深度学习CTPN+CRNN模型实现图片内文字的定位与识别(OCR)
1:样本获取
**算法论文:** Synthetic Data for Text Localisation in Natural Images Github: https://github.com/ankush-me/SynthText
**词库:** https://pan.baidu.com/s/10anmu + 英文词汇 经过处理后得到大约500兆 6000万词组
**字体:** ubntu系统下支持中文的字体,选了大概10种字体左右
**背景图片库:** http://zeus.robots.ox.ac.uk/textspot/static/db/bg_img.tar.gz 大约有一万张分割好的图片
**算法大致过程:** 随机从背景图片库中选出一张图片,随机从词库中选出一些词组,与背景图片分割
的块进行匹配,选好字体,颜色,大小,变换等信息,将词组写入背景块中,
扣取背景块矩形框作为一个个样本。
**样本类似**
2:网络设计:
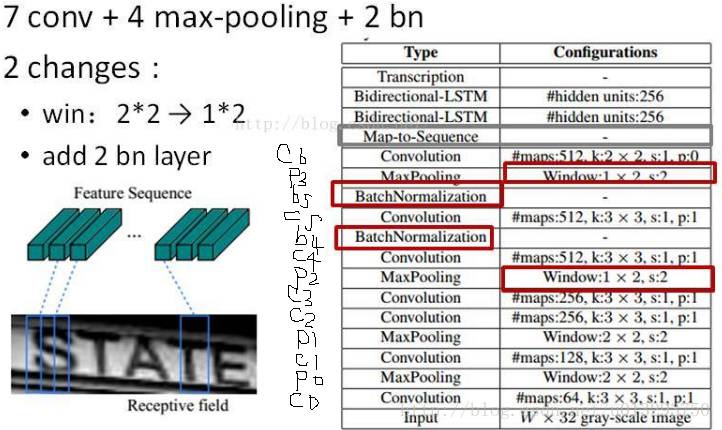
网络:
1:input: 输入文字块,归一化到32*w 即height缩放到32,宽度按高度的比率缩 放,当然,也可以缩放到自己想要的宽度,如128(测试时统一缩放到[32,128],训练时为批次训练,缩放到[32,Wmax])
下面以32*128(w,h)分析
2:conv3层时数据大小为256*8*32,两个pooling层宽高各除以4
3:pooling2层时 步长为(2,1) dilation (1,1)
所以此时输出为256*4*33
4:bn层不改变输出的大小(就是做个归一化,加速训练收敛,个人理解),同样p3层时,w+1,所以pooling3层时,输出为512*2*34
5:conv7层时,kernel 为2*2,stride(1,1) padding(0,0)
Wnew = (2 + 2 * padW - kernel ) / strideW + 1 = 1
Hnew = 33
所以conv7层输出为512*1*33
6: 后面跟两个双向Lstm,隐藏节点都是256
Blstm1输出33*1*256
Blstm2输出33*1*5530 5530 = 字符个数 + 非字符 = 5529 + 1
最终的输出结果直观上可以想象成将128分为33份,每一份对应5530个类别的概率
3:实验结果
自动生成差不多150万个样本,测试集1500张左右,测试集全对率62%左右。因为硬件限制,所以样本较少,感觉样本数量应该要几千万甚至上亿,模型才会比较稳定。150万个样本训练也没收敛,还有2.5左右的cost.
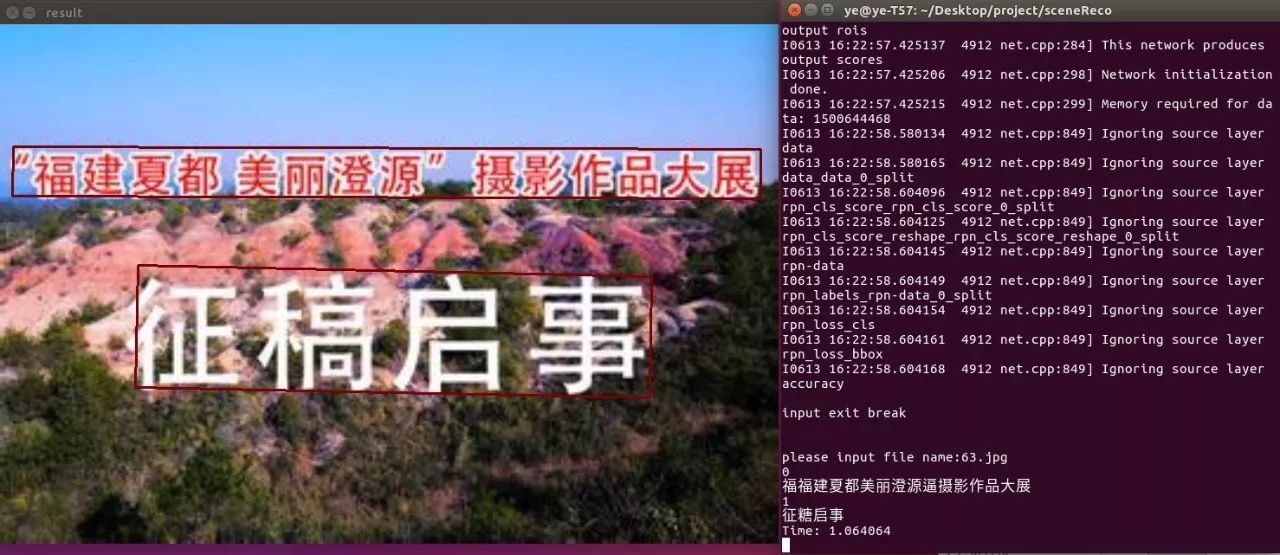
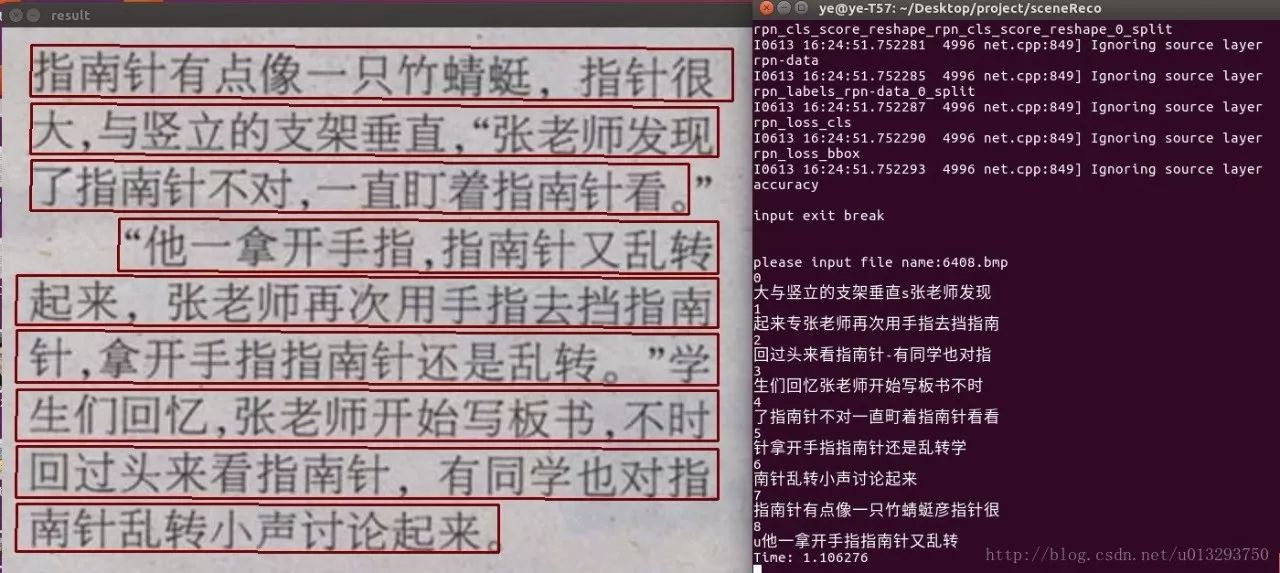
4:CTPN+CRNN整合场景文字检测识别结果
没有进行版面分析,所以识别结果没有按顺序输出
其中标点符号训练集较少,错得较多。整体识别率感觉还行,如果加大训练样本至几千万,上亿,模型应该会比较稳定,识别也会比较好
深度学习CTPN+CRNN模型实现图片内文字的定位与识别(OCR)相关推荐
- Python深度学习之分类模型示例,MNIST数据集手写数字识别
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片. 我们把60000个训练样本分成两部分,前 ...
- 打开深度学习的潘多拉魔盒(模型可视化)
打开深度学习的潘多拉魔盒(模型可视化) - v3.x 深度学习原理与实践(开源图书)-总目录,建议收藏,告别碎片阅读! 深度学习在各个领域攻城略地,在诸多领域秒杀传统算法,但是其运作细节一直是个黑盒. ...
- 基于深度学习的图像识别模型研究综述
基于深度学习的图像识别模型研究综述 摘要:深度学习是机器学习研究中的一个新的领域,其目的在于训练计算机完成自主学习.判断.决策等人类行为并建立.模拟人脑进行分析学习的神经网络,它模仿人类大脑的机制来解 ...
- 1 图片channels_深度学习中各种图像库的图片读取方式
深度学习中各种图像库的图片读取方式总结 在数据预处理过程中,经常需要写python代码搭建深度学习模型,不同的深度学习框架会有不同的读取数据方式(eg:Caffe的python接口默认BGR格式,Te ...
- 深度学习100+经典模型TensorFlow与Pytorch代码实现大合集
关注上方"深度学习技术前沿",选择"星标公众号", 资源干货,第一时间送达! [导读]深度学习在过去十年获得了极大进展,出现很多新的模型,并且伴随TensorF ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大...
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- 深度学习 vs. 概率图模型 vs. 逻辑学
深度学习 vs. 概率图模型 vs. 逻辑学 发表于2015-04-30 21:55|6304次阅读| 来源quantombone|1 条评论| 作者Tomasz Malisiewicz 深度学习de ...
- Python工程能力进阶、数学基础、经典机器学习模型实战、深度学习理论基础和模型调优技巧……胜任机器学习工程师岗位需要学习什么?...
咱不敢谈人工智能时代咋样咋样之类的空话,就我自己来看,只要是个营收超过 5 亿的互联网公司,基本都需要具备机器学习的能力.因为大部分公司盈利模式基本都会围绕搜索.推荐和广告而去. 就比如极客时间,他的 ...
- 从FM推演各深度学习CTR预估模型
本文的PDF版本.代码实现和数据可以在我的github取到. 1.引言 点击率(click-through rate, CTR)是互联网公司进行流量分配的核心依据之一.比如互联网广告平台,为了精细化权 ...
最新文章
- 《OpenCV3编程入门》学习笔记5 Core组件进阶(一)访问图像中的像素
- SpringBoot 中 JPA 的使用
- Meshlab和CloudCompare截图时去除“旋转圈”
- java基础(五) String性质深入解析
- Confluence 6 在升级之前
- Bootstrap的坑--千万别踩
- C++array容器用法解析,它与普通数组究竟有何不同?
- 字段计算器中的功能_Flask实践:计算器
- 【HNOI2006】【BZOJ1192】鬼谷子的钱袋(水题,位运算?)
- MIPS指令集确实够精简,编译文件明显小
- window版本下载安装kafka和ZooKeeper并调试
- nagios监控详解
- 对飞猪H5端API接口sign签名逆向实验
- 计算多项式的小技巧(Horner法则)
- 使用一个SQL查询出每门课程的成绩都大于80分的学生姓名
- JavaScript 实现 HTMLDecode
- token过期后刷新token并重新发起请求
- 为何互联网公司纷纷开始做直播?
- box-shadow实现内部阴影
- 2. C++ Visual Studio中同一个项目包含多个有main函数的源文件怎么分别运行?
热门文章
- Linux小白想成为007,先会用“John the Ripper工具”
- 简单制作一个网页需要注意的
- android平台下OpenGL ES 3.0使用GLSurfaceView对相机Camera预览实时处理
- SQL学习笔记(三): 视图与一些复杂查询(虽复杂但常用)
- 捷报 | 美格智能Cat.1模组SLM332中标中国电信定制版Cat.1模组产品招募
- RecyclerView(一)最简单的recyclerview
- 少年歌行游戏一直显示连接服务器,少年歌行出现第三方登陆失败怎么办 解决方案一览...
- 【转】公司版本控制管理解决方案
- 10道前端面试题(带答案)
- 程序人生:起薪13k,兜兜转转还得是软件测试