[hive学习翻译]Hive - Introduction
术语“大数据”用于大数据集的集合,包括大量,高速度和各种日益增加的数据。使用传统的数据管理系统,很难处理大数据。因此,Apache Software Foundation引入了一个称为Hadoop的框架来解决大数据管理和处理难题。
Hadoop
Hadoop是一个开放源代码框架,用于在分布式环境中存储和处理大数据。它包含两个模块,一个是MapReduce,另一个是Hadoop分布式文件系统(HDFS)。
MapReduce:它是一个并行编程模型,用于在大型商品硬件集群上处理大量的结构化,半结构化和非结构化数据。
HDFS:Hadoop分布式文件系统是Hadoop框架的一部分,用于存储和处理数据集。它提供了一个容错文件系统在商用硬件上运行。
Hadoop生态系统包含用于帮助Hadoop模块的不同子项目(工具),如Sqoop,Pig和Hive。
Sqoop:用于在HDFS和RDBMS之间导入和导出数据。
Pig:这是一个用于为MapReduce操作开发脚本的过程语言平台。
Hive:它是一个用于开发SQL类型脚本以执行MapReduce操作的平台。
注意:有多种方法来执行MapReduce操作:
使用Java MapReduce程序的传统方法用于结构化,半结构化和非结构化数据。
使用Pig来处理结构化和半结构化数据的MapReduce的脚本方法。
Hive查询语言(HiveQL或HQL),用于MapReduce使用Hive处理结构化数据。
什么是Hive
Hive是一个用于在Hadoop中处理结构化数据的数据仓库基础结构工具。它驻留在Hadoop之上,用于总结大数据,并使查询和分析变得容易。
最初Hive由Facebook开发,后来Apache软件基金会将其开发并进一步开发为Apache Hive名下的开源软件。它被不同的公司使用。例如,Amazon在Amazon Elastic MapReduce中使用它。
Hive不是
- 关系数据库
- 用于线上事务处理(OLTP)
- 用于实时查询和行级更新的语言
Hive的特点
- 它将模式存储在数据库中,并将处理后的数据存储到HDFS中。
- 它是为OLAP设计的。
- 它提供了用于查询的SQL类型语言,称为HiveQL或HQL。
- 它是熟悉,快速,可扩展和可扩展。
以下组件图描述了Hive的体系结构:
![]()
This component diagram contains different units. The following table describes each unit:
| Unit Name | Operation |
|---|---|
| User Interface |
Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user interfaces that Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server). Hive是一个数据仓库基础设施软件,可以创建用户和HDFS之间的交互。 Hive支持的用户界面有Hive Web UI,Hive命令行和Hive HD Insight(在Windows服务器中)。 |
| Meta Store |
Hive chooses respective database servers to store the schema or Metadata of tables, databases, columns in a table, their data types, and HDFS mapping. Hive选择相应的数据库服务器来存储表,数据库,表中的列,其数据类型和HDFS映射的模式或元数据。 |
| HiveQL Process Engine |
HiveQL is similar to SQL for querying on schema info on the Metastore. It is one of the replacements of traditional approach for MapReduce program. Instead of writing MapReduce program in Java, we can write a query for MapReduce job and process it. HiveQL类似于SQL用于查询Metastore上的模式信息。 它是MapReduce程序的传统方法的替代品之一。 代替在Java中编写MapReduce程序,我们可以为MapReduce作业编写一个查询并处理它。 |
| Execution Engine |
The conjunction part of HiveQL process Engine and MapReduce is Hive Execution Engine. Execution engine processes the query and generates results as same as MapReduce results. It uses the flavor of MapReduce. HiveQL进程Engine和MapReduce的连接部分是Hive执行引擎。 执行引擎处理查询并生成与MapReduce结果相同的结果。 它使用MapReduce的风格。 |
| HDFS or HBASE |
Hadoop distributed file system or HBASE are the data storage techniques to store data into file system. Hadoop分布式文件系统或HBASE是将数据存储到文件系统中的数据存储技术。 |
Working of Hive
The following diagram depicts the workflow between Hive and Hadoop.
下图描述了Hive和Hadoop之间的工作流。
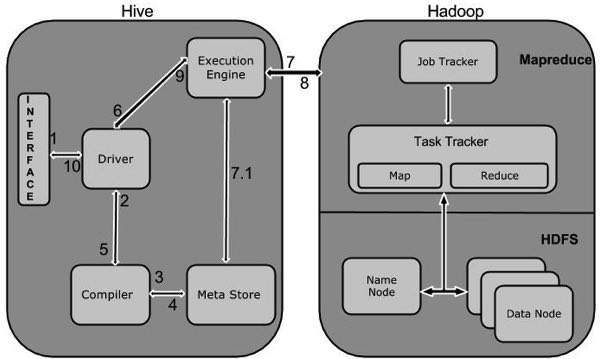
The following table defines how Hive interacts with Hadoop framework:
| Step No. | Operation |
|---|---|
| 1 |
Execute Query
The Hive interface such as Command Line or Web UI sends query to Driver (any database driver such as JDBC, ODBC, etc.) to execute. |
| 2 |
Get Plan
The driver takes the help of query compiler that parses the query to check the syntax and query plan or the requirement of query. |
| 3 |
Get Metadata
The compiler sends metadata request to Metastore (any database). |
| 4 |
Send Metadata
Metastore sends metadata as a response to the compiler. |
| 5 |
Send Plan
The compiler checks the requirement and resends the plan to the driver. Up to here, the parsing and compiling of a query is complete. |
| 6 |
Execute Plan
The driver sends the execute plan to the execution engine. |
| 7 |
Execute Job
Internally, the process of execution job is a MapReduce job. The execution engine sends the job to JobTracker, which is in Name node and it assigns this job to TaskTracker, which is in Data node. Here, the query executes MapReduce job. |
| 7.1 |
Metadata Ops
Meanwhile in execution, the execution engine can execute metadata operations with Metastore. |
| 8 |
Fetch Result
The execution engine receives the results from Data nodes. |
| 9 |
Send Results
The execution engine sends those resultant values to the driver. |
| 10 |
Send Results
The driver sends the results to Hive Interfaces. |
from:https://www.tutorialspoint.com/hive/hive_introduction.htm
转载于:https://www.cnblogs.com/hager/p/6322867.html
[hive学习翻译]Hive - Introduction相关推荐
- Hive学习笔记 —— Hive的安装
1. Hive的安装模式 官网下载安装包:http://hive.apache.org/ 历史版本下载:http://archive.apache.org/ 本次使用:http://archive.a ...
- Hive学习笔记 —— Hive的体系结构
1. Hive的体系结构 Hadoop 用HDFS进行存储,利用MapReduce进行计算 元数据存储(MetaStore) 通常是存储在关心数据库,如mysql.derby中 在Hive执行HQL语 ...
- Hive学习——单机版Hive的安装
目录 一.基本概念 (一)Hive概念 (二)优势和特点 (三)Hive元数据管理 (四)Hive架构 (五)Hive Interface – 其他使用环境 二.Hive环境搭建 1.自动安装脚本 2 ...
- HIVE学习系列——Hive操作
文章目录 Hive表介绍 基本句法-创建新表: Demo运行(以实际使用中的常用句法为编写规范): Q&A 基本句法-向table添加数据 Demo运行(承接创建的表) Q&A 基本句 ...
- Hive学习笔记 —— Hive的数据类型
Hive本质上是一个数据库,可以创建表,表有列组成,而列支持的主要类型有:基本数据类型.复杂数据类型.时间数据类型. 1. Hive的数据类型之基本数据类型 tinyint/smallint/int/ ...
- Hive学习笔记 —— Hive的管理
1. Hive的启动方式 CLI(命令行)方式 Web界面方式 远程服务启动方式 2. Hive的管理之CLI方式 直接输入 # <HIVE_HOME>/bin/hive 的执行程序 输入 ...
- Hive学习笔记 —— Hive概述
1. 数据仓库简介 1.1 数据仓库 可以利用数据仓库来保存我们的数据,但是数据仓库有别于我们常见的一般数据库.数据仓库是一个面向主题的.集成的.不可更新的.随时间不变化的数据集成,它用于支持企业或组 ...
- HIve学习:Hive分区修改
文章目录 什么是Hive的分区 分区意义 分区技术 分区方法和本质 创建一级分区表 创建二级分区表 如何修改Hive的分区 查看分区 添加分区 分区名称修改 修改分区路径 删除分区 分区类别 hive ...
- 【转】Hive学习路线图
原文博客出自于:http://blog.fens.me/hadoop-hive-roadmap/ 感谢! Hive学习路线图 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Ha ...
最新文章
- poj3686(最小权值完美匹配)
- 专业音频如何把电平转换成dbu_这是我见过最细致的音频系统增益设置指南,跟着学起来!...
- Classes in JScript – Part III 类的继承与封装
- IIS6文件权限不对触发了Windows身份认证问题解决方法
- java内存模型概述_Java内存模型-快速概述和注意事项
- Appscan_web安全测试工具 (含修改启动浏览器的方法)
- Python3 中的 asyncio async await 概念(实例)(ValueError: too many file descriptors in select())
- 程序员挑战高薪,你必须会的十大面试题《一》
- 10年老分析师:数据分析不只是一个岗位,更是一种职场必备能力
- 《2001太空漫游》50周年:一部电影和一整个时代
- 差分pid模块_基于数字PID切换控制的Buck变换器研究
- vscode推荐编程字体
- tp5 生成二维码并与背景图合并
- Maven(六)Maven传递性和依赖性
- 论如何进行培养独立解决问题的能力
- 关闭Vue Eslint语法检查
- MySQL索引数据结构详解
- 【Dart 教程系列第 10 篇】Dart 之 removeLast 删除数组的最后一个元素
- 史上最强红利指数——标普A股红利机会指数全解析
- 为什么直通车关键词点击率和转化率会低
热门文章
- Codeforces Beta Round #9 (Div. 2 Only) C. Hexadecimal's Numbers dfs
- PEP 0498 -- Literal String Interpolation 翻译(未完待续)
- Bitmap 索引 vs. B-tree 索引:如何选择以及何时使用?——2-5
- Ajax PHP 边学边练 之四 表单
- 一次“炼狱”般的电脑维护
- 观察者模式 Observer 发布订阅模式 源 监听 行为型 设计模式(二十三)
- 用两张图告诉你,为什么你的App会卡顿?
- # W3C 中文离线教程 2016 年版
- PL/SQL程序设计 第一章 PL/SQL 程序设计简介
- Microsoft Visual Studio 2010 Service Pack 1