LDA基本介绍以及LDA源码分析(BLEI)
基本介绍:
doc-topic分布服从多项分布,狄利克雷分布是其共轭先验。这样参数的个数就变成K+N*K, N为词个数,K为topic个数,与文档个数无关。如果我想知道一个文档的topic分布怎么办?下面介绍下train以及predic的方法。作者采用了varitional inference进行推导,过程就免了,列出来几个重要的公式:
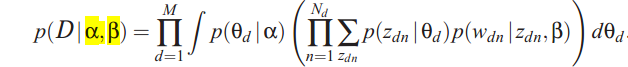
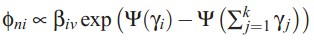
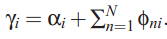
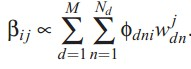
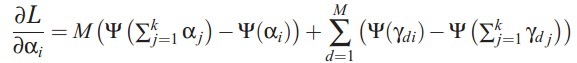

变分后,计算出来的似然函数,其似然值用户判断迭代的收敛程度:
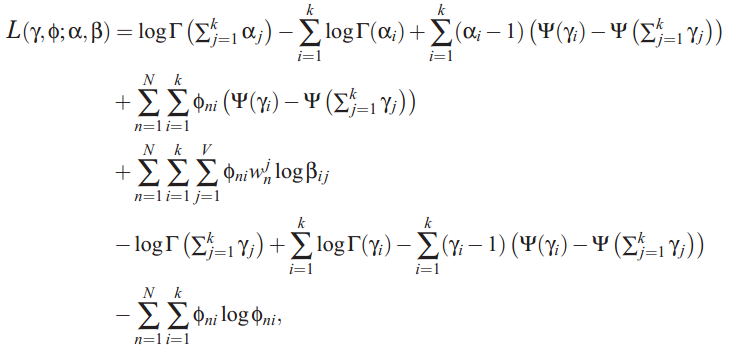
|
for (k = 0; k < num_topics; k++) { for (i = 0; i < NUM_INIT; i++) { d = floor(myrand() * c->num_docs); printf("initialized with document %d\n", d); doc = &(c->docs[d]); for (n = 0; n < doc->length; n++) { ss->class_word[k][doc->words[n]] += doc->counts[n]; } } for (n = 0; n < model->num_terms; n++) { ss->class_word[k][n] += 1.0; ss->class_total[k] = ss->class_total[k] + ss->class_word[k][n]; } } |
|
void run_em(char* start, char* directory, corpus* corpus) { int d, n; // allocate variational parameters var_gamma = malloc(sizeof(double*)*(corpus->num_docs)); int max_length = max_corpus_length(corpus); // initialize model char filename[100]; lda_suffstats* ss = NULL; sprintf(filename,"%s/000",directory); // run expectation maximization int i = 0; while (((converged < 0) || (converged > EM_CONVERGED) || (i <= 2)) && (i <= EM_MAX_ITER)) // e-step //这里是核心,针对每篇文档计算相关模型参数 // m-step lda_mle(model, ss, ESTIMATE_ALPHA); // check for convergence converged = (likelihood_old - likelihood) / (likelihood_old); |
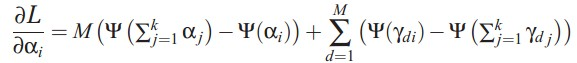
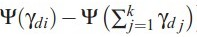 ,但是实际α只有一个,所以作者通过在所有topic上的分布计算出α。
,但是实际α只有一个,所以作者通过在所有topic上的分布计算出α。
|
double doc_e_step(document* doc, double* gamma, double** phi, lda_model* model, lda_suffstats* ss) { double likelihood; int n, k; // posterior inference likelihood = lda_inference(doc, model, gamma, phi); // update sufficient statistics double gamma_sum = 0; for (n = 0; n < doc->length; n++) ss->num_docs = ss->num_docs + 1; return(likelihood); |
|
double lda_inference(document* doc, lda_model* model, double* var_gamma, double** phi) { double converged = 1; double phisum = 0, likelihood = 0; double likelihood_old = 0, oldphi[model->num_topics]; int k, n, var_iter; double digamma_gam[model->num_topics]; // compute posterior dirichlet while ((converged > VAR_CONVERGED) && //update γ,这里面没有用到α,原始公式不同 // printf("[LDA INF] %8.5f %1.3e\n", likelihood, converged); |
|
double compute_likelihood(document* doc, lda_model* model, double** phi, double* var_gamma) { double likelihood = 0, digsum = 0, var_gamma_sum = 0, dig[model->num_topics]; int k, n; for (k = 0; k < model->num_topics; k++) lgamma(α*k) - k*lgamma(alpha) for (k = 0; k < model->num_topics; k++) for (n = 0; n < doc->length; n++) |
|
void lda_mle(lda_model* model, lda_suffstats* ss, int estimate_alpha) { int k; int w; for (k = 0; k < model->num_topics; k++) printf("new alpha = %5.5f\n", model->alpha); |
转自:http://blog.csdn.net/hxxiaopei/article/details/8034308
LDA基本介绍以及LDA源码分析(BLEI)相关推荐
- BFD库的使用介绍 nm工具源码分析
bfd介绍 想深入了解elf等可执行文件的原理(包括结构.运行等细节),用bfd库作切入点是比较好的选择. BFD是Binary format descriptor的缩写, 即二进制文件格式描述,是很 ...
- Django----FBV 与 CBV 介绍、CBV源码分析
文章目录 一.CBV和FBV 二.CBV 源码分析 一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应. 响应可以是一张网页的HTML内容,一个重定 ...
- 《恋上数据结构第1季》哈希表介绍以及从源码分析哈希值计算
哈希表(Hash Table) 引出哈希表 哈希表(Hash Table) 哈希冲突(Hash Collision) JDK1.8的哈希冲突解决方案 哈希函数 如何生成 key 的哈希值 Intege ...
- tapable源码分析
webpack 事件处理机制Tapable webpack 的诸多核心模块都是tapable的子类, tapable提供了一套完整事件订阅和发布的机制,让webpack的执行的流程交给了订阅的插件去处 ...
- Spring IOC 容器源码分析 - 循环依赖的解决办法
1. 简介 本文,我们来看一下 Spring 是如何解决循环依赖问题的.在本篇文章中,我会首先向大家介绍一下什么是循环依赖.然后,进入源码分析阶段.为了更好的说明 Spring 解决循环依赖的办法,我 ...
- spark读取文件源码分析-1
文章目录 1. 问题背景 2. 测试代码 3. 生成的DAG图 1. job0 2. job1 4. job0 产生的时机源码分析 1. 调用DataFrameReader.load,DataFram ...
- libevent c++高并发网络编程_【多线程高并发编程】Callable源码分析
程序猿学社的GitHub,欢迎Starhttps://github.com/ITfqyd/cxyxs 本文已记录到github,形成对应专题. 前言 通过上一章实现多线程有几种方式,我们已经了解多线程 ...
- 从源码分析Android的Glide库的图片加载流程及特点
转载:http://m.aspku.com/view-141093.html 这篇文章主要介绍了从源码分析Android的Glide库的图片加载流程及特点,Glide库是Android下一款人气很高的 ...
- CyclicBarrier---JDK1.8源码分析
CyclicBarrier源码分析 一. CyclicBarrier介绍 二. CyclicBarrier源码分析 ①. CyclicBarrier的内部类---Generation类 ②. Cycl ...
最新文章
- 公益合种油松专车3天领证
- Mac卸载mysql并安装mysql升级到8.0.13版本
- Laravel插件推荐
- 十行代码实现网页标题滚动效果!
- 看动画学算法系列之:后缀数组suffix array
- 【C++ primer】第七章 函数-C++的编程模块
- candence pcb走线等长_Allegro的通用等长规则设置方法
- Byobu(tmux)的使用与定制
- CTRL+ALT快捷键汇总
- Diamond types are not supported at language level ‘5‘ 解决方法
- 社交网络分析中重要指标说明
- 手机连接Fiddler后无法上网问题解决
- 0ops CTF/0CTF writeup
- 下厨房内部孵化项目——懒饭产品体验分析报告
- 《前端框架Vue.js》
- 计量经济学笔记5-Eviews操作-异方差的检验与消除(White检验与加权最小二乘)
- [简单逆向]某直播APP 收费直播链接获取-AES解密
- 一分钟带你了解新版系统集成资质——信息系统建设和服务能力评估(CS)
- 家庭生活指南杂志家庭生活指南杂志社家庭生活指南编辑部2022年第6期目录
- 复辟变后寄友人——李大钊