大数据入门之Hadoop基础学习
前言
目前人工智能和大数据火热,使用的场景也越来越广,日常开发中前端同学也逐渐接触了更多与大数据相关的开发需求。因此对大数据知识也有必要进行一些学习理解
基础概念
大数据的本质
一、数据的存储:分布式文件系统(分布式存储)
二、数据的计算:分部署计算
基础知识
学习大数据需要具备Java知识基础及Linux知识基础
学习路线
(1)Java基础和Linux基础
(2)Hadoop的学习:体系结构、原理、编程
第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)
第二阶段:数据分析引擎 -> Hive、Pig
数据采集引擎 -> Sqoop、Flume第三阶段:HUE:Web管理工具
ZooKeeper:实现Hadoop的HAOozie:工作流引擎(3)Spark的学习
第一阶段:Scala编程语言第二阶段:Spark Core -> 基于内存、数据的计算第三阶段:Spark SQL -> 类似于mysql 的sql语句第四阶段:Spark Streaming ->进行流式计算:比如:自来水厂(4)Apache Storm 类似:Spark Streaming ->进行流式计算
NoSQL:Redis基于内存的数据库
HDFS
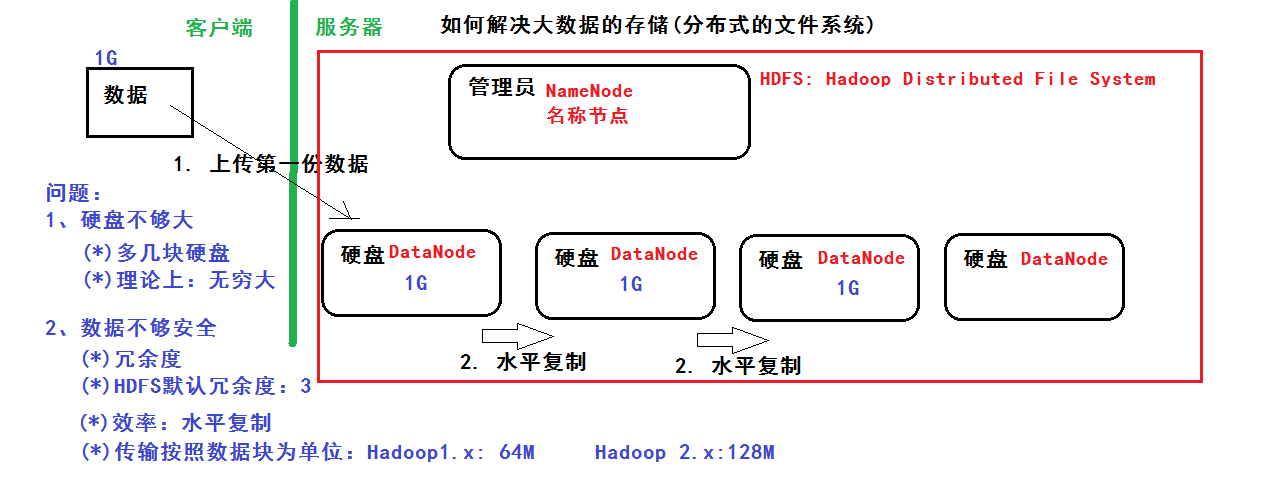
分布式文件系统 解决以下问题:
1、硬盘不够大:多几块硬盘,理论上可以无限大
2、数据不够安全:冗余度,hdfs默认冗余为3 ,用水平复制提高效率,传输按照数据库为单位:Hadoop1.x 64M,Hadoop2.x 128M
管理员:NameNode 硬盘:DataNode
MapReduce
基础编程模型:把一个大任务拆分成小任务,再进行汇总
MR任务:Job = Map + Reduce Map的输出是Reduce的输入、MR的输入和输出都是在HDFS
MapReduce数据流程分析:
Map的输出是Reduce的输入,Reduce的输入是Map的集合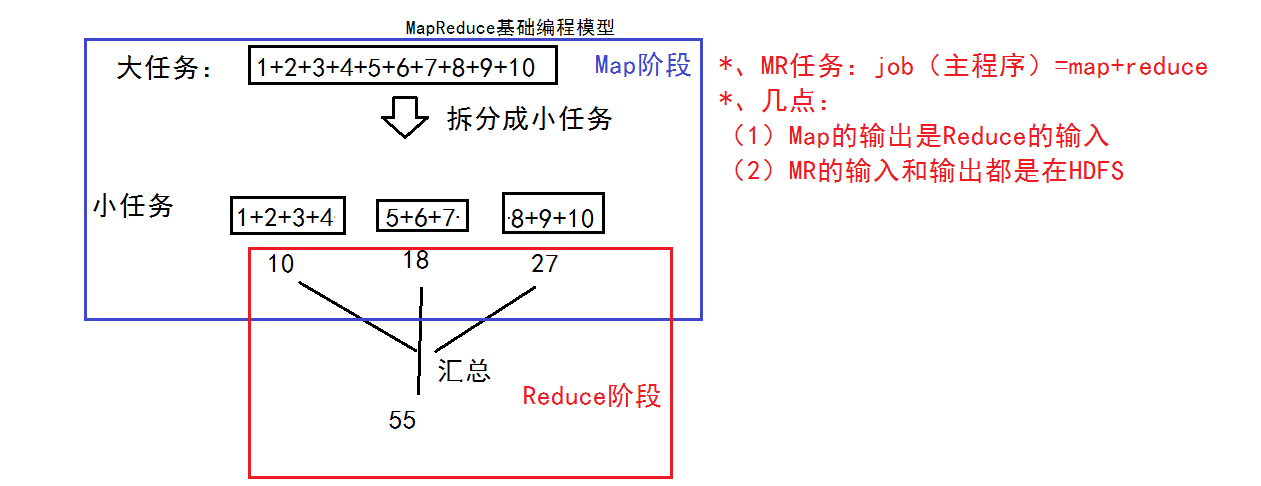
HBase
什么是BigTable?: 把所有的数据保存到一张表中,采用冗余 ---> 好处:提高效率
1、因为有了bigtable的思想:NoSQL:HBase数据库
2、HBase基于Hadoop的HDFS的
3、描述HBase的表结构
核心思想是:利用空间换效率
Hadoop环境搭建
环境准备
Linux环境、JDK、http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0-src.tar.gz
安装
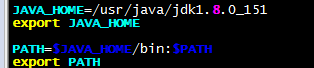
1、安装jdk、并配置环境变量
vim /etc/profile 末尾添加
2、解压hadoop-3.0.0.tar.gz、并配置环境变量
tar -zxvf hadoop-3.0.0.tar.gz -C /usr/local/
mv hadoop-3.0.0/ hadoop

vim /etc/profile 末尾添加

配置
Hadoop有三种安装模式:
本地模式 :1台主机 不具备HDFS,只能测试MapReduce程序伪分布模式:1台主机 具备Hadoop的所有功能,在单机上模拟一个分布式的环境(1)HDFS:主:NameNode,数据节点:DataNode(2)Yarn:容器,运行MapReduce程序主节点:ResourceManager从节点:NodeManager全分布模式:至少3台
我们以伪分布模式为例配置:
修改hdfs-site.xml:冗余度1、权限检查false
<!--配置冗余度为1-->
<property><name>dfs.replication</name><value>1</value>
</property><!--配置权限检查为false-->
<property><name>dfs.permissions</name><value>false</value>
</property>
修改core-site.xml
<!--配置HDFS的NameNode-->
<property><name>fs.defaultFS</name><value>hdfs://192.168.56.102:9000</value>
</property><!--配置DataNode保存数据的位置-->
<property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value>
</property>
修改mapred-site.xml
<!--配置MR运行的框架-->
<property><name>mapreduce.framework.name</name><value>yar</value>
</property>
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property><name>mapreduce.application.classpath</name><value>/usr/local/hadoop/etc/hadoop,/usr/local/hadoop/share/hadoop/common/*,/usr/local/hadoop/share/hadoop/common/lib/*,/usr/local/hadoop/share/hadoop/hdfs/*,/usr/local/hadoop/share/hadoop/hdfs/lib/*,/usr/local/hadoop/share/hadoop/mapreduce/*,/usr/local/hadoop/share/hadoop/mapreduce/lib/*,/usr/local/hadoop/share/hadoop/yarn/*,/usr/local/hadoop/share/hadoop/yarn/lib/*,</value>
</property>
修改yarn-site.xml
<!--配置ResourceManager地址-->
<property><name>yarn.resourcemanager.hostname</name><value>192.168.56.102</value>
</property><!--配置NodeManager执行任务的方式-->
<property><name>yarn.nodemanager.aux-service</name><value>mapreduce_shuffle</value>
</property>
格式化NameNode
hdfs namenode -format
看到common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted表示格式化成功
启动
start-all.sh
(*)HDFS:存储数据
(*)YARN:
访问
(*)命令行
(*)Java Api
(*)WEB Console
HDFS: http://192.168.56.102:50070
Yarn: http://192.168.56.102:8088

查看HDFS管理界面和yarn资源管理系统


基本操作:
HDFS相关命令
-mkdir 在HDFD创建目录 hdfs dfs -mkdir /data-ls 查看目录 hdfs dfs -ls-ls -R 查看目录与子目录 hdfs dfs -ls -R-put 上传一个文件 hdfs dfs -put data.txt /data/input-copyFromLocal 上传一个文件 与-put一样-moveFromLocal 上传一个文件并删除本地文件 -copyToLocal 下载文件 hdfs dfs -copyTolocal /data/input/data.txt-put 下载文件 hdfs dfs -put/data/input/data.txt-rm 删除文件 hdfs dfs -rm-getmerge 将目录所有文件先合并再下载-cp 拷贝-mv 移动-count 统计目录下的文件个数-text、-cat 查看文件-balancer 平衡操作

MapReduce示例
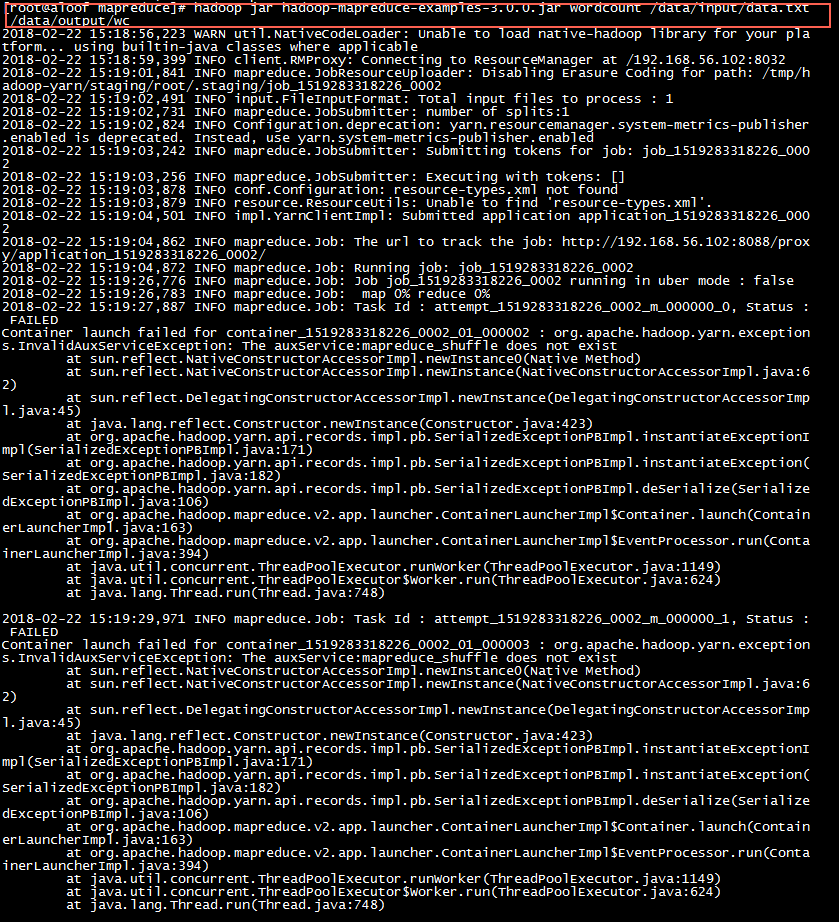
结果:

如上 一个最简单的MapReduce示例就执行成功了
思考
Hadoop是基于Java语言的,前端日常开发是用的PHP,在使用、查找错误时还是蛮吃力的。工作之余还是需要多补充点其它语言的相关知识,编程语言是我们开发、学习的工具,而不应成为限制我们技术成长的瓶颈
大数据入门之Hadoop基础学习相关推荐
- 大数据入门(Hadoop生态系统)
Hadoop生态系统为大数据领域提供了开源的分布式存储和分布式计算的平台,这一章我们进行Hadoop生态系统的入门学习,介绍其中分布式文件系统HDFS.分布式资源调度YARN.分布式计算框架MapRe ...
- 【大数据笔记】hadoop基础——各组件介绍
目录 故事背景 Hadoop 与大数据之间到底是什么关系? 1.数据存储:HDFS,一个分布式文件系统 2. 数据分析:MapReduce 计算引擎 HDFS(Hadoop 分布式文件系统) MapR ...
- 大数据新手的0基础学习路线,从菜鸟到高手的成长之路
大数据作为一个新兴的热门行业,吸引了很多人,但是对于大数据新手来说,按照什么路线去学习,才能够学习好大数据,实现从大数据菜鸟到高手的转变.这是很多想要学习大数据的朋友们想要了解的. 今天我们就来和大家 ...
- 自动化专业学习大数据开发,零基础学习分享
上课一直坐在前排的杨同学,年前辞职来专心学习大数据技术.被问到为什么想转行学习大数据时,之前从事无线通信优化工作的他说:"我的工作经常出差,而且上升空间不是很大,因为经常出差肯定要转行,不如 ...
- 大数据入门(Hadoop)
大数据的开发流程: 产品人员提需求 数据部门搭建数据平台(搭建一个集群),分析数据指标. 数据可视化(邮件的展示,邮件的发送,大屏展示) 大数据部门的组织结构: Hadoop是什么?作用? 狭义:Ha ...
- 【大数据入门】Hadoop技术原理与应用之基于Hadoop的数据仓库Hive
基于Hadoop的数据仓库Hive 文章目录 基于Hadoop的数据仓库Hive @[toc] 6.1 概述 6.1.1 数据仓库概念 6.1.2 传统数据仓库面临的挑战 6.1.3 Hive简介 6 ...
- 大数据笔记30—Hadoop基础篇13(Hive优化及数据倾斜)
Hive优化及数据倾斜 知识点01:回顾 知识点02:目标 知识点03:Hive函数:多行转多列 知识点04:Hive函数:多行转单列 知识点05:Hive函数:多列转多行 知识点06:Hive函数: ...
- 大数据入门培训之大数据开发基础知识学习
在目前相信大多数IT开发人员对于人工智能+大数据并不陌生,使用的场景也越来越广,日常开发中前端同学也逐渐接触了更多与大数据相关的开发需求.因此对大数据知识也有必要进行一些学习理解,带大家来学习了解一下 ...
- 女友问粉丝过万如何庆祝,我发万字长文《保姆级大数据入门篇》感恩粉丝们支持,学姐|学妹|学弟|小白看了就懂
2021大数据领域优质创作博客,带你从入门到精通,该博客每天更新,逐渐完善大数据各个知识体系的文章,帮助大家更高效学习. 有对大数据感兴趣的可以关注微信公众号:三帮大数据 目录 粉丝破万了 新星计划申 ...
最新文章
- 来玩Play框架07 静态文件
- 笔记-项目整体管理-开工会议-kick-off-meeting
- 易语言微凉模块oracle,跟着微凉学易语言 【简单子类化】
- Cannot fit requested classes in a single dex file. Try supplying a main-dex list.
- android 默认浏览器 视频播放 二维码,Android调用系统默认浏览器访问的方法
- Linux用管道移动文件夹,常用的Linux上的文件管理类命令讲解及演示
- r语言插补法_R语言用多重插补法估算相对风险
- 计算机教育部 学科分类,教育部学科分类与代码分类查询
- 景深的计算及弥散圆、光圈的概念
- 电子计算机上面cutup,cutup(cut up用法总结)
- 我对TCP协议的一点形而上的看法
- 小样儿老师:我的嵌入式学习之路(一)
- Ubuntu / Debian: sudo 出现 unable to resolve host 错误解决办法
- IJCAI TEXT PAPERS
- 统计学第四周-概率分布
- 一线PPT制作理论——简洁电磁环境构建
- WordPress论坛主题:LightSNS - 主打轻社交
- android 分辨率 2k,小米8分辨率是不是2k?
- 基于双向LSTM的影评情感分析算法设计学习记录
- Foxmail 配置公司邮箱