阿里云EMR异步构建云HBase二级索引
一、非HA EMR构建二级索引
云HBase借助Phoenix实现二级索引功能,对于Phoenix二级索引的详细介绍可参考https://yq.aliyun.com/articles/536850?spm=a2c4e.11153940.blogrightarea544746.26.673e7308MxY7Lc
当Phoenix表数据量较大时,可以选择异步构建索引方式,利用MR快速同步索引数据,同时降低HBase服务端负载。
由于云HBase没有MR,需要借助外部计算引擎(自建Hadoop集群或者阿里云EMR),详细操作步骤可参考阿里云瑾谦大神的博客:https://yq.aliyun.com/articles/544746?spm=a2c4e.11153940.blogcont574090.11.28895835Lse5dN
这篇文章主要介绍在非HA的EMR环境下执行bulkload向phoenix表中批量入库,构建二级索引稍有不同,但大体上类类似,只不过将bulkload命令替换成二级索引构建命令:
yarn --config ${CONF_DIR} jar ${PHOENIX_HOME}/phoenix-${version}-client.jar org.apache.phoenix.mapreduce.index.IndexTool --data-table "TABLENAME" --index-table "INDEXNAME" --output-path "hdfs://hbase-cluster/path/"${CONF_DIR}是需要创建的用户配置目录,用户需要把配置有云HBase zookeeper信息的hbase-site.xml和云HBase的hdfs-site.xml配置文件放在该目录下。
hbase-site.xml配置:
<configuration><property><name>hbase.zookeeper.quorum</name><value>zk1,zk2,zk3</value></property>
</configuration>
--data-table 是phoenix数据表的表名
--index-table是phoenix中已经创建好的索引表名
--output-path是云HBase集群hdfs的目录,要指定hdfs的nameservice,二级索引的数据本质还是利用BulkLoad生成,HFile文件存放在改目录下,然后再move到索引表中。
二、HA EMR构建二级索引
如果构建二级索引时EMR集群开启了HA,在使用上述步骤过程中,可能会遇到下面的问题:
这个问题原因是由于开启HA的EMR集群HDFS的nameservice名跟云HBase的HDFS的nameservice名相同导致的。
解决这个问题需要联系工作人员把云HBase集群HDFS的nameservice改掉(以hbase-cluster为例),并在EMR集群中把指定hdfs-site.xml配置修改为改动后的云HBase的nameservice名。
云HBase集群HDFS的nameservice修改完成后,可以按照以下步骤操作:
- 在EMR的客户机上新建配置目录,并将EMR集群的core-site.xml、hdfs-site.xml以及yarn-site.xml、mapred-site.xml拷贝到新建的配置目录。
- 修改hdfs-site.xml将EMR集群和云HBase集群的hdfs配置合并。
原hdfs-site.xml已经有dfs.nameservices配置项,需要将云HBase的namesercie也添加到该配置,实例如下:
<property><name>dfs.nameservices</name><value>emr-cluster,hbase-cluster</value></property>
// emr-cluster表示EMR集群的nameservice,hbase-cluster表示云HBase的nameservice
然后在hdfs-site.xml配置文件添加如下云HBase的配置:
<property> <name>dfs.client.failover.proxy.provider.hbase-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.hbase-cluster</name> <value>true</value> </property> <property> <name>dfs.ha.namenodes.hbase-cluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hbase-cluster.nn1</name> <value>{emr-header-1-host}:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hbase-cluster.nn2</name> <value>{emr-header-2-host}:8020</value> </property> //{emr-header-1-host}和{emr-header-2-host}为云HBase的主备节点的主机或IP,需联系工作人员获取
3.配置云HBase的zookeeper配置项
在第1步新建的配置目录下,增加hbase-site.xml配置
<configuration><property><name>hbase.zookeeper.quorum</name><value>zk1,zk2,zk3</value></property></configuration>// zk1,zk2,zk3为云HBase的zookeeper配置,可在云HBase管理控制台查看。
4.执行异步构建索引命令实例
yarn --config /etc/ecm/hbase-conf/ jar /opt/alihbase-1.1.4/lib/phoenix-4.11.0-AliHBase-1.1-0.3-client.jar org.apache.phoenix.mapreduce.index.IndexTool --data-table WEB_STAT --index-table WEB_IDX --output-path hdfs://hbase-cluster/tmp/WEB_STAT/1/ /etc/ecm/hbase-conf/为第1步新建配置目录
/opt/alihbase-1.1.4/lib/phoenix-4.11.0-AliHBase-1.1-0.3-client.jar为依赖phoenix client jar包
WEB_STAT为测试原表,WEB_IDX为异步索引表
常见问题:
- 如果运行bulkload或二级索引的mapreduce程序一直处于卡住状态,即map一直0%,最终失败。异常信息如下:

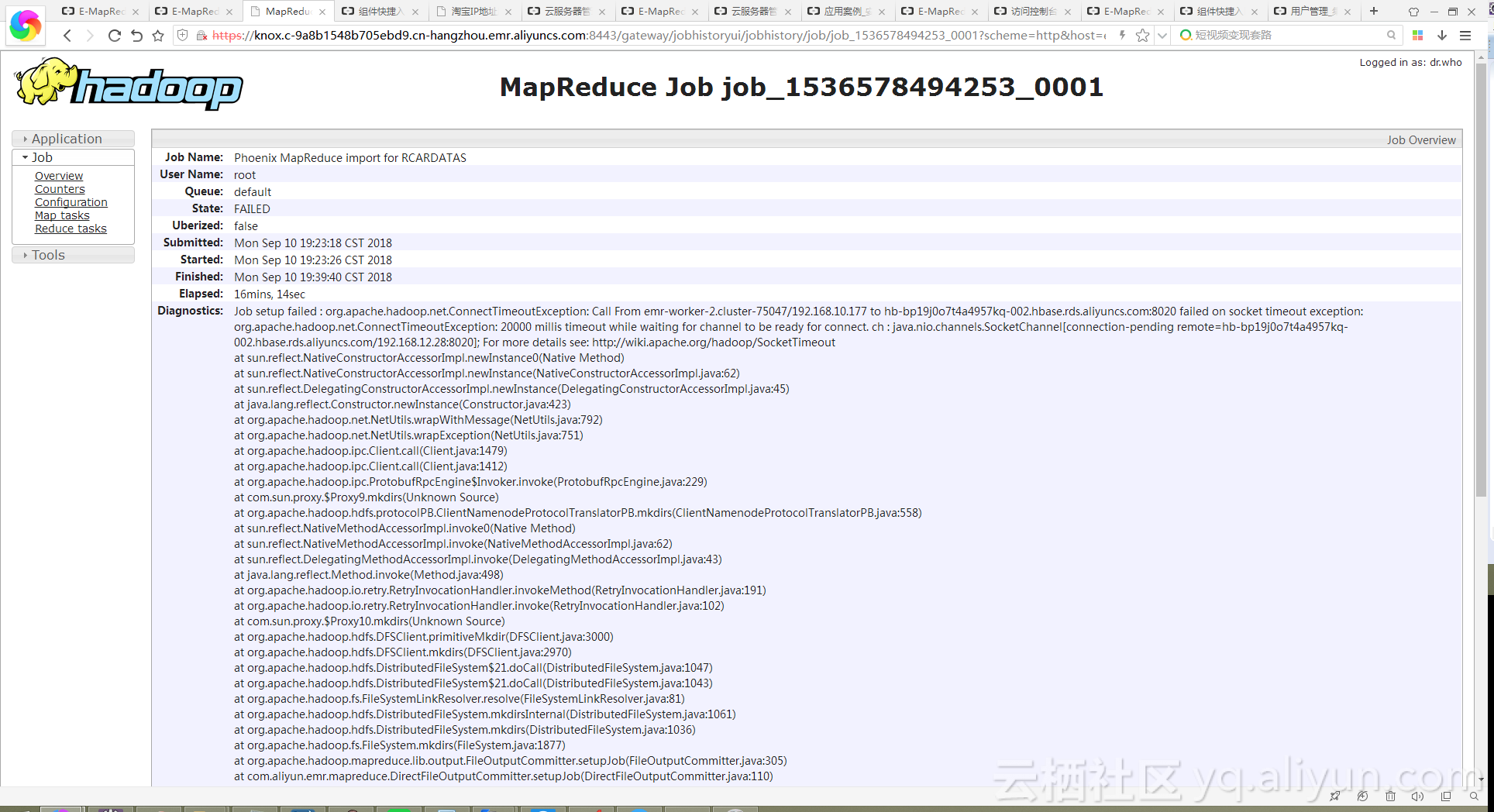
解决办法:检查EMR集群的子节点是否加入到云HBase的白名单中。
2.如果EMR运行MR任务时Reduce运行过程中备Killed,日志信息出现“container killed on request.Exit code is 143"信息,如下图:
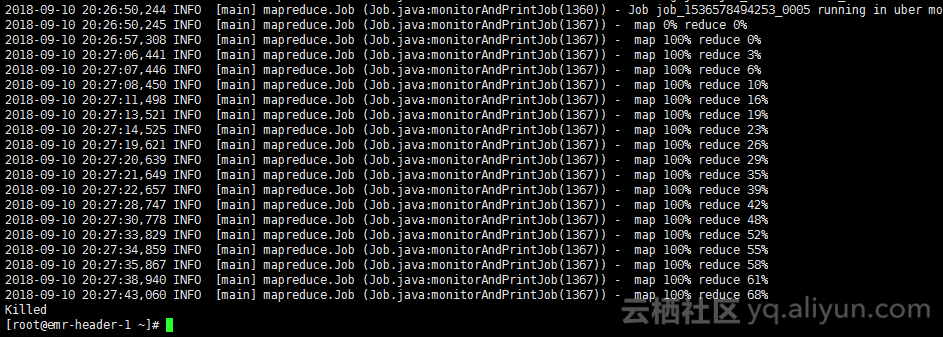
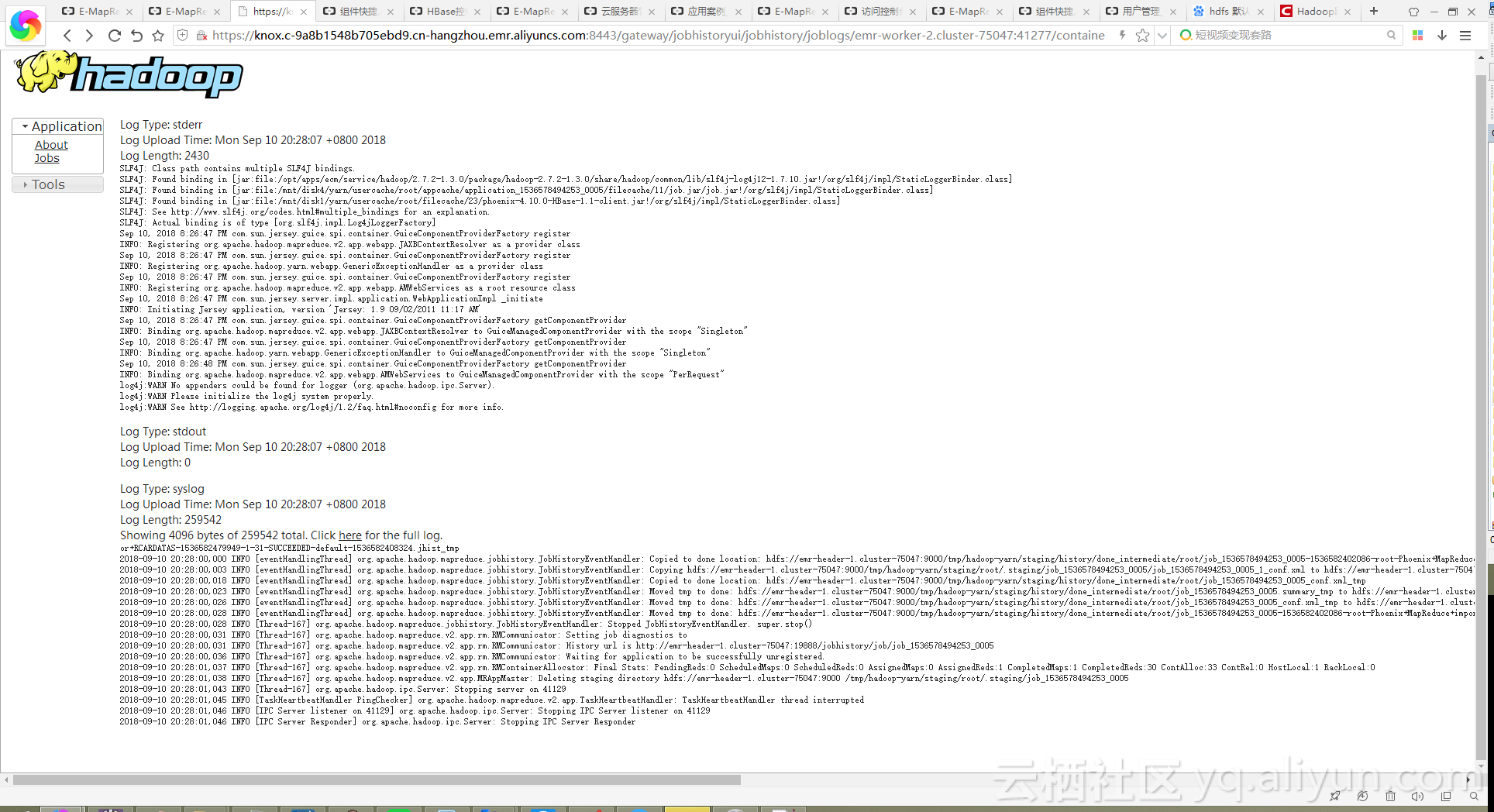
解决办法:原因是HBase表分区过多,EMR集群在配置较低情况下配置不太合理。修改下Yarn配置:
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers</description></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value><description>Ratio between virtual memory to physical memory when setting memory limits for containers</description></property>
阿里云EMR异步构建云HBase二级索引相关推荐
- 使用solr构建hbase二级索引
使用solr构建hbase二级索引 @(HBASE)[hbase, solr] 使用solr构建hbase二级索引 一概述 一业务场景描述 二技术方案 1技术方案一 2技术方案二 3关于索引的建议 二 ...
- 云上的云:AVOS Cloud在云平台上构建云服务的经验分享
2019独角兽企业重金招聘Python工程师标准>>> 云上的云:AVOS Cloud在云平台上构建云服务的经验分享 AVOS Cloud作为国内领先的云后端服务提供商,为移动应用开 ...
- hbase组合rowkey_「从零单排HBase 11」HBase二级索引解决方案
HBase一个令人惋惜的地方,就是不支持二级索引.因此,社区有了很多补充方案来填补HBase的二级索引能力的缺陷. 今天,我们就来看看有哪些二级索引方案,通过对比各个方案的优缺点,并结合我们的具体场景 ...
- 基于Solr的Hbase二级索引
关于Hbase二级索引 HBase 是一个列存数据库,每行数据只有一个主键RowKey,无法依据指定列的数据进行检索.查询时需要通过RowKey进行检索,然后查看指定列的数据是什么,效率低下.在实际应 ...
- 基于ES的HBase二级索引方案
HBase不支持多条件查询,不提供二级索引,难以满足用户对检索功能多样性和高效率两方面的需求.由索引模块的需求分析可知,本文解决通过,提出数据与索引的分离,利用HBase数据库的存储模式灵活多变,容纳 ...
- CDH 6 安装 Hbase 二级索引 Solr + Key-Value Store Indexer
目录 一.集群安装Solr + Key-Value Store Indexer 二.创建Hbase二级索引 1.更改表结构,允许复制 2.创建相应的SolrCloud集合 3.创建 collecti ...
- 华为HBase 二级索引调研
1.Overall Solution 解决思想: 一个user table对应一个index table index的创建与更新全部在RS端的cp-processor里实现 核心思想:一个actual ...
- 【金猿产品展】拍乐云——新一代实时音视频云服务,构建云上的每一次美好互动...
拍乐云产品 本项目由拍乐云投递并参与"数据猿年度金猿策划活动--2021大数据产业创新服务产品榜单及奖项"评选. 数据智能产业创新服务媒体 --聚焦数智 · 改变商业 拍乐云提供的 ...
- 用友谢志华:汇集企业云服务,构建云生态
不久前,在主题为"赢在企业互联网"的2017用友伙伴大会上,用友网络执行副总裁兼用友云事业群总裁谢志华阐述了面向社会化商业应用的用友云服务,并介绍了用友云的整体架构. 一站式云服务 ...
最新文章
- 2022-2028年中国儿童医疗行业深度调研及投资前景预测报告
- C# IL DASM 使用
- oracle创建表空间及用户,Oracle创建表空间和用户
- 统计学习方法六:支持向量机三(支持向量定量理解和算法总结)
- php 解析数组,如何用PHP解析array数组
- 什么是冬至?冬至的由来?
- RHELServer6.2下编译GDAL和mysql和proj4支持
- 软工实践第一次作业-自我审视和规划
- 小程序页面之间的跳转方法
- .NET 指南:属性与方法之间的选择
- 优点 spark_分布式计算引擎之星——Spark
- 使用nrm管理npm源的切换
- Spy++ —— 窗口、消息查看分析利器
- 【微信小程序】页面导航
- linux基本功之df命令实战
- 74LS273 八D型触发器 功能介绍
- 学习记录:VB.NET.操作ACCESS数据库
- 计算出某年某月某日是星期几
- R语言ggplot2可视化:使用geom_rect函数在指定的位置添加自定义颜色的方框突出(hightlight)特定区域内的数据内容(transparent window/keyhole)
- mysql 密码修改