重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕
重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕摘要:我们提供了第一个大型场景草图数据集SketchyScene,目的是推进对物体和场景层面的素描研究。该数据集是通过一个新颖且精心设计的众包管道创建的,使用户能够有效地生成大量逼真和多样化的场景草图。 SketchyScene包含超过29,000个场景级草图,7,000多对场景模板和照片,以及11,000多个对象草图。场景草图中的所有对象都具有地面实况语义和实例掩码。该数据集还具有高度可扩展性和可扩展性,可轻松扩展和/或更改场景组成。我们通过训练场景草图语义分割的新计算模型,展示新数据集如何实现多种应用,包括图像检索,草图着色,编辑和字幕等,展示了SketchyScene的潜在影响。数据集和代码可以在ECCV 2018 SketchyScene。

重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕简介:在数据驱动计算时代,大规模数据集已成为改进和区分机器学习算法的性能,稳健性和通用性的驱动力。近年来,计算机视觉社区已经接受了许多用于图像的大型且丰富注释的数据集(例如,ImageNET [8]和Microsoft COCO [15]),3D对象(例如,ShapeNET [2,30]和PointNET [17] ])和场景环境(例如,SUN [31]和纽约大学数据库[22])。在视觉形式的各种表现形式中,手绘草图占据了特殊的位置,因为与大多数其他形象不同,它们来自人类创造。人类非常熟悉草图作为一种艺术形式,草图可以说是最紧凑,最直观,最常用的机制,可以直观地表达和传达我们的印象和想法。
最近在计算机视觉和图形的草图理解和基于草图的建模方面取得了重大进展。一些大型的草图数据集[9,19,10]也在此过程中得到了构建和利用。然而,这些数据集都是由对象草图形成的,草图分析和处理任务大部分都在笔划或对象层面。将两者扩展到场景级别是对草绘视觉形式的更深层次和更丰富的推理的自然进展。随后的分析和数据合成问题变得更具挑战性,因为草绘的场景可能包含以复杂方式交互的许多对象。虽然场景理解是计算机视觉的标志性任务之一,但是对场景草图的理解问题尚未得到很好的研究。
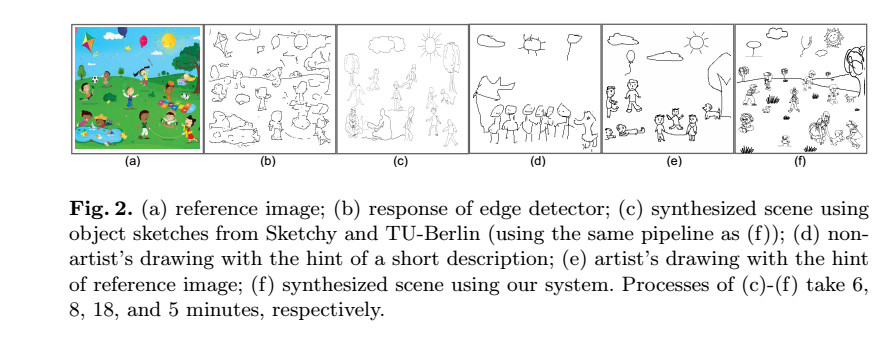
在本文中,我们介绍了第一个大型的场景草图数据集,我们将其称为SketchyScene,以便于在对象和场景级别进行草图理解和处理。显然,将图像转换为边缘图[32]是行不通的,因为结果与手绘草图的特征不同。基于预定义的布局模板自动组合现有的对象草图并将对象草图拟合到库存照片中都是具有挑战性的问题,这些问题不太可能产生大量的实际结果(参见图2(b))。在我们的工作中,我们采用众包设计并设计一个新颖直观的界面,以减轻用户的负担并提高他们的生产力。我们提供对象草图,以便通过简单的交互式操作(如拖放和缩放对象草图)创建场景草图,而不是要求用户从头开始绘制整个场景草图(这可能是单调乏味和令人生畏的)。 。为了确保场景草图的多样性和真实性,我们提供参考图像以指导/激励用户在草图生成期间。通过用户友好的界面,参与者可以有效地创建高质量的场景草图。另一方面,以这种方式合成的场景草图大体上是粗略的草图[9,19],它们与专业艺术家制作的草图不太相似。
SketchyScene包含对象和场景级数据,并附带丰富的注释。总的来说,该数据集包含超过29,000个场景草图和超过11,000个属于45个常见类别的对象草图。此外,还提供了超过7,000对场景草图模板和参考照片以及超过200,000个标记实例。请注意,场景草图中的所有对象都具有地面实况语义和实例掩码。更重要的是,SketchyScene由于其面向对象的合成机制而具有灵活性和可扩展性。可以使用SketchyScene中的可用实例切换/切出草图场景模板中的对象草图,以丰富数据集。
我们通过实验证明了SketchyScene的潜在影响。最重要的是,数据集提供了一个跳板来调查与场景草图相关的各种问题(在“场景草图”上快速的Google图像搜索会返回数百万个结果)。在我们的工作中,我们首次研究了场景草图的语义分割。为此,我们评估了高级自然图像分割模型DeepLab-v2 [3],探索了不同因素的影响并提供了丰富的见解。我们还演示了新数据集启用的几个应用程序,包括基于草图的场景图像检索,草图着色,编辑和字幕。
相关工作:大型草图数据集,近年来,大规模的草图数据集大量增加,主要受草图识别/合成[9,10]和SBIR [35,19]等应用的推动。然而,该领域仍然相对欠发达,现有数据集主要促进草图的对象级分析。这是人类草图数据无处不在的直接结果 - 除了免费自动抓取(如照片)之外,它们必须经过精心挑选。
TU-Berlin [9]是第一个这样的大型人群素描数据集,主要用于草图识别。它包含20,000个草图,涵盖250多个类别。最近的QuickDraw [10]数据集要大得多,在345个类别中有5000万个草图。虽然足够大以便于中风水平分析[6],但这些数据集中的草图是通过勾画出一个语义概念(例如“猫”,“房子”)而产生的,没有参考照片或自然的精神回忆场景/对象。这极大地限制了所描绘的视觉细节和变化的水平,因此使它们不适合细粒度匹配和场景级解析。例如,面部几乎都在正面视图中,并在QuickDraw中描绘为笑脸。
[35]和[19]的并行工作通过收集FG-SBIR的对象实例草图进一步推进了该领域。 QMUL数据库[35]包括两个对象类别(鞋和椅子)的716个草图 - 照片对,参考照片从在线购物网站上爬行。 Sketchy [19]包含75,471个草图和12,500张相应照片,涵盖范围更广的类别(共125个)。对象实例草图是通过要求众包来描绘他们对参考照片的精神回忆而产生的。与概念草图[9,10]相比,它们基本上展示了更多的对象细节,并且与参考照片具有匹配的姿势。然而,对于这个项目而言,两者的共同缺点在于其有限的姿势选择和对象配置。 QMUL草图在单个对象配置下仅展示一个对象姿势(侧视图)。场景草图虽然展示了更多的物体姿势和配置,但仍然受到限制,因为它们的参考照片主要由以相对平坦的背景为中心的单个物体组成(因此描绘没有物体相互作用)。这个缺点实际上使它们都不适合我们的场景草图解析任务,其中复杂的相互对象交互决定了高度的对象姿势和配置变化,以及细微的细节。例如,在图1中描绘的野餐场景中,人们以不同的姿势和配置出现,彼此之间具有微妙的眼神接触。图2(c)显示了使用Sketchy和TU-Berlin的草图的组成结果。
重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕贡献:SketchyScene是第一个专门为场景级草图理解而设计的大型数据集。它与上述所有数据集的不同之处在于它超越了单个对象草图理解以处理场景草图,并且有目的地包括具有不同姿势,配置和对象细节的各种对象草图选择以适应复杂的场景级对象交互。虽然现有数据集Abstract Scenes [38]为理解视觉数据中的高级语义信息提供了类似的动机,但它们关注的是使用剪辑艺术组成的抽象场景,其中包括更多的视觉线索,如颜色和纹理。此外,他们的场景仅限于描述两个角色和少数几个对象之间的交互,而SketchyScene中的场景内容和相互对象交互则很多更多样化。
重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕Sketch理解,草图识别可能是草图理解中研究最多的问题。自TU-Berlin数据集[9]发布以来,已经提出了许多工作,并且识别性能早已超过人类水平[36]。现有的算法可以大致分为两类:1)使用手工制作的特征[9,20],2)学习深度特征表示[36,10],后者通常明显优于前者保证金。其他工作流已经深入研究将对象级草图解析为其语义部分。 [25]提出了一种用于零件级和。级的熵下降笔划合并算法对象级草图分割。黄等人。 [13]利用由语义标记组件组成的3D模板模型库来导出部分级结构。 Schneider和Tuytelaars [21]通过观察CRF框架下的显着几何特征(如T结和X结)来进行草图分割。这项工作不是研究单个对象识别或部分级草图分割,而是通过提出第一个大型场景草图数据集,对草图的场景级解析进行探索性研究。
Scene草图应用程序,虽然没有先前的工作旨在解析场景级的草图,但已经提出了一些利用场景草图作为输入的有趣应用。 Sketch2Photo [5]是一个结合草图和照片蒙太奇的系统,用于逼真的图像合成,其中Sketch2Cartoon [28]是一个类似于卡通图像的系统。同样地,假设物体已在粗略场景中被分割,Xu等人。 [33]提出了一个名为sketch2scene的系统,它通过将检索到的3D形状与2D草图场景中的分割对象对齐来自动生成3D场景。 Sketch2Tag [26]是一个SBIR系统,其中场景项被自动识别并用作文本查询以提高检索性能。除了例外,所有上述应用都涉及手动标记和/或感知草图的分割。在这项工作中,我们提供了场景草图的自动分割方法,并通过提出一些新的应用程序来展示所提议的数据集的潜力。
SketchyScene数据集,场景草图数据集应该在其配置,对象交互和细微外观细节方面反映具有足够多样性的场景,其中草图还应包含不同类别的多个对象。此外,数据集的数量很重要,特别是在深度学习的背景下。然而,如前所述,基于现有数据集构建此类数据集是不可行的,而从人类收集数据可能既昂贵又耗时,因此需要高效且有效的数据收集管道。最简单的解决方案是让人们直接用提供的对象或场景标签绘制场景作为提示(即[9]中使用的策略)。不幸的是,这种方法在我们的案例中被证明是不可行的:(1)大多数人不是受过训练的艺术家。结果,他们努力绘制场景中存在的复杂物体,特别是当它们处于不同的姿势和物体配置时(见图2(d)); (2)虽然不同的人有不同的绘画风格,但人们倾向于画出特定的场景布局。例如,鉴于暗示“几个人在地上玩耍,太阳,树,云,气球和狗”,人们总是沿着水平线绘制物体。这使得收集的场景草图布局单调,视觉特征稀疏。 (3)重要的是,这个解决方案是不可扩展的 - 一般人需要大约8分钟才能完成合理质量的场景草图,专业人员花费18分钟(参见图2(e))。这将禁止我们收集大规模数据集。
因此设计了一种新的数据收集策略,即通过在参考图像的指导下组合所提供的对象组件来合成粗略场景。整个过程包括三个步骤。第1步:数据准备。我们为数据集选择了45个类别,包括对象和东西类。具体来说,我们首先考虑几个常见场景(例如,花园,农场,餐厅和公园),并从中提取100个对象/东西类作为原始候选。然后我们定义了三个超类,即天气,对象和场(环境),并将候选分配到每个超类中。最后,我们通过考虑他们在现实生活中的组合和共性来从他们中选出45个。

我们没有要求工人绘制每个对象,而是为他们提供了大量的对象草图(每个对象候选者也称为“组件”)作为候选者。为了在姿势和外观方面对物体外观有足够的变化,我们搜索并下载了每个类别约1,500个组件。然后,我们聘请了5名经验丰富的工人,从具有多个组件的草图中手动挑选出包含单个组件或切口单个组件的草图。对于一些搜索组件很少的类别(<20),如“伞”,组件通过手动绘图进行了扩充。我们共收集了所有44个类别的11,316个组件(不包括“道路”,均为手绘,“其他”)。每个类别的这些组件分为三组:训练(5468),验证(2362)和测试(3486)。 45个类别的代表性组件如图3所示。
为了保证数据集中场景布局的多样性,我们还添加了一组卡通照片作为参考图像。苏氨酸我们从每个预定义的超类(例如,太阳(天气),兔子(对象),山峰(环境))对类标签进行采样,我们生成了1,800个查询项目1.每个检索到大约300张卡通照片 查询项目。 手动重新移动重复的图像后,有7,264个参考图像(4730个图像是唯一的)。 这些参考图像也被分成三组用于训练(5,616),验证(535)和测试(1,113)。步骤2:场景草图合成。 为了提高人类创作者的效率,我们设计了一个基于网络的习惯用于草图场景合成的应用程序。 关于80名工人被雇用来制作场景草图。图4显示了应用程序的界面(名为“USketch”)。
如前所述,我们通过允许工作人员在参考图像的引导下拖动,旋转,缩放和变形组件草图,促进了粗略场景图像的创建。该过程详见图4.值得注意的是(1)我们为不同的工人提供了不同的组件草图(甚至是同一类别),以隐含地控制对象草图的多样性。否则,工人倾向于从候选池中选择前几个样本; (2)我们要求工人在场景合成期间尽可能地产生各种遮挡。这是为了模拟真实场景并促进分割研究。我们的服务器记录了由此产生的粗略场景的每个场景项的变换和语义标签。
在此步骤中,我们使用相应组件库中的组件,基于每个参考图像收集一个场景草图。因此,我们获得了7,264个独特的场景草图。这些独特的场景草图进一步用作场景模板以生成更多场景草图。
第3步:注释和数据扩充。参考图像设计用于帮助工作人员编写场景并丰富场景草图的布局。但是,参考图像中的对象不一定包含在我们的数据集中,即45个类别。为了通过提供更准确的注释来促进未来的研究,我们要求工作人员注释每个对象实例的对齐状态。
鉴于我们的数据集中有大量组件,有效的数据增强策略是将对象草图替换为同一类别中的其余组件。具体来说,我们为每个工人生成的场景自动生成了另外20个场景草图,并要求工人为Step2的每个场景模板选择4个最合理的场景。最后,我们在数据增强后获得了29K +粗略的场景图像。数据集统计与分析。总而言之,我们完全获得:
人类创造的1.7,264个独特的场景模板。每个场景模板包含至少3个对象实例,其中对象实例的最大数量为94.平均每个模板有16个实例,6个对象类和7个包含的实例。被遮挡实例的最大数量为66.图5示出了物体频率的分布。
数据增加后2.29,056个场景草图(步骤3);
3.11,316个属于44个类别的对象草图。这些组件可用于对象级草图研究任务;
4.4730独特的参考卡通风格图像,其成对对象与场景草图相对应;
5.所有草图都具有100%准确的语义级和实例级分段注释(如图6所示)。
可扩展性。通过数据集中提供的场景模板和草图组件,可以进一步扩充SketchyScene。 (1)人们可以对每个草图部分进行分割,以获得部分级别或笔划级别的信息; (2)草图组件可以替换为来自其他资源的草图,以生成具有更多样式的场景草图。
重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕结论,讨论和未来的工作,在本文中,我们介绍了第一个大型的场景草图数据集,称为SketchyScene。 它包含总共29,056个场景草图,使用7,264个场景模板和11,316个对象草图生成。 场景中的每个对象都进一步增加了语义标签和实例级掩码。 数据集是在模块化数据收集过程之后收集的,这使得它具有高度可扩展性和可扩展性。 我们已经展示了将多个基于图像的分割模型适应场景草图数据的主要挑战和信息性见解。 有一些很有希望的未来方向可以进一步增强我们的场景草图数据集,包括添加场景级注释和文本标题以启用基于文本的场景生成等应用程序。
开源关键词:SketchyScene
原文标题:SketchyScene: Richly-Annotated Scene Sketches
from: http://www.sohu.com/a/246667938_100177858
重磅开源人工智能大型场景草图数据集图像检索草图着色编辑和字幕相关推荐
- 重磅开源人工智能纹理分割自动分割由参考纹理覆盖图像自监督学习
重磅开源人工智能纹理分割自动分割由参考纹理覆盖图像自监督学习(特约点评:人工智能纹理分割自动分割由参考纹理覆盖图像自监督学习对于纹理分割提供了新的思路,这个创新点趣说人工智能必须推荐.来自网友小星的推 ...
- 今年CVPR,我们填补了3D场景布局数据集空白,并向全世界开源!
点击上方"3D视觉工坊",选择"星标" 干货第一时间送达 6月14日,"Learning 3D Generative Model" Work ...
- 阿里巴巴淘系开源大型3D家具数据集(3D-FUTURE)推动3D家居智能研究
出品 | 阿里巴巴新零售淘系技术部&躺平 阿里巴巴淘系技术部与英国伦敦大学伯贝克学院 Steve Maybank 教授(Fellow of the IEEE and a Member of t ...
- 重磅MIT开源人工智能算法评估和理解对抗Logit配对的稳健性
重磅MIT开源人工智能算法评估和理解对抗Logit配对的稳健性摘要:我们评估了对抗性Logit Pairing的稳健性,这是最近针对广告范例提出的防御措施. 我们发现,使用Adversarial Lo ...
- 重磅!谷歌开源TensorFlow 3D场景理解库
来源丨机器之心 编辑丨杜伟.陈萍 继 2020 年初 Facebook 开源基于 PyTorch 的 3D 计算机视觉库 PyTorch3D 之后,谷歌也于近日开源了一个基于 TF 框架的高度模块化和 ...
- 开源人工智能算法一种新颖的超像素采样网络深层特征来估计任务特定的超像素
开源人工智能算法一种新颖的超像素采样网络深层特征来估计任务特定的超像素摘要: 超像素提供图像数据的有效低/中级表示,这极大地减少了后续视觉任务的图像基元的数量. 现有的超像素算法无法区分,因此难以集成 ...
- 金城教授:基于手绘草图的图像检索技术研究
5 月 26 日下午,在第二十八期七牛云架构师实践日,金城教授进行了<基于手绘草图的图像检索技术研究>为题的演讲.本文是对演讲内容的整理. 作者介绍: 金城,复旦大学计算机科学技术学院教授 ...
- 300米远程深度估计:港科大重磅开源自动驾驶深度感知新技术,远超现有雷达|CVPR2020
原文链接:300 米远程深度估计:港科大重磅开源自动驾驶新技术,远超现有雷达|CVPR2020 本文原创首发自极市平台公众号,请授权后转载. 论文标题:Depth Sensing Beyond LiD ...
- NAS+CNN+Transformer=ViT-Res!MIT团队重磅开源ViT-Res,精度高于DeiT-Ti8.6%
关注公众号,发现CV技术之美 本文分享论文『Searching for Efficient Multi-Stage Vision Transformers』,由 MIT 团队重磅开源 ViT-Res, ...
最新文章
- iOS 通知观察者的被调函数不一定运行在主线程
- android152 笔记 2
- Android开发--初探SQLiteDataBase/数据库的创建,更新,插入,查询
- dev gridview 打印列数过多_R语言:如何将多张统计图绘制在一张上面
- wps文档提取关键词_Cisdem Document Reader5实用文档阅读器
- Docker和容器如何改善eZ的软件开发
- 网络协议 22 - RPC 协议(下)- 二进制类 RPC 协议
- 机器学习基础(三十八) —— 从几率到逻辑斯函数
- 保存页面的滚动条的位置
- 二分图最大权匹配:Kuhn-Munkres算法
- 搭建petalinux开发环境
- 1~3年产品经理经典面试题
- python时间序列分析包_python关于时间序列的分析
- 使用python库relate搭建LMS学习管理系统
- 软件测试中常用的简称
- MATLAB中如何作随时间变化图
- 电影《寒战1》中的管理知识
- 【DPABI教程】DPARSF详细教程笔记
- 打破应试教育的思想才是重生之路
- It‘s highly recommended that you fix the library with ‘execstack -c <libfile>‘, or link it with ‘-z