《多核与GPU编程:工具、方法及实践》----1.5 并行程序性能的预测与测量
本节书摘来自华章出版社《多核与GPU编程:工具、方法及实践》一书中的第1章,第1.5节, 作 者 Multicore and GPU Programming: An Integrated Approach[阿联酋]杰拉西莫斯·巴拉斯(Gerassimos Barlas) 著,张云泉 贾海鹏 李士刚 袁良 等译, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.5 并行程序性能的预测与测量
构建并行程序要比串行程序更具挑战性。并行程序程序员需要解决诸如共享资源访问、负载均衡(即,将计算负载分配到所有计算资源上来最小化执行时间)以及程序终止(即,以协调方式暂停程序)等相关问题。
编写并行程序应该首先确定并行能否提升程序性能,加速问题的解决。并行程序的开发成本决定了程序员不可能简单地实现多个并行版本,通过测试找出最佳和最差版本,来评估项目的可行性。虽然对于最简单的问题,这个方法可能是可行的。但是即使能够这样,如果能够确定一个先验的最佳开发路径,并按照这个路径进行并行开发,是非常有利的。
并行程序的开发始于其对应的串行版本。虽然这看起来有些矛盾,但是我们需要回答这些问题:如果没有一个对应的串行程序版本,我们如何知道并行程序对性能的提升?我们需要一个基准性能,而这个基准性能只能从串行程序中获得。此外,我们如何判定并行程序执行结果的正确性?当然,这并不是说串行程序的执行结果肯定是正确的,但是串行程序能够更容易获得正确的执行结果。
当然,串行算法及相关程序的开发也可以提供一些该程序是否能够并行化的信息。这是很关键的,因为我们需要回答关于并行程序的可行性及成本效益的几个问题:
程序中最耗时的子程序在哪里?这是最应该并行化的部分。
这些子程序一旦被确定后,并假设是可以并行化的。那么,期望的性能提升是多少?
这里需要澄清一个问题:并行所需的串行程序并不是能够解决相同问题的任意程序。它必须能够并行化。例如,如果需要对数据进行并行排序,那么最适合的串行实现为桶排序算法。桶排序算法的串行实现可以帮助我们预测并行实现的性能,并能够指出算法中最耗时的部分。虽然快速排序的串行实现可以提供基准性能信息,但是它不能回答上面提到的两个问题。
一旦实现串行版本后,我们可以利用性能分析工具(profiler)来回答上面两个问题。性能分析工具可以收集程序的调用频率、执行时间以及内存使用等信息。性能分析工具使用许多不同技术来执行这些任务。其中,最常用的技术如下:
程序插桩(instrumentation):修改将要进行性能分析的程序代码以便收集信息。例如,在每条指令执行之前增加一个专用计数器。虽然这可以提供非常精确的信息,但同时会增加程序的执行时间。除此之外,该技术需要重新编译目标程序。
采样(sampling):定期中断目标程序以便查询正在执行的函数。显然,该技术不能提供同程序插桩一样的精确信息,但是目标程序不需要重新编译,且执行时间也不会发生大的变化。
valgrind程序分析工具集包含了一个基于程序插桩技术的性能分析工具。该工具在执行性能分析操作之前进行程序插桩操作,这意味着不需要用户干预。下面是该工具使用的一个例子:

其中,./bucketsort 1000000为目标程序和程序参数。
该工具的输出是一个命名为callgrind.out的文件,该文件包含了分析结果。该结果可以通过前端程序(如kcachegrind)进行可视化。图1-10为可视化结果。
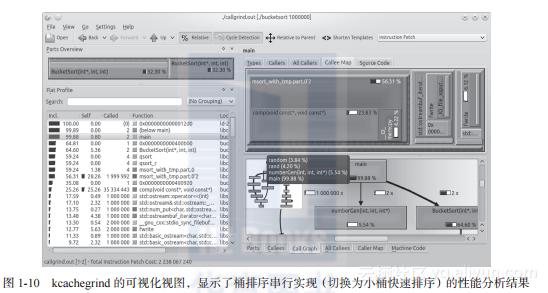
当然,相关领域的经验和知识可以允许程序员无须对串行程序进行性能分析,就可以确定串行程序中需要并行化的热点。
然而,性能分析工具可以回答第二个问题:并行程序可以提供多少潜在的性能提升。传统上,这可以通过近似数学模型实现,该数学模型允许我们捕捉将要执行的计算的本质问题。通过对串行程序执行性能分析操作,可以提供这些数学模型的参数。接下来的一节将讨论Amdahl定律,该定律即使上述的简单模型。
除数学模型的性能预测之外,必须要对并行程序进行实际测试,这主要有两个原因:正确性和性能。并行程序的正确性必须要进行验证。并行程序可以以不确定的方式执行,因为时间可能会影响计算结果。当然,并行程序一般会消除这个不良特性。此外,测试可以暴露并行程序初始设计的弱点以及需要解决的性能问题。
正确测试并行程序的方法如下。
除非特殊说明,否则需要测试并行程序的整体执行时间。如果串行程序只有一部分并行化,可仅针对这部分进行加速比和效率计算。然而,整体运行时间可用来检测并行方案对整体性能的影响,并判断其成本效益。例如,假设一个程序仅仅有10%的部分进行了并行化,即使这部分的加速比为100倍。如果该程序的串行版本的运行时间为100秒,那么并行版本的运行时间也高于90秒。
性能结果应该是多次执行时间的平均值,可能包括标准偏差。执行次数因问题而异。例如,如果对一个执行时间为3天的应用程序执行100次,显然是不现实的。然而,只运行3次求平均值会产生不可靠的统计数据。因此,需要一个谨慎的平衡。
去除“异常值”。即,在计算平均值时,需要去除过大或者过小的性能结果。这是因为这些结果通常表示执行异常(例如,访存越界或者计算机的负载发生了变化)。然而,需要重点对不利结果做出解释而不是简单去除。
可扩展性是非常重要的。所以,需要测试不同输入规模及不同计算平台大小下的性能结果(理想情况下,需要覆盖真实应用场景的所有情况)。
性能测试时的输入应该从小到大,但应该都包括真实应用场景中的问题规模(如果这个规模可以确定)。
当使用多核计算平台时,并行程序开启的线程或者进程数量不应超过可用的硬件提供的计算内核的数目。超线程是一个特例,因为这个技术使操作系统认为处理器的计算内核数目是实际值的两倍。然而,这些逻辑计算内核并不具备真正计算内核的计算能力。所以,虽然操作系统认为这些内核是有效的(例如,有8个计算内核),但是相对应的硬件资源不存在,这样对可扩展性的分析是不利的。理想情况下,当测试可扩展性时,应该关闭超线程,或者开启的线程数目不要超过实际的物理内核数。
下一节讨论的两个定律可在不需要对并行程序进行实现和测试的前提下,预测并行程序性能。尽管已证明Amdahl定律是有缺陷的,但是它依然有影响力。
1.5.1 Amdahl定律
1967年,Gene Amdahl定义了一个简单的实验思想来获取并行程序的可能
性能收益。Amdahl假设:
我们有一个在单CPU上执行时间为T的串行程序。
该串行程序可并行的比例为α,其中0≤α≤1。同时,串行处理剩余的1–α部分。
并行执行没有通信开销,并且并行部分可以平均分配到多个CPU上执行。这个假设适应于多核CPU架构,因为在这种架构下,所有计算内核共享内存。
基于这些假设,在N个计算节点上能够获得的加速比上限是:
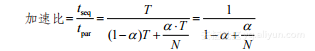
(1-5)
因为我们忽略了所有任务划分/通信/协调开销。所以,如果设定N →∞,式(1-5)定义的可能最大加速比是:
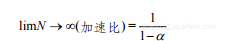
(1-6)
式(1-6)非常重要,它通过简单、容易记忆的方式解决了一个非常复杂的问题:并行程序对于问题的解决可以带来多少性能提升?同时,式(1-6)采用了完全抽象的方式,不依赖于具体的计算平台,仅与问题的特性相关,即α。
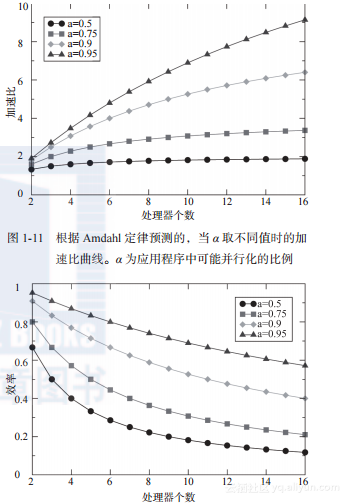
图1-11显示了在α取不同值的情况下,Amdahl定律的性能预测。这是非常引人注意的,因为预测的加速比受到了严格限制。即使α是一个比较好的值,加速比依然很低。例如当α = 0.9时,无论使用多少个处理器,加速比不可能超过10。
同样的情况也出现在图1-12中的效率曲线中。即使α = 95%,效率也会有较大幅度的降低。
Amdahl定律有一个非常有意思的结果,这可能是该定律产生的原因。Amdahl定律是在小型机出现的时代发布的。与大型机相比,小型机便宜但计算性能差。一个问题出现了:哪个是加速问题解决的最佳投资?是昂贵但计算性能高的大型机还是便宜但计算性能低的小型机呢?
用“蚁群与象群”这个比喻来描述这个两难的问题,产生的结果是没有疑问的。基于这个假设的数学证明如下:假设有一个应用程序,在单个高性能CPU A上执行的时间为TA,在单个较低性能CPU B上执行的时间为TB。那么,根据执行时间,CPU A要比CPU B快r=TB/TA倍。如果我们购买NB个性能较低的CPU B,相对于单个高性能CPU A,我们可能达到的最高加速比为:
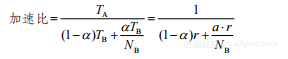
(1-7)
如果NB无限大,我们可以得到的加速比上限为:

(1-8)
这就意味着加速比不会超过1。
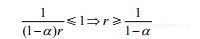
(1-9)
所以,当 α = 90%且 r = 10时,最佳的解决方案是使用单个昂贵但性能高的CPU,而不是使用多个便宜但性能低的CPU。
问题是这个结果与高性能计算的现实并不一致。2014年6月公布的全球超级计算机Top 500排行榜中,由几万到上百万个桌面级处理器的计算内核(其中,排第1名的中国“天河二号”拥有3 120 000个计算内核)构成的超级计算机是主流的。如果蚁群获取了胜利,说明我们的方法存在缺陷。这将在下一节讨论。
1.5.2 Gustafson-Barsis定律
Amdahl定律是错误的,因为已经反复证明它无法解释现实数据:并行程序经常超过预期的加速比限制。
最终,在Amdahl定律发布20年后,Gustafson 和 Barsis开始以一种更为恰当的方式进行问题测试。
并行计算平台并不是仅仅加速串行程序的执行。它可以处理更大的问题。所以,我们应该测试当使用串行计算平台来处理并行计算平台处理的相同问题时,串行计算平台该如何处理。而不是测试并行程序相对于串行程序的性能加速比。
假设:
有一个并行应用程序,在N个CPU上执行的时间为T。
该应用程序在所有计算机上运行的时间占总运行时间的比例为:0 ≤ α ≤ 1,剩下的1 – α需要串行处理。
在串行计算机上解决该问题所需要的总时间为:
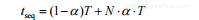
(1-10)
因为原并行计算部分现在需要串行处理。
加速比如下:
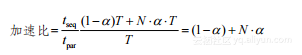
(1-11)
对应的效率如下:
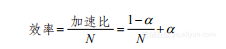
(1-12)
当N无限大时,效率的下限是α。
图1-13显示了这种情况下的加速比曲线,它是图1-11的一个变种。当不考虑通信开销时,其结果确实过于乐观,但这正是潜力所在。
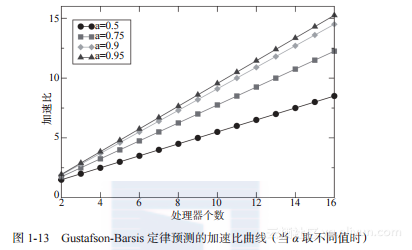
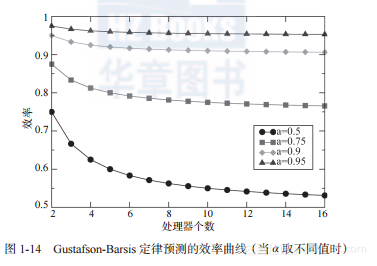
图1-14中的效率曲线依然非常不错。即使当α = 50%时,在16个CPU上的效率也没有低于50%。这也太异想天开了。即使是极易并行的程序,当N不断增大时,通信开销会成为加速比和效率降低的一个重要因素。通常情况下,能够获得90%的效率就已经是非常不错的成就了。
习题
1.研究全球超级计算机性能排名中的Top 10,指出这些超级计算机:
运行什么操作系统?
由多少个CPU/GPU构成?
总内存是多少?
用于编程的软件工具是什么?
2.AMD和NVIDIA的顶级GPU包含多少个计算内核?这些芯片的峰值性能是多少GFlop?
3.世界上最强大的超级计算机性能会有两个值:Rpeak和Rmax,单位都是TFlo/s(每秒进行多少百万亿次浮点计算)。为什么要这样做?从Rpeak到Rmax,性能降低的因素是什么?有没有可能达到Rpeak?
4.一个串行应用程序中,有20%的比例必须串行执行,现需要实现3倍的性能提升。为实现这个目标,需要多少个CPU?如果要实现5倍的加速比,需要多少个CPU?
5.一个运行在5台计算机上的并行程序中,有10%的并行部分。相对于在一个计算机上的串行执行,加速比是多少?如果我们想将加速比提升两倍,需要多少个CPU?
- 将一个不可并行部分占5%的应用程序修改为并行程序。目前市场上有两种并行计算机:计算机X有4个CPU,每个CPU可在1个小时内完成该应用程序的执行;计算机Y有16个CPU,每个CPU可在2个小时内执行完该应用程序。如果需要最小化运行时间,你该买哪个计算机?
7.使用合并排序算法实现一个简单的排序程序,该程序用来对大规模(比如107)32位的整型数据进行排序。输入和输出数据存储在文件中,所以I/O操作为该应用程序的串行部分。尽管合并排序算法不能在任意多个处理器上平均分配计算负载,但该算法依然被认为是非常适合并行执行的排序算法。假设计算负载能够平均分配。应用程序可并行部分的运行时间占整体运行时间的比例为α,该值通过性能分析工具(如gprof 或者valgrind)获得。使用这个值来预测合并排序程序的加速比。
α依赖于输入规模吗?如果依赖,你该如何修改预测值及对应的图形说明?
8.一个并行程序在10个CPU上执行,执行时间为串行执行总时间的15%。我们应该使用性能为多少的CPU,才能保证串行运行时间和并行运行时间相同?
《多核与GPU编程:工具、方法及实践》----1.5 并行程序性能的预测与测量相关推荐
- 《多核与GPU编程:工具、方法及实践》----1.3 现代计算机概览
本节书摘来自华章出版社<多核与GPU编程:工具.方法及实践>一书中的第1章,第1.3节, 作 者 Multicore and GPU Programming: An Integrated ...
- python使方法执行10次_Python提升程序性能的七个手段
1. 使用局部变量 尽量使用局部变量代替全局变量: 便于维护, 也可以避免不必要的资源浪费 使用局部变量替换模块名字空间的变量, 例如: ls = os.linesep. 一方面给可以提高程序性能, ...
- MPI并行程序开发设计----------------------------------并行编程模型和算法等介绍
---------------------------------------------------------------------------------------------------- ...
- c++整理程序 dev_C编程从入门到实践:C语言开发工具详解(2)
DEV C++是一款经典的轻量级C语言开发工具,其安装大小只有几十兆,并且具有图形视图界面,操作比较容易.在DEV C++编码界面中可以使用复制和粘贴等命令,这提高了开发效率. 2.3.1安装DEV ...
- dev c++如何恢复默认设置_C编程从入门到实践:C语言开发工具详解(2)
DEV C++是一款经典的轻量级C语言开发工具,其安装大小只有几十兆,并且具有图形视图界面,操作比较容易.在DEV C++编码界面中可以使用复制和粘贴等命令,这提高了开发效率. 2.3.1安装DEV ...
- 《DevOps实战:VMware管理员运维方法、工具及最佳实践》——2.3 配置管理
本节书摘来自华章计算机<DevOps实战:VMware管理员运维方法.工具及最佳实践>一书中的第2章,第2.3节,作者:小特雷弗 A. 罗伯茨(Trevor A. Roberts Jr.) ...
- python gpu编程_Python笔记_第四篇_高阶编程_进程、线程、协程_5.GPU加速
Numba:高性能计算的高生产率 在这篇文章中,笔者将向你介绍一个来自Anaconda的Python编译器Numba,它可以在CUDA-capable GPU或多核cpu上编译Python代码.Pyt ...
- 多核时代多线程编程(一)基本策略
1.1问题分析 1.2分工原则 1.2.1确定线程数 1.2.2确定任务的数量 1.3共享可变性 1.4小结 1.5参考资料 大家对并发(concurrency).多线程(Multi-Threadin ...
- 深度学习之GPU编程知识总结
概念解析 首先,我们先整理一下:平时在使用一些GPU加速算法是都是在Python环境下执行,但是一般的Python代码是没办法使用GPU加速的,因为GPU是更接近计算机底层的硬件,Python一类的高 ...
最新文章
- java.getRunTime.exe
- VB动态添加WebBrowser控件,并拦截弹出窗口(不用引用任何组件)
- 你会为情怀买单么?反正我会!
- yum whatprovides 查找哪个包可以提供缺失的文件
- linux串口工具 SRT,汇编语言实现串口通信(PC和单片机间).doc
- Bootstrap+MetroNic_1.5.4 Head meta
- 【自适应盲均衡4】基于RLS的多径衰落信道均衡算法(RLS-CMA)的理论推导与MATLAB仿真
- rabbitmq 延迟队列_Delayed Message 插件实现 RabbitMQ 延迟队列
- RabbitMQ从初学到精通一
- Laravel核心技术解析(1)—— Composer 组件管理与自动加载
- LVS详解(五)——LVS NAT模式实战
- mysql的分页存储过程,能够传出总记录数
- 华为网络技术大赛笔记——存储器基础原理
- 联想e470c怎么修改电脑语言,联想电脑语言切换不了怎么办
- oracle8i odac for c,ODAC for delphi
- UnicodeDecodeError: 'gbk' codec can't decode byte 0xfe in position 575056: illegal multibyte sequenc
- 八,分隔符,其他符号和数据的讲解
- arduino传感器大全
- 如何使用ansible管理多台远程服务器
- 汇编总结:无符号除法,有符号除法,取余,无符号乘法,有符号乘法指令
热门文章
- www/index.html would like to use your current location
- ElementUI的DateTimePicker组件添加验证规则以及限制选择范围
- session和cookie到底有什么联系?这一篇文章给你分析的明明白白~
- 每个开发人员都应该知道的 15 个 IntelliJ IDEA 快捷方式
- 有关gcc,make,gdb的知识
- java静态和动态的区别是什么意思_Java中的动态和静态多态性有什么区别?
- 免费直播丨企服 9 大标杆规模化获客模型解读,制胜企服 3.0 时代
- 在新浪潮中,服务教育是你的竞争利器
- 神策分析 1.10 推数据全景化,跨部门联动释放共享价值
- 【VMCloud云平台进阶篇】Monitor监控(一)