观看 B站视频-Mysql-随堂笔记
观看 B站 视频:https://www.bilibili.com/video/BV1fx411X7BD?p=1
SQL\DB\DBMS分别是什么?关系?
DB:database,数据库,数据库实际上在硬盘上以文件形式存在
DBMS:database management system,数据库管理系统,常见的有:Mysql
Oracle,DB2,SqlserverSQL:
结构化查询语句,标题通用语言,高级语言,在sql执行的时候,实际上内部会先进行编译,DBMS
进行编译,再执行sql程序员输出sql,DBMS负责执行sql,通过执行sql来操作DB中的数据
DBMS-(执行)-》SQL-(操作)-》DB

什么是表?
table 是数据库的基本组成单元,所有数据以表格的形式组织,可读性强
一个表包括行和列,
行:被称为数据,记录(data)
列:被称为字段(column)
每一该字段包括哪些属性:字段名,数据类型,相关的约束(比如长度、非空、唯一)
学习Mysql,通用语句增删改查,分类:
DQL(数据查询语言):select,查询数据
DML(数据操作语言):insert delete update,对表数据增删改
DDL(数据定义语言): create drop alter。对表结构的增删改
TCL(事务控制语言):commit提交事务,rollback 回滚事务
(TCL中T,transaction事务)DCL(数据控制语言):grant授权,revoke撤销权限等,
测试数据,建表
员工表 emp
部门表 dept
薪资等级表 salgrade
数据库常用命令:
登录mysql 数据管理系统
- mysql -uroot -p3333
- mysql -uroot -p3333
查看有哪些数据
- show databases;(mysql命令)
- show databases;(mysql命令)
查看当前使用的数据库是哪个?
- select database();
- select database();
查看当前mysql版本号
- select version();
- select version();
初始化数据(使用sql文件,批量初始化数据库,根据脚本的内容在数据库增删改查数据,大部分是用于导入新数据)
source D:/XXX/XXXX/XXX.sql ,source命令 执行sql语句,完成初始化
以下是下面学习sql需要的初始化数据
链接:https://pan.baidu.com/s/1M5JNO4oHvHPHlCql4Xjweg
提取码:hdys
创建数据库 test01
create database test01;
使用数据库 test01
use test01
查看所使用的数据库中的表
show tables;
查看库中的所有表
show tables from mysql;
新建表格
表名在数据库中建议t_ ,tbl_ 开始命名
create table table_name (column_name, column_typ);
CREATE TABLE MyGuests (id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY
KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
email VARCHAR(50),
reg_date TIMESTAMP)CREATE TABLE emp (EMPNO int);
复制表
create table 新表名称 as select 语句,将查询结果作为内容复制到新表
create table emp1 as select * from emp;
增加表字段(增加列column)
ALTER TABLE table_name add ( <新字段名><数据类型>[约束条件]);
ALTER TABLE emp ADD (ENAME varchar(10), JOB varchar(9), MGR int(4),
HIREDATE date, SAL double(7,2), COMM double(7,2), DEPTNO int(2));
删除表字段(删除列column)
alter table 表名 drop column 列名;
alter table test4 drop column addr;
删表
drop table table_name; – 删除表结构+数据,表数据无法找回;
truncate table table_name; –
删除表数据,表数据无法找回,无法和where连用,速度排第二,一般用于删除确认不要的大数据;delete from table where … ; –
删除表中的数据,不删除表结构,速度最慢,但可以与where连用,可以删除指定的行,
给表的某一列增加主键key
alter table table_name add primary key (column_name);
alter table emp add primary key (EMPNO);
查看表结构
desc table_name;
desc emp;
查看创建表的语句:
- show create table emp;
删库
- drop database test01
停止一条sql: \c
退出mysql:exit(); quit; CTRL+c \q
简单的查询语句:DQL = select 字段名1,字段名2 … from 表名;
(sql语句以分号结尾,不区分大小写)select * from emp; – 实际开发不建议使用 * ,效率低
查询员工薪资?
- select ename,sal from emp;
查员工年薪(字段可以进行数学运算)
- select ename, sal*12 from emp;
给查询结果的列起别名 as
- select ename, sal * 12 as yearsal from emp;
select ename, sal * 12 as ‘年薪’ from emp; –
标准中文字符串使用单引号括起来select ename, sal * 12 yearsal from emp; –
起别名,as关键字可以省略
条件查询 where :select 字段1,字段2 。。。 from 表名 where 条件;
精准查询:查询ename为KING的薪资sal;
- select empno, sal from emp where ename=‘KING’;
运算符查询(大于 小于 不等于 某值之间。。):
- select ename, sal from emp where sal >= 2000; --大于某值查询
select ename, sal from emp where sal <> 3000; – 不等于某值查询
select ename, sal from emp where sal != 3000; – 不等于某值查询
select ename, sal from emp where sal >= 1000 and sal <= 5000; –
大于1000小于5000的薪资员工select ename,sal from emp where sal between 1000 and 5000; –
between xx and xxx 查询区间,应用于数字查询,闭区间select empno,ename from emp where ename berween ‘A’ and ‘B’; -
between xx and xxx 查询区间,应用于字母查询,左闭右开区间
空查询 IS NULL, or is not null ,null
和0.00不一样,null代表什么也没有,空- select ename , sal from emp where comm is null; –
找出没有津贴的员工
- select ename , sal from emp where comm is null; –
or 或者,找出工作岗位是MANAGER 和 SALESMAN的员工
select ename, job from emp where job = ‘MANAGER’ or job =
‘SALESMAN’;or 和 and 联合使用 找出薪资大于1000并且
编号是20,30的员工(and优先级高于or,当不确定运算符优先级的时候,加小括号,加小括号优先级高,先执行)select empno, deptno ,ename,sal from emp where sal > 1000 and
(deptno =30 or deptno = 20);
in查询 等同于 or:找出工作岗位是MANAGER 和 SALESMAN的员工
select ename , sal from emp where job in (‘MANAGER’,‘SALESMAN’);
select ename , sal from emp where sal in (800,5000); –
注意in,查询的是等于的数据不是区间数据
- select ename, sal from emp where sal not in (800,5000); – not in
查询不等于的数据
模糊查询 like ‘%xxx%’;
select ename , sal from emp where ename like ‘%A%’; –
找出名字含有A的select id,name from t_user where name like ‘%\_%’ ;
–找出名字中含有下划线(下划线是特殊字符,需要转义才能查出)
select empno, ename from emp where ename like ‘%T’; –
找出最后一个字符是‘T‘ 的名字select empno, ename from emp where ename like ‘K%’; –
找出第一个字符是‘K‘ 的名字
排序(order by 升序asc,降序desc ) order by 不指定的情况下默认升序
select 字段1,字段2,,,from 表名 order by 字段1 desc --降序
select 字段1,字段2,,,from 表名 order by 字段1 --升序
select 字段1,字段2,,,from 表名 order by 字段1 asc --升序
薪资升降序
select ename, sal from emp order by sal desc; — 降序
select ename, sal from emp order by sal asc; — 生序
先按工资降序,当工资一样再按照名字升序
- select ename, sal from emp order by sal desc, ename asc; –
当薪资相同时,后面的名字升序才会执行,(靠前的字段优先级高,对排序起主导作用)
- select ename, sal from emp order by sal desc, ename asc; –
根据列数排序 order by column_number
- select ename ,sal from emp order by 2;
找出工作是SALESMAN的且工资起别名降序排列 顺序 select》 where》as》order
by- select ename, job, sal as salary from emp where job = ‘SALESMAN’
order by salary desc;
- select ename, job, sal as salary from emp where job = ‘SALESMAN’
分组函数(多行处理函数,统计多行数据,输出一个结果值) count计数 sum求和 max
最大值 min 最小值
avg平均值(对一组数据进行操作的sql,特点是1、输入多行输出1行,
2、自动忽略null,3、分组函数不能用于where后面)sum:
- select sum(sal) from emp;
max : 最高工资
- select max(sal) from emp;
min: 最低工资
- select min(sal) from emp;
avg:平均工资
- select avg(sal) from emp;
count: 找出总人数
select count(*) from emp; – count(*)
统计记录总条数,和某个字段条数无关select count(ename) from emp; – count(字段)
,统计某一字段不为null的记录条数
找出高于平均工资的人的薪资
select ename,sal ,avg(sal) avg_sal from emp where sal>avg_sal; –
分组函数不能用于where后select ename,sal from emp where sal > (select avg(sal) from emp);
– 可以嵌套查询,带小括号的优先级高,先执行
单行处理函数(运算多少行,输出是多少行)
计算每个员工的年薪
- select ename,(sal+comm)*12 as yearsal from emp; --sal是薪资, comm
是薪资津贴
,由于comm有为null,在数据库计算中,有null参与的,结果输出都是null,所有数据库都是这样规定的
- select ename,(sal+comm)*12 as yearsal from emp; --sal是薪资, comm
ifnull (作用:把为null 的数据,当做 xxx 处理):属于单行处理函数
- select ename, ifnull(comm,0) from emp; – 把为null的数据当做0处理
- select ename, (sal + ifnull(comm,0) )*12 as yearsal from emp ;
计算年薪
分组过滤-group by 和 having;
group by :
作用:按照某个(些)字段进行分组;
如果一条sql里没有group by,说明整张表数据自成一组(group by被省略)
当一条语句中有group by的话,select后面只能跟分组函数和参与分组的字段
一般分组函数结合group by使用,执行优先级高于分组函数,低于where
,from>where>group by>having>select>order by
找出每个岗位的最高薪资;
- select ename,max(sal) from emp group by job; – 执行顺序:
from>group by>select
- select ename,max(sal) from emp group by job; – 执行顺序:
找出每种工作岗位的最高薪资
- select ename, max(sal) , job from emp group by job;
–该语句虽然有结果,但是结果没有意义,在oracle数据库中会报错,语法错误,当一条语句中有group
by的话,select后面只能跟分组函数和参与分组的字段
- select ename, max(sal) , job from emp group by job;
多个字段联合分组–找出每个部门不同工作岗位的最高薪资
- select max(sal) from emp group by deptno , job;
having:having对分组(group
by)之后的数据进行再次过滤;一般能用where过滤就先用where,因为having过滤效率低,having必须结合group by使用,是黄金搭档找出每个部门的最高薪资,要求显示薪资大于2900的数据(对于条件很多的查询,进行拆分,然后合并)
第一步。找出每个部门的最高薪资
- select deptno, max(sal) from emp group by deptno;
第二步,找出薪资大于2900的薪资
- select sal from emp where sal > 2900;
第三步,组合,找出每个部门的最高薪资,要求显示薪资大于2900的数据
- select deptno, max(sal) from emp where sal > 2900 group by
deptno;
- select deptno, max(sal) from emp where sal > 2900 group by
找出每个部门的平均薪资,要求显示薪资大于2000的数据
第一步,找出每个部门的平均薪资
- select deptno, avg(sal) from emp group by deptno;
第二步,找出薪资大于2900的数据 having必须结合group by使用
- select deptno , avg(sal) from emp group by deptno having
avg(sal) > 2000; – 这里不能用where,where后面不能跟avg(sal)分组函数,所以只能用having
- select deptno , avg(sal) from emp group by deptno having
去重 distinct
- select distinct job from emp; – distinct
要出现在所有关键字前方,当distinct后面有多个字段,代表多个字段联合去重
统计岗位的数量
- select count(distinct job) from emp;
- select count(distinct job) from emp;
- select distinct job from emp; – distinct
连接(多表)查询
根据语法年限分类SQL92 SQL99
根据连接方式划分
内连接
等值连接
非等值连接
自连接
外连接
左外连接
右外连接
全连接
连接查询的笛卡尔乘积现象:
案例:找出每一个员工的部门名称,要求显示员工名和部门名。部门表dept,员工表
emp第一步,查询员工表员工姓名和部门编号 select ename, deptno from
emp; --14条记录第二步,查询部门编号和部门名称:select deptno , dname from dept;
– 4条记录第三步,连接查询:select ename, dname from emp, dept;
–56条记录,即14*4,两张表的查询,无任务条件限制时,底层会根据字段进行一对一匹配,即量表记录的乘积,上述会匹配56次,查询并显示出来,这就是笛卡尔乘积现象第四步,加别名: select e.ename,d.dname from emp e ,dept d;
提高执行效率: 上述语句找ename,
会到emp和dept两张表都找,加了别名就是指定寻找的表,提高了执行效率增加可读性
第五步:避免笛卡尔积现象,让ename和dname联合展示,即增加条件限制,展示最终的14条有效数据
select e.ename, d.dname from emp e , dept d where e.deptno =
d.deptno; --SQL92语法思考,避免笛卡尔积现象,会减少记录的匹配次数吗?
- 不会,底层匹配仍然是乘积次数,只是显示的是有效记录,不会提高底层的效率
内连接之等值链接:最大特点:条件是等量关系 两表查询
案例:找出每一个员工的部门名称,要求显示员工名和部门名。部门表dept,员工表
empSQL92语法 select e.ename, d.dname from emp e , dept d where e.deptno
= d.deptno;SQL99语法 select e.ename, d.dname from emp e jion dept d on e.deptno
= d.deptno; – on 后面的连接条件,是等量关系,a=b (
说明 SQL99 是常用的语法,使用 A表join B表 on 条件,替代A表,B表 where 关键字,官方说辞99语法结构更清晰,表的连接条件和后来的where条件分离了 )99语法格式: 。。。。A (inner) join B on 连接条件 where 其他条件 ,–
inner 可省略
内连接之非等值连接:最大特点是,链接条件中的关系是非等量关系
案例:找出每个员工的工资等级,要求显示员工名、工资,工资等级,emp,salgrade
select e.ename , e.sal , s.grade from emp e join salgrade s on e.sal
between s.losal and s.hisal;select – select
- e.ename , e.sal , s.grade – 。。。
from – from
- emp e --A表
join – join
- salgrade s – B表
on – on
- e.sal between s.losal and s.hisal ; –
on后面的连接条件,是非等值,是其他条件
- e.sal between s.losal and s.hisal ; –
自连接:最大的特点是,一张表看做两张表,自己连接自己
案例,找出每个员工的上级领导,要求显示员工名和对应的领导名
第一步:查询员工名,员工编号,员工领导的编号
- select empno, ename, mgr from emp;
第二步,查询出领导名称,领导编号
- select empno, ename from emp; – 员工既是领导也是员工,
第三步 ,找出关键信息,员工的领导编号 mgr = 领导的员工编号empno
- select a.ename as ‘员工名’,b.ename as ‘领导名’ from emp a join
emp b on a.mgr = b.empno;
- select a.ename as ‘员工名’,b.ename as ‘领导名’ from emp a join
外连接·:主表的数据无条件查询出来,主副表之分,主表匹配不到的内容,副表以null的形式展示出来
案例:找出每个员工的上级领导?(所有员工必须全部查询出来)
内连接 select a.ename as ‘员工名’,b.ename as ‘领导名’ from emp a
join emp b on a.mgr = b.empno; –
没有领导的员工默认不展示,是13条记录,类似于丢失了一条外连接
- select a.ename as ‘员工名’,b.ename as ‘领导名’ from emp a left
(outer) join emp b on a.mgr = b.empno; –
左外连接,以员工表为主表,找员工对应的领导,outer 可以省略
- select a.ename as ‘员工名’,b.ename as ‘领导名’ from emp b right
(outer) join emp a on a.mgr = b.empno; – 右外连接 ,
以员工表为主表,找员工对应的领导
- select a.ename as ‘员工名’,b.ename as ‘领导名’ from emp a left
案例:找出没有员工的部门,
分析,部门表做主表,员工表做副表,员工表里无该部门的员工的话会提供null来与部门表的部门编号匹配,查员工name为null
的对应的deptno,就是没有员工的部门select e.ename ,d.deptno from emp e right join dept d on
e.deptno = d.deptno where e.ename is NULL;
三表查询
上图,代表A表先和B表连接查询,查询出来的表再继续和C表连接查询案例:找出每一个员工的部门名称和薪资等级
- select e.ename, d.dname,s.grade from emp e join dept d on
e.deptno = d.deptno join salgrade s on e.sal between s.losal and
s.hisal;
- select e.ename, d.dname,s.grade from emp e join dept d on
案例:找出每一个员工的部门名称和薪资等级以及上级领导(这里要求没有领导的员工也要查出来,需要使用外连接,防止null的数据被忽略)
- select e.ename, d.dname,s.grade,e1.ename from emp e join dept d
on e.deptno = d.deptno join salgrade s on e.sal between s.losal
and s.hisal left join emp e1 on e.mgr = e1.empno;
- select e.ename, d.dname,s.grade,e1.ename from emp e join dept d
嵌套子查询
select 语句中嵌套select语句,被嵌套的select语句就是子查询
select …(select)… from ,…(select) … where …(select)…;
案例:找出高于平均工资的人的薪资 where (select…)
- select ename,sal from emp where sal > (select avg(sal) from emp);
案例:找出每个部门平均薪资的等级 from (select…)
第一步,找出每个部门的平均薪水(按照部门编号分组,求sal 的均值)
- select deptno, avg(sal) avg_sal from emp group by deptno;
第二步
,找出薪资的等级(将上一个查询结果当成一张新平均薪资表,在下一个sql里那平均薪资去薪资等级表查询薪资等级)- select t.avg_sal , s.grade from (select deptno, avg(sal) avg_sal
from emp group by deptno) t join salgrade s on t.avg_sal between
s.losal and s.hisal;
- select t.avg_sal , s.grade from (select deptno, avg(sal) avg_sal
案例: 找出每个部门平均的薪资等级 from (select…)
1. 第一步,找出每个员工的薪资等级1. select e.ename, e.sal, e.deptno, s.grade from emp e join salgrade son e.sal between s.losal and s.hisal ;2. 第二步,找出每个部门的平均的薪资等级1. select e.ename, e.sal, e.deptno, avg(s.grade) from emp e joinsalgrade s on e.sal between s.losal and s.hisal group by deptno;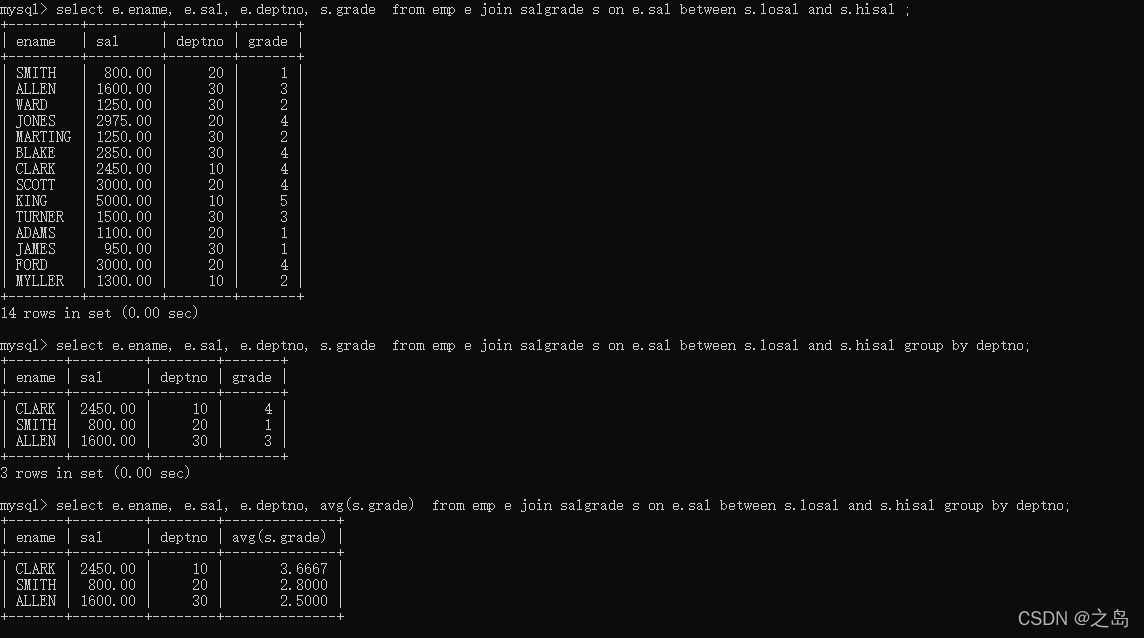2. 案例:找出每个员工所在的部门名称,要求显示员工名和部门名select(select...),把要展示的字段,换成表单表查询的sql语句1. select e.ename, (select d.dname from dept d where e.deptno =d.deptno) as dname from emp e;
- union,可以将查询结果集相加展示
1. 案例:找出岗位是MANAGER 和 SALESMAN的员工1. select ename, job from emp where job='MANAGER' or job='SALESMAN';1. select ename,job from emp where job in('MANAGER','SALESMAN');2. select ename, job from emp where job='MANAGER' union selectename, job from emp where job='SALESMAN';2. 案例,找出员工名和部门名,两张不相关的表中数据拼接一起展示3. select ename from emp union select dname from dept;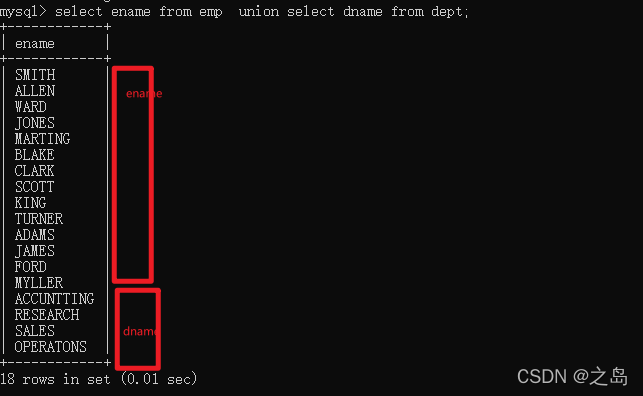
- limit (重点重点,分页查询全靠它)
1. 特点:limit是mysql特有,其他数据库没有,不通用。(oracle中有一个相同机制,叫做rownum)2. 作用:limit取结果集中的部分数据3. 语法特点1. limit startIndex ,length --从0开始,0表示第一条数据,length表示取几条数据4. 案例:取出工资前5名的员工(降序取前5个)5. select ename,sal from emp order by sal desc limit 0,5;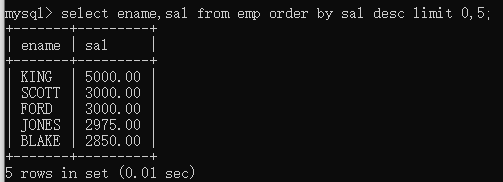8. 案例,找出工资在第4到第9名的员工1. select ename, sal from emp order by sal desc limit 3, 6;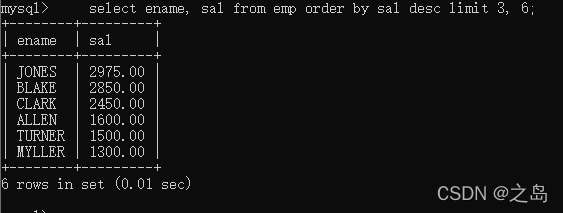
- 通用的标准分页 sql?
2. 每页显示pageSize条记录,第pageNo页:(pageNo - 1)\* pageSize,pageSize
- insert语句插入数据
1. 语法格式:1. 单行数据: insert into表名(字段名1,字段名2,字段名3,....)values(值1,值2,值3.。。) --字段数量和值的数量相同,且数据类型对应上2. 多行数据:insert into table_name(字段) values(第一行字段值),(第二行字段值),(第三行....);2. insert into t_student(id,name,sex,classno,birth)values(1,'zhangsan','1','gaosan','1990-12-23');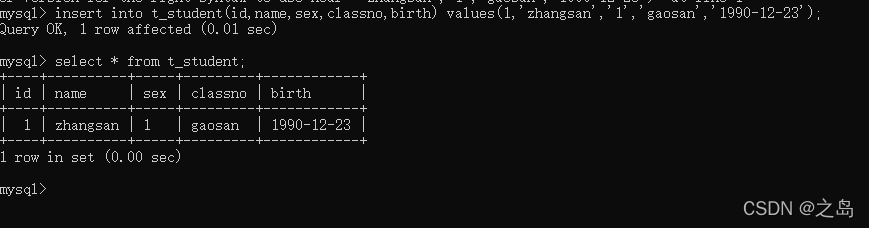4. insert into t_student(id,name,sex,classno)values(2,'lisi','0','gaosan'); -- 字段限制notnull的必须插入值,可以是null的,不插入的话会自动变为null,这些null只能通过update修改,insert只负责插入一条完整的数据,即使字段值为空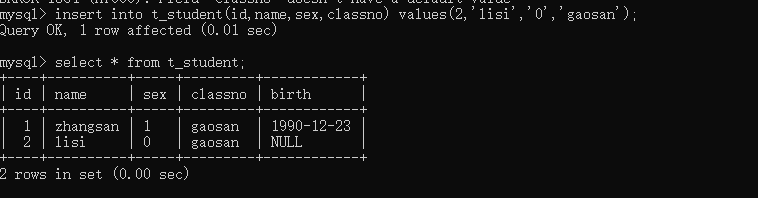6. 一次插入多行数据1. insert into t_student(id,name,sex,calssno,birth) values(3,'zhangsan1','1','gaosan','1997-02-11'),(4,'zhangsan2','0','gaoer','1996-09-29'),(5,'zhangsan3','1','gaoyi','2000-10-03');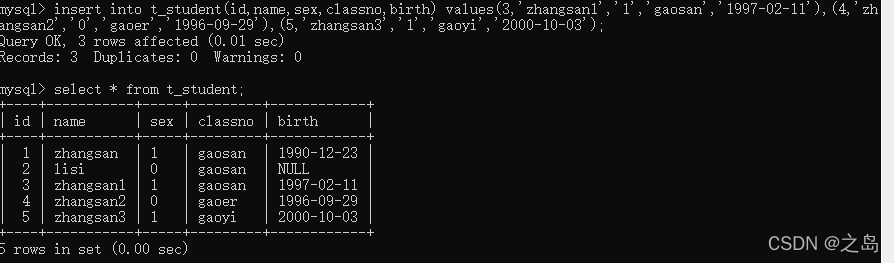7. 表复制:1. 将查询结果作为内容复制到新表1. create table 新表名称 as select 语句,2. create table emp1 as select \* from emp;2. 将查询结果插入到一张表中.1. insert into dept1 select \* from dept; --插入的时候要明确两张表的字段即数据类型一致,否则字段和值不匹配,会报错
- update 修改数据
1. 语法:update 表名 set 字段1=值1,字段2=值2 ... where 条件...;2. 案例:将部门编号10的员工sal修改为1000,将job修改为 SALESMAN;1. update emp1 set sal=100 ,job='SALESMAN' where deptno = 10;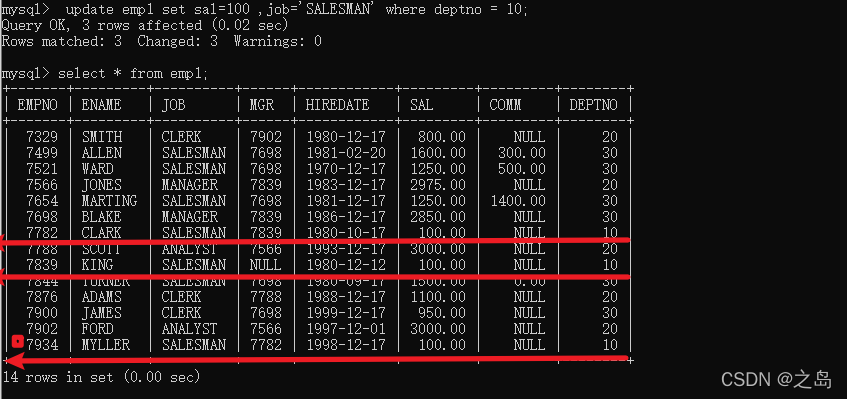3. 修改所有记录1. update emp1 set empno=7721, ename='JACK' ;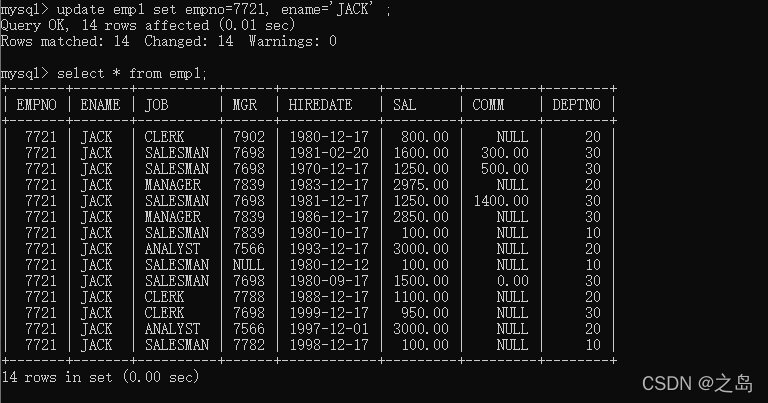
- 删除数据
1. 语法格式:delete from 表名 where 条件;--全部删除2. 删除10部门的数据:delete from emp1 where deptno = 10;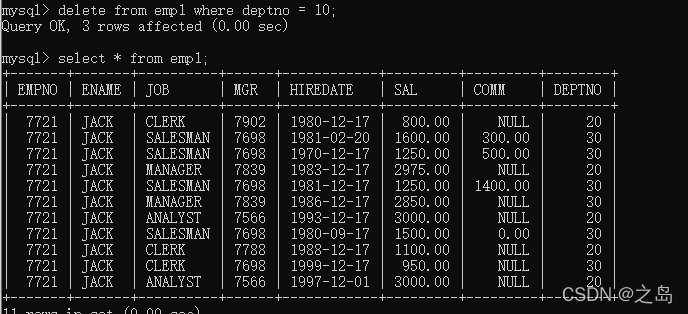4. 删除所有记录: delete from emp1;5. 删除大表(重点):truncate table table_name ;-- 表被截断,不可回滚,永久丢失
- 约束
1. 2. 插入的时候要明确两张表的字段即数据类型一致,否则字段和值不匹配,会报错
- update 修改数据
1. 语法:update 表名 set 字段1=值1,字段2=值2 ... where 条件...;2. 案例:将部门编号10的员工sal修改为1000,将job修改为 SALESMAN;1. update emp1 set sal=100 ,job='SALESMAN' where deptno = 10;2. [外链图片转存中...(img-uk54bX0v-1648536517097)]3. 修改所有记录1. update emp1 set empno=7721, ename='JACK' ;2. [外链图片转存中...(img-dRlCIvtI-1648536517098)]
- 删除数据
1. 语法格式:delete from 表名 where 条件;--全部删除2. 删除10部门的数据:delete from emp1 where deptno = 10;3. [外链图片转存中...(img-zSYjB1XW-1648536517098)]4. 删除所有记录: delete from emp1;5. 删除大表(重点):truncate table table_name ;-- 表被截断,不可回滚,永久丢失
- 约束
1. 2. 
视图
基本概念
视图(VIEW):一个或者多个数据表里的数据的逻辑显示,视图并不存储数据(一般用来隐藏敏感数据,例如:工资,银行卡等)
视图是一种虚拟表,本身是不具有数据的,占用很少的内存空间,它是SQL中的一个重要概念。
视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
视图的创建和删除只影响视图本身,不影响对应的基表。但是当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化,反之亦然。
向视图提供数据内容的语句为SELECT语句,可以将视图理解为存储起来的SELECT语句
在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化;反之亦然。
视图,是向用户提供基表数据的另一种表现形式。通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复杂的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。理解和使用起来都非常方便。
视图的优点:简化查询;控制数据的访问
- 创建视图
在CREATE VIEW语句中嵌入子查询
CREATE [OR REPLACE]
[ALGORITHM = {UNDEFINED MERGE |TEMPTABLE}] (这里是算法)
VIEW view_name [(字段列表)]
AS 查询语句
[WITH [CASCADED |LOCAL ] CHECK OPTION] - 精简版
CREATE
VIEW view_name [(字段列表)]
AS 查询语句
创建单表视图
针对单表创建视图
针对单表创建视图
CREATE VIEW emps_view
AS SELECT * FROM emps;
SELECT * FROM emps_view;
1
2
3
4
5
6
7
8
确定视图中字段名的方式1
CREATE VIEW emps_view2
查询语句中字段的别名会作为视图的字段名
AS SELECT employee_id emp_id,last_name lname,salary
FROM emps
WHERE salary>8000;
1
2
3
4
5
确定视图中字段名的方式2
小括号内字段的个数与SELECT中字段的个数相同
CREATE VIEW emps_view3 (emp_id,NAME,monthly_sal)
AS SELECT employee_id emp_id,last_name lname,salary
FROM emps
WHERE salary>8000;
SELECT * FROM emps_view3;
1
2
3
4
5
6
7
8
情况二:视图中的字段在基表中可能没有对应的字段(用了函数)
CREATE VIEW emp_sal
AS
SELECT department_id,AVG(salary) avg_sal
FROM emps
WHERE department_id IS NOT NULL
GROUP BY department_id;
SELECT * FROM emp_sal;
1
2
3
4
5
6
7
8
针对多表(创建联合视图)
SELECT e.employee_id,e.department_id,d.department_name
FROM depts d JOIN emps e
ON d.department_id=e.department_id;
1
2
3
利用视图对数据进行格式化
CREATE VIEW vu_emp_dept1
AS
SELECT CONCAT(e.last_name,‘(’,d.department_name,‘)’) emp_info
FROM emps e JOIN
depts d
ON e.department_id=d.department_id;
SELECT * FROM vu_emp_dept1;
1
2
3
4
5
6
7
8
基于视图创建视图
2.3基于视图创建视图
CREATE VIEW vu_emp4
AS SELECT first_name , last_name
FROM emps_view;
SELECT * FROM vu_emp4;
1
2
3
4
5
6
查看视图(其实和显示表差不多)
语法一:查看数据库的表对象、视图对象
SHOW TABLES;
1
语法二:查看试视图的结构
DESC / DESCRIBE 视图名称;
1
语法三:查看视图的属性信息
#查看视图的属性信息
SHOW TABLE STATUS LIKE ‘视图名称’;
1
2
3
执行结果显示,注释Comment为VIEW,说明该表为视图,其他信息为null,说明这是一个虚表。
语法四:查看视图的详细定义信息
SHOW CREATE VIEW vu_emp4;
- 索引
MySQL 索引是什么?
官方定义:索引(INDEX)是帮助mysql高效获取数据的数据结构。可以得到索引的本质:索引是数据结构。
拥有排序和查找两大功能,用于解决where和order by后面字段是否执行快。
分类?
普通索引:没有任何限制。add index
唯一索引:索引列中的值必须唯一,允许空值。add unique index
主键索引:特殊的唯一索引,不允许空值。PK
Mysql索引
观看 B站视频-Mysql-随堂笔记相关推荐
- 观看 B站视频-Jmeter实操笔记
B站视频: 花一万多找的 JMeter接口测试+性能测试高阶自动化测试零基础入门全教学_哔哩哔哩_bilibili整理好了相关视频的随堂笔记.最新面试教学大厂面试真题和VIP学员的学习指导路线,放到B ...
- Linux(b站视频兄弟连)自学笔记第十五章——启动管理
Linux(b站视频兄弟连)自学笔记第十五章--启动管理 CentOS 6.x启动管理 系统运行级别 系统启动过程 启动引导程序grub Grub配置文件 Grub加密与字符界面分辨率调整 系统修复模 ...
- Linux(b站视频兄弟连)自学笔记第十章——shell基础
Linux(b站视频兄弟连)自学笔记第十章--shell基础 概述 Shell是什么? Shell的分类 Linux支持的Shell 脚本的执行方式 echo输出命令 第一个脚本 脚本执行 Bash的 ...
- Linux(b站视频兄弟连)自学笔记第六章——软件包管理
Linux(b站视频兄弟连)自学笔记第六章--软件包管理 简介 软件包分类 RPM命令管理 包命令与依赖性 安装升级与卸载 查询 校验和文件提取 yum在线管理 IP地址的配置和网络yum源 yum命 ...
- Linux(b站视频兄弟连)自学笔记第十一章——shell编程
Linux(b站视频兄弟连)自学笔记第十一章--shell基础 正则表达式 字符截取命令 cut命令 printf命令 awk命令 sed命令 字符处理命令 判断条件 流程控制 if语句 case语句 ...
- Linux(b站视频兄弟连)自学笔记第十六章——备份与恢复
Linux(b站视频兄弟连)自学笔记第十六章--备份与恢复 概述 dump和restore命令 概述 dump和restore命令
- Linux(b站视频兄弟连)自学笔记第十四章——日志管理
Linux(b站视频兄弟连)自学笔记第十四章--日志管理 简介 rsyslogd 日志轮替 简介 rsyslogd 日志轮替
- Linux(b站视频兄弟连)自学笔记第十三章——Linux系统管理
Linux(b站视频兄弟连)自学笔记第十三章--Linux系统管理 进程管理 进程查看 终止进程 工作管理 系统资源查看 系统定时任务 进程管理 进程查看 终止进程 工作管理 上一条是后台运行,下面是 ...
- Linux(b站视频兄弟连)自学笔记第十二章——Linux服务管理
Linux(b站视频兄弟连)自学笔记第十二章--Linux服务管理 服务分类 RPM包安装服务的管理 独立服务的管理 基于xinetd 的服务管理 源码包服务管理 服务分类 RPM包安装服务的管理 独 ...
最新文章
- 想找到女朋友,你得掌握这些算法
- Ribbon负载均衡策略配置
- linux emule 编译 wx-config --libs,linux下编译wxwidgets所写程序所遇到的问题
- 【转载】SQL执行计划
- mysql数据库断开连接_解决mysql服务器在无操作超时主动断开连接的情况
- 远程桌面连接数超过最大限制解决方法
- Linux文件查找之findlocate
- java 初始化和清楚_浅谈Java中的初始化和清理
- MapReduce on Yarn 的流程和架构图
- [物理学与PDEs]第5章第3节 守恒定律, 应力张量
- python gzip压缩_Python gzip –压缩解压缩
- java类型转换方法_Java中基本数据类型转换的方法
- TP6 WhereIn排序问题
- Qt项目中,用QPainter进行绘制图形时,边角显示不完整问题的梳理
- C1模拟试卷的一个算法题
- 【简写】编程领域简写
- 一种基于扩展反电动势的永磁同步电机无位置控制算法,全部C语言 编写,含有矢量控制大部分功能(弱磁,解耦,过调制,死区补偿等)
- 企业不得不知的BYOD实施十大风险
- 密码学系列 - 默克尔路径
- MTK8788[android 9.0]汇顶GT9XX TP触摸屏驱动流程分析