XGBoost详解(原理篇)
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、XGBoost简介
二、XGBoost原理
1、基本组成元素
2、整体思路
(1)训练过程——构建XGBoost模型
(2)测试过程
3、目标函数
(1)最初的目标函数
(2)推导
4、从目标函数到特征划分准则 + 叶子节点的值的确定
(1) 编辑 的定义
(2)引入真实的编辑和正则化项代换
(3)求出 编辑 —— 定下该叶子结点的值
(4)目标函数的最优解——与信息增益的连接
(5)特征划分准则——“信息增益”
5、从目标函数到加权分位法(实现对每个特征具体的划分)
(1)引入原因
(2)“特征值重要性”的提出
(3)目标函数到平方损失
(4)特征值重要性排序函数
(5)切分点寻找
(6)计算分裂点的策略
三、XGBoost对缺失值的处理
四、XGBoost的优缺点
1、优点
(1)精度高
(2)灵活性强
(3)防止过拟合
(4)缺失值处理
(5)并行化操作
2、缺点
一、XGBoost简介
XGBoost全称为eXtreme Gradient Boosting,即极致梯度提升树。
XGBoost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器(个体学习器间存在强依赖关系,必须串行生成的序列化方法)。
Note:关于Boosting算法详见博文集成学习详解_tt丫的博客-CSDN博客
XGBoost是一种提升树模型,即它将许多树模型集成在一起,形成一个很强的分类器。其中所用到的树模型则是CART回归树模型。
Note:CART回归树模型详见博文决策树详解_tt丫的博客-CSDN博客
二、XGBoost原理
1、基本组成元素
XGBoost的基本组成元素是:决策树。
这些决策树即为“弱学习器”,它们共同组成了XGBoost;
并且这些组成XGBoost的决策树之间是有先后顺序的:后一棵决策树的生成会考虑前一棵决策树的预测结果,即将前一棵决策树的偏差考虑在内,使得先前决策树做错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一棵决策树。
2、整体思路
(1)训练过程——构建XGBoost模型
从目标函数出发,可以推导出“每个叶子节点应该赋予的权值”,”分裂节点后的信息增益“,以及”特征值重要性排序函数“。
与之前决策树的建立方法类似。当前决策树的建立首先根据贪心算法进行划分,通过计算目标函数增益(及上面所说的”分裂节点后的信息增益“),选择该结点使用哪个特征。
选择好哪个特征后,就要确定分左右子树的条件了(比如选择特征A,条件是A<7):为了提高算法效率(不用一个一个特征值去试),使用“加权分位法”,计算分裂点(这里由”特征值重要性排序函数“得出分裂点)。
并且对应叶子节点的权值就由上述的“每个叶子节点应该赋予的权值”给出。
不断进行上述算法,直至所有特征都被使用或者已经达到限定的层数,则完整的决策树构建完成。
(2)测试过程
将输入的特征,依次输入进XGBoost的每棵决策树。每棵决策树的相应节点都有对应的预测权值w,将“在每一棵决策树中的预测权值”全部相加,即得到最后预测结果,看谁大,谁大谁是最后的预测结果。
3、目标函数
(1)最初的目标函数
设定第 t 个决策树的目标函数公式如下:
符号定义:
n表示样本数目;
表示与有关的损失函数,这个损失函数是可以根据需要自己定义的;
表示样本 i 的实际值;
表示前 t 棵决策树一起对样本 i 的预测值;
表示第t棵树的模型复杂度,这里是正则化项,为了惩罚更复杂的模型(通过减小树的深度和单个叶子节点的权重值),减缓过拟合。
T为当前子树的深度,w为叶子节点的节点值。
(2)推导
A、根据Boosting的原理简化
根据Boosting的原理:第 t 棵树对样本 i 的预测值=前 t-1 棵预测树的预测值 + 第 t 棵树的预测值
即:
这里补充一下:Shrinkage(收缩过程):
Shrinkage即:每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。就是说它不完全信任每一个棵残差树(达到防止过拟合的效果),它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。即给每棵数的输出结果乘上一个步长η (收缩率),如下公式所示:
后续的公式推导都默认 η = 1。
那么最初的目标函数就可以化为:
符号定义:
表示第 t 棵决策树对样本 i 的预测值
B、根据二阶泰勒展开
分析:
我们知道,二阶泰勒展开公式:
将上面的
当成
,即把
当作 x ,把
。
这样一来,
就是
啦。
那么就有:
其中:
——表示一阶导数,是可以求出来的已知数
——表示二阶导数,是可以求出来的已知数
C、去掉常数项
因为我们的目的是要最小化目标函数,那些常数项我们可以把它们暂时搁置。
4、从目标函数到特征划分准则 + 叶子节点的值的确定
(1) 的定义
XGBoost把 定义为
其中代表了样本 i 在哪个叶子节点上,w表示叶子结点的权重(即决策树的预测值)
(2)引入真实的和正则化项代换
进一步化为:
其中:
代表决策树 q 在叶子节点 j 上的取值(即表示位于第j个叶子结点有哪些样本)
这样就把累加项从样本总数变为了针对当前决策树的叶子节点。
再令 和
,
再次化简为:
(3)求出 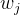 —— 定下该叶子结点的值
—— 定下该叶子结点的值
因为我们的目的是最小化目标函数,因此我们对上式求导,令其为0。
即我们应该将叶子结点的值设为
(4)目标函数的最优解——与信息增益的连接
这个又叫结构分数,类似于信息增益,可以对树的结构进行打分。
信息增益:更能确定多少——目标函数:预测对了多少
(5)特征划分准则——“信息增益”
其中 L 下标是值划分到左子树时的目标函数最优值,R 下标是值划分到右子树时的目标函数最优值。在实际划分时,XGBoost会基于“Gain最大”的节点进行划分。
第一部分是新的左子叶的分数(即该节点进行特征分裂后左子叶的目标函数);第二部分是新的右子叶的分数(即该节点进行特征分裂后右子叶的目标函数);第三部分是原来叶子的分数(即该节点未进行特征分裂前的目标函数);第四部分是新增叶子的正则系数。
体现的意义即为:判断分裂节点后的信息增益(第一部分+第二部分)是否大于未分裂的情况,并且考虑到模型会不会太复杂的问题(如果增加的分数小于正则项,节点不再分裂)。
5、从目标函数到加权分位法(实现对每个特征具体的划分)
(1)引入原因
比如说,有一个特征A是一个离散的连续变量,有100个不同的值,范围是[1,100]。那么如果选择特征D来分裂节点时,需要尝试100种不同的划分,一个一个算然后再对比Gain,可以是可以,但会导致算法的效率很低。
XGBoost为了实现可以不用尝试每一种的划分,只选取几个值进行尝试,提出了加权分位法。
(2)“特征值重要性”的提出
为了得到值得进行尝试的划分点,我们需要建立一个函数对该特征的特征值进行"重要性"排序。根据排序的结果,再选出值得进行尝试的特征值。
(3)目标函数到平方损失
我们前面得到的目标函数长这样:
我们把 提出来,变成:
然后因为 和
都是已知数,相当于常量,我们给他加上它们的相关运算,在后面再给他减掉一个常数,结果不变。
C为常数项
现在我们得到的式子即为:真实值为 ,权重为
的平方损失项+正则化项+常数项
(4)特征值重要性排序函数
因此,我们可以得出结论:一个样本对于目标函数值的贡献,在于其 。因此可以根据
对特征值的“重要性”进行排序。XGBoost提出了一个新的函数,这个函数用于表示一个特征值的"重要性"排名:(这里的特征值表示:某个等待判断分裂的节点属性,中的某个取值)
![]()
其中:
:第k个特征的每个样本的特征值(
)与其相应的
组成的集合;
:表示第 i 个样本对于第k个特征的特征值,和其对应的
的分母:第k个特征的所有样本的
式子表示的意义是:特征值小于z的样本特征重要性分布占比
(5)切分点寻找
之后对一个特征的所有特征值进行排序。在排序之后,设置一个值 ϵ (采样频率)。这个值用于对要划分的点进行规范。对于特征k的特征值的划分点有,两个相连划分点的
值之差的绝对值要小于 ϵ (为了让相邻的划分点的贡献度都差不多)。同时,为了增大算法的效率,也可以选择每个切分点包含的特征值数量尽可能多。
![]()
(6)计算分裂点的策略
基于加权分位法,我们有两种策略进行分裂点的计算:全局策略和局部策略。
A、全局策略
即在一棵树的生成之前,就已经计算好每个特征的分裂点。在整个树的生成过程当中,用的都是一开始计算的分裂点。这也就代表了使用全局策略的开销更低,但如果分裂点不够多的话,准确率是不够高的。
B、局部策略
根据每一个节点所包含的样本,重新计算其所有特征的分裂点(即边建立树边重新更新分裂点)。
因为在一棵树的分裂的时候,样本会逐渐被划分到不同的结点中(即每个结点所包含的样本,以及这些样本有的特征值是不一样的)。因此,我们可以对每个结点重新计算分裂点,以保证准确性,但这样会使局部策略的开销更大,但分裂点数目不用太多,也能够达到一定的准确率。
(1)在分裂点数目相同,即 ϵ 相同的时候,全局策略的效果比局部策略的效果差;
(2)全局策略可以通过增加分裂点数目,达到逼近局部策略的效果
三、XGBoost对缺失值的处理
对于特征A,我们首先将样本中特征A的特征值为缺失值的样本全部剔除。然后我们正常进行样本划分。
最后,我们做两个假设:一个是缺失值全部归在左子节点;一个是归在右子节点。哪一个得到的增益大,就代表这个特征最好的划分。
Note:对于加权分位法中对于特征值的排序,缺失值不参与(即缺失值不会作为分裂点,gblinear将缺失值视为0)
四、XGBoost的优缺点
1、优点
(1)精度高
XGBoost对损失函数进行了二阶泰勒展开, 一方面为了增加精度, 另一方面也为了能够自定义损失函数,二阶泰勒展开可以近似许多损失函数。(对比只用到一阶泰勒的GBDT)
(2)灵活性强
XGBoost不仅支持CART,还支持线性分类器;
XGBoost还支持自定义损失函数,只要损失函数有一二阶导数。
(3)防止过拟合
A、正则化
XGBoost在目标函数中加入了正则项,用于惩罚过大的模型复杂度,有助于降低模型方差,防止过拟合。
B、Shrinkage(缩减)
主要是为了削弱每棵树的影响,让后面有更大的学习空间,学习过程更加的平缓。
C、列抽样
在建立决策树的时候,不用再遍历所有的特征了,可以进行抽样。
一方面简化了计算,另一方面也有助于降低过拟合。
(4)缺失值处理
(5)并行化操作
有一些不相关可以很好的支持并行计算
2、缺点
时间复杂度和空间复杂度都较高(预排序过程)。
欢迎大家在评论区批评指正,谢谢~
XGBoost详解(原理篇)相关推荐
- MSTP详解- 原理篇
MSTP详解-原理篇 一. MSTP产生背景 二. MSTP基本概念 三.MSTP端口角色 四.MSTP的端口状态与收敛机制 五. MSTP 拓扑计算原理 5.1 MSTP 向量优先级 5.2 CIS ...
- STP和RSTP详解-原理篇
STP和RSTP详解-原理篇 一.STP 1.1 STP基本概念 1.2 STP三个定时器 1.3 STP BPDU报文 1.3.1 配置 BPDU 1.3.2 TCN BPDU 1.3.3 BPDU ...
- Redis五种基本数据类型底层详解(原理篇)
Redis五种基本数据类型底层详解 详细介绍Redis用到的数据结构 简单动态字符串 SDS和C字符串的区别 总结 链表 字典 哈希表 字典 哈希算法 解决键冲突 rehash(重点) 渐进式reha ...
- Docker网络详解——原理篇
前言 当你开始大规模使用Docker时,你会发现需要了解很多关于网络的知识.Docker作为目前最火的轻量级容器技术,有很多令人称道的功能,如Docker的镜像管理.然而,Docker同样有着很多不完 ...
- BERT详解——原理篇(组会PPT,其中大量参考李宏毅的bert课程视频)
- IIS负载均衡-Application Request Route详解第一篇: ARR介绍
IIS负载均衡-Application Request Route详解第一篇: ARR介绍 说到负载均衡,相信大家已经不再陌生了,本系列主要介绍在IIS中可以采用的负载均衡的软件:微软的Appli ...
- IIS负载均衡-Application Request Route详解第二篇:创建与配置Server Farm
自从本系列发布之后,收到了很多的朋友的回复!非常感谢,同时很多朋友问到了一些问题,有些问题是一些比较基本的问题,由于时间的缘故,不会一一的为大家回复,如果有不明白的,希望大家勤自学!本系列虽然不难,但 ...
- IIS负载均衡-Application Request Route详解第二篇:创建与配置Server Farm(转载)
IIS负载均衡-Application Request Route详解第二篇:创建与配置Server Farm 自从本系列发布之后,收到了很多的朋友的回复!非常感谢,同时很多朋友问到了一些问题,有些问 ...
- Linux使用详解(进阶篇)
文章目录 Linux使用详解(进阶篇) 1.Linux目录说明 2.操作防火墙 3.ulimit命令和history命令 4.RPM和Yum的使用 5.设置系统字符集 6.vi & vim编辑 ...
- Openharmony应用NAPI详解--基础篇
NAPI是什么? 简单点理解就是在Openharmony里,实现上层js或ets应用与底层C/C++之间交互的框架. Openharmony里的官方解释:NAPI(Native API)组件是一套对外 ...
最新文章
- Javascript数组常见的方法
- 二维矩阵与二维矩阵之间的卷积
- xshell MySQL表备份_shell mysql数据迁移/备份
- CodeForces - 976F Minimal k-covering
- uat测试用例怎么写_你会写测试用例吗
- STM32F1移植UCOSII
- CHIP-SEQ 芯片分析时,对于来自重复实验的数据,怎样进行MACS peaks calling 分析?
- centOs安装 ruby环境
- html下拉菜单hover,css用hover制作下拉菜单
- OC5028B 内置MOS开关降压型LED恒流驱动器
- 新钛云服冯祯旺:让云管理成为水电一样的基础服务
- c语言fscanf 发生段错误,亚嵌教育
- 纽约大学文理学院转计算机专业,纽约大学文理学院内部转专业 看看你能否转专业...
- binlog实时同步
- maven的使用-很全
- java服装连锁店后台管理系统计算机毕业设计MyBatis+系统+LW文档+源码+调试部署
- 自己更换云平台绑定QQ号的方法
- 少壮不努力,长大搞IT
- 《初级会计电算化实用教程(金蝶KIS专业版)》一1.3 电算化会计信息系统
- 表哥用Python爬取数千条淘宝商品数据后,发现淘宝这些潜规则!