文本数据可视化_如何使用TextHero快速预处理和可视化文本数据
文本数据可视化
自然语言处理 (Natural Language Processing)
When we are working on any NLP project or competition, we spend most of our time on preprocessing the text such as removing digits, punctuations, stopwords, whitespaces, etc and sometimes visualization too. After experimenting TextHero on a couple of NLP datasets I found this library to be extremely useful for preprocessing and visualization. This will save us some time writing custom functions. Aren’t you excited!!? So let’s dive in.
在进行任何NLP项目或竞赛时,我们将大部分时间用于预处理文本,例如删除数字,标点符号,停用词,空白等,有时还会进行可视化处理。 在几个NLP数据集上试验TextHero之后,我发现此库对于预处理和可视化非常有用。 这将节省我们一些编写自定义函数的时间。 你不兴奋!!? 因此,让我们开始吧。
We will apply techniques that we are going to learn in this article to Kaggle’s Spooky Author Identification dataset. You can find the dataset here. The complete code is given at the end of the article.
我们将把本文中要学习的技术应用于Kaggle的Spooky Author Identification数据集。 您可以在此处找到数据集。 完整的代码在文章末尾给出。
Note: TextHero is still in beta. The library may undergo major changes. So some of the code snippets or functionalities below might get changed.
注意:TextHero仍处于测试版。 图书馆可能会发生重大变化。 因此,下面的某些代码段或功能可能会更改。
安装 (Installation)
pip install texthero前处理 (Preprocessing)
As the name itself says clean method is used to clean the text. By default, the clean method applies 7 default pipelines to the text.
顾名思义, clean方法用于清理文本。 默认情况下, clean方法将7个default pipelines应用于文本。
from texthero import preprocessingdf[‘clean_text’] = preprocessing.clean(df[‘text’])fillna(s)fillna(s)lowercase(s)lowercase(s)remove_digits()remove_digits()remove_punctuation()remove_punctuation()remove_diacritics()remove_diacritics()remove_stopwords()remove_stopwords()remove_whitespace()remove_whitespace()
We can confirm the default pipelines used with below code:
我们可以确认以下代码使用的默认管道:

Apart from the above 7 default pipelines, TextHero provides many more pipelines that we can use. See the complete list here with descriptions. These are very useful as we deal with all these during text preprocessing.
除了上述7个默认管道之外, TextHero还提供了更多可以使用的管道。 请参阅此处的完整列表及其说明。 这些非常有用,因为我们在文本预处理期间会处理所有这些问题。
Based on our requirements, we can also have our custom pipelines as shown below. Here in this example, we are using two pipelines. However, we can use as many pipelines as we want.
根据我们的要求,我们还可以具有如下所示的自定义管道。 在此示例中,我们使用两个管道。 但是,我们可以使用任意数量的管道。
from texthero import preprocessing custom_pipeline = [preprocessing.fillna, preprocessing.lowercase] df[‘clean_text’] = preprocessing.clean(df[‘text’], custom_pipeline)自然语言处理 (NLP)
As of now, this NLP functionality provides only named_entity and noun_phrases methods. See the sample code below. Since TextHero is still in beta, I believe, more functionalities will be added later.
到目前为止,此NLP功能仅提供named_entity和noun_phrases方法。 请参见下面的示例代码。 由于TextHero仍处于测试阶段,我相信以后会添加更多功能。
named entity
命名实体
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)print(nlp.named_entities(s)[0])Output:[('Narendra Damodardas Modi', 'PERSON', 0, 24), ('Indian', 'NORP', 31, 37), ('14th', 'ORDINAL', 64, 68), ('India', 'GPE', 99, 104), ('2014', 'DATE', 111, 115)]noun phrases
名词短语
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)print(nlp.noun_chunks(s)[0])Output:[(‘Narendra Damodardas Modi’, ‘NP’, 0, 24), (‘an Indian politician’, ‘NP’, 28, 48), (‘the 14th and current Prime Minister’, ‘NP’, 60, 95), (‘India’, ‘NP’, 99, 104)]表示 (Representation)
This functionality is used to map text data into vectors (Term Frequency, TF-IDF), for clustering (kmeans, dbscan, meanshift) and also for dimensionality reduction (PCA, t-SNE, NMF).
此功能用于将文本数据映射到vectors (术语频率,TF-IDF), clustering (kmeans,dbscan,meanshift)以及降dimensionality reduction (PCA,t-SNE,NMF)。
Let’s look at an example with TF-TDF and PCA on the Spooky author identification train dataset.
让我们看一下Spooky作者标识训练数据集中的TF-TDF和PCA的示例。
train['pca'] = ( train['text'] .pipe(preprocessing.clean) .pipe(representation.tfidf, max_features=1000) .pipe(representation.pca))visualization.scatterplot(train, 'pca', color='author', title="Spooky Author identification")
可视化 (Visualization)
This functionality is used to plotting Scatter-plot, word cloud, and also used to get top n words from the text. Refer to the examples below.
此功能用于绘制Scatter-plot ,词云,还用于从文本中获取top n words 。 请参考以下示例。
Scatter-plot example
散点图示例
train['tfidf'] = ( train['text'] .pipe(preprocessing.clean) .pipe(representation.tfidf, max_features=1000))train['kmeans_labels'] = ( train['tfidf'] .pipe(representation.kmeans, n_clusters=3) .astype(str))train['pca'] = train['tfidf'].pipe(representation.pca)visualization.scatterplot(train, 'pca', color='kmeans_labels', title="K-means Spooky author")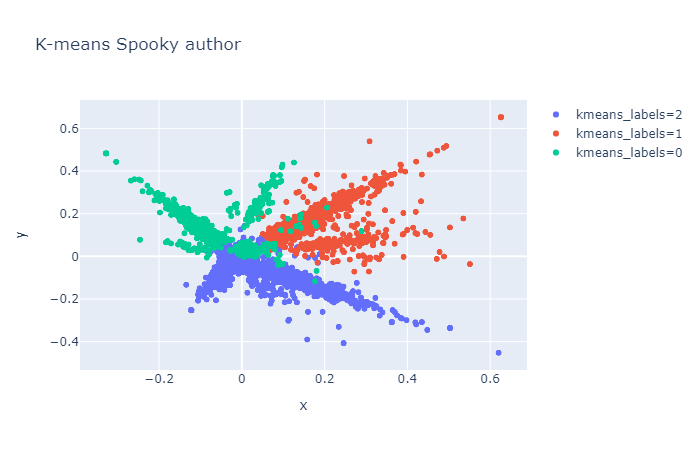
Wordcloud示例 (Wordcloud example)
from texthero import visualizationvisualization.wordcloud(train[‘clean_text’])
热门单词示例 (Top words example)
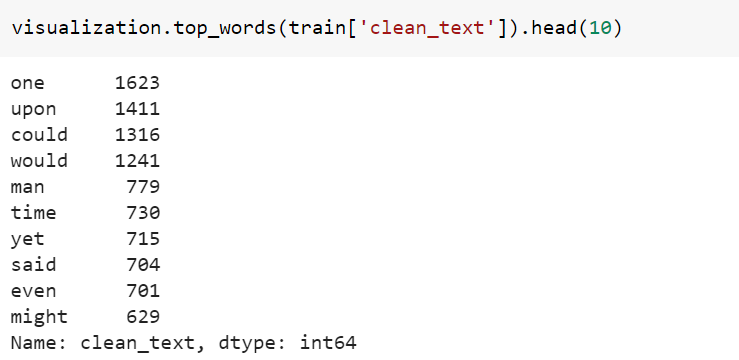
完整的代码 (Complete Code)
结论 (Conclusion)
We have gone thru most of the functionalities provided by TextHero. Except for the NLP functionality, I found that rest of the features are really useful which we can try to use it for the next NLP project.
我们已经通过了TextHero提供的大多数功能。 除了NLP功能以外,我发现其余功能确实有用,我们可以尝试将其用于下一个NLP项目。
Thank you so much for taking out time to read this article. You can reach me at https://www.linkedin.com/in/chetanambi/
非常感谢您抽出宝贵的时间阅读本文。 您可以通过https://www.linkedin.com/in/chetanambi/与我联系
翻译自: https://medium.com/towards-artificial-intelligence/how-to-quickly-preprocess-and-visualize-text-data-with-texthero-c86957452824
文本数据可视化
http://www.taodudu.cc/news/show-997362.html
相关文章:
- 真实感人故事_您的数据可以告诉您真实故事吗?
- k均值算法 二分k均值算法_使用K均值对加勒比珊瑚礁进行分类
- 衡量试卷难度信度_我们可以通过数字来衡量语言难度吗?
- 视图可视化 后台_如何在单视图中可视化复杂的多层主题
- python边玩边学_边听边学数据科学
- 边缘计算 ai_在边缘探索AI!
- 如何建立搜索引擎_如何建立搜寻引擎
- github代码_GitHub启动代码空间
- 腾讯哈勃_用Python的黑客统计资料重新审视哈勃定律
- 如何使用Picterra的地理空间平台分析卫星图像
- hopper_如何利用卫星收集的遥感数据轻松对蚱hopper中的站点进行建模
- 华为开源构建工具_为什么我构建了用于大数据测试和质量控制的开源工具
- 数据科学项目_完整的数据科学组合项目
- uni-app清理缓存数据_数据清理-从哪里开始?
- bigquery_如何在BigQuery中进行文本相似性搜索和文档聚类
- vlookup match_INDEX-MATCH — VLOOKUP功能的升级
- flask redis_在Flask应用程序中将Redis队列用于异步任务
- 前馈神经网络中的前馈_前馈神经网络在基于趋势的交易中的有效性(1)
- hadoop将消亡_数据科学家:适应还是消亡!
- 数据科学领域有哪些技术_领域知识在数据科学中到底有多重要?
- 初创公司怎么做销售数据分析_为什么您的初创企业需要数据科学来解决这一危机...
- r软件时间序列分析论文_高度比较的时间序列分析-一篇论文评论
- selenium抓取_使用Selenium的网络抓取电子商务网站
- 裁判打分_内在的裁判偏见
- 从Jupyter Notebook切换到脚本的5个理由
- ip登录打印机怎么打印_不要打印,登录。
- 机器学习模型 非线性模型_调试机器学习模型的终极指南
- 您的第一个简单的机器学习项目
- 鸽子为什么喜欢盘旋_如何为鸽子回避系统设置数据收集
- 追求卓越追求完美规范学习_追求新的黄金比例
文本数据可视化_如何使用TextHero快速预处理和可视化文本数据相关推荐
- nlp文本数据增强_如何使用Texthero为您的NLP项目准备基于文本的数据集
nlp文本数据增强 Natural Language Processing (NLP) is one of the most important fields of study and researc ...
- antd 文本域超长问题_一款能快速批量处理SQL文本的软件:NimbleText
前言 做为一个后台程序员,在日常工作中,经常会遇到领导扔给一个Excel,让把 Excel 的数据导入数据库的情况. 如果只是少量数据,几条甚至说几十条,还可以勉强地组织一下 insert 插入语句: ...
- excel删除重复数据保留一条_Excel怎么快速查找和删除重复数据
我们用excel表格记录了大量的数据,当要做数据整理时候发现很多重复数据,那么怎么筛选删除呢? ---------------------------------------------------- ...
- 偏移出来的数据不准_独家解读!京东高可用分布式流数据存储的架构设计
作者 | 李玥 编辑 | Vincent AI 前线导读:每天,超过千亿交易相关的数据在京东数千个系统中高速流转,确保数据的高可靠.高可用.一致性对京东的消息中间件系统是一项艰巨的技术挑战.为高性能. ...
- python获取期货行情可视化_用Pandas获取商品期货价格并可视化
用Pandas获取商品期货价格并可视化 摘 要 1.用pandas从excel中读取数据: 2.用pandas进行数据清洗.整理: 3.用bokeh进行简单的可视化. 1.数据读取 本文主要是将获取 ...
- python爬微博数据中心_怎样用python爬新浪微博大V所有数据?
最近为了做事件分析写了一些微博的爬虫,两个大V总共爬了超70W的微博数据. 官方提供的api有爬取数量上限2000,想爬取的数据大了就不够用了... 果断撸起袖子自己动手!先简单说一下我的思路: 一. ...
- 不动产测绘数据入库_不动产登记中的房产与地籍测绘数据整合
不动产登记中的房产与地籍测绘数据整合 摘要:随着房地产领域的快速发展,各级对不动产登记制度越来越重视.不动 产权籍调查是不动产登记的一项基础性工作,建立不动产登记信息数据库离不开 地基测绘和调查.为快 ...
- 商业方向的大数据专业_结合当前的人才需求趋势,大数据专业考研时可以选择哪些主攻方向...
首先,对于大数据专业的本科生来说,当前读研是不错的选择,随着大数据技术开始逐渐落地应用,产业领域需要大量高端应用型人才,所以如果没有继续读博的计划,可以重点关注一下专硕. 在读研方向的选择上,可以重点 ...
- 开源 画图_[软件使用05] 快速使用 Deeptools 对 ChIP-seq 数据画图!
前情提要: [软件使用 3] 使用MACS2分析ChIP-seq数据,快速入门! 详细讲解了ChIP-seq的一些基本概念.数据的下载和处理,并且也用 ChIPseeker 初步画图. 本文主要讲述如 ...
最新文章
- 提升思辨能力和判断力
- 【机器学习】机器学习Top10算法,教你选择最合适的那一个!一文读懂ML中的解析解与数值解...
- 课程范例 20150916html1 练习
- js如何把ajax获取的值返回到上层函数里?
- 数据结构之树状数组(候补)
- Linux 基础知识系列第三篇
- 【Python】Python3.7.3 - sys.flag 命令行选项标志结构序列
- 监控管理平台 OpenNMS
- 两数据库Dblink数据抽取blob
- matlab阅读怎么放大镜,matlab局部放大
- centos 打包某个目录_Linux(CentOS)下目录档案管理以及档案文件系统打包压缩
- Eclipse, Lomboz and Tomcat 的配置和调试
- 随访软件的计算机技术,患者随访管理系统
- LibCef中的一些坑
- JavaEE:Cookie和Session
- 作业 5:词频统计——增强功能
- debian 7 调整控制台分辨率
- 推荐两款github敏感信息搜集工具(gsil、gshark)
- 使地方坐标系BIM模型与CAD严格在LSV内对准
- linux ubuntu动物,[趣闻]Ubuntu各大发行版的动物代号