《深入理解Hadoop(原书第2版)》——2.3Hadoop系统的组成
本节书摘来自华章计算机《深入理解Hadoop(原书第2版)》一书中的第2章,第2.3节,作者 [美]萨米尔·瓦德卡(Sameer Wadkar),马杜·西德林埃(Madhu Siddalingaiah),杰森·文纳(Jason Venner),译 于博,冯傲风,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.3Hadoop系统的组成
本节内容会细致深入地讲解Hadoop系统的各个组成部分。我们先介绍构成Hadoop 1.x 系统的组件,再介绍构成Hadoop 2.x 系统的新组件。宏观上说,Hadoop 1.x系统有以下几个守护进程:
- 名称节点(NameNode):维护着存储在HDFS上的所有文件的元数据信息。这些元数据信息包括组成文件的数据块信息,及这些数据块在数据节点上的位置。正如你将看到的,这个组件正是使用Hadoop 1.x搭建大型计算集群系统的瓶颈所在。
- 辅助名称节点(Secondary NameNode):这不是名称节点的热备份。实际上,它作为Hadoop平台的一个组件,其命名不是很恰当。它为名称节点组件执行一些内务处理功能(housekeeping functions)。
- 数据节点(DataNode):把真正的数据块存放在本地硬盘上,这些数据块组成了保存在HDFS上的每个文件。
- 作业跟踪器(JobTracker):这是Hadoop系统的主要组件之一,它负责一个任务的整个执行过程。它的具体功能包括:调度各个子任务(Mapper任务和Reducer任务各自的子任务)到各自的计算节点运行,时刻监控任务运行和计算节点的健康状况,对失败的子任务重新调度执行。正如我们即将演示的,就像名称节点一样,这个组件是使用Hadoop 1.x搭建大型计算集群系统的瓶颈所在。
- 任务跟踪器(TaskTracker):运行在各个数据节点上,用来启动和管理各个Map/Reduce任务。与作业跟踪器进行通信。
Hadoop 1.x集群有两种类型的节点:主节点(master nodes)和从节点(slave nodes)。
主节点负责执行如下几个守护进程:
- 名称节点进程
- 辅助名称节点进程
- 作业跟踪器进程
从节点分布在整个集群上并执行如下几个守护进程:
- 数据节点进程
- 任务跟踪器进程
在整个集群上,虽然每种主节点守护进程只有一个运行实例,但是其数据节点进程和任务跟踪器进程有多个运行实例。在一个规模较小的或者用于开发/测试的集群上,三个主节点进程全部运行在一台服务器上。对于生产环境系统或者规模较大的集群,三个主节点进程分别运行在不同的服务器上是明智的选择。
2.3.1Hadoop 分布式文件系统
Hadoop分布式文件系统(HDFS)用于支持数据处理程序要处理的大文件。这样的程序在处理数据的时候,有一次写、多次读的特点。
HDFS文件系统由以下几个守护进程协调地运行来提供服务:
- 名称节点进程
- 辅助名称节点进程
- 数据节点进程
HDFS系统也是主从架构的。运行名称节点进程的服务器为主节点,运行数据节点进程的服务器为从节点。一般情况下,集群中的每个从节点都会运行一个数据节点进程。这个数据节点进程管理着挂载到这个数据节点上的存储设备。HDFS系统提供一个统一的文件系统命名空间,用户就像使用一个文件系统一样来存取集群节点上的数据。名称节点进程负责管理这些存储在集群上的文件的元数据。
- Hadoop文件的本质是块存储
首先,你应该理解集群中文件的物理存储方式。在Hadoop系统中,每个文件被分隔为多个数据块。一个典型的数据块大小为64MB,也可以将其配置为32MB或者128MB。在HDFS中,文件块的大小是按照文件的大小来配置的。如果一个文件的大小不是一个文件块大小的整数倍,空间也不会浪费很多,因为只是最后一个文件块未被完全占满。一个大文件会被分隔为多个数据块来存储。
每个数据块存储在数据节点上。为了防止节点故障,这些数据块是有备份的。在Hadoop系统中,备份数量默认配置为3。具备机架感知功能的Hadoop系统把文件的一个数据块存放在本地机架上的一台计算节点上(假设Hadoop客户端运行在本地机架中的一台数据节点上,否则,Hadoop客户端会随机选择一个机架)。这个数据块的第二个备份会被存放在另外一个远程机架上的计算节点中。这个数据块的第三个备份会被存放在第二个数据块备份机架上的另一台计算节点中。Hadoop系统借助一个单独配置的网络拓扑文件实现机架感知功能,这个网络拓扑文件配置了机架到计算节点的域名系统(DNS)名称之间的映射,该网络拓扑文件的路径配置在Hadoop配置文件中。
许多Hadoop系统会把文件备份因子降为2。运行在EMC 公司的Isilon硬件之上的Hadoop系统就是这样一个例子。这样做的原因是这套硬件系统使用了RAID 5的技术,这个技术本身就内置了数据的冗余备份,从而可以降低Hadoop系统的文件备份因子。降低文件备份因子的一个很明显的好处就是提高了系统I/O性能(少写一个备份)。这个链接中的白皮书讲解了这样的系统架构设计:http://www.emc.com/collateral/software/white-papers/h10528-wp-hadoop-on-isilon.pdf。
为什么不把三个文件数据块的备份分别存放到不同的机架上呢?毕竟,这样做可以增加数据冗余度。这样做的话,抵御机架故障的能力更强,而且还可以增加机架的数据吞吐量。但是,机架故障的概率远低于计算节点故障的概率,而且把数据块备份到不同的机架可导致Hadoop系统写性能的大幅下降。所以,一个折中的方案就是把两个数据块的备份存放在同一个远程机架上的不同计算机点中,以此换取Hadoop系统写性能的提高。这种基于Hadoop系统性能限制的巧妙设计在Hadoop系统中是很常见的。
2.文件元数据和名称节点
当客户端向HDFS请求读取或者存储一个文件的时候,它需要知道要访问的数据节点是哪一个。知道这个信息之后,客户端可以直接访问那个数据节点。文件的元数据信息由名称节点来负责维护。
HDFS系统提供一个统一的文件系统命名空间,用户就像使用一个文件系统一样来存取集群节点上的数据。HDFS把存储在目录中的文件按照一定的层级展示出来,目录是可以嵌套的。所有文件和目录的元数据信息都由名称节点来负责管理。
名称节点管理所有的文件操作,包括文件/目录的打开、关闭、重命名、移动等等。数据节点就负责存储实际的文件数据。这是一个非常重要的区别。当客户点请求或者发送文件数据,文件的数据在物理上是不经过名称节点传输的。否则这将是一个极其严重的瓶颈。客户端仅仅是简单地从名称节点获取文件的元数据,然后根据其元数据信息直接从数据节点获取文件的数据块。
名称节点存储的一些元数据包括:
- 文件/目录名称及相对于其父目录的位置。
- 文件和目录的所有权及权限。
- 各个数据块的文件名。所有数据块以文件的形式存放在数据节点的本地文件系统的目录中,该目录可以被Hadoop系统管理员配置。
需要注意的是名称节点并不存储每个数据块的位置(数据节点的身份信息)。数据节点的身份信息(DataNode identity)在集群启动的时候从每个数据节点获取。名称节点维护的信息是,HDFS上的文件由哪些数据块(数据节点上每个数据块的文件名)组成。
元数据存储在名称节点的本地磁盘上,但是为了快速访问,在集群操作的时候会把这些元信息加载到内存。这个策略对于提高Hadoop系统的操作性能是很关键的,但是同时也成为了Hadoop系统的一个瓶颈,由此催生出了Hadoop 2.x系统。
每个元数据信息大约占用200字节的RAM。假设一个1GB大小的文件,数据块的大小为64MB。这么大的一个文件需要16×3(包括文件备份数量)=48个数据块的存储量。现在假设有1000个文件,每个文件的大小为1MB。这么大的一个文件需要1000×3(包括文件备份数量)=3000 个数据块的存储量(每个文件只需要占用数据块1MB的存储空间即可,但是多个文件不能存储在同一个数据块中)。这样的话,元数据的数据量将会大幅增长。这将会导致名称节点更大量的内存占用。这个例子也解释了为什么Hadoop系统更适合存储大文件,而不适合存储大量的小文件。海量的小文件会轻易地拖垮名称节点服务器。
名称节点服务器上存放元数据的文件为fsimage。Hadoop系统运行期间任何涉及对元数据修改的操作都保存在内存中,并且被持久存储到另外一个名为edits的文件。辅助名称节点会周期性地把edits文件中的信息合并到fsimage文件中。(当我们在讲解辅助名称节点的时候,会深入细致地分析这个合并过程。)保存到HDFS上的实际文件数据并不会存放在fsimage和edits文件中,实际的数据存放在运行着数据节点守护进程的从节点的数据块中。正如前文讲到的,这些数据块以文件的形式存放在集群的从节点中。这些数据块中存放的是文件的原始数据,不存放文件元数据。但是,如果名称节点中保存的元数据丢失了,会导致整个集群不可用。名称节点中的元数据为客户端提供了数据块的信息,这些存放在从节点中的数据块存有文件的真实数据。
数据节点守护进程周期性的发送心跳信息给名称节点。这使得名称节点可以感知所有数据节点的健康状况,从而,客户端的请求不会被发送到故障数据节点。
- HDFS系统写文件的机制
一个HDFS文件系统的写操作涉及文件的创建。从客户端的角度来看,HDFS系统不支持文件的更新。(这样说并不十分准确,因为在HBase中已经使用了HDFS系统的文件追加特性。但是,不建议客户端使用这样的功能。)在下文的讲述中,我们假定HDFS文件系统的默认备份因子为3。
图2-3用图表的形式描述了HDFS文件系统写操作过程,通过这张图表我们对整个操作过程有了一个大致的认识。
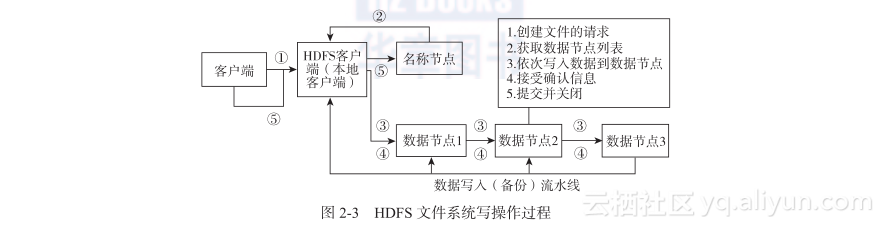
客户端把一个文件写入到HDFS文件系统需要经过以下几个步骤:
1)客户端在联系名称节点之前,会把文件数据流式地读入(streaming the file contents)到客户端本地文件系统中的一个临时文件中。
2)当文件数据的大小达到一个数据块的大小时,客户端就联系名称节点。
3)名称节点会在HDFS文件系统的层级结构中创建一个文件,然后把数据块的标识符和数据节点上的位置信息发送给客户端。这个数据节点数据块信息列表里面还包括了其备份节点的数据块信息列表。
4)进行完上述的步骤之后,客户端就会根据上一步的数据块信息把本地临时文件中的数据刷新(flush)到集群上的数据块中(只写入到第一个数据节点中)。这样,真实的文件数据就放在了集群数据节点本地文件存储系统中。
5)当文件(客户端可以访问的HDFS文件)被关闭时,名称节点会执行一个提交操作,从而使得该文件在集群中为可见状态。如果在提交操作完成之前名称节点挂掉了,这个文件就丢失了。
其中步骤4我们要拿出来详细讲解一下,这个步骤中的刷新操作过程如下:
1)第一个数据节点以数据包(其大小一般为4KB)的形式从客户端接收数据。当这一小部分数据写入到第一个数据节点的本地存储中时,它还会被传送到第二个数据节点中保存。
2)当第二个数据节点开始把数据块写入到本地磁盘时,这个包含文件数据块的数据包会被同时传送到第三个数据节点。
3)最终,这个包含文件数据的数据包写入到第三个数据节点中,此时,这部分的文件数据及其备份就以数据管道的方式存放到HDFS文件系统中。
4)保存包含文件数据的数据包成功之后,其确认包(acknowledgment packet)会从保存了该数据包的计算节点通过数据管道返回给前一个保存了该数据包的计算节点。最后,第一个数据节点会发送确认包到客户端。
5)当客户端接收到了数据块保存成功的确认,数据块就被认为是持久地存储到了集群中的计算节点上。客户端会发送最终的确认信息给名称节点。
6)在数据管道中的任何数据节点发生故障,数据管道就会关闭。文件数据将会被写入其他数据节点。名称节点会感知到文件数据没有备份完成,就会执行重新备份的过程,把数据备份到状态良好的节点,以确保达到要求的文件备份水平。
7)每个数据块都会有一个校验和,这个校验和用来检测数据块的完整性。这些校验和存放在HDFS中另外一个隐藏的文件中,当读取数据块的时候用来校验数据块的完整性。
- HDFS系统读文件的机制
现在我们来讲解如何从HDFS中读取一个文件。图2-4展示了HDFS系统读文件的过程。
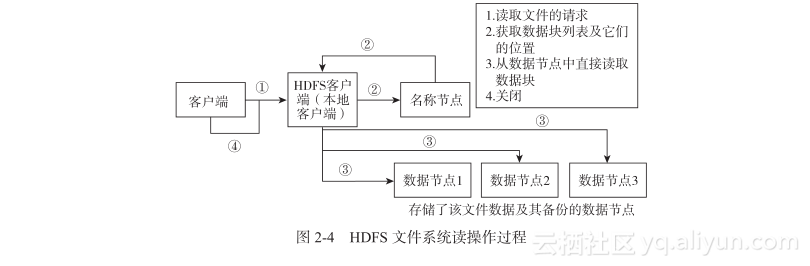
客户端从HDFS中读取文件的步骤为:
1)客户端访问名称节点,名称节点返回组成文件的数据块列表及数据块的位置(包括备份数据块的位置)。
2)客户端会直接访问数据节点以获取数据块中的数据。如果此时其访问的数据节点出现故障,就会访问存放备份数据块的数据节点。
3)读取数据块的时候会计算该数据块的校验和,并将该校验和与写入文件时的校验和作比较。如果检验失败,则从其他数据节点获取备份数据块。
- HDFS系统删除文件的机制
在HDFS系统上删除一个文件,遵从以下步骤:
1)名称节点仅仅重命名了文件路径,使其移动到了/trash目录。需要注意的是,这个操作过程是链接到重命名文件路径的元数据的更新操作。这个执行过程非常迅速。/trash 目录中的文件会保存一段时间,这个保存时间是预先确定的(当前设定为6小时而且当前不可配置)。在这段时间内,把删除的文件从/trash目录中移动出来即可迅速地恢复该文件。
2)当/trash目录中的文件超过了保存时间时,名称节点就会将该文件从HDFS命名空间中删除。
3)删除文件会使得该文件相关的数据块被释放,HDFS系统随后会显示增加了一些空闲空间。
HDFS系统中的文件备份因子是可变的,它可以减小。通过一次心跳信息,这个文件备份因子的变化信息就可以由名称节点发出,数据节点就会动态地从本地存储系统中删除相应的数据块,这样一来,集群就会有更多的空闲存储空间了。所以,名称节点可以动态维护文件的备份数量。
6.确保HDFS系统的可靠性
Hadoop系统和HDFS系统都有很强的抗故障能力。在以下两种情况下会造成数据丢失:
- 数据节点故障:每个数据节点周期性地发送心跳信息到名称节点(默认3秒钟一次)。如果名称节点在预先设定的时间段内没有收到心跳信息,它就会认为数据节点有故障了。此刻,名称节点就会主动地对存储在故障数据节点上的数据块重新备份,把相关数据块(从其他健康节点的备份数据块获取)转移到状态健康的数据节点。这样就可以确保数据块备份数量不变。
- 位腐(bit rot)现象导致的数据损坏:这是指当电荷(在传输过程中)发生衰减而导致的数据丢失的情况。在HDFS系统读取数据块的操作过程中会进行数据校验和核对,这种情况的数据损坏就会被发现。如果数据块的校验失败了,便认为这个数据块已经损坏,就会读取该数据块的备份,然后名称节点会重新备份这个损坏了数据块,使得数据块的备份数量达到预先设定的数据块备份数量。
2.3.2辅助名称节点
现在我们来讨论辅助名称节点在Hadoop系统中的角色。这个组件因为它不合适的名字而导致很多错误的理解。辅助名称节点不是用于进行故障切换的节点。
通过前文,我们知道名称节点在内存中维护着所有的元数据。名称节点最先从存放在本地文件系统中的fsimage文件将元数据加载到内存中。在Hadoop系统中的一系列操作运行过程中,元数据信息在内存中不断更新。为了防止数据丢失,这些数据操作记录还会被持久存储到另外一个名为edits的本地文件中。
fsimage文件并不实际存储各个数据块的位置。这些信息是Hadoop系统在每个数据节点启动的时候,名称节点从每个数据节点获取的,并被存放在名称节点的内存中。
edits文件是用来在Hadoop系统运行期间收集元数据的变化的。如果Hadoop系统重启了,在Hadoop重启的过程中,edits文件中的内容会与fsimage文件中的内容合并。显然,这会拖慢Hadoop系统的重启时间。辅助名称节点就是来处理这个问题的。
辅助名称节点的作用就是周期性地把edits文件中的内容与fsimage文件中的内容合并。为此目的,辅助名称节点会周期性地顺序执行下列步骤:
1)辅助名称节点会请求名称节点来结转(roll over)edits文件,确保新的更新保存到一个新的文件。这个新的文件名字叫做edits.new。
2)辅助名称节点向名称节点请求获取fsimage文件和edits文件。
3)辅助名称节点把edits文件和fsimage文件合并,生成一个新的fsimage文件。
4)名称节点从辅助名称节点接收到新生成的fsimage文件,并替代旧的fsimage文件。同时将edits文件中的内容替换成步骤1中创建的edit.new文件的内容。
5)更新fstime文件来记录发生的检查点操作。
现在应该很清楚为什么名称节点可以导致Hadoop 1.x系统单点故障。如果edits文件和fsimage文件数据损坏了,存放在HDFS系统上的所有数据都会丢失。所以,集群中的数据节点可以是安装了JBOD(不使用RAID技术的数组硬盘)的商用服务器,而名称节点和辅助名称节点必须安装了更为可靠的存储系统(基于RAID技术的存储系统),以确保数据不丢失。前面提到的那两个文件还必须要定期备份。如果这两个文件需要从其备份文件恢复,那么从当前到备份时刻所有的数据操作都会丢失。表2-1总结了HDFS系统中名称节点上的关键文件。

2.3.3任务跟踪器
任务跟踪器(TaskTracker)守护进程在集群中每台计算节点中运行,接收诸如Map、Reduce和Shuffle这些操作任务的请求。每个任务跟踪器都会分配一定的槽位数(a set of slots),其槽位数的数量一般与计算节点上可用的CPU核数一致。任务跟踪器接收到一个(来自作业跟踪器)的请求之后,就会启动一个任务(task),任务跟踪器会为这个任务初始化一个新的JVM。JVM重用是可以的,但这项功能在实际用法示例中并不常见。使用Hadoop 平台的大多数用户都将该功能关闭了。任务跟踪器分配一项任务取决于它的可用槽位(slots)数量(槽位数量=实际运行的任务数量)。任务跟踪器负责向作业跟踪器(JobTracker)发送心跳消息。除了向作业跟踪器反馈任务跟踪器的运行状况之外,心跳信息中还包括了任务跟踪器当前可用的槽位数量。
2.3.4作业跟踪器
作业跟踪器(JobTracker)守护进程负责启动和监控MapReduce作业。当一个客户端向Hadoop系统提交一个作业,作业的启动流程如图2-5所示。

该过程的详细步骤如下:
1)作业跟踪器接收到了作业请求。
2)大多数的MapReduce作业都需要一个或多个输入文件目录。任务跟踪器向名称节点发出请求,获得一个数据节点的列表,这个列表上的数据节点中存储了组成输入文件数据的数据块。
3)作业跟踪器为作业的执行做准备工作。在这个步骤中,任务跟踪器确定执行该作业需要的任务(Map任务和Reduce任务)数量。作业跟踪器尽量把这些任务都调度到离数据块最近的位置上运行。
4)作业跟踪器把任务提交到每个任务跟踪器节点去执行。任务跟踪器节点监控任务执行情况。任务跟踪器以预先设定的时间间隔发送心跳信息到作业跟踪器。如果作业跟踪器在预先设定的时间间隔之后,没有收到任务跟踪器发来的心跳信息,那么就认为该任务跟踪器节点出现故障,任务就会被调度到另外一个节点去运行。
5)一旦所有的任务都执行完毕,作业跟踪器就会更新作业状态为成功。如果任务反复失败达到一定的数量(这个数值可以通过Hadoop系统的配置文件来指定),作业跟踪器就会宣布作业运行失败。
6)客户端会轮询作业跟踪器及时地获得作业运行状态。
到目前为止对Hadoop 1.x系统组件的讲解,可以很清楚地知道,作业跟踪器的故障会导致Hadoop系统的单点故障。如果作业跟踪器节点挂掉,集群上所有的任务都将无法正确运行。同样,由于仅有一个作业跟踪器节点运行,在多任务同时运行的系统环境中,会增加该作业跟踪器节点的工作负载。
《深入理解Hadoop(原书第2版)》——2.3Hadoop系统的组成相关推荐
- 虚拟内存(深入理解计算机系统原书第3版9节读书笔记)
深入理解计算机系统(原书第3版)读书笔记,其实就是嚼碎了原文然后把一部分挑了出来摘要,免得读着读着忘了 文章目录 前言 一.物理和虚拟寻址 二.地址空间 三.虚拟内存作为缓存的工具 1.DRAM缓存的 ...
- Linux设备驱动程序(第三版)/深入理解计算机系统(原书第2版)/[Android系统原理及开发要点详解].(韩超,梁泉)百度云盘下载
文档下载云盘连接:http://pan.baidu.com/s/1dDD2sgT 更多其他资料,请关注淘宝:http://shop115376623.taobao.com/ http://item.t ...
- 深入理解ElasticSearch(原书第2版)
为了方便人们从海量信息中快速检索出内容,搜索引擎应运运出.ElasticSearch是一个款基于apache lucene 的开源搜索引擎,它具有开源,分布式,准实时,restful,便于二次开发等特 ...
- 《深入理解Hadoop(原书第2版)》——1.3大数据的编程模型
本节书摘来自华章计算机<深入理解Hadoop(原书第2版)>一书中的第1章,第1.3节,作者 [美]萨米尔·瓦德卡(Sameer Wadkar),马杜·西德林埃(Madhu Siddali ...
- 《深入理解Hadoop(原书第2版)》——2.6本章小结
本节书摘来自华章计算机<深入理解Hadoop(原书第2版)>一书中的第2章,第2.6节,作者 [美]萨米尔·瓦德卡(Sameer Wadkar),马杜·西德林埃(Madhu Siddali ...
- 《深入理解Elasticsearch(原书第2版)》——第2章 查询DSL进阶 2.1 Apache Lucene默认评分公式解释...
本节书摘来自华章计算机<深入理解Elasticsearch(原书第2版)>一书中的第2章,第2.1节,作者 [美]拉斐尔·酷奇(Rafal Ku)马雷克·罗戈任斯基(Marek Rogoz ...
- 《深入理解Elasticsearch(原书第2版)》——1.4 小结
本节书摘来自华章计算机<深入理解Elasticsearch(原书第2版)>一书中的第1章,第1.4节,作者 [美]拉斐尔·酷奇(Rafal Ku)马雷克·罗戈任斯基(Marek Rogoz ...
- 《深入理解Elasticsearch(原书第2版)》一1.3 在线书店示例
本节书摘来自华章出版社<深入理解Elasticsearch(原书第2版)>一书中的第1章,第1.3节,作者[美]拉斐尔·酷奇(Rafal Ku) 马雷克·罗戈任斯基(Marek Rogoz ...
- 《机器学习与R语言(原书第2版)》一2.3 探索和理解数据
本节书摘来自华章出版社<机器学习与R语言(原书第2版)>一书中的第2章,第2.3节,美] 布雷特·兰茨(Brett Lantz) 著,李洪成 许金炜 李舰 译更多章节内容可以访问云栖社区& ...
最新文章
- CVE-2016-1779技术分析及其背后的故事
- python教程:深copy浅copy
- 推荐搜索炼丹笔记:双塔模型在Airbnb搜索排名中的应用
- javascript 函数和对象 再顺一顺
- Kafka消息格式中的变长字段(Varints)
- 小师妹学JavaIO之:用Selector来发好人卡
- MDK中利用宏定义__DATE__和__TIME__设置产品的代码固件版本
- LINQ to SQL语句(1)之Where
- go项目中使用makefile文件
- JAVA中为什么要用接口定义编程_【Java公开课|为什么要用Java接口,这些内容你一定要搞清楚】- 环球网校...
- 《深入解析IPv6(第3版)》——11.4 流量转换
- 树莓派禁用SD卡上的swap交换空间
- virtualbox安装Windows server 2003
- 学习廖雪峰 Git 总结
- matlab确定物体影子,用MATLAB浅析太阳影子定位问题
- 【Proteus仿真】Arduino UNO +WS2812玩转霓虹灯
- LVDS,接口,时序讲解,非常好的文章
- 敏捷开发-Scrum
- C++网站开发MVC框架TreeFrog Framework教程——7.ERB模板
- 交叉编译ortp、osip2、eXosip2、mediastreamer2及其附带的库实现SIP软电话
热门文章
- ubuntu samba服务器的安装文件,在Ubuntu16.04中搭建samba服务器并用win10连接实现共享文件...
- android wear2.9新功能,Android Wear 2.0确认2月9日正式登场
- 如何用jsp连接mysql_如何用jsp连接mysql数据库
- redhat 添加ssh端口_RHEL 7修改ssh默认端口号
- c语言编程房屋中介系统,房地产经纪人优题库app下载-房地产经纪人优题库app安卓版下载v4.6.0 - 非凡软件站...
- python函数参数定义顺序_Python函数定义-位置参数-返回值
- 电饼锅的样式图片价格_2020年三明治机/电饼铛推荐选购指南,电饼档那个牌子好?有哪些好用的三明治机/早餐机/电饼铛?...
- lede更改软件源_Linux的上传和下载——Ubuntu中软件的安装和ftp服务器的搭建
- .net 获取字符串中的第一个逗号的位置_SQLZOO中做错过的题
- win7php网页显示空白,win7系统ie11打开网页显示空白的解决方法