Python通过抓包和使用cookie爬取微博完全讲解(附视频)
今天给大家录制了一个爬新浪微博的爬虫,也用到了抓包分析网址,但相较于以前,单纯的使用抓包分析网址在新浪微博是无效的。
cookie是什么
某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)。目前有些 Cookie 是临时的,有些则是持续的。临时的 Cookie 只在浏览器上保存一段规定的时间,一旦超过规定的时间,该 Cookie 就会被系统清除。持续的 Cookie 则保存在用户的 Cookie 文件中,下一次用户返回时,仍然可以对它进行调用。
注意:
微博中的cookie有时间限制,如果运行有问题,可以更换下cookie
如何使用cookie
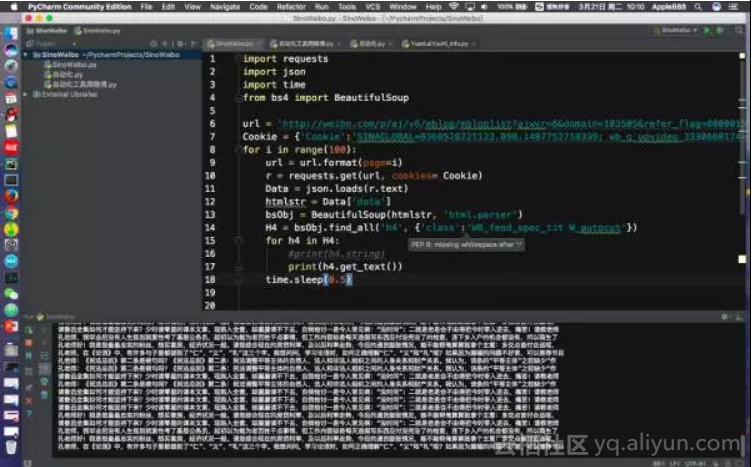
Cookie = {‘Cookie’: ’UM_distinctid=15ab64ecfd6592-0afad5b368bd69-1d3b6853-13c680-15ab64ecfd7b6;remember_user_token=W1sxMjEzMTM3XSwiJDJhJDEwJHhjYklYOGl2eTQ0Yi54WC5seVh2UWUiLCIxNDg5ODI2OTgwLjg4ODQyODciXQ%3D%3D---ac835770a030c0595b2993289e39c37d82ea27e2;CNZZDATA1258679142=559069578-1488626597-https%253A%252F%252Fwww.baidu.com%252F%7C1489923851’}我们要构造成字典格式,如上。这样应用到请求网址的时候添加到请求头中去即可(不懂也没关系,继续往下看,有视频讲说的)。
requests库
rquests is an elegant and simple HTTP library for Python, built for human beings. Requests是一个优雅简洁的Python HTTP库,给人类使用。
使用方法如下:
r=requests.get(url,cookiess = Cookie)实战分析
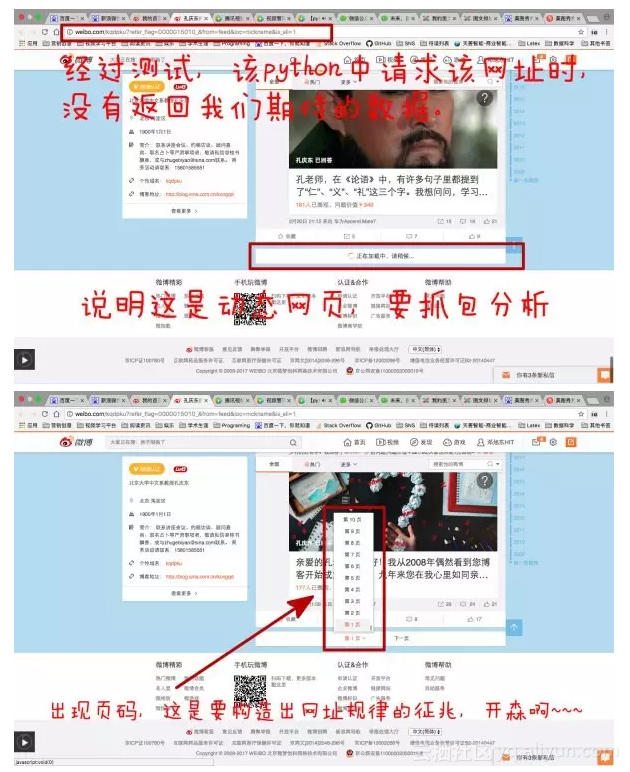
那么我们打开开发者工具,抓包分析下网址验证我们的网址规律思路
抓包分析

接下来我只是测试下,抓孔庆东微博博文的标题,如下图红色方框对应的html标签是h4
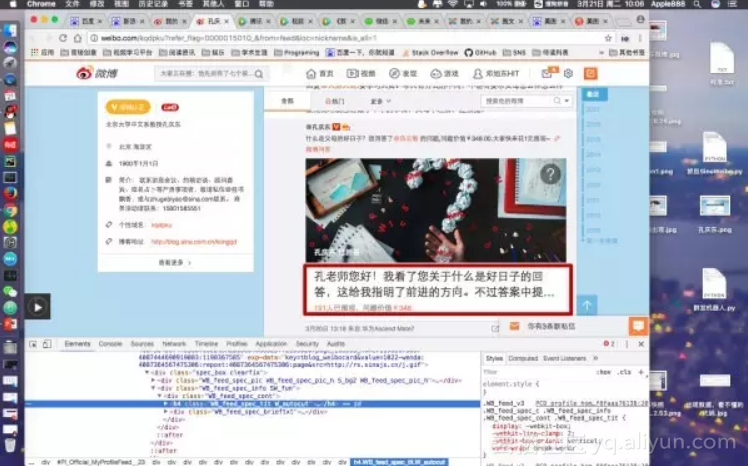
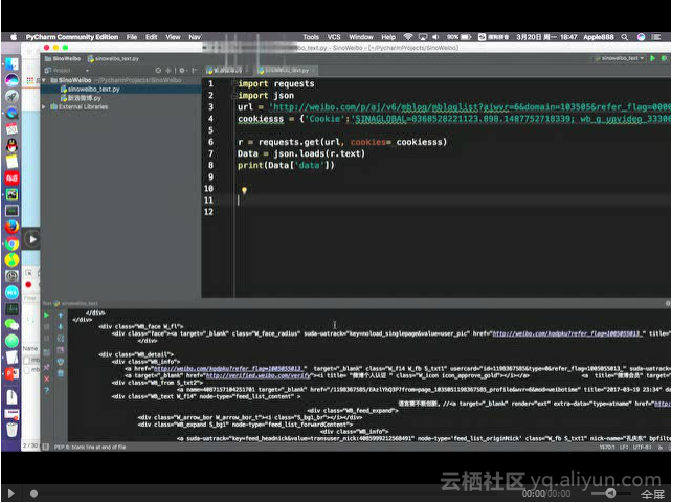
代码及运行图部分
本文视频讲解如下:
原文发布时间为:2017-03-21
本文作者:邓旭东
本文来自云栖社区合作伙伴“Python中文社区”,了解相关信息可以关注“Python中文社区”微信公众号
Python通过抓包和使用cookie爬取微博完全讲解(附视频)相关推荐
- python 爬虫实例-python爬虫实例,一小时上手爬取淘宝评论(附代码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- Python爬虫实例,一小时上手爬取淘宝评论(附代码)!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 1 明确目的 通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据. ...
- 爬虫实例:正则表达式爬取微博热搜榜
最近在学习python的爬虫知识,分享一个爬取微博热搜的实例,代码很简单. 用到了requests,re,xlwt库 直接看图: #1导入模块 import requests import re im ...
- php抓取微博评论,python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name" ...
- Python爬虫抓包工具使用
Python爬虫抓包工具使用 一. 常用的工具 python pycharm 浏览器 chrome 火狐 fiddler 2 fiddler的使用 二. 操作界面 三.界面含义 1. 请求 (Requ ...
- python 抓包 scapy udp,python+scapy 抓包與解析
最近一直在使用做流量分析,今天把 scapy 部分做一個總結. python 的 scapy 庫可以方便的抓包與解析包,無奈資料很少,官方例子有限,大神博客很少提及, 經過一番嘗試后,總結以下幾點用法 ...
- Python爬虫——批量爬取微博图片(不使用cookie)
引言:刚开始我想要爬取微博的照片,但是发现网上大多数的blog都是需要一个cookie的东西,当时我很难得到,偶然翻到一个个人的技术博客: http://www.omegaxyz.com/2018/0 ...
- python爬取微博内容_Python 爬虫如何机器登录新浪微博并抓取内容?
最近为了做事件分析写了一些微博的爬虫,两个大V总共爬了超70W的微博数据. 官方提供的api有爬取数量上限2000,想爬取的数据大了就不够用了... 果断撸起袖子自己动手!先简单说一下我的思路: 一. ...
- python 登陆微博 被删除 token_爬取微博信息,使用了cookie仍然无法登录微博
按照网上的模板自己写了类似的代码爬取微博,可是response回来的html是登录界面的html,应该是没有成功登陆微博,但是和网上的代码是基本一样的 from bs4 import Beautifu ...
最新文章
- python最新版本-最新版Python 3.8.6 版本发布
- Python 字符串与列表去重
- 细数非对称加密与对称加密的区别
- 【渝粤教育】 国家开放大学2020年春季 1303护理伦理学 参考试题
- HTML 链接 强制打开“另存为...”弹出式文本链接打开HTML
- 大小不固定的图片、多行文字的水平垂直居中
- android版本更新代码
- Qt error: collect2: error: ld returned 1 exit status
- 双层pdf软件free_如何一键下载网上文档以及pdf
- Flink从1.7到1.14版本升级汇总
- 前端二面必会面试题(附答案)
- vi php pear,PEAR
- linux pppd源码下载_linux pppd脚本配置(转载)
- 推荐一款实用的用户画像工具--快鲸scrm
- BUUCTF做题小结
- Crypto如何塑造数字革命 |链捕手
- java语言读后感_《Java语言程序设计基础篇》读后感锦集
- 怎么压缩jpg图片文件大小?jpg图片格式的压缩方法
- 2019年十大创新产品
- 农业平台设备:有人云DTU+精讯畅通传感器实现温度等采集