python简单爬虫代码-Python爬虫――写出最简单的网页爬虫
最近对python爬虫有了强烈地兴趣,在此分享自己的学习路径,欢迎大家提出建议。我们相互交流,共同进步。
1.开发工具
笔者使用的工具是sublime text3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷。推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你。
sublime text3搭建python开发环境推荐查看此博客:
[sublime搭建python开发环境][http://www.cnblogs.com/codefish/p/4806849.html]
2.爬虫介绍
爬虫顾名思义,就是像虫子一样,爬在Internet这张大网上。如此,我们便可以获取自己想要的东西。
既然要爬在Internet上,那么我们就需要了解URL,法号"统一资源定位器”,小名"链接”。其结构主要由三部分组成:
(1)协议:如我们在网址中常见的HTTP协议。
(2)域名或者IP地址:域名,如:www.baidu.com,IP地址,即将域名解析后对应的IP。
(3)路径:即目录或者文件等。
3.urllib开发最简单的爬虫
(1)urllib简介
Module
Introduce
urllib.error
Exception classes raised by urllib.request.
urllib.parse
Parse URLs into or assemble them from components.
urllib.request
Extensible library for opening URLs.
urllib.response
Response classes used by urllib.
urllib.robotparser
Load a robots.txt file and answer questions about fetchability of other URLs.
(2)开发最简单的爬虫
百度首页简洁大方,很适合我们爬虫。
爬虫代码如下:
fromurllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# openthe URL
req = request.urlopen(URL)
# readthe URL
html = req.read()
# decode the URL toutf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()
结果如下图:
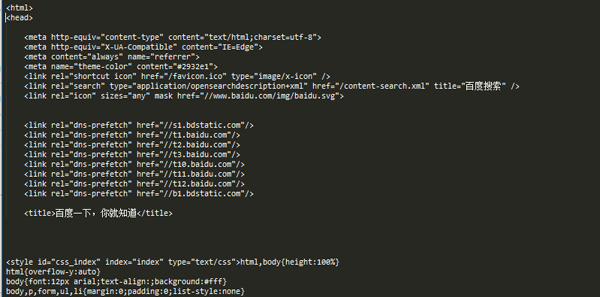
我们可以通过在百度首页空白处右击,查看审查元素来和我们的运行结果对比。
当然,request也可以生成一个request对象,这个对象可以用urlopen方法打开。
代码如下:
fromurllib import request
def vists_baidu():
# createa request obkect
req = request.Request('http://www.baidu.com')
# openthe request object
response = request.urlopen(req)
# readthe response
html = response.read()
html = html.decode('utf-8')
print(html)
if __name__ == '__main__':
vists_baidu()
运行结果和刚才相同。
(3)错误处理
错误处理通过urllib模块来处理,主要有URLError和HTTPError错误,其中HTTPError错误是URLError错误的子类,即HTTRPError也可以通过URLError捕获。
HTTPError可以通过其code属性来捕获。
处理HTTPError的代码如下:
fromurllib import request
fromurllib import error
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
excepterror.HTTPErrorase:
print(e.code)
if __name__ == '__main__':
Err()
运行结果如图:
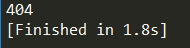
404为打印出的错误代码,关于此详细信息大家可以自行百度。
URLError可以通过其reason属性来捕获。
chuliHTTPError的代码如下:
fromurllib import request
fromurllib import error
def Err():
url = "https://segmentf.com/"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
excepterror.URLErrorase:
print(e.reason)
if __name__ == '__main__':
Err()
运行结果如图:

既然为了处理错误,那么***两个错误都写入代码中,毕竟越细致越清晰。须注意的是,HTTPError是URLError的子类,所以一定要将HTTPError放在URLError的前面,否则都会输出URLError的,如将404输出为Not Found。
代码如下:
fromurllib import request
fromurllib import error
# ***种方法,URLErroe和HTTPError
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
excepterror.HTTPErrorase:
print(e.code)
excepterror.URLErrorase:
print(e.reason)
大家可以更改url来查看各种错误的输出形式。
【编辑推荐】
【责任编辑:枯木 TEL:(010)68476606】
点赞 0
python简单爬虫代码-Python爬虫――写出最简单的网页爬虫相关推荐
- python最简单的爬虫代码,python小实例一简单爬虫
python新手求助 关于爬虫的简单例子 #coding=utf-8from bs4 import BeautifulSoupwith open('', 'r') as file: fcontent ...
- 深度学习研究生如何快速提升代码能力,写出高效的代码?
深度学习代码与前端代码区别 深度学习的代码能力与开发后台或者前端的工程代码能力不是一个概念. 写前端代码:脑海中是整个工程的架构,写代码则是把这些架构用 code 具体化. 写深度学习代码:脑海中浮现 ...
- python简单好看的代码_Python新手写出漂亮的爬虫代码1
初到大数据学习圈子的同学可能对爬虫都有所耳闻,会觉得是一个高大上的东西,仿佛九阳神功和乾坤大挪移一样,和别人说"老子会爬虫",就感觉特别有逼格,但是又不知从何入手,这里,博主给大家 ...
- python简单爬虫代码-python爬虫超简单攻略,带你写入门级的爬虫,抓取上万条信息...
原标题:python爬虫超简单攻略,带你写入门级的爬虫,抓取上万条信息 最近经常有人问我,明明看着教程写个爬虫很简单,但是自己上手的时候就麻爪了...那么今天就给刚开始学习爬虫的同学,分享一下怎么一步 ...
- python爬虫代码-Python爬虫大小项目集合
今天为大家带来了自己的爬虫代码集,主要是以往学习Python爬虫过程中写过的大小项目,可能不是很全面,但是持续在更新,那我的代码里有什么? 1. Cnblogs - 博客园爬虫 使用Urllib库实现 ...
- python爬虫代码-python网络爬虫源代码(可直接抓取图片)
在开始制作爬虫前,我们应该做好前期准备工作,找到要爬的网站,然后查看它的源代码我们这次爬豆瓣美女网站,网址为:用到的工具:pycharm,这是它的图标 ...博文来自:zhang740000的博客 P ...
- python爬虫代码-Python爬虫入门(01) -- 10行代码实现一个爬虫
跟我学习Python爬虫系列开始啦.带你简单快速高效学习Python爬虫. 一.快速体验一个简单爬虫 以抓取简书首页文章标题和链接为例 简书首页 就是以上红色框内文章的标签,和这个标题对应的url链接 ...
- python发音1001python发音-怎样才能写出 Pythonic 的代码 #P1001#
L = [ i*i fori inrange(5) ] forindex, data inenumerate(L, 1):print(index, ':', data) 去除 import 语句和列表 ...
- python如何写代码_如何写出优雅的Python代码?
有时候你会看到很Cool的Python代码,你惊讶于它的简洁,它的优雅,你不由自主地赞叹:竟然还能这样写.其实,这些优雅的代码都要归功于Python的特性,只要你能掌握这些Pythonic的技巧,你一 ...
- python爬取拼多多爆款数据_利用风变Python快速爬取海量数据,写出10万+爆文
我是从事自媒体内容创作者,每天都用心创作,保证文章质量,然后希望能出爆文,但似乎事情没有那么简单--自己认为可以的内容和标题但推送出去后,展示量和阅读量都低得可怜,心想,每次都这么用心,但结果却这样, ...
最新文章
- easyexcel 填充模板 格式变了_Qamp;A | 如何制作规范的电子合同模板?
- LeetCode 372. 超级次方(快速幂)
- 网络数据隐私保护,阿里工程师怎么做?
- zabbix客户端掉线查看进程time_wait过多
- FCS省选模拟赛 Day7
- Hyper-V 虚拟网络设置
- ekho嵌入式Linux移植全过程
- python做var模型_VAR模型学习笔记
- MCE公司:Pfizer入局IDO1小分子抑制剂
- 惠州 菜鸟机器人_京东PK阿里谁怕谁?菜鸟称:智能机器人仓库已在广东惠阳投入使用...
- why-they-are-using-vi
- Computational principles of synaptic memory consolidation(2016 Nature Neuroscience)
- 分数段统计函数c语言,Excel 五个函数统计学生期末考试分数段
- SparkSQL专题1 ~ 造数
- 监控摄像头1天存储计算机,如何计算一个摄像机一天占用多少的存储量?
- LETO型空间光调制器(SLM)的安装
- 【仅供娱乐】计算机算命之Python通天六十四卦
- FDC2214+FPGA转换芯片使用和配置(非接触液位检测设计)
- 个人对latch的一些个理解
- 我的新书:《Jetpack Compose:Android全新UI编程》已出版