hazelcast配置内存_在内存数据网格中引入hazelcast imdg
hazelcast配置内存
Today’s article will be oriented to a very specific concept, which is the In-Memory Data Grid or IMDG, discussing all the ideas introduced by this one.
今天的文章将针对一个非常具体的概念,即内存数据网格或IMDG,讨论该概念引入的所有想法。
IMDG is a general or abstract concept, which describes a way to leverage some kind of distributed system for storing data and performing in-memory computations on stored data.
IMDG是一个通用或抽象的概念,它描述了一种利用某种分布式系统来存储数据并对存储的数据执行内存中计算的方法。
Being an abstract construction, we will dive into a concrete implementation of the concept, looking specifically at Hazelcast In-Memory Data Grid.
作为抽象结构,我们将深入研究该概念的具体实现,特别是针对Hazelcast In-Memory Data Grid 。
What is an In-Memory Data Grid (IMDG)?
什么是内存中数据网格(IMDG)?
First of all, let’s introduce the concept of Data Grid. A Data Grid is a system of multiple servers that work together to manage information and related operations in a distributed environment.
首先,让我们介绍数据网格的概念。 数据网格是由多个服务器组成的系统,这些服务器协同工作以管理分布式环境中的信息和相关操作。
The servers from the grid can be located in the same location or distributed across multiple data centers.
网格中的服务器可以位于同一位置,也可以分布在多个数据中心中。
An In-Memory Data Grid is a grid that stores data entirely into Random Access Memory (RAM).
内存中数据网格是将数据完全存储到随机存取存储器(RAM)中的网格。
The visual representation of how a Data Grid looks like can be seen below.
可以在下面看到数据网格外观的直观表示。
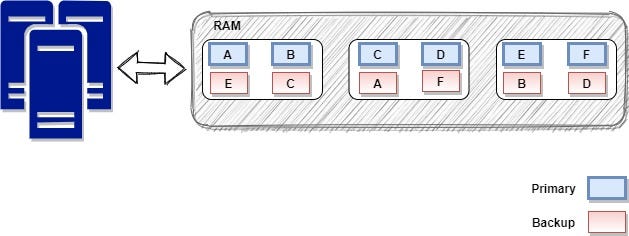
We can see that data is distributed across the entire cluster in such a way that the load and the capacity are balanced across all nodes in the grid. Also, the data is stored in multiple copies on different nodes. This will offer automatic resilience in case of single or multiple server failures.
我们可以看到,数据以这样的方式分布在整个群集中,即负载和容量在网格中的所有节点之间得到平衡。 同样,数据存储在不同节点上的多个副本中。 如果单台或多台服务器发生故障,这将提供自动恢复能力。
If we need to scale the grid, which means that we need more capacity, we can just add more servers to the grid. The IMDG will redistribute data to even out the load across all available nodes. The same process works in reverse if one or multiple servers becomes unavailable. In such a case, some backups stored on running nodes will be promoted as primaries.
如果我们需要扩展网格,这意味着我们需要更多的容量,我们可以向网格中添加更多的服务器。 IMDG将重新分配数据,以平衡所有可用节点上的负载。 如果一个或多个服务器不可用,则相同的过程相反。 在这种情况下,某些存储在运行节点上的备份将被升级为主数据库。
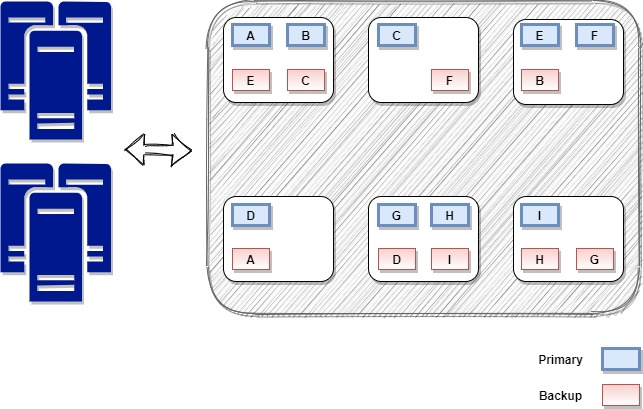
The above-described scenario can be viewed in the below diagram. We can see how adding three more servers to our data grid, the load was redistributed to all the members in the cluster.
可以在下图中查看上述场景。 我们可以看到如何在数据网格中再添加三台服务器,并将负载重新分配给集群中的所有成员。
Why to use an In-Memory Data Grid?
为什么要使用内存数据网格?
There is more than one reason for using an IMDG. In the following, I will enumerate only a few of them.
使用IMDG的原因不只一种。 在下文中,我将仅列举其中一些。
Performance increase: we have seen what is the real cost of latency. One of the best advantages of an In-Memory Data Grid is the increase in the entire system performance.
性能提升:我们已经看到了延迟的真正成本是多少。 内存中数据网格的最大优点之一就是可以提高整个系统的性能。
Moving all the data from external data sources into memory will increase the performance of the entire system. In this way, we will avoid all the database read or write operations and replace them with reading and writing data from memory, which can be up to 1000 times faster.
将所有数据从外部数据源移到内存中将提高整个系统的性能。 这样,我们将避免所有数据库的读或写操作,而将它们替换为从内存中读取和写入数据,这可以快1000倍。
Data structure: the data structure itself is a simple key-value store, rather than a complex relational model. This simple structure is easy for developers to work with, while still providing all the ACID transactional properties.
数据结构:数据结构本身是简单的键值存储,而不是复杂的关系模型。 这种简单的结构使开发人员易于使用,同时仍提供所有ACID事务属性。

Operations: from an operational perspective, we already saw how an IMDG can be scaled up and down and how redundancy is built-in, which will allow us to easily achieve a highly-available system.
运营:从运营的角度来看,我们已经了解了IMDG的扩展和缩减方式以及内置的冗余机制,这将使我们轻松实现高可用性系统。

When to use an In-Memory Data Grid?
何时使用内存数据网格?
We have seen so far some of the advantages provided by an IMDG, but let’s look at some specific use-cases.
到目前为止,我们已经看到了IMDG提供的一些优势,但让我们看一些特定的用例。
There are two major use-cases for an In-Memory Data Grid: Data Cache and Data Service Fabric. Let’s see some characteristics of each of these two use-cases and also some real-world examples of IMDG usage.
内存中数据网格有两个主要用例:数据缓存和数据服务结构。 让我们看看这两个用例的每个特征,以及一些IMDG用法的真实示例。
Data cache
资料快取
In modern distributed systems, one of the common issues that we are facing when the number of users grows large enough is the contention on some data store or some component of the system which is providing data to the rest of the system’s components.
在现代分布式系统中,当用户数量增长到足够大时,我们面临的常见问题之一是对某些数据存储或系统某些组件的争用,该争用为系统的其他组件提供数据。
A solution to this issue is to move the data into some distributed cache and retrieve the data from there. Because the data is all resident in memory, there is no read/write delay to a datastore. So we are eliminating both the data store bottleneck along with the slow network connections.
解决此问题的方法是将数据移到某个分布式缓存中,然后从那里检索数据。 由于数据全部驻留在内存中,因此对数据存储区没有读/写延迟。 因此,我们消除了数据存储瓶颈和缓慢的网络连接。
By using an IMDG in this way we don’t have to worry about the performance of the network between middleware and the database. Also, we can work-around the long-running calculations that keep the application blocked for continuing and move them into memory, basically, this is a step forward into designing a reactive system according to the reactive manifesto.
通过以这种方式使用IMDG,我们不必担心中间件和数据库之间的网络性能。 此外,我们可以解决长期运行的计算问题,这些计算会使应用程序阻塞以继续运行,并将其移入内存,基本上,这是根据React式清单设计React式系统的第一步。
2. Data Service Fabric
2.数据服务架构
By using the IMDG as a Data Service Fabric we can perform near real-time integration between multiple components of a system.
通过将IMDG用作数据服务结构,我们可以在系统的多个组件之间执行近乎实时的集成。
In this way, we achieve a lot of computing power which can help us in designing a responsive distributed system, which is the core of the entire reactive systems idea.
这样,我们获得了很多计算能力,可以帮助我们设计响应式分布式系统,这是整个React式系统构想的核心。
Leveraging the IMDG can allow us to use it as a messaging platform, basically performing in-memory streaming.
利用IMDG可以使我们将其用作消息传递平台,基本上执行内存中的流传输。
Real-world examples
真实的例子
Some real-world examples from the industry are:
该行业的一些实际示例是:
- Analytics, which includes Risk Analysis or Fraud Detection
分析,包括风险分析或欺诈检测 - Trading Systems, like Foreign Exchange Trading or Stock Exchange
交易系统,例如外汇交易或证券交易所 - eCommerce
电子商务 - Online Gaming
线上游戏
Basic operations of an In-Memory Data Grid
内存中数据网格的基本操作
When looking at an IMDG implementation we should analyze some basic operations of it.
在查看IMDG实现时,我们应该分析它的一些基本操作。
Cluster
簇
The first of these operations is the capacity to run as a cluster. A cluster is a set of members that work together as a single unit to execute applications or perform specific tasks.
这些操作中的第一个是作为集群运行的能力。 集群是一组成员,这些成员作为一个单元一起工作以执行应用程序或执行特定任务。
The cluster ensures the even distribution of the data across all the nodes. Also, it provides high scalability and fault tolerance.
集群可确保在所有节点之间均匀分布数据。 而且,它提供了高可伸缩性和容错能力。
The scalability performance of an IMDG is up to thousands of members or terabytes of data.
IMDG的可伸缩性性能高达数千个成员或TB级数据。
Discovery
发现
Another important aspect that the IMDG must take care of is the discovery mechanism which allows nodes to form a cluster or to find and join an existing cluster.
IMDG必须照顾的另一个重要方面是发现机制,该机制允许节点形成集群或查找并加入现有集群。
When an IMDG node is started, it looks for finding an existing cluster to join. If no cluster exists, then the node remains running as a stand-alone node. The second node will find the first one and together will form a cluster. Subsequently, all the other nodes will join the existing cluster.
启动IMDG节点后,它将寻找要加入的现有集群。 如果不存在群集,则该节点将继续作为独立节点运行。 第二个节点将找到第一个,并一起形成一个集群。 随后,所有其他节点将加入现有群集。

Data distribution
资料分配
An IMDG must provide data distribution. The data is distributed across the entire cluster via replication or partitioning which is also known as sharding.
IMDG必须提供数据分发。 数据通过复制或分区(也称为分片 )分布在整个群集中。
Replication assumes that all nodes in the cluster will store a specific data structure which is very useful for achieving a high fault-tolerance degree.
复制假定集群中的所有节点都将存储特定的数据结构,这对于实现高容错度非常有用。
Partitioning means that a data structure is divided across multiple nodes in the cluster into disjoint pieces called partitions. For achieving a high degree of fault-tolerance we can provide partition backups.
分区是指将数据结构在群集中的多个节点之间划分为称为分区的不相交的片段。 为了实现高度的容错能力,我们可以提供分区备份。
Replication and Partitioning
复制和分区
We can have an entire and separate discussion about replication and partitioning, but in the following, we will try to show the consequences of using each of them in our distributed system.
我们可以对复制和分区进行完整而单独的讨论,但是在下面,我们将尝试展示在分布式系统中使用它们的后果。
We will avoid putting them in comparison or trying to consider what are the pros and cons of each because there is no one solution better than the other. As Michael Nygard shows in one of his articles, it’s about the consequences of choosing one or the other, not about the advantages or disadvantages of it.
我们将避免将它们进行比较或尝试考虑每种方案的优缺点,因为没有一种解决方案比另一种更好。 正如迈克尔·尼加德(Michael Nygard)在他的一篇文章中所展示的那样 ,这与选择一个或另一个有关,而不是其优缺点。
When we dealing with replication we will benefit from:
当我们处理复制时,我们将受益于:
- the highest degree of availability because each node in the cluster can be used for serving data;
可用性最高,因为集群中的每个节点均可用于提供数据; - workload scalability because the nodes in the cluster can be used for doing parallel computations;
工作负载可伸缩性,因为集群中的节点可用于进行并行计算; - instantaneous failure recovery due to the fact that all nodes are storing an instance of our replicated data structure.
由于所有节点都在存储我们复制的数据结构的实例,因此可以实现瞬时故障恢复。
Still, there is a cost to be paid when we choose replication instead of partitioning for some data:
但是,当我们选择复制而不是对某些数据进行分区时,仍然需要付出一定的代价:
- there is a negative performance impact because when a data is changed, then that change must be propagated to all cluster members;
这会对性能产生负面影响,因为当数据更改时,该更改必须传播到所有集群成员; - synchronization of data or keeping the data consistent is challenging and when the data becomes out of sync then we can be not reliable anymore;
数据同步或保持数据一致性是具有挑战性的,当数据不同步时,我们将不再可靠。 - replicated clusters have scalability issues because a new cluster member adds just another instance of a replicated structure, so if we want more memory available then we must scale in a vertical way the memory of the nodes.
复制群集存在可伸缩性问题,因为新的群集成员仅添加了复制结构的另一个实例,因此,如果我们想要更多的可用内存,则必须以垂直方式扩展节点的内存。
If we will look at replication from the CAP Theorem point of view, we will face an Available and Partition-Tolerant (AP) system.
如果我们从CAP定理的角度来看复制,我们将面对一个可用且耐分区的(AP)系统。
On the other hand, when we are using partitioning we will take advantage of the following:
另一方面,当我们使用分区时,我们将利用以下优势:
- workload scalability because the data is partitioned across all the nodes and we can use cluster members in parallel for doing computations;
工作量可伸缩性,因为数据在所有节点上进行了分区,并且我们可以并行使用集群成员进行计算; - failure recovery achieved by the usage of partition backups;
通过使用分区备份实现故障恢复; - increased memory scalability provided by adding more nodes to our cluster and producing a rebalancing of the partitions;
通过向群集中添加更多节点并重新分区来提供更大的内存可伸缩性; - compared with replication, there is no need for data synchronization, then the negative performance impact is out of discussion.
与复制相比,不需要进行数据同步,那么负面的性能影响已不在讨论之列。
As in the case of replication, partitioning implies doing some trade-offs:
与复制一样,分区意味着需要进行一些折衷:
- when we make changes to our cluster like adding or removing nodes, the data must be migrated so that it will be evenly distributed across all cluster members. This can have a negative performance impact in our system;
当我们对集群进行更改(例如添加或删除节点)时,必须迁移数据,以便将其平均分配给所有集群成员。 这可能会对我们的系统产生负面的性能影响; - there are large memory requirements when doing partitioning because of the backups that are made to partitions.
由于要对分区进行备份,因此在进行分区时对内存的需求很大。
Looking at a system that uses partitioning, from the CAP Theorem perspective, we will see a Consistent and Partition-Tolerant (CP) kind of system.
从CAP定理的角度来看,使用分区的系统,我们将看到一种一致性和分区容忍(CP)的系统。
Deployment options
部署选项
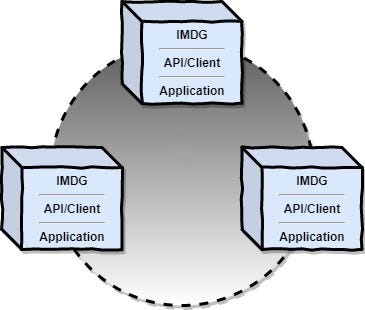
There are two deployment models when using an IMDG: embedded IMDG and classical Client-Server architecture.
使用IMDG时有两种部署模型:嵌入式IMDG和传统的客户端-服务器体系结构。
Embedded IMDG
嵌入式IMDG
This deployment model means that the server on the cluster member is running in the same process with the business application. Basically in this way, the data and the business logic are co-located in the same process. This is called data locality and is very efficient. This deployment model is used when dealing with the highest performance requirements.
此部署模型意味着集群成员上的服务器与业务应用程序正在同一进程中运行。 基本上以这种方式,数据和业务逻辑位于同一流程中。 这称为数据局部性,非常有效。 在满足最高性能要求时使用此部署模型。
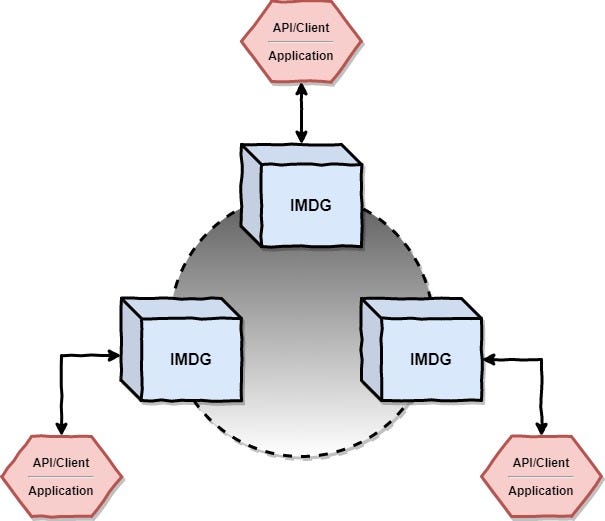
Client-Server
客户端服务器
The Client-Server architecture assumes that IMDG members and business applications are running in two separate processes. The integration between the IMDG cluster and business apps is made via an IMDG client or APIs.
客户端-服务器体系结构假定IMDG成员和业务应用程序在两个单独的进程中运行。 IMDG群集和业务应用程序之间的集成是通过IMDG客户端或API进行的。
The performance is not as good as in the case of the embedded IMDG model, but we will benefit from the decoupling between the cluster and the applications which will allow us to scale and evolve each of them independently. Also, this decoupling will allow us to develop business applications in whatever programming language we want.
性能不如嵌入式IMDG模型,但我们将从群集和应用程序之间的解耦中受益,这将使我们能够独立地扩展和发展它们。 而且,这种解耦将使我们能够使用所需的任何编程语言来开发业务应用程序。
Another very important aspect of this kind of deployment is that the business apps can be rebooted without losing the data that is stored in some IMDG members, as in the case of the Embedded IMDG model.
这种部署的另一个非常重要的方面是,与嵌入式IMDG模型一样,可以重新启动业务应用程序而不会丢失存储在某些IMDG成员中的数据。
Hazelcast IMDG — Characteristics
Hazelcast IMDG —特征
During the rest of the article, we will look at some specific characteristics of one of the most popular implementations of the IMDG concept: Hazelcast IMDG.
在本文的其余部分中,我们将介绍IMDG概念的最流行实现之一的某些特定特征:Hazelcast IMDG。
Why we should choose Hazelcast IMDG?
为什么我们应该选择Hazelcast IMDG?
When we think about why should we choose Hazelcast when we need an IMDG we should have in mind the following aspects:
当我们考虑为什么需要IMDG时为什么要选择Hazelcast,我们应该牢记以下几个方面:
Marked leader: Hazelcast is the marked leader among In-Memory Data Grid solutions.
标记的领导者 :Hazelcast是内存数据网格解决方案中的标记的领导者。

Rich API: it has a rich API and provides clients in various programming languages such as Java, C#.NET, Python, and so on. It has all the powerful features of an IMDG and a huge open source community.
丰富的API:它具有丰富的API,并以各种编程语言(例如Java,C#.NET,Python等)为客户提供。 它具有IMDG和庞大的开源社区的所有强大功能。

Ease of use: it has legendary ease of use because it’s basically a simple key-value data store. The data structures are standard ones like Map, List, or Queue (in Java there are just other implementations of the standard Java interfaces for java.util.List or java.util.Map). Also, the redundancy and scaling aspects are built-in.
易于使用:它具有传奇般的易用性,因为它基本上是一个简单的键值数据存储。 数据结构是诸如Map,List或Queue之类的标准结构(在Java中,还有java.util.List或java.util.Map的标准Java接口的其他实现)。 同样,冗余和扩展方面是内置的。

Distributed data store & computation system: Hazelcast it’s both a distributed data store and a distributed computation system. We can leverage it in both of these ways.
分布式数据存储和计算系统: Hazelcast它既是分布式数据存储又是分布式计算系统。 我们可以通过两种方式利用它。
Hazelcast Cluster Discovery
Hazelcast群集发现
As we have already seen, when talking about an IMDG, a very important aspect is the Cluster Discovery mechanism. Hazelcast provides multiple methods that can be used:
正如我们已经看到的,在谈论IMDG时,一个非常重要的方面是集群发现机制。 Hazelcast提供了多种可以使用的方法:
TCP/IP multicast discovery which is not recommended in a production environment;
在生产环境中不建议使用TCP / IP多播发现 ;
TCP/IP unicast discovery which implies managing a static list of addresses of some members of the cluster;
TCP / IP单播发现 ,这意味着管理集群中某些成员的地址的静态列表;
Various discovery plugins for cloud, like Eureka, Zookeeper, Kubernetes, Openshift, Pivotal Cloud Foundry, Google Cloud Platform, Amazon Web Services, Microsoft Azure;
各种针对云的发现插件 ,例如Eureka,Zookeeper,Kubernetes,Openshift,Pivotal Cloud Foundry,Google Cloud Platform,Amazon Web Services,Microsoft Azure;
Implement a custom discovery mechanism via Discovery Service Provider Interface (SPI).
通过发现服务提供者接口(SPI) 实现自定义发现机制 。
User code deployment
用户代码部署
Another important and powerful feature of Hazelcast is user code deployment.
Hazelcast的另一个重要而强大的功能是用户代码部署 。
This feature allows us to load pieces of code from the client to the cluster members. Basically, we can have code that can be viewed as a task on the client-side and when we want to execute that piece of code, we can serialize it and execute on the cluster members without having it in the classpath of these.
此功能使我们可以将代码片段从客户端加载到集群成员。 基本上,我们可以将代码视为客户端上的任务,并且当我们想要执行那段代码时,我们可以对其进行序列化并在集群成员上执行,而无需将其置于类的类路径中。
The feature is not enabled by default and requires some specific configurations to be done, both on the client-side and on the cluster members.
该功能默认情况下未启用,并且需要在客户端和群集成员上进行一些特定的配置。
On the client-side project, it’s necessary to add all the classes that we want to load into the cluster member and also to specify the classload that owns these classes.
在客户端项目上,有必要将我们要加载的所有类添加到集群成员中,并指定拥有这些类的类加载。
On the cluster member side, it’s enough to enable the user code deployment feature.
在集群成员方面,足以启用用户代码部署功能。
Hazelcast-Spring
榛树泉
Hazelcast-Spring is another module provided by Hazelcast when we want to use it inside Spring Framework projects.
当我们要在Spring Framework项目中使用Hazelcast时, Hazelcast-Spring是Hazelcast提供的另一个模块。
This module can be used by adding hazelcast-spring as a dependency to our Gradle or Maven project. It’s worth mentioning that hazelcast-spring’s version is not the same as Hazelcast’s version.
通过添加hazelcast-spring作为对Gradle或Maven项目的依赖项,可以使用此模块。 值得一提的是hazelcast-spring的版本与Hazelcast的版本不同。
This module, together with the user code deployment feature allows us to use the Dependency Inversion Principle for integrating the client and the server of Hazelcast.
该模块与用户代码部署功能一起使我们可以使用依赖反转原理来集成Hazelcast的客户端和服务器。
Basically, on the client-side, we can use an abstract class or an interface, which can be injected using the dependency injection provided by Spring, without having an actual implementation of this abstract class or interface into our client. The class where the dependency is injected it’s annotated with the @SpringAware and will be serialized and executed into the cluster member.
基本上,在客户端,我们可以使用抽象类或接口,可以使用Spring提供的依赖项注入来注入抽象类或接口,而无需将该抽象类或接口实际实现到客户端中。 注入依赖项的类将使用@SpringAware进行注释,并将被序列化并执行到集群成员中。
On the cluster member side, we must provide at least an implementation of this abstract class or interface and create a Spring Bean of this type.
在集群成员方面,我们必须至少提供此抽象类或接口的实现,并创建这种类型的Spring Bean。
When the serialized class will be executed on the cluster member side, the actually implemented dependency will be injected by the Spring IOC container.
当序列化的类将在集群成员端执行时,实际实现的依赖项将由Spring IOC容器注入。
Example project
示例项目
In the following, we will see a real example where Hazelcast is used in combination with Spring Boot, leveraging some features specific to an IMDG along with Hazelcast-Spring and Hazelcast user code deployment.
在下面的内容中,我们将看到一个真实的示例 ,其中将Hazelcast与Spring Boot结合使用,并利用IMDG的一些特定功能以及Hazelcast-Spring和Hazelcast用户代码部署。
Business scenario
业务场景
We will use Hazelcast IMDG for developing a Foreign Exchange Quotation Management System.
我们将使用Hazelcast IMDG开发外汇报价管理系统。
The High-Level Architecture looks like the following:
高级体系结构如下所示:
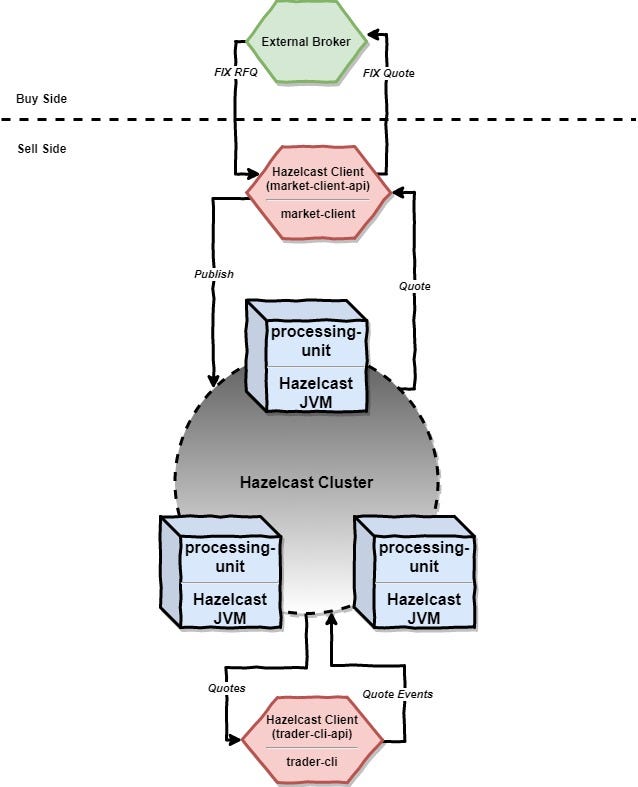
System’s components
系统组成
The system developed consists of:
开发的系统包括:
Two Spring Boot microservices: market-client and trader-cli which are basically Hazelcast clients and are communicating with the grid via APIs, specifically market-client-api and trader-cli-api.
两个Spring Boot微服务: market-client和trader-cli ,它们基本上是Hazelcast客户端,并通过API(特别是market-client-api和trader-cli-api)与网格通信。
One Spring Boot microservice called processing-unit which is basically a Hazelcast server member that will join the cluster when started.
一个Spring Boot微服务称为处理单元 ,它基本上是一个Hazelcast服务器成员,将在启动时加入集群。
The market-client is used for publishing quotation prices from an external broker into the grid. Also, it should be used for publishing transactions that are made into our system back into the external broker.
市场客户用于将外部经纪人的报价发布到网格中。 此外,它还应用于将在我们的系统中进行的交易发布回外部经纪人。
The trader-cli is a client used by trader to buy or sell FX pairs.
trader-cli是交易者用来购买或出售外汇对的客户。
Hazelcast features used
使用的Hazelcast功能
The current example uses the Client-Server deployment model, leveraging the TCP/IP unicast cluster discovery mechanism. Also, there are both replicated and partitioned data structures used.
当前示例使用Client-Server部署模型,并利用TCP / IP单播群集发现机制。 另外,同时使用复制的和分区的数据结构。
Conclusions
结论
- We have seen what an In-Memory Data Grid (IMDG) is and also what are its characteristics;
我们已经了解了什么是内存中数据网格(IMDG)及其特征。 - There are some benefits that can be obtained by using an IMDG, like performance increase, usage of simple data structures, or operations simpleness;
使用IMDG可以获得一些好处,例如性能提高,使用简单数据结构或操作简单。 - It were presented the two major use-cases for using Hazelcast: as a data cache or as a data service fabric, along with some examples from the industry;
它介绍了使用Hazelcast的两个主要用例:作为数据缓存或数据服务结构,以及来自行业的一些示例。 - There was presented both concepts of replication and partitioning along with the consequences of each of them;
介绍了复制和分区的概念,以及每个概念的后果。 - We have seen which are the deployment models for an IMDG;
我们已经看到了IMDG的部署模型。 - There were presented the characteristics of Hazelcast IMDG as a concrete implementation of the IMDG concept and also why should we choose Hazelcast when we need an IMDG;
介绍了Hazelcast IMDG作为IMDG概念的具体实现的特点,以及为什么在需要IMDG时为什么要选择Hazelcast? - We have seen two special features of Hazelcast: user-code deployment and hazelcast-spring module and how we can use both of them into a concrete implementation.
我们已经看到了Hazelcast的两个特殊功能:用户代码部署和hazelcast-spring模块,以及如何将它们都用于具体的实现中。
Don’t forget to follow me on Twitter!
别忘了在Twitter上关注我!
翻译自: https://medium.com/@bogdan.dina03/introducing-in-memory-data-grid-hazelcast-imdg-1f2af2be5344
hazelcast配置内存
相关文章:
- Hazelcast IMDG参考中文版手册-第一章-前言
- Hazelcast IMDG参考中文版手册-第四章-配置
- Hibernate缓存集成IMDG
- 开源IMDG之GridGain
- Hazelcast IMDG参考中文版手册-第三章-概述
- Hazelcast IMDG参考中文版手册-第二章-入门
- 大数据应用实践2: IMDG应用场景
- 初探HazelCast IMDG内存数据网格-简介
- Hazelcast IMDG技术详解
- Hazelcast IMDGJet详解
- Hazelcast IMDG参考中文版手册-第七章-分布式数据结构
- 内存数据网格IMDG简介
- Qq也进入鸿蒙系统,鸿蒙系统完善进行中,手机QQ接入HMS不需要后台运行秒收信息...
- 怎么恢复qq空间删除的日志文件呢
- python2.7 BeautifulSoup 爬QQ空间说说-含源码-第一天
- 仿QQ空间登录,解决键盘挡住输入框的问题
- 用MySQL绘制新年祝福图形_qq空间留言代码之新年祝福篇
- QQ空间迁移_【深度解锁数据恢复】
- android QQ分享、QQ空间分享
- 模仿QQ空间 网页设计
- selenium——爬取qq空间说说
- netcore 集成 CAP 使用 rabbitMQ集群
- XGBoost导读与实战阅读记录(一)——rabit和allreduce
- darts-clone、RABIT交叉编译
- 消息队列RabbitMQ入门与PHP实战
- RabbitMQ基础篇 (一)
- haproxy+rabbitmq镜像集群
- RabbitMQ-核心概念及AMQP协议
- C语言/C++常见习题问答集锦(六十四) 之兔子繁殖(递归与非递归)
- Rabbit安装及简单的使用
hazelcast配置内存_在内存数据网格中引入hazelcast imdg相关推荐
- jQuery EasyUI使用教程之在数据网格中添加搜索功能
2019独角兽企业重金招聘Python工程师标准>>> <jQuery EasyUI最新版下载> 在本教程中,我们将向你展示如何从数据库中获取数据,并将其显示到数据网格中 ...
- showdialog 尝试读取或写入受保护的内存_共享内存在不同系统的应用与优劣详解...
共享内存是一种使计算机程序能够同时共享内存资源以实现更高性能和更少冗余数据副本的技术.共享系统内存可以在单处理器系统.并行多处理器或集群微处理器上运行.对于分布式系统会有一些差异,但共享内存也可以其上 ...
- 剩余 大小 查看内存_谈谈内存压缩那些事
1. 技术背景 说到压缩这个词,我们并不陌生,应该都能想到是降低占用空间,使同样的空间可以存放更多的东西,类似于我们平时常用的文件压缩,内存压缩同样也是为了节省内存. 尽管当前android手机6G ...
- java应用程序占用高内存_对Java应用程序中的内存问题进行故障排除
java应用程序占用高内存 重要要点 解决内存问题可能很棘手,但是正确的方法和正确的工具集可以大大简化此过程. Java HotSpot JVM可以报告几种OutOfMemoryError消息,因此务 ...
- c++ 无法读取内存_为什么内存频率只有2133比实际低?开XMP提高内存频率方法
如今新装机,DDR4主流内存频率主要是2400MHz和2666MHz,不少用户还会配备更的高频率内存,例如3000MHz.3200MHz.3600MHz,甚至更高的4000+MHz内存,电脑做好系统之 ...
- 剩余 大小 查看内存_计算机内存管理介绍
作者:Adam原文:https://www.cnblogs.com/adamwong/p/10678015.html 计算机操作系统内存管理是十分重要的,因为其中涉及到很多设计很多算法.<深入理 ...
- 引导最大内存_实际内存不够大,可用内存更加小,这样解决
内存在电脑上是非常重要的一个部件,电脑种所运行的程序都是在内存里面进行的,因此内存的大小也决定可同时运行的程序的多少,当电脑内存不足时就会影响电脑的性能. 有时电脑安装的内存明明很大,但实际可用的内存 ...
- 数据科学领域有哪些技术_领域知识在数据科学中到底有多重要?
数据科学领域有哪些技术 Jeremie Harris: "In a way, it's almost like a data scientist or a data analyst has ...
- webform空间在html输出数据库,如何:在 ASP 上的数据网格中导出数据。 Microsoft Excel 的 NET WebForm...
启动 Visual Studio .NET. 在"文件"菜单上,指向"新建",然后单击"项目". 在 "项目类型" 窗格 ...
最新文章
- flask Blueprint蓝图
- Noip2016day1 天天爱跑步running
- wxpython可视化_使用wxPython的绘图模块wxPyPlot进行数据可视化
- 小程序原生组件调用mpvue父组件方法
- 扎实的基础是成功的法宝
- VB 去除文本框粘贴功能
- Smart Client Software Factory 初试
- python文件处理——JSON格式文件
- VNC 远程重装 Linux
- js脚本实现自由复制百度文库文字
- 从烂漫少女到已为人母:八年青春 梦断互联网
- 一招解决 Mac JD-JUI 打不开问题
- 自己动手搭建家庭局域网(三),千兆网+NAS存储+低成本
- 在WINDOWS 10上SQL SERVER如何远程调试防火墙
- 2019第十届蓝桥杯——I.胖子迷宫
- 登录前的人机验证VAPTCHA
- 同期收治患者住院天数_(完整版)DDD值算法
- Linux系统mysql半同步复制
- inaturalist昆虫数据集
- SVM要点总结(一)