二分类模型评价指标-AUC
***********************************AUC的含义和计算****************************************
AUC针对二分类模型效果进行评价,二分类模型有时可能得到的是一个概率值,这个概率值表明为(0或1类)的可能性(不同于决策树分类,我们会直接得到一个确切分类),我们划定一个具体概率值p,大于则为正,小于则为负,然后使用acc或其他指标评价,其实这样做有很大漏洞,我们不能准确找到这个具体概率值p来确定正负样本的概率分界,这样得到的评价指标信服力和准确性都不稳定,于是我们提出了AUC,直接从概率值入手,仅仅对二分类模型进行评价。
①数学上的解释:ROC曲线下对应X轴的投影面积
ROC曲线:x轴为伪阳性率,y轴为真阳性率,真阳性率 = 真阳性数/(真阳性数+伪阳性数),伪阳性率= 伪阳性数/(真阳性数+伪阳性数),将真伪阳性率的值都标注在ROC平面上,再连起来构成ROC曲线,然后ROC在x轴的投影面积就是我们要求的AUC值。
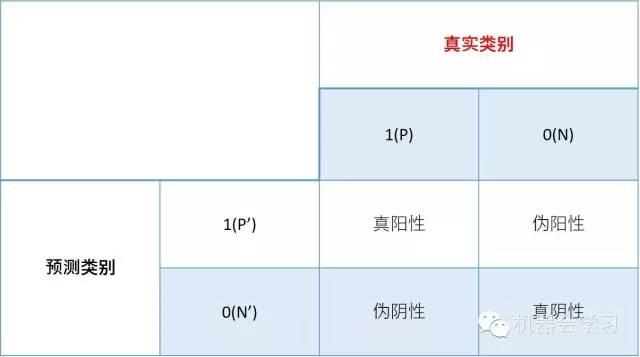
②通俗点的解释:从正样本中随机抽取一个样本,从负样本中随机抽取一个样本,通过二分类模型对其进行预测,得到正样本的预测概率为p1,负样本的为p2,p1>p2的可能性或概率就是AUC。
通过二分类模型,对所有正负样本获得一个score,首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。然后把所有的正类样本的rank相加,再减去所有正样本和正样本配对的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N(除以M×N就是转化为可能性)。即

公式解释:
1、为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1
2、根据上面的解释,不难得出,rank的值代表的是能够产生score前大后小的这样的组合数,但是这里包含了(正,正)的情况,所以要减去这样的组(即排在它后面正例的个数),即可得到上面的公式
另外,特别需要注意的是,再存在score相等的情况时,对相等score的样本,需要 赋予相同的rank(无论这个相等的score是出现在同类样本还是不同类的样本之间,都需要这样处理)。具体操作就是再把所有这些score相等的样本 的rank取平均。然后再使用上述公式。
二分类模型评价指标-AUC相关推荐
- [机器学习] 二分类模型评估指标---精确率Precision、召回率Recall、ROC|AUC
一 为什么要评估模型? 一句话,想找到最有效的模型.模型的应用是循环迭代的过程,只有通过持续调整和调优才能适应在线数据和业务目标. 选定模型时一开始都是假设数据的分布是一定的,然而数据的分布会随着时间 ...
- 衡量二分类模型的统计指标(TN,TP,FN,FP,F1,准确,精确,召回,ROC,AUC)
文章目录 - 衡量二分类问题的统计指标 分类结果 混淆矩阵 准确率 精确率 召回率 F1评分 推导过程 ROC曲线.AUC - 衡量二分类问题的统计指标 分类结果 二分类问题,分类结果有以下四种情 ...
- 机器学习100天(二十):020 分类模型评价指标-PR曲线
机器学习100天!今天讲的是:分类模型评价指标-PR曲线! <机器学习100天>完整目录:目录 上一节我们已经了解了混淆矩阵的概念,并掌握了精确率.召回率的计算公式,在这里.现在我们来学习 ...
- 机器学习100天(二十二):022 分类模型评价指标-Python实现
机器学习100天!今天讲的是:分类模型评价指标-Python实现! <机器学习100天>完整目录:目录 打开spyder,首先,导入标准库. import numpy as np impo ...
- 机器学习分类模型评价指标详述
问题建模 机器学习解决问题的通用流程:问题建模--特征工程--模型选择--模型融合 其中问题建模主要包括:设定评估指标,选择样本,交叉验证 解决一个机器学习问题都是从问题建模开始,首先需要收集问题的资 ...
- 分类模型评价指标说明
分类模型评价指标说明 分类涉及到的指标特别容易搞混,不是这个率就是那个率,最后都分不清谁是谁,这份文档就是为此给大家梳理一下. 文章目录 分类模型评价指标说明 混淆矩阵 例子 混淆矩阵定义 混淆矩阵代 ...
- auc到多少有意义_对模型评价指标AUC的理解
AUC是一种衡量机器学习模型分类性能的重要且非常常用的指标,其只能用于二分类的情况. AUC的本质含义反映的是对于任意一对正负例样本,模型将正样本预测为正例的可能性 大于 将负例预测为正例的可能性的 ...
- 对模型评价指标AUC的理解
AUC是一种衡量机器学习模型分类性能的重要且非常常用的指标,其只能用于二分类的情况. AUC的本质含义反映的是对于任意一对正负例样本,模型将正样本预测为正例的可能性 大于 将负例预测为正例的可能性的 ...
- 深入探讨分类模型评价指标
每天给你送来NLP技术干货! 来自:AI算法小喵 前言 众所周知,机器学习分类模型常用评价指标有Accuracy, Precision, Recall和F1-score,而回归模型最常用指标有MAE和 ...
- AI:神经网络IMDB电影评论二分类模型训练和评估
AI:Keras神经网络IMDB电影评论二分类模型训练和评估,python import keras from keras.layers import Dense from keras import ...
最新文章
- poj3280Cheapest Palindrome(记忆化)
- 矩阵树定理2020HDU多校第6场j-Expectation[位运算+期望]
- 跟我做CVS版本管理试验
- 各维度 特征 重要程度 随机森林_机器学习算法——随机森林
- JTLParser-linux上jmeter的jtl文件二次分析
- Vite2.0搭建Vue3移动端项目
- 观察者模式-对象行为型
- javascript中闭包的真正作用
- 移民新西兰,两个博客
- 建文高考成绩查询2021,2021届新高考语文强化模拟卷(三).pdf
- 2017年西南民族大学程序设计竞赛-网络同步赛
- 给你个使用NAS私有云服务器的理由
- 计算机双工模式,windows10系统如何设置网络双工模式?
- 怎么用linux给苹果手机降级,如何将软件包降级
- findfirst, findnext
- 高精度加法 高精度减法 高度除法 高精度乘法 方法总结
- 上班族做什么副业赚钱?全面解析副业赚钱模式!
- 【可视化分析案例】用python分析Top100排行榜数据
- VS2012 BIDS之Reporting Service/SSRS 项目
- 关于立象OS-214TT条码打印的一些问题