伯克利与微软联合发布Blink:使GPU计算实现高达2倍加速
本文来自SysML 2018,由星云Clustar编译并授权InfoQ发布,原文链接:http://www.sysml.cc/doc/151.pdf
大规模分布式机器学习应用中,GPU间参数聚合的速度对整体训练速度起到至关重要的作用,尤其当今GPU算力越来越强,参数聚合速度的重要性也日益显著。伯克利与微软在SysML 2018上推出了一个基于NVLink构建的高性能的参数聚合通讯库Blink并发表了相关论文。文中重点介绍了Blink的设计,并通过实验来证明其有效性。
1.引言
大型深度学习模型进行训练时,需要花费不少的时间,如ImageNet 1K等模型通常需要数天甚至数周才能在单个GPU上进行训练,所以就需要从单GPU扩展到多GPU进行训练。减少DNN训练时间最广泛使用的方法是使用数据并行随机梯度下降(SGD)来并行化训练。在数据并行训练中,每个GPU具有模型参数的完整副本,并且在输入数据的子集上独立地训练, GPU经常需要与参与训练的其他GPU交换参数。在大规模训练时,跨GPU同步参数会带来显著的开销 - 这个问题会因为GPU计算越来越快,模型规模越来越大而变得更加严重,从而使得通信成本上的问题变得愈发突出。
模型参数交换通常使用collective通信原语实现,例如All-Reduce [2]。NVIDIA collective通信库(NCCL)[7]是一种先进的实现方式,可通过PCIe或更新的互连方式(如NVLink)提供GPU间collective通信原语。通过将NCCL纳入Tensorfow [1],Uber的研究人员表明,端到端的训练过程可以加快60%。
但是,对于某个特定拓扑结构,NCCL并不总是有效地使用所有可用链路。这是因为NCCL使用的是基于环的模式进行数据传输,并在给定拓扑中创建尽可能多的环。考虑图1中的拓扑,是现代NVIDIA DGX-1的拓扑实现,这里我们从GPU A使用Broadcast操作。由于每个链路都是双向的,我们可以构建两个环,如图1所示(a)。从一个环开始是A-\u0026gt; B-\u0026gt; D-\u0026gt; C-\u0026gt; A,另一个反方向是A-\u0026gt; C-\u0026gt; D-\u0026gt; B-\u0026gt; A。要做广播A可以将数据分成两部分,并在每个环上发送一个部分。因此,如果数据大小为n并且链路带宽大小为b,则所花费的时间将是 n除以2b。请注意,A \u0026lt; - \u0026gt; D和B \u0026lt; - \u0026gt; C(虚线表示)的两个交叉链接没被有效利用起来。
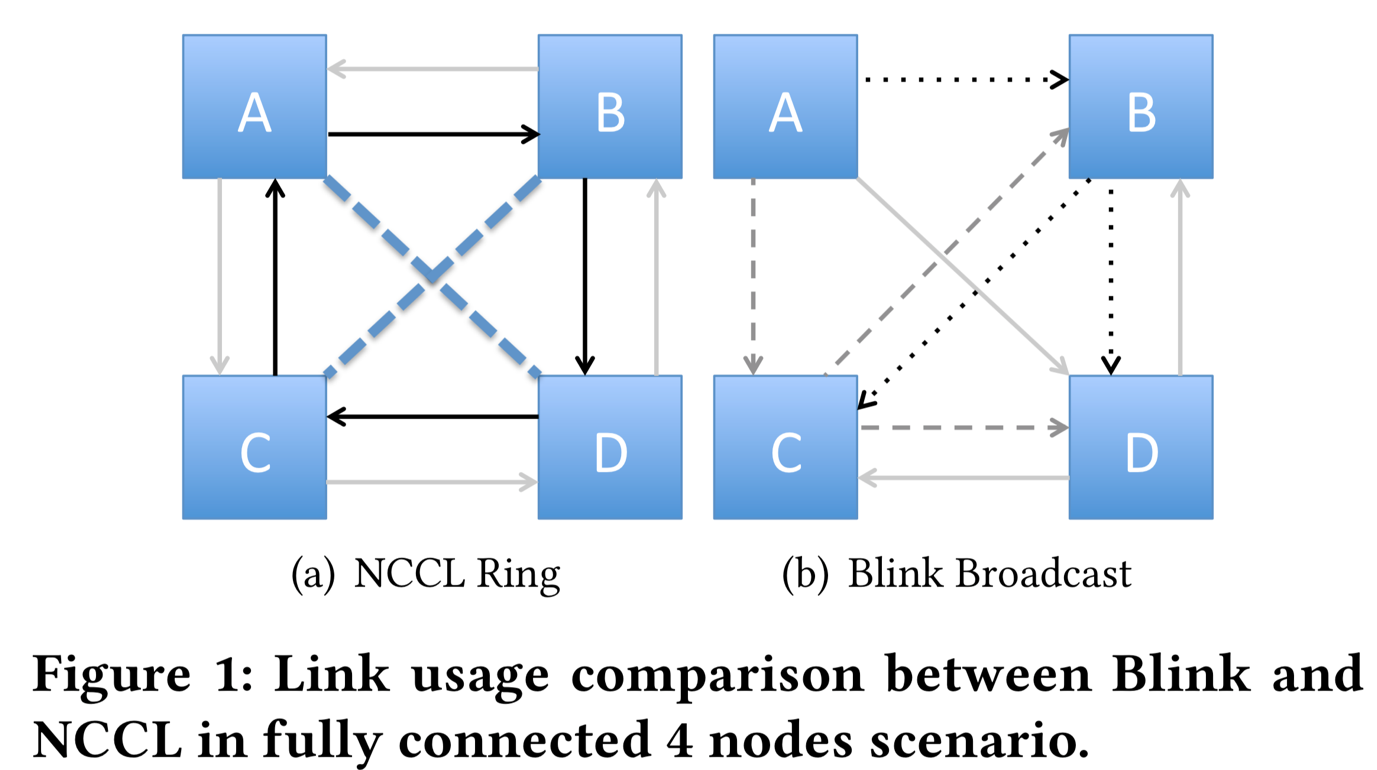
为实现更高的链路利用率,从而加快速度传输,我们提出Blink,这是一系列使用基于广播的数据传输方案的协议,能够充分利用相连的GPU组来实现更高效率。Blink还旨在克服拓扑异构性的困难,这种困难是由于使用的GPU数量不同、硬件层的异构性,多机器训练而引起的。例如,在图1(b)中,我们在Blink中展示了一个广播协议。在这种情况下,从GPU A发送到GPU B的数据,然后再被广播到GPU C和GPU D。我们可以构造三个这样的转发树,因此链路利用率提高,并且所花费的总时间变为n除以3b。
通常,Blink的协议遵循如下分层方案:对于给定网络拓扑,首先将网络划分为组内所有节点完全连接的组。在第一阶段,执行内部广播,其中使用组内的每个全连接节点进行通信交换数据。在第二阶段,执行跨组转发,跨组进行通信,并转发相应组内的跨组数据。我们在Blink中为四个通信原语(Broadcast,Gather,All-Gather,All-Reduce)设计了对应的通信协议。在NVIDIA DGX-1机器上使用多达8个GPU的实验表明,与最先进的库相比,Blink可以实现高达2倍的加速。
2.背景
GPU互连拓扑:在这项工作中使用的主要测试平台是NVIDIA DGX-1,它是一个配备8个P100或V100 GPU的架构。GPU不仅可以通过PCIe连接,还可以通过新设计的被称为NVLink [8]的互连技术连接。NVLink是一种高带宽且节能的互联技术,可实现20-25 GB / s的吞吐量。如图2(a)所示,基于P100的DGX-1具有NVLink拓扑。该拓扑结构由两个方形GPU组连接组成,此外还有2条跨GPU组的长连接。
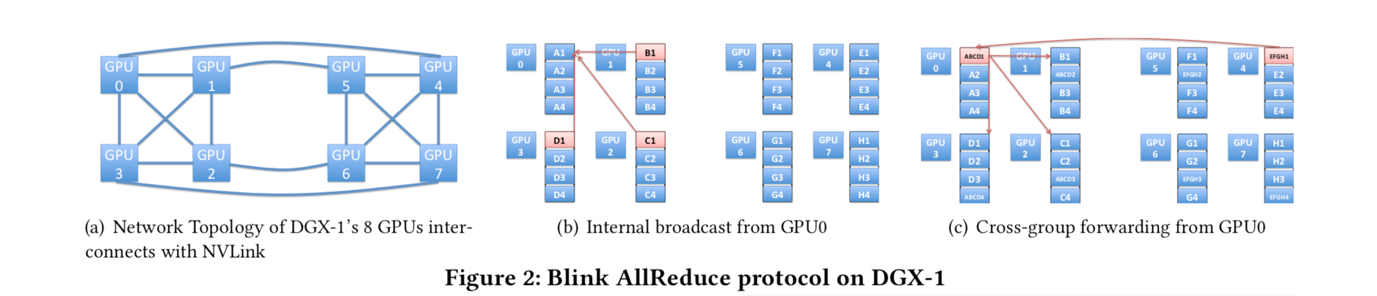
广播与环:基于环的NCCL数据传输浪费了无法形成新环的链路。基于网络拓扑结构,NCCL将拓扑划分为不相交的环。在大多数情况下,我们有剩余的、不能形成新的环的链接,导致这些链接闲置或浪费。在我们基于P100的DGX-1机器的NCCL基准测试中,如果我们使用4到7个GPU,它只能形成一个双向环(如图2(a)所示),超过一半的链路空闲。例如,如果我们在DGX-1机器内的8个GPU中使用6个GPU,则它仅使用16个NVLink中的6个。
3.BLINK
接下来,我们来说明Blink中基于广播的协议,将如何提高链路利用率,并处理可变数量的GPU。通常在调度数据传输之前,我们首先将节点划分为完全连接的组,在每个组内执行collective通信,然后跨组进行同步。虽然可以在任何网络拓扑中实现此节点分组,但为了简单起见,我们将讨论基于DGX-1拓扑的AllReduce协议。
3.1 Blink中的AllReduce
基于DGX-1拓扑,我们的协议以分层方式进行。首先,我们将此拓扑划分为两组,每组包含4个完全连接的GPU。我们使用内部广播在每个组内执行reduce,然后跨组通过跨组转发进行通信。
内部广播:在内部广播阶段,我们使用reduce-scatter协议。如果,每个组中有4个GPU,并将每个GPU上的数据分成4个块。然后,我们让GPU1,GPU2,GPU3将他们的第一块数据(即图2(b)中的B1,C1,D1)传输到GPU0,这样在这个reduce-scatter步骤之后,GPU0将拥有最终的第一块组内的结果(即ABCD1)。同时,我们将所有第二块数据传输到GPU1,以便GPU1具有第二块的最终结果,依此类推。在此阶段结束时,每个GPU将具有来自组内的最终结果的一个块。注意,即使当不使用组中的所有节点时(例如,当跨6个GPU执行all-reduce时),该方案也适用。由于来自完全连接组的节点的子集也完全连接,所以,我们可以复用上述相同的内部广播协议。
跨组转发:在跨组转发阶段,我们使用跨组链接来聚合其他组的内部结果,并在组内转发最终结果。在我们的示例中,GPU0从另一个组中接收GPU4的结果(即图2(c)中的EFGH1),并和自身的结果(即ABCD1)进行聚合,然后在组内转发最终结果的第一个数据块。整个过程用图2(c)中带箭头的线表示。注意,可以同时执行该聚合和转发。
3.2 Benchmark
接下来,介绍上述AllReduce方案的性能基准。
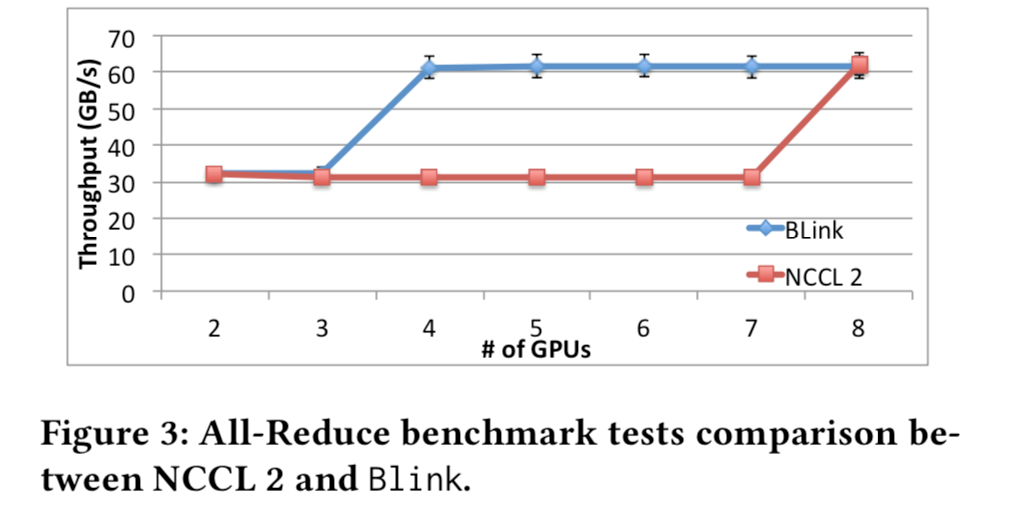
我们使用NVIDIA DGX-1机器并在每个GPU上初始化1GB数据。随着GPU的数量从2变为8,我们比较了NCCL 2和Blink实现的吞吐量。如图3所示,与NCCL 2相比,Blink可以在4到7个GPU情况下实现2倍的吞吐量。吞吐量差异的主要原因是Blink可以使用我们的两步数据传输方案来利用更多NVLink链路。
4.未来工作与结论
本文介绍了Blink,一个包含了一系列基于广播的collective通信原语的通讯库。与NCCL中基于环的数据传输相比,此方案可以实现更好的链路利用率、更高的吞吐量并在不同数量的GPU场景下依然有效。在当下硬件异构,以及跨机器Collective通信的环境中,我们将继续推广和拓展Blink。
伯克利与微软联合发布Blink:使GPU计算实现高达2倍加速相关推荐
- 英伟达发布ChatGPT专用GPU,性能提升10倍,还推出云服务,普通企业也能训练LLM...
Pine 发自 凹非寺 量子位 | 公众号 QbitAI "AI的iPhone时刻已至",英伟达或成最大赢家. 在GTC2023大会上,黄仁勋接连放出大招: 不仅发布了ChatGP ...
- 英伟达发布全球最大GPU:性能提升10倍,售价250万
夏乙 发自 凹非寺 量子位 出品 | 公众号 QbitAI 英伟达的新杀器又来了. 刚刚,在GTC 2018大会上,黄仁勋发布全球最大GPU. 他说的是DGX-2. DGX-2能够实现每秒2千万亿次浮 ...
- 强核问世:NVIDIA发布A100 80GB GPU,为AI超级计算带来全球最强GPU
近日,NVIDIA发布NVIDIA A100 80GB GPU,这一创新产品将支持NVIDIA HGX AI超级计算平台.该GPU内存比上一代提升一倍,能够为研究人员和工程师们提供空前的速度和性能,助 ...
- 首届昇腾计算产业峰会成功举办,AITISA与华为联合发布“白皮书”
2020年9月26日,由中国科学技术信息研究所指导,新一代人工智能产业技术创新战略联盟(AITISA).中国人工智能产业发展联盟(AIIA)."互联网+"联盟.华为技术有限公司联合 ...
- 秒云与趋动科技联合发布容器云平台与GPU资源池化整体解决方案
近日,秒云联合趋动科技,共同发布基于容器云平台与GPU资源池化整体解决方案,并完成秒云容器云平台与趋动科技OrionX AI算力资源池化解决方案的兼容认证测试,测试结果表明双方产品完全兼容,各项功能运 ...
- 每日新闻:百度首个无人驾驶运营项目落户武汉;微软叫停Linux专利战;网易携手芬兰电信Elisa;瑞星华为联合发布云安全解决方案...
关注中国软件网 最新鲜的企业级干货聚集地 今日热点 Gartner发布2018年第二季度全球服务器市场报告 日前,国际权威研究机构Gartner发布了2018年第二季度全球服务器市场报告,报告显示,在 ...
- 微软研究院和清华大学联合发布 “开放学术图谱(OAG)2.0版本”
来源:微软研究院AI头条 本文约3000字,建议阅读5分钟. 本文为你介绍了最新发布的开放学术图谱2.0版本. [导 读]开放学术组织(Open Academic Society)是由微软.清华.艾伦 ...
- 微软联合创始人都看好,这项技术有什么过人之处?
作者| flow 编辑| 3D视觉开发者社区 前言 本文针对当下深度学习模型太大的问题进行了技术改进,首次提出了XNOR-Net的概念.文章提出二值网络的两个版本,Binary-Weight-Netw ...
- 浪潮发布业界最高GPU密度的SR-AI整机柜
在不久前结束的2017浪潮云数据中心全国合作伙伴大会(IPF)上,浪潮秉承坚持围绕"计算+"战略,进一步明确业务重心,聚焦智慧计算,发展开放融合的计算生态,建立智慧计算市场的领导力 ...
- 美国 CISA 和 NIST 联合发布软件供应链攻击相关风险及缓解措施
聚焦源代码安全,网罗国内外最新资讯! 编译:奇安信代码卫士 专栏·供应链安全 数字化时代,软件无处不在.软件如同社会中的"虚拟人",已经成为支撑社会正常运转的最基本元素之一,软件 ...
最新文章
- iOS 快速定位到系统设置界面
- python操作js中的输入_Python调用JavaScript代码的方法
- 【深入Java虚拟机JVM 10】回收方法区
- 测试你的Python 水平----7
- Windows内置系统账户Local system/Network service/Local Service
- 3.4 常用的两种 layer 层 3.7 字体与文本
- ubuntu下cmake安装
- 强化学习环境学习-gym[atari]-paper中的相关设置
- 【Excel】用公式提取Excel单元格中的汉字
- 支持生僻字且自动识别utf-8编码的php汉字转拼音类,支持生僻字且自动识别utf-8编码的php汉字转拼音类...
- python-体质指数BMI计算
- String常用的api(最全)
- 怎样用计算机打出Abc,妙用智能ABC输入法 -电脑资料
- 解决2K、4K等高分屏下Photoshop窗口、字体太小等问题
- 实现复数类中的运算符重载
- pygame绘制简单游戏——壁球(图像型,节奏型)
- 0-1背包问题及python实现
- 期刊介绍|中科院一区8+期刊,影响因子飞涨,国人友好,明显扩刊趋势!
- 计算机课程设计jsp+servlet社区居民健康档案管理系统【安装调试+代码讲解+文档报告】
- 山雨欲来风满楼,历史关口考验个人助理柯塔娜