倾斜。
方案优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
方案缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
方案实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然 OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个 key之后,直接在程序中将那些key给过滤掉。
解决方案三:提高shuffle操作的并行度
方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
方案实现思路:在对RDD执行shuffle算子时,给shuffle算子传入一个参数,比如 reduceByKey(1000),该参数就设置了这个shuffle算子执行时shuffle read task的数量。对于Spark SQL中的shuffle类语句,比如group by、join等,需要设置一个参数,即spark.sql.shuffle.partitions,该参数代表了shuffle read task的并行度,该值默认是200,对于很多场景来说都有点过小。
方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个 key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。具体原理如下图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有 100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。 所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用嘴简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
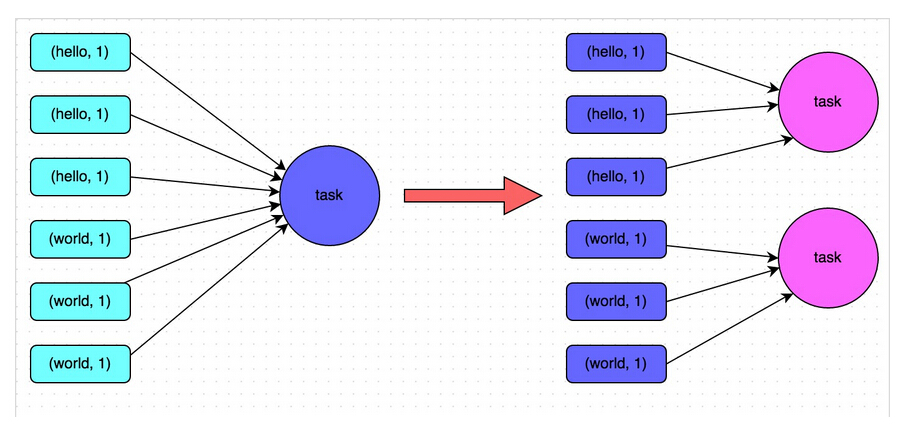
解决方案四:两阶段聚合(局部聚合+全局聚合)
方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机 数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
方案优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
方案缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
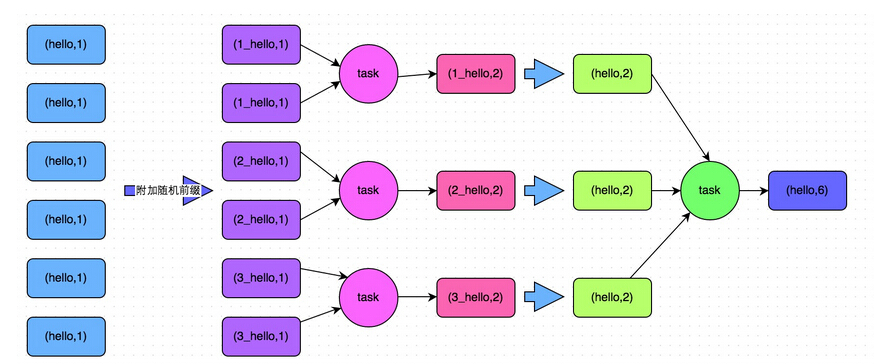
- // 第一步,给RDD中的每个key都打上一个随机前缀。
- JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(
- new PairFunction<Tuple2<Long,Long>, String, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
- throws Exception {
- Random random = new Random();
- int prefix = random.nextInt(10);
- return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
- }
- });
- // 第二步,对打上随机前缀的key进行局部聚合。
- JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(
- new Function2<Long, Long, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Long call(Long v1, Long v2) throws Exception {
- return v1 + v2;
- }
- });
- // 第三步,去除RDD中每个key的随机前缀。
- JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(
- new PairFunction<Tuple2<String,Long>, Long, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
- throws Exception {
- long originalKey = Long.valueOf(tuple._1.split("_")[1]);
- return new Tuple2<Long, Long>(originalKey, tuple._2);
- }
- });
- // 第四步,对去除了随机前缀的RDD进行全局聚合。
- JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(
- new Function2<Long, Long, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Long call(Long v1, Long v2) throws Exception {
- return v1 + v2;
- }
- });
解决方案五:将reduce join转为map join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操 作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存 中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量 数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数 据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。具体原理如下图所示。
方案优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会 比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那 么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
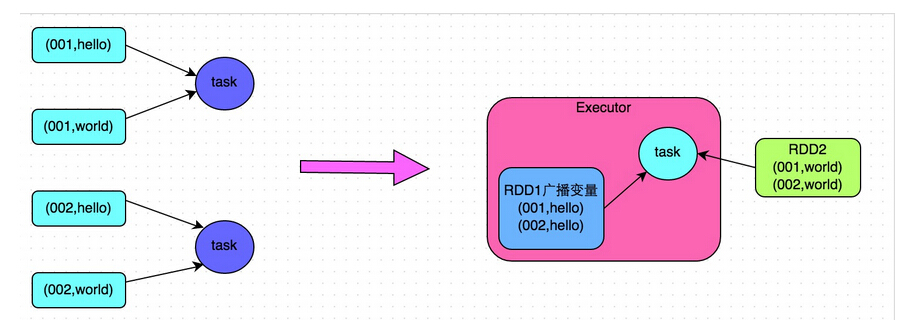
- // 首先将数据量比较小的RDD的数据,collect到Driver中来。
- List<Tuple2<Long, Row>> rdd1Data = rdd1.collect()
- // 然后使用Spark的广播功能,将小RDD的数据转换成广播变量,这样每个Executor就只有一份RDD的数据。
- // 可以尽可能节省内存空间,并且减少网络传输性能开销。
- final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data);
- // 对另外一个RDD执行map类操作,而不再是join类操作。
- JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair(
- new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple)
- throws Exception {
- // 在算子函数中,通过广播变量,获取到本地Executor中的rdd1数据。
- List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value();
- // 可以将rdd1的数据转换为一个Map,便于后面进行join操作。
- Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>();
- for(Tuple2<Long, Row> data : rdd1Data) {
- rdd1DataMap.put(data._1, data._2);
- }
- // 获取当前RDD数据的key以及value。
- String key = tuple._1;
- String value = tuple._2;
- // 从rdd1数据Map中,根据key获取到可以join到的数据。
- Row rdd1Value = rdd1DataMap.get(key);
- return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value));
- }
- });
- // 这里得提示一下。
- // 上面的做法,仅仅适用于rdd1中的key没有重复,全部是唯一的场景。
- // 如果rdd1中有多个相同的key,那么就得用flatMap类的操作,在进行join的时候不能用map,而是得遍历rdd1所有数据进行join。
- // rdd2中每条数据都可能会返回多条join后的数据。
解决方案六:采样倾斜key并分拆join操作
方案适用场景:两个RDD/Hive表进行join的时候,如果数据量都比较大,无法采用“解决方案五”,那么 此时可以看一下两个RDD/Hive表中的key分布情况。如果出现数据倾斜,是因为其中某一个RDD/Hive表中的少数几个key的数据量过大,而另 一个RDD/Hive表中的所有key都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:
- 对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
- 然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
- 接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
- 再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
- 而另外两个普通的RDD就照常join即可。
- 最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
方案实现原理:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,可以将少数几个key分拆成独立RDD,并附加随机前缀打散成n份去进行join,此时这几个key对应的数据就不会集中在少数几个task上,而是分散到多个task进行join了。具体原理见下图。
方案优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行join。而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
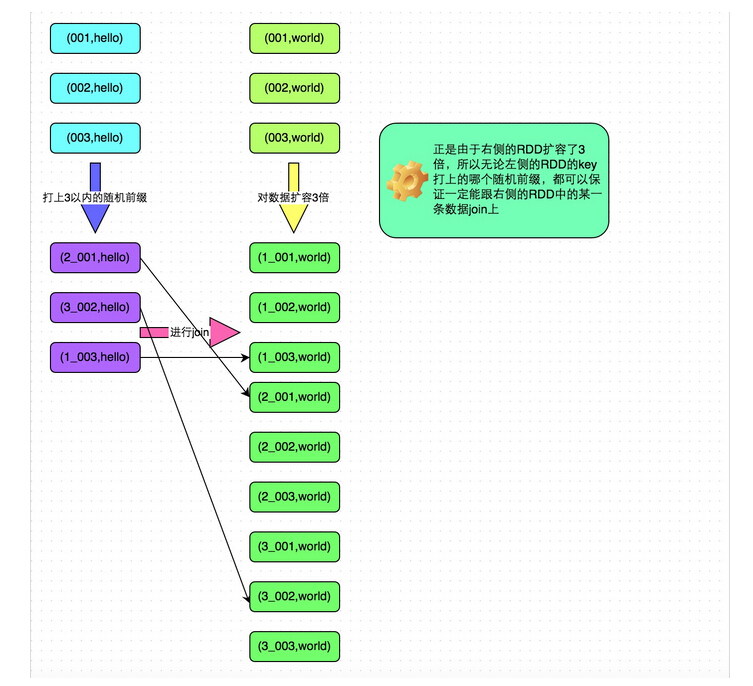
- // 首先从包含了少数几个导致数据倾斜key的rdd1中,采样10%的样本数据。
- JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
- // 对样本数据RDD统计出每个key的出现次数,并按出现次数降序排序。
- // 对降序排序后的数据,取出top 1或者top 100的数据,也就是key最多的前n个数据。
- // 具体取出多少个数据量最多的key,由大家自己决定,我们这里就取1个作为示范。
- JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
- new PairFunction<Tuple2<Long,String>, Long, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
- throws Exception {
- return new Tuple2<Long, Long>(tuple._1, 1L);
- }
- });
- JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
- new Function2<Long, Long, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Long call(Long v1, Long v2) throws Exception {
- return v1 + v2;
- }
- });
- JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
- new PairFunction<Tuple2<Long,Long>, Long, Long>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
- throws Exception {
- return new Tuple2<Long, Long>(tuple._2, tuple._1);
- }
- });
- final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
- // 从rdd1中分拆出导致数据倾斜的key,形成独立的RDD。
- JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
- new Function<Tuple2<Long,String>, Boolean>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Boolean call(Tuple2<Long, String> tuple) throws Exception {
- return tuple._1.equals(skewedUserid);
- }
- });
- // 从rdd1中分拆出不导致数据倾斜的普通key,形成独立的RDD。
- JavaPairRDD<Long, String> commonRDD = rdd1.filter(
- new Function<Tuple2<Long,String>, Boolean>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Boolean call(Tuple2<Long, String> tuple) throws Exception {
- return !tuple._1.equals(skewedUserid);
- }
- });
- // rdd2,就是那个所有key的分布相对较为均匀的rdd。
- // 这里将rdd2中,前面获取到的key对应的数据,过滤出来,分拆成单独的rdd,并对rdd中的数据使用flatMap算子都扩容100倍。
- // 对扩容的每条数据,都打上0~100的前缀。
- JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
- new Function<Tuple2<Long,Row>, Boolean>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
- return tuple._1.equals(skewedUserid);
- }
- }).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Iterable<Tuple2<String, Row>> call(
- Tuple2<Long, Row> tuple) throws Exception {
- Random random = new Random();
- List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
- for(int i = 0; i < 100; i++) {
- list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
- }
- return list;
- }
- });
- // 将rdd1中分拆出来的导致倾斜的key的独立rdd,每条数据都打上100以内的随机前缀。
- // 然后将这个rdd1中分拆出来的独立rdd,与上面rdd2中分拆出来的独立rdd,进行join。
- JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
- new PairFunction<Tuple2<Long,String>, String, String>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<String, String> call(Tuple2<Long, String> tuple)
- throws Exception {
- Random random = new Random();
- int prefix = random.nextInt(100);
- return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
- }
- })
- .join(skewedUserid2infoRDD)
- .mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<Long, Tuple2<String, Row>> call(
- Tuple2<String, Tuple2<String, Row>> tuple)
- throws Exception {
- long key = Long.valueOf(tuple._1.split("_")[1]);
- return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
- }
- });
- // 将rdd1中分拆出来的包含普通key的独立rdd,直接与rdd2进行join。
- JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
- // 将倾斜key join后的结果与普通key join后的结果,uinon起来。
- // 就是最终的join结果。
- JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
解决方案七:使用随机前缀和扩容RDD进行join
方案适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义,此时就只能使用最后一种方案来解决问题了。
方案实现思路:
- 该方案的实现思路基本和“解决方案六”类似,首先查看RDD/Hive表中的数据分布情况,找到那个造成数据倾斜的RDD/Hive表,比如有多个key都对应了超过1万条数据。
- 然后将该RDD的每条数据都打上一个n以内的随机前缀。
- 同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。
- 最后将两个处理后的RDD进行join即可。
方案实现原理:将原先一样的key通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同 key”分散到多个task中去处理,而不是让一个task处理大量的相同key。该方案与“解决方案六”的不同之处就在于,上一种方案是尽量只对少数倾 斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情 况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
方案优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
方案缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
方案实践经验:曾经开发一个数据需求的时候,发现一个join导致了数据倾斜。优化之前,作业的执行时间大约是60分钟左右;使用该方案优化之后,执行时间缩短到10分钟左右,性能提升了6倍。
- // 首先将其中一个key分布相对较为均匀的RDD膨胀100倍。
- JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(
- new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
- throws Exception {
- List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
- for(int i = 0; i < 100; i++) {
- list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
- }
- return list;
- }
- });
- // 其次,将另一个有数据倾斜key的RDD,每条数据都打上100以内的随机前缀。
- JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(
- new PairFunction<Tuple2<Long,String>, String, String>() {
- private static final long serialVersionUID = 1L;
- @Override
- public Tuple2<String, String> call(Tuple2<Long, String> tuple)
- throws Exception {
- Random random = new Random();
- int prefix = random.nextInt(100);
- return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
- }
- });
- // 将两个处理后的RDD进行join即可。
- JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
解决方案八:多种方案组合使用
在实践中发现,很多情况下,如果只是处理较为简单的数据倾斜场景,那么使用上述方案中的某一种基本就可以解决。但是如果要处理一个较为复杂的数据倾 斜场景,那么可能需要将多种方案组合起来使用。比如说,我们针对出现了多个数据倾斜环节的Spark作业,可以先运用解决方案一和二,预处理一部分数据, 并过滤一部分数据来缓解;其次可以对某些shuffle操作提升并行度,优化其性能;最后还可以针对不同的聚合或join操作,选择一种方案来优化其性 能。大家需要对这些方案的思路和原理都透彻理解之后,在实践中根据各种不同的情况,灵活运用多种方案,来解决自己的数据倾斜问题。
shuffle调优
调优概述
大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作 业的性能更上一层楼,就有必要对shuffle过程进行调优。但是也必须提醒大家的是,影响一个Spark作业性能的因素,主要还是代码开发、资源参数以 及数据倾斜,shuffle调优只能在整个Spark的性能调优中占到一小部分而已。因此大家务必把握住调优的基本原则,千万不要舍本逐末。下面我们就给 大家详细讲解shuffle的原理,以及相关参数的说明,同时给出各个参数的调优建议。
ShuffleManager发展概述
在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。而随着Spark的版本的发展,ShuffleManager也在不断迭代,变得越来越先进。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。
因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于 HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但 是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
下面我们详细分析一下HashShuffleManager和SortShuffleManager的原理。
HashShuffleManager运行原理
未经优化的HashShuffleManager
下图说明了未经优化的HashShuffleManager的原理。这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
我们先从shuffle write开始说起。shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个 task处理的数据按key进行“分类”。所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文 件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?很简单,下一个stage的task有多少个,当前stage的每个task就要创建 多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个 task,总共有10个Executor,每个Executor执行5个Task,那么每个Executor上总共就要创建500个磁盘文件,所有 Executor上会创建5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
接着我们来说说shuffle read。shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个 节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数 据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
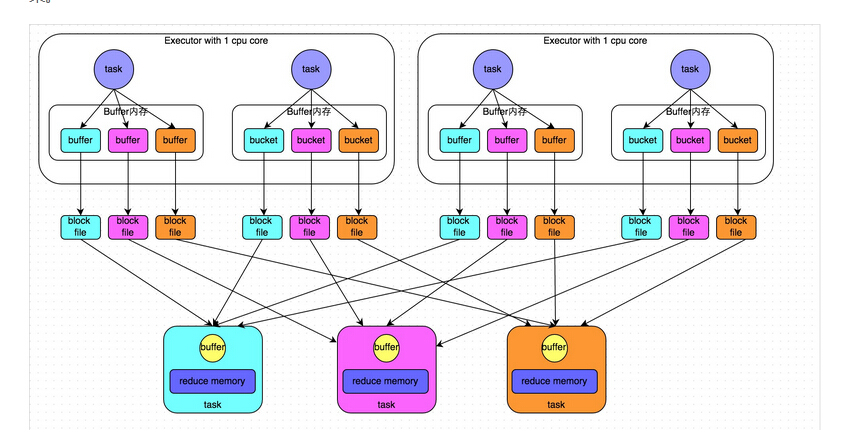
优化后的HashShuffleManager
下图说明了优化后的HashShuffleManager的原理。这里说的优化,是指我们可以设置一个参 数,spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。通常来说,如果我 们使用HashShuffleManager,那么都建议开启这个选项。
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个 shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件 内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就 是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件, 这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
假设第二个stage有100个task,第一个stage有50个task,总共还是有10个Executor,每个Executor执行5个 task。那么原本使用未经优化的HashShuffleManager时,每个Executor会产生500个磁盘文件,所有Executor会产生 5000个磁盘文件的。但是此时经过优化之后,每个Executor创建的磁盘文件的数量的计算公式为:CPU core的数量 * 下一个stage的task数量。也就是说,每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
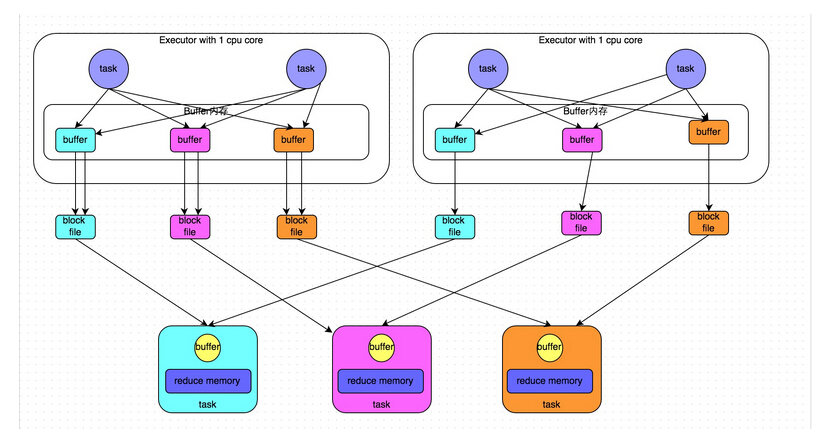
SortShuffleManager运行原理
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用 bypass机制。
普通运行机制
下图说明了普通的SortShuffleManager的原理。在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子, 可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内 存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一 下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是 10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的 BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存 缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并, 这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件, 也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的 start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共 有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此 此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
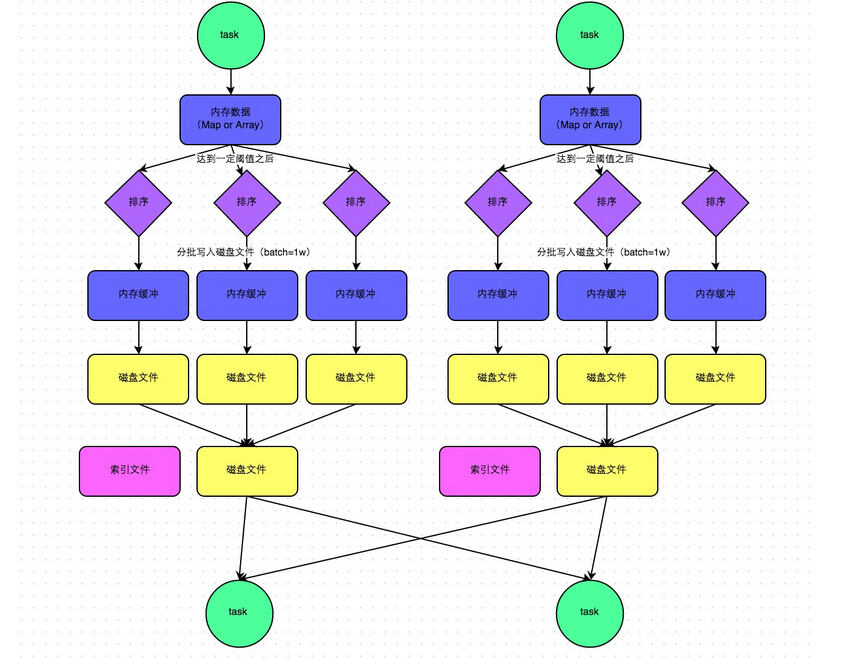
bypass运行机制
下图说明了bypass SortShuffleManager的原理。bypass运行机制的触发条件如下:
- shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
- 不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件 之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独 的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘 文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
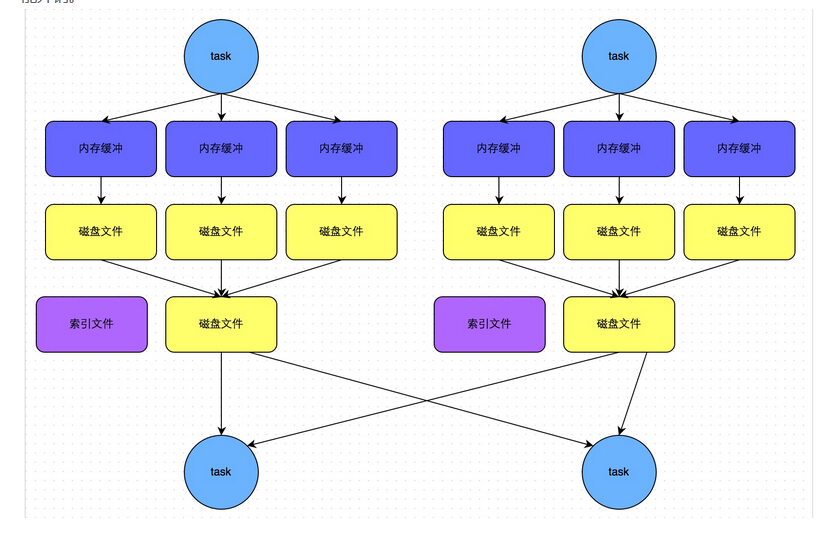
shuffle相关参数调优
以下是Shffule过程中的一些主要参数,这里详细讲解了各个参数的功能、默认值以及基于实践经验给出的调优建议。
spark.shuffle.file.buffer
- 默认值:32k
- 参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
- 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
- 默认值:48m
- 参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
- 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
- 默认值:3
- 参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取 还是没有成功,就可能会导致作业执行失败。
- 调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定 性。
spark.shuffle.io.retryWait
- 默认值:5s
- 参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
- 调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.memoryFraction
- 默认值:0.2
- 参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
- 调优建议:在资源参数调优中讲解过这个参数。如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
spark.shuffle.manager
- 默认值:sort
- 参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的 堆外内存管理机制,内存使用效率更高。
- 调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的 SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的 HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort要慎用,因为之前发现了 一些相应的bug。
spark.shuffle.sort.bypassMergeThreshold
- 默认值:200
- 参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临 时磁盘文件都合并成一个文件,并会创建单独的索引文件。
- 调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁 盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
- 默认值:false
- 参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度 合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
- 调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将 spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在 实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
spark笔记spark优化相关推荐
- Spark笔记——技术点汇总
Spark笔记--技术点汇总 目录 · 概况 · 手工搭建集群 · 引言 · 安装Scala · 配置文件 · 启动与测试 · 应用部署 · 部署架构 · 应用程序部署 · 核心原理 · RDD概念 ...
- 学习笔记Spark(十)—— Spark MLlib应用(2)—— Spark MLlib应用
三.Spark MLlib应用 3.1.Spark ML线性模型 数据准备 基于Spark ML的线性模型需要DataFrame类型的模型数据,DataFrame需要包含:一列标签列,一列由多个特征合 ...
- 学习笔记Spark(七)—— Spark SQL应用(2)—— Spark DataFrame基础操作
二.Spark DataFrame基础操作 2.1.DataFrame DataFrame是一种不可变的分布式数据集,这种数据集被组织成指定的列,类似于关系数据库中的表. 数据集的每一列都带有名称和类 ...
- MaxCompute Spark 资源使用优化详解
简介:本文主要讲解MaxCompute Spark资源调优,目的在于在保证Spark任务正常运行的前提下,指导用户更好地对Spark作业资源使用进行优化,极大化利用资源,降低成本. 本文作者:吴数傑 ...
- spark 笔记 1: 如何着手
spark 笔记 1: 如何着手 必读:从官方的开发者页面着手,包括如何构建spark以及编码规范(强烈建议读读编程规范)等:https://cwiki.apache.org/confluence/d ...
- spark 笔记 16: BlockManager
spark 笔记 16: BlockManager 先看一下原理性的文章:http://jerryshao.me/architecture/2013/10/08/spark-storage-modul ...
- [Spark]Spark常用的优化方法
目录 优化目的 Spark-core的优化 Yarn 模式下动态资源调度 Shuffle阶段调优 MapPartitions分区替换map计算结果 使用foreachPartitions替代forea ...
- spark基础理论及优化思路
文章目录 spark 有哪些组件? spark 工作机制? shuffle优化? 程序调优 参数调优 spark 如何保证宕机迅速恢复? Spark Streaming 和 Storm 有何区别? S ...
- Spark的性能优化案例分析(下)
前言 Spark的性能优化案例分析(上),介绍了软件性能优化必须经过进行性能测试,并在了解软件架构和技术的基础上进行.今天,我们通过几个 Spark 性能优化的案例,看一看所讲的性能优化原则如何落地. ...
最新文章
- ucOS_II移植:Stm32启动代码分析
- ubuntu设置始终亮屏_ubuntu设置关闭屏幕和锁定
- 2016 - 2 - 20 ARC知识总结(二 autorelease概念及实现)
- iOS 缓存的获取计算与清除归零
- 7.python实现高效端口扫描器之nmap模块
- java jdbc连接oracle数据库连接 不抛出异常,JDBC连接Oracle发生异常的原因
- matlab怎么画园与椭圆,[转载]【MATLAB】画圆和椭圆
- java webpack web项目_零基础如何学习web前端,入门教程分享
- 错误调试:Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4
- 实战Node—幼教平台
- aix系统服务器日志外发,AIX系统日志
- Fiddler中文乱码解决方法
- java求阶乘1-20_java求1+2!+3!+...+20!的和,java1到20的阶乘
- 用vs2010写c语言调试,vs2010怎么写c语言调试
- 第三方支付竞争走向下半场 汇付天下构建多方共赢新生态
- 澳大利亚麦考瑞大学计算机系杨坚教授团队招收2022-2023年博士研究生
- 安卓6.0+通电自动开机
- python爬取17000个球员_Python爬取NBA球员生涯数据及简单可视化
- js template换行_D3.js实现文本的换行详解
- P02014026黄一洋————信息论问题回答