《深入理解Elasticsearch(原书第2版)》——第2章 查询DSL进阶 2.1 Apache Lucene默认评分公式解释...
本节书摘来自华章计算机《深入理解Elasticsearch(原书第2版)》一书中的第2章,第2.1节,作者 [美]拉斐尔·酷奇(Rafal Ku)马雷克·罗戈任斯基(Marek Rogoziski),张世武 余洪淼 商旦 译,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第2章
查询DSL进阶
在上一章,我们了解了什么是Apache Lucene,它的整体架构,以及文本分析过程是如何完成的。之后,我们还介绍了Lucene的查询语言及其用法。除此之外,我们也讨论了Elasticsearch,讨论了它的架构,以及一些核心概念。在本章,我们将深入研究Elasticsearch的查询DSL(Domain Specific Language)。在了解那些高级查询之前,我们将先了解Lucene评分公式的工作原理。到本章结束,将涵盖以下内容:
- Lucene默认评分公式是如何工作的
- 什么是查询重写
- 什么是查询模板以及如何使用查询模板
- 如何优化复杂的Boolean查询
- 复杂Boolean查询的性能奥秘
- 如何为特定场景选择合适的查询类型
2.1 Apache Lucene默认评分公式解释
评分是Apache Lucene查询处理过程的一个重要环节。评分是指针对给定查询计算某个文档的score属性的过程。什么是文档得分?它是一个刻画文档与查询匹配程度的参数。在本节,我们将了解Apache Lucene的默认评分机制:TF/IDF(词频/逆文档频率)算法以及它是如何影响文档查询结果的。了解评分公式的工作原理对构造复杂查询以及分析查询中因子的重要性都是很有价值的。同时,掌握Lucene评分机制的基础知识有助于我们更好地优化查询来获取符合我们使用场景的结果。
2.1.1 何时文档被匹配上
一个文档被Lucene返回,意味着该文档与用户提交的查询是匹配的。在这种情况下,每个被返回文档会有一个得分。在某些场景下,所有文档的得分都一样(比如使用constant_score查询),不过一般情况下,各个文档的得分是不一样的。得分越高,文档更相关,至少从Apache Lucene及其评分公式的角度来看是这样的。得分还取决于匹配的文档、查询和索引内容,因此,很显然同一个文档对不同查询的得分是不同的。读者需要注意,同一文档在不同查询中的得分不具备可比较性,不同查询返回文档中的最高得分也不具备可比较性。这是因为文档得分依赖多个因子,除了权重和查询本身的结构,还依赖被匹配的词项数目、词项所在字段,以及用于查询规范化的匹配类型,如此等等。在一些比较极端的情况下,同一个文档在相似查询中的得分非常悬殊,仅仅是因为使用了自定义得分查询或者命中词项数的急剧变化。
现在,让我们再回到评分过程。为了计算文档得分,我们需要考虑以下这些因子。
- 文档权重(document boost):索引期赋予某个文档的权重值。
- 字段权重(field boost):查询期赋予某个字段的权重值。
- 协调因子(coord):基于文档中词项个数的协调因子,一个文档命中了查询中的词项越多,得分越高。
- 逆文档频率(inverse document frequency):一个基于词项的因子,用来告诉评分公式该词项有多么罕见。逆文档频率越高,词项就越罕见。评分公式利用该因子,为包含罕见词项的文档加权。
- 长度范数(Length norm):每字段的基于词项个数的归一化因子(在索引期被计算并存储在索引中)。一个字段包含的词项数越多,该因子的权重越低,这意味着Apache Lucene评分公式更“喜欢”包含更少词项的字段。
- 词频(Term frequency):一个基于词项的因子,用来表示一个词项在某个文档中出现了多少次。词频越高,文档得分越高。
- 查询范数(Query norm):一个基于查询的归一化因子,它等于查询中词项的权重平方和。查询范数使不同查询的得分能互相比较,尽管这种比较通常是困难和不可行的。
2.1.2 TF/IDF评分公式
从Lucene 4.0版本起,Lucene引入了多种不同的打分公式,这一点或许你已经有所了解了。不过,我们还是希望在此探索一下默认的TF/IDF打分公式的一些细节。请记住,为了调节查询相关性,你并不需要深入理解这个公式的来龙去脉,但是了解它的工作原理却非常重要,因为这有助于简化相关度调优过程。
1. Lucene的理论评分公式
TF/IDF公式的理论形式如下:
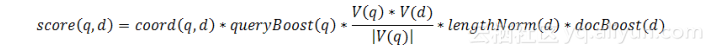
上面的公式融合了布尔检索模型和向量空间检索模型。我们不打算在此讨论理论评分公式,而是直接跳到实践中使用的评分公式,看看Lucene内部是如何实现和使用评分公式的。
关于布尔检索模型和向量空间检索模型的知识远远超出了本书的讨论范围,想了解更多相关知识,请参考http://en.wikipedia.org/wiki/Standard_Boolean_model 和http://en.wikipedia.org/ wiki/Vector_Space_Model。
2. Lucene的实际评分公式
现在让我们看看Lucene实际使用的评分公式:
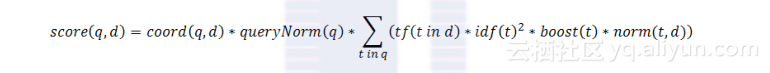
也许你已经看到了,评分公式是一个关于查询q和文档d的函数,正如我们之前提到的一样。有两个因子并不直接依赖查询词项,它们是coord和queryNorm,这两个因子与查询词项的一个求和公式相乘。
求和公式中每个加数由以下因子连乘所得:词频,逆文档频率,词项权重,范数。范数就是之前我们提到过的长度范数。
这个公式听起来很复杂。请别担心,你并不用记住所有的细节,你只需要意识到哪些因素是与评分有关的即可。从前面的公式我们可以导出一些基本的规则:
- 越罕见的词项被匹配上,文档得分越高。Lucene认为包含独特单词的文档比包含常见单词的文档更重要。
- 文档字段越短(包含更少的词项),文档得分越高。通常,Lucene更加重视较短的文档,因为这些短文档更有可能和我们查询的主题高度吻合。
- 权重越高(不论是索引期或是查询期赋予的权重值),文档得分越高。因为更高的权重意味着特定数据(文档、词项、短语等)具有更高的重要性。
正如你所见,Lucene将最高得分赋予同时满足以下条件的文档:包含多个罕见查询词项,词项所在字段较短(该字段索引了较少的词项)。该公式更“喜欢”包含罕见词项的文档。
如果你想了解更多关于Apache Lucene TF/IDF评分公式的信息,请参考Apache lucene 中TFIDFSimilarity类的文档:http://lucene.apache.org/core/4_9_0/core/org/ apache/lucene/search/similarities/TFIDFSimilarity.html.
2.1.3 Elasticsearch如何看评分
总而言之,Elasticsearch使用了Lucene的评分功能,幸运的是Elasticsearch允许我们挑选可用的similarity类实现,或者自定义similarity类,来替换默认的评分算法。不过请记住,Elasticsearch不仅仅是Lucene的简单封装,因为它虽然使用了Lucene的评分功能,但不仅限于Lucene的评分功能。
用户可以使用各种不同的查询类型,以精确控制文档评分的计算。例如使用function_score查询时,可以通过使用脚本(scripting)来改变文档得分,也可以使用Elasticsearch 0.90中出现的二次评分功能,通过在返回文档集之上执行另外一个查询,重新计算top-N文档的得分。
想了解更多Apache Lucene查询类型,请参考http://lucene.apache.org/core/4_9_0/queries/org/apache/lucene/queries/package-summary.html 上的相关文档。
2.1.4 一个例子
现在,我们已经了解评分的工作原理。接下来我们看一个在现实生活中应用评分的简单例子。首先我们需要创建一个名为scoring的新索引。使用如下命令创建这个索引:

简单起见,我们使用了只有一个物理分片和0个副本的索引(我们不需要在这个例子中关心分布式文档频率)。我们需要索引一个简单的文档,代码如下:

接着我们执行一个简单的匹配(match)查询,查询的词项是“document”。

Elasticsearch返回的结果如下:

显然,刚才索引的这个文档被匹配上了,并且被赋予了得分。我们可以通过下面这条命令来查看得分的计算过程:
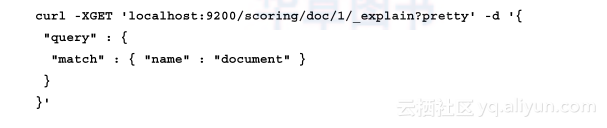
Elasticsearch返回的结果如下:


可以看出,Elasticsearch给出了针对给定文档和查询的详细的得分计算过程。同时可以看出,得分等于词项频率(本例中是1)和逆文档频率(0.30685282)以及字段范数(0.625)的乘积。
现在,我们再把另一个文档加入索引。

此时,如果执行最开始的查询,我们将看到如下响应:


现在,可以对比一下TF/IDF评分公式在现实场景中的工作了。在把第2个文档索引到相同分片后(请记住我们创建的索引只有一个分片且没有副本),得分发生了变化,尽管此时的查询和刚才的一样。这是因为一些影响得分的因子已经改变了。比如,逆文档频率变了,因此得分也会跟着改变。我们还需要注意对比一下两个文档的得分。我们查询了一个单词“document”,查询匹配上了两个文档的相同字段的相同词项。第2个文档的得分为什么较低,是因为和第1个文档相比,它的name字段多了一个词项。根据先前的知识储备,我们知道,文档越短,Lucene给出的得分越高。
希望这个简短的介绍会让你对评分工作机制认识得更清楚,在你需要优化查询时理解目标查询的工作过程。
《深入理解Elasticsearch(原书第2版)》——第2章 查询DSL进阶 2.1 Apache Lucene默认评分公式解释...相关推荐
- 深入理解ElasticSearch(原书第2版)
为了方便人们从海量信息中快速检索出内容,搜索引擎应运运出.ElasticSearch是一个款基于apache lucene 的开源搜索引擎,它具有开源,分布式,准实时,restful,便于二次开发等特 ...
- 虚拟内存(深入理解计算机系统原书第3版9节读书笔记)
深入理解计算机系统(原书第3版)读书笔记,其实就是嚼碎了原文然后把一部分挑了出来摘要,免得读着读着忘了 文章目录 前言 一.物理和虚拟寻址 二.地址空间 三.虚拟内存作为缓存的工具 1.DRAM缓存的 ...
- Linux设备驱动程序(第三版)/深入理解计算机系统(原书第2版)/[Android系统原理及开发要点详解].(韩超,梁泉)百度云盘下载
文档下载云盘连接:http://pan.baidu.com/s/1dDD2sgT 更多其他资料,请关注淘宝:http://shop115376623.taobao.com/ http://item.t ...
- 数据库系统概念原书第六版黑皮书第一章课后习题作业答案
文章目录 1.8列出文件处理系统和DBMS之间的四个显著区别. 1.9 解释物理数据独立性的概念,以及它在数据库系统中的重要性. 1.10 列出数据库管理系统的五个职责.对每个职责,说明当它不能被履行 ...
- java第十版基础篇答案第九章_《Java语言程序设计》(基础篇原书第10版)第九章复习题答案...
第九章 9.1:类为对象定义属性和行为,对象从类创建. 9.2:public class ClassName { } 9.3:ClassName v; 9.4:new ClassName(); 9.5 ...
- 《深入理解Elasticsearch(原书第2版)》——第1章 Elasticsearch简介
2019独角兽企业重金招聘Python工程师标准>>> 第1章 Elasticsearch简介 摘要: 欢迎来到Elasticsearch的世界并阅读本书第2版.通过阅读本书,我们 ...
- 《渗透测试实践指南 必知必会的工具与方法 (原书第2版)》读书摘录
----------------------------------------------------------------------------分割线--------------------- ...
- 《深入理解Elasticsearch(原书第2版)》——1.4 小结
本节书摘来自华章计算机<深入理解Elasticsearch(原书第2版)>一书中的第1章,第1.4节,作者 [美]拉斐尔·酷奇(Rafal Ku)马雷克·罗戈任斯基(Marek Rogoz ...
- 《深入理解Elasticsearch(原书第2版)》一1.3 在线书店示例
本节书摘来自华章出版社<深入理解Elasticsearch(原书第2版)>一书中的第1章,第1.3节,作者[美]拉斐尔·酷奇(Rafal Ku) 马雷克·罗戈任斯基(Marek Rogoz ...
最新文章
- html android canvas兼容_快来!这里有5分钟看完马上学会的HTML基础大全
- EXTJS布局示例(panel,Viewport,TabPanel)
- C#如何安全、高效地玩转任何种类的内存之Span的本质(一)。
- 前端学习(2532):Vuex中action
- puppy linux中文设置,Puppy Linux 中文支持包制作方法
- 2017.5.9 积木大赛 思考记录
- python 列表推导
- 在linux里flash自动转图片
- 基于分割和识别的服饰商品的自动推荐
- RocketMQ 实战-SpringBoot整合RocketMQ
- 【滤波器】基于matlab低通滤波器(LPF)设计【含Matlab源码 323期】
- c++代码打印爱心图(适用初学者)
- Amesim更改为中文
- 《Efficient Android Threading》Chapter 3---Threads on Android (Android中的线程)
- 企业支付宝账号注册认证流程
- 部队室内靶场有哪些硬件设备和强制性存在的系统
- 在线时钟html5,HTML5应用之时钟
- 计算机科学导论任务书,计算机科学导论论文提纲格式范文 计算机科学导论论文提纲如何写...
- 谷歌及360浏览器插件制作
- 计算机储存容量5mb,笔记本电脑的硬盘上 8455MB(CYL 16383,H16,S63) 640GB (LBA 1,250,263,728Sectors) 分别表示什么意思?...
热门文章
- [LeetCode]Merge Sorted Array
- LeetCode:Spiral Matrix I II
- Linux-6.5下 MariaDB-10基于percona-XtraBackup备份工具的原理及配置详解
- spring读取配置文件初始化容器操作总结
- [转贴]电阻电容的封装形式如何选择
- mysql 二级什么意思_MySQL二级等级考试归纳——PHP篇
- ctf 文件头crc错误_[CTF隐写]png中CRC检验错误的分析
- oracle rpad mysql_Oracle生成不重复票号与LPAD,RPAD与NEXTVAL函数解析
- 飞线5根连接图_“飞线”和“跳线”有什么区别,你用对了吗?电路故障的排查方法...
- 简单介绍oracle重置序列的方法