BERT: 理解上下文的语言模型
BERT 全名为 Bidrectional Encoder Representations from Transformers, 是 Google 以无监督的方式利用大量无标注文本生成的语言代表模型,其架构为 Transforer 中的 Encoder.
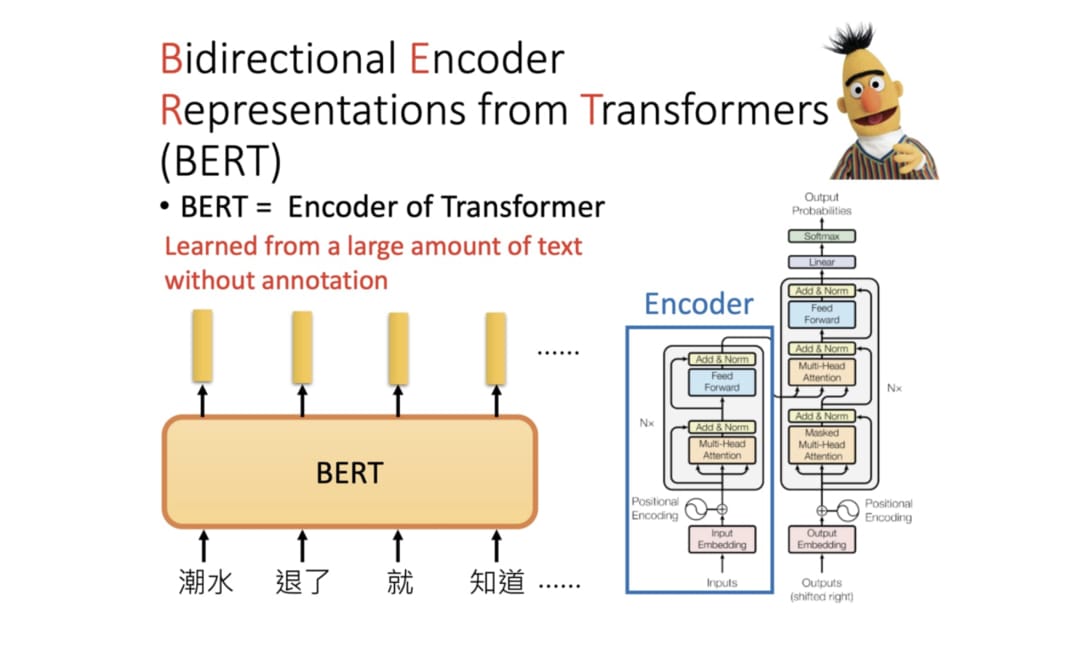
以前在处理不同的 NLP 任务通常需要不同的 Language Model (LM),而设计这些模型并测试其性能需要不少的人力,时间以及计算资源。 BERT 模型就在这种背景下应运而生,我们可以将该模型套用到多个 NLP 任务,再以此为基础 fine tune 多个下游任务。fine tune BERT 来解决下游任务有5个简单的步骤:
- 准备原始文本数据
- 将原始文本转化成 BERT 相容的输入格式
- 利用 BERT 基于微调的方式建立下游任务模型
- 训练下游任务模型
- 对新样本做推论
那 BERT 模型该怎么用呢,thanks to 开源精神,BERT 的作者们已经开源训练好的模型,我们只需要使用 TensorFlow or PyTorch 将模型导入即可。
import torch
from transformers import BertTokenizer
from IPython.display import clear_outputPRETRAINED_MODEL_NAME = "bert-base-chinese" # 指定简繁中文 BERT-BASE 预训练模型# 取得此预训练模型所使用的 tokenizer
tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)clear_output()
上述代码选用了有 12 层 layers 的 BERT-base, 当然你还可以在 Hugging Face 的 repository 找到更多关于 BERT 的预训练模型:
- bert-base-chinese
- bert-base-uncased
- bert-base-cased
- bert-base-german-cased
- bert-base-multilingual-uncased
- bert-base-multilingual-cased
- bert-large-cased
- bert-large-uncased
- bert-large-uncased-whole-word-masking
- bert-large-cased-whole-word-masking
这些模型的区别主要在于:
- 预训练步骤使用的文本语言
- 有无分大小写
- 模型层数
- 预训练时遮住 wordpieces 或是整个 word
接下来我就简单的介绍一个情感分类任务来帮大家联系 BERT 的 fine tune
1.准备原始文本数据
首先加载我们需要用到的库:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import torch
import transformers as tfs
import warningswarnings.filterwarnings('ignore')
然后加载数据集,本文采用的数据集是斯坦福大学发布的一个情感分析数据集SST,其组成成分来自于电影的评论。
train_df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)train_set = train_df[:3000] #取其中的3000条数据作为我们的数据集
print("Train set shape:", train_set.shape)
train_set[1].value_counts() #查看数据集中标签的分布
得到输出如下:
Train set shape: (3000, 2)
1 1565
0 1435
Name: 1, dtype: int64
可以看到积极与消极的标签对半分。
这是数据集的部分内容:
0 1
0 a stirring , funny and finally transporting re... 1
1 apparently reassembled from the cutting room f... 0
2 they presume their audience wo n't sit still f... 0
3 this is a visually stunning rumination on love... 1
4 jonathan parker 's bartleby should have been t... 1
... ... ...
6915 painful , horrifying and oppressively tragic ,... 1
6916 take care is nicely performed by a quintet of ... 0
6917 the script covers huge , heavy topics in a bla... 0
6918 a seriously bad film with seriously warped log... 0
6919 a deliciously nonsensical comedy about a city ... 1
2. 将原始文本转化成 BERT 相容的输入格式
我们对原来的数据集进行一些改造,分成 batch_size 为 64 大小的数据集,以便模型进行批量梯度下降
sentences = train_set[0].values
targets = train_set[1].values
train_inputs, test_inputs, train_targets, test_targets = train_test_split(sentences, targets)batch_size = 64
batch_count = int(len(train_inputs) / batch_size)
batch_train_inputs, batch_train_targets = [], []
for i in range(batch_count):batch_train_inputs.append(train_inputs[i*batch_size : (i+1)*batch_size])batch_train_targets.append(train_targets[i*batch_size : (i+1)*batch_size])
3. 利用 BERT 基于微调的方式建立下游任务模型
在这里我们采取 fine-tuned 使得 Bert 与线性层一起参与训练,反向传播会更新二者的参数,使得 Bert 模型更适合这个分类任务。
class BertClassificationModel(nn.Module):def __init__(self):super(BertClassificationModel, self).__init__() model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased') self.tokenizer = tokenizer_class.from_pretrained(pretrained_weights)self.bert = model_class.from_pretrained(pretrained_weights)self.dense = nn.Linear(768, 2) #bert默认的隐藏单元数是768, 输出单元是2,表示二分类def forward(self, batch_sentences):batch_tokenized = self.tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,max_len=66, pad_to_max_length=True) #tokenize、add special token、padinput_ids = torch.tensor(batch_tokenized['input_ids'])attention_mask = torch.tensor(batch_tokenized['attention_mask'])bert_output = self.bert(input_ids, attention_mask=attention_mask)bert_cls_hidden_state = bert_output[0][:,0,:] #提取[CLS]对应的隐藏状态linear_output = self.dense(bert_cls_hidden_state)return linear_output
4.训练下游任务模型
#train the model
epochs = 3
lr = 0.01
print_every_batch = 5
bert_classifier_model = BertClassificationModel()
optimizer = optim.SGD(bert_classifier_model.parameters(), lr=lr, momentum=0.9)
criterion = nn.CrossEntropyLoss()for epoch in range(epochs):print_avg_loss = 0for i in range(batch_count):inputs = batch_train_inputs[i]labels = torch.tensor(batch_train_targets[i])optimizer.zero_grad()outputs = bert_classifier_model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()print_avg_loss += loss.item()if i % print_every_batch == (print_every_batch-1):print("Batch: %d, Loss: %.4f" % ((i+1), print_avg_loss/print_every_batch))print_avg_loss = 0
5.对新样本做推论
# eval the trained model
total = len(test_inputs)
hit = 0
with torch.no_grad():for i in range(total):outputs = bert_classifier_model([test_inputs[i]])_, predicted = torch.max(outputs, 1)if predicted == test_targets[i]:hit += 1print("Accuracy: %.2f%%" % (hit / total * 100))
预测结果如下:
Accuracy: 82.27%
由此可见,经过微调后的模型效果还不错。
好了,这篇 blog 就讲到这里吧。
我是 Anthony, 我们下次再见.
参考文章:
- 进击的 BERT: NLP 界的巨人之力与迁移学习
- 基于 BERT 模型的文本情感分类实例解析
- 李宏毅教授介绍 ELMO, BERT, GPT 的视频
BERT: 理解上下文的语言模型相关推荐
- 语言模型BERT理解
一.BERT概述 BERT是由Google在2018年提出的一种预训练语言模型.BERT的创新之处在于采用了双向Transformer编码器来生成上下文相关的词向量表示. 传统的单向语言模型只考虑了左 ...
- ELMo:基于上下文的语言模型,5分钟构建语义搜索引擎代码实战
2019-12-05 20:53:41 作者:Josh Taylor 编译:ronghuaiyang 导读 5分钟内构建一个基于ELMo的语义搜索引擎,在NLP中,上下文就是一切. 使用最先进的ELM ...
- 现有大语言模型(ChatGPT)的上下文理解能力还是假象吗?
人工智能的一个重要方面是人机交互智能,人机交互智能的核心在于机器对自然语言的理解,而机器翻译是衡量这种理解的有效方式. 按照目前LLM的技术路线,仅仅靠计算语言形式的概率能否产生人类式理解还是未知,但 ...
- 基于TensorRT的BERT实时自然语言理解(上)
基于TensorRT的BERT实时自然语言理解(上) 大规模语言模型(LSLMs)如BERT.GPT-2和XL-Net为许多自然语言理解(NLU)任务带来了最先进的精准飞跃.自2018年10月发布以来 ...
- BERT通俗笔记:从Word2Vec/Transformer逐步理解到BERT
前言 我在写上一篇博客<22下半年>时,有读者在文章下面评论道:"july大神,请问BERT的通俗理解还做吗?",我当时给他发了张俊林老师的BERT文章,所以没太在意. ...
- NLP教程笔记:BERT 双向语言模型
NLP教程 TF_IDF 词向量 句向量 Seq2Seq 语言生成模型 CNN的语言模型 语言模型的注意力 Transformer 将注意力发挥到极致 ELMo 一词多义 GPT 单向语言模型 BER ...
- Bert算法:语言模型-BERT详细介绍
本文的目的是向NLP爱好者们详细解析一个著名的语言模型-BERT. 全文将分4个部分由浅入深的依次讲解. 1.Bert简介 BERT是2018年10月由Google AI研究院提出的一种预训练模型. ...
- NLP 第五周 语言模型,bert(2)
BERT类预训练语言模型 我们传统训练网络模型的方式首先需要搭建网络结构,然后通过输入经过标注的训练集和标签来使得网络可以直接达成我们的目的.这种方式最大的缺点就是时间长,因为我们对于模型权重的初始化 ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
预训练语言模型整理(ELMo/GPT/BERT...)简介 预训练任务简介# 自回归语言模型# 自编码语言模型 预训练模型的简介与对比 ELMo 细节# ELMo的下游使用# GPT/GPT2# GP ...
最新文章
- 组建核心团队时的困惑
- Java 取得文件名的后缀
- 《机器学习》课程视频(数据处理、模型构建与优化)
- 牛客网编程题python输入输出_牛客网算法题目记录
- 牵引力教育就业数据显示:很多大学毕业就等于失业?
- Asp.Net MVC4入门指南(9):查询详细信息和删除记录
- K8S Learning(4)——Namespace
- java对象引用出错_上传图片错误:尝试在空对象引用上调用虚拟方法’java.lang.String android.net.Uri.getLastPathSegment()’...
- 解决Eclipse建立Maven项目后无法建立src/main/java资源文件夹的办法
- 一招教你数据仓库如何高效批量导入与更新数据
- 试问我们都在做些什么类型的测试?
- winform程序的皮肤问题
- 大数据导论章节答案_大数据概论智慧树章节答案
- Linux设备驱动程序(LDD)中snull的编译问题
- 计算机病毒note01
- MATLAB struct函数(结构体数组)
- python编程自学网-python自学网
- 系统服务器cpu需求测算,服务器cpu占用率多少算正常
- 蓝牙LMP剖析(二)
- AI插画师:生成对抗网络