论文笔记:《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》
论文笔记:《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》

论文来源:arXiv2017
论文作者:Orest Kupyn,Volodymyr Budzan等
下载链接:PDF | github
论文主要贡献:
- 提出使用DeblurGAN对模糊图像去模糊,网络结构基于cGAN和“content loss”。获得了目前最佳的去模糊效果
- 将去模糊算法运用到了目标检测上,当待检测图像是模糊的的时候,先对图像去模糊能提高目标检测的准确率
- 提出了一个新的合成模糊图像的方法
Introduction
最近,生成式对抗网络(GAN)在图像超分辨率重建、in-painting等问题上取得了很好的效果。GAN能够保留图像中丰富的细节、创造出和真实图像十分相近的图像。而在CVPR2017上,一篇由Isola等人提出的《Image-to-Image Translation with Conditional Adversarial Networks》的论文更是使用条件生成式对抗网络(cGAN)开启了“image-to-image translation”任务的大门。


本文的思想主要受近期图像超分辨率重建和“image-to-image translation”的启发,把去模糊问题当做“image-to-image translation”的一个特例。使用的网络是 image-to-image translation 论文中使用的cGAN(pix2pix)。
Proposed method:DeblurGAN的实现
给出一张模糊的图像 ,我们希望重建出清晰的图像
。为此,作者构建了一个生成式对抗网络,训练了一个CNN作为生成器
和一个判别网络
。
网络结构
整体结构如下图:


生成器CNN的结构如下图:


网络结构类似Johnson在风格迁移任务中提出的网络。作者添加了“ResOut”,即“global skip connection”。CNN学习的是残差,即 ,这种方式使得训练更快、模型泛化能力更强。
判别器的网络结构与PatchGAN相同(即 image-to-image translation 论文中采用的判别网络)。
损失函数
损失函数使用的是“content loss”和“adversarial loss”之和:


在文章实验中, 。
Adversarial loss
训练原始的GAN(vanilla GAN)很容易遇到梯度消失、mode collapse等问题,训练起来十分棘手。后来提出的“Wassertein GAN”(WGAN)使用“Wassertein-1”距离,使训练不那么困难。之后Gulrajani等提出的添加“gradient penalty”项,又进一步提高了训练的稳定性。WGAN-GP实现了在多种GAN结构上稳定训练,且几乎不需要调整超参数。本文使用的就是WGAN-GP,adversarial loss的计算式为:

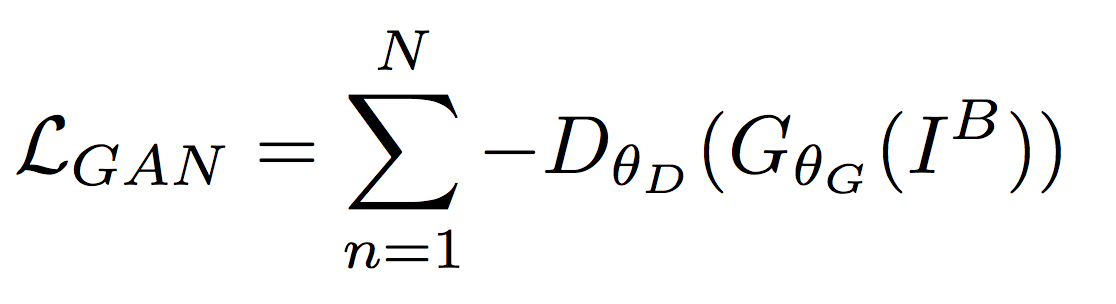
Content loss
内容损失,也就是评估生成的清晰图像和ground truth之间的差距。两个常用的选择是L1(也称为MAE,mean absolute error)损失,和L2(也称为MSE)损失。最近提出了“perceptual loss”,它本质上就是一个L2 loss,但它计算的是CNN生成的feature map和ground truth的feature map之间的距离。定义如下:


其中, 表示将图像输入VGG19(在ImageNet上预训练的)后在第i个max pooling层前,第j个卷积层(after activation)输出的feature map。
表示feature map的维度。
Motion blur generation
相比其他的image-to-image translation任务,例如超分辨率和风格化,去模糊问题很难获得清晰-模糊的图像对用于训练。一种常见的办法是使用高速摄像头拍摄视频,从视频帧中获得清晰图像、合成模糊图像(详见我的另一篇文章:论文笔记:《Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring》)。另一种方法就是用清晰图像卷积上各式各样的“blur kernel”,获得合成的模糊图像。作者在现有第二种方法的基础上进一步拓展,提出的方法能够模拟更复杂的“blur kernel”。
首先,作者采用了Boracchi和Foi[1]提出的运动轨迹随机生成方法(用马尔科夫随机过程生成);然后对轨迹进行“sub-pixel interpolation”生成blur kernel。当然,这种方法也只能在二维平面空间中生成轨迹,并不能模拟真实空间中6D相机的运动。(具体细节arXiv上ver.2还没有提及,有待作者的更新)
Training Details
DeblurGAN的代码在很大程度上借鉴了pix2pix的代码,使用的框架是pyTorch。作者一共在不同数据集上训练了三个model,分别是:
:训练数据是GOPRO数据集,将其中的图像随机裁剪成256×256的patches输入网络训练
:训练数据集是MS COCO生成的模糊图像(根据上面提到的方法),同样随机裁剪成256×256的patches
:在以上两个数据集的混合数据集上训练,合成图像:GOPRO=2:1
所有模型训练时的batch size都为1。作者在单张Titan-X GPU上训练,每个模型需要6天的训练时间。
实验结果对比
GoPro数据集


上图是DeblurGAN和Nah等人提出的 Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring 方法的结果对比。左侧一列是输入的模糊图像,中间是Nah等人的结果,右侧是DeblurGAN的结果。PSNR、SSIM两项指标的评估结果可以参见下表。


Kohler标准数据集


参考文献
[1]G. Boracchi and A. Foi. Modeling the performance of image restoration from motion blur. Image Processing, IEEE Transactions on, 21(8):3502 –3517, aug. 2012.
收藏
http://www.taodudu.cc/news/show-2353243.html
相关文章:
- C++ fstream详解
- 解决BIEE中地图FOI数据过多
- P.W.N. CTF - MISC - Canadian FOI
- FOI对象中显示labels --Oracle Map
- FOI2019算法冬令营D1
- 【FOI】异或问题
- FOI 2019 游记
- [FOI2020WC模拟]看上去很简单
- FOI冬令营 Day4
- FOI冬令营 Day1
- FOI 冬令营 Day6
- [FOI2020]楼房搭建
- [FOI2020]手链强化
- 镜头评价指标及测试方法(一)
- [TSP-FCOS]Rethinking Transformer-based Set Prediction for Object Detection
- html a 标签 邮件超链接 发送邮件
- html中的邮件标签
- 邮件在线编辑器-零基础制作精美图文并茂的HTML邮件不费力
- 玩转HTML邮件格式-编写图文并茂邮件如此简单
- 发送 HTML 形式的邮件
- 注册成功邮件html代码模板
- outlook邮件插入HTML格式内容调试
- 邮件该如何发送html代码
- 邮箱发送html邮件,遇到的问题(如阿里邮箱如何发送html邮件、qq向阿里发送邮件样式丢失等)解决方法
- mac下发html邮件的方法
- 制作HTML邮件邮箱注意问题和解决方案--兼容手机邮箱、电脑邮箱和邮件客户端
- html邮件的排版问题
- HTML邮件模板编写规则,编写邮件HTML模板
- Springboot发送美观的HTML邮件
- 邮件签名——html模板
论文笔记:《DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks》相关推荐
- 论文笔记之Understanding and Diagnosing Visual Tracking Systems
Understanding and Diagnosing Visual Tracking Systems 论文链接:http://dwz.cn/6qPeIb 本文的主要思想是为了剖析出一个跟踪算法中到 ...
- 《Understanding and Diagnosing Visual Tracking Systems》论文笔记
本人为目标追踪初入小白,在博客下第一次记录一下自己的论文笔记,如有差错,恳请批评指正!! 论文相关信息:<Understanding and Diagnosing Visual Tracking ...
- 论文笔记Understanding and Diagnosing Visual Tracking Systems
最近在看目标跟踪方面的论文,看到王乃岩博士发的一篇分析跟踪系统的文章,将目标跟踪系统拆分为多个独立的部分进行分析,比较各个部分的效果.本文主要对该论文的重点的一个大致翻译,刚入门,水平有限,如有理解错 ...
- 目标跟踪笔记Understanding and Diagnosing Visual Tracking Systems
Understanding and Diagnosing Visual Tracking Systems 原文链接:https://blog.csdn.net/u010515206/article/d ...
- 追踪系统分模块解析(Understanding and Diagnosing Visual Tracking Systems)
追踪系统分模块解析(Understanding and Diagnosing Visual Tracking Systems) PROJECT http://winsty.net/tracker_di ...
- ICCV 2015 《Understanding and Diagnosing Visual Tracking Systems》论文笔记
目录 写在前面 文章大意 一些benchmark 实验 实验设置 基本模型 数据集 实验1 Featrue Extractor 实验2 Observation Model 实验3 Motion Mod ...
- Understanding and Diagnosing Visual Tracking Systems
文章把一个跟踪器分为几个模块,分别为motion model, feature extractor, observation model, model updater, and ensemble po ...
- CVPR 2017 SANet:《SANet: Structure-Aware Network for Visual Tracking》论文笔记
理解出错之处望不吝指正. 本文模型叫做SANet.作者在论文中提到,CNN模型主要适用于类间判别,对于相似物体的判别能力不强.作者提出使用RNN对目标物体的self-structure进行建模,用于提 ...
- ICCV 2017 UCT:《UCT: Learning Unified Convolutional Networks forReal-time Visual Tracking》论文笔记
理解出错之处望不吝指正. 本文模型叫做UCT.就像论文题目一样,作者提出了一个基于卷积神经网络的end2end的tracking模型.模型的整体结构如下图所示(图中实线代表online trackin ...
- CVPR 2018 STRCF:《Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking》论文笔记
理解出错之处望不吝指正. 本文提出的模型叫做STRCF. 在DCF中存在边界效应,SRDCF在DCF的基础上中通过加入spatial惩罚项解决了边界效应,但是SRDCF在tracking的过程中要使用 ...
最新文章
- 关于stm32的数据类型
- Yum编译安装Error Downloading Packages报错
- Mybatis 针对ORACLE和MYSQL的批量插入与多参数批量删除
- [BZOJ3206][Apio2013]道路费用
- Knox网关、网关简介、概述、支持的Apache Hadoop服务、支持的Apache Hadoop生态系统的UI、参考资料
- gcc 5.2.0 手动更新(亲测)
- 一文带你掌握OBS的两种常见的鉴权方式
- mysql时间设计模式_java 23种设计模式及具体例子 收藏有时间慢慢看
- openjudge-1664 放苹果
- android助手盒子版,小米盒子助手
- JVM上篇:内存与垃圾回收篇一--JVM与Java体系结构
- 小米9刷鸿蒙,小米手机怎么刷机 小米9刷第三方ROM方法【详解】
- DockOne微信分享(六十六): Docker网络方案初探
- 微信小程序用户昵称表情字符储存的方案
- java基于springboot+vue的协同过滤算法的图书推荐系统 nodejs
- 2016年最新高效的60个网络推广方法汇总
- SFP-GE模块(1310nm, LC) 是什么意思
- 通过cluster reshard实现Redis集群缩减节点实战【详细步骤】
- 用 navicat 导出设计表表结构
- 【linux】血泪经验,在安装Linux上一定要创建/data 分区,将数据盘和系统盘分开,方便重新安装系统,随时恢复Linux系统,其实特别简单,还有7个常用技巧