基准风险因子暴露度_具有性能基准SQL Server索引填充因子
基准风险因子暴露度
In this article, we will study in detail about the how SQL Server Index Fill factor works.
在本文中,我们将详细研究SQL Server索引填充因子的工作方式。
索引填充系数 (Index Fill factor)
SQL Server Index Fill Factor is a percentage value to be filled data page with data in SQL Server. This option is available in index properties to manage data storage in the data pages. It plays vital role in Query Performance Tuning. Default value is 0 in SQL Server Index Property with each index of Tables, it prevents 100% storage to be filled in each data page. We can modify that value by performance benchmarking over nature of data and size of data.
SQL Server索引填充因子是要用SQL Server中的数据填充数据页面的百分比值。 索引属性中提供此选项,以管理数据页中的数据存储。 它在查询性能调优中起着至关重要的作用。 对于每个表索引,SQL Server索引属性中的默认值为0,这样可以防止在每个数据页中填充100%的存储。 我们可以通过对数据的性质和数据的大小进行性能基准测试来修改该值。
E.g. Fill factor value set to ‘100’ will allow 100% data storage occupancy of the data page and ‘90’ will allow 90% storage occupancy of data page and the rest of the space will be free which can be utilized for data modifications on the page and not for new records insert.
例如,填充因子值设置为“ 100”将允许数据页的数据存储空间为100%,“ 90”将允许数据页的数据存储空间为90%,其余空间将是空闲的,可用于修改页面,而不是用于新记录的页面。
Here, performing the small benchmark with an example. I added one table [tbl_user] in [auth] Database.
这里,以一个小基准测试为例。 我在[auth]数据库中添加了一个表[tbl_user] 。
USE [auth]
GO
CREATE TABLE [dbo].[tbl_user]
(user_id bigint IDENTITY(1,1) PRIMARY KEY,fname varchar(128) NULL,lname varchar(128) NULL,email varchar(128) NULL
)
We will perform benchmark in two stats and analyse the result-set.
我们将在两个统计数据中执行基准测试并分析结果集。
- Without Fill factor没有填充因子
- With Fill factor有填充系数
没有填充因子 (Without Fill factor)
The default SQL Server Index Fill factor value is 0(100%). With the 100% usage of the page could bring the recital issues while performing large sized table or data updates on the table as there will be no space left for data modification/s.
默认SQL Server索引填充因子值为0(100%)。 如果页面使用率达到100%,则在执行大型表或表上的数据更新时可能会出现独奏问题,因为将没有空间用于数据修改。
In this situation, how rows will be restructured? will it on the same page or moved to new one? Will be discussed in detail with example and sample data.
在这种情况下,将如何重组行? 它会在同一页面上还是移到新页面上? 将通过示例和示例数据进行详细讨论。
Primary key defined on column user_id on the table; check the default values by index Property the Fill Factor value is set to ‘0 (Zero)’, which can be added to Index by SQL command as well while adding index.
在表的user_id列上定义的主键; 通过索引检查默认值属性填充因子值设置为“ 0(零)”,添加索引时也可以通过SQL命令将其添加到索引。
Query to Get Page Number Allocated to Table:
查询以获取分配给表的页码:
Example: 256 rows inserted into table and current Index Fill factor value is 0(100%). The query as below:
示例:在表中插入256行,当前索引填充因子值为0(100%)。 查询如下:
SELECT a.database_id, a.object_id, a.extent_page_id, a.allocated_page_page_id, a.next_page_file_id, a.previous_page_page_id FROM sys.dm_db_database_page_allocations(DB_ID('auth'), OBJECT_ID('tbl_user'),NULL, NULL, 'DETAILED') a INNER JOIN sys.indexes i ON i.object_id = a.object_id AND i.index_id = a.index_id WHERE page_type = 1 --page_type_desc = 'DATA_PAGE'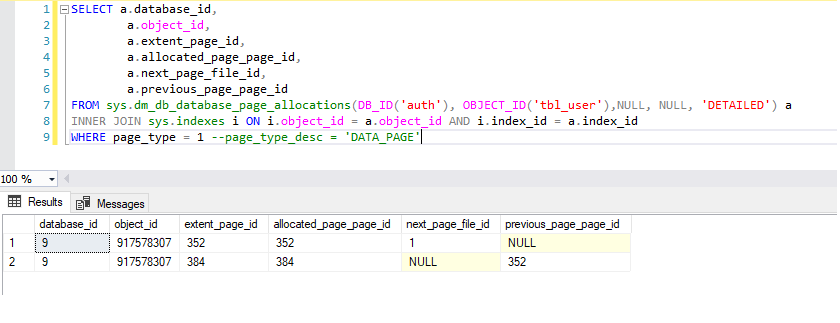
In query, specified page_type = 1, which returns Data Pages only.
在查询中,指定的page_type = 1,仅返回数据页。
We can find number of data pages for the table by DBCC command as well. Query as below:
我们也可以通过DBCC命令找到该表的数据页数。 查询如下:
DBCC IND(auth, tbl_user, -1)Two pages 352 & 384 (Result in the Screenshot above) are allocated to store 256 rows. Now when DBCC PAGE command used it returns the same rows and with this it also returns the Header and Hex dump of data page based on given parameters. Keep in mind before executing Trace Flag ‘3604’ should be enabled in session to get query output in client
两个页面352和384 (上面的屏幕快照中的结果)分配为存储256行。 现在,当使用DBCC PAGE命令时,它返回相同的行,并以此返回基于给定参数的数据页眉和十六进制转储。 请记住,在会话中应启用执行跟踪标志“ 3604”,以在客户端中获取查询输出
DBCC TRACEON(3604) DBCC PAGE(db_name/db_id, file id, page_id, 0/1/2/3)Fourth parameter will decide the detailed output of this command:
第四个参数将决定该命令的详细输出:
0 – Page Header only
0 –仅页面标题
1 – Page Header and all rows hex dump with slots
1 –页面标题和所有带有插槽的十六进制转储
2 – Page Header and all rows hex dump
2 –页眉和所有行的十六进制转储
3 – Page Header and row explanation
3 –页面标题和行说明
DBCC PAGE('auth', 1, 352, 1)or
要么
DBCC PAGE(9, 1, 352, 1)
Query Output 1.01:
查询输出1.01:
| PAGE: (1:352) | ||
| PAGE HEADER: | ||
| Page @0x00000260EDF48000 | ||
| m_pageId = (1:352) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x200 |
| m_objId (AllocUnitId.idObj) = 180 | m_indexId (AllocUnitId.idInd) = 256 | |
| Metadata: AllocUnitId = 72057594049724416 | ||
| Metadata: PartitionId = 72057594043301888 | Metadata: IndexId = 1 | |
| Metadata: ObjectId = 917578307 | m_prevPage = (0:0) | m_nextPage = (1:354) |
| pminlen = 12 | m_slotCnt = 147 | m_freeCnt = 15 |
| m_freeData = 7883 | m_reservedCnt = 0 | m_lsn = (36:2320:23) |
| m_xactReserved = 0 | m_xdesId = (0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 1792311503 | DB Frag ID = 1 | |
| 页面:(1:352) | ||
| 页面标题: | ||
| 页面@ 0x00000260EDF48000 | ||
| m_pageId =(1:352) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x200 |
| m_objId(AllocUnitId.idObj)= 180 | m_indexId(AllocUnitId.idInd)= 256 | |
| 元数据:AllocUnitId = 72057594049724416 | ||
| 元数据:PartitionId = 72057594043301888 | 元数据:IndexId = 1 | |
| 元数据:ObjectId = 917578307 | m_prevPage =(0:0) | m_nextPage =(1:354) |
| pminlen = 12 | m_slotCnt = 147 | m_freeCnt = 15 |
| m_freeData = 7883 | m_reservedCnt = 0 | m_lsn =(36:2320:23) |
| m_xactReserved = 0 | m_xdesId =(0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 1792311503 | DB Frag ID = 1 | |
See here, all the field holds quite a meaningful data in PAGE HEADER section. m_slotCnt = 147 represents the number of rows/records in a page and rest of 109 records are placed in second page.
看到这里,所有字段在PAGE HEADER部分中都保存了相当有意义的数据。 m_slotCnt = 147表示页面中的行数/记录数,其余109条记录位于第二页中。
What will happen if we update the rows in first page?
如果我们更新首页中的行会发生什么?
Now let us try to update the data in the existing table by concatenating user_id with email in the email column in table. This will require more space to update the rows on the page, however the Fill Factor is set to ‘100%’ and we have fill the page with 100% data, therefore no free space left on page. Let us update the table and check the source of pages.
现在,让我们尝试通过在表的电子邮件列中将user_id与电子邮件串联来更新现有表中的数据。 这将需要更多空间来更新页面上的行,但是“填充因子”设置为“ 100%”,并且我们已用100%的数据填充页面,因此页面上没有剩余空间。 让我们更新表格并检查页面来源。
UPDATE tbl_user SET email = CAST(user_id AS VARCHAR(10)) + email
After updating table, the list of pages we get for the table using the query returns 3 rows instead of 2 (refer to the previous result-set). Now the data has got distribute in 3 pages and rows are restructured. Even DBCC PAGE command helps to track number of rows in individual page.
更新表格后,使用查询为表格获取的页面列表将返回3行而不是2行(请参阅上一个结果集)。 现在,数据已分3页分发,并重新组织了行。 甚至DBCC PAGE命令也有助于跟踪单个页面中的行数。
DBCC TRACEON(3604)
DBCC PAGE(9, 1, 352, 1)
Before the update statement run, there were a 147 rows in a table (Refer to Query out-put 1.01) now as the rows got restructured in 3 pages and first page is now filled out with 73 rows. This row split process will take more time to perform this operation and could consume more CPU and Memory resource as well moreover for the heavy transaction-based table, update over the table without SQL Server index Fill Factor could generate locks as well.
在运行update语句之前,表中现在有147行(请参阅查询输出1.01),因为这些行在3页中进行了重组,而第一页现在已填充73行。 此行拆分过程将花费更多时间来执行此操作,并且可能消耗更多的CPU和内存资源,而且对于基于事务的繁重表来说,在没有SQL Server索引填充因子的情况下更新表也会生成锁。
Query Output 1.02:
查询输出1.02:
| m_pageId = (1:368) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x200 |
| m_objId (AllocUnitId.idObj) = 185 | m_indexId (AllocUnitId.idInd) = 256 | |
| Metadata: AllocUnitId = 72057594050052096 | ||
| Metadata: PartitionId = 72057594043629568 | Metadata: IndexId = 1 | |
| Metadata: ObjectId = 917578307 | m_prevPage = (0:0) | m_nextPage = (1:449) |
| pminlen = 12 | m_slotCnt = 73 | m_freeCnt = 3935 |
| m_freeData = 7247 | m_reservedCnt = 0 | m_lsn = (37:104:93) |
| m_xactReserved = 0 | m_xdesId = (0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 179036614 | DB Frag ID = 1 | |
| m_pageId =(1:368) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x200 |
| m_objId(AllocUnitId.idObj)= 185 | m_indexId(AllocUnitId.idInd)= 256 | |
| 元数据:AllocUnitId = 72057594050052096 | ||
| 元数据:PartitionId = 72057594043629568 | 元数据:IndexId = 1 | |
| 元数据:ObjectId = 917578307 | m_prevPage =(0:0) | m_nextPage =(1:449) |
| pminlen = 12 | m_slotCnt = 73 | m_freeCnt = 3935 |
| m_freeData = 7247 | m_reservedCnt = 0 | m_lsn =(37:104:93) |
| m_xactReserved = 0 | m_xdesId =(0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 179036614 | DB Frag ID = 1 | |
here, the Index fragmentation is also important to notice while working on SQL Server index Fill factor. For this table we have 66.66% Fragmentation count after performing the update on table. Index fragmentation does effects Index performance in SQL Server. Therefore, with higher Fill factor fragmentation value the cost will be high, hence it should be consumed by applying proper amount on this setting. We can check fragmentation by below query.
在这里,在使用SQL Server索引填充因子时,索引碎片也很重要。 对于此表,在对表执行更新后,我们的碎片计数为66.66%。 索引碎片确实会影响SQL Server中的索引性能。 因此,较高的填充因子碎片值将导致成本较高,因此应通过在此设置上应用适当的量来消耗它。 我们可以通过以下查询检查碎片。
SELECT dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = 9
ORDER BY indexstats.avg_fragmentation_in_percent desc
具有填充因子: (With Fill Factor:)
Fill factor value regulates the percentage of data to be filled in each data page. In this example, SQL Server index Fill factor value defined with 80 on Primary Index means that each page of table will have 20% free space and 80% space will be allocating to store the data. To apply changes in Fill factor will always rebuilt the index.
填充因子值调节每个数据页面中要填充的数据的百分比。 在此示例中,在主索引上用80定义SQL Server索引填充因子值表示表的每一页将具有20%的可用空间,并且80%的空间将分配用于存储数据。 要应用“填充因子”更改,将始终重建索引。
We have now inserted same 256 rows into same table again to check the allocated number of pages to the table. Data gets split in 3 pages this time whereas it got split in two pages done without Fill factor.
现在,我们再次将相同的256行插入到同一表中,以检查分配给该表的页数。 这次数据分成3页,而没有填充因子的情况下分成2页。
Looking at number of the rows on the first page, we can see 118 rows are stored (Query Output 2.01) as compare with previous result (100% Fill factor) data split in 2 pages on data insertion and 147 rows on the first page (Query Output 1.01).
查看第一页上的行数,我们可以看到与先前结果(100%填充因子)数据相比,在插入数据时分为2页,在第一页中有147行,存储了118行(查询输出2.01)。查询输出1.01)。
Here It keeps 20 % room vacant on each page for inserting new row into table according to the Fill factor amount.
此处,它根据填充因子的数量在每页上保留20%的空位,以便将新行插入表中。
DBCC TRACEON(3604)
DBCC PAGE(auth, 1, 368, 1)
Query Output 2.01:
查询输出2.01:
| PAGE HEADER: | ||
| Page @0x00000260F6CB2000 | ||
| m_pageId = (1:368) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x200 |
| m_objId (AllocUnitId.idObj) = 183 | m_indexId (AllocUnitId.idInd) = 256 | |
| Metadata: AllocUnitId = 72057594049921024 | ||
| Metadata: PartitionId = 72057594043498496 | Metadata: IndexId = 1 | |
| Metadata: ObjectId = 917578307 | m_prevPage = (0:0) | m_nextPage = (1:376) |
| pminlen = 12 | m_slotCnt = 118 | m_freeCnt = 1607 |
| m_freeData = 6349 | m_reservedCnt = 0 | m_lsn = (36:3352:61) |
| m_xactReserved = 0 | m_xdesId = (0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 1731328174 | DB Frag ID = 1 | |
| 页面标题: | ||
| 页面@ 0x00000260F6CB2000 | ||
| m_pageId =(1:368) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x200 |
| m_objId(AllocUnitId.idObj)= 183 | m_indexId(AllocUnitId.idInd)= 256 | |
| 元数据:AllocUnitId = 72057594049921024 | ||
| 元数据:PartitionId = 72057594043498496 | 元数据:IndexId = 1 | |
| 元数据:ObjectId = 917578307 | m_prevPage =(0:0) | m_nextPage =(1:376) |
| pminlen = 12 | m_slotCnt = 118 | m_freeCnt = 1607 |
| m_freeData = 6349 | m_reservedCnt = 0 | m_lsn =(36:3352:61) |
| m_xactReserved = 0 | m_xdesId =(0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 1731328174 | DB Frag ID = 1 | |
Let us update table again as previous example and check the rows allocation in page structure. Here we find that no changes found in first page and even we can see that more free space has been occupied by existing rows. considered, no pages are reorganized and avoided locks on targeted rows and those page dependent rows.
让我们再次像前面的示例一样更新表,并检查页面结构中的行分配。 在这里,我们发现首页没有任何变化,甚至可以看到现有行已占用了更多的可用空间。 考虑到,不会重组任何页面,并避免锁定目标行和那些与页面相关的行。
UPDATE tbl_user SET email = CAST(user_id AS VARCHAR(10)) + email
DBCC PAGE(auth, 1, 368, 1)
Query Output 2.02:
查询输出2.02:
| m_pageId = (1:368) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x0 |
| m_objId (AllocUnitId.idObj) = 194 | m_indexId (AllocUnitId.idInd) = 256 | |
| Metadata: AllocUnitId = 72057594050641920 | ||
| Metadata: PartitionId = 72057594044219392 | Metadata: IndexId = 1 | |
| Metadata: ObjectId = 949578421 | m_prevPage = (0:0) | m_nextPage = (1:376) |
| pminlen = 12 | m_slotCnt = 118 | m_freeCnt = 1361 |
| m_freeData = 7018 | m_reservedCnt = 0 | m_lsn = (37:3856:131) |
| m_xactReserved = 0 | m_xdesId = (0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 0 | DB Frag ID = 1 | |
| m_pageId =(1:368) | m_headerVersion = 1 | m_type = 1 |
| m_typeFlagBits = 0x0 | m_level = 0 | m_flagBits = 0x0 |
| m_objId(AllocUnitId.idObj)= 194 | m_indexId(AllocUnitId.idInd)= 256 | |
| 元数据:AllocUnitId = 72057594050641920 | ||
| 元数据:PartitionId = 72057594044219392 | 元数据:IndexId = 1 | |
| 元数据:ObjectId = 949578421 | m_prevPage =(0:0) | m_nextPage =(1:376) |
| pminlen = 12 | m_slotCnt = 118 | m_freeCnt = 1361 |
| m_freeData = 7018 | m_reservedCnt = 0 | m_lsn =(37:3856:131) |
| m_xactReserved = 0 | m_xdesId =(0:0) | m_ghostRecCnt = 0 |
| m_tornBits = 0 | DB Frag ID = 1 | |
Not only the number of the rows remain the same on the page one, even index fragmentation looks good compare to previous one.
不仅行数在第一页上保持不变,即使索引碎片与上一页相比看起来也不错。
结论: (Conclusion:)
In this example we have used 80% Fill Factor, however it doesn’t make sense to push without any benchmarking for the table. In most cases SQL Server index Fill factor will help to get well performed when Table having large number of rows and frequent update over the rows. Before setting the Fill Factor we need to analyse the Datatype of columns, actual cell size of the rows, Average number of rows in the pages and estimated updated size of row cell. This proper calculation derives an actual Fill factor value which need to be applied on the table.
在此示例中,我们使用了80%的填充因子,但是在没有对该表进行任何基准测试的情况下进行推送是没有意义的。 在大多数情况下,当表具有大量行并且频繁更新行时,SQL Server索引填充因子将有助于获得良好的性能。 在设置填充因子之前,我们需要分析列的数据类型,行的实际单元格大小,页面中的平均行数以及行单元格的估计更新大小。 这种适当的计算会得出一个实际的填充因子值,需要将其应用到表格中。
Without calculation, less Fill factor can degrade the Read operation. unnecessary more pages to find rows in a table consumes more resources and IO. Please be sure to get proper value to be set on Index.
如果不进行计算,则较少的填充因子会降低读取操作的性能。 不必要的更多页面来查找表中的行会消耗更多的资源和IO。 请确保获得正确的值以在索引上设置。
翻译自: https://www.sqlshack.com/sql-server-index-fill-factor-with-performance-benchmark/
基准风险因子暴露度
基准风险因子暴露度_具有性能基准SQL Server索引填充因子相关推荐
- Barra 结构化风险模型实现(1)——沪深300指数的风格因子暴露度分析
米筐科技(RiceQuant)策略研究报告:Barra 结构化风险模型实现(1)--沪深300指数的风格因子暴露度分析 江嘉键 1 年前1 概述 Barra 结构化风险模型是全球知名的投资组合表现和风 ...
- 结构化风险模型----转:沪深300指数的风格因子暴露度分析(一)
from: https://xueqiu.com/7381621247/73649418 1 概述 Barra 结构化风险模型是全球知名的投资组合表现和风险分析工具.最近一段时间,我们米筐科技量化策略 ...
- QUANT[10]量化交易——因子暴露度,因子收益与模型
QUANT[1]:从零开始量化交易 - プロノCodeSteel - CSDN博客 QUANT[2]:量化交易策略基本框架搭建 - プロノCodeSteel - CSDN博客 QUANT[3]:量化交 ...
- sql索引调优_使用内置索引利用率指标SQL Server索引性能调优
sql索引调优 描述 (Description) Indexing is key to efficient query execution. Knowing what indexes are unne ...
- 详细讲解SQL Server索引的性能问题
在良好的数据库设计基础上,能有效地使用索引是SQL Server取得高性能的基础,SQL Server采用基于代价的优化模型,它对每一个提交的有关表的查询,决定是否使用索引或用哪一个索引.因为查询执行 ...
- sql错误索引中丢失_收集,汇总和分析丢失SQL Server索引统计信息
sql错误索引中丢失 描述 (Description) Indexing is key to efficient query execution. Determining what indexes a ...
- SQL SERVER索引原理及填充因子
在SQL Server中,索引是按B树(平衡树)结构进行组织的,索引B树中的每一页称为一个索引节点,B树的顶端节点称为根节点,索引中的底层节点称为叶节点,根节点与叶节点之间的任何索引级别统称为中间级, ...
- sql 2017 机器学习_使用R和SQL Server 2017进行机器学习
sql 2017 机器学习 The primitive Business Intelligence (BI) methodology has its primary focus on data sou ...
- T-SQL查询高级—SQL Server索引中的碎片和填充因子
写在前面:本篇文章需要你对索引和SQL中数据的存储方式有一定了解.标题中高级两个字仅仅是因为本篇文章需要我的T-SQL进阶系列文章的一些内容作为基础. 简介 在SQL Server中,存储数据 ...
最新文章
- 使用Blender Houdini轻松学习FX特效
- 华为 mysql实例监控,华为云文档数据库服务DDS监控告警全新优化
- java 重力脚本_用Java模拟游戏重力的实现(弹跳)
- 解读GAN及其 2016 年度进展
- Rinne Loves Edges
- v380智能快配连接不上怎么办_Win7系统电脑设置连接远程桌面的操作方法
- CentOS7的/tmp目录自动清理规则
- 使用keytool生成密钥对
- SQL Server中数据透视表的Python脚本
- 虚拟机备份克隆导致SQL SERVER 出现IO错误案例
- Guava CaseFormat
- 怎样远程连接Access数据库
- 计算机程序设计的史诗TAOCP
- ISO 3166-1 国家编码
- Tomcat 端口被javaw.exe占用 有效解决方法
- 小觅相机运行VINS-Fusion(二)——Camera-IMU参数标定
- PS教程 | 美女面部剥落碎片效果
- 系统更新win10服务器出错怎么办,windows10更新升级失败0x80072ee2解决方法
- DevOps亚马逊AWS相关介绍
- Weka数据挖掘——选择属性