查询sql执行计划_使用SQL执行计划进行查询性能调整
查询sql执行计划
In the previous articles of this series (see the index at bottom), we went through many aspects of the SQL Execution Plan, where we discussed how the Execution Plan is generated internally, the different types of plans, the main components and operators and how to read and analyze the plans that are generated using different tools. In this article, we will show how we can use an Execution Plan in tuning the performance of T-SQL queries.
在本系列的前几篇文章中(请参阅底部的索引),我们研究了SQL执行计划的许多方面,讨论了内部如何生成执行计划,计划的不同类型,主要组件和运算符以及如何执行。阅读和分析使用不同工具生成的计划。 在本文中,我们将展示如何使用执行计划来调整T-SQL查询的性能。
SQL Server query performance tuning is considered as a top priority and an endless battle for database administrators to achieve the best performance for their managed systems, with the least resources consumption. The first method that any database administrator recalls when thinking about the queries performance tuning is using SQL Execution Plans. This is because the plan tells us what to tune, by showing how the query is internally executed with presentation for the execution road map, the most expensive part of the query, signs that help in writing the query in the best way and the recommended indexes.
SQL Server查询性能调优被认为是数据库管理员以最低的资源消耗实现其托管系统的最佳性能的头等大事,也是一场无休止的战斗。 任何数据库管理员在考虑查询性能调整时都会想起的第一种方法是使用SQL执行计划。 这是因为该计划通过显示查询在内部如何执行以及执行路线图,查询中最昂贵的部分,有助于以最佳方式编写查询的符号和推荐索引的方式,告诉我们要调整的内容。
There are number of general signs in the SQL Execution Plan that indicate potentially bad performance spots on the query. For example, the most expensive operator that has the highest cost, related to the overall query cost, is a good starting point for the query performance troubleshooting. In addition, the fat arrows, that followed with thin ones, indicates large number of records being processed and flowed from one operator to the other to retrieve small number of records, could be also a sign for a missing index or data multiplication performance issue.
SQL执行计划中有许多常规符号,它们指示查询上潜在的性能下降点。 例如,与整体查询成本相关的,成本最高的最昂贵的运算符 ,是查询性能故障排除的良好起点。 此外,粗箭头 (后跟细箭头)表示正在处理大量记录,并从一个操作员流向另一个操作员以检索少量记录,这也可能表示索引丢失或数据乘法性能问题。
After understanding the role of each plan operator discussed in this series, you can recognize the extra operators that degrade the performance of the query due to its addition overhead. Also, the Scan operators that are used for scanning the overall table or index, indicates most of the time that there is a missing index, the index is badly used, or the query contains no filtering condition. Another sign from the Execution Plan for a performance issue in the query, are the Execution Plan Warnings. These messages are used to warn about different problems with the query to troubleshoot, such as tempdb spills issues, missing indexes or bad cardinality estimates.
了解了本系列中讨论的每个计划运算符的作用之后,您可以认识到由于其额外开销而降低查询性能的额外运算符 。 另外,用于扫描整个表或索引的扫描运算符在大多数情况下会指示缺少索引,索引使用不正确或查询不包含过滤条件。 执行计划中针对查询中的性能问题的另一个标志是执行计划警告 。 这些消息用于警告有关查询的各种问题以进行故障排除,例如tempdb溢出问题,索引丢失或基数估计错误。
To understand how to use a SQL Execution Plan in tuning the performance SQL queries, let us go through our practical demo. Before starting with the first example, we will create two new tables using the CREATE TABLE T-SQL statements below:
为了了解如何使用SQL执行计划来调整性能SQL查询,让我们来看一下实际的演示。 在开始第一个示例之前,我们将使用下面的CREATE TABLE T-SQL语句创建两个新表:
CREATE TABLE Employee_Main
( Emp_ID INT IDENTITY (1,1) PRIMARY KEY,EMP_FirsrName VARCHAR (50),EMP_LastName VARCHAR (50),EMP_BirthDate DATETIME,EMP_PhoneNumber VARCHAR (50),EMP_Address VARCHAR (MAX)
)
GO
CREATE TABLE EMP_Salaries
( EMP_ID INT IDENTITY (1,1),EMP_HireDate DATETIME,EMP_Salary INT,CONSTRAINT FK_EMP_Salaries_Employee_Main FOREIGN KEY (EMP_ID) REFERENCES Employee_Main (EMP_ID),
)
GO
After creating the tables, we will fill each table with 100K records, using ApexSQL Generate, as shown below:
创建表之后,我们将使用ApexSQL Generate ,用100K条记录填充每个表,如下所示:
Tuning Simple Query
调整简单查询
Now the tables are ready for the demo. Assume that we need to tune the performance of the following badly behaving SELECT statement:
现在,表已准备好进行演示。 假设我们需要调整以下表现差的SELECT语句的性能:
SELECT [EMP_ID],[EMP_HireDate],[EMP_Salary]FROM [AdventureWorks2016CTP3].[dbo].[EMP_Salaries]WHERE [EMP_ID]< 1000
The best way of tuning the previous query performance, is studying the SQL Execution Plan of that query. If you execute the previous SELECT query, including the Actual Execution Plan, the generated plan in our case will be like:
调整先前查询性能的最佳方法是研究该查询SQL执行计划。 如果您执行上一个SELECT查询(包括实际执行计划),则在我们的情况下生成的计划将类似于:
It is clear from the generated plan, that the SQL Server Engine scans all the table rows (100K records) to retrieve the requested data (1 record). This is obvious from three signs:
从生成的计划很明显,SQL Server Engine扫描所有表行(100K条记录)以检索请求的数据(1条记录)。 从以下三个迹象可以明显看出:
- the Table Scan operator 表扫描运算符
- the high cost for that operator 该运营商的高昂成本
- and the transition from the fat arrow, that flows the data from the Table Scan to the next operator, to the think arrow of the flows the output data. 从宽箭头到将数据从表格扫描流到下一个运算符的过渡到流向输出数据的思考箭头的过渡。
Using ApexSQL Plan, a free SQL Execution plan analysis tool, you can check the execution statistics of the query, such as the number of reads, the duration and the CPU cost, that are high for that query, as shown below:
使用免费的SQL执行计划分析工具 ApexSQL Plan,您可以检查查询的执行统计信息,例如对该查询而言很高的读取次数,持续时间和CPU成本,如下所示:
The three signs derived from the previous plan direct us to the main cause of the query’s bad performance, which is the absence of an index, in the EMP_Salary table, that can speed up the data retrieval process from that table. We will go ahead and create an index on the EMP_ID column of the EMP_Salary table, using the CREATE INDEX T-SQL statement below:
从以前的计划中得出的三个信号将我们引导到查询性能差的主要原因,即EMP_Salary表中没有索引,这可以加快从该表进行数据检索的速度。 我们将继续使用下面的CREATE INDEX T-SQL语句在EMP_Salary表的EMP_ID列上创建索引:
CREATE NONCLUSTERED INDEX IX_EMP_Salaries_EMP_ID ON EMP_Salaries (EMP_ID)
… then run the same T-SQL statement, including the Actual Execution Plan.
…然后运行相同的T-SQL语句,包括实际执行计划。
You will see from the generated Execution Plan that, that the SQL Server Engine will Seek for the requested data in the created index directly, without the need to scan the overall underlying table, with the cost of the Index Seek reduced to 50%. In addition, the number of records flowed from the Index Seek operator to the next operator was reduced significantly, that is clear from the thickness of the arrow, as shown in the plan below:
从生成的执行计划中您将看到,SQL Server引擎将直接在创建的索引中寻找请求的数据,而无需扫描整个基础表,并将索引寻找的成本降低到50%。 此外,从索引查找运算符流向下一个运算符的记录数量大大减少了,这从箭头的粗细可以明显看出,如下图所示:
Checking the execution statistics of the query, you will see how the number of rows was reduced to 2 with negligible duration and CPU cost, as shown below:
检查查询的执行统计信息,您将看到如何将行数减少到2,而持续时间和CPU成本却可以忽略不计,如下所示:
If you look deeply in the previous plan, you can find another sign for a performance issue, which is the extra expensive RID Lookup and Nested Loops operators. Recall from the previous article about the Execution Plan operators that, the SQL Server Engine used the NonClustered index to retrieve the EMP_ID column and returns for the underlying table to retrieve the rest of columns. This issue can be fixed by creating a covering index, that allows the SQL Server Engine to retrieve all the columns from that sorted index, without the need to check the underlying table.
如果您仔细查看以前的计划,则会发现性能问题的另一个迹象,那就是昂贵的RID查找和嵌套循环运算符。 回忆一下有关执行计划运算符的前一篇文章,SQL Server引擎使用NonClustered索引检索EMP_ID列,并返回基础表以检索其余列。 通过创建覆盖索引可以解决此问题,该索引允许SQL Server Engine从该排序索引中检索所有列,而无需检查基础表。
The below CREATE INDEX T-SQL statement can be used to create a covering index for that query:
下面的CREATE INDEX T-SQL语句可用于为该查询创建覆盖索引:
CREATE NONCLUSTERED INDEX IX_EMP_Salaries_EMP_ID ON EMP_Salaries (EMP_ID) INCLUDE (EMP_HireDate,EMP_Salary ) WITH DROP_EXISTING
Running the same SELECT statement, including the Actual Execution Plan of the query, you will see that the RID Lookup and the Nested Loops operators are no longer appeared, as the SQL Server Engine found all requested data in the sorted covering plan, as shown below:
运行相同的SELECT语句,包括查询的实际执行计划,您将看到RID查找和嵌套循环运算符不再出现,因为SQL Server Engine在排序的覆盖计划中找到了所有请求的数据,如下所示:
Tuning Complex Query
调整复杂查询
We saw how the SQL Execution plan helped us in tuning the performance of a simple query. Will it help us with more complex query in the same way?
我们看到了SQL执行计划如何帮助我们调整简单查询的性能。 它会以相同的方式帮助我们进行更复杂的查询吗?
Let us drop the index that was created on the EMP_Salaries table to start a clear scenario, using the DROP INDEX T-SQL statement below:
让我们使用下面的DROP INDEX T-SQL语句删除在EMP_Salaries表上创建的索引以启动一个清晰的场景:
DROP INDEX IX_EMP_Salaries_EMP_ID ON EMP_Salaries
Assume that we need to tune the performance of the below SELECT query, that joins the two EMP test tables created previously, to retrieve the employee’s information:
假设我们需要调整下面的SELECT查询的性能,该查询将先前创建的两个EMP测试表连接起来,以检索员工的信息:
SELECT EMP_FirsrName, EMP_LastName, EMP_BirthDate, EMP_Address, EMP_HireDate, EMP_Salary
FROM [dbo].[Employee_Main] EM
JOIN [dbo].[EMP_Salaries] ES
ON EM.[EMP_ID] =ES.[EMP_ID]
WHERE EM.[EMP_ID] > 2470 AND ES.EMP_Salary >450
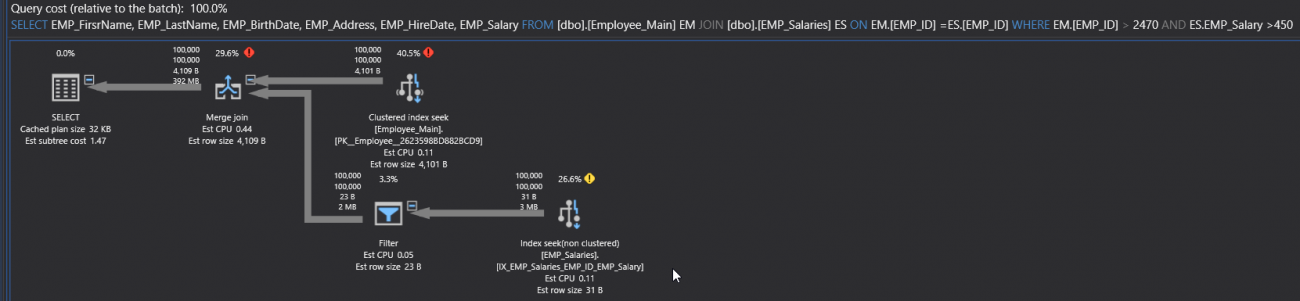
If you execute the SELECT query, including the Actual Execution Plan of the query. You will see from the generated plan number of performance issue signs, such as the Table Scan operator, due to scanning the overall underlying table, the fat arrow, due to large number of rows flowing between the operators and the extra expensive operators such as the Hash Match operator, as shown in the SQL Execution Plan below:
如果执行SELECT查询,包括查询的实际执行计划。 您会从生成的计划中看到许多性能问题征兆,例如Table Scan操作符,这是由于扫描了整个基础表,而实线箭头则是由于操作符与昂贵的操作符(例如,哈希匹配运算符,如下面SQL执行计划中所示:
Checking the execution statistics of the query, you will see the large number of reads, the long duration and the high CPU cost, as shown below:
检查查询的执行统计信息,您将看到大量读取,持续时间长和CPU成本高,如下所示:
From the upper part of the Execution Plan, you will see, in green, a CREATE INDEX T-SQL statement for a recommended index that will enhance the performance of the query, as shown below:
在执行计划的上部,将以绿色显示CREATE INDEX T-SQL语句,用于推荐的索引,它将增强查询的性能,如下所示:
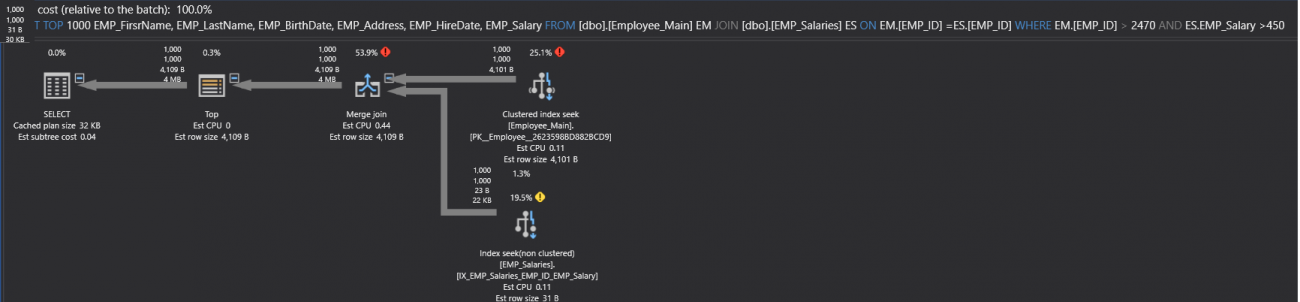
If we create the suggested index, then execute the SELECT statement again, including the Actual Execution Plan of the query. The generated SQL Execution Plan will show that, the Table Scan operator changed to Index Seek operator. But the arrow still fat, which is a normal behavior here, as there is no transition from fat arrow to thin arrow, as shown below:
如果我们创建建议的索引,则再次执行SELECT语句,包括查询的实际执行计划。 生成SQL执行计划将显示,“表扫描”运算符已更改为“索引查找”运算符。 但是箭头仍然很胖,这在这里是正常现象,因为从胖箭头到细箭头没有过渡,如下所示:
With the minimal enhancements in the execution duration and PU cost, as shown in the execution statistics of the query below:
在执行持续时间和PU成本方面有最小的提高,如以下查询的执行统计信息所示:
At this step, the enhancement that can be performed in the query performance, can be achieved by writing the query in a better way. For example, the thickness of the arrow can be reduced using the TOP clause that limits the number of returned rows. On the other hand, the Filter operator can be removed by creating a new index on the EMP_Salaries table, using the CREATE INDEX T-SQL statement below:
在此步骤中,可以通过以更好的方式编写查询来实现查询性能上的增强。 例如,可以使用TOP子句来减小箭头的粗细,该子句会限制返回的行数。 另一方面,可以通过使用以下CREATE INDEX T-SQL语句在EMP_Salaries表上创建新索引来删除Filter运算符:
CREATE NONCLUSTERED INDEX [IX_EMP_Salaries_EMP_Salary] ON [dbo].[EMP_Salaries] ([EMP_Salary] )
And the generated Execution Plan, after these modifications, will be like:
经过这些修改后,生成的执行计划将类似于:
It is clear from the previous examples, the importance of the SQL Execution Plans in tuning the performance of the different T-SQL queries. Stay tuned for the next article in which we will show where the plans are saved in SQL Server memory and how to save the execution plans for reuse!
从前面的示例可以清楚地看出,SQL执行计划在调整不同T-SQL查询的性能中的重要性。 请继续阅读下一篇文章,我们将在其中显示计划在SQL Server内存中的保存位置以及如何保存执行计划以供重用!
目录 (Table of contents)
| SQL Server Execution Plans Overview |
| SQL Server Execution Plans Types |
| How to Analyze SQL Execution Plan Graphical Components |
| SQL Server Execution Plans Operators – Part 1 |
| SQL Server Execution Plans Operators – Part 2 |
| SQL Server Execution Plans Operators – Part 3 |
| SQL Server Execution Plans Operators – Part 4 |
| SQL Execution Plan enhancements in SSMS 18.0 |
| A new SQL Execution Plan viewer |
| Using the SQL Execution Plan for Query Performance Tuning |
| Saving your SQL Execution Plan |
| SQL Server执行计划概述 |
| SQL Server执行计划类型 |
| 如何分析SQL执行计划图形组件 |
| SQL Server执行计划操作员–第1部分 |
| SQL Server执行计划操作员–第2部分 |
| SQL Server执行计划操作员–第3部分 |
| SQL Server执行计划操作员–第4部分 |
| SSMS 18.0中SQL执行计划增强功能 |
| 新SQL执行计划查看器 |
| 使用SQL执行计划进行查询性能调整 |
| 保存您SQL执行计划 |
翻译自: https://www.sqlshack.com/using-the-sql-execution-plan-for-query-performance-tuning/
查询sql执行计划
查询sql执行计划_使用SQL执行计划进行查询性能调整相关推荐
- sql server 缓存_了解SQL Server查询计划缓存
sql server 缓存 Whenever a query is run for the first time in SQL Server, it is compiled and a query p ...
- sql server 缓存_搜索SQL Server查询计划缓存
sql server 缓存 Whenever a query is executed in SQL Server, its execution plan, as well as some useful ...
- sql server 统计_看SQL Server 2016中的新实时查询统计信息
sql server 统计 With the release of SQL Server 2016 also comes a great new feature to get a live view ...
- sql学习练习题_学习SQL:练习SQL查询
sql学习练习题 Today is the day for SQL practice #1. In this series, so far, we've covered most important ...
- mysql查询自定义列明_自定义sql查询出的结果集的列名都是数据库的字段名。
代码如下: @Override public DataPageDTO empsPage(EmpListPageParams params) { FileSqlManager fm = new File ...
- mysql查询和某人一样_使用sql语句实现查询某人的排名,分数相同排名相同
一.第一种形式排名 如:4个学生的分数分别是:100.90.90.80 排名结果为:第一.第二.第二.第三 SELECT count(DISTINCT score) FROM tbl_score WH ...
- mysql sql wait 写法_有关SQL语句写法注意的那些事情(原创整理)
前段时候针对开发做的SQL语句写法方面注意点的培训, 特意总结了一下,也共享一下. 书写SQL需要注意的若干问题(MySQL版) 一.基本问题 1,在系统中运行的SQL查询,先考虑一下能不能在Slav ...
- sql azure 语法_将SQL工作负载迁移到Microsoft Azure:服务选择
sql azure 语法 In the previous article, Migrating SQL workloads to Microsoft Azure: Planning the jump, ...
- sql azure 语法_方便SQL笔记本,用于在Azure Data Studio中进行故障排除
sql azure 语法 This article prepares a handy SQL Notebook for DBAs. You can use this notebook to troub ...
最新文章
- python range函数与numpy arange函数,xrange与range的区别
- Web.config 灵活配置
- Linux对外连接端口数限制
- linux运维相关操作(centos/Ubuntu)
- html 文本框 初始化,Flutter 文本框初始化时显示默认值
- for循环及break和continue的区别
- python封装:隐藏对象中的属性或方法(三分钟读懂)
- 让vue文件直接在浏览器中运行
- 剑指offer——面试题60:把二叉树打印成多行
- 【KDD20】TAdaNet: 用于图增强元学习的任务自适应网络
- IChat之天气模块相关
- C语言中bzero函数
- DXperience-7.1.1 Sources 源代下载
- Docker快速入门-腾讯云
- python deamon example
- veu项目中下载图片到本地
- hdoj 1163 Eddy's digital Roots(数学问题,继续分析) .
- 转载:asm volatile GCC的内嵌汇编语法 ATT汇编语言语法
- and desgin Vue页面,使用watch监视, <a-input>内的值, 自动计算出填入框的值,用vue中watch监听input组件的变化
- HTML5期末大作业:个人空间相册网页设计 (6页) HTML+CSS+JavaScript