【RL系列】Multi-Armed Bandit问题笔记
原文地址:http://blog.sciencenet.cn/home.php?mod=space&uid=3189881&do=blog&id=1121466
这是我学习Reinforcement Learning的一篇记录总结,参考了这本介绍RL比较经典的Reinforcement Learning: An Introduction (Drfit) 。这本书的正文部分对理论的分析与解释做的非常详细,并且也给出了对结论详尽的解析,但是把问题的解决和实现都留到到了课后题,所以本篇文章主要侧重与对Multi-Armed Bandit问题解决算法的实现以及对实现中可能遇到的问题进行一个总结与记录。此外,如果困于书中对于理论解释的冗长,可以参考下面这两篇文章(推荐阅读顺序为:书 → 下面这两篇 → 本篇):
从Multi-arm Bandits问题分析 - RL进阶
《Reinforcement Learning》 读书笔记 2:多臂Bandit(Multi-armed Bandits)
问题分析
Multi-Armed Bandit问题是一个十分经典的强化学习(RL)问题,翻译过来为“多臂抽奖问题”。对于这个问题,我们可以将其简化为一个最优选择问题。
假设有K个选择,每个选择都会随机带来一定的收益,对每个个收益所服从的概率分布,我们可以认为是Banit一开始就设定好的。举个例子,对三臂Bandit来说,每玩一次,可以选择三个臂杆中的任意一个,那么动作集合Actions = [1, 2, 3],这里的1、2、3分别表示一号臂杆,二号臂杆和三号臂杆。掰动一号号臂杆时,获得的收益服从均匀分布U(-1, 1),也就是说收益为从-1到1的一个随机数,且收益的均值为0。那么二号臂杆和三号臂杆也同样有自己收益的概率分布,分别为正态分布N(1, 1)和均匀分布U(-2, 1)。这里所需要解决关键问题就是,如何选择动作来确保实验者能获得的收益最高。
我们可以从收益的概率分布上发现二号臂杆的收益均值最高,所以每次实验拉动二号即可,最优选择即为二号。但是对于实验者来说收益概率分布是个黑箱,并不能做出直接判断,所以我们使用RL来估计出那个最优的选择。
算法实现
这里以Sample Average Epsilon-greedy算法为例,给出RL解决Multi-Armed Bandit问题的大致框架:
1. 随机生成收益均值序列,这里我们假设所有选择对应的收益概率分布均为方差相同的正态分布,只不过各个分布的均值不一,这里使用Matlab代码来进行解释
% 10-Armed Bandit K = 10; AverReward = randn([1 K]);% Reward for each Action per experiment % Reward(Action) = normrnd(AverReward(Action), 1);
2. 依据epsilon-greedy判断当前应当选择的动作。在每次实验开始时,随机一个大于0小于1的值,如果该值小于epsilon,则随机选择动作;如果大于,选择当前平均收益最高的那个动作。
N = 1000 % 1000 experimentsfor n = 1:N[max i] = max(Q);if(max~=0 & rand(1) < 1 - epsilon)Action = i;elseAction = unidrnd(K);end% Q is a set of records of current average reward.% Action is in {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}% Q(1) represents current average reward for action = 1.
end
3. 使用增量形式实现更新当前平均收益Q值
N = 1000 % 1000 experimentsfor n = 1:N[max i] = max(Q);if(max~=0 & rand(1) < 1 - epsilon)Action = i;elseAction = unidrnd(K);end% Q is a set of records of current average reward.% Action is in {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}% Q(1) represents current average reward for action = 1.Reward(Action) = normrnd(AverReward(Action), 1);N(Action) = N(Action) + 1;Q(Action) = (Reward(Action) - Q(Action))*(1/N(Action)) + Q(Action);
end
评价指标
依据 Reinforcement Learning: An Introduction (Drfit) 中关于这一部分的结论分析,主要的两个评价指标是Average Reward和Optimal Action Rate。这两个指标都是用来评价不同算法的优劣程度的。这里的Average Reward和先前提到的当前收益均值是有所不同的。参照上一部分算法实现中给的例子,每次学习过程需要进行1000次实验,每次学习完成后则会得到一个最优估计值,将最优估计值Q记录下来并进行下一次学习,当进行n次学习后,评价收益均值即为这n个Q值的均值,给出Average Reward的计算方法:
需要注意的是,在计算Average Reward(AR)时,各动作的收益概率分布需要保持不变。不同的算法得到的AR值也不同,通常来说一个算法的AR值越高表明依据该算法获得的最优估计值与实际的最优值间的差距越小,简单来说就是该算法的可靠性越高。
Optimal Action Rate(OAR) 表示最佳动作选择率,当进行多次学习时,计算最优估计值与实际最优值速对应的动作相符的频率,将其近似为一个算法的OAR。通常来说,一个算法的OAR越高,说明该算法估计的成功率越高,稳定性越好。
这里给出不同epsilon值所对应不同的epsilon-greedy算法的AR与OAR的对比。下面先给出实验的具体参数设置:
10-Armed Bandit,也就是说K = 10
Epsilon = [0 0.01 0.1 1]
测试算法为Sample Average
收益服从正态分布N(Reward(Action), 1)
每次学习实验次数最高为500次
学习次数为固定为500次
下图给出了随着实验次数的增加,Average Reward的变化图像:
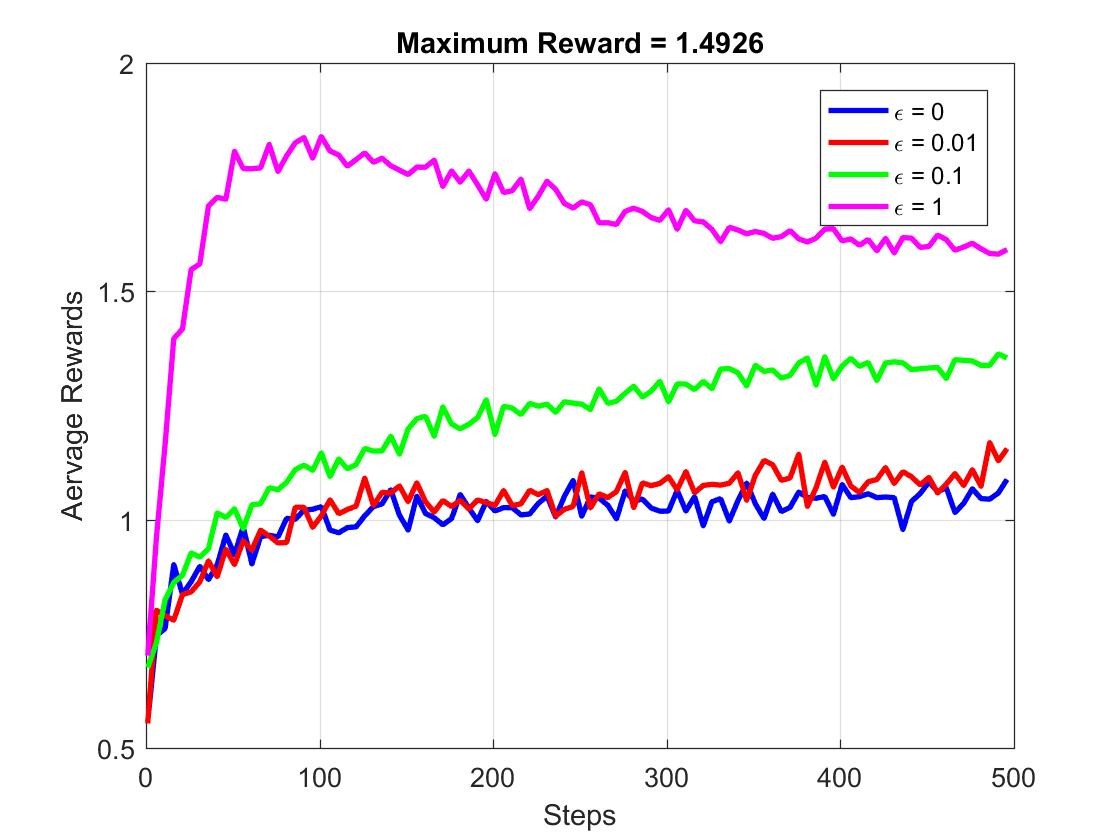
注意:这里的Maximum Reward指的是实际的最优收益均值。Step数为每次实验的次数,从1到500。
我们来简单分析一下这几条曲线。可以发现,当实验次数增大时,各个epsilon所对应的Average Reward(AR)也逐渐稳定,在Step数达到500时,随着epsilon的增加,AR值实际上也是增大的。
理论上我们的最优收益均值为1.4926,而对于epsilon=0, 0.01或0.1的情况,AR值都没能达到1.4926,这说明在每个500次学习过程中,有一些学习过程的最优估计值并不是真的最优,也就是说受到greedy算法的影响,部分学习过程只获取了局部最优。
为了更加清楚的了解不同参数,不同算法获取的最优估计值是全局最优的概率,就需要引入评价指标Optimal Action Rate(OAR),下面给出OAR计算的具体参数:
10-Armed Bandit,K = 10
Epsilon = [0 0.1 1]
测试算法为Recency-Weighted Average,alpha = 0.1
收益服从正态分布N(Reward(Action), 1)
每次学习实验次数最高为1000次
学习次数为固定为500次
下面给出OAR的变化图像:
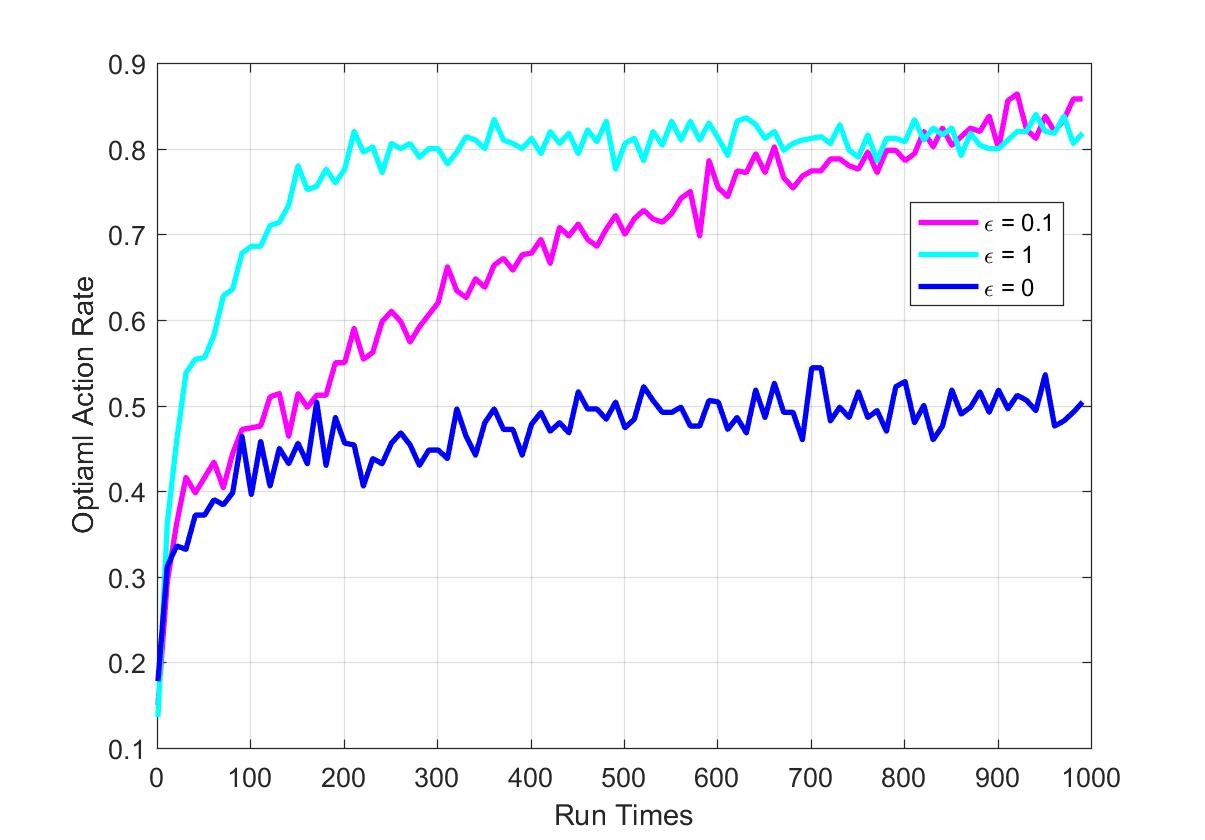
可以发现,当epsilon = 0时,也就是完全greedy策略学习得到的最优动作估计只有大约50%是准确的,也是说,大约50%的情况都仅找到了局部最优。对于epsilon = 1的情况,也就是完全随机选择动作,大约有80%的几率可以找到最优动作,是普遍高于使用greedy策略的。
依据AR和OAR这两个评价指标,我们来总结一下greedy策略和完全随机动作选择的优缺点。
| 优点 | 缺点 | |
| greedy策略 |
|
|
| 随机策略 |
|
|
为了平衡greedy策略的优缺点,才有了epsilon-greedy算法的实现。参考书Reinforcement Learning: An Introduction 随后引入了Optimistic Initial Value的概念和使用方法。具体的理论过程这里就不进行讨论了,我们直接来看看引入后的效果如何,这里以评价指标OAR为例:
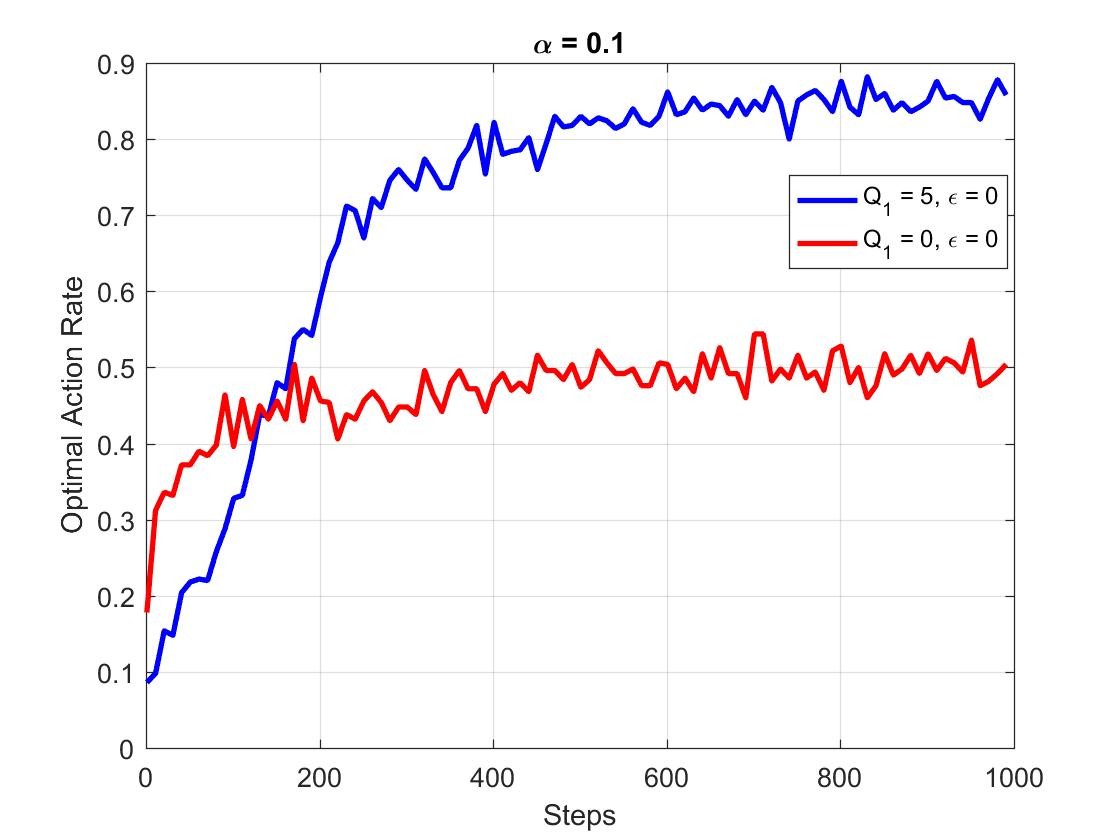
将计算中Q值的初值设为5后,greedy策略的OAR从50%左右上升到接近90%,优化效果还是十分明显的。
小结
先谈一谈计算效率的问题。使用Matlab对AR和OAR这两个评价指标进行计算是十分耗时的,两个指标计算的时间复杂度都是O(n^3),也就是说如果试验次数在1000次以上,想要得到这两个评价指标需要10亿次级别的循环。Matlab在开了并行运算的前提下(双核),并且将step的间隔从1改为10,才将每个参数算法运行的时间控制在15分钟左右。我想如果可以用GPU CUDA进行计算,应该可以将计算时间大幅缩短。
下一篇【RL系列】的文章将着重关注Multi-Armed Bandit问题的其它解决方法。
【RL系列】Multi-Armed Bandit问题笔记相关推荐
- MATLAB写UCB算法,科学网—【RL系列】Multi-Armed Bandit问题笔记——UCB策略实现 - 管金昱的博文...
本篇主要是为了记录UCB策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Introduction ( ...
- MATLAB马尔科夫决策过程遗传,科学网—【RL系列】马尔可夫决策过程与动态编程笔记 - 管金昱的博文...
推荐阅读顺序: Reinforcement Learning: An Introduction (Drfit) 本篇 马尔可夫决策过程 马尔可夫决策(MDP)过程为强化学习(RL)提供了理论基础,而动 ...
- 离线强化学习(Offline RL)系列3: (算法篇) IQL(Implicit Q-learning)算法详解与实现
[更新记录] 论文信息:Ilya Kostrikov, Ashvin Nair, Sergey Levine: "Offline Reinforcement Learning with Im ...
- 离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)
论文原文:[Yifan Wu, George Tucker, Ofir Nachum: "Behavior Regularized Offline Reinforcement Learnin ...
- 离线强化学习(Offline RL)系列3: (算法篇) AWAC算法详解与实现
[更新记录] 论文信息:AWAC: Accelerating Online Reinforcement Learning with Offline Datasets [Code] 本文由UC Berk ...
- Zynq-7000系列之linux开发学习笔记:编译Linux内核和制作设备树(六)
开发板:Zynq7030数据采集板 PC平台:Ubuntu-18.04 + MobaXterm 开发环境:Xilinx Vivado + SDK -18.3 交叉编译工具:arm-linux-gnue ...
- 基于赛灵思7系列+vivado软件的入门笔记
基于赛灵思7系列+vivado软件的入门笔记 0. 基础准备 0.0. 参考资料 0.1. start up 写一个计数器,实现LED灯闪烁 0.2 常见语法相关的注意事项 0. 基础准备 0.0. ...
- 离线强化学习(Offline RL)系列3: (算法篇) Onestep 算法详解与实现
[更新记录] 论文信息: David Brandfonbrener, William F. Whitney, Rajesh Ranganath, Joan Bruna: "Offline R ...
- 离线强化学习(Offline RL)系列4:(数据集) 经验样本复杂度(Sample Complexity)对模型收敛的影响分析
[更新记录] 文章信息:Samin Yeasar Arnob, Riashat Islam, Doina Precup: "Importance of Empirical Sample Co ...
最新文章
- Android 使用反射机制获取或设置系统属性(SystemProperties)
- Android Studio 插件开发详解三:翻译插件实战
- launchMode
- 【数字逻辑设计】关于Logisim的使用说明
- 我的树莓派3配置脚本
- 字符编码(一):序言
- 自定义scrollview右侧的滑动条
- 通过PDMS系统文件快速批量添加颜色规则
- 常用计算机应用软件,电脑必备哪些应用软件?
- 用Netlogo实现病毒传播对经济的影响分析
- C++:实现量化exchangerate汇率测试实例
- 我对TCP CDG拥塞控制算法的改进和优化
- graphpad prism横坐标怎么设置不显示数值_graphpad,prism,符号显示有问题
- google书签找回
- 写给自己的学习计划(迷惘找不到方向的时候就看
- matlab累积概率分布,[转载]Matlab累积分布函数cdf与概率密度函数pdf
- Android设计模式-迭代器模式
- kubectl describe
- 限制Input只能输入汉字、数字
- 教授专栏25 | 李家涛:从中国元素到全球管理理论—中国管理研究三十年[Part Ⅰ]...
热门文章
- 获取所有股票历史行情数据
- python输入一个英文句子、统计并输出单词数_C语言实现输入多行英文句子然后统计单词数和行数,如何输入?我的代码问题在哪里?...
- 小猿圈分享适合零基础学python的书籍
- 电脑开机后鼠标右键点击桌面图标反应很慢,要等上1分钟左右右键内容才能出来怎么办?
- 使用CH341 I2C连接北醒TF系列I2C模式 Python例程
- POI 2011 切题记
- BC26 OPEN开发之--LWM2M连接分析
- linux高级格式化磁盘,linux下格式化磁盘及分区
- 计算机开机密码有几成,电脑密码设置有哪些类型 电脑开机密码忘了怎么解锁...
- React+阿里云Aliplayer播放器实现rtmp直播(推流时间差,重启播放器,计时观看)