Java开发面试问题,Jsoup解析html
System.out.println("\n");}Elements widthElements = doc.getElementsByAttribute("width"); // 根据属性名称来查询DOM(id class type 等),用的少一般很难找用这种方法System.out.println("=======输出with的DOM==============");for (Element e : widthElements) {System.out.println(e.toString());//不能用 e.html() 这里需要输出 DOM}//<a href="https://www.cnblogs.com/rope/" target="_blank"><img width="48" height="48" class="pfs" src="//pic.cnblogs.com/face/1491596/20180916131220.png" alt=""/></a>Elements targetElements = doc.getElementsByAttributeValue("target", "_blank");System.out.println("=======输出target-_blank的DOM==============");for (Element e : targetElements) {System.out.println(e.toString());}
}
四、Jsoup使用选择器语法查找DOM元素---------------------我们前面通过标签名,Id,Class样式等来搜索DOM,这些是不能满足实际开发需求的,很多时候我们需要寻找有规律的DOM集合,很多个有规律的标签层次,这时候,选择器就用上了。css jquery 都有,Jsoup支持css,jquery类似的选择器语法。/**
- 有层级关系
*/
@Test
public void test3() throws IOException {
Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements linkElements = doc.select("#post_list .post_item .post_item_body h3 a"); //通过选择器查找所有博客链接DOM(范围重小到大)for (Element e : linkElements) {System.out.println("博客标题:" + e.text());//超链接的内容}System.out.println("--------------------带有href属性的a元素--------------------------------");Elements hrefElements = doc.select("a[href]"); // 带有href属性的a元素for (Element e : hrefElements) {System.out.println(e.toString());}System.out.println("------------------------查找扩展名为.png的图片----------------------------");Elements imgElements = doc.select("img[src$=.png]"); // 查找扩展名为.png的图片DOM节点for (Element e : imgElements) {System.out.println(e.toString());}System.out.println("------------------------获取第一个元素----------------------------");Element element = doc.getElementsByTag("title").first(); // 获取tag是title的所有DOM元素String title = element.text(); // 返回元素的文本System.out.println("网页标题是:" + title);
}
五、Jsoup获取DOM元素属性值-----------------/**
- 获取 DOM 元素属性值
*/
@Test
public void test4() throws IOException {
Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements linkElements = doc.select("#post_list .post_item .post_item_body h3 a"); //通过选择器查找所有博客链接DOMfor (Element e : linkElements) {System.out.println("博客标题:" + e.text());//获取里面所有的文本System.out.println("博客地址:" + e.attr("href"));System.out.println("target:" + e.attr("target"));}System.out.println("------------------------友情链接----------------------------");Element linkElement = doc.select("#friend_link").first();System.out.println("纯文本:" + linkElement.text());//去掉 htmlSystem.out.println("------------------------Html----------------------------");System.out.println("Html:" + linkElement.html());
}
/*** 获取文章的 url*/@Testpublic void test5() throws IOException {Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements linkElements = doc.select("#post_list .post_item .post_item_body h3 a"); //通过选择器查找所有博客链接DOMfor (Element e : linkElements) {System.out.println(e.attr("href"));}}```注意:Element 的几个获取内容的方法区别1. text() 获取的是去掉了 html 元素,也就是只用元素内容2. toString() DOM3. html() 获取里面所有的 html 包括文本```import org.apache.http.HttpEntity;import org.apache.http.client.methods.CloseableHttpResponse;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.CloseableHttpClient;import org.apache.http.impl.client.HttpClients;import org.apache.http.util.EntityUtils;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.junit.Test;import java.io.IOException;public class Main {/*** 输入一个网址返回这个网址的字符串*/public String getHtml(String str) throws IOException {CloseableHttpClient httpclient = HttpClients.createDefault(); // 创建httpclient实例HttpGet httpget = new HttpGet(str); // 创建httpget实例CloseableHttpResponse response = httpclient.execute(httpget); // 执行get请求HttpEntity entity = response.getEntity(); // 获取返回实体String content = EntityUtils.toString(entity, "utf-8");response.close(); // 关闭流和释放系统资源return content;}/*** 爬取 博客园* 1、网页标题* 2、口号*/@Testpublic void test() throws IOException {Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements elements = doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素Element element = elements.get(0); // 获取第1个元素String title = element.text(); // 返回元素的文本System.out.println("网页标题:" + title);Element element2 = doc.getElementById("site_nav_top"); // 获取id=site_nav_top的DOM元素String navTop = element2.text(); // 返回元素的文本System.out.println("口号:" + navTop);}/*** Jsoup 查找 DOM 元素*/@Testpublic void test2() throws IOException {Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements itemElements = doc.getElementsByClass("post_item"); // 根据样式名称来查询DOMSystem.out.println("=======输出post_item==============");for (Element e : itemElements) {System.out.println(e.html());//获取里面所有的 html 包括文本System.out.println("\n");}Elements widthElements = doc.getElementsByAttribute("width"); // 根据属性名称来查询DOM(id class type 等),用的少一般很难找用这种方法System.out.println("=======输出with的DOM==============");for (Element e : widthElements) {System.out.println(e.toString());//不能用 e.html() 这里需要输出 DOM}//<a href="https://www.cnblogs.com/rope/" target="_blank"><img width="48" height="48" class="pfs" src="//pic.cnblogs.com/face/1491596/20180916131220.png" alt=""/></a>Elements targetElements = doc.getElementsByAttributeValue("target", "_blank");System.out.println("=======输出target-_blank的DOM==============");for (Element e : targetElements) {System.out.println(e.toString());}}/*** 有层级关系*/@Testpublic void test3() throws IOException {Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements linkElements = doc.select("#post_list .post_item .post_item_body h3 a"); //通过选择器查找所有博客链接DOM(范围重小到大)for (Element e : linkElements) {System.out.println("博客标题:" + e.text());//超链接的内容}System.out.println("--------------------带有href属性的a元素--------------------------------");Elements hrefElements = doc.select("a[href]"); // 带有href属性的a元素for (Element e : hrefElements) {System.out.println(e.toString());}System.out.println("------------------------查找扩展名为.png的图片----------------------------");Elements imgElements = doc.select("img[src$=.png]"); // 查找扩展名为.png的图片DOM节点for (Element e : imgElements) {System.out.println(e.toString());}System.out.println("------------------------获取第一个元素----------------------------");Element element = doc.getElementsByTag("title").first(); // 获取tag是title的所有DOM元素String title = element.text(); // 返回元素的文本System.out.println("网页标题是:" + title);}/*** 获取 DOM 元素属性值*/@Testpublic void test4() throws IOException {Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements linkElements = doc.select("#post_list .post_item .post_item_body h3 a"); //通过选择器查找所有博客链接DOMfor (Element e : linkElements) {System.out.println("博客标题:" + e.text());//获取里面所有的文本System.out.println("博客地址:" + e.attr("href"));System.out.println("target:" + e.attr("target"));}System.out.println("------------------------友情链接----------------------------");Element linkElement = doc.select("#friend_link").first();System.out.println("纯文本:" + linkElement.text());//去掉 htmlSystem.out.println("------------------------Html----------------------------");System.out.println("Html:" + linkElement.html());}/*** 获取文章的 url*/@Testpublic void test5() throws IOException {Document doc = Jsoup.parse(getHtml("http://www.cnblogs.com/")); // 解析网页 得到文档对象Elements linkElements = doc.select("#post_list .post_item .post_item_body h3 a"); //通过选择器查找所有博客链接DOMfor (Element e : linkElements) {System.out.println(e.attr("href"));}}}```六、Jsoup工具类----------```public class JsoupUtil {/*** 获取value值* * @param e* @return*/public static String getValue(Element e) {return e.attr("value");}/*** 获取* <tr>* 和* </tr>* 之间的文本* * @param e* @return*/public static String getText(Element e) {return e.text();}/*** 识别属性id的标签,一般一个html页面id唯一* * @param body* @param id* @return*/public static Element getID(String body, String id) {Document doc = Jsoup.parse(body);// 所有#id的标签Elements elements = doc.select("#" + id);// 返回第一个return elements.first();}/*** 识别属性class的标签* * @param body* @param class* @return*/public static Elements getClassTag(String body, String classTag) {Document doc = Jsoup.parse(body);// 所有#id的标签return doc.select("." + classTag);# 最后无论是哪家公司,都很重视基础,大厂更加重视技术的深度和广度,面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。针对以上面试技术点,我在这里也做一些资料分享,希望能更好的帮助到大家。**[戳这里免费领取以下资料](https://gitee.com/vip204888/java-p7)**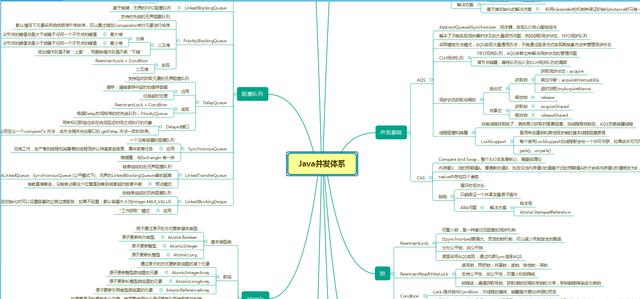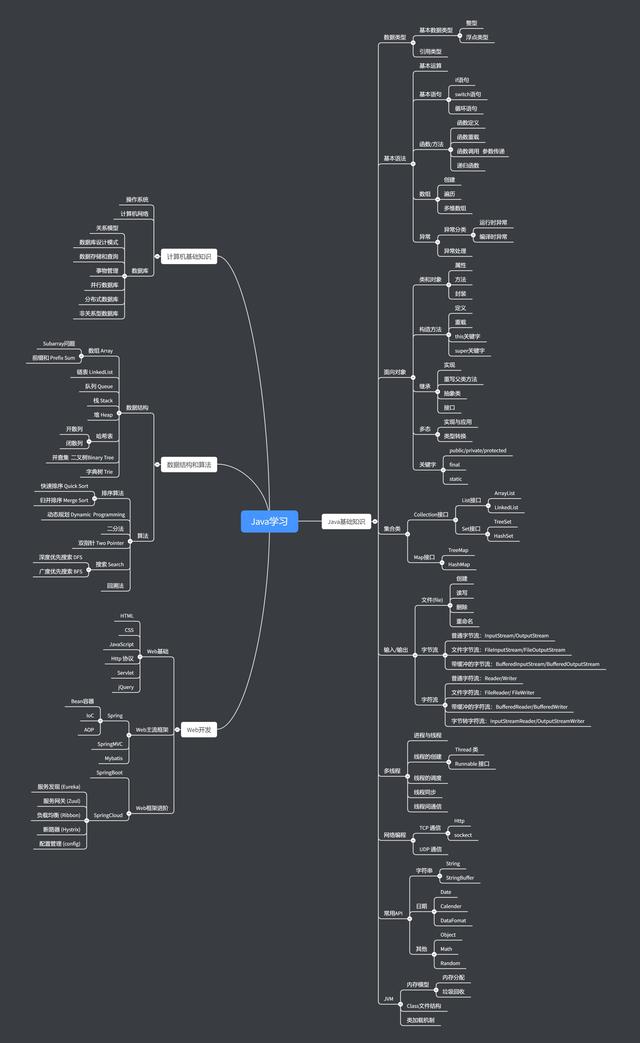);}/*** 识别属性class的标签* * @param body* @param class* @return*/public static Elements getClassTag(String body, String classTag) {Document doc = Jsoup.parse(body);// 所有#id的标签return doc.select("." + classTag);# 最后无论是哪家公司,都很重视基础,大厂更加重视技术的深度和广度,面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。针对以上面试技术点,我在这里也做一些资料分享,希望能更好的帮助到大家。**[戳这里免费领取以下资料](https://gitee.com/vip204888/java-p7)**[外链图片转存中...(img-TY4YFjRn-1628071718536)][外链图片转存中...(img-TS1s3TLk-1628071718539)][外链图片转存中...(img-a1UHOP9p-1628071718540)]Java开发面试问题,Jsoup解析html相关推荐
- Java开发面试高频考点学习笔记(每日更新)
Java开发面试高频考点学习笔记(每日更新) 1.深拷贝和浅拷贝 2.接口和抽象类的区别 3.java的内存是怎么分配的 4.java中的泛型是什么?类型擦除是什么? 5.Java中的反射是什么 6. ...
- Java开发面试常见的技术问题整理
Java开发面试常见的技术问题整理 介绍 对jvm的了解? jvm类加载机制 jvm运行时数据区||Jvm体系结构五大块 jvm自带的加载器 jvm的双亲委派模式 什么是GC jvm的垃圾回收算法 怎 ...
- 初级Java开发面试必问项!!! 标识符、字面值、变量、数据类型,该学学了!
最近事情太多,没太时间写博客.今天抽空再整理整理面试中的那点事吧,帮助那些正在找工作或想跳槽找工作的学弟学妹们. 前面我己写过多篇推文,相信看过我文章的伙伴们已经了解掌握了不少.从目前流行的开发技术. ...
- Java开发面试简历这么写,命中率达70%
上篇文章我们了解到,想要有面试机会,首先要完成一份好的简历.但是在撰写简历的时候,往往有一些细节很容易被忽视,导致面试机会远远不如自己的期望值.一份经过优化的简历,面试的命中率可以达到70%.那我们就 ...
- 顺丰java面试题_顺丰java开发面试分享,顺丰java面试经面试题
今天要给大家分享的是一个小伙伴的顺丰java开发面试过程,其中包括了面试流程,面试题目,和回答,感兴趣的朋友可以来了解一下哈. 一.面试流程 是中午进行的面试,首先是做自我介绍,之后就是讲一下项目,然 ...
- 视频教程:Java常见面试题目深度解析!
视频教程:Java常见面试题目深度解析! Java作为目前比较火的计算机语言之一,连续几年蝉联最受程序员欢迎的计算机语言榜首,因此每年新入职Java程序员也数不胜数.很多java程序员在学成之后,会面 ...
- 2017-10-19 远光软件Java开发面试+达达京东到家笔试总结
远光软件Java开发面试: Java创建对象过程 JavaScript创建对象的方法 直接创建.用函数来创建 jQuery有哪些选择题 元素选择器 层叠选择器 过滤选择器 ...
- 富士康java面试_富士康Java开发面试题目
int leapyear(int y) //计算润年 { if(y%4==0 && y%100!=0 || y!=100 && y%400==0) return 1; ...
- 富士康Java开发面试题目
int leapyear(int y) //计算润年 { if(y%40 && y%100!=0 || y!=100 && y%4000) return 1; else ...
- 博学谷java题库判断_博学谷Java开发面试基础笔试题及答案分享
博学谷Java开发面试基础笔试题分享:char 型变量中能不能存贮一个中文汉字?为什么?"=="和 equals 方法究竟有什么区别?静态变量和实例变量的区别?是否可以从一个 st ...
最新文章
- MySQL数据库备份及二进制文件恢复
- 英语语法---形容词短语详解
- Spring MVC研究之MVC pure string response debug
- onlyoffice启用HTTPS
- 语音识别(3)---语音识别技术原理
- 再推新机!小米A3正式发布 售价249欧元起
- 国庆海报设计适合哪些精品背景纹理?
- rm: cannot remove `.user.ini‘: Operation not permitted异常该如何解决?
- 创业需要的学习能力不是读书考试做题也不是所谓的思维格局
- 图书管理系统项目开发计划书
- Element UI 极简教程(1)
- Windows 10 如何修改桌面路径位置
- 使用 cajViewer 将 caj文件 转换 pdf文件
- 爬取电影天堂最新电影的名称和下载链接(增量爬取mysql存储版)
- 炫酷的生日快乐网页 【附带源码】
- 《非暴力沟通两性篇》读书笔记
- 做不大的支付宝小程序,逃不脱的付钱关系
- 从零开始学python的第19天
- 思科路由器设置时区和自动重启
- 服务器页是指包含什么脚本程序的网页,有会做的吗?
热门文章
- asp.net oracle优化,[转]ASP.NET性能优化
- azure mysql 只读节点_Azure MySQL PaaS 创建MySQL异地只读数据库 (Master-Slave)
- linux防火墙添加端口并开闭防火墙
- input val >=zero input_val <=one
- DLL load failed while importing _pywrap_tensorflow_internal
- 双系统 win10 时间不对
- opengl 预览摄像头
- 论文精读——CenterNet :Objects as Points
- approxPolyDP-轮廓近似
- 青龙羊毛——新快手极速版(搬运,非原创)