Activity Recognition行为识别
暑假听了computer vision的一个Summer School,里面Jason J. Corso讲了他们运用Low-Mid-High层次结构进行Video Understanding 和 Activity Recognition的方法,受益颇深,在这里把他的方法总结一下:
-------------------------------------------------------------------------------------------------
1. 层次结构表示:
- 底层part 重用
- 每个object都是一个由有向和无向边连接起来的混合图
- 底层通过非线性学习让原子节点形成时空线、平面和区域
人的活动呢,就是这些object在中层和高层连接的混合图
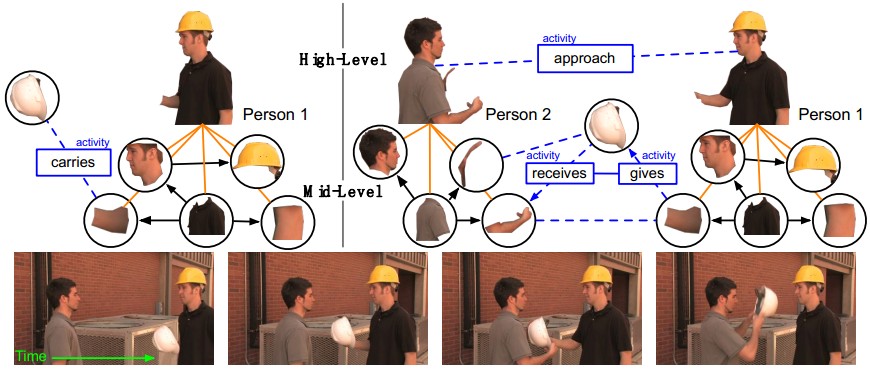
-------------------------------------------------------------------------------------------------
2. Motion Perception——STS
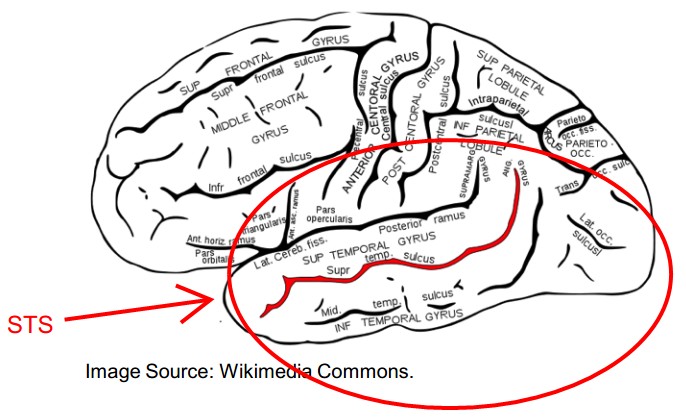
Different action stimulate different subpopulation of cells.
-------------------------------------------------------------------------------------------------
3. Activity Recognition
Corso的方法:
- Low-Level:底层最effective的做法是Bag of Features,特征为bottom-up / low level的时空特征,随着时间和层次不断update。通过模版进行底层object检测;
- Mid-Level:中间层从images中检测、跟踪2D骨架pose,并通过背景内容分析动态pose;
- High-Level:高层活动组合方法为,将不同时间点的feature组成时间-概率模型。时间上进行feature的时空跟踪,概率上根据组成语法进行概率模型的组合。
- Recognition的另一种表示方法:Segmentation
思想:建立Space-Time Patch Descriptors,组成visual Words直方图,建立多通道分类器。

找出shikongHarris角点:
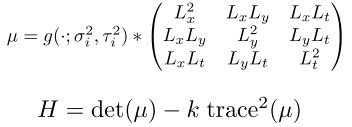
要求在feature上进行Densely Sample而非Sparse Sample。
提取Action Feature:f,用HOG/HOF描述
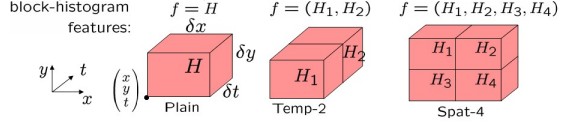
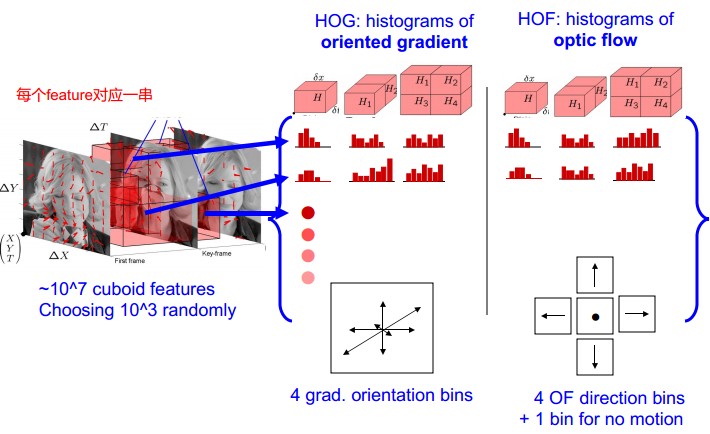
Space-Time Patch描述子形成histogram。每个histogram,是特征点在x,y,t三个分量上的直方图。
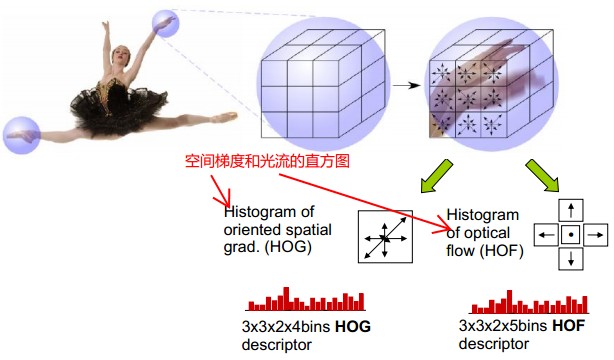
但是采用HOG、HOF存在问题,就是只能从前后帧去看,而不能考虑整个球的特征变化。出于这一想法,提出了HOG3D, 该特征在BMVC08中有文章进行具体描述,此处不予赘述,大家有兴趣去看文章吧。
-------------------------------------------------------------------------------------------------
4. 行为轨迹
采用 KLT: Kanade-Lucas-Tomasi Feature Tracker 进行特征点的跟踪,可作为局部特征检测的辅助手段。
- Trajectories by Local Keypoint Tracking
- Use Dense Trajectory(Dense sampling can improve object recognition and action recognition)
- CVPR 2011 Wang et al. “Action Recognition by Dense Trajectories.”中提出了一种方法,用一个单密度光流场跟踪轨迹
- 用HOG/HOF/MBH进行轨迹点描述

-------------------------------------------------------------------------------------------------
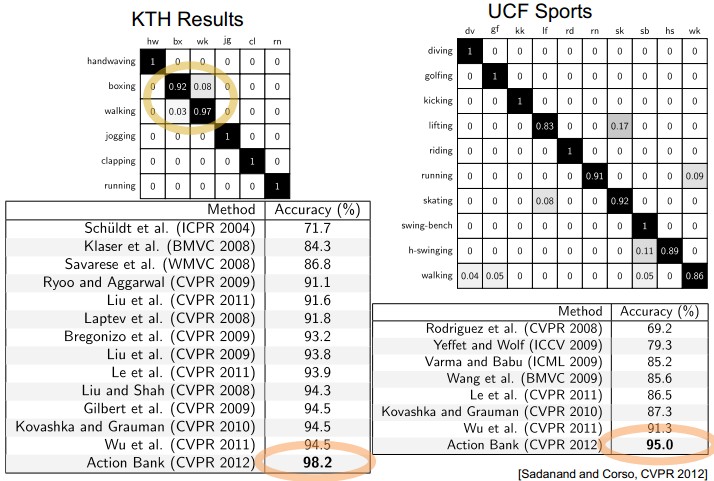
5. Action Bank
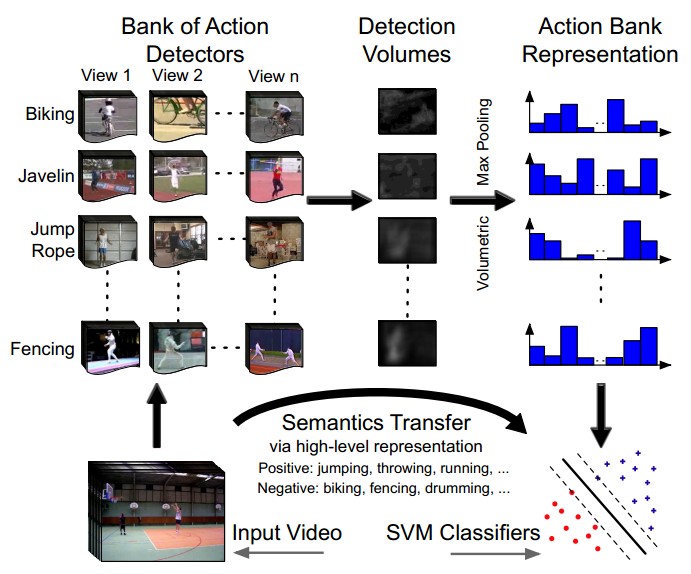
图中所示为Action bank的基本思想<CVPR 2012: Action Bank: A High-Level Representation of Activity in Video>
Action bank :
- 记录在不同scale和viewpoints的一个大action detector集合
- 在Ns个scales上进行检测,action bank上有Na个detector,每组action-scale上有1^3+2^3+4^3=73维向量。所以action bank特征向量共有Na*Ns*73维(关于73怎么来的可以详细参考《Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories》)
- 实际做的时候采用1-2个scale上的detector
- classifier 使用SVM分类器:
- 实现Action Bank的建立:
1. 选取UCF上的50个action,KTH上6个action和visint.org上的digging action,组成205 templates totally
2. 每个action选择3-6个不同视角、style或运动节奏的examples
3. 平均分辨率:50×120pixel;40-50frames/example
简单的说呢,就是根据不同视角、style和运动节奏来描述一个templates,由此组成了205个模版,描述57个action。
- 关于模版
-------------------------------------------------------------------------------------------------
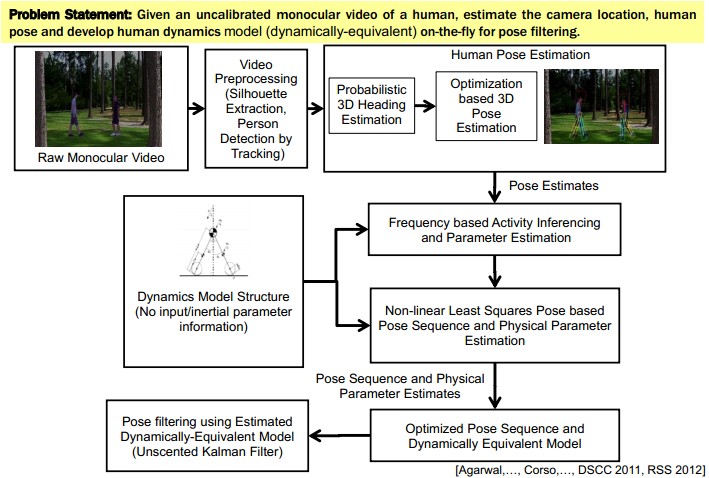
6. 基于Human Pose方法的Activity 识别
- 将人分为不同part,进行各部分的姿势估计可以清晰的进行model描述。

- 3D Human Pose Estimation:
-------------------------------------------------------------------------------------------------
7. 基于Parts的Human Pose Estimation
模型结合了局部appearance和对称结构,有多篇文章涉及模型估计:
Pictorial Structures (Fischler & Elschlager 73, Felzenswalb and Huttenlocher 00)
Cardboard People (Yu et al 96)
Body Plans (Forsyth & Fleck 97)
Active Appearance Models (Cootes & Taylor 98)
Constellation Models (Burl et all 98, Fergus et al 03)
采用deformable part model
Slide credit: D. Ramanan. Method is from Yang and Ramanan, CVPR 2011.

Result:

- Dynamic Pose based Activity Recognition
2. For classification we use many one-versus-one histogram intersection kernel SVMs.
3. 处理dynamic pose和全局context都在动的情况,用 HoG3D and Dense Trajectory可得better效果。
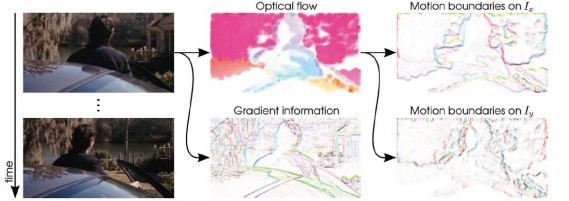
9.视频分割:Beyond Points for Video Understanding
标准方法:
- meanshift
- Graph-Based
- Hierarchical graph-based
- Nystrom normalized cuts
- Segmentation by weighted aggregation
ECCV 2012 Xu, Xiong and Corso的方法:将视频看做一个流,根据流向和时间上的马尔科夫假设建立一个估计构架,进行video分割。
Segmentation: S = {S1, S2, ... , Sm}
Input Video: V = {V1, V2, ... , Vm}(时间序列上的输入流)
取S*=arg min E(S|V)
在一个layer的分割中采取:

在整个hierarchy中采取同样假设:
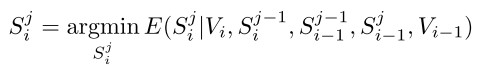


<ECCV 2012 Xu, Xiong and Corso>
Activity Recognition行为识别相关推荐
- 对比学习系列论文CPCforHAR(一):Contrastive Predictive Coding for Human Activity Recognition
0.Abusurt 0.1逐句翻译 Feature extraction is crucial for human activity recognition (HAR) using body-worn ...
- 文献记录(part47)--KU-HAR: An open dataset for heterogeneous human activity recognition
学习笔记,仅供参考,有错必纠 数据集- KU-HAR: An open dataset for heterogeneous human activity recognition 摘要 在人工智能中,人 ...
- 【Paper】WISDM:Activity Recognition using Cell Phone Accelerometers
论文原文:点击此处 论文下载:点击此处 论文被引:2034 论文年份:2010 本文是WISDM (WIreless Sensor Data Mining) 无线传感数据挖掘实验室的第一篇论文. 如果 ...
- 【Paper】WISDM:The Impact of Personalization on Smartphone-Based Activity Recognition
论文原文 论文下载 论文被引:144 论文年份:2012 The Impact of Personalization on Smartphone-Based Activity Recognition ...
- TensorFlow for Hackers (Part VI) - Human Activity Recognition using LSTMs on Android
Ever wondered how your smartphone, smartwatch or wristband knows when you're walking, running or sit ...
- 构建 Darknet 分类器 (Tiny Darknet) 训练数据集 (color recognition 颜色识别/color classification 颜色分类)
构建 Darknet 分类器 (Tiny Darknet) 训练数据集 (color recognition 颜色识别/color classification 颜色分类) 1. CompCars_C ...
- 行为识别 Activity Recognition
行为识别 行为检测是一个广泛的研究领域,其应用包括安防监控.健康医疗.娱乐等. 课程大纲 导论 图卷积在行为识别中的应用:论文研读,代码解读,实验 Topdown关键点检测中的hrnet:论文研读,代 ...
- Face Recognition 人脸识别
本项目face_recognition是一个强大.简单.易上手的人脸识别开源项目,并且配备了完整的开发文档和应用案例,特别是兼容树莓派系统. 为了便于中国开发者研究学习人脸识别.贡献代码,我将本项目R ...
- 头歌--人脸识别系统--Face recognition 人脸识别
目录 第1关:人脸检测 第2关:人脸特征点获取 第3关:人脸识别 第4关:人脸识别绘制并展示 第1关:人脸检测 '''****************BEGIN****************''' ...
最新文章
- ThinkPHP 详细介绍
- Galaxy Project | 一些尝试与思考
- java程序员修炼之道
- CKO将成为企业发展的军师--转自世界名人网
- python实现api接口的脚本_Zabbix批量添加主机,Python调用api接口方式【脚本定制】...
- 探探自动配对PHP_CentOS7 - 安装Apache HTTP Server和PHP
- linux 统计当前目录下文件或者文件夹的数量
- 【记录】启用Windows 10下的linux子系统
- 关于使用scrapy框架时出现 No module named 'win32api问题
- html顶栏符号不显示,html – 带有USE标记的SVG无法呈现
- Scala(一):概述
- Linux学习笔记11
- protobuf repeated string 赋值
- 作为兼并重组的重要方式之一,企业合并、分立的具体形式?
- 远程控制 - 手机完全控制电脑之TeamViewer
- 微信中的表情符号代码对照表
- 动态和静态查看一个进程的内存使用
- 《黑头人》(暂定)开发日志
- 房贷中的等额本息和等额本金有什么区别?
- Google Earth Engine(GEE)——如何将众多小区域面和点或者多点矢量转化成为一个矢量边界防止超限使用(bounds)
热门文章
- 重庆市推进组建区块链数字资产交易所
- 2014腾讯WE大会:开启未来的五大科技发展趋势
- 更改日期为英文_如何在 Linux 上检查所有用户密码到期日期 | Linux 中国
- Java Review - ArrayList 源码解读
- Apache ZooKeeper - JMX监控 ZooKeeper 的运行状态
- Apache ZooKeeper - 使用原生的API操作ZK_ACL权限
- Tomcat - Tomcat 8.5.55 启动过程源码分析阶段三_start阶段
- Algorithms_基础数据结构(02)_线性表之链表_单向链表
- Nginx-从零开始使用nginx实现反向代理及负载均衡
- Shell echo-使用echo实现更复杂的输出格式控制