Hadoop(十二):从源码角度分析Hadoo是如何将作业提交给集群的
为什么80%的码农都做不了架构师?>>> 
一:MapReduce提交作业过程的流程图
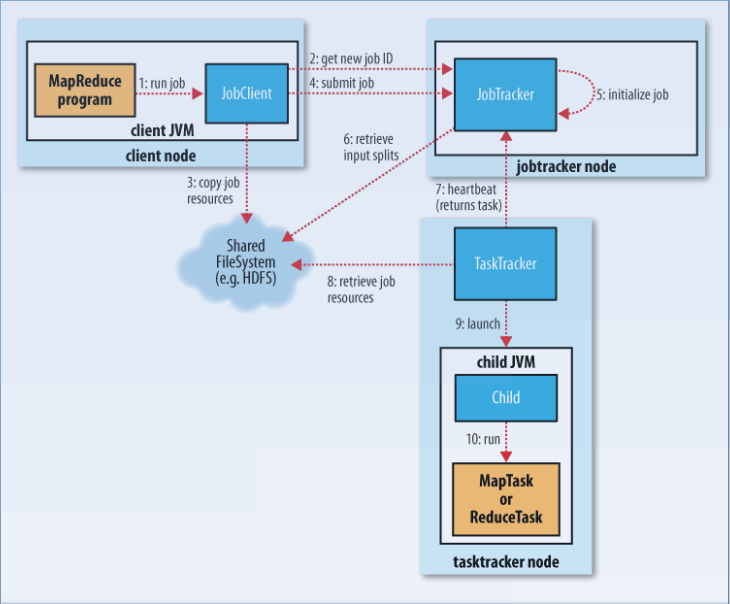
通过图可知主要有三个部分,即: 1) JobClient:作业客户端。 2) JobTracker:作业的跟踪器。 3) TaskTracker:任务的跟踪器。
MapReduce将作业提交给JobClient,然后JobClient与JobTracker交互,JobTracker再去监控与分配TaskTracker,完成具体作业的处理。
以下分析的是Hadoop2.6.4的源码。请注意: 源码与之前Hadoop版本的略有差别,所以有些概念还是与上图有点差别。
二:MapReduce如何提交作业
2.1 完成作业的真正提交,即:
**job.waitForCompletion(true)**
跟踪waitForCompletion, 注意其中的submit(),如下:
/*** Submit the job to the cluster and wait for it to finish.*/public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,ClassNotFoundException {if (state == JobState.DEFINE) {submit();}if (verbose) {monitorAndPrintJob();} else {// get the completion poll interval from the client.int completionPollIntervalMillis = Job.getCompletionPollInterval(cluster.getConf());while (!isComplete()) {try {Thread.sleep(completionPollIntervalMillis);} catch (InterruptedException ie) {}}}return isSuccessful();}
参数 verbose ,如果想在控制台打印当前的任务执行进度,则设为true
**
2.2 submit()
** 在submit 方法中会把Job提交给对应的Cluster,然后不等待Job执行结束就立刻返回
同时会把Job实例的状态设置为JobState.RUNNING,从而来表示Job正在进行中
然后在Job运行过程中,可以调用getJobState()来获取Job的运行状态
/*** Submit the job to the cluster and return immediately.*/public void submit() throws IOException, InterruptedException, ClassNotFoundException {ensureState(JobState.DEFINE);setUseNewAPI();connect();final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {return submitter.submitJobInternal(Job.this, cluster);}});state = JobState.RUNNING;LOG.info("The url to track the job: " + getTrackingURL());}而在任务提交前,会先通过connect()方法链接集群(Cluster):
private synchronized void connect()throws IOException, InterruptedException, ClassNotFoundException {if (cluster == null) {cluster = ugi.doAs(new PrivilegedExceptionAction<Cluster>() {public Cluster run()throws IOException, InterruptedException, ClassNotFoundException {return new Cluster(getConfiguration());}});}}
这是一个线程保护方法。这个方法中根据配置信息初始化了一个Cluster对象,即代表集群
public Cluster(Configuration conf) throws IOException {this(null, conf);}public Cluster(InetSocketAddress jobTrackAddr, Configuration conf) throws IOException {this.conf = conf;this.ugi = UserGroupInformation.getCurrentUser();initialize(jobTrackAddr, conf);}private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)throws IOException {synchronized (frameworkLoader) {for (ClientProtocolProvider provider : frameworkLoader) {LOG.debug("Trying ClientProtocolProvider : "+ provider.getClass().getName());ClientProtocol clientProtocol = null; try {if (jobTrackAddr == null) {clientProtocol = provider.create(conf);} else {clientProtocol = provider.create(jobTrackAddr, conf);}if (clientProtocol != null) {clientProtocolProvider = provider;client = clientProtocol;LOG.debug("Picked " + provider.getClass().getName()+ " as the ClientProtocolProvider");break;}else {LOG.debug("Cannot pick " + provider.getClass().getName()+ " as the ClientProtocolProvider - returned null protocol");}} catch (Exception e) {LOG.info("Failed to use " + provider.getClass().getName()+ " due to error: " + e.getMessage());}}}if (null == clientProtocolProvider || null == client) {throw new IOException("Cannot initialize Cluster. Please check your configuration for "+ MRConfig.FRAMEWORK_NAME+ " and the correspond server addresses.");}}
而在上段代码之前,
private static ServiceLoader<ClientProtocolProvider> frameworkLoader =ServiceLoader.load(ClientProtocolProvider.class);
可以看出创建客户端代理阶段使用了java.util.ServiceLoader,包含LocalClientProtocolProvider(本地作业)和YarnClientProtocolProvider(yarn作业)(hadoop有一个Yarn参数mapreduce.framework.name用来控制你选择的应用框架。在MRv2里,mapreduce.framework.name有两个值:local和yarn),此处会根据mapreduce.framework.name的配置创建相应的客户端
mapred-site.xml:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
2.3 实例化Cluster后开始真正的任务提交
submitter.submitJobInternal(Job.this, cluster);
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException {//validate the jobs output specs checkSpecs(job);Configuration conf = job.getConfiguration();addMRFrameworkToDistributedCache(conf);Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);//configure the command line options correctly on the submitting dfsInetAddress ip = InetAddress.getLocalHost();if (ip != null) {submitHostAddress = ip.getHostAddress();submitHostName = ip.getHostName();conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);}JobID jobId = submitClient.getNewJobID();job.setJobID(jobId);Path submitJobDir = new Path(jobStagingArea, jobId.toString());JobStatus status = null;try {conf.set(MRJobConfig.USER_NAME,UserGroupInformation.getCurrentUser().getShortUserName());conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir");// get delegation token for the dirTokenCache.obtainTokensForNamenodes(job.getCredentials(),new Path[] { submitJobDir }, conf);populateTokenCache(conf, job.getCredentials());// generate a secret to authenticate shuffle transfersif (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {KeyGenerator keyGen;try {int keyLen = CryptoUtils.isShuffleEncrypted(conf) ? conf.getInt(MRJobConfig.MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS, MRJobConfig.DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS): SHUFFLE_KEY_LENGTH;keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);keyGen.init(keyLen);} catch (NoSuchAlgorithmException e) {throw new IOException("Error generating shuffle secret key", e);}SecretKey shuffleKey = keyGen.generateKey();TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),job.getCredentials());}copyAndConfigureFiles(job, submitJobDir);Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);// Create the splits for the jobLOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));int maps = writeSplits(job, submitJobDir);conf.setInt(MRJobConfig.NUM_MAPS, maps);LOG.info("number of splits:" + maps);// write "queue admins of the queue to which job is being submitted"// to job file.String queue = conf.get(MRJobConfig.QUEUE_NAME,JobConf.DEFAULT_QUEUE_NAME);AccessControlList acl = submitClient.getQueueAdmins(queue);conf.set(toFullPropertyName(queue,QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());// removing jobtoken referrals before copying the jobconf to HDFS// as the tasks don't need this setting, actually they may break// because of it if present as the referral will point to a// different job.TokenCache.cleanUpTokenReferral(conf);if (conf.getBoolean(MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {// Add HDFS tracking idsArrayList<String> trackingIds = new ArrayList<String>();for (Token<? extends TokenIdentifier> t :job.getCredentials().getAllTokens()) {trackingIds.add(t.decodeIdentifier().getTrackingId());}conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,trackingIds.toArray(new String[trackingIds.size()]));}// Set reservation info if it existsReservationId reservationId = job.getReservationId();if (reservationId != null) {conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());}// Write job file to submit dirwriteConf(conf, submitJobFile);//// Now, actually submit the job (using the submit name)//printTokens(jobId, job.getCredentials());status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());if (status != null) {return status;} else {throw new IOException("Could not launch job");}} finally {if (status == null) {LOG.info("Cleaning up the staging area " + submitJobDir);if (jtFs != null && submitJobDir != null)jtFs.delete(submitJobDir, true);}}}通过如下代码正式提交Job到Yarn:
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
到最后,通过RPC的调用,最终会返回一个JobStatus对象,它的toString方法可以在JobClient端打印运行的相关日志信息。
if (status != null) {return status;}
public String toString() {StringBuffer buffer = new StringBuffer();buffer.append("job-id : " + jobid);buffer.append("uber-mode : " + isUber);buffer.append("map-progress : " + mapProgress);buffer.append("reduce-progress : " + reduceProgress);buffer.append("cleanup-progress : " + cleanupProgress);buffer.append("setup-progress : " + setupProgress);buffer.append("runstate : " + runState);buffer.append("start-time : " + startTime);buffer.append("user-name : " + user);buffer.append("priority : " + priority);buffer.append("scheduling-info : " + schedulingInfo);buffer.append("num-used-slots" + numUsedSlots);buffer.append("num-reserved-slots" + numReservedSlots);buffer.append("used-mem" + usedMem);buffer.append("reserved-mem" + reservedMem);buffer.append("needed-mem" + neededMem);return buffer.toString();}
(到这里任务都给yarn了,这里就只剩下监控(如果设置为true的话)),即:
if (verbose) {monitorAndPrintJob();}
这只是完成了作业Job的提交。
转载于:https://my.oschina.net/gently/blog/693954
Hadoop(十二):从源码角度分析Hadoo是如何将作业提交给集群的相关推荐
- Mybatis底层原理学习(二):从源码角度分析一次查询操作过程
在阅读这篇文章之前,建议先阅读一下我之前写的两篇文章,对理解这篇文章很有帮助,特别是Mybatis新手: 写给mybatis小白的入门指南 mybatis底层原理学习(一):SqlSessionFac ...
- 【Android 插件化】Hook 插件化框架 ( 从源码角度分析加载资源流程 | Hook 点选择 | 资源冲突解决方案 )
Android 插件化系列文章目录 [Android 插件化]插件化简介 ( 组件化与插件化 ) [Android 插件化]插件化原理 ( JVM 内存数据 | 类加载流程 ) [Android 插件 ...
- 从源码角度分析MapReduce的map-output流程
文章目录 前言 流程图 源码分析 1 runNewMapper方法 2.NewOutputCollector方法 2.1 createSortingCollector方法 2.1.1 collecto ...
- Android开发知识(二十三)从源码角度分析ListView的滑动复用机制
文章目录 前言 认识RecycleBin机制 ListView的布局方式 ListView的元素创建流程 ListView滑动加载过程 前言 ListView作为一个常用的列表控件,虽然现在基本被Re ...
- 从源码角度分析 Mybatis 工作原理
作者:vivo互联网服务器团队-Zhang Peng 一.MyBatis 完整示例 这里,我将以一个入门级的示例来演示 MyBatis 是如何工作的. 注:本文后面章节中的原理.源码部分也将基于这个示 ...
- 带你从源码角度分析ViewGroup中事件分发流程
序言 这篇博文不是对事件分发机制全面的介绍,只是从源码的角度分析ACTION_DOWN.ACTION_MOVE.ACTION_UP事件在ViewGroup中的分发逻辑,了解各个事件在ViewGroup ...
- 从源码角度分析MapReduce的reduce流程
文章目录 前言 流程图 Reduce都干了哪些事? 源码分析 1.run方法 1.1 比较器getOutputValueGroupingComparator 1.1.1 getOutputKeyCom ...
- 【易懂】Java源码角度分析put()与putIfAbsent()的区别——源码分析系列
一.put()方法 1. 源码分析 Java中并未给出put()的源码,因此我们看一下put()方法中给出的注释: Associates the specified value with the sp ...
- 从源码角度分析Android中的Binder机制的前因后果
为什么在Android中使用binder通信机制? 众所周知linux中的进程通信有很多种方式,比如说管道.消息队列.socket机制等.socket我们再熟悉不过了,然而其作为一款通用的接口,通信开 ...
最新文章
- locust入门:单机使用locust运行压力测试
- Git远程仓库Github
- k8s基础概念:pause容器和pod控制器类型
- CLR via C# (二)
- 谈谈技术原则,技术学习方法,代码阅读及其它
- 本地页面存1天的缓存
- NET-由于该控件目前不可见、未启用或类型不允许,因此无法将焦点移向
- 【C】malloc动态分配内存和free释放
- java适应性自旋锁_深夜!小胖问我,什么是自旋锁?怎么使用?适用场景是啥?...
- 解决maven打包打不进lib下的第三方jar包问题
- mysql如何进行数据透视,mysql-如何优化数据透视表的条件检查?
- 反射创建对象_面试题汇集——java反射
- chrome官网下载网址
- 新浪微博如何批量删除以前发过的微博
- 华为是怎样研发的(10)——知识管理
- 使用Route报错:A <Route> is only ever to be used as the child of <Routes> element, never rendered directl
- 2.3 构建C语言入职教程
- linux proftpd 用户,linux之proftpd搭建(随时盖楼)
- 网络管理——直接网络管理规范
- apache 开启php fpm,apache php fpm安装方法详解
热门文章
- 收藏——CodeProject - 使用特性(attributes)和激活机制来实现工厂模式
- [转载]如何发送和接收 Windows Phone 的 Toast 通知
- 【iOS Tips】002-实现“简单单例模式”的几种方法?
- Mysql组复制故障恢复测试
- [转]数据结构:图的存储结构之邻接多重表
- css基础 设置链接颜色
- ERP_Oracle Fusion Application新一代ERP介绍
- 灵活管理Hadoop各发行版的运维利器 - vSphere Big Data Extensions
- 关于excel导入到封装成工具类jar包和web版门店收银网络无法无法连接上的解决方法...
- android 虚拟机快捷键中英列表