基于双向LSTM和迁移学习的seq2seq核心实体识别
http://spaces.ac.cn/archives/3942/
暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
于是要找到句子的核心词,我只需要给每个句子计算一个输出向量,然后比较它与句子中每个词的向量的cos值,降序排列就行了。这个方法的明显优势是运行速度很快。最终,我用这个模型在公开评测集上做到了0.35的准确率,后来感觉难以提升,就放弃了这个思路。
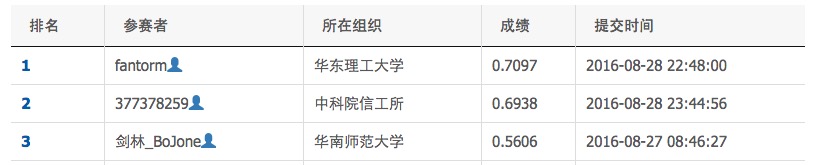
为什么放弃?事实上,这个思路在“核心识别”这部分做得很好,但它的致命缺陷就是:它依赖于分词效果。分词系统往往会把一些长词构成的核心实体切开,比如“朱家花园”切分为“朱家/花园”,切分后要进行整合就难得多了。于是,我参照《【中文分词系列】 4. 基于双向LSTM的seq2seq字标注》一文,用词标注的思路来做,因为这个思路不明显依赖于分词效果。最终我用这个思路做到了0.56的准确率。
大概步骤是:
1、将句子分词,然后用Word2Vec训练词向量;
2、将输出转化为5tag标注问题:b(核心实体首词)、m(核心实体中)、e(核心实体末词)、s(单词成核心实体)、x(非核心实体部分);
3、用双层双向LSTM进行预测,用viterbi算法进行标注。
最后,需要一提的是,根据这种思路,甚至可以不分词就来做核心实体识别,但总的来说,还是分了词的效果会好一些,并且分词有利于降低句子长度(100字的句子分词后变成50词的句子),这有利于减少模型的参数个数。这里我们只需要一个简单的分词系统即可,并且不需要它们内置的新词发现功能。
迁移学习
但是,用这个思路之前我是很不确定它最终的效果的。主要原因是:百度给出了1.2万的训练样本,但却有20万的测试样本。比例如此悬殊,效果似乎很难好起来。此外,有5个tag,其中相比x这个tag,其他四个tag的数量是很少的,只有1.2万的训练样本,似乎存在数据不充分的问题。
当然,实践是检验真理的唯一标准。这个思路的首次测试就达到了0.42的准确率,远高于我前面精心调节了大半个月的CNN思路,于是我就往这个思路继续做下去。在继续做下去之前,我分析了这种思路效果不错的原因。我觉得,主要原因有两个:一个是“迁移学习”,另外一个就是LSTM强大的捕捉语义的能力。
传统数据挖掘的训练模型,是纯粹在训练集上做的。但是我们很难保证,训练集跟测试集是一致的,准确来说,就是很难假设训练集和测试集的分布是一样的。于是乎,即使模型训练效果非常好,测试效果也可能一塌糊涂,这不是过拟合所致,这是训练集和测试集不一致所造成的。
解决(缓解)这个问题的一个思路就是“迁移学习”。迁移学习现在已经是比较综合的建模策略了,在此不详述。一般来说,它有两套方案:
1、在建模前迁移学习,即可以把训练集和测试集放在一起,来学习建模用到的特征,这样得来的特征已经包含了测试集的信息;
2、在建模后迁移学习,即如果测试集的测试效果还不错,比如0.5的准确率,想要提高准确率,可以把测试集连同它的预测结果一起,当做训练样本,跟原来的训练样本一起重新训练模型。
大家可能对第2点比较困惑,测试集的预测结果不是有错的吗?输入错误的结果还能提高准确率?托尔斯泰说过“幸福的家庭都是相似的,不幸的家庭各有各的不幸”,放到这里,我想说的是“正确的答案都是相同的,错误的答案各有各的不同”。也就是说,如果进行第2点训练,测试集中给出的正确答案,效果会累积,因为它们都是正确的(相同的)模式的出来的结果,但是错误的答案各有不同的错误模式,如果模型参数有限,不至于过拟合,那么模型就会抹平这些错误模式,从而倾向于正确的答案。当然,这个理解是否准确,请读者点评。另外,如果得到了新的预测结果,那么可以只取两次相同的预测结果作为训练样本,这样的正确答案的比例就更高了。
在这个比赛中,迁移学习体现在:
1、用训练语料和测试语料一起训练Word2Vec,使得词向量本捕捉了测试语料的语义;
2、用训练语料训练模型;
3、得到模型后,对测试语料预测,把预测结果跟训练语料一起训练新的模型;
4、用新的模型预测,模型效果会有一定提升;
5、对比两次预测结果,如果两次预测结果都一样,那说明这个预测结果很有可能是对的,用这部分“很有可能是对的”的测试结果来训练模型;
6、用更新的模型预测;
7、如果你愿意,可以继续重复第4、5、6步。
双向LSTM
主要的模型结构:
'''
用最新版本的Keras训练模型,使用GPU加速(我的是GTX 960)
其中Bidirectional函数目前要在github版本才有
'''
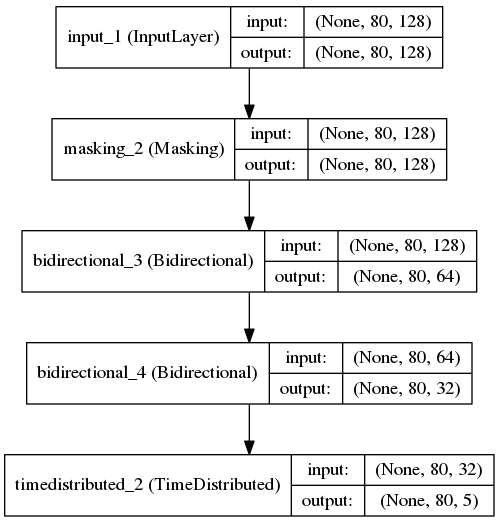
from keras.layers import Dense, LSTM, Lambda, TimeDistributed, Input, Masking, Bidirectional from keras.models import Model from keras.utils import np_utils from keras.regularizers import activity_l1 #通过L1正则项,使得输出更加稀疏 sequence = Input(shape=(maxlen, word_size)) mask = Masking(mask_value=0.)(sequence) blstm = Bidirectional(LSTM(64, return_sequences=True), merge_mode='sum')(mask) blstm = Bidirectional(LSTM(32, return_sequences=True), merge_mode='sum')(blstm) output = TimeDistributed(Dense(5, activation='softmax', activity_regularizer=activity_l1(0.01)))(blstm) model = Model(input=sequence, output=output) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 就是用了双层的双向LSTM(单层我也试过,多加一层效果好一些),保留LSTM每次的输出,然后对每个输出都做一下softmax,整个过程基本就是分词系统一样了。
当然,这个模型的好坏,很大程度上还取决于词向量的质量。经过多次调试,我发现如下的词向量参数基本是最优的:
word2vec = gensim.models.Word2Vec(dd['words'].append(d['words']), min_count=1, size=word_size, workers=20, iter=20, window=8, negative=8, sg=1) 也就是说,skip-gram的效果要比cbow要好,负样本采样的模式要比层次softmax要好,负样本的数目要适中,窗口大小也要适中。当然,这个所谓的“最优”,是多次人工调试后,我自己“直观感觉”的,欢迎大家做更多的测试。
关于比赛
百度跟西安交大这个比赛其实去年我也留意到了,但是我去年还是菜鸟水平,没法做那么艰难的任务。今年尝试做了一下,感觉收获颇丰的。
首先,比赛是百度举行的,单凭这点已经很有吸引力了,因为通常感觉如果能得到百度的肯定,那是一件了不起的事情,所以挺期待这类比赛的(希望有时间参加吧),也希望百度的比赛越办越好哈(套话了~)。其次,在这个过程中,我对语言模型的例子、深度网络的搭建与使用等,都有了更加深入的认识了,比如CNN怎么用于语言任务、可以用于哪些语言任务,还有seq2seq的初步使用等。
很碰巧的是,这次是一个自然语言处理任务,上次泰迪杯是一个图像任务,两次加起来,我把自然语言处理和图像的基本任务都做了一遍,心里对这些任务的处理都比较有底了,感觉挺踏实的。
完整代码
说明文件
基于迁移学习和双向LSTM的核心实体识别
==============================================================
总的步骤(在train_and_predict.py中一一对应)
==============================================================1、训练语料和测试语料都分词,目前用的是结巴分词;
2、转化为5tag标注问题,构建训练标签;
3、训练语料和测试语料一起训练Word2Vec模型;
4、用双层双向LSTM训练标注模型,基于seq2seq的思想;
5、用模型进行预测,预测准确率大约会在0.46~0.52波动;
6、将预测结果当作标签数据,与训练数据一起,重新训练模型;
7、用新模型预测,预测准确率会在0.5~0.55波动;
8、比较两次预测结果,取交集当做标签数据,与训练数据一起,重新训练模型;
9、用新模型预测,预测准确率基本保持在0.53~0.56。==============================================================
编译环境:
==============================================================硬件环境:
1、96G内存(事实上用到10G左右)
2、GTX960显卡(GPU加速训练)软件环境:
1、CentOS 7
2、Python 2.7(以下均为Python第三方库)
3、结巴分词
4、Numpy
5、SciPy
6、Pandas
7、Keras(官方GitHub版本)
8、Gensim
9、H5PY
10、tqdm==============================================================
文件使用说明:
==============================================================train_and_predict.py
包含了从训练到预测的整个过程,只要“未开放的验证数据”格式跟“开放的测试数据”opendata_20w格式一样,那么就可以
与train_and_predict.py放在同一目录,然后运行
python train_and_predict.py
就可以完成整个过程,并且会生成一系列文件:--------------------------------------------------------------
word2vec_words_final.model,word2vec模型words_seq2seq_final_1.model,首次得到的双层双向LSTM模型
--- result1.txt,首次预测结果文件
--- result1.zip,首次预测结果文件压缩包words_seq2seq_final_2.model,通过第一次迁移学习后得到的模型
--- result2.txt,再次预测结果文件
--- result2.zip,再次预测结果文件压缩包words_seq2seq_final_3.model,通过第二次迁移学习后得到的模型
--- result3.txt,再次预测结果文件
--- result3.zip,再次预测结果文件压缩包words_seq2seq_final_4.model,通过第三次迁移学习后得到的模型
--- result4.txt,再次预测结果文件
--- result4.zip,再次预测结果文件压缩包words_seq2seq_final_5.model,通过第四次迁移学习后得到的模型
--- result5.txt,再次预测结果文件
--- result5.zip,再次预测结果文件压缩包
---------------------------------------------------------------==============================================================
思路说明:
==============================================================迁移学习体现在:
1、用训练语料和测试语料一起训练Word2Vec,使得词向量本捕捉了测试语料的语义;
2、用训练语料训练模型;
3、得到模型后,对测试语料预测,把预测结果跟训练语料一起训练新的模型;
4、用新的模型预测,模型效果会有一定提升;
5、对比两次预测结果,如果两次预测结果都一样,那说明这个预测结果很有可能是对的,用这部分“很有可能是对的”的测试结果来训练模型;
6、用更新的模型预测;
7、如果你愿意,可以继续重复第4、5、6步。双向LSTM的思路:
1、分词;
2、转换为5tag标注问题(0:非核心实体,1:单词的核心实体,2:多词核心实体的首词,3:多词核心实体的中间部分,4:多词核心实体的末词);
3、通过双向LSTM,直接对输入句子输出预测标注序列;
4、通过viterbi算法来获得标注结果;
5、因为常规的LSTM存在后面的词比前面的词更重要的弊端,因此用双向LSTM。
train_and_predict.py(代码并没整理,仅供测试参考)
#! -*- coding:utf-8 -*-'''
基于迁移学习和双向LSTM的核心实体识别迁移学习体现在:
1、用训练语料和测试语料一起训练Word2Vec,使得词向量本捕捉了测试语料的语义;
2、用训练语料训练模型;
3、得到模型后,对测试语料预测,把预测结果跟训练语料一起训练新的模型;
4、用新的模型预测,模型效果会有一定提升;
5、对比两次预测结果,如果两次预测结果都一样,那说明这个预测结果很有可能是对的,用这部分“很有可能是对的”的测试结果来训练模型;
6、用更新的模型预测;
7、如果你愿意,可以继续重复第4、5、6步。双向LSTM的思路:
1、分词;
2、转换为5tag标注问题(0:非核心实体,1:单词的核心实体,2:多词核心实体的首词,3:多词核心实体的中间部分,4:多词核心实体的末词);
3、通过双向LSTM,直接对输入句子输出预测标注序列;
4、通过viterbi算法来获得标注结果;
5、因为常规的LSTM存在后面的词比前面的词更重要的弊端,因此用双向LSTM。
'''import numpy as np import pandas as pd import jieba from tqdm import tqdm import re d = pd.read_json('data.json') #训练数据已经被预处理成为标准json格式 d.index = range(len(d)) #重新定义一下索引,当然这只是优化显示效果 word_size = 128 #词向量维度 maxlen = 80 #句子截断长度 ''' 修改分词函数,主要是: 1、英文和数字部分不分词,直接返回; 2、双书名号里边的内容不分词; 3、双引号里边如果是十字以内的内容不分词; 4、超出范围内的字符全部替换为空格; 5、分词使用结巴分词,并关闭新词发现功能。 ''' not_cuts = re.compile(u'([\da-zA-Z \.]+)|《(.*?)》|“(.{1,10})”') re_replace = re.compile(u'[^\u4e00-\u9fa50-9a-zA-Z《》\(\)()“”·\.]') def mycut(s): result = [] j = 0 s = re_replace.sub(' ', s) for i in not_cuts.finditer(s): result.extend(jieba.lcut(s[j:i.start()], HMM=False)) if s[i.start()] in [u'《', u'“']: result.extend([s[i.start()], s[i.start()+1:i.end()-1], s[i.end()-1]]) else: result.append(s[i.start():i.end()]) j = i.end() result.extend(jieba.lcut(s[j:], HMM=False)) return result d['words'] = d['content'].apply(mycut) #分词 def label(k): #将输出结果转换为标签序列 s = d['words'][k] r = ['0']*len(s) for i in range(len(s)): for j in d['core_entity'][k]: if s[i] in j: r[i] = '1' break s = ''.join(r) r = [0]*len(s) for i in re.finditer('1+', s): if i.end() - i.start() > 1: r[i.start()] 基于双向LSTM和迁移学习的seq2seq核心实体识别相关推荐
- NAACL| 基于标签感知的双迁移学习在医学命名实体识别中的应用
本期给大家介绍上海交通大学APEX数据和知识管理实验室俞勇教授课题组发表在NAACL的文章"Label-aware Double Transfer Learning for Cross-Sp ...
- 猿创征文丨深度学习基于双向LSTM模型完成文本分类任务
大家好,我是猿童学,本期猿创征文的第三期,也是最后一期,给大家带来神经网络中的循环神经网络案例,基于双向LSTM模型完成文本分类任务,数据集来自kaggle,对电影评论进行文本分类. 电影评论可以蕴含 ...
- 深度学习基于双向 LSTM 模型完成文本分类任务
大家好,本期给大家带来神经网络中的循环神经网络案例,基于双向LSTM模型完成文本分类任务,数据集来自kaggle,对电影评论进行文本分类. 电影评论可以蕴含丰富的情感:比如喜欢.讨厌.等等.情感分析( ...
- 基于双向 lstm 和残差神经网络的 rna 二级结构预测方法
目录 结果 结论 背景 结果 学习结果和演示 预测结果和比较 讨论 结论 材料和方法 数据收集和处理 摘要 背景: 研究表明,rna 二级结构是由配对碱基构成的平面结构,在基本生命活动和复杂疾病中发挥 ...
- 基于特征的对抗迁移学习论文_有关迁移学习论文
如果你有好的想法,欢迎讨论! 1 Application of Transfer Learning in Continuous Time Series for Anomaly Detection in ...
- NNDL 实验七 循环神经网络(4)基于双向LSTM的文本分类
6.4 实践:基于双向LSTM模型完成文本分类任务 电影评论可以蕴含丰富的情感:比如喜欢.讨厌.等等. 情感分析(Sentiment Analysis)是为一个文本分类问题,即使用判定给定的一段文本信 ...
- 基于卷积神经网络与迁移学习的油茶病害图像识别
基于卷积神经网络与迁移学习的油茶病害图像识别 1.研究思路 利用深度卷积神经网络强大的特征学习和特征表达能力来自动学习油茶病害特征,并借助迁移学习方法将AlexNet模型在ImageNet图像数据集上 ...
- 基于联合分布适配的迁移学习(论文翻译)
基于联合分布适配的迁移学习 Abstract 迁移学习应用在计算机视觉是一种有效的技术,可以利用源域中丰富的标记数据为目标域构建准确的分类器.然而,大多数现有方法并没有同时减少域间边缘分布和条件分布的 ...
- 基于特征的对抗迁移学习论文_学界 | 综述论文:四大类深度迁移学习
选自arXiv 作者:Chuanqi Tan.Fuchun Sun.Tao Kong. Wenchang Zhang.Chao Yang.Chunfang Liu 机器之心编译 参与:乾树.刘晓坤 本 ...
最新文章
- MySQL - 索引优化案例实操
- TCP和UDP的优缺点及区别
- GPS NMEA 0183 4.10协议/GPS Linux串口驱动
- discusz 判断当前页是门户还是论坛
- Android 常用 adb 命令总结【转】
- 库,表,记录的相关操作
- 中国幻想向欧美妥协取得5G权益将是一种错误
- 高通qusb bulk驱动_1999元!Redmi新机发布:首发高通全新SoC
- cacheable中的condition和unless
- 隐藏在计算机网卡怎样删除,卸载电脑中隐藏虚拟网卡设备的解决方法
- 揭秘阿里巴巴的客群画像
- 机器学习备忘录 | 二分类模型常用评价指标汇总
- UnityShader语法英文入门
- 使用STM32CubeMX创建USB MSC工程
- 高斯滤波/高斯模糊(Gaussian blur)和高斯噪声(Gaussian noise)
- mbr+ghost装黑苹果OS X 10.13
- 信贷反欺诈风险管理体系|附欺诈策略细则
- 云存储中不可不知的五个安全问题及应对措施
- NSTextField 处于编辑状态时,点击return键 结束编辑,NSButton的return快捷方法不响应
- VFP中使用winsock控件收发二进制数据