多层线性模型和面板数据模型笔记(待完善,持续更)
多层线性模型和面板数据模型笔记(待完善,持续更)
申明:部分内容参考网上优秀的热衷分享的作者,此篇文章仅作个人学习的综合整理,侵权自觉删掉。
引用的文章观点主要来自:
知乎:统计学中的「固定效应 vs. 随机效应」
连享会:Stata: 面板数据模型一文读懂
一、多层线性模型Hierarchical Linear Model
1 传统回归分析模型
Yi=β0+β1Xi+εiY_i=\beta_0+\beta_1X_i+\varepsilon_iYi=β0+β1Xi+εi
其中εi∼N(0,σ2)\varepsilon_i \sim N(0,\sigma^2)εi∼N(0,σ2)
基本假设-来源于伍德里奇教材P129:
线性于参数,随机抽样,不存在完全共线性,误差条件均值为零,误差同方差性,误差正态分布
2 多层数据
多层数据是指观测数据在单位上具有嵌套关系。
比如,学生嵌套于学校。
同一单位内的观测,具有更大相似性。
比如,同一学校的学生比其他学校的学生更具有相似性。
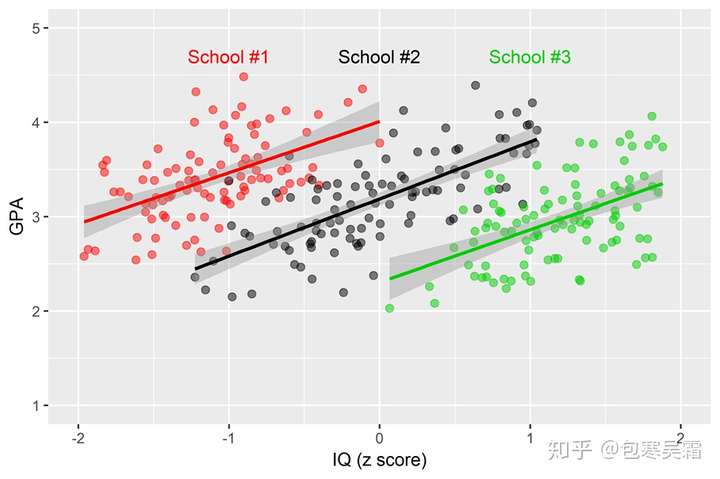
假设现在要考察学校教学设备对学生成绩的影响,在20所学校抽取1000名学生,那么可能有的学校为贵族学校,因此学生家长经济水平较高,可以缴纳更多设备费用,而另外的平民学校则负担不了额外的设备费用,因此,学生成绩受学校的教学设备影响,而学校设备又受学校整体经济水平影响。
![]()
![]()
多层数据违背了传统回归分析模型的残差相互独立假设,导致其得到的标准误估计不正确(太小)。
假如对个体水平上进行分析,比如每个学生,则假设同一班级的学生间相互独立,是不合理的。
加入对单位水平上进行分析,不如不同班级间的比较,则会丢失班级内学生个体间的差异的信息。
独立性不满足会带来标准误估计偏小从而导致犯第一类错误的概率偏大。
3 处理方式:建立HLM模型
将Yij=β0+β1Xij+εijY_ij=\beta_0+\beta_1X_{ij}+\varepsilon_{ij}Yij=β0+β1Xij+εij 改写成 Yij=β0+β1Xij+uj+rijY_{ij}=\beta_0+\beta_1X_{ij}+u_j+r_{ij}Yij=β0+β1Xij+uj+rij
其中 uju_juj ,定义的是第 j 组的残差项,解释的是总截距和第 j 组的截距之间的差异
而 rijr_{ij}rij 定义的是第 j 组第 i 个观测的残差项
特点:
HLM会把多层嵌套结构数据在因变量上的总方差进行分解:
总方差 = 组内方差(Level 1)+ 组间方差(Level 2)
Var(εij)=Var(uj)+Var(rij)Var(\varepsilon_{ij})=Var(u_j)+Var(r_{ij})Var(εij)=Var(uj)+Var(rij)
X 和 Y 之间的关系不依赖于 j (β1\beta_1β1不依赖于 j)
模型的另一种表达:
KaTeX parse error: No such environment: equation at position 8: \begin{̲e̲q̲u̲a̲t̲i̲o̲n̲}̲ \begin{split} …
现在用两个水平分析模型:
水平1即Level 1(如学生,组内的个体):
Yij=β0j+β1jXij+εijY_{ij}=\beta_{0j}+\beta_{1j}X_{ij}+\varepsilon_{ij}Yij=β0j+β1jXij+εij
学生成绩=β0+β1∗学校设备建设程度+rij学生成绩=\beta_0+\beta_1*学校设备建设程度+r_{ij}学生成绩=β0+β1∗学校设备建设程度+rij
水平2即Level 2(如学校,不同的单位):
β0j=γ00+γ01W1j+u0j\beta_{0j}=\gamma_{00}+\gamma_{01}W_{1j}+u_{0j}β0j=γ00+γ01W1j+u0j
β1j=γ10+γ11W1j+u0j\beta_{1j}=\gamma_{10}+\gamma_{11}W_{1j}+u_{0j}β1j=γ10+γ11W1j+u0j
γ00\gamma_{00}γ00和γ10\gamma_{10}γ10表示截距和斜率的整体均值,用来描述总体情况的变化趋势。
β0j=γ00+γ01学校整体经济水平+u0j\beta_{0j}=\gamma_{00}+\gamma_{01}学校整体经济水平+u_{0j}β0j=γ00+γ01学校整体经济水平+u0j
β1j=γ10+γ11学校整体经济水平+u0j\beta_{1j}=\gamma_{10}+\gamma_{11}学校整体经济水平+u_{0j}β1j=γ10+γ11学校整体经济水平+u0j
包寒吴霜-知乎用户:我们还可以引入学校水平的自变量来对学校间的GPA均值差异进行解释,比如教师数量、教学经费……这些变量由于只在学校层面变化,对于每个学校内的每一个学生而言都只有一种可能的取值,因此必须放在Level 2的方程中作为群体水平自变量,而不能简单地处理为个体水平自变量——这也就是HLM的另一个存在的意义:可以同时纳入分析个体与群体水平的自变量。
在充分理解了HLM的原理之后再去理解其他统计方法就会比较轻松,尤其是在理解固定效应FE和随机效应RE这件事情上。但在HLM的话语体系中,我们不太直接说FE和RE,因为这两个词对于HLM而言太过于笼统
| 固定截距(fixed intercept) | 随机截距(random intercept) | 固定斜率(fixed slope) | 随机斜率(random slope) |
|---|---|---|---|
| HLM中不存在,同理,面板数据模型中也不存在 | HLM中常用 | 斜率在不同组内是相同的 | 斜率在不同组内是不同的 |

4 对固定效应和随机效应的理解
在HLM的框架下探讨固定效应还是随机效应,更多的是指**「斜率」为固定还是随机**。
二、面板数据Panel Data Model
1 面板数据基本定义
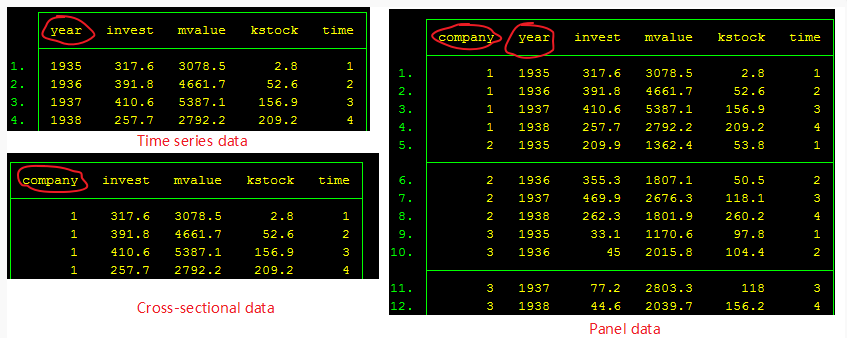
面板数据可以理解为由时间维度和横截面维度组成的数据。
在经济学里,可以是研究不同省份在不同年份的经济增长受创新投入的影响。
司马懿-知乎用户:面板数据和横断面数据的区别就在于,面板数据多了一个时间的维度。也就是说,一个人的数据不但能够横向的和同一时间的其他人相比,也能够纵向的和之前之后的自己相比。
如果把一个人在不同时间的数据称为一组数据的话,那么前者称为组间差异,后者称为组内差异。
面板数据的优点是既可以考虑到横截面数据存在的共性,也可以分析模型中横截面因素的个体特殊效应。

郭凯明-连享会:欲研究影响企业利润的决定因素,我们认为企业规模 (截面维度)和技术进步(时间维度)是两个重要的因素。
截面数据仅能研究企业规模对企业利润的影响程度,时间序列数据仅能研究技术进步对企业利润的影响。
2 最简单的面板数据模型介绍
(1)符号含义规范
yity_{it}yit——因变量在横截面 i 和时间 t 上的数值
xitjx_{it}^jxitj——第 j 个解释变量在横截面 i 和时间 t 上的数值
为方便讨论,一般假设有 K 个解释变量,N个横截面,T个时间指标
记第 i 个横截面的数据
yi=[yi1yi2⋮yiT]T×1\boldsymbol y_i= \begin{bmatrix} y_{i1} \\ y_{i2} \\ \vdots \\ y_{iT} \end{bmatrix}_{T×1}yi=⎣⎢⎢⎢⎡yi1yi2⋮yiT⎦⎥⎥⎥⎤T×1 Xi=[Xi11Xi22⋯X1kKXi21Xi22⋯X2kK⋮⋮⋮⋮XiT1XiT2⋯XiTK]T×K\boldsymbol X_i= \begin{bmatrix} X_{i1}^1 &X_{i2}^2 & \cdots &X_{1k} ^K \\ X_{i2}^1 &X_{i2}^2 & \cdots &X_{2k}^K \\ \vdots & \vdots &\vdots & &\vdots \\ X_{iT}^1 &X_{iT}^2 & \cdots &X_{iT}^K \end{bmatrix}_{T×K}Xi=⎣⎢⎢⎢⎡Xi11Xi21⋮XiT1Xi22Xi22⋮XiT2⋯⋯⋮⋯X1kKX2kKXiTK⋮⎦⎥⎥⎥⎤T×K μi=[μi1μi2⋮μiT]T×1\boldsymbol \mu_i= \begin{bmatrix} \mu_{i1} \\ \mu_{i2} \\ \vdots \\ \mu_{iT} \end{bmatrix}_{T×1}μi=⎣⎢⎢⎢⎡μi1μi2⋮μiT⎦⎥⎥⎥⎤T×1
再记
y=[y1y2⋮yN]N⋅T×1\boldsymbol y= \begin{bmatrix} \boldsymbol y_{1} \\ \boldsymbol y_{2} \\ \vdots \\ \boldsymbol y_{N} \end{bmatrix}_{N·T×1}y=⎣⎢⎢⎢⎡y1y2⋮yN⎦⎥⎥⎥⎤N⋅T×1 X=[X1X2⋮XN]N⋅T×K\boldsymbol X= \begin{bmatrix} \boldsymbol X_{1} \\ \boldsymbol X_{2} \\ \vdots \\ \boldsymbol X_{N} \end{bmatrix}_{N·T×K}X=⎣⎢⎢⎢⎡X1X2⋮XN⎦⎥⎥⎥⎤N⋅T×K μ=[μ1μ2⋮μN]N⋅T×1\boldsymbol \mu= \begin{bmatrix} \boldsymbol \mu_{1} \\ \boldsymbol \mu_{2} \\ \vdots \\ \boldsymbol \mu_{N} \end{bmatrix}_{N·T×1}μ=⎣⎢⎢⎢⎡μ1μ2⋮μN⎦⎥⎥⎥⎤N⋅T×1 β=[β1β2⋮βK]K×1\boldsymbol \beta= \begin{bmatrix} \beta_{1} \\ \beta_{2} \\ \vdots \\ \beta_{K} \end{bmatrix}_{K×1}β=⎣⎢⎢⎢⎡β1β2⋮βK⎦⎥⎥⎥⎤K×1
(2)建立简单面板数据模型
建立以下用矩阵形式表达的面板数据模型:
y=Xβ+μ\boldsymbol y=\boldsymbol X \boldsymbol \beta+ \boldsymbol \mu y=Xβ+μ
基于这个模型,对系数 β\boldsymbol \betaβ 和随机误差项 μ\boldsymbol \muμ 进行不同假设,可以衍生出不同的面板数据模型。
(3)对误差项μit\boldsymbol \mu_{it}μit 的拆分
为了分析每个个体的特殊效应,可对μit\boldsymbol \mu_{it}μit 设定:
μit=αi+εit\boldsymbol \mu_{it}=\boldsymbol \alpha_i+\boldsymbol \varepsilon_{it}μit=αi+εit
αi\boldsymbol \alpha_iαi 代表第 i 个个体的特殊效应,反映了不同个体之间的差别。
郭凯明-连享会:αi\boldsymbol \alpha_iαi 不随时间改变,如个人的消费习惯、企业文化和经营风格等
个人理解:这里讨论的个体应该是以横截面为个体。研究不同省份在不同年份的经济增长受创新投入的影响中,不同的省份就是不同的个体。
再如要研究影响一个人工资的因素,除了学历、工作经验年数外,还有不可测的变量如关系和能力,这些都是一些个人的异质性因素,即αi\boldsymbol \alpha_iαi
如果αi\boldsymbol \alpha_iαi和Xit\boldsymbol X_{it}Xit 相关,即corr(αi,Xit)≠0corr(\boldsymbol \alpha_i,\boldsymbol X_{it})\ne 0corr(αi,Xit)=0,则该模型为固定效应模型。若二者不相关,那就是随机效应模型。
郭凯明-连享会:固定效应模型假设个体效应在组内是固定不变的,个体间的差异反映在每个个体都有一个特定的截距项上; 随机效应模型则假设所有的个体具有相同的截距项, 个体间的差异是随机的,这些差异主要反应在随机干扰项的设定上。
| 固定效应分类 | 说明 | |
|---|---|---|
| 个体固定 | 对于不同的时间序列(个体)只有截距项不同的模型:从时间和个体上看,面板数据回归模型的解释变量对被解释变量的边际影响均是相同的,而目除模型的解释变量之外,影响被解释变量的其他所有(未包括在回归模型或不可观测的)确定性变量的效应只是随个体变化而不随时间变化。 | |
| 时间固定 | 时点固定效应模型就是对于不同的截面(时点)有不同截距的模型。如果确知对于不同的截面,模型的截距显著不同,但是对于不同的时间序列(个体)截距是相同的,那么应该建立时点固定效应摸型: | |
| 双固定 | 时点个体固定效应模型就是对于不同的截面(时点)、不同的时间序列(个体)都有不同截距的模型。如果确知对于不同的截面、不同的时间序列(个体)模型的截距都显著不相同,那么应该建立时点个体固定效应模型 |
3 固定效应模型
(1)假设
固定模型中假定
μit=αi+εit\boldsymbol \mu_{it}=\boldsymbol \alpha_i+\boldsymbol \varepsilon_{it}μit=αi+εit 的αi\boldsymbol \alpha_iαi 对每一个个体是固定的常数。
注:α1\alpha_1α1,α2\alpha_2α2,`···,αN\alpha_NαN是不全相等的。
郭凯明-连享会:当对所有的 i , αi\boldsymbol \alpha_iαi 均相等时,模型退化为混合数据模型 ( Pooled OLS )。
(2)检验方法
Hausman检验——H0:αi与Xit不相关H_0:\alpha_i与X_{it}不相关H0:αi与Xit不相关
若有证据拒绝此零假设,则可以判断出该模型需要采用固定效应模型。
4 问题集
问题1:
您好,请问一下面板数据回归时候加时间效应与不加时间效应,核心解释变量符号不一样,是怎么回事?
回答1:
面板数据模型中,控制时间效应后,此时的估计系数是排除了随时间变化的影响因素后的结果。相对来说,此时的结果更为可信。
问题2:
请问一下面板数据回归一定要加时间效应吗?不加可以吗?
谢谢老师
回答2:
个人建议,采用面板数据时,最好控制时间固定效应。当然这个也不是绝对的,我也看到有文献提供的代码里,并没有加时间固定效应。个人的理解,关键还是看你的被解释变量是否随时间变化,比如经济增长速度、产业结构系数等,在中国现阶段的情况下,这些变量一般是随着时间变化的,建议加上时间固定效应;如果你的被解释变量基本不随时间变化,我个人觉得这种情况下,加上时间固定效应与否,对你的结果影响都不大。
问题3:
面板不是还有个随机效应嘛?
回答3:
我只能说,你是看过书的人,所以才知道随机效应。其实随机效应压根就没什么用处。有人信誓旦旦说可以用hausman来检验。我只能告诉你,这检验压根就不可靠。可靠也是理论上可靠,实践上根本没人信。
最权威的建议就是:当你无法判断该用固定效应还是随机效应的时候,选择固定效应更可靠。随机效应不是任何时候都可以做,但是固定效应是任何时候都可以做。所以你知道该怎么做了吧。
4 stata操作
目前Stata已有许多相关面板数据模型命令,包括(不限于):
- `xtreg` :普通面板数据模型,包括固定效应与随机效应
- `xtabond/xtdpdsys/xtabond2/xtdpdqml/xtlsdvc`:动态面板数据模型
- `spxtregress/xsmle`: 空间面板数据模型
- `xthreg`:面板门限模型
- `xtqreg/qregpd/xtrifreg`: 面板分位数模型
- `xtunitroot`: 面板单位根检验
- `xtcointtest/ xtpedroni/xtwest`: 面板协整检验
- `sfpanel`: 面板随机前沿模型
- `xtpmg/xtmg`:非平稳异质面板模型
备注
自由度
(degree of freedom,缩写为df)
可以简单地理解为可以独立变化的数据量。
计算公式是:df=总变量数−衍生量数df=总变量数-衍生量数df=总变量数−衍生量数
具体以例子理解。
在 a+b=6a+b=6a+b=6中,df=1,因为只有一个数据量 a 可自由变化,b 会受 a 的选值所限制。df=2−1=1df=2-1=1df=2−1=1
估计总体的平均数,所用统计量为样本平均数μ\muμ,当样本总量为n,由于相对样本平均值无其他衍生量,因此df=1df=1df=1。但是如果估计总体方差,所用统计量是样本方差s2s^2s2, 需要用到样本平均数μ\muμ,相对样本方差只有一个衍生量,因此df=n−1df=n-1df=n−1。
在t检验中,t=β^SEt=\frac{\hat\beta}{SE}t=SEβ^,假设样本总量为n,同时相对t统计量需要两个衍生量β^\hat\betaβ^和SESESE,所以
多层线性模型和面板数据模型笔记(待完善,持续更)相关推荐
- 决胜b端产品经理学习笔记01(持续更新版)
决胜b端-初识b端产品 什么是b端产品 b端产品,适用对象是企业或组织,用来解决企业某类经营管理问题. 1.核心价值:规模(提升收入).成本(降低成本).效率(提高效率).品质(保证品质).风控 好的 ...
- 空间计量模型_Stata空间面板数据模型专题直播丨Stata空间计量3月远程直播
2月28日19:00-21:00Stata空间计量直播专题课(空间面板数据模型)提供全套资料及课后Q&A 空间面板数据模型的前生今世:静态.动态和具有共同因子约束的空间面板数据模型. 模型选择 ...
- STATA面板数据模型进行Hausman检验
STATA面板数据模型进行Hausman检验 1.导入数据 可以通过如下多种方式导入 1.1 可以通过点击stata软件的图标,输入数据 1.2 通过点击文件->导入 可以导入各种文本格式的数据 ...
- 使用SAS,Stata,HLM,R,SPSS和Mplus的多层线性模型HLM
简介 最近我们被客户要求撰写关于多层线性模型的研究报告,包括一些图形和统计输出.本文档用于比较六个不同统计软件程序(SAS,Stata,HLM,R,SPSS和Mplus)的两级多层(也称分层或层次)线 ...
- 多层高速PCB设计学习笔记(二)基本设计原则及EMC分析
系列文章目录 多层高速PCB设计学习(一)初探基本知识(附单层设计补充) 多层高速PCB设计学习笔记(二)基本设计原则及EMC分析 多层高速PCB设计学习笔记(三) GND的种类及PCB中GND布线实 ...
- 多层高速PCB设计学习笔记(五)四层板实战(下)之阻抗控制计算(SI9000)
系列文章目录 多层高速PCB设计学习(一)初探基本知识(附单层设计补充) 多层高速PCB设计学习笔记(二)基本设计原则及EMC分析 多层高速PCB设计学习笔记(三) GND的种类及PCB中GND布线实 ...
- 多层高速PCB设计学习笔记(三) GND的种类及PCB中GND布线实战
系列文章目录 多层高速PCB设计学习(一)初探基本知识(附单层设计补充) 多层高速PCB设计学习笔记(二)基本设计原则及EMC分析 多层高速PCB设计学习笔记(三) GND的种类及PCB中GND布线实 ...
- 1.面板数据模型理论--变截距面板数据模型
变截距面板数据模型 变截距面板数据模型理论介绍 混合效应模型 背景思想 回归公式可以忽略个体与时间变化的差异,因此所有的数据特征可以通过一个公式进行刻画.进行数据的大杂烩.乱炖.为什么采取这么直接粗暴 ...
- Stata:动态面板数据模型与xtabond2应用
全文阅读:Stata:动态面板数据模型与xtabond2应用| 连享会主页 目录 1. Nickell 偏差 2. 动态面板估计方法 3. 实证案例 4. 参考资料 5. 相关推文 为了处理内生性 ...
- 多层高速PCB设计学习笔记(四)四层板实战(上)之常见模块要求
系列文章目录 多层高速PCB设计学习(一)初探基本知识(附单层设计补充) 多层高速PCB设计学习笔记(二)基本设计原则及EMC分析 多层高速PCB设计学习笔记(三) GND的种类及PCB中GND布线实 ...
最新文章
- IP Header包
- Python2+Selenium入门03-元素定位
- 不安全网络中的数据安全传输利器——GnuPG(下)
- Set OPENCV_ENABLE_NONFREE CMake option and rebuild the library in function解决方法
- 前端学习(3049):vue+element今日头条管理-请求获取数据
- c语言如何把变量按位颠倒,求答案,用C语言编程,用户输入一个正整数,把他的各位数字前后颠倒,并输入点到后的结果...
- 神奇的“const”
- 外媒:美国降雪引发事故 2天内造成3人死亡2人受伤
- ios添加全局悬浮按钮_MIUI10快报:全局透明壁纸上线,本地视频支持设为锁屏壁纸...
- 五、移动端技术解决方案
- 阵列win不识别linux识别,解决Raid模式下重装系统无法识别固态硬盘的问题
- 各种笔记本进入BIOS的快捷键
- tds3014 自动测试软件,TDS3014 Tektronix TDS3014C
- 一锁知千秋,再和腾讯大佬的技术对话,我还是小看锁了!面试加分的答案都已安排
- python分块处理功能_Python自然语言处理学习笔记之信息提取步骤分块(chunking)...
- Pinia(小菠萝)使用方法
- 学姐的大厂面试总结,想进大厂的必看!!!
- 非线性规划(凸规划,无约束最优化方法,约束最优化方法)
- Windows Server网络操作系统安装
- 华为折叠x2是鸿蒙系统吗,华为mateX2发布,鸿蒙系统四月上线,matex2首批搭载。...