sql隐式连接和显示链接_SQL Server中的嵌套循环联接–批处理排序和隐式排序
sql隐式连接和显示链接
In SQL Server, it`s not always required to fully understand the internal structure, especially for performance and optimization, if the database design is good, because SQL Server is a very powerful Relational Database and, as such, it has many inbuilt optimization processes which assure a response to the users as fast as possible. But it is always beneficial for the SQL Server developers and administrators to understand the internal structure of the SQL Server so that they can understand and fix the problems that slowed the response of the Database.
在SQL Server中,如果数据库设计良好,则并不总是需要完全了解内部结构,尤其是对于性能和优化,因为SQL Server是一个非常强大的关系数据库,因此它具有许多内置的优化过程。这样可以确保尽快回复用户。 但是,对于SQL Server开发人员和管理员来说,了解SQL Server的内部结构始终是有益的,这样他们就可以理解和解决降低数据库响应速度的问题。
The following article is the third edition in the Nested Loop Join series (Introduction to a Nested Loop Join in SQL Server, Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates) in which we will try to understand the Batch Sort, Explicit Sort and some interesting facts about Nested Loop Join.
下面的文章是嵌套循环联接系列的第三版( SQL Server中的 嵌套循环联接 简介 , 并行嵌套循环联接–嵌套循环联接和残差谓词的内侧 ),我们将尝试了解批处理排序,显式排序以及有关嵌套循环连接的一些有趣事实。
Before we start, it is important to understand two data access methods from the permanent storage system.
在开始之前,重要的是要了解永久性存储系统中的两种数据访问方法。
In a nutshell, when the requested data is not in the cache, it has to bring the data from permanent storage and put it in the buffer cache. The two ways of accessing the data from permanent storage system are Sequential and Random access. For conventional rotating magnetic disks, accessing is much faster in a sequential manner than the random access, because disk hardware works in that particular manner. For reading the random IOs, disk head has to move back and forth, due to which the random-access method delivers a lower rate of throughput.
简而言之,当请求的数据不在高速缓存中时,它必须将数据从永久存储中取出并放入缓冲区高速缓存中。 从永久存储系统访问数据的两种方式是顺序访问和随机访问。 对于常规的旋转磁盘,由于磁盘硬件以这种特定方式工作,因此以顺序方式进行的访问要比随机存取要快得多。 为了读取随机IO,磁盘头必须来回移动,因此,随机访问方法的吞吐量较低。
Usually, sequential access is not a problem unless the table is highly fragmented because when the table is fragmented, the data is not organized in contiguous clusters on the disk.
通常,除非表高度碎片化,否则顺序访问是没有问题的,因为当表碎片化时,数据不会在磁盘上的连续群集中组织。
In the latest permanent storage systems which are more expensive, faster and more advanced, the latency between sequential and random-access methods has been reduced, but sequential reads are still preferred.
在更昂贵,更快速,更先进的最新永久存储系统中,减少了顺序访问和随机访问方法之间的等待时间,但是顺序读取仍然是首选。
It is needed to understand this concept because inner side of Nested Loop Join fetches the data from the disk in a random manner.
需要理解此概念,因为嵌套循环连接的内侧以随机方式从磁盘中获取数据。
批处理排序和隐式排序 (Batch Sort and Implicit Sort)
Nested Loop Joins generates random IOs to the inner side. To minimize the random IO impact the Query Optimizer uses some techniques, one of them is sorting the outer input. This technique is only applicable when the joining column(s) of the inner side table is already sorted (indexed). If it is sorted then the Query Optimizer might choose to sort the outer joining column(s).
嵌套循环连接会在内部生成随机IO。 为了最大程度地减少随机IO的影响,查询优化器使用了一些技术,其中一种是对外部输入进行排序。 仅当内侧表的连接列已排序(索引)时,此技术才适用。 如果已排序,则查询优化器可能会选择对外部联接列进行排序。
To sort the Outer input, it either chooses Explicit Sort or Batch Sort. Explicit Sort is a part of the optimization process which is appropriate for a large set of data, but for a medium set of data it can be very expensive and blocking as well and may cost some additional IOs. For a medium set of rows, a post optimization process is used which is called Batch Sort.
要对外部输入进行排序,可以选择“显式排序”或“批量排序”。 显式排序是优化过程的一部分,适用于大量数据,但是对于中等数据集,它可能非常昂贵且会阻塞并且可能会花费一些额外的IO。 对于中等规模的行,使用后优化过程,称为批处理排序。
Batch Sort is not visible as an iterator in the execution plan, but can be seen in the properties window of the Nested Loop Join as an Optimized TRUE keyword, as this is the part of the post optimization process even Optimized keyword does not guarantee that Batch Sort applied to the outer rows.
批处理排序在执行计划中作为迭代器不可见,但可以在嵌套循环联接的属性窗口中以Optimized TRUE关键字看到,因为这是后期优化过程的一部分,即使Optimized关键字也不能保证Batch排序应用于外排。
To see this phenomenon in action we are changing the Somedata column of DBO.T1 table to char(8000) with some random number on the search column and indexing the search column.
为了了解这种现象的发生,我们将DBO.T1表的Somedata列更改为char(8000),并在搜索列上添加了一些随机数,并为搜索列建立了索引。
ALTER TABLE T1 ALTER COLUMN somedata Char(8000)
GO
;With RevOrder As
(
Select searchcol , ROW_number() Over(Order by primarykey DESC ) RK from
t1
)
UPDATE RevOrder SET searchcol = RK CREATE INDEX BatchSort ON T1 (searchcol)
GONow the searchcol column is updated with some random data, so we can clearly see the difference for both output result set. Run the query and have a look at the below result, for better visible differences in the result set, prepare the cache by running the below query twice.
现在,使用一些随机数据更新了searchcol列,因此我们可以清楚地看到两个输出结果集之间的差异。 运行查询并查看以下结果,为更好地显示结果集中的差异,请运行两次以下查询以准备缓存。
SELECT PrimaryKey , KeyCol, SearchCol
FROM T1
WHERE SearchCol < 1250
Option (Recompile , Loop Join)
GOSELECT Primarykey ,KEYcol, searchcol
FROM T1
WHERE SearchCol < 1251
Option (Recompile , Loop Join)
GO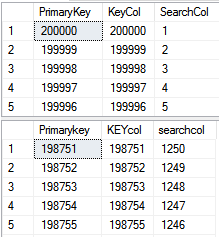
Before we explain the above result set, I would like to draw your attention on the two indexes on the DBO.T1 table.
在解释上述结果集之前,我想提醒您注意DBO.T1表上的两个索引。
The first index is a unique clustered Index on the primarykey column that technically means it is logically sorted on a primarykey column and rest columns are on its leaf level. In the above script, I have created another Index on searchcol column (Batch Sort) which is logically sorted on the searchcol and as usual, it has a primary key column on the leaf level.
第一个索引是主键列上的唯一聚集索引,从技术上讲,这意味着它在逻辑上在主键列上进行排序,其余列在其叶级别上。 在上面的脚本中,我在searchcol列上创建了另一个索引(批处理排序),该索引在searchcol上进行了逻辑排序,并且像往常一样,它在叶级别上具有主键列。
So, for the above-expressed query, it would be better to return the result by seeking the batch index and then get all the remaining rows from the clustered index. Now look at both result sets and you can see that the result order is quite different. Why is the result order different?
因此,对于上述查询,最好通过查找批处理索引返回结果,然后从聚簇索引中获取所有剩余的行。 现在查看两个结果集,您会发现结果顺序完全不同。 为什么结果顺序不同?
It is possible that both queries choose a different execution plan. Now see the below actual execution plan.
这两个查询可能选择不同的执行计划。 现在,请参见下面的实际执行计划。
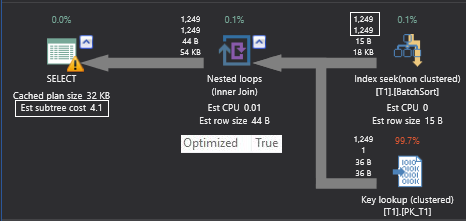
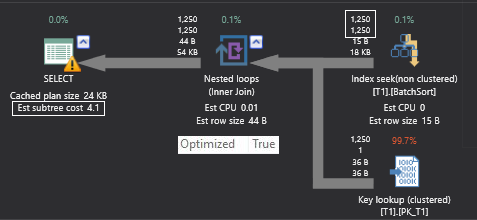
Of course, row count and cost of the iterators can vary slightly because the estimated number of rows are different for both queries. Apart from that, there is an Optimized keyword in the property window of Nested Loop Join iterator and this indicates that the outer row can enable a batch sort to minimize the impact of random access to the inner table.
当然,迭代器的行数和开销可能会略有不同,因为两个查询的估计行数都不同。 除此之外,Nested Loop Join迭代器的属性窗口中还有一个Optimized关键字,这表明外部行可以启用批处理排序,以最大程度地减少对内部表的随机访问的影响。
Optimize keyword indicates that outer side data could be sorted, but there is no guarantee as seen in the above example. You can see that both the query plans have the optimized keyword true, but sort order is entirely different. The first result set is sorted on the searchcol column and the second result is sorted on the primary key column which means that batch sort has applied on the second execution plan, but not on the first plan.
Optimize关键字表示可以对外部数据进行排序,但是不能保证如上例所示。 您可以看到两个查询计划都具有优化关键字true,但是排序顺序完全不同。 第一个结果集在searchcol列上排序,第二个结果在主键列上排序,这意味着批次排序已应用于第二个执行计划,但没有应用于第一个计划。
Batch sort is a lightweight process and this is quite good for the medium set of rows, but if the Query Optimizer determines that it might get a large set of rows, then it chooses a full sort on the inner side of a nested loop join. To see this in action we will change the literal value below:
批处理排序是一个轻量级的过程,对于中等规模的行集来说非常好,但是如果查询优化器确定它可能会获得大量行集,那么它会在嵌套循环连接的内侧选择一个完整的排序。 为了了解这一点,我们将在下面更改文字值:
SELECT *
FROM T1 WITH (INDEX (BatchSort))
WHERE SearchCol < 90000
OPTION (RECOMPILE)
GO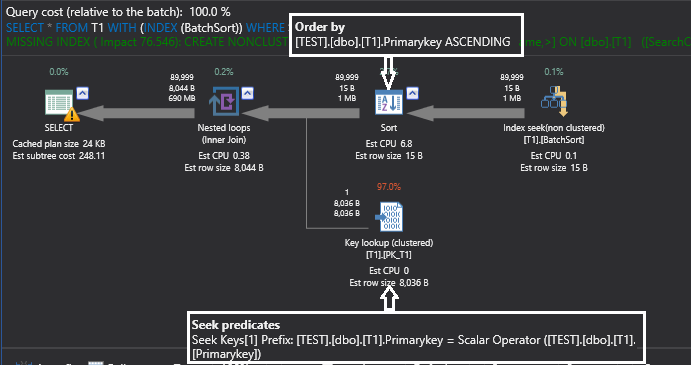
Looking at the above execution plan, there is a sort iterator which is sorting the outer input on the primary key column (the implicit sort might not be seen in your testing machine because it depends on the estimated number of rows on the outer input and the configured memory to SQL Server, we will see this in the next subsection).
查看上面的执行计划,有一个排序迭代器正在对主键列上的外部输入进行排序(隐式排序在您的测试机中可能看不到,因为它取决于外部输入和行的估计行数)。配置到SQL Server的内存,我们将在下一部分中看到)。
Now the outer set or rows are sorted and inner set of rows are already sorted on the primary key column, so the Nested Loop Join can minimize the impact of random access to the inner input.
现在,对外部集或行集进行了排序,而对内部行集已经在主键列上进行了排序,因此嵌套循环联接可以最大程度地减少对内部输入的随机访问的影响。
Both techniques given above are quite good, but their usefulness depends on the hardware you are using. To measure the performance difference you could run the test below.
上面给出的两种技术都非常好,但是其实用性取决于您使用的硬件。 要衡量性能差异,您可以运行以下测试。
批处理排序和隐式排序对性能的影响 (Performance Impact of Batch Sort and Implicit Sort)
Please note that in the below script that there is DBCC DropCleanBuffers which removes all clean buffers from the buffer pool so it is not recommended at all on the production server.
请注意,在下面的脚本中,有DBCC DropCleanBuffers可以从缓冲池中删除所有干净的缓冲区,因此完全不建议在生产服务器上使用它。
To perform the tests, we are using the documented Trace Flag 2340 to disable the batch sort. Script and Results are below.
为了执行测试,我们使用记录在案的Trace Flag 2340禁用批处理排序。 脚本和结果如下。
Batch Sort Test Script:
批处理排序测试脚本:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
DECLARE @a varchar(max)
SET STATISTICS TIME ON;
SELECT
@a = Primarykey,
@a = Keycol,
@a = SearchCol,
@a = somedata
FROM T1 WITH (INDEX (BatchSort))
WHERE SearchCol < 30000
OPTION (RECOMPILE)
SET STATISTICS TIME OFF;PRINT 'With Batch Sort'CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SET STATISTICS TIME ON;SELECT
@a = Primarykey,
@a = Keycol,
@a = SearchCol,
@a = somedata
FROM T1 WITH (INDEX (BatchSort))
WHERE SearchCol < 30000
OPTION (RECOMPILE ,QUERYTRACEON 2340)
SET STATISTICS TIME OFF;PRINT 'Without Batch Sort'
The first query in the above script, with batch sort enabled, took 2.2 seconds and the second query without batch sort took 4.3 seconds on my system.
在上面的脚本中,启用了批处理排序的第一个查询花费了2.2秒,而没有批处理排序的第二个查询花费了4.3秒。
Now test with the full inner sort:
现在使用完整的内部排序进行测试:
CHECKPOINT;
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;Declare @Primarykey int
Declare @Keycol varchar (50)
Declare @SearchCol int
Declare @SomeData char(8000)DECLARE @Lit int
SET @Lit = 150000
SET STATISTICS TIME ON;
SELECT
@Primarykey = Primarykey,
@Keycol = Keycol,
@SearchCol = SearchCol,
@SomeData = somedata
FROM T1 WITH (INDEX (BatchSort))
WHERE SearchCol < 150000
OPTION (RECOMPILE)
SET STATISTICS TIME OFF;
PRINT 'With Explict Sort'CHECKPOINT;
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET STATISTICS TIME ON;
SELECT
@Primarykey = Primarykey,
@Keycol = Keycol,
@SearchCol = SearchCol,
@SomeData = somedata
FROM T1 WITH (INDEX (BatchSort))
WHERE SearchCol < @Lit
OPTION (RECOMPILE, QUERYTRACEON 2340,OPTIMIZE FOR (@Lit = 30000))
SET STATISTICS TIME OFF;
PRINT 'Without Explict and Batch Sort'
Looking at the above script, the first query is using the full inner sort while the second is neither using full sort nor the batch sort. To confirm this, you can view the estimated/actual execution plan.
看上面的脚本,第一个查询使用完整内部排序,第二个查询既不使用完整排序也不使用批处理排序。 要确认这一点,您可以查看估计/实际执行计划。
An Estimated execution plan was used on my system for the above test.
我的系统上使用了估计执行计划进行上述测试。
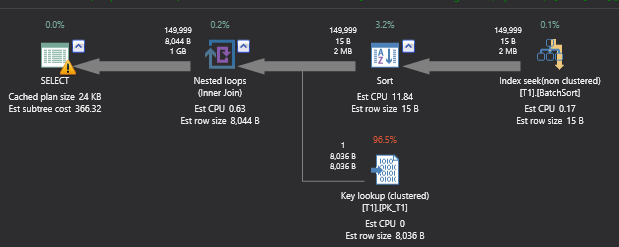
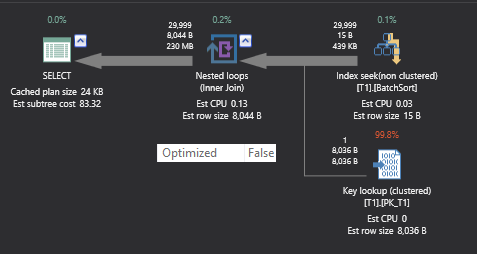
On my system first query with batch sort took 16.8 seconds and second query without full or batch sort took 25.7 seconds to complete the execution.
在我的系统上,具有批处理排序的第一个查询花费了16.8秒,而没有完全或批处理排序的第二个查询花费了25.7秒来完成执行。
However, those were just basic tests and the performance difference varies a lot with the different hardware setup, data load and the current IO pressure.
但是,这些只是基本测试,性能差异会因硬件设置 ,数据负载和当前IO压力的不同而有很大差异 。
Even these results can differ on some latest hardware setups (SSD, SSD NVMe etc.) because they perform random IOs much faster than the traditional Rotating Disks. On those Setup Batch Sort and Inner sort is just an additional overhead.
即使这些结果在某些最新的硬件设置(SSD,SSD NVMe等)上也可能有所不同,因为它们执行随机IO的速度比传统的旋转磁盘快得多。 在那些设置中,“批次排序”和“内部排序”只是一个额外的开销。
批处理排序,显式排序和冷缓存假设 (Batch Sort, Explicit Sort and Cold Cache Assumption)
If you are following the series carefully, then you would know that the Query Optimizer considers some assumptions before generating the execution plan. One of the major assumptions which influence the plan choice is that every query starts with a cold cache, also known as Cold Cache Assumptions.
如果您认真地遵循该系列,那么您将知道Query Optimizer在生成执行计划之前会考虑一些假设。 影响计划选择的主要假设之一是,每个查询均以冷缓存(也称为冷缓存假设)开始。
Batch and Explicit sort is not an exception. Both work well with the Cold Cache accompanied with prefetching (we will see this in the next part of this series) some organizations keep a large amount of memory on the servers, for those Batch and Explicit sort can be just an overhead.
批处理和显式排序也不例外。 两者都可以与伴随预取的Cold Cache一起很好地工作(我们将在本系列的下一部分中看到),一些组织在服务器上保留了大量内存,因为那些Batch和Explicit排序可能只是开销。
Since Batch Sort and Explicit sort were first introduced in the SQL Server 2005, some customers reported that some queries consumed high CPU in the new version and the reason was Batch Sort, so there is a documented trace flag 2340 to disable the batch sort, and the whole article can be read here.
由于SQL Server 2005中首次引入了批处理排序和显式排序,因此一些客户报告说,在新版本中,某些查询消耗了较高的CPU,其原因是批处理排序,因此有文档记录的跟踪标志2340禁用了批处理排序,并且整篇文章可以在这里阅读。
There is no Trace Flag to disable the explicit sort as per my knowledge.
据我所知,没有跟踪标志可以禁用显式排序。
The above query can be tested without the cleaning of Buffer cache (Remove DropCleanbuffer command) and the query may be found without the Batch/Explicit sort running slightly better than with Batch/Explicit sort.
可以在不清除缓冲区缓存的情况下测试上述查询(删除DropCleanbuffer命令),并且可以在不运行Batch / Explicit排序的情况下比使用Batch / Explicit排序更好地查找该查询。
批次排序(优化的嵌套循环联接)计算 (Batch Sort (Optimized Nested Loop Join) Calculations)
In the aforementioned tests, it was found that the Optimize (Batch Sort) property of Nested Loop Join is usually TRUE in the executions Plan when the inner side of the table is sorted (indexed, except when joining and where condition is in the same column), unless the inner side of the structure contains less than 1.280 +1 per MB data pages available to the SQL Server database.
在上述测试中,发现对表的内侧进行排序(已建立索引)时,嵌套循环联接的Optimize(批处理排序)属性在执行计划中通常为TRUE,但联接和条件位于同一列时除外),除非结构的内部每SQL Server数据库可用的MB数据页面每MB少于1.280 +1。
For example, if the SQL Server database is configured to maximum 1000 MB only then Optimized Property will be TRUE, when the inner side of the structure would have at least (1000 *1.280 +1) = 1281.00 pages.
例如,如果仅将SQL Server数据库配置为最大1000 MB,则当结构的内部至少具有(1000 * 1.280 +1)= 1281.00页时,Optimized属性将为TRUE。
Even when the Optimize property is true, Optimizer does not activate the batch sort because it is a post optimization process and when the execution plan creates it has no idea that it would activate or not.
即使Optimize属性为true,Optimizer也不会激活批处理排序,因为它是后期优化过程,并且在执行计划创建时不知道它是否会激活。
It was observed that Batch Sort is activated only when the estimated outer rows are more than or equal to 1250 (this is undocumented stuff and can change).
据观察,仅当估计的外部行大于或等于1250时,才激活“批次排序”(这是未记录的内容,可以更改)。
批处理排序(优化的嵌套循环连接)测试详细信息 (Batch Sort (Optimized Nested Loop Join) Tests Details)
To conclude the tests, two tables are created and are named BS and BS2 respectively. BS table contains only one column with primary key (Unique Clustered Index) and the other table is BS2 which has two columns where one is the primary key (Unique Clustered Index) and another is Non-Clustered Index, we will query against the Non-clustered index.
为了结束测试,将创建两个表,分别命名为BS和BS2。 BS表仅包含一个具有主键的列(唯一聚簇索引),另一表是BS2,它具有两列,其中一列是主键(唯一聚簇索引),另一列是非聚簇索引,我们将针对非聚集索引。
Download the script at the bottom of the article.
Tests are conducted in SQL Server 2008 to SQL server 2016.
在文章底部下载脚本。
测试在SQL Server 2008到SQL Server 2016中进行。
Note that below script contains some commands, like sp_configure ‘max server memory’ that could harm your system, so do not run the below test in the production environment.
请注意 ,以下脚本包含一些命令,例如sp_configure'max server memory'可能会损害您的系统 ,因此请不要在生产环境中运行以下测试。
关于嵌套循环联接的有趣事实 (Interesting Facts About Nested Loop Join)
In SQL Server, we have three physical join types:
在SQL Server中,我们有三种物理联接类型:
- Hash Match 哈希匹配
- Merge Join 合并加入
- Nested Loop Join 嵌套循环联接
All three are useful in different conditions, but only Nested Loop Join is the physical join type which supports non-equality predicate while joining the other tables.
这三个函数在不同条件下都很有用,但是只有嵌套循环连接是物理连接类型,它在连接其他表时支持非等式谓词。
Another interesting fact about Nested Loop Join is that it does not support right outer join, it actually converts all the right outer joins to the left outer joins. Because of the above fact that Nested Loop Join does not support full outer join directly and therefore converts full outer join to one left outer join concatenated with one semi left join.
关于嵌套循环连接的另一个有趣的事实是,它不支持右外部连接,它实际上将所有右外部连接转换为左外部连接。 由于上述事实,嵌套循环联接不直接支持完全外部联接,因此将完全外部联接转换为与一个半左联接连接的一个左外部联接。
Let us test the mentioned above facts:
让我们检验上述事实:
Test with Non-Equality Predicate Script:
使用非等式谓词脚本进行测试:
PRINT 'First Query'
SELECT TOP 1 *
FROM OuterTable OT1
JOIN Innertable_Parallel ot2
ON ot1.Keycol <> ot2.Keycol
OPTION (LOOP JOIN)
GOPRINT 'Second Query'
SELECT TOP 1 *
FROM OuterTable OT1
JOIN Innertable_Parallel ot2
ON ot1.Keycol <> ot2.Keycol
OPTION (HASH JOIN)
GOPRINT 'Third Query'
SELECT TOP 1 *
FROM OuterTable OT1
JOIN Innertable_Parallel ot2
ON ot1.Keycol <> ot2.Keycol
OPTION (MERGE JOIN)
GO
Looking at the message tab, neither the hash or merge joins are able to produce the physical plan, only the loop join is able to produce a plan for the non-equality predicate.
查看消息选项卡,散列或合并联接均无法生成物理计划,只有循环联接能够为非相等谓词生成计划。
Nested Loop Join Does Not Support Right Outer Join Physically:
嵌套循环连接在物理上不支持正确的外部连接:
To test whether the Nested Loop Join supports the Right Outer Join physically or not, we will write a query with Right Outer Join and then we will see the execution plan.
为了测试嵌套循环联接是否物理上支持右外联接,我们将使用右外联接编写查询,然后查看执行计划。
Look at the query and its estimated execution plan below:
在下面查看查询及其估计的执行计划:
SELECT *
FROM T1 OT1
Right Outer Join T2 ot2
ON ot1.Keycol = ot2.Keycol
OPTION (LOOP JOIN )
GO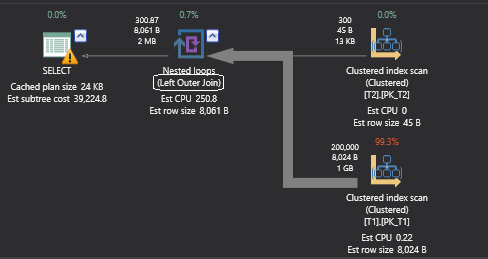
Looking at the physical join of the above query in the execution plan, in the query text it is written as “T1 Right Join T2”, but the Query Optimizer has converted it into the T2 left join T1 which is logically equivalent to the above expressed query and it is common for the Query Optimizer to choose this transformation based on costing, but on the above case the Query Optimizer is bound to choose Left Outer Join because it cannot use Right Outer Loop Join. To check that we need to force the above query.
查看上述查询在执行计划中的物理联接,在查询文本中将其写为“ T1右联接T2”,但是查询优化器已将其转换为T2左联接T1,这在逻辑上等同于上述表示形式查询,并且查询优化器通常基于成本计算来选择此转换,但是在上述情况下,查询优化器势必选择左外连接,因为它不能使用右外循环连接。 为了检查我们需要强制执行以上查询。
SELECT *
FROM OuterTable OT1
RIGHT JOIN Innertable_Parallel ot2
ON ot1.Keycol = ot2.Keycol
OPTION (LOOP JOIN, FORCE ORDER)
GO
Looking at the above message, we can see that the Query Optimizer is not able to produce a plan when forcing the query with the Right Join.
查看上面的消息,我们可以看到在使用Right Join强制查询时,Query Optimizer无法生成计划。
嵌套循环联接不直接支持完全外部联接 (Nested Loop Join Does Not Support Full Outer Join Directly)
We have seen above that the Nested Loop Join does not support the Right Join directly, and therefore the Nested Loop Join does not support the full outer join directly. It actually converts Full Outer Join into one Left Outer Join and concatenates with the Semi Left Join. To confirm this is to run the query and see the execution plan, look at the query and plan below:
上面我们已经看到嵌套循环联接不直接支持右联接,因此嵌套循环联接不直接支持完整的外部联接。 它实际上将完全外部联接转换为一个左外部联接,并与半左联接连接。 要确认这是运行查询并查看执行计划,请查看下面的查询和计划:
SELECT TOP 10 ot1.SearchCol,ot2.Primarykey
FROM T1 OT1
FULL JOIN T2 ot2
ON ot1.Keycol = ot2.Keycol
OPTION (LOOP JOIN , Maxdop 1)
GO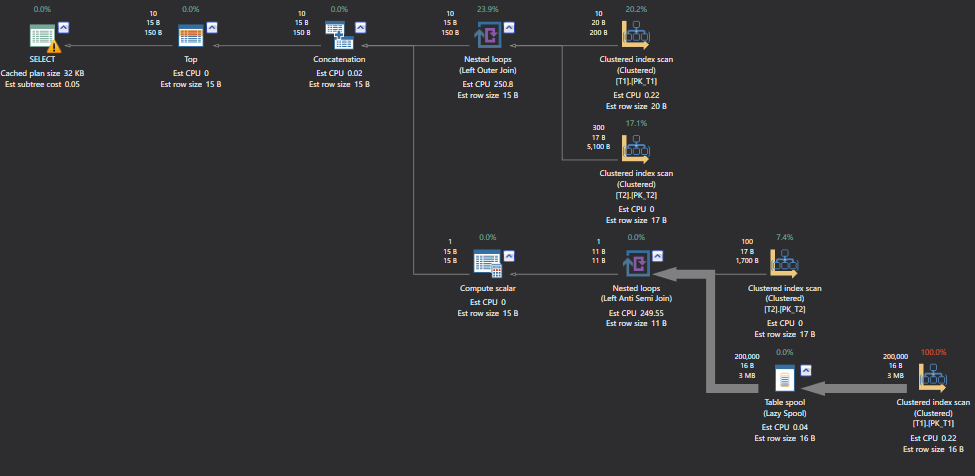
Looking at the above execution plan we observe that both the tables have been used twice to get the result for Full Outer Join.
查看上面的执行计划,我们发现两个表都已使用两次以获取完全外部联接的结果。
The Query Optimizer fulfills the Joining part in three steps:
查询优化器通过三个步骤实现了Joining部分:
First Step: First table left join second table
Second Step: Second table left semi join first table
Third Step: Concatenate the results of both output
第一步:第一张桌子离开,第二张桌子
第二步:第二张表左半联接第一张表
第三步:连接两个输出的结果
It is very interesting to note how the Nested Loop Join supports the full outer join. An alternative way to mimic this is by converting the above steps into a query and then looking at the execution plan, the same execution plan will be seen as in the full nested loop join.
注意到嵌套循环连接如何支持完整的外部连接非常有趣。 模仿此情况的另一种方法是,将上述步骤转换为查询,然后查看执行计划,将在完全嵌套循环联接中看到相同的执行计划。
To check this, we convert the full join query into the three steps described above and then check the execution plan.
为此,我们将完全联接查询转换为上述三个步骤,然后检查执行计划。
SELECT
Top 10 *
FROM (SELECT
ot1.SearchCol,
ot2.Primarykey
FROM T1 OT1
LEFT JOIN T2 ot2
ON ot1.Keycol = ot2.KeycolUNION ALLSELECT
NULL SearchCol,
ot2.Primarykey
FROM T2 ot2
WHERE NOT EXISTS (SELECT
*
FROM T1 OT1
WHERE ot1.Keycol = ot2.Keycol)) TBL
OPTION (LOOP JOIN , maxdop 1)
GO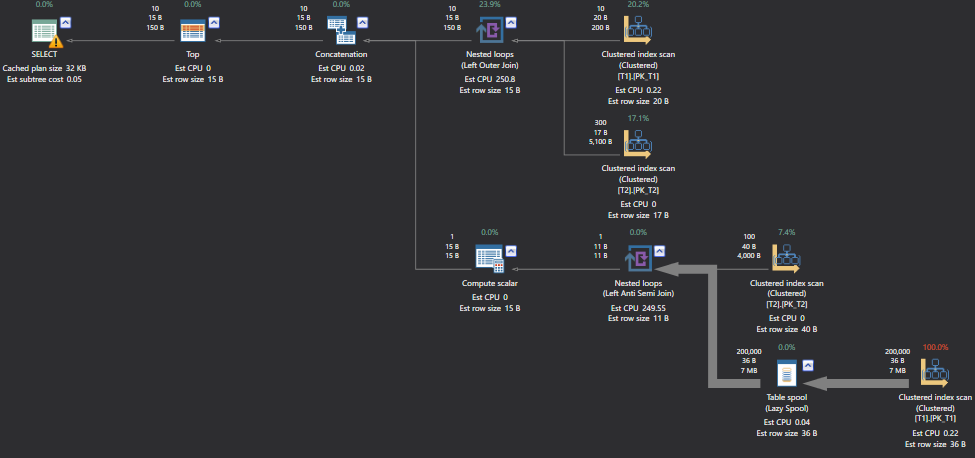
On observing the above execution plan, we see that nothing has changed and it is similar to nested loop full outer join. Moreover, the sub tree cost is equal for both.
观察以上执行计划,我们发现什么都没有改变,这类似于嵌套循环完全外部联接。 而且,两者的子树成本相等。
The Nested Loop Join is an amazing physical join type which is often misunderstood. These are just a few interesting facts about Nested Loop Join, and you can feel free to add more in the comment section.
嵌套循环联接是一种令人惊奇的物理联接类型,通常会被误解。 这些只是关于嵌套循环连接的一些有趣事实,您可以随时在评论部分中添加更多内容。
We have tried our best to cover the basics of Nested Loop Join and for better insights we recommend our readers to visit the links provided in the below section.
我们已尽力介绍了嵌套循环连接的基础知识,并且为了获得更深入的了解,我们建议读者访问以下部分提供的链接。
资料下载 (Downloads)
- Batch Sort Test Script批处理测试脚本
Previous articles in this series:
本系列以前的文章:
- Introduction to a Nested Loop Join in SQL ServerSQL Server中的嵌套循环联接简介
- Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates并行嵌套循环连接–嵌套循环连接和残留谓词的内侧
有用的链接 (Useful links)
- OPTIMIZED Nested Loops Joins优化的嵌套循环联接
- High CPU after upgrading to SQL Server 2005 from 2000 due to batch sort由于批次排序从2000升级到SQL Server 2005后的高CPU
- SQL Server can’t start after accidently set the “max server memory” to 0意外将“最大服务器内存”设置为0后,SQL Server无法启动
翻译自: https://www.sqlshack.com/nested-loop-joins-sql-server-batch-sort-implicit-sort/
sql隐式连接和显示链接
sql隐式连接和显示链接_SQL Server中的嵌套循环联接–批处理排序和隐式排序相关推荐
- sql如何遍历几百万的表_SQL Server中遍历表中记录的方法
遍历表有下面几种方法 1.使用游标 2.使用表变量 3.使用临时表 下面通过一个实例分别介绍三中方法的实现: 1.需求 给HR.Employees表,fullname 列赋值,其值为 firstnam ...
- 第3周 区_SQL Server中管理空间的基本单位
第3周 区_SQL Server中管理空间的基本单位 原文:第3周 区_SQL Server中管理空间的基本单位 哇哦,SQL Server性能调优培训已经进入第3周了!同时你已经对SQL Serve ...
- sql隐式转换_SQL Server中的隐式转换
sql隐式转换 This article will provide an overview of SQL Server implicit conversion including data type ...
- 用SQL表达内连接和外链接
前置:https://blog.csdn.net/jaihk662/article/details/80072281 https://blog.csdn.net/jaihk662/article/de ...
- java代码转置sql数据_SQL Server中的数据科学:数据分析和转换–使用SQL透视和转置
java代码转置sql数据 In data science, understanding and preparing data is critical, such as the use of the ...
- sql limit 子句_SQL Server中的FOR XML PATH子句
sql limit 子句 As SQL professionals, we often have to deal with XML data in our databases. This articl ...
- sql server 群集_SQL Server中的Microsoft群集
sql server 群集 Microsoft Clustering is the next data mining topic we will be discussing in our SQL Se ...
- sql server序列_SQL Server中的Microsoft时间序列
sql server序列 The next topic in our Data Mining series is the popular algorithm, Time Series. Since b ...
- sql 实现决策树_SQL Server中的Microsoft决策树
sql 实现决策树 Decision trees, one of the very popular data mining algorithm which is the next topic in o ...
最新文章
- 基于ESP32的竞赛裁判系统功能调试-硬件修改建议
- css 水平垂直居中实现方式
- 《深入理解计算机系统》读书笔记五:信息的表示和存储
- Boost::Regex 使用方法 (英文)
- PTA 7-1 求奇数和 (C语言)
- 这个网站不错,根据引用jar包路径查找原JAR包
- android R 文件 丢失的处理 如何重新生成
- 当点击ListView的列头时,对ListView排序
- 帕雷诺的个展“共此时”在沪开幕 体验真实与虚妄的交错人生
- php mysql 内存表_用mysql内存表来代替php session的类_PHP教程
- D-S envidence theory(DS 证据理论)的基本概念和推理过程
- newifimini出厂固件_newifi 新路由 mini用哪个Pandora固件
- 笔记——H.264/AVC与H.265/HEVC基本总结
- IDEA(或Android Studio)切换Git分支时弹出Git Checkout Problem
- (问题)双击页面时,会出现蓝色背景,选中文字,css 样式解决问题
- (此文精辟)[汇编学习]献给汇编初学者-函数调用堆栈变化分析(转自黑客风云)
- chrome如何对部分网页截图
- 网络运营商名称显示amp;SIM名称显示
- SMART PLC如何修改运动控制向导生成的点动速度(JOG_SPEED)
- Linux服务器操作习惯培养