(六)6.6 Neurons Networks PCA
主成分分析(PCA)是一种经典的降维算法,基于基变换,数据原来位于标准坐标基下,将其投影到前k个最大特征值对应的特征向量所组成的基上,使得数据在新基各个维度有最大的方差,且在新基的各个维度上数据是不相关的,PCA有几个关键的点:
1)归一化均值与方差,均值归一化后便于计算,方差归一化后便于对各个维度进行比较
2)新基为正交基,即各个坐标轴是相互独立的(可理解为垂直),只需要取新基上取方差最大的前几个维度即可
3)PCA的前提是只对服从高斯分布的数据特征提取效果较好,这就大大限制了它的应用范围。如果数据呈任意分布,那么不论在原始空间中如何做正交变换,都不可能找到一组最优的特征方向,找到所谓的“主分量”也就不能表达数据的特征结构了(比如说数据呈现正方形)。
引入
假设有一条淘宝物品记录,格式如下:
( 浏览量, 访客数, 下单数, 成交数, 成交金额)
这五个属性可以代表五个维度,分别对应坐标系中的五个坐标轴(基),给定在这组基上的一组样本点:
(500,240,25,13,2312.15)T
可以看到这就是一条物品的记录,五个维度的计算并不复杂,但当处理的数据的维度上万,甚至十万、百万时,(比如1000*1000的图片)这种情况下会带来非常大的计算量,所以有必要对数据进行降维。降维意味着信息的丢失,比如对于以上数据,去掉下成交金额这一个维度,将丢失很多关于物品的信息,所以PCA只能尽量避免信息的丢失。
相关性:维度教高的数据在某几个维度间两辆一般会存在一些相关性,比如如上的浏览量与访客数往往成正比关系,这种情况下去掉其中一个维度,往往不会丢失太多信息。以上给出的只是直观的描述,我们到底删除哪一列损失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始数据决定具体的降维操作步骤?
线性代数基础
下面先来看一个高中就学过的向量运算:内积。两个维数相同的向量的内积被定义为:
![]()
内积运算会将向量映射为实数,下面看内积的几何意义,二维向量A,B,其中A=(x1,y1),B=(x2,y2),
![]()
现在从A点向B所在直线引一条垂线。这条垂线与B的交点叫做A在B上的投影,再设A与B的夹角是a,则投影的矢量长度为![]() ,其中
,其中![]() ,是线段A的长度
,是线段A的长度
把内积表示为一种熟悉的形式有:
![]()
A与B的内积等于A到B的投影长度乘以B的模。再进一步,如果我们假设B的模为1,即让|B|=1,那么就变成了:
![]()
也就是说,设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度!
再来看基的概念,我们对二维平面上的向量(x,y)非常熟悉,如以上的A、B就是两个向量,仔细看就知道(x,y)分别表示在x轴上的投影为x,在y周上的投影为y。也就是说这里有一个隐含定义,现在分别取x轴正向、y轴正向一个模为1的向量,向量(x,y)分别在x轴投影为x,在y轴投影为y,注意投影也为矢量。准确的表示为向量x,y的线性组合:
![]()
此时(1,0)T与(0,1)T可以称作向量的一组基。
![]()
所以要准确描述向量,首先要给定一组基,然后给向量在基的各个直线上的投影即可。标准坐标系下经常忽略第一步以(1,0)和(0,1)为基。
例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了。上面的基就可以变为![]()
现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,可以得到新基的坐标为:![]() ,下图给出点(3,2)在新基的图:
,下图给出点(3,2)在新基的图:
![]()
另外这里要注意的是,例子中的基都是正交的(即内积为0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
![]()
于是一组向量的基变换被干净的表示为矩阵的相乘。
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
![]()
特别要注意的是,这里R可以小于N,而R决定了变换后数据的维数。也就是说,我们可以将一N维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。很多同学在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
根据以上的基变换可以看出,如果给定一组新基,其维度小于向量本身的维度,则变换后的数据就是原始数据再新基中的地维表示,降维的目的就达到了,但对于PCA还有一个问题:即如何选取一组合理的基以最大化的保留原始信息?
先看一个例子,对于五条二维数据:
(1 ,1) (1 ,3) (2, 3) (4 ,4) (2 ,4)
将其表示为矩阵形式:
![]()
为了便于处理,把每个维度的的数据都减去对应维度的均值,这样每个维度均变为0均值。
![]()
可以看到,归一化为0均值后(注意,省略了方差归一化的步骤,因为数据在两个维度方差相同),样本在直角坐标系的图为
![]()
要把如上数据降低为1维,如何找到一个新的方向,使得信息尽可能不丢失呢?直观的做法是,投影后的点尽量分散,这种分散程度,可以用方差来度量,方差的公式如下:
![]()
对于每个维度都变化为0均值后,方差可以表示为:
![]()
于是问题转变为,寻找一组基,使得数据变化到这组基之后,方差最大。
对于n维数据降低到k维时,为了让两个维度尽可能多的保留初始信息,他们之间应该是独立的,不相关的,因为相关代表两个维度间存在冗余信息,对于均值归一化为0之后的数据,度量两个维度的相关性可以用协方差来表示:
![]()
当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
根据以上推倒,需要将协方差矩阵对角化,使得数据每个维度本身之间有最大的方差,而两两维度之间的协方差为0,即尽最大量减少数据的冗余,假设变化后的数据为Y,协方差矩阵为D,D为一个对角阵,且主对线线元素按大小排列,原始数据X的协方差矩阵为C,D与C的关系如下:
![]()
现在事情很明白了!我们要找的P不是别的,而是能让原始协方差矩阵对角化的P。
换句话说,优化目标变成了寻找一个矩阵P,满足PCPT是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量λλ重数为r,则必然存在r个线性无关的特征向量对应于λ,因此可以将这r个特征向量单位正交化。
由上面两条可知,一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,设这n个特征向量为![]() ,我们将其按列组成矩阵:
,我们将其按列组成矩阵:
![]()
其中Λ为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
到这里,我们发现我们已经找到了需要的矩阵P:
![]()
P是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是C的一个特征向量。如果设P按照ΛΛ中特征值的从大到小,将特征向量从上到下排列,则用P的前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
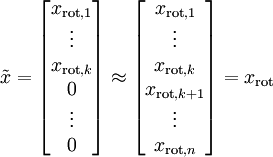
假设现在输入数据集表示为 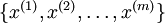 ,维度
,维度 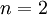 即
即 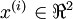 。假设我们想把数据从2维降到1维。(在实际应用中,我们也许需要把数据从256维降到50维;在这里使用低维数据,主要是为了更好地可视化算法的行为)。下图为数据集:
。假设我们想把数据从2维降到1维。(在实际应用中,我们也许需要把数据从256维降到50维;在这里使用低维数据,主要是为了更好地可视化算法的行为)。下图为数据集:
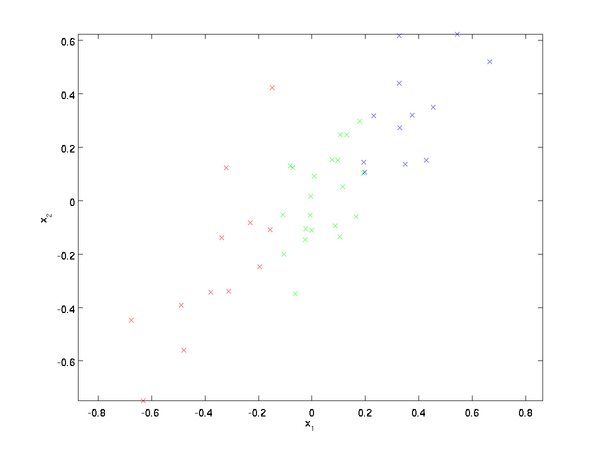
这些数据已经进行了预处理,使得每个特征 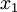 和
和 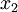 具有相同的均值(零)和方差。预处理的方式如下:
具有相同的均值(零)和方差。预处理的方式如下:
![]()
注意:这里1,2步是把数据各个维度的均值归一到0,而3,4步是把数据的方差归一为单位方差,这样各个维度间即可进行合理比较,否则数据各个维度规模不一致会导致方差的规模不一致(对于一些数据比如灰度图像,其在各个维度上的取值均为0-255之间的数值,所以对其进行方差归一化没有必要的,可以省略3,4步),为了使数据方差最大化,且降低数据之间的相关性,根据之前的分析,可以得到以下两个方向,根据图中显示,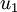 是数据变化的主方向,而
是数据变化的主方向,而 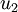 是次方向。
是次方向。
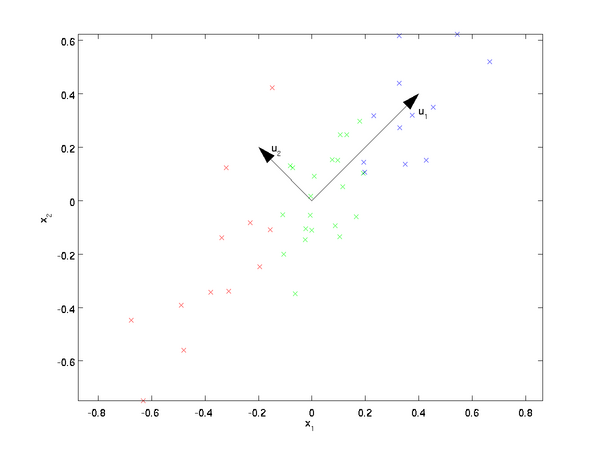
也就是说,数据在 方向上的变化要比在 方向上大。为更形式化地找出方向 和 ,首先计算出矩阵 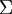 ,如下所示:
,如下所示:
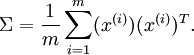
假设数据为三维,其协方差矩阵 为:
![]()
注意协方差矩阵的计算,![]() ,对于均值归一化后,直接在对应维度上相乘即可,先计算出协方差矩阵的特征向量,按列排放,而组成矩阵
,对于均值归一化后,直接在对应维度上相乘即可,先计算出协方差矩阵的特征向量,按列排放,而组成矩阵 :
:
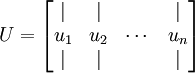
在本例中,向量 和 构成了一个新基,可以用来表示数据。令 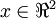 为训练样本,那么
为训练样本,那么 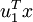 就是样本点
就是样本点  在维度 上的投影的长度(幅值)。同样的,
在维度 上的投影的长度(幅值)。同样的, 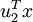 是 投影到 维度上的长度(幅值)。
是 投影到 维度上的长度(幅值)。
至此,我们可以把 用 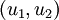 基表达为:
基表达为:
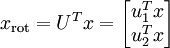
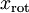 即为在新基下的坐标,在新基上,数据的方差可以表示为:
即为在新基下的坐标,在新基上,数据的方差可以表示为:
对数据集中的每个样本  分别进行旋转:
分别进行旋转: 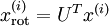 for every ,然后把变换后的数据 显示在坐标图上,可得:
for every ,然后把变换后的数据 显示在坐标图上,可得:
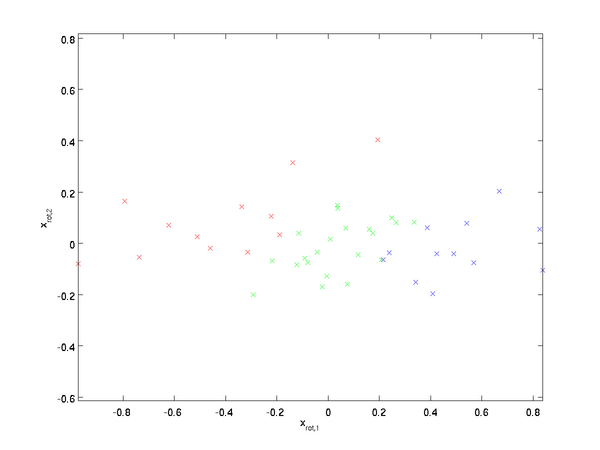
这就是把训练数据集旋转到 , 基后的结果。一般而言,运算 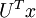 表示旋转到基 ,, ...,
表示旋转到基 ,, ...,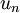 之上的训练数据。矩阵 有正交性,即满足
之上的训练数据。矩阵 有正交性,即满足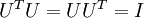 ,所以若想将旋转后的向量 还原为原始数据 ,将其左乘矩阵即可:
,所以若想将旋转后的向量 还原为原始数据 ,将其左乘矩阵即可: 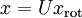 , 验算一下:
, 验算一下: 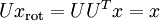 .
.
数据的主方向就是旋转数据的第一维 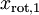 。因此,若想把这数据降到一维,可令:
。因此,若想把这数据降到一维,可令:
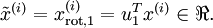
更一般的,假如想把数据 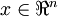 降到
降到  维表示
维表示 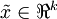 (令
(令 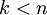 ),只需选取 的前 个成分,分别对应前 个数据变化的主方向。
),只需选取 的前 个成分,分别对应前 个数据变化的主方向。
PCA的另外一种解释是: 是一个 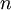 维向量,其中前几个成分可能比较大(例如,上例中大部分样本第一个成分
维向量,其中前几个成分可能比较大(例如,上例中大部分样本第一个成分 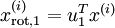 的取值相对较大),而后面成分可能会比较小(例如,上例中大部分样本的
的取值相对较大),而后面成分可能会比较小(例如,上例中大部分样本的 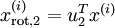 较小)。
较小)。
PCA算法做的其实就是丢弃 中后面(取值较小)的成分,就是将这些成分的值近似为零。具体的说,设 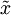 是
是 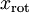 的近似表示,那么将 除了前 个成分外,其余全赋值为零,就得到:(这里 与 分别表示样本向量)
的近似表示,那么将 除了前 个成分外,其余全赋值为零,就得到:(这里 与 分别表示样本向量)
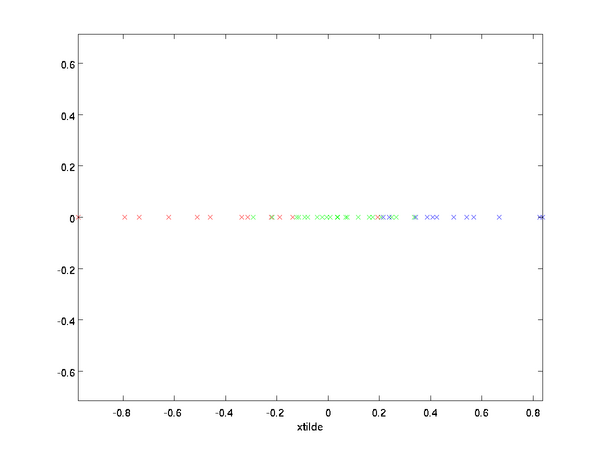
在本例中,可得 的点图如下(取 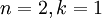 ):
):
然而,由于上面 的后 项均为零,没必要把这些零项保留下来。所以,我们仅用前 个(非零)成分来定义 维向量 。
项均为零,没必要把这些零项保留下来。所以,我们仅用前 个(非零)成分来定义 维向量 。
这也解释了为什么以 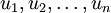 为基来表示数据:要决定保留哪些成分变得很简单,只需取前 个成分即可。得到了原始数据 的低维“压缩”表征量 , 反过来,如果给定 ,应如何还原原始数据 呢? 的基为要转换回来,只需 即可。把 看作将 的最后 个元素被置0所得的近似表示,给定 ,可以通过在其末尾添加 个0来得到对
为基来表示数据:要决定保留哪些成分变得很简单,只需取前 个成分即可。得到了原始数据 的低维“压缩”表征量 , 反过来,如果给定 ,应如何还原原始数据 呢? 的基为要转换回来,只需 即可。把 看作将 的最后 个元素被置0所得的近似表示,给定 ,可以通过在其末尾添加 个0来得到对 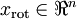 的近似,最后,左乘 便可近似还原出原数据 。计算如下:
的近似,最后,左乘 便可近似还原出原数据 。计算如下:
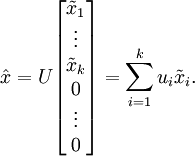
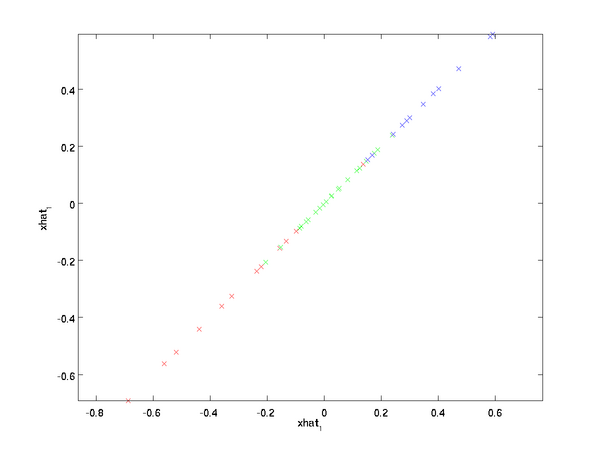
如下即为重构为原来基坐标下的点:
在PCA中有一个问题是主成分数K的选取,K的取值过大数据压缩效率不高,K的取值过小,数据信息丢失就会严重。决定K值得选取通常会考虑k的方差百分比,如果 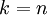 ,那么我们得到的是对数据的完美近似,也就是保留了100%的方差,即原始数据的所有变化都被保留下来;相反,如果
,那么我们得到的是对数据的完美近似,也就是保留了100%的方差,即原始数据的所有变化都被保留下来;相反,如果 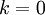 ,那等于是使用零向量来逼近输入数据,也就是只有0%的方差被保留下来。
,那等于是使用零向量来逼近输入数据,也就是只有0%的方差被保留下来。
一般而言,设 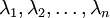 表示 的特征值(按由大到小顺序排列),使得
表示 的特征值(按由大到小顺序排列),使得 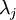 为对应于特征向量
为对应于特征向量 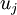 的特征值。即 投影后第j个维度的方差。保留前 个成分,则保留的方差百分比可计算为:
的特征值。即 投影后第j个维度的方差。保留前 个成分,则保留的方差百分比可计算为:
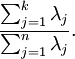
在上面简单的二维实验中,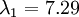 ,
,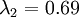 。因此,如果保留
。因此,如果保留 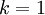 个主成分,等于我们保留了
个主成分,等于我们保留了 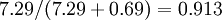 ,即91.3%的方差。
,即91.3%的方差。
容易证明,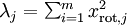 。因此,如果
。因此,如果 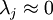 ,则说明
,则说明 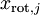 也就基本上接近于0,所以用0来近似它并不会产生多大损失。这也解释了为什么要保留前面的主成分(对应的 值较大)而不是末尾的那些。 这些前面的主成分 变化性更大,取值也更大,如果将其设为0势必引入较大的近似误差。
也就基本上接近于0,所以用0来近似它并不会产生多大损失。这也解释了为什么要保留前面的主成分(对应的 值较大)而不是末尾的那些。 这些前面的主成分 变化性更大,取值也更大,如果将其设为0势必引入较大的近似误差。
以处理图像数据为例,一个惯常的经验法则是选择 以保留99%的方差,换句话说,我们选取满足以下条件的最小 值:
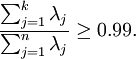
对其它应用,如不介意引入稍大的误差,有时也保留90-98%的方差范围。若向他人介绍PCA算法详情,告诉他们你选择的 保留了95%的方差,比告诉他们你保留了前120个(或任意某个数字)主成分更好理解。
协方差矩阵为PCA变换后数据在新基上的方差,取前K个特征值对应前K维最大的方差方向,且数据在新基的方向为特征值对应的特征向量方向:
![]()
中间那部分很熟悉啊,不就是样本特征的协方差矩阵么(![]() 的均值为0,一般协方差矩阵都除以m-1,这里用m)。用
的均值为0,一般协方差矩阵都除以m-1,这里用m)。用![]() 来表示
来表示![]() ,
,![]() 表示
表示![]() ,那么上式写作,
,那么上式写作,![]() 。由于u是单位向量,即
。由于u是单位向量,即![]() ,上式两边都左乘u得,
,上式两边都左乘u得,![]() ,即
,即![]() ,
,![]() 就是
就是![]() 的特征值,u是特征向量。最佳的投影直线是特征值
的特征值,u是特征向量。最佳的投影直线是特征值![]() 最大时对应的特征向量,其次是
最大时对应的特征向量,其次是![]() 第二大对应的特征向量,依次类推。因此,我们只需要对协方差矩阵进行特征值分解,得到的前k大特征值对应的特征向量就是最佳的k维新特征,而且这k维新特征是正交的。得到前k个u以后,样例
第二大对应的特征向量,依次类推。因此,我们只需要对协方差矩阵进行特征值分解,得到的前k大特征值对应的特征向量就是最佳的k维新特征,而且这k维新特征是正交的。得到前k个u以后,样例![]() 通过以下变换可以得到新的样本。
通过以下变换可以得到新的样本。
![]() 其中的第j维就是
其中的第j维就是![]() 在
在![]() 上的投影。
上的投影。
参考:
1) http://blog.codinglabs.org/articles/pca-tutorial.html
2) UFLDL
3) http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
转载于:https://www.cnblogs.com/ooon/p/5307122.html
(六)6.6 Neurons Networks PCA相关推荐
- (六) 6.1 Neurons Networks Representation
面对复杂的非线性可分的样本是,使用浅层分类器如Logistic等需要对样本进行复杂的映射,使得样本在映射后的空间是线性可分的,但在原始空间,分类边界可能是复杂的曲线.比如下图的样本只是在2维情形下的示 ...
- CS229 6.6 Neurons Networks PCA主成分分析
主成分分析(PCA)是一种经典的降维算法,基于基变换,数据原来位于标准坐标基下,将其投影到前k个最大特征值对应的特征向量所组成的基上,使得数据在新基各个维度有最大的方差,且在新基的各个维度上数据是不相 ...
- CS229 6.5 Neurons Networks Implements of Sparse Autoencoder
sparse autoencoder的一个实例练习,这个例子所要实现的内容大概如下:从给定的很多张自然图片中截取出大小为8*8的小patches图片共10000张,现在需要用sparse autoen ...
- pca 主成分分析_六分钟的主成分分析(PCA)的直观说明。
pca 主成分分析 Principle Component Analysis (PCA) is arguably a very difficult-to-understand topic for be ...
- 面向机器学习的特征工程 六、降维:用 PCA 压缩数据集
来源:ApacheCN<面向机器学习的特征工程>翻译项目 译者:@cn-Wziv 校对:@HeYun 通过自动数据收集和特征生成技术,可以快速获得大量特征,但并非所有这些都有用.在第 3 ...
- 第六篇:Feedforward Networks 前向网络
目录 深度学习 前馈神经网络 神经网络单元 矩阵向量表示法 输出层 从数据中学习 主题分类 主题分类 - 改进 作者署名 语言模型(回顾,前面的几篇讲过) 作为分类器的语言模型 前馈神经网络语言模型 ...
- 图神经网络论文阅读(十六) GraLSP: Graph Neural Networks with Local Structural Patterns,AAAI 2020
本文作者来自香港科技大学.北大和北邮,其中包含宋国杰老师和石川老师,这两位都是国内研究图表示学习的翘楚了.之前读石川团队论文的时候自己犯傻发邮件问了一个比较弱智的问题,石川老师还是让学生耐心帮我解答了 ...
- DL:深度学习算法(神经网络模型集合)概览之《THE NEURAL NETWORK ZOO》的中文解释和感悟(六)
DL:深度学习算法(神经网络模型集合)概览之<THE NEURAL NETWORK ZOO>的中文解释和感悟(六) 目录 DRN DNC NTM CN KN AN 相关文章 DL:深度学习 ...
- Squeeze-and-Excitation Networks(SENet )
SENet 是 ImageNet 2017(ImageNet收官赛)的冠军模型,和ResNet的出现类似,都在很大程度上减少了之前模型的错误率,并且复杂度低,新增参数和计算量小. SE block并不 ...
- pca降维python实例_Python机器学习笔记:使用scikit-learn工具进行PCA降维
之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-learn工具来进行PCA降维. 在数据处理中,经常会遇到特征维度比样本数量多得多 ...
最新文章
- count相加 sqlserver_mssql sqlserver sum(1)、sum(2)、count(1)、count(8)、count(*)、统计函数应用区别简介...
- 分布式项目 cookie共享方案
- 28岁程序员狂赚上亿宣布退休,网友:这就是命!
- eclipse插件开发(三) 简易4页签编辑器(源码 | 设计 | JS | CSS)配色修复JS多行注释问题
- Node.js连接mysql报加密方式错误解决方案
- 2018国庆雅礼D3T1
- 漂亮的不像实力派--锤子新品“坚果手机”发布会
- 算法分析与设计:众数问题(C++,分治法)
- 智能消防栓监控系统解决方案
- 人脸识别系统服务器摄像头,人脸识别摄像头要求
- 股指期货真是个好东西
- Ubuntu虚拟机安装
- 仪用放大电路+lm324三级放大+滤波
- 超级科技网络安全风险评估服务,全面了解网络系统面临的安全风险
- V853 替换开机启动LOGO
- 未明学院:国际政治专业出身,如何pk掉港大、美籍商科生,拿下亚马逊市场部德勤offer!
- ecu根据什么信号对点火提前角_刷ECU能让发动机秒变高功?工程师:你还太年轻...
- 一份DevOps工程师职责清单,待你查阅
- springcloud使用RestTemplate进行接口调用
- 【路径规划】基于matlab A_star算法机器人避障最短路径规划【含Matlab源码 2295期】
热门文章
- c++ idea 插件_IDEA的基本使用:让你的IDEA有飞一般的感觉
- 让计算机工作起来教学反思,计算机教学反思
- 谷歌浏览器截图_谷歌浏览器如何截图?
- linux 查看tomcat启动_一次tomcat启动特别慢的排查
- python做自动化控制postman_Python自动化学习笔记(1)认识接口测试以及postman、Charles工具简单应用...
- cognos报表导出excel_17个新增功能点,让报表更惊艳!
- 通过Web.config中的configSections配置自己系统的全局常量
- Red Hat 5.6-64位使用yum升级PHP
- ==、Equals 、ReferenceEquals它们的异同
- [C# 基础知识系列]专题十一:匿名方法解析