Python爬虫框架Scrapy 学习笔记 2 ----- 爬取Mininova网站种子文件信息
1. 任务描述
目标网站:http://www.mininova.org/yesterday/
目标网站截图:
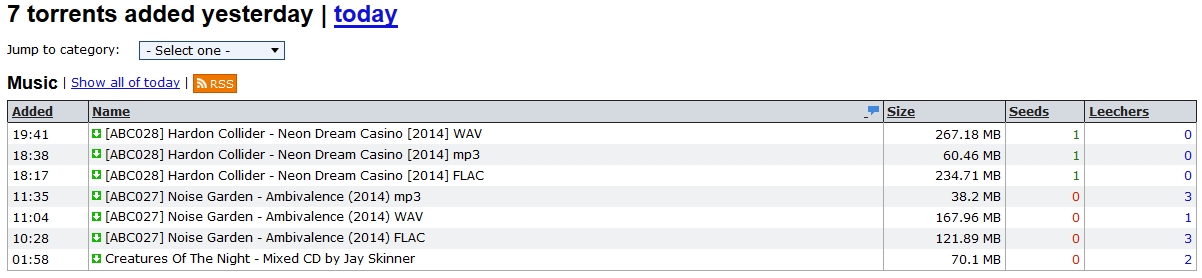
-------------------------------------
可以看到种子文件的列表,这些链接的url可以用正则表达式表示为: /tor/\d+
随便点一个进去,进入资源详情页:http://www.mininova.org/tor/13278086
详情页截图
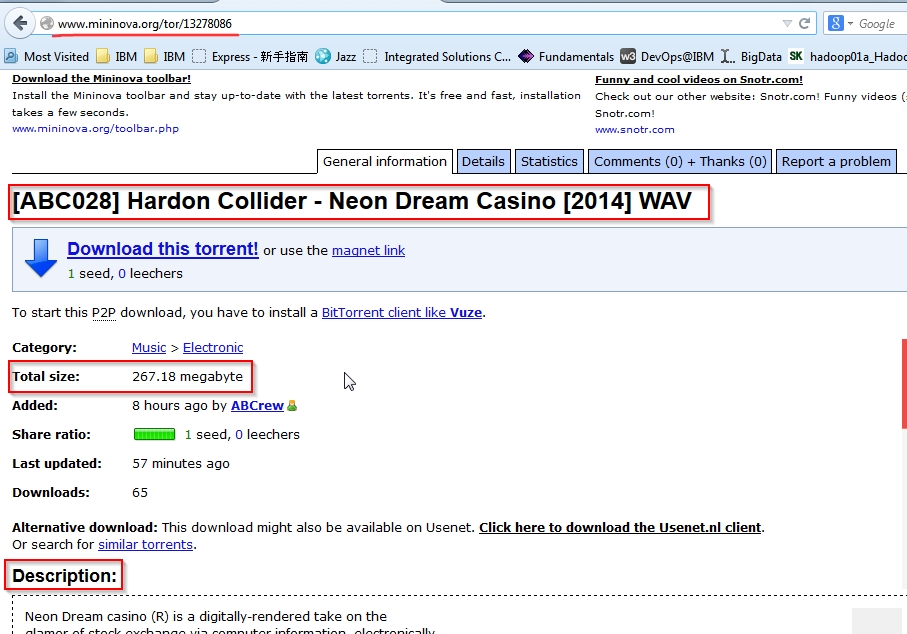
截图中的:资源名称, 资源大小,和资源描述就是我们要抓取的信息。
2. 定义scrapy item.
mininova.py
import scrapyclass TorrentItem(scrapy.Item):url = scrapy.Field()name = scrapy.Field()description = scrapy.Field()size = scrapy.Field()3. 查看网页源文件,确定我们要抓取的内容的XPath表达式。对XML Path Language不熟悉的话可以参考:http://www.w3.org/TR/xpath/
| Item | XPath |
| name | //hi/text() |
| size | //div[@id='specifications']/p[2]/text()[2] |
| descripthin | //div[@id='description'] |
4. 最终的代码为:
mininova.py
import scrapy
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractorclass TorrentItem(scrapy.Item):url = scrapy.Field()name = scrapy.Field()description = scrapy.Field()size = scrapy.Field()class MininovaSpider(CrawlSpider):name = 'mininova'allowed_domains = ['mininova.org']start_urls = ['http://www.mininova.org/yesterday']rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')] def parse_torrent(self, response):torrent = TorrentItem()torrent['url'] = response.urltorrent['name'] = response.xpath("//h1/text()").extract()torrent['description'] = response.xpath("//div[@id='description']").extract()torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract()return torrent5. 运行代码
将mininova.py复制到C:\
打开cmd,输入命令: scrapy runspider --output=spider_out.json mininova.py
文件的后缀名很重要,scrapy会根据后缀名确定输出格式
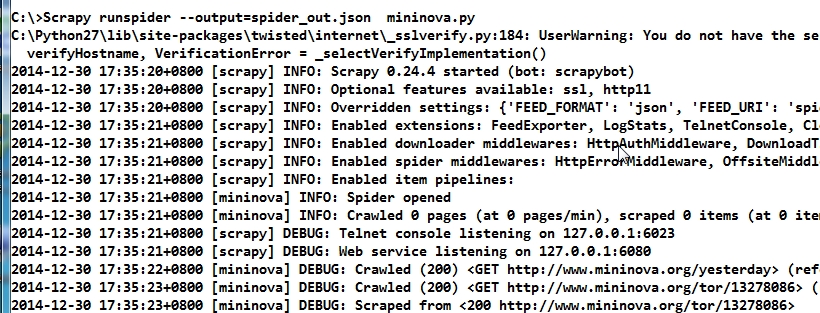
6. 查看输出

转载于:https://blog.51cto.com/dingbo/1597695
Python爬虫框架Scrapy 学习笔记 2 ----- 爬取Mininova网站种子文件信息相关推荐
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twis ...
- Python爬虫框架Scrapy学习笔记
scrapy.png 本文主要内容针对Scrapy有初步了解的同学.结合作者的实际项目中遇到的一些问题,汇成本文. 之后会写一些具体的爬虫demo, 放到 https://github.com/han ...
- Python爬虫框架 scrapy 入门经典project 爬取校花网资源、批量下载图片
####1.安装scrapy 建议:最好在新的虚拟环境里面安装scrapy 注意:博主是在 Ubuntu18.04 + Python3.6 环境下进行开发的,如果遇到安装scrapy不成功请自行百度/ ...
- Python爬虫框架Scrapy 学习笔记 6 ------- 基本命令
1. 有些scrapy命令,只有在scrapy project根目录下才available,比如crawl命令 2 . scrapy genspider taobao http://detail.tm ...
- Hadoop笔记之十七——爬虫框架scrapy实际案例(爬取安卓版QQ阅读)
话不多说,我们的目的: 使用scrapy爬取安卓版QQ阅读所有的小说(只是小说的基本信息,小说内容是不要想的.千万不要想--) 环境准备 安卓收集模拟器:夜神模拟器 安卓手机抓包工具:fiddler ...
- python爬虫天天基金_不使用Python爬虫框架,多线程+代理池爬取天天基金网、股票数据...
提到爬虫,大部分人都会想到使用Scrapy工具,但是仅仅停留在会使用的阶段.为了增加对爬虫机制的理解,我们可以手动实现多线程的爬虫过程,同时,引入IP代理池进行基本的反爬操作. 本次使用天天基金网进行 ...
- scrapy 学习笔记1 爬取 www.dmoz.org 网站信息
1. 安装配置 具体的安装过程, 官网已经写的很清楚了http://doc.scrapy.org/en/latest/intro/install.html#windows 不过在实际安装过程中还是遇到 ...
- Python爬虫攻略(2)Selenium+多线程爬取链家网二手房信息
申明:本文对爬取的数据仅做学习使用,请勿使用爬取的数据做任何商业活动,侵删 前戏 安装Selenium: pip install selenium 如果下载速度较慢, 推荐使用国内源: pip ins ...
- Python爬虫 selenium自动化 利用搜狗搜索爬取微信公众号文章信息
少年最好的地方就是:虽然嘴上说要放弃,心底却总会憋着一口气.--刘同 文章目录 一.需求和网页分析 二.selenium爬虫 一.需求和网页分析 URL:https://weixin.sogou.co ...
最新文章
- maven的setting.xml文件配置信息【仅仅更改了一处】
- 哈哈哈哈!如果孔子是个程序员,一定是P14
- LintCode-56.两数之和
- jquery通过ajax提交form
- Python语言防坑小技巧
- git log 查看某文件的修改历史
- 嵌入式linux添加环境变量,Linux环境变量
- BE的完整形式是什么?
- spring boot配置druid(德鲁伊)
- UDP 协议报文格式
- 两个rsa密文相乘还能解密吗_RSA加密算法 | BitOL|比特在线-关注区块链技术动态的区块链导航...
- html5 播放 3gp,一个html5播放视频的video控件只支持android的默认格式mp4和3gp
- 医学图像开源数据集汇总
- Xcode 模拟器(Simulator)进行录屏,保存成mp4格式
- Java 后端服务的跨域处理
- 小技巧,windows电脑上多开软件的办法
- 如何购买一台腾讯云服务器
- 浅析我国地球科学研究现状及其它
- mysql删除不彻底,mysql删除不彻底的解决方法
- 新时期下大型数据中心机房给排水及消防设计要点分析