深度强化学习之:模仿学习(imitation learning)
深度强化学习之:模仿学习(imitation learning)
2017.12.10

本文所涉及到的 模仿学习,则是从给定的展示中进行学习。机器在这个过程中,也和环境进行交互,但是,并没有显示的得到 reward。在某些任务上,也很难定义 reward。如:自动驾驶,撞死一人,reward为多少,撞到一辆车,reward 为多少,撞到小动物,reward 为多少,撞到 X,reward 又是多少,诸如此类。。。而某些人类所定义的 reward,可能会造成不可控制的行为,如:我们想让 agent 去考试,目标是让其考 100,那么,这个 agent 则可能会为了考 100,而采取作弊的方式,那么,这个就比较尴尬了,是吧 ?我们当然想让 agent 在学习到某些本领的同时,能遵守一定的规则。给他们展示怎么做,然后让其自己去学习,会是一个比较好的方式。
本文所涉及的三种方法:1. 行为克隆,2. 逆强化学习,3. GAN 的方法
接下来,我们将分别介绍这三种方法:
一、Behavior Cloning :
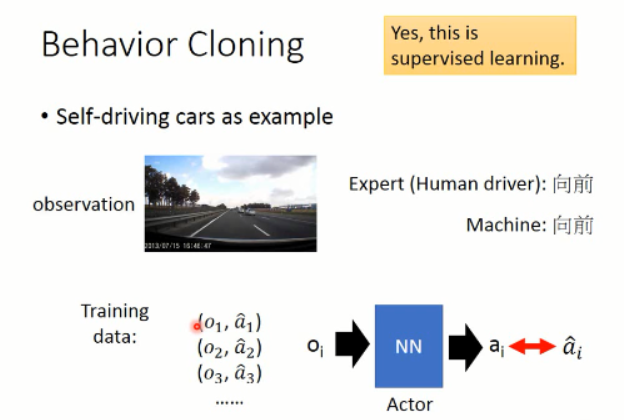
这里以自动驾驶为例,首先我们要收集一堆数据,就是 demo,然后人类做什么,就让机器做什么。其实就是监督学习(supervised learning),让 agent 选择的动作和 给定的动作是一致的。。。
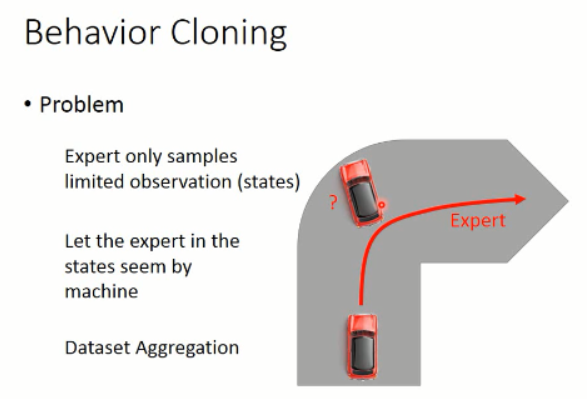
但是,这个方法是有问题的,因为 你给定的 data,是有限的,而且是有限制的。那么,在其他数据上进行测试,则可能不会很好。
要么,你增加 training data,加入平常 agent 没有看到过的数据,即:dataset aggregation 。
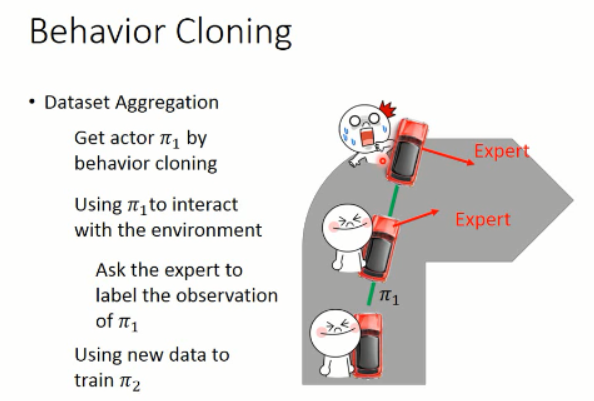
通过不断地增加数据,那么,就可以很好的改进 agent 的策略。有些场景下,也许适应这种方法。。。

而且,你的观测数据 和 策略是有联系的。因为在监督学习当中,我们需要 training data 和 test data 独立同分布。但是,有时候,这两者是不同的,那么,就惨了。。。
于是,另一类方法,出现了,即:Inverse Reinforcement Learning (也称为:Inverse Optimal Control,Inverse Optimal Planning)。
二、Inverse Reinforcement Learning (“Apprenticeship learning via Inverse Reinforcement Learning”, ICML 2004)
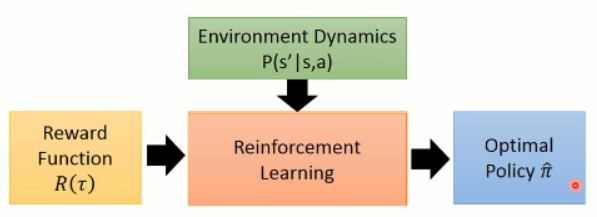
顾名思义,IRL 是 反过来的 RL,RL 是根据 reward 进行参数的调整,然后得到一个 policy。大致流程应该是这个样子:
但是, IRL 就不同了,因为他没有显示的 reward,只能根据 人类行为,进行 reward的估计(反推 reward 的函数)。
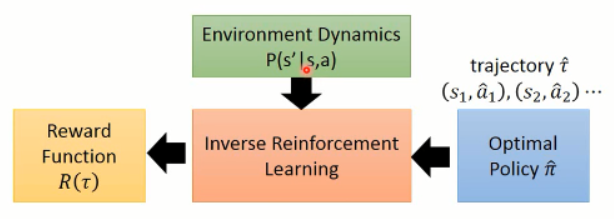
在得到 reward 函数估计出来之后,再进行 策略函数的估计。。。
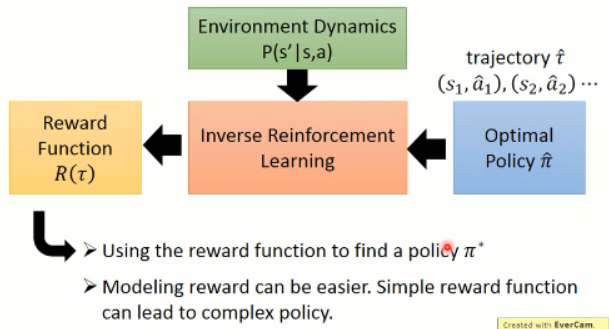
原本的 RL,就是给定一个 reward function R(t)(奖励的加和,即:回报),然后,这里我们回顾一下 RL 的大致过程(这里以 policy gradient 方法为例)

而 Inverse Reinforcement Learning 这是下面的这个思路:

逆强化学习 则是在给定一个专家之后(expert policy),通过不断地寻找 reward function 来满足给定的 statement(即,解释专家的行为,explaining expert behavior)。。。
专家的这个回报是最大的,英雄级别的,比任何其他的 actor 得到的都多。。。
据说,这个 IRL 和 structure learning 是非常相似的:
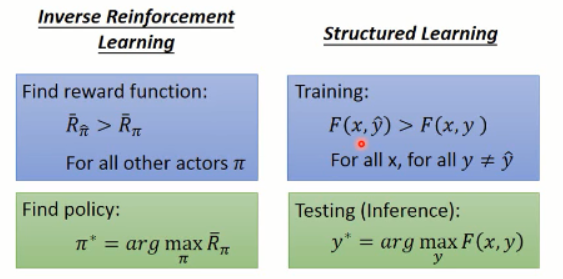
可以看到,貌似真是的哎。。。然后,复习下什么是 结构化学习:

我们对比下, IRL 和 结构化学习:
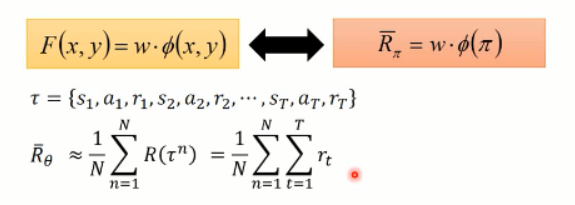
=======================================================================
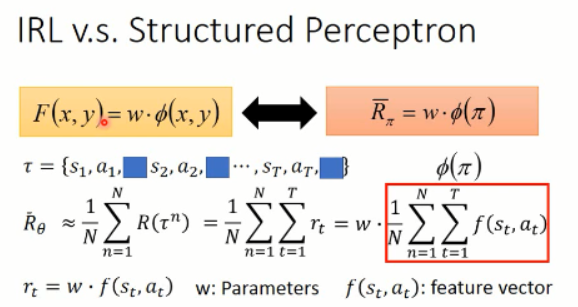
我们可以看到,由于我们无法知道得到的 reward 情况,所以,我们只能去估计这些 奖励的函数,然后,我们用参数 w 来进行估计:
所以, r 可以写成 w 和 f(s, a) 相乘的形式。w 就是我们所要优化的参数,而 f(s,a)就是我们提取的 feature vector。

那么 IRL 的流程究竟是怎样的呢???
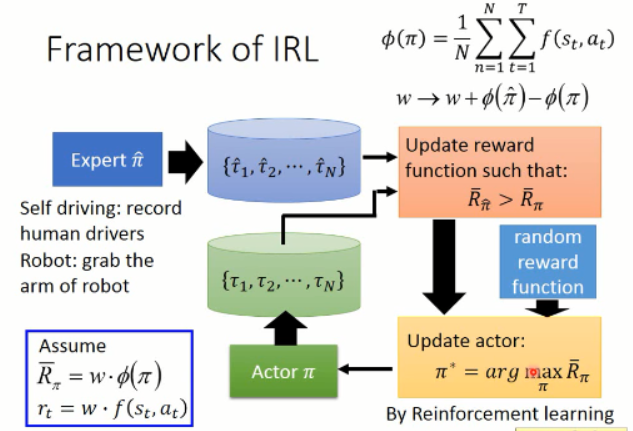
上面就是 IRL 所做的整个流程了。
三、GAN for Imitation Learning (Generative Adversarial imitation learning, NIPS, 2016)
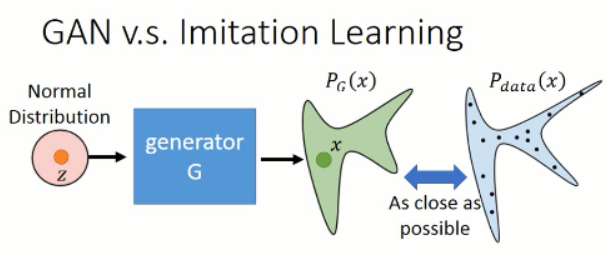
那么如何用 GAN 来做这个事情呢?对应到这件事情上,我们知道,我们想得到的 轨迹 是属于某一个高维的空间中,而 expert 给定的那些轨迹,我们假设是属于一个 distribution,我们想让我们的 model,也去 predict 一个分布出来,然后使得这两者之间尽可能的接近。从而完成 actor 的训练过程,示意图如下所示:
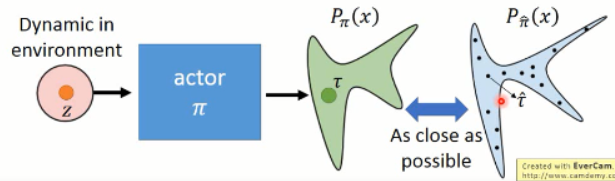
=============================== 过程 ================================
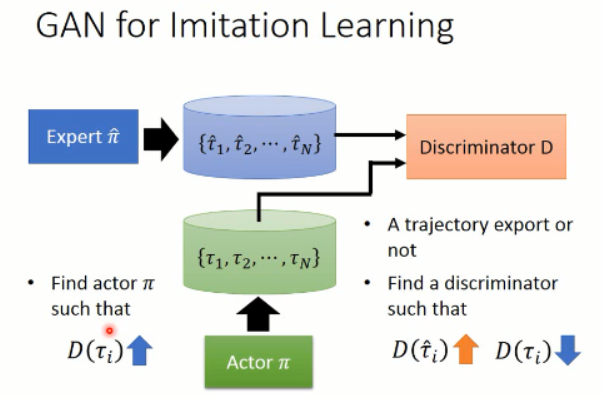
====>> Generator:产生出一个轨迹,
====>> Discriminator:判断给定的轨迹是否是 expert 做的?

==========================================================================
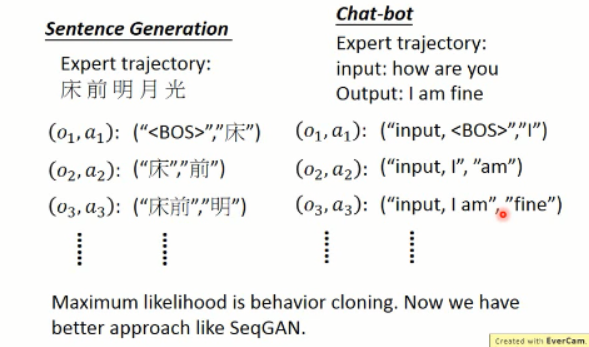
Recap:Sentence Generation and Chat-bot
==========================================================================
===========================================================
===========================================================
Examples of Recent Study :








深度强化学习之:模仿学习(imitation learning)相关推荐
- 深度强化学习8:Imitation Learning
[李宏毅深度强化学习笔记]8.Imitation Learning qqqeeevvv 2020-01-30 18:18:16 3344 收藏 4 分类专栏: 强化学习 # 理论知识 </div ...
- 深度强化学习(Deep Reinforcement Learning)的资源
深度强化学习(Deep Reinforcement Learning)的资源 2015-04-08 11:21:00| 分类: Torch | 标签:深度强化学习 |举报 |字号 订阅 Goo ...
- 深度强化学习之模仿学习(Imitation Learning)
上一部分研究的是奖励稀疏的情况,本节的问题在于如果连奖励都没有应该怎么办,没有奖励的原因是,一方面在某些任务中很难定量的评价动作的好坏,如自动驾驶,撞死人和撞死动物的奖励肯定不同,但分别为多少却并 ...
- 深度强化学习—— 译 Deep Reinforcement Learning(part 0: 目录、简介、背景)
深度强化学习--概述 翻译说明 综述 1 简介 2 背景 2.1 人工智能 2.2 机器学习 2.3 深度学习 2.4 强化学习 2.4.1 Problem Setup 2.4.2 值函数 2.4.3 ...
- 深度强化学习-稀疏奖励及模仿学习-笔记(七)
稀疏奖励及模仿学习 稀疏奖励 Sparse Reward Reward Shaping Curiosity Curriculum Learning Reverse Curriculum Generat ...
- 纯干货-5Deep Reinforcement Learning深度强化学习_论文大集合
本文罗列了最近放出来的关于深度强化学习(Deep Reinforcement Learning,DRL)的一些论文.文章采用人工定义的方式来进行组织,按照时间的先后进行排序,越新的论文,排在越前面.希 ...
- 万字总结83篇文献:深度强化学习之炒作、反思、回归本源
来源:深度强化学习实验室 本文约15000字,建议阅读10+分钟 本文为你深入浅出.全面系统总结强化学习的发展及未来展望. 深度强化学习是深度学习与强化学习相结合的产物,它集成了深度学习在视觉等感知问 ...
- 深度强化学习发展现状及展望:万字总结解读83篇文献
深度强化学习是深度学习与强化学习相结合的产物,它集成了深度学习在视觉等感知问题上强大的理解能力,以及强化学习的决策能力,实现了端到端学习.深度强化学习的出现使得强化学习技术真正走向实用,得以解决现实场 ...
- 深度强化学习泡沫及路在何方?
一.深度强化学习的泡沫 2015年,DeepMind的Volodymyr Mnih等研究员在<自然>杂志上发表论文Human-level control through deep rein ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
最新文章
- 【每日DP】day 5、P1095 守望者的逃离(好像悟到了DP的真谛)难度⭐⭐★
- 游戏企业的“逆袭”,从用好这套解决方案开始 →
- javascript基础--数组排序
- Linux:文件描述符
- 十问十答 Apache 许可证
- 查看oracle自动优化,使用索引查询更快,优化器为何不能自动识别
- linux 控制台存储,技术|使用 Stratis 从命令行管理 Linux 存储
- 四川大学计算机专业贵州分数线,四川大学2016年在贵州省高考各专业录取分数线...
- 国笔手机输入法MTK支持的语言
- 分布式和集中式版本控制工具-svn,git,mercurial比较分析
- 计算机上英语CE,计算器英语
- 云流化助力虚拟展厅,更炫酷的展示方案
- zookeeper启动报错:already running as process
- c++ vector的底层实现
- 大数据人工智能实验室-大数据培训方案
- python灰色波浪线_PyCharm取消波浪线、下划线和中划线的实现
- EMC常见术语-dB、dBm、dBw以及如何计算
- safari浏览器在使用videojs-contrib-quality-levels.js 播放视频时 清晰度失效, 报错Unhandled Promise Rejection: AbortError
- Linux命令行与shell脚本编程之笔记(3)
- 强化学习——蛇棋游戏gym环境搭建