《多核与GPU编程:工具、方法及实践》----1.3 现代计算机概览
本节书摘来自华章出版社《多核与GPU编程:工具、方法及实践》一书中的第1章,第1.3节, 作 者 Multicore and GPU Programming: An Integrated Approach[阿联酋]杰拉西莫斯·巴拉斯(Gerassimos Barlas) 著,张云泉 贾海鹏 李士刚 袁良 等译, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.3 现代计算机概览
现代计算机模糊了Flynn分类的界限。为了获取更高性能,根据其测试的层次,现代计算机既是MIMD也是SIMD。
通过小型化和改进半导体材料增加晶体管数目,现代计算机目前主要有两种趋势。
- 增加片上内核数目,结合专门的SIMD指令集(例如,SSE以及MMX、AESNI等),并扩大缓存。Intel X86 CPU以及Intel Xeon Phi协处理器是最好的例子。
- 采用异构架构,通常是CPU+GPU,并分别处理不同任务。AMD的APU(Accelerated Processing Unit,APU)是最好的例子。Intel为其CPU和集成的GPU也提供了基于OpenCL的计算。
然而,为什么将CPU和GPU集成到同一块芯片上有重要意义?在回答这个问题之前,我们先讨论GPU究竟为我们带来了什么。
GPU(Graphics Processing Unit,图形处理器),也称为图形加速卡,是一种快速处理大规模图形数据(在这些数据放入显示缓冲区之前)的专用处理器。GPU芯片的设计和传统CPU有很大的不同。CPU将芯片的大部分用于缓存(有时是多级缓存),只有小部分用于复杂算术和逻辑处理单元(Arithmetic and Logical Processing Unit,ALU)。其中,复杂的指令解码和预测硬件设计避免在访问内存数据时的挂起。
相反,GPU设计者选择了不同的道路:少量片上缓存,大量能够并行执行的简单ALU。之所以采用这种设计,是因为图形处理程序比较简单,且数据重用率低。为了能够充分利用多个计算内核,GPU配备了高性能的内存总线用于访问GPU主存。
图1-3显示了两者设计的不同。尽管图1-3并没有显示出各部分所占芯片的真实比例,但却非常清晰地显示出:在CPU上缓存占绝大部分,GPU上计算逻辑单元占绝大部分。
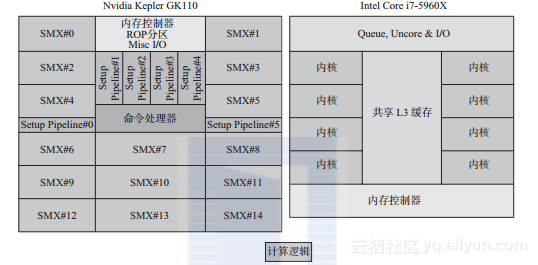
图1-3 NVIDIA Titan GPU和Intel i7-5960X八核CPU在硅芯片上的设计框图。该框图并没有显示各部分在芯片上的真正比例,只是显示了计算逻辑所占的相对比例。每个SMX SIMD块包含64KB的缓存/共享内存。每个i7计算内核包含32KB的数据缓存(L1)、32KB的指令缓存(L1)、256KB的L2缓存,以及20MB的 共享L3缓存
已经证明GPU可以提供前所未有的强大计算能力。然而,CPU和GPU通常使用性能非常低的总线(如PCIe)进行通信,这大大降低了异构计算系统的有效性。这主要是因为只有将数据从CPU内存传递到GPU内存后,GPU才能够处理它们。这导致了数据规模阈值的产生,当数据规模小于这个阈值时,使用GPU并不是一个合适的方法。8.5.2节的案例研究对这个问题进行了详细说明(见图8-16中CPU和GPU平台上的执行时间与数据规模)。
现在,将CPU和GPU集成到同一个芯片上的重要意义就非常明显了。理论上,这种设计可以更好地整合计算资源,并获得更高的性能。但这需要等待时间的检验。
本章下面的内容将回顾在现代多核计算机领域中一些颇具影响力的处理器设计。虽然它们不能领先很长时间,但是它们为以后处理器的设计提供了方向。
1.3.1 Cell BE处理器
Cell BE(宽带引擎)处理器(著名的有索尼PS3的专用处理器)由索尼、东芝和IBM于2007年合作推出。Cell的设计超越时代:采用主/从、异构、MIMD架构。配备给PS3的Cell芯片具备如下特征。
主处理器(master)是一个64位的PowerPC计算内核(称为PPE(Power Processing Element,Power处理单元)),可以运行两个线程。主要负责运行操作系统并管理从处理器。
从处理器(worker)是8个128位的向量处理器(SPE(Synergistic Processing Element,协同处理单元))。每个SPE都有256KB的片上本地内存(不是缓存),称为本地存储(local store),用于存储数据和代码。
SPE计算内核和PPE并不兼容:二者都有自己专门的SIMD指令集。PPE负责进行初始化并调度任务开始执行。SPE间通过一条称为EIB(Element Interconnect Bus,单元互联总线)的高速环形互联总线进行通信,如图1-4所示。SPE不能直接访问主存,但它可以在主存和本地存储间进行DMA传输。
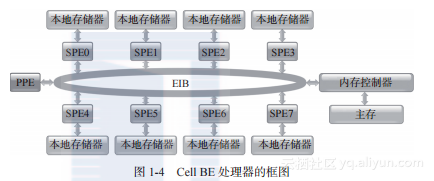
该硬件设计的目标是最大化计算效率,但降低了易编程性。
Cell是臭名远扬的编程最困难的平台之一。
Cell推出时,是市场上最强大的处理器,双精度峰值性能可以达到102.4GFlops。Cell很快成为构建基于PS3集群的“预算超级计算机”的重要组件。运行在上面的应用包括天体物理模拟、卫星成像和生物医学应用。这里需要注意的是,IBM建造的Roadrunner超级计算机(2008~2009年世界最快的计算机),配备了12 240个PowerXCell 8i处理器和6562个AMD皓龙处理器。PowerXCell 8i是原Cell处理器的增强版本:提高了双精度浮点运算性能。
可能是因为其编程难度以及GPU的发展,Cell处理器已经逐渐退出历史舞台。
1.3.2 NVIDIA Kepler
Kepler是NVIDIA专门为计算应用设计的第三代GPU架构。同之前架构相比,新架构采用了全新设计。当程序员针对这个架构编写程序时,与传统SMP的差别非常明显。本节将讨论使GPU具有强大计算能力的架构特征。
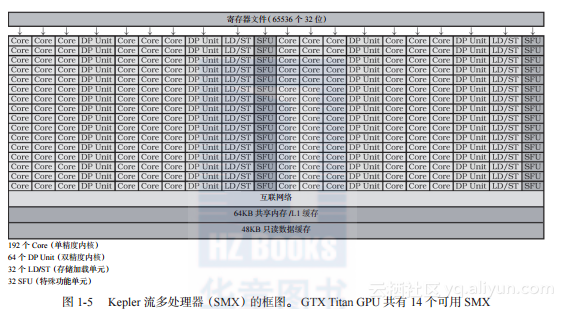
Kepler GPU 的计算内核(CUDA Core)按组组织,称为流多处理器(Kepler架构称为SMX,之前架构中称为SM,下一代Maxwell架构中称为SMM)。每个Kepler SMX包含了可在SIMD模式下执行的192个计算内核。这些内核可以运行相同的指令序列但处理不同的数据。
然而,每个SMX可运行属于自己的程序。SMX的总数量是区别同一系列中不同芯片的主要标志。Kepler系列中性能最高的GPU是GTX Titan,包含15个SMX。其中,为提高产品效益,一个SMX被禁用。所以GTX Titan GPU总共包含14 × 192 = 2688个计算内核。这个SMX在双GPU芯片(GTX Titan Z)上启用,使得该GPU的计算内核达到了惊人的5760个。AMD的双GPU芯片:R9 295X2也包含了5632个计算内核,最大限度满足高性能发烧友的需求。
GTX Titan GPU上的2688个计算内核可以提供高达4.5TFlops的单精浮点运算性能和1.5TFlops的双精浮点运算性能。每个SMX只有64个双精度计算单元(单精计算单元的三分之一)。图1-5显示了Kepler架构的框图。
第5章详细讨论如何在这个架构上进行编程。简单讲,GPU用做协处理器,由CPU分配工作任务。CPU称为主机(host)。为2688个计算内核的每一个都生成一个单独的线程显然是不合适的。相反,GPU编程环境允许调用称为kernel的特殊函数,这些kernel运行时会有不同的内在/内置变量。事实上,每个kernel的调用可生成上万个甚至百万个线程,每个线程将会运行在GPU的一个计算内核上。
主机的执行顺序可总结为:a)将数据发送到GPU上;b)调用kernel;c)等待接收GPU的执行结果。
为实现线程的快速执行,设计GPU片上内存以保持数据尽可能“接近”计算内核(每个计算内核可使用255个32位的寄存器)。为降低访存延迟,Kepler架构增加了L2缓存。然而,相对于传统CPU的每个计算内核,L1缓存/共享内存还是太小。传统CPU每个计算内核的L1缓存已经达到兆字节数量级。共享内存是可寻址内存,对应用程序来说是不透明的,可以认为是可编程缓存。
这些新的架构特点表明GPU将会采用传统CPU的设计特点。较早的GPU是没有缓存的,每个SM的共享内存也限定在16KB。
另外一个新的架构特性是引入了动态并行概念。动态并行允许kernel生成额外的计算任务。为简单起见,你可以认为这允许递归。但是动态并行显然要深刻得多,因为它增加了GPU程序的复杂性。
NVIDIA宣称与之前架构相比,Kepler架构可提供超过3倍GFlop/W的性能,但这仅仅是“蛋糕上的糖衣”。Kepler架构GPU是一款采用CPU设计特点、具有非常高性能的处理器,它通过使用更多、更好的计算内核大大提高了整体计算性能。
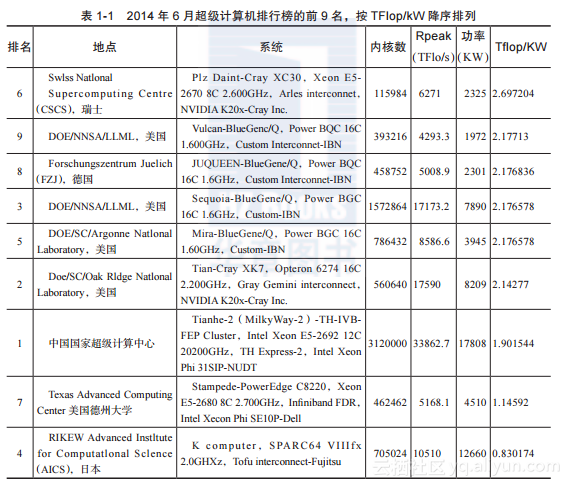
表1-1显示了Kepler架构的功耗和能效。最高效的计算机(测量单位是TFlop/kW)是Piz Daint,一个配备了NVIDIA K20x(GK110架构)GPU的计算机。
在考虑了任务生成和共享后,GPU和CPU就是“平等”的吗?下面的讨论将会回答这个问题。
1.3.3 AMD APU
本章介绍的第三个处理器主要面向游戏机市场:索尼的PS4。AMD的APU处理器将CPU和GPU集成到同一个芯片上。尽管这不是什么大新闻,但是最引人注目的是CPU和GPU具有统一的内存空间。这也就意味着CPU将任务发送到GPU,并从GPU获取任务结果时时没有通信开销。同时,它还消除了GPU编程中的主要困扰之一:显式(或者隐式,基于中间件)数据传输。
AMD APU芯片实现了异构系统架构(Heterogeneous System Architecture ,HSA)。HSA由HAS基金会(HSA Foundation,HSAF)开发,并作为一个开放行业标准收到AMD、ARM、 Imagination Technologies、MediaTek、Texas Instruments、Samsung Electronics和Qualcomm等企业支持。
HSA架构定义了两种类型的计算内核[31]。
面向延迟的处理单元(Latency Compute Unit,LCU),CPU的一般形式。LCU既支持CPU原有的指令集,也支持HSA中间语言(HSA intermediate language ,HSAIL)指令集。
面向吞吐量的处理单元(Throughput Compute Unit,TCU),GPU的一般形式。TCU只支持HASIL指令集。TCU的目标是实现高效并行执行。
使用HSAIL编写的代码在执行之前会首先转化为目标计算单元的原有指令集。正是由于这种兼容性,CPU计算内核可以执行GPU代码,并且HSA应用程序可以运行在任意计算平台上(不用考虑该计算平台是由LCU构成还是由TCU构成)。HSA还满足如下特点。
共享虚拟内存。LCU和TCU共享页表,简化了操作系统的内存管理,并允许TCU使用虚拟内存。现代GPU并不支持虚拟内存,并受到物理内存大小的限制。TCU可能会产生页表错误。
一致性内存。内存堆默认实现了完全一致性。这可以使开发者在LCU和TCU上使用软件开发模式,如生产者–消费者模式。
用户层次的作业队列。每个应用程序都有一个作业调度队列,用来存储来自用户空间的作业请求。这个过程操作系统kernel不需要干预。更重要的是,LCU和TCU不但可以将作业请求存储到自己的队列中,而且可以存储到对方的队列中。CPU和GPU完全是平等的。
硬件调度。TCU引擎硬件可以在不同应用程序的任务队列中自动切换。这个过程不需要操作系统的干预,实现了TCU利用率的最大化。
同时,测试表明CPU计算内核和GPU计算内核的集成能提高计算的能效比。无论是对嵌入式领域还是对服务器领域这都是非常重要的。
图1-6显示了AMD Kaveri芯片的架构框图。HSA可以说是未来的一个发展方向,它可以将任务分配给最合适的计算节点,而不用忍受性能非常低的外围总线。串行任务更适合运行在LCU/CPU计算内核上,同时并行任务更适合运行在高带宽、高计算吞吐量的TCU/GPU计算内核上。
AMD Kaveri家族的A10 7850 APU可以提供856 GFlops的峰值计算性能。然而,在本书写作的时候,传统软件并没有针对该硬件进行优化,从而不同充分发挥它的计算潜能。
1.3.4 从多核到众核?:Tilera TILE-Gx8072和Intel Xeon Phi
十年来,GPU一直拥有数百个简单计算内核,却能够高效完成图像处理等特殊任务。对于一个能够执行操作系统任务和应用软件的通用CPU来说,要实现同样的效果却不容易。在过去的十年里,已经出现了由结合这两种不同设计优势的芯片并且通过良好的网络配置构建的并行计算机。这是一个成功小型化的例子。

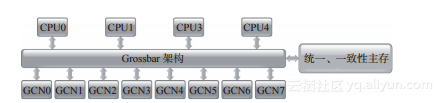
2007年8月发布的Tilera EILE74协处理器是CPU众核模式的第一次尝试。TILE64由二维网格形式的64个计算内核组成。同时,Tilera又推出了包含9、36和72个计算内核的不同版本。图1-7显示了包含72个计算内核的TILE-Gx8072。二维网格中,各个计算内核的通信信道称为iMesh。iMesh由5条相互独立的网状网络组成,可提供超过110Tbit/s的带宽。计算内核可进行非阻塞通信,每个时钟周期切换一次。每个计算内核有32KB的指令L1缓存、32KB的数据L1缓存、256KB的L2缓存。所有计算内核共享18MB的一致性L3缓存。所有计算内核通过4个DDR3控制器访问主RAM。
TILE-Gx8072 CPU主要面向网络(如滤波、限速)、多媒体(例如,转码)和云应用市场。其中重点是网络市场,其芯片设计包含32个1Gbit/s的端口、8个10Gbit/s的XAUI 端口以及两个专用压缩加密与加速引擎(MiCA),证明了这一点。
在GPU模式下,Tilera芯片可以作为协处理器从主CPU/主机端减少(offload)繁重的计算任务。4个PCIe接口可用来加速协处理器和主机端的通信。同时,Tilera芯片可以运行Linux内核,因此可以作为独立的计算平台。Tilera为这个芯片提供了一个软件开发平台:多核开发环境(Multicore Development Environment ,MDE)。MDE基于开源软件工具构建,如GNU C/C++编译器、Elicpse IDE、Boost、TBB(Thread Building Block)以及其他库。因此,它可以使用已有的工具进行多核开发,并保持对大量编程语言、编译器和库的兼容性。第3章和第4章讨论的工具和技术对于针对Tilera 芯片开发软件是非常合适的。
Intel踏入众核领域的时间比较晚(2012年),但依然令人瞩目。如2014年世界超级计算机Top 500排行榜的前十名,就有两台是用Intel Xeon Phi协处理器构建的。其中,中国天河二号超级计算机位列第一。
Intel Xeon Phi协处理器拥有61个x86计算内核,这些计算内核都是高度定制的Pentium内核。这些定制包括:为了隐藏流水线停滞或者访存延迟,每个内核可同时运行4个线程;512位宽;在SIMD模式下每个时钟周期可处理16个单精度浮点数和8个双精度浮点数的向量处理单元(Vector Processing Unit,VPU)。同时,VPU还有一个扩展数学单元(Extended Math Unit,EMU),可用于处理复杂函数,如:倒数、平方根以及指数操作。每个计算内核有32KB的指令L1缓存、32KB的数据L1缓存、512KB的一致性L2缓存。
计算内核间的通信采用了一个知名的通信架构,这个架构曾经应用于Cell BE芯片上,称为环状架构(如图1-8所示)。
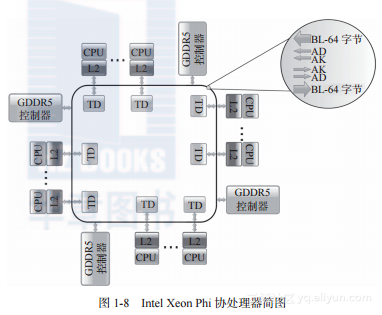
这个环状架构是双向的,由6个独立的环构成,每个方向上各有3个。这3个环分别是一个64字节宽的数据环和两个窄环——一个地址环(Address Ring ,AD)和一个确认环(Acknowledgment Ring,AK)。AD环负责传输读写命令和内存地址,AK环用于确保L2 缓存的一致性。
L2缓存的一致性由分布式标记目录(Tag Directory,TD)管理。TD含有芯片上所有L2缓存行的信息。
当一个计算内核发生L2缓存缺失时,通过AD环发送一个地址请求到TD。如果请求的数据块在其他计算内核的L2缓存(假如为Core1)中,该计算内核通过AD环将一个转发请求发送给Core1,随后,所请求的数据块通过数据环转发。如果所请求的数据块没有在片上,TD将发送内存地址到内存控制器。
每种类型的环都有两个,主要是为了保证可扩展性。测试表明:当只使用AK环和AD环中的一个时,只能维持30~35个计算内核的通信。
GDDR5内存控制器存在于计算内核之间,并通过这些环进行访问。内存地址在这些控制器间均匀分配,以确保所有控制器都不会成为性能瓶颈。
硬件设计令人印象深刻。然而,如何对这61个计算内核进行编程呢?Intel Xeon Phi协处理器可作为一个PCIe卡,并能够运行Linux操作系统。一个专门的设备驱动程序可使PCIe总线成为一种网络接口。这就意味着,如同和主机通过网络互联的其他主机一样,协处理器也可以作为一个主机。用户可通过SSH登录Intel Xeon Phi协处理器。
应用程序既可以运行在主机上,也可以将它们的一部分计算任务分配到Intel Xeon Phi协处理器上运行,甚至完全运行在协处理器上(这称为native模式)。Intel Xeon Phi协处理器可用利用所有的已有共享内存或者分布式内存工具框架。程序员可以使用多线程、OpenMP、Intel TBB、MPI或者其他类似的工具构建程序。这同GPU相比是一个非常大的优势,因为GPU’需要程序员掌握新的工具和技术。
最后,值得注意的是,所有众核处理器架构都具有一个显著的硬件特性:相对较低的时钟频率。如GPU(0.8~1.5 GHz),TILE-Gx8072(1.2 GHz),Intel Xeon Phi(1.2~1.3 GHz)。这是将数十亿个晶体管集成到同一个芯片上所必须付出的代价,因为信号传播延迟会增加。
《多核与GPU编程:工具、方法及实践》----1.3 现代计算机概览相关推荐
- 《多核与GPU编程:工具、方法及实践》----1.5 并行程序性能的预测与测量
本节书摘来自华章出版社<多核与GPU编程:工具.方法及实践>一书中的第1章,第1.5节, 作 者 Multicore and GPU Programming: An Integrated ...
- c++整理程序 dev_C编程从入门到实践:C语言开发工具详解(2)
DEV C++是一款经典的轻量级C语言开发工具,其安装大小只有几十兆,并且具有图形视图界面,操作比较容易.在DEV C++编码界面中可以使用复制和粘贴等命令,这提高了开发效率. 2.3.1安装DEV ...
- dev c++如何恢复默认设置_C编程从入门到实践:C语言开发工具详解(2)
DEV C++是一款经典的轻量级C语言开发工具,其安装大小只有几十兆,并且具有图形视图界面,操作比较容易.在DEV C++编码界面中可以使用复制和粘贴等命令,这提高了开发效率. 2.3.1安装DEV ...
- 《DevOps实战:VMware管理员运维方法、工具及最佳实践》——2.3 配置管理
本节书摘来自华章计算机<DevOps实战:VMware管理员运维方法.工具及最佳实践>一书中的第2章,第2.3节,作者:小特雷弗 A. 罗伯茨(Trevor A. Roberts Jr.) ...
- python gpu编程_Python笔记_第四篇_高阶编程_进程、线程、协程_5.GPU加速
Numba:高性能计算的高生产率 在这篇文章中,笔者将向你介绍一个来自Anaconda的Python编译器Numba,它可以在CUDA-capable GPU或多核cpu上编译Python代码.Pyt ...
- 深度学习之GPU编程知识总结
概念解析 首先,我们先整理一下:平时在使用一些GPU加速算法是都是在Python环境下执行,但是一般的Python代码是没办法使用GPU加速的,因为GPU是更接近计算机底层的硬件,Python一类的高 ...
- 推荐书籍:CUDA并行程序设计:GPU编程指南
过去的五年中,计算领域目睹了英伟达(NVIDIA)公司带来的变革.随后的几年,英伟达公司异军突起,逐渐成长为最知名的游戏硬件制造商之一.计算统一设备架构(Compute Unified Device ...
- 基于c++ amp的gpu编程
目录 摘要: 1 简介 2 性能改进 2.1 异构平台 2.2 gpu架构 2.3 通过平行的性能改进 3 gpu编程架构 3.1 opencl 3.2 cdua 3.3 c++ amp 4 一个c+ ...
- 《代码阅读方法与实践之读书笔记之一》
<代码阅读方法与实践之读书笔记之一> 阅读代码是程序员的基本技能,同时也是软件开发.维护.演进.审查和重用过程中不可或缺的组成部分.<代码阅读方法与实践之读书笔记之一>这本书围 ...
最新文章
- Linux 2.6 完全公平调度算法CFS(Completely Fair Scheduler) 分析
- django ajax 简书,Django_ajax
- Linux:ps命令以及进程状态详解
- 1698 -Access denied for user 'root@xxxx'
- 常用键盘对应keyascii码
- 单干必备:论嵌入式模块化编程、驱动分离的重要性
- mysql amoeba 事务_MySQL-Amoeba
- 孤独的根号三 (Missing NUMBER)
- 关于H.264编码原理以及IPB帧
- 用python写生日快乐说说_祝自己生日快乐的说说
- [BJWC2018]第k大斜率
- Python 源码学习:类型和对象
- Ubuntu下web开发,php编辑器推荐
- android bitmap设置透明度,Android 设置图片 Bitmap任意透明度
- 什么是虚继承?虚基类?
- [THUWC2017]在美妙的数学王国中畅游 LCT+泰勒展开+求导
- 华为云设计语言_多云架构落地设计和实施方案【华为云分享】
- websocket系列:基于tio-websocket-spring-boot-starter实现二进制数据发送
- springmvc中Model的理解
- json,异步加载,回调函数