HtmlAgilityPack/xpath
在网上发现了一个.NET下的HTML解析类库HtmlAgilityPack。HtmlAgilityPack是一个支持用XPath来解析HTML的类库,在花了一点时间学习了解HtmlAgilityPack的API和XPath之后,周公就做了一个简单的工具完成了这个功能,目前在CSDN上周公博文的收集地址为:http://blog.csdn.net/zhoufoxcn/archive/2011/06/23/6564578.aspx,在51CTO上周公博文的收集地址为http://zhoufoxcn.blog.51cto.com/792419/595327。HtmlAgilityPack是一个开源的.NET类库,它的主页是http://htmlagilitypack.codeplex.com/,在这里可以下载到最新版的类库及API手册,此外还可以下载到一个用于调试的辅助工具。
XPath简明介绍
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
下面列出了最有用的路径表达式:
nodename:选取此节点的所有子节点。
/:从根节点选取。
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.:选取当前节点。
..:选取当前节点的父节点。
例如有下面一段XML:
- <?xml version="1.0" encoding="utf-8"?>
- <Articles>
- <Article>
- <Title>在ASP.NET中使用Highcharts js图表</title>
- <Url>http://zhoufoxcn.blog.51cto.com/792419/537324</Url>
- <CreateAt type="en">2011-04-07</price>
- </Article>
- <Article>
- <Title lang="eng">Log4Net使用详解(续)</title>
- <Url>http://blog.csdn.net/zhoufoxcn/archive/2010/11/23/6029021.aspx</Url>
- <CreateAt type="zh-cn">2010年11月23日</price>
- </Article>
- <Article>
- <Title>J2ME开发的一般步骤</title>
- <Url>http://blog.csdn.net/zhoufoxcn/archive/2011/06/12/6540223.aspx</Url>
- <CreateAt type="zh-cn">2011年06月12日</price>
- </Article>
- <Article>
- <Title lang="eng">PowerDesign高级应用</title>
- <Url>http://zhoufoxcn.blog.51cto.com/792419/166415</Url>
- <CreateAt type="zh-cn">2007-09-08</price>
- </Article>
- </Articles>
针对上面的XML文件,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
/Articles/Article[1]:选取属于Articles子元素的第一个Article元素。
/Articles/Article[last()]:选取属于Articles子元素的最后一个Article元素。
/Articles/Article[last()-1]:选取属于Articles子元素的倒数第二个Article元素。
/Articles/Article[position()<3]:选取最前面的两个属于 bookstore 元素的子元素的Article元素。
//title[@lang]:选取所有拥有名为lang的属性的title元素。
//CreateAt[@type='zh-cn']:选取所有CreateAt元素,且这些元素拥有值为zh-cn的type属性。
/Articles/Article[Order>2]:选取Articles元素的所有Article元素,且其中的Order元素的值须大于2。
/Articles/Article[Order<3]/Title:选取Articles元素中的Article元素的所有Title元素,且其中的Order元素的值须小于3。
HtmlAgilityPack API简明介绍
在HtmlAgilityPack中常用到的类有HtmlDocument、HtmlNodeCollection、
HtmlNode和HtmlWeb等。
其流程一般是先获取HTML,这个可以通过HtmlDocument的Load()或LoadHtml()来加载静态内容,或者也可以HtmlWeb的Get()或Load()方法来加载网络上的URL对应的HTML。
得到了HtmlDocument的实例之后,就可以用HtmlDocument的DocumentNode属性,这是整个HTML文档的根节点,它本身也是一个HtmlNode,然后就可以利用HtmlNode的SelectNodes()方法返回多个HtmlNode的集合对象HtmlNodeCollection,也可以利用HtmlNode的SelectSingleNode()方法返回单个HtmlNode。
HtmlAgilityPack实战
下面是一个解析CSDN博客的代码实例:
- using System;
- using System.Collections.Generic;
- using System.Text;
- using HtmlAgilityPack;
- using System.Text.RegularExpressions;
- namespace CrawlPageApplication
- {
- /**
- * 作者:周公
- * 日期:2011-06-23
- * Blog: http://blog.csdn.net/zhoufoxcn or http://zhoufoxcn.blog.51cto.com
- * Weibo: http://weibo.com/zhoufoxcn
- */
- public class CSDN_Parser
- {
- private const string CategoryListXPath = "//html[1]/body[1]/div[1]/div[1]/div[2]/div[1]/div[1]/dl[1]/dd[3]/div[1]/ul[1]/li";
- private const string CategoryNameXPath = "//li[1]/a[2]";
- /// <summary>
- /// 分析博客首页
- /// </summary>
- /// <param name="url"></param>
- /// <returns></returns>
- public static List<Category> ParseIndexPage(string url)
- {
- Uri uriCategory=null;
- List<Category> list = new List<Category>(40);
- HtmlDocument document = new HtmlDocument();
- //注意,这里省略掉了使用本人其它类库中加载URL的类,而是直接加载本地的HTML文件
- //string html = HttpWebUtility.ReadFromUrl(url, Encoding.UTF8);
- //document.LoadHtml(html);
- document.Load("CSDN_index.html", Encoding.UTF8);
- HtmlNode rootNode = document.DocumentNode;
- HtmlNodeCollection categoryNodeList = rootNode.SelectNodes(CategoryListXPath);
- HtmlNode temp = null;
- Category category = null;
- foreach (HtmlNode categoryNode in categoryNodeList)
- {
- temp = HtmlNode.CreateNode(categoryNode.OuterHtml);
- category = new Category();
- category.Subject = temp.SelectSingleNode(CategoryNameXPath).InnerText;
- Uri.TryCreate(UriBase, temp.SelectSingleNode(CategoryNameXPath).Attributes["href"].Value, out uriCategory);
- category.IndexUrl = uriCategory.ToString();
- category.PageUrlFormat=category.IndexUrl+"?PageNumber={0}";
- list.Add(category);
- Category.CategoryDetails.Add(category.IndexUrl, category);
- }
- return list;
- }
- }
- }
当然实现类似的解析51CTO的博客文章数据的代码如下:
- using System;
- using System.Collections.Generic;
- using System.Text;
- using HtmlAgilityPack;
- using System.Text.RegularExpressions;
- namespace CrawlPageApplication
- {
- /**
- * 作者:周公
- * 日期:2011-06-23
- * Blog: http://blog.csdn.net/zhoufoxcn or http://zhoufoxcn.blog.51cto.com
- * Weibo: http://weibo.com/zhoufoxcn
- */
- public class CTO_Parser
- {
- private static Encoding PageEncoding = Encoding.GetEncoding("gb2312");
- private static readonly Uri UriBase = new Uri("http://zhoufoxcn.blog.51cto.com");
- private static string CategoryListXPath = "/html[1]/body[1]/div[5]/div[1]/div[1]/div[2]/ul[1]/li";
- private static string CategoryNameXPath = "/li[1]/a[1]";
- /// <summary>
- /// 分析博客首页
- /// </summary>
- /// <param name="url"></param>
- /// <returns></returns>
- public static List<Category> ParseIndexPage(string url)
- {
- Uri uriCategory = null;
- List<Category> list = new List<Category>(40);
- HtmlDocument document = new HtmlDocument();
- //string html = HttpWebUtility.ReadFromUrl(url, PageEncoding);
- //document.LoadHtml(html);
- document.Load("51cto_index.html", PageEncoding);
- HtmlNode rootNode = document.DocumentNode;
- HtmlNodeCollection categoryNodeList = rootNode.SelectNodes(CategoryListXPath);
- HtmlNode temp = null;
- Category category = null;
- foreach (HtmlNode categoryNode in categoryNodeList)
- {
- temp = HtmlNode.CreateNode(categoryNode.OuterHtml);
- if (temp.SelectSingleNode(CategoryNameXPath).InnerText != "全部文章")
- {
- category = new Category();
- category.Subject = temp.SelectSingleNode(CategoryNameXPath).InnerText;
- Uri.TryCreate(UriBase, temp.SelectSingleNode(CategoryNameXPath).Attributes["href"].Value, out uriCategory);
- category.IndexUrl = uriCategory.ToString();
- category.PageUrlFormat = category.IndexUrl + "/page/{0}";
- list.Add(category);
- Category.CategoryDetails.Add(category.IndexUrl, category);
- }
- }
- return list;
- }
- }
- }
在上面的代码中出现了一个Category类,该类的定义如下:
为了鼓励大家动手尝试以及在本项目中使用了周公的私家类库,所以不提供全部源代码下载,这里提供周公操作的最终软件界面:
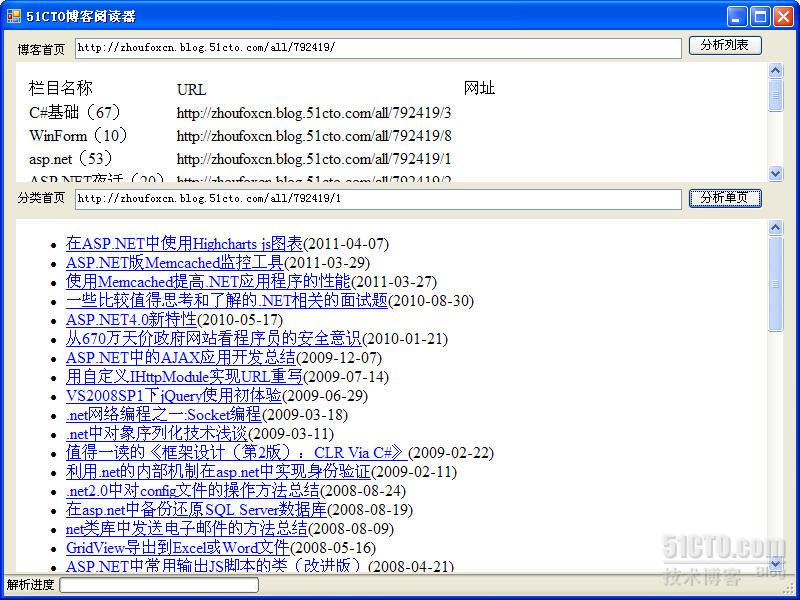
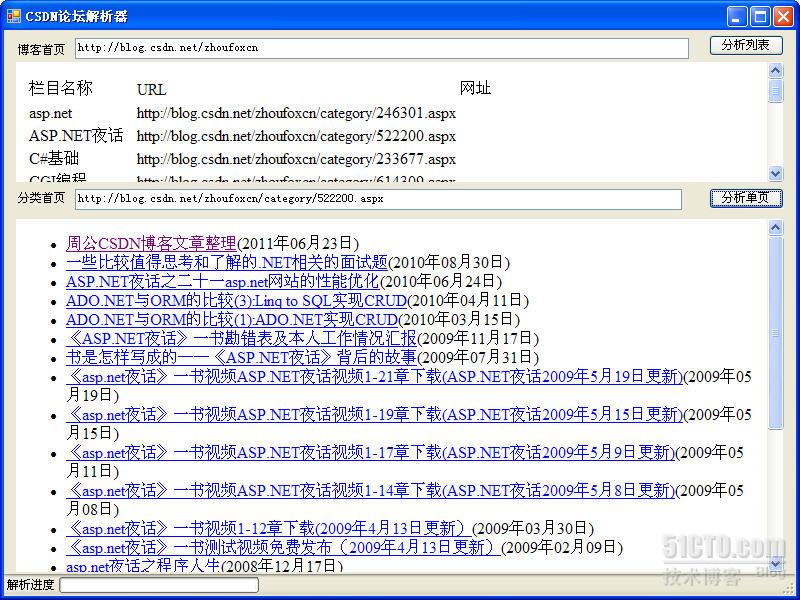
总结:HtmlAgilityPack确实是一个功能强大、体积小的开源HTML解析类库,在本篇仅仅是介绍了其中几个类的用法,但光这些就足以供周公快速实现了许久没有实现的功能,如果让周公用正则表达式来实现类似的功能,时间肯定要比用这个长得多。
说明:周公最近也在琢磨一些关于微博的应用,如果有相同爱好者或者在使用微博的读者,请围观周公的微博,网址是:http://weibo.com/zhoufoxcn。
2011-06-24
周公
转载于:https://www.cnblogs.com/wangrsh2010/archive/2011/09/22/2184935.html
HtmlAgilityPack/xpath相关推荐
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
[转]C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子) 第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流 ...
- C# 网络爬虫+HtmlAgilityPack+Xpath+爬虫工具类的封装的使用
目录 1 工具准备 2 思路准备 3 附加知识准备--XPath 简述 看看例子 用XPath来寻找标签 获取所有同名的标签 获取指定标签 一个实例 最后的补充 4 代码实现 5 爬虫工具类的封装 6 ...
- Python带你轻松进行网页爬虫
前不久DotNet开源大本营通过为.NET程序员演示如何在.NET下使用C#+HtmlAgilityPack+XPath进行网页数据的抓取,从而为我们展示了HtmlAgilitypack利器的优点和使 ...
- 【原创】C#玩高频数字彩快3的一点体会
购彩风险非常高,本人纯属很久以前对数字高频彩的一点研究.目前已经远离数字彩,重点研究足球篮球比赛资料库和赛果预测. 这是一篇在草稿箱保存了1年多的文章,一直没发现,顺便修改修改分享给大家.以后会有更多 ...
- linux php com,Linux_COM简介,世上无难事,只要肯登攀, - phpStudy
COM简介 "世上无难事,只要肯登攀",所以你要有信心成为一个COM程序员,而且你一定能. 事实上,我们每次设置文本编程控件的Text属性时,就已经在使用COM,同样在DAO数据控 ...
- 老蜗牛写采集:网络爬虫(二)
短小精悍的xNet 这个一个俄国牛人写的开源工具,为啥说他强悍了,因为他将所有Http协议的底层都实现了一遍,这有啥好处?只要你是写爬虫的,都会遇到一个让人抓狂的问题,就是明明知道自己Http请求头跟 ...
- 【笔记】汉字拼音互转(带音标和笔顺)共20842字
1 爬取拼音和笔顺 拼音爬自https://zidian.900cha.com/.数据文件汉字拼音带音标和笔顺共20842字("壭亪寽兯嚸"这五个字没收) 笔顺爬自http:// ...
- HtmlAgilityPack中SelectSingleNode的XPath和CSS选择器
XPath和CSS选择器 原文:http://ejohn.org/blog/xpath-css-selectors 最近,我做了很多工作来实现一个同时支持XPath和CSS 3的解析器,令我惊讶的是: ...
- [翻译]使用HtmlAgilityPack更好的HTML分析和验证
让我们面对它,有时候,当您正在编写自定义的提取和验证规则时Microsoft.VisualStudio.TestTools.WebTesting.HtmlDocument 类不会剪切它.HtmlDoc ...
最新文章
- oracle体系结构-内存管理
- mysql killed 不掉,解决:kernel: Out of memory: Killed process 15967, UID 27, (mysqld).
- windows php cli 后台运行_【续】windows环境redis未授权利用方式梳理
- android第五天晚:surfaceView
- *【POJ - 1860】Currency Exchange (单源最长路---Bellman_Ford算法判正环)
- 编译 linux 3,linux内核的编译(3)
- Power BI应用案例:淘宝用户行为分析实战
- 交叉编译linux内核实例(最详细)总结
- 【模拟】Parity
- C++三角定位法求两圆交点坐标
- VBA操作WORD(三):设置页面
- cocos2dx-lua制作新手引导
- 中学化学教学参考杂志社中学化学教学参考编辑部2022年第15期目录
- 有感无刷电机正反转电流差别大
- 不是所有电子签名都具备法律效力
- 应急响应之Windows权限维持--隐藏篇
- 华为路由器:NAT地址转换技术
- 塑胶模具设计公式参数计算工具
- 苹果秋季发布会打破惯例:最强芯片A14先用在iPad上!
- 30天自制操作系统:第十二天 定时器(1)