搜狗信息流推荐算法实践
本文根据搜狗王东老师在6月9日,DataFunTalk算法技术沙龙中分享的“搜狗信息流推荐算法交流”编辑整理而成,在未改变原意的基础上稍做修改。

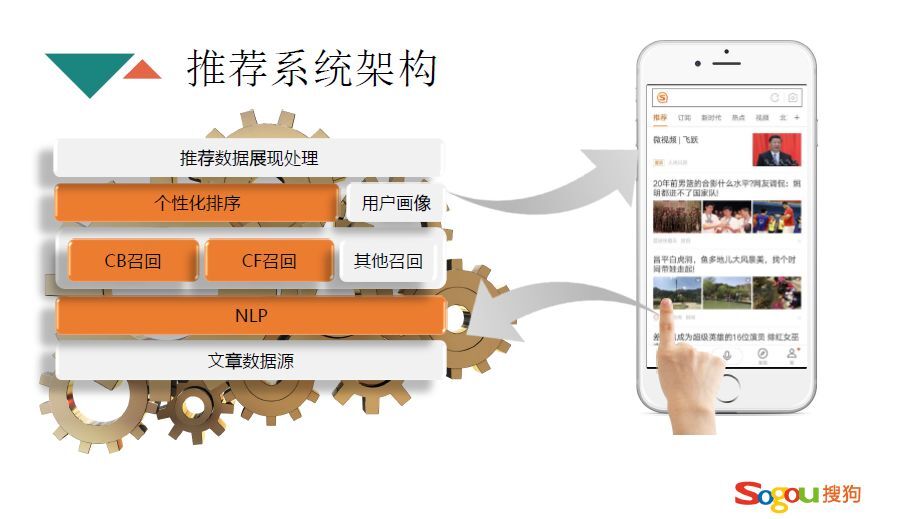
本次分享将从上面四个方面介绍,挑选了在信息流分享领域最重要的三个方面,从这三个方面就能基本完成一个信息流产品。首先是推荐系统的架构,如下图所示,是一个经典的推荐系统架构。首先是数据源,数据源可能是抓取的,或者是合作的,或者是自媒体产生的。数据源即包括图文的数据源,也包括视频的数据源。本文主要关注图文领域。有了数据源之后,首先要进行一下NLP处理,它的作用就是对文章进行抽象,用有限的、关键的topic进行概括出来。接下来一层是召回层,就是通过用户的兴趣和点击把用户需要的文章召回出来,进行浓缩,从一亿多文章到几千左右的量级。再对几千左右的文章进行个性化的排序,最后进行展现处理,推荐给客户端。用户在客户端进行点击操作时,反馈会回到系统中来更新用户的画像,对用户新的请求进行新的推荐。本次主要讲标橘红色的内容。
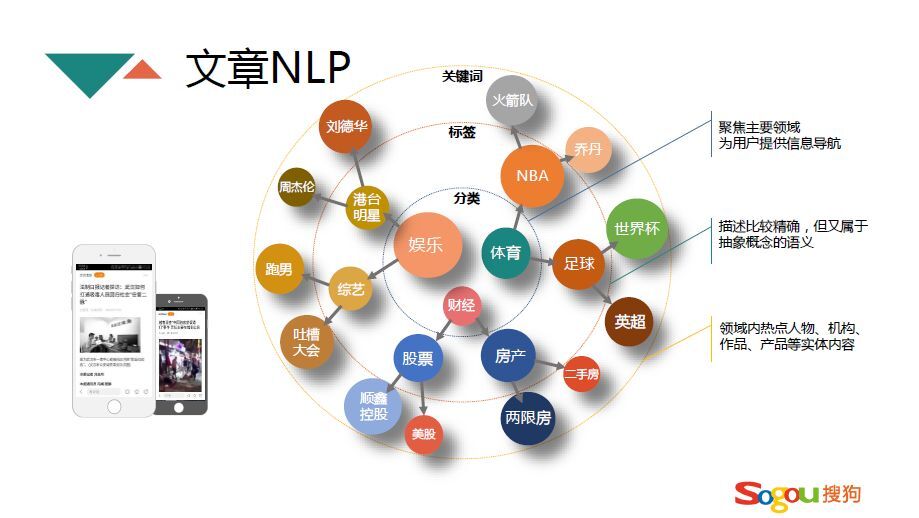
文章NLP是推荐系统的基石,在搜狗公司文章NLP就是把文章分为三个不同维度的体系,这个维度每个公司都不一样,有的简单的话可能就两个维度,复杂的话可能有更多维度。搜狗是采用三个维度的,大的维度是分类,分类是把整个客观世界的信息分成若干个大的类别,能够覆盖主要的领域,比如说任何一篇文章都可以对应某一个相应的分类上去。比分类更低一级的是标签,标签是属于一部分分类,它也是一个集合,比如说NBA这个标签属于体育分类,但是它也是一些概念的集合,比如说下面的火箭队、乔丹。标签是处于关键词和分类中间的体系,像关键词就属于实体的集合,具体的话比如人名、综艺节目。经过这三级体系,就把这整个文章形成一套非常有结构的组织,每一层体系都能代表用户的兴趣级别。
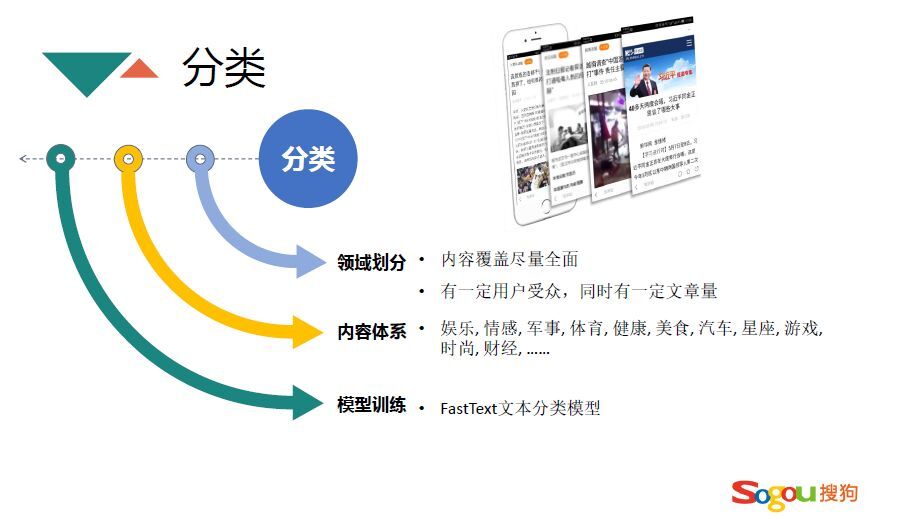
接下来具体讨论下三个级别的概念是怎么计算的。首先是分类这个级别是个比较大的领域,这个领域必须有一定的受众,能够把文章非常恰当的安放到领域当中,目前内容体系有上百个分类,几十个热门分类,比如娱乐、情感、军事、体育等,绝大多数用户的兴趣都会集中在这几个分类当中。怎么训练分类模型呢,采用的是FastText多分类模型,训练的时候每个分类分别收集几十万的文章。
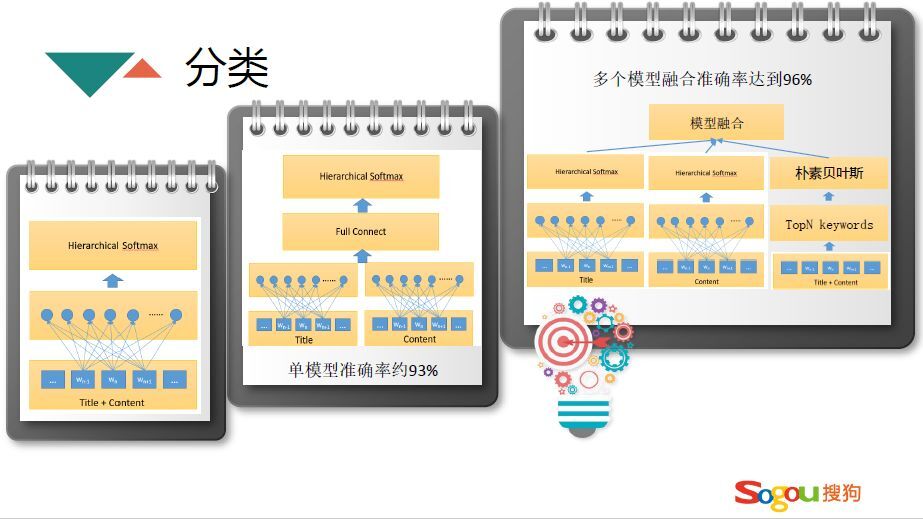
分类模型经过一些阶段的迭代,最终选择比较满意的一个。最开始简单的使用FastText模型,进行文本的多分类,最开始把content和title放在一起,作为文本输入到神经网络当中进行分类,分类效果还可以。后来通过研究之后发现对于文章来说,title和content的重要度是不一样的,很多情况下title是能表述文章的,把title和content分成两部分进行FastText训练,再进行全连接,进行多分类,这样准确度能达到93%。后续优化的时候除了使用FastText还进行了多模型的融合,使用多个模型融合再进行投票,最终准确率达到96%。
接下来是标签的方法,标签和分类都是有限可数的,标签有几百个,都是人为总结出来的,描述比较精确。每个标签都是对应分类当中的,在计算标签的时候使用TextCNN分类模型,每个标签收集几万篇文章。
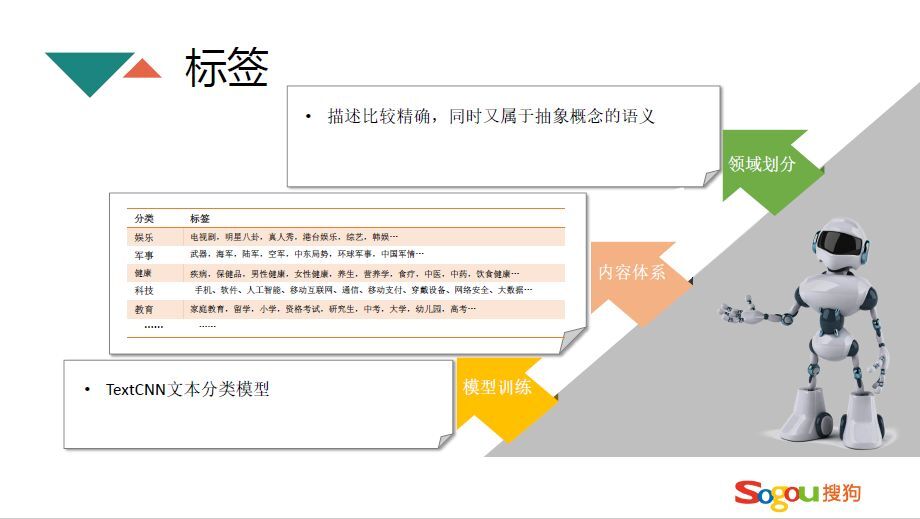
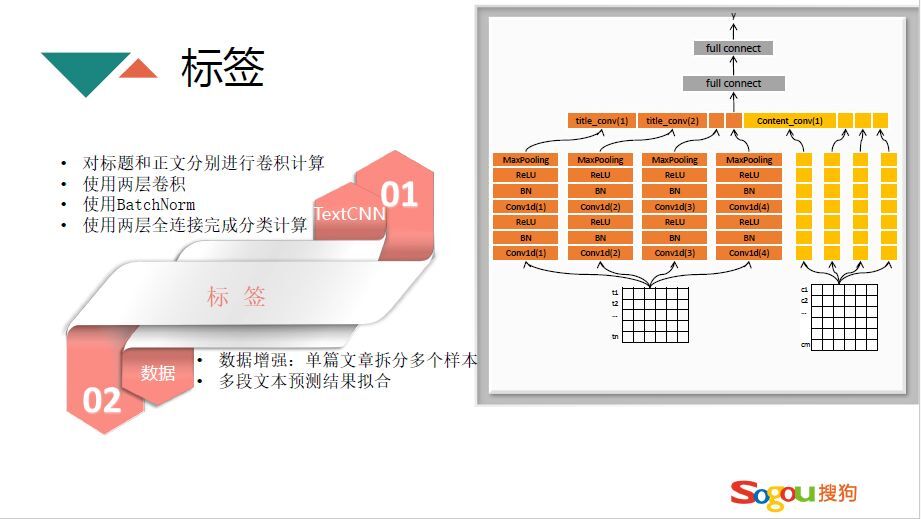
TextCNN分类模型和FastText模型不一样,FastText对于一个文章只会对应到一个分类当中,但是标签不一样,可以有多个标签。TextCNN分类模型对进行了卷积计算,能在更高维度理解标签的定义。模型的整个架构是把标题和正文分开进行卷积,用两层卷积,再进行两层全连接,最后输出一个分类。为了使分类效果更好,也进行了一些数据增强的处理,比如说单篇文章拆分成多个样本,在预测的时候把整篇文章拆成多段文本进行预测拟合,最后进行投票确定最终标签。不同模型测试的实验效果,人工评估比测试集评估准确率高的原因在于做测试集时一篇文章只会打一个标签,人工评估可以分多个类别。fastText能达到75%,TextCNN能达到88%,然后采用“TextCNN+数据增强+多段结果预测”能达到90%,用RNN和RCNN结果差不多。
关键词是各个分类中的热点人物、机构、作品等实体内容,但推荐与知识图谱不同并不需要很多实体,需要能代表兴趣。因此将热点实体经过人工筛选最终筛选出几万的实体量,都是相关领域热门的有代表性的实体。实体词需要实时的进行更新。关键是如何发现实体并将其加入实体集,我们我定期发掘新产生的的热门词汇,通过计算给相关的标注人员推荐给可以作为标注的人们关键词,通过人工方式确定是否可以录入。

关键词的计算由于样本太多无法通过分类来计算,解决方案是从文章中找关键词,选择与其topic相关的关键词作为代表。做关键词一般有两种模型,一种是相似度模型(TF-idf、lda、word2vec),将词与文章都用向量代表,算出词与文章的相似度,找最相近的词。另一个是概率模型Skip-Gram+层次softMax,下面着重介绍概率模型。
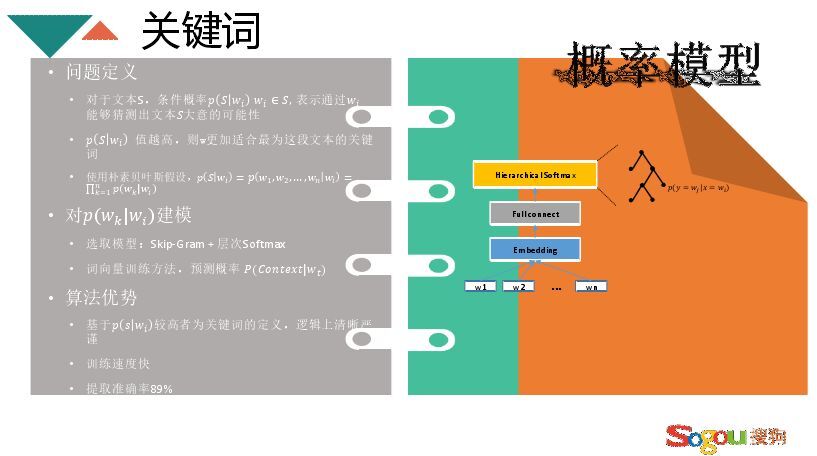
假如有一个文本S,有若干个词,条件概率(见上图)。概率越高则该词更能表示这个文本,更适宜做文本的关键词。将关键词做一个贝叶斯假设,即是词与词之间转换概率的乘积,对词的转换概率的建模。采用word2vec,Skip-Gram思想,输入的是文本空间,经过embedding,然后softMax全连接,最后得出一个词转换为另一个词的转换概率,word2vec不需要右边的树,但是本模型主要利用树结构,算出转换概率后,依据贝叶斯假设选出概率最大的作为关键词,最终准确率能够达到89%。
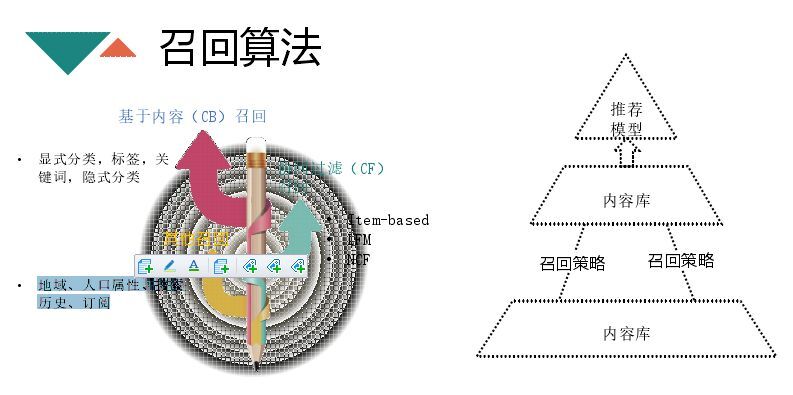
接下来介绍下召回算法,主要是基于内容召回、基于用户、协同过滤的召回等。基于内容召回就是:显式分类,标签,关键词,比如点击周杰伦的文章,周杰伦就会进入你的用户画像里面,下次进行刷新操作就会出现周杰伦相关的文章,进行排序。这三个维度都是人指定的,但是可以用lda等方式将文章分为几百几千的维度,每个维度内文章是相似的,相似原因不是人为可读的,这也可以作为nlp处理的一个方向,还有点击历史相似的文章;协同过滤主要用的是Item-based、LFM、NCF等;还有一些其他的召回,如地域、人口属性、搜索历史、订阅。其他召回不依赖用户行为,对于没有用户行为的新用户你可以通过额外信息进行召回,解决冷启动的问题。
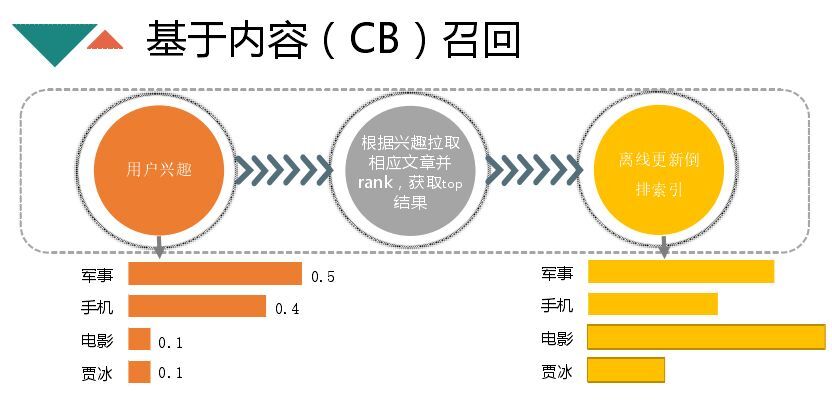

CB召回是在用户画像维护一个用户兴趣的集合以及相应的权重,线下会维护用户兴趣对应的文章列表。这些列表与用户个性化联系紧密,只要一个用户对军事有兴趣,就会将军事列表拉回来做排序。兴趣文章列表维护是CB召回的核心,有两种策略,一种是基于规则的,第二种就是基于模型排序。我们在召回简化为对CTR预测,使用的是LR模型。特征的选取与文章排序预期有关,优质的文章可读性很强,时效性(越新的文章信息量越足),相关度要高。
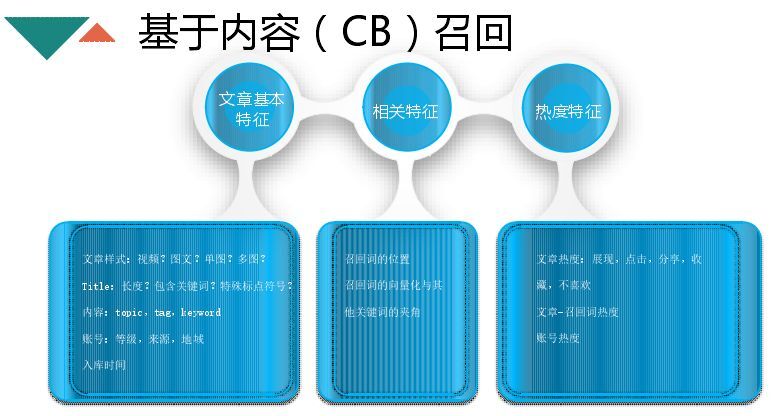
分为三个维度,一个是文章的基本特征,文章样式、图文、长度、是否包含热门关键词、账号等级(能够很好区分出是否是好文章)、入库时间;还有相关特征,词在文章中的位置、出现的频率以及词和词的向量化与其他关键词的夹角;热度特征主要就是文章的热度、点击、分享、不喜欢,还有文章里面召回词的热度,在一定程度也体现文章的质量。将这些特征作为线下模型计算的特征。
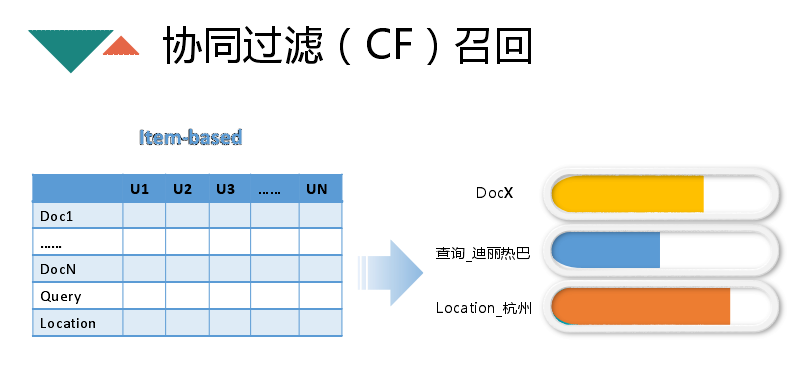
接下来讲一下协同过滤召回,主要是协同召回矩阵,横的是doc,竖的是用户。Item-based就是用户来表示文章doc的向量,通过计算doc与doc之间的相似度来确定doc与doc间的相关性,进而推荐相关的内容。首先是维护每一个doc相关的文章排序,除此之外还有query的协同,如搜doc1的人也搜了query,那么搜query的人可能也对doc1感兴趣,location协同,人口属性也是类似。第一种效果最好,后面相对差一些,但是好处如果冷启动发生,下面两种方法就能推出相关的文章。冷启动无法避免,但是CF某种程度能解决这方面的问题。
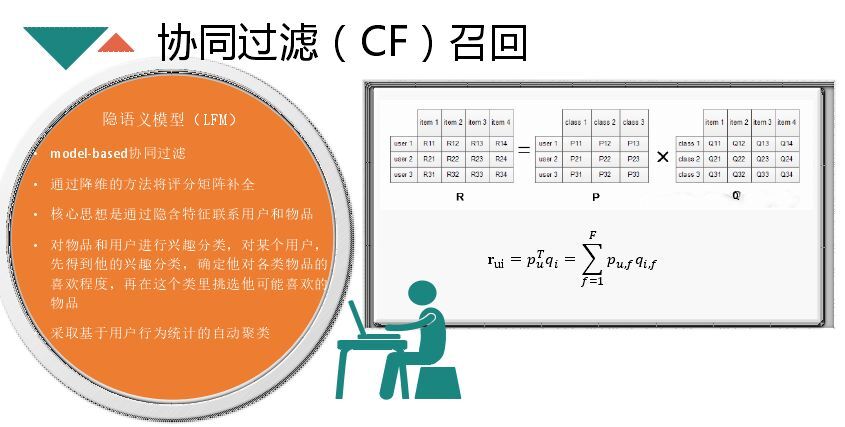
上面的CF是基于矩阵,算的是item与item间的关系,并不直接算item与user的相似度。而隐语模型将矩阵进行分解,变成两个矩阵,将user与item转化为同一个维度,就是对用户点击的分类,就可以直接计算item与user的相似度。目前用的比较多的就是隐语模型,主要用在电影评分领域,在推荐领域也是可以使用。还有一种方式是NCF,就是用神经网络的方式来训练user与item的相似度,通过同样的embedding维度,将user与item统一到同一个向量空间,通过神经网络训练出各自的向量,最后得出用户与item的向量关系。
召回的目的是为了从几亿空间里面找出可以精排的集合,召回基于用户画像,召回与召回间不可比,因此需要对召回集合做个性化排序。

依据信息流产品个性化排序大致分为以下几个阶段:起先基于规则的,然后就是基于LR的预估,最常用的点击率预估模型,速度快,效果好, 与人工规则相比,效果提升显著。后续进行优化,一种是GBDT+LR(Facebook提出的一种方法)实验过程中速度受限,对比LR优化效果不明显。后续用了FTRL优化,思想是在线更新LR模型,在LR的基础上,效果提升明显。目前用的比较多的是基于深度学习,wide\u0026amp;deep模型,在FTRL的基础上,效果再次提升6%。传统机器学习主要处理特征比较明显,表格式的学习任务,深度学习主要解决图像、语音、文本等。推荐问题正好是两者问题的交叉,两种方法都可以使用。
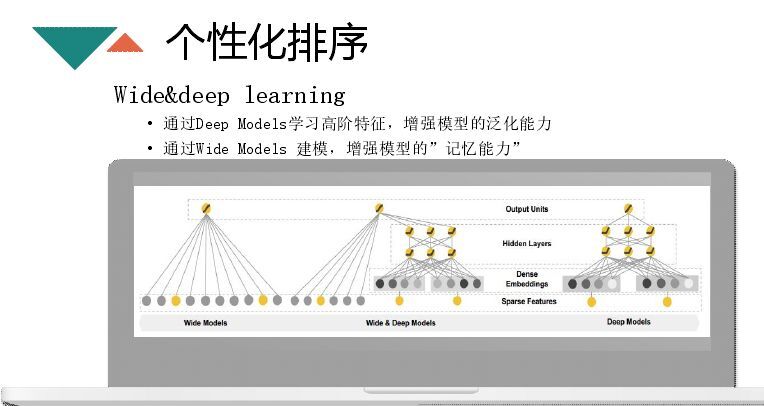
着重讲一下Wide\u0026amp;deep learning模型,该模型将逻辑回归和深度神经网络结合在一起,逻辑回归有一个记忆能力,deep层有泛化能力,wide和deep层的特征需要甄别,能够很好地提升效果。特征工程主要分为三个方面,一方面文章本身的特征,比如内容方面(nlp特征、图片、篇幅、深度),属性就是文章热度、长好特征、时效性、原创性;还有就是用户特征,如用户兴趣、年龄、性别、学历、地域;第三部分就是做特征交叉,在做GDBT+LR时还需要做人工交叉,比如用户兴趣与内容的匹配度,还会利用FM还做自动交叉。
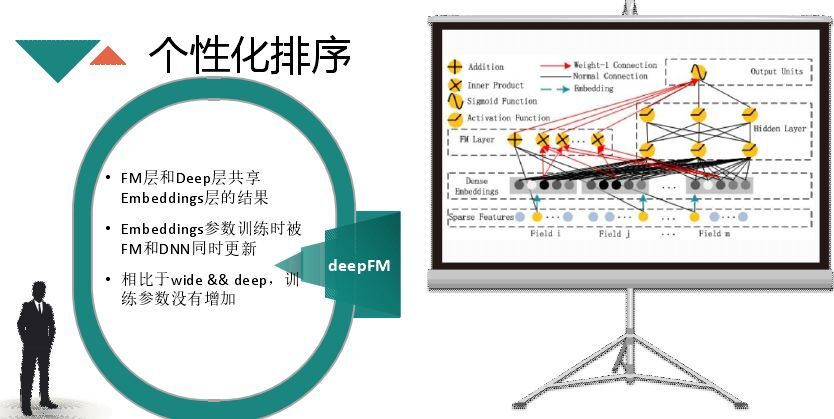
FM交叉也需要embedding,目前流行的用deep,就是FM和deep层用同一层embedding的结果,参数并没有增加,同时完成深度与广度层的embedding,最后进行一个最终预测。

最后做一下总结,首先文章NLP是做推荐的基石,开始做文章处理,后续做用户画像、特征交叉时都需要用到文章NLP。文章NLP不仅限对文章抽象,还包括文章的分级,比如深度文章、浅度文章,还有地域类文章。召回算法有很多,策略和算法同样重要,在召回层并不需要使用特别复杂的算法,你用什么策略召回更重要。个性化排序都是从传统模型向深度模型转换,向头条等巨头使用的是多模型融合,效果也更好。对于初期信息流产品可能不需要这些东西,用户画像需要但不需要太细,但是在演进过程中不可或缺。比如多样性,用CTR预测必然收敛,就需要解决如何打散,如何进行用户新兴趣发现等,还有冷启动问题,没有用户行为时如何推荐,还有质量控制也是必须的,比如现在大环境下一旦有不合适东西推荐出来就会出现严重后果;时效性也很重要,但是评估很困难,有些还需要人工与算法结合,人力也是一个挑战;视频在信息流产品比重越来越重,与图像类似,目前基本以CTR乘以时长作为目标预测,图文基本以CTR为主;视频title很短,如果对视频进行topic、tag等操作抽象往往得不到一个好的结果。
本文来自王东在 DataFun 社区的演讲,由 DataFun 编辑整理。
搜狗信息流推荐算法实践相关推荐
- 【算法实践】搜狗信息流推荐算法交流.pdf(附下载链接)
今天给大家带来搜狗科技王东先生所做的分享<搜狗信息流推荐算法交流.pdf>,本分享共包含如下四大部分: 1.推荐系统架构: 2.文章NLP: 3.召回算法: 4.个性化排序. 本PPT共2 ...
- 【实践】信息流推荐算法实践 深入
0 文章转自: https://blog.csdn.net/dengxing1234/article/details/79756265 一. 背景 负责信息流推荐系统后台算法的工作也有一段时间,从零开 ...
- 腾讯信息流推荐业务实践:内容分发场景的多目标架构实践
猜你喜欢 0.2022年1月份热门报告盘点&下载1.如何搭建一套个性化推荐系统?2.从零开始搭建创业公司后台技术栈3.全民K歌推荐系统算法.架构及后台实现4.微博推荐算法实践与机器学习平台演进 ...
- 推荐系统(十一) 2021-2022年工业界推荐算法实践经验汇总
对2021-2022年,工业界推荐算法实践经验进行了梳理,主要以下几个维度进行归纳: 推荐系统(十一) 2021-2022年工业界推荐算法实践经验汇总对2021-2022年,工业界推荐算法实践经验进行 ...
- 微博多尺度序列推荐算法实践
今天给大家分享新浪微博机器学习算法专家谌贻荣博士在2021年全球机器学习ji s户大会上所做的分享<微博多尺度序列推荐算法实践.pdf>,关注推荐算法及其实践的伙伴们别错过啦!(到省时查报 ...
- 【实践】微博多尺度序列推荐算法实践.pdf(附下载链接)
今天给大家分享新浪微博机器学习算法专家谌贻荣博士在2021年全球机器学习ji s户大会上所做的分享<微博多尺度序列推荐算法实践.pdf>,关注推荐算法及其实践的伙伴们别错过啦!(到#小程序 ...
- 【推荐实践】微博多尺度序列推荐算法实践.pdf(附下载链接)
今天给大家分享新浪微博机器学习算法专家谌贻荣博士在2021年全球机器学习ji s户大会上所做的分享<微博多尺度序列推荐算法实践.pdf>,关注推荐算法及其实践的伙伴们别错过啦!(到#小程序 ...
- 【实践】微博推荐算法实践与机器学习平台演进.pdf(附PPT下载链接)
大家好,今天给大家分享新浪微博申恩兆老师所做的分享<微博推荐算法实践与机器学习平台演进>,本次分享的PPT共38页,包含如下四大部分: 1.微博数据规模简介: 2.相关推荐场景描述: 3. ...
- 微博推荐算法实践与机器学习平台演进
分享嘉宾:申恩兆.李志然 新浪微博 编辑整理:赵文娇.Hoh 出品平台:DataFunTalk 导读:微博作为全球领先的中文广场社交平台,拥有海量用户与数据.在从海量数据中挖掘有价值的信息,为业务赋能 ...
最新文章
- 机器学习01-定义、线性回归、梯度下降
- windows10 删除文件 的权限才能对此文件夹进行更改 解决办法
- oracle中导入导出数据备份数据库
- 机器学习——人工神经网络之参数设置(BP算法)
- 【Java】总结Java数组的拷贝和输出
- python文件编码转换工具_python实现unicode转中文及转换默认编码的方法
- SQLAlchemy engine.Connection
- 用TCP/IP实现自己简单的应用程序协议:成帧器部分
- leetcode-884-两句话中的不常见单词
- 计算机上无线网络开关在哪里,笔记本电脑的无线网络开关在哪里
- 黑产用“未来武器”破解验证码
- 嘟嘟噜~~~第一次写博,纪念一下
- 人工智能机器人发展前景,使用/教程/实例
- Cocos2d之Box2d基础知识
- 本土回忆! 即使你走的再远,也不能忘了让你生长的老家文化~
- 三星 SGH-I900/I908修改生产日期
- SRM 576 D2 L3:CharacterBoard2
- 绿灰配色的微信营销PPT模板-优页文档
- 漫步数学分析十一——紧集
- 强大的魔兽改键--可以像11对战平台一样,自动进入BN!支持命令改键;
热门文章
- Ubuntu+mps-youtube for crawling video / audio
- 简单快捷方法:CAJ 文件转 成PDF文件
- springboot导入项目依赖报错_使用Spring Boot很简单,go!!!
- html 模板引擎 热部署,springboot系列四、配置模板引擎、配置热部署
- c语言从键盘输入千米数,第二章 C语言编程基础.ppt
- 波士顿动力机器狗入驻庞贝古城,还要钻盗洞打击违法犯罪
- 技术宅硬核跨年,DIY墨水屏日历:自动刷新位置、天气,随机播放2000多条「毒鸡汤」| 开源...
- 嬴彻科技拿下SemanticKITTI榜单两项第一
- 姚班天才漆子超、IOI金牌得主陈启峰等联手进军AR领域:全员顶尖科技公司技术背景,打造“5G+AI+AR”先锋...
- 活动推荐 | 2019日立「视频分析技术黑客马拉松」报名启动,还有高额奖金等你赢...