用Hadoop分析金庸人物关系网-实验报告
用Hadoop分析金庸人物关系网
--- 用大数据粗略的分析金庸人物关系网
整体结果报告
达到预期目标并完成了选做内容

实验目标描述:
金庸的江湖
课程设计目标
通过一个综合数据分析案例:”金庸的江湖--金庸武侠小说中的任务关系挖掘“,来学习和掌握MapReduce程序设计。通过本课程设计的学习,可以体会如何使用MapReduce完成一个综合性的数据挖掘任务,包括全流程的数据预处理、数据分析、数据后处理等。
涉及的编程技能:
1.Hadoop中使用第三发JAR包辅助分析
2.掌握简单的MapReduce算法设计:a) 单词同现算法;
b) 数据整理与归一化算法
c) 数据排序(选做)
3.掌握带有迭代特性的MapReduce算法设计:a) PageRank算法
b) 标签传播(Label Propagation)算法(选座)
...etc 具体见课程设计要求
编写环境
编写环境: VMware WorkStation 11 Ubuntu Hadoop 2.7.1 IDEA
测试编译环境: macOS Sierra 10.12.6 IDEA 2017
实际运行集群: 南京大学计算机系pasa大数据集群
编译依赖包:
ansj_seg-5.1.3.jar
nlp-lang-1.7.3.jar
hadoop-common-2.7.1.jar
hadoop-dfs-2.7.1.jar
hadoop-mapreduce-client-core-2.7.1.jar

带依赖打包运行在2.7.1的hadoop集群即可
实验进展流程图:
| Task | Main |
|---|---|
| Task1 | 提取人名,清理无关文本(使用已提供的名字册) |
| Task2 | 人名同现统计 |
| Task3 | 人物关系图构建与特征归一化 |
| Task4 | 基于人物关系图的PageRank计算 |
| Task5 | 数据分析:在人物关系图上的标签传播 并根据结果染色 |
| Task6 | 分析结果整理 |
实现代码模块
| Module | Function |
|---|---|
| 数据预处理 | Task1-Task3 |
| 数据处理-PageRank | Task4 |
| 数据处理-LPA | Task5 |
代码注解:
- Txt2name:
- TransferTask.java: 实现数据与处理方面的mapreduce的job设置,同时将人名列表放入cache中,方便后续的读取。
- TransferMapper.java: 完成自定义词典的配置,进行中文分词操作,提取出其中词性为Name的分词(在自定义词典时,将所有要提取的任务名称的词性均置为Name),提取出人名同现键对,以此作为reducer函数的输入。其中<value,key>为输出,value为人名,key为与其同现过的人名。
- TransferReducer.java: 以mapper的输出键对作为输入,将同样的键值对进行合并输出类似于<(a,b),time>的键对,以a为主要人物,进行下一步的权重归一化操作,根据不同键值对出现次数的不同,计算权重,将输出格式设为”人名1 人名2:权重2,人名3:权重3……”,各权重值之和为1。
- PageRank:
- PageRankDriver.java: 对外接口函数,可通过操作此函数来实现对其余功能的调用,并实现驱动多趟循环的功能
- GraphBuilder.java: 该java文件主要进行初始化操作,输入的<key,value>为<文本行号,文本内容>,对之进行处理,赋予初始的pr值输出为key:关系有向图节点人名,value:带pr值的从属人名
- PageRankIter.java: 此java文件包含了pagerank功能函数,,对初始化的pr的值进行迭代工作,参考书上内容后我们设置为迭代次数固定为30次,不对其进行是否收敛的判断以减少工作量。其中mapper函数的输入为上一轮迭代的输出,<key,value>中key为行号,value为每一行的内容,输出<key,value>中,key为人物名,value为更新后的pr值。将mapper的输出传入reducer函数中,输出新一轮迭代后的文件,格式为:”人名1 PR值 人名2:权重2,人名3:权重3,……”。
- PageRankViewer.java: 主要针对最后一次迭代的结果进行处理,调整其存储结构,只提取<人名,pr值>,将其输出到txt文件中,其中FinalRank中存储最后的PageRank结果。除此之外,在次函数中同时实现了对所有人名pr值的排序工作,将其从大到小一次排序。
- TagVisual:
- LPADriver.java: 为对外接口函数,调用此函数可以完成对LPA算法的调用,同时为满足多次迭代操作,在其中设置for循环,实现多趟操作功能。
- GraphBuilder.java: 对分词后的输出结果进行处理,将其格式设置为:”人名1 Tag |人名2:权重2:Tag2,人名3:权重3:Tag3,……”,在初始化时每个人物的标签设置为其本身。
- LPA.java: 此文件实现了LPA算法,将上一次迭代的输出文件作为下一次的输入文件,根据权重调整人名1的Tag值,并将其传送给与其相关的人物,监督其也调整Tag值。
- TagViewer.java: 在LPADriver.java中设置迭代次数为10次,因此TagViewer.java的输入文件为LPA迭代十次后的输出文件。首先自定义一个map存储结构,选取14篇文章中的”主人公”,将其Tag置为1~14后存入map中。对输入文件进行提取工作,(人名,Label),其中Label值为1~14。此Project主要为可视化操作提供文件输入。
- Gephi:
- 针对1模块输出的txt用python处理得到边的csv,通过2,3模块得到的pr和lpa tag处理得到点的csv。导入后稍加调整即可获得所需图像
具体模块内实现细节:
- Module1 没什么好说的,借助外部jar还是很好写的
- Module2 这部分的pagerank迭代参照书上MapReduce算法部分,结构相同,也没什么好说的,关键就是处理好map和reduce以及定义好处理的数据格式。实现上还需要注意pagerank的溢出和泄露问题,加个判断语句即可。
- Module3 这部分debug时间较长细节处会说
Module1:
就不给出详细描述了,详见作业设计中
这里仅仅给出应有的输入输出的图片


对于的处理结果可见处理的中间结果
Module2:
PageRank算法部分:
注意预防Rank Sink和Rank Leak
针对这两个问题,我们采取将表达式变为
pagerank = (double) (1 - 0.8) + 0.8 * pagerank;这种形式可以避免以上的问题(可以说阻尼系数是0.8)
- 一般来讲这个松弛系数取0.85,PRsum就是不同贡献值的和。最后,做一步清理工作,一是只保留人名和PageRank值,二是利用mapreduce自带的排序,将PageRank值作为主键,得到一个从高到低排序的人名表。
数据格式 :
| 状态 | 数据格式 |
|---|---|
| Module1执行后的结果 | 一灯大师 哑梢公:0.00234192037470726,鲁有脚:0.00936768149882904,杨康:0.00702576112412178,耶律燕:0...等 |
| PageRank初始化 | 一灯大师 1.0 哑梢公:0.00234192037470726,鲁有脚:0.00936768149882904,杨康:0.00702576112412178,耶律燕:...等 |
| PageRank Mapper 给所有从属节点发出 | 针对从属节点pagekey,value=weight*pr |
| PageRank Mapper 针对节点本身发出 | 一灯大师 1.0 |哑梢公:0.00234192037470726,鲁有脚:0.00936768149882904,杨康:0.00702576112412178,耶律燕:...等 |
| PageRank Reduce | 接受处理以上的同一个key的数据,当遇到直接的节点,权值,通过阻尼系数计算后的pagerank值相加,用于更新这个key的新的pr值,而加上|标识符号的串作为下一轮开始的初始串。 |
我们在这里一共迭代了30次(实际上15次基本就稳定了)
Module3
这个部分本来不应该有什么问题的,实际上却遇到了一个很严重的问题
这部分的算法基本参照Wayne1234他们的,我认为他们描述的比较好:
- 标签传播(Label Propagation)是一种半监督的图分析算法,他能为图上的顶点打标签,进行图顶点的聚类分析,从而在一张类似社交网络图中完成社区发现(Community Detection)。该任务中,我们用每个聚类的核心人物作为这个类的标签,比如下面输出中,“张无忌”实际上是一个标签名,表示“杨逍”属于张无忌这个类。
实现思路: LPA需要迭代,因此我们采用了和PageRank差不多的方式做了初始化,初始化文件的格式如下:
一灯大师 一灯大师&乔寨主,0.0022988506,乔寨主;华筝,0.0022988506,华筝;……
这里,“一灯大师”是key,value中,“&”前面的“一灯大师”表示key对应的标签,我们的初始化标签均和自己相同。后面,“乔寨主”是人名,中间数字是它的权重,后一个“乔寨主”是它的标签,在迭代的时候我们会更新这个标签,这里初始化的时候使用的是自己的名字。迭代过程中最关键的是如何选取新的标签,遍历“&”后面的“人名,权值,标签”列表,我们要统计出那个贡献值最高的标签。举例:
一灯大师 一灯大师&乔寨主,0.0022988506,乔寨主;华筝,0.0022988506,华筝;……
- 假设我们现在正在统计的就是这一行数据,在解析“&”后面的字符串时,除了第一次迭代之外,会出现多个人对应同一个标签的情况,因此需要一个数组来存储每个标签在当前字符串中的总权值,如果该标签还没出现,那把该标签新家进去,该标签的权值作为总权值的一个初值。比如说现在的这个数组是空的,我发现“乔寨主”的标签是“乔寨主”,那么这个数组里就应该添加一条记录:“乔寨主”这个标签的当前权值是0.00229…,后面还有“乔寨主”的话,直接用那个权值加上当前的“乔寨主”的总权值即可。我们还需要一个数组记录下这整个字符串中的所有人名,这个后面会用到。现在我们已经有了一组“标签,权重”的记录,因此从中挑选权重最高的作为key的标签就可以了,注意输出到reduce的时候,为了保持迭代时文件格式一致,应当将这个长字符串一起发送给reduce。我们还有一件事要做,告诉所有和当前key相关的其他key,当前key对应的标签变了,所以我们输出遍历之前记录了整个字符串中所有人名的数组,以单个人名为key,将更新过的当前的key和标签作为value也输出到reduce以供reduce更新。Reduce过程做的工作就是更新长字符串中的标签,最后按照统一格式写到文件。最后还有一步清理工作,只保留标签和人名输出一个最终文件即可。
这个地方的严重BUG
“有些人走着走着就散了”,在我们第一个版本的LPA迭代,一轮迭代后,1283行剩下了1178行,很多影响力大的人物后面的后缀加起来都没有1,很是奇怪。看了下我们的代码认为实现没有问题
先说说我们定义的数据格式在Map和Reduce阶段的变化:
- Mapper: 主串 Key newLabel | lineAfterKey(即原有从属权值信息等)
- Mapper: 通知更改串 Keylink & key : newLabel 其中keylink为从属人物 key为主标签 (这里其实有没有更新都会发送更改信息的)
- Reduce: 拿下主串,记录下原有从属权值信息
- Reduce: 根据通知更改串,更改标签为最新标签
详细的执行方式和上面描写的是一致的,而特别的识别符也是&
后面DeBug修改的是Reduce阶段的一个策略
初始的策略是:
Reduce阶段,首先取最长的那个基础串,记录下他们的权值(用hash记录)(因为另一种更新串的数据格式是 [ key & 原有key 已更改的新标签] 采取的被动更新,就是遍历reduce发过来的所有串,解析到&就更新一个新的子节点加进去。
结果就是有的人走着走着就散了,几次迭代过后就没数据了。
后期修改的策略:
Reduce阶段,首先取最长的那个基础串,记录下他们的权值(用hash记录)(因为另一种更新串的数据格式是 [ key & 原有key 已更改的新标签] 采取的主动更新,遍历主串的从属串,从解析到&的字符串中更新标签。这样就保证了一个都不会少
现在能确保得到结果可是任然不知道初始策略错在了哪里
这边的问题其实到现在还没想清楚,知道为什么的麻烦在issue中告知
Gephi部分的处理
起初在lpa标签传播阶段没有分类的,只是把最后每个人对应的标签打印处理,通过一个简单的python程序统计下一共多少种,之后给它分类到各个作品里,再写一个函数重新跑一标签使自动对应作品标号
Gephi需要的边和点的数据也不是很困难,通过python可以轻松的处理,关键是Gephi显示的数据有些迷,之前有几次一直把标签当做了主要的区别符号输出,导致了一大片一大片的标签名散在上面。后来调整里几下就好了
实验结果
Gephi总体结果:

更换参数获得的新聚类图: 说明我们的标签传播算法还是准确的

主要角色:

一些局部图 鹿鼎记

神雕侠侣
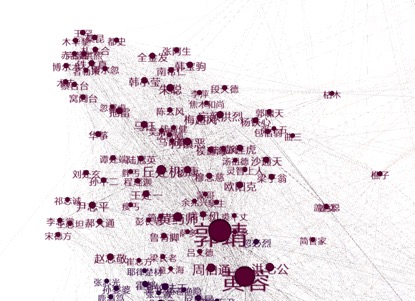
神雕侠侣和射雕英雄传的交界处

图中一些连接处 这边可以看出没有了其实应该占比较高的说不得什么的,因为在模块一中考虑了这一点特殊处理了一些只在某些作品中有意义的人物名

更多细节可以参见Gephi文件夹中的gephi文件
优化与总结
- 在分词部分,主要时间花在了外部依赖jar包的调整上,由于没有找到助教推荐的版本,采用了最新的版本,但在最新版本中,ansj_seg的函数接口与原版的略有不同。从最后的分词结果来看,可以认为此次实验中的分词工作基本完成,对人物权重进行归一化处理后,文件结构较为清晰,为之后的功能提供了一个较好的输入。
- 起初在人物中没有删除说不得等可变成常用语句的角色名,导致大汉、汉子、说不得这类词本来在某部作品中的人物可能到处出现,后来发现还有“农妇”,“胖妇人”“哑巴这种”,妥善的处理方式我认为是在之前加上作品前缀,就不会有滑稽的相关联了,因为这种角色名不可能是连着几部作品的。
- LPA标签传播部分遇到过一个很大的问题,错误处在第一次迭代上,初始化结束之后,第一轮迭代结果人物剩下了1180几个,而原来1283个,真的是“有些人走着走着就散了”,肯定是reduce出了问题,当时的策略是:map阶段,更新节点标签,同时产生一个通知所有相关节点的数据,在reduce阶段,遍历通知节点添加后缀产生新的字符串。这是一个被动的方式,到了凌晨3点多想到了解决方法,主动更新,也就是我们记录下所有的后缀,遍历后缀匹配,强制更新每个后缀的标签吗,这样果然就没有人散了。
- 大数据集群的运行状态资源分布有时候也会影响运行结果,举个例子,15号凌晨的时候有两个小组和我们一起跑,结果那次运行跑挂了,我们认为是代码问题,改了半天没发现错误,再次跑一遍就是正确的。
- 本次的结果优化,由于做实验起初就看到了比较好的方案,所以也没自己优化,要是编个起初怎么样,后期怎么样也没意思。集群的性能还是很强大的,我们的程序只有map和reduce,如果进一步优化其实可以再谢谢partition之类的?不过不影响最后结果。
Contributer:
| ID | Task |
|---|---|
| Ericyz | 组长,主要完成LPA部分Debug,数据可视化处理,实验报告总结,Github编写Wiki。 |
| 你爱上的我 | 主要完成PageRank–MapReduce算法设计,LPA-MapReduce算法设计。 |
| MissAngel | 主要完成小说中文分词功能,LPA部分Debug,实验报告撰写。 |
| 福克斯四世 | 主要完成小说中文分词功能,实验报告完善,jar包编译调试。 |
Reference:
金庸的江湖,人物关系分析 Jinyong-Novels-Analysis -Wayne1234 标签算法部分描述很好
基于15本金庸小说的人物关系图挖掘 MapReduce-JinYongsWorld -sunfvrise 代码框架结构很好 分成三个模块
《深入理解大数据》机械工业出版社,黄宜华,苗凯翔
PIG标签传播算法和超级英雄们的社区发现
转载于:https://www.cnblogs.com/ericyz/p/7225458.html
用Hadoop分析金庸人物关系网-实验报告相关推荐
- 不错的金庸人物考考你android游戏源码
这是刚刚在源码天堂上看到的一款不错的金庸人物考考你android游戏源码,分享给大家学习一下吧. 1.有关金庸原著小说的问答题.2.题目多为金庸qq群的比赛题.较难,目测能通关者不会很多.3.&quo ...
- 计算机基础知识实验结果及分析,计算机大学计算机基础实验报告.doc
计算机大学计算机基础实验报告 计算机__大学计算机基础实验报告 2012 年 12 月 13日 姓 名学 号年 级2012级专 业班 级2班实验题目:文件与文件夹的管理实验目的: 1.熟练掌握资源管理 ...
- 苍蝇的下场——金庸人物之招式应对
最残忍的打法--梅超风:抓住苍蝇以后,把脑袋揪下来,在上面按五个洞. 最损失的打法--一灯:几记一阳指过后,苍蝇倒是被烧焦了,可是屋里的彩电.床单.墙皮.地板无一幸免...... 最仿生的打法--欧阳 ...
- 编译原理预测分析法c语言,编译原理预测分析法C语言的实验报告.doc
题目:编写识别由下列文法所定义的表达式的预测分析程序. EàE+T | E-T | T TàT*F | T/F |F Fà(E) | i 输入:每行含一个表达式的文本文件. 输出:分析成功或不成功信息 ...
- 第二次实验报告:使用Packet Tracer分析应用层协议
姓名:谢明亮 学号:201821121103 班级:1814 1.实验目的 熟练使用Packet Tracer工具.分析抓到的应用层协议数据包,深入理解应用层协议,包括语法.语义.时序. 2.实验内容 ...
- matlab数字信号处理实验报告,数字信号处理实验报告(Matlab与数字信号处理基础).doc...
西华大学实验报告(理工类) 开课学院及实验室:电气信息学院 6A-205实验时间 :年月日学 生 姓 名学号成 绩学生所在学院电气信息学院年级/专业/班课 程 名 称数字信号处理课 程 代 码实验项目 ...
- 华北电力大学计算机图形学实验报告,华北电力大学计算机图形学实验报告分析.doc...
华北电力大学计算机图形学实验报告分析 科 技 学 院 课程设计(综合实验)报告 ( 2013 -- 2014 年度第 2 学期) 实验名称 OpenGL基本图元绘制实验 课程名称 计算机图形学 | | ...
- 计算机网络数据分析报告,贵州大学计算机网络实验报告-实验四-分析IP协议数据包格式...
贵州大学计算机网络实验报告-实验四-分析IP协议数据包格式 (7页) 本资源提供全文预览,点击全文预览即可全文预览,如果喜欢文档就下载吧,查找使用更方便哦! 9.9 积分 贵州大学GUIZHOU UN ...
- Java1.使用二分搜索算法查找任意N个有序数列中的指定元素。 2.通过上机实验进行算法实现。 3.保存和打印出程序的运行结果,并结合程序进行分析,上交实验报告。 4.至少使用两种方法进行编程,直接查
1.使用二分搜索算法查找任意N个有序数列中的指定元素. 2.通过上机实验进行算法实现. 3.保存和打印出程序的运行结果,并结合程序进行分析,上交实验报告. 4.至少使用两种方法进行编程,直接查找/递归 ...
最新文章
- C#调用API向外部程序发送数据(转载)
- Android Volley入门到精通:初识Volley的基本用法
- 一种简洁明了地读取文本文件的方法
- php识别地址,实现地址自动识别实例(PHP)
- python程序设计方法_Python程序设计现代方法
- fastadmin绑定edit.html,FAST-ADMIN 根据生成命令行修改页面
- mysql入门很简单(一)
- java正向最大匹配算法_java中文分词之正向最大匹配法实例代码
- 第一篇 你好,我叫Flask
- 北斗导航 | ARAIM:Advanced RAIM流程及基本原理(LPV-200)
- 如何对接快递助手物流查询接口【干货】
- 编译libpng + zlib
- 惠普、华三、华为、戴尔、联想服务器维保查询地址汇总
- linux平台生成awr报告,Linux平台生成awr报告
- MySQL 8 安装教程
- 坚持#第212天~零基础自学云计算基础语言应用1~5节
- 《指弹:The Sprinter》
- 【Java设计模式】——单例模式
- Unveiling the java.lang.Out OfMemoryError
- Ubuntu20.04安装Nvidia驱动——4060显卡(黑屏解决方法)
热门文章
- HTML的无序(ul)、有序(ol)、定义(dl)列表标签
- 阿里云官方出品:全面总结阿里云云原生架构方法论与实践经验
- centos挂载盘到根下_centos挂载磁盘及扩展根目录
- 二级路由dhcp关闭连不上wifi_无线宽带路由器除了WiFi上网还能有什么用,如何正确设置DHCP服务...
- CentOS7中使用yum安装Nginx
- python语音唤醒功能_百度语音识别 语音唤醒失败
- 使用Python做QQ机器人
- 腾讯文档导出Excel文档显示‘文件已损坏,无法打开‘解决方法
- MS COCO数据集人体关键点评估(Keypoint Evaluation)(来自官网)
- (附源码)springboot基于微信小程序的高校计算机类课程思政库的设计与实现 毕业设计 271611