IBM SPSS Modeler 18.1最新版本正式发布 | 附下载
IBM 数据挖掘分析平台IBM SPSS Modeler在市场上一直占据领导者地位,其专业性及易用性一直受到广大用户的喜爱,该平台也不负众望,我们的研发团队一直致力于不断的技术更新及功能的提升,最新版本IBM SPSS Modeler 18.1于2017-6-20正式发布,该版本又给我们带来了哪些新的功能及技术要点,我们将在本文做介绍,需要更进一步了解的,可以随时与我们联系。
首先,该版本从3个大的方面做了增强,分别是:

接下来一一为大家做介绍:
一、进一步增强和扩展与开源技术的集成
从IBM SPSS Modeler 16.0版本开始,就已经开始与开源平台R与Python的集成,在最新版本中,集成力度增强。
1.新增Python编写的功能节点
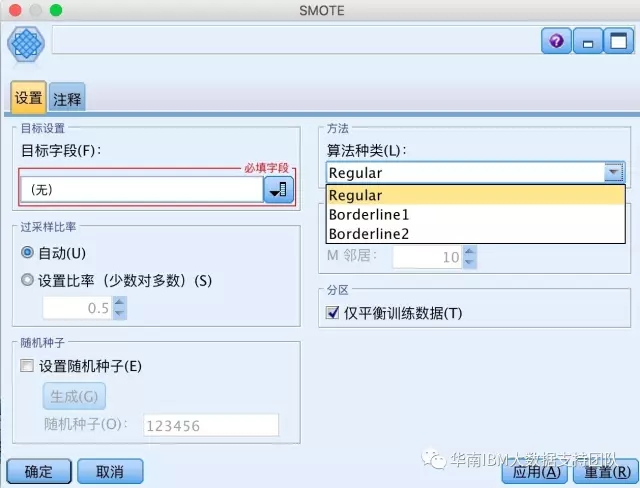
在该版本,最受关注的一个功能就是在IBM SPSS Modeler下方的面板中,新增了Python面板,并新增加了4个Python编写的节点功能,包括【SMOTE】、【XGBoost Liner】、【XGBoost树】以及【一类SVM】,如下图:

接下来我们简单介绍下这几个节点的功能:
SMOTE

在数据分析过程中,经常会遇到数据集不平衡的问题,不平衡数据集指的是数据集内各类样本点数目相差较大的数据集,比如做设备故障预测的时候,出现故障的设备可能只有1%,而99%的设备是正常的,这时候,数据的不平衡,如果不加以处理,会造成模型无法生成或者模型效果很差,SMOTE就是解决数据不平衡问题的高级技术,SMOTE全称是 SyntheticMinority Over-sampling Technique, 在IBM SPSS Modeler中,有【平衡】节点可以处理数据不平衡的问题,但只是简单的对数据集进行复制或删减,有时候效果并不好,而SMOTE对不平衡数据集进行预处理,通过利用已有样本以及其近邻,合成新样本数据对少数类进行“过采样”,效果要更好一些,并且该节点还提供SMOTE算法的提升算法,包括Borderline1-SMOTE和Borderline2-SMOTE,可最大限度解决数据不平衡的问题。
XGBoost树和XGBoost Linear

XGBoost是使用梯度提升框架实现的高效、灵活、可移植的机器学习库,全称是eXtreme Gradient Boosting,在很多数据分析竞赛中(比如Kaggle),该算法都被实践证明是表现很好的算法,因此在实际应用中,推荐大家尝试使用。
在IBM SPSS Modeler 18.1版本中,集成了XGBoost Tree和XGBoost Linear两个算法,XGBoost Tree是将树模型用作基本模型的梯度提升算法的高级实现。提升算法以迭代方式学习弱分类器,然后将它们添加到最终的强分类器中。XGBoost Tree 具有很高的灵活性,并提供了很多参数调整。
XGBoost Linear是将线性模型用作基本模型的梯度提升算法的高级实现。提升算法以迭代方式学习弱分类器,然后将它们添加到最终的强分类器中。
一类SVM

一类 SVM 节点使用无监督学习算法,此节点可用于新内容检测,它将检测指定样本集的软边界,以便按是否属于该集合对新点进行分类。
这几个算法都是由Python语言编写,因此在该版本中,IBM SPSS Modeler已经集成了Python 2.7环境,用户不需要再去安装Python环境以及IBM SPSS Modeler与Python 的集成插件,即可直接运行Python算法。
2.新增直接运行R或Python的功能节点
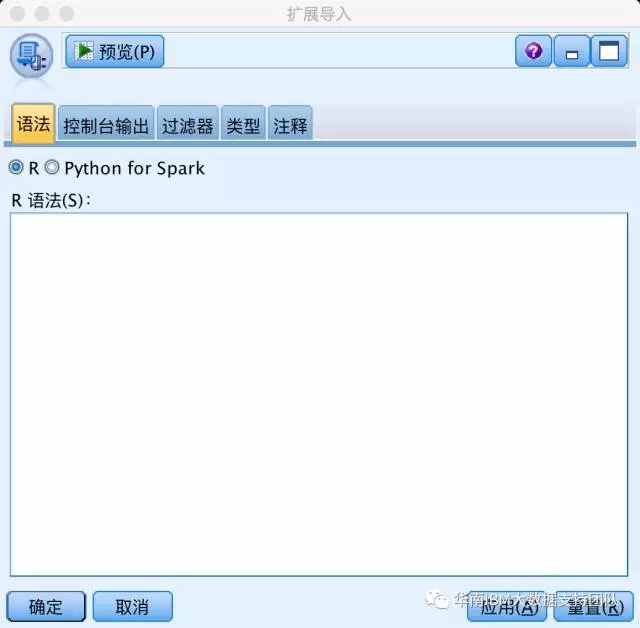
在该新版本中,可直接使用R或Python for Spark构建【扩展导入】、【扩展转换】、【扩展输出】和【扩展导出】的功能节点,如下图:

比如在源节点中的【扩展导入】,用户可以自由选择使用R或Python for Spark语法实现,如果使用R,可以是任何版本的R(官方建议使用R 3.3.3),而不像之前的18.0版本一样,要求必须是3.2.2,而如果是Python语法,因为已经集成了Python 2.7版本,所以用户直接用就可以了,需要注意的是Python 2与Python 3某些语法的差别。
3.IBM SPSS Modeler 18.1已集成了Spark 2.0
当前版本已经集成了Spark 2.0,可直接利用其技术优势加速计算运行效率。
二、与其它服务的集成
1.与优化引擎ILOG CPLEX的集成
CPLEX优化

在该版本中,新增了【CPLEX优化】节点,可以通过优化编程语言(OPL)模型文件来使用基于优化的复杂计算,来实现优化分析场景。
2.轻松导入天气数据
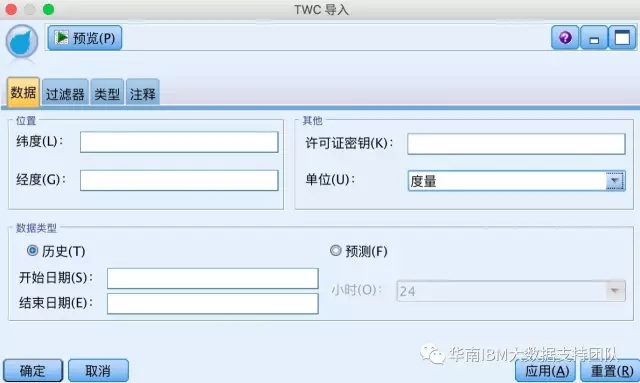
TWC导入

天气情况的变化越来越大程度影响着人们的行为习惯,因此天气数据的重要性也越来越为人们所重视,在最新版本中,新增了TWC导入(The Weather Company)节点,这也是在IBM收购了该公司之后,将其数据资产应用于IBM SPSS Modeler分析平台中来的一次全新尝试。
在该节点中,您可以自由输入需要的地理位置信息(经纬度)以及时间信息(开始日期与结束日期),即可获取该时空的天气数据,包括有:latitude(纬度)、longitude(经度)、time(时间)、day_ind(指示夜间或白天)、temp(温度)、dewpt(露点)、rh(相对湿度)、heat_index(热指数)、wc(风向)、wx_phrase(多云、少云等)、pressure(气压)、clds(云)、vis(能见度)、wspd(风速)、gust(阵风/雨)、wdir(风寒指数)、uv_index(紫外线指数)等。
当然,天气数据作为数据资产,不是免费使用,是需要购买许可证密钥的。
3.支持更多的数据源/Hadoop分布式文件系统
新版本新增更多的数据源连接,包括如下:
·Apache Hive 1.2.1 including SQLoptimization
·Cloudera Impala
·Hortonworks HDP 2.5 datathrough BigSQL
·IBM Biginsights for ApacheHadoop
·MapR
·Huawei Fusion Insight on RedHat 7
·Non-wire driver for Oracle andOracle ODBC drivers are now supported
·PostgreSQL
·HP Vertica now supports SQLoptimization
三、激发分析潜能
1.文本分析功能的增强
IBM SPSS Modeler提供的文本分析可以连接不同数据源,如下图,主要包括文件、网页、文本等。

提供的文本分析功能支持多种语言,包括英语、荷兰语、法语、德语、意大利语、葡萄牙语、西班牙语等,除了提供基本语言包之外,还提供针对不同语言,多种应用场景的词库包,可满足不同应用场景的文本分析,比如客户关系管理、满意度分析、品牌管理、客户关怀、欺诈分析等,客户只需要在原来的词库基础上,做些简单的调整修改即可直接使用。
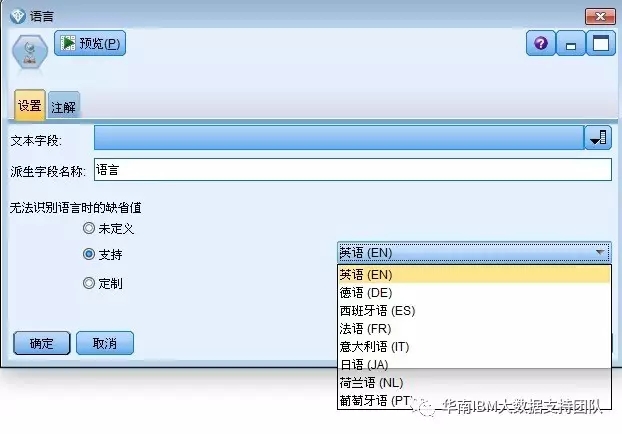
语言

新版本中,增加了【语言】节点,可针对文本中存在多种语言的语言识别及分析。
2.增强 Hadoop分布式系统上运行的算法性能
主要包括几个方面的性能提升:
1.优化了AS Spark Cache的管理:在一个Job中尽可能的重用了缓存的数据,并且在不再需要时继续清除cache;
2.支持使用Spark的资源动态分配机制:允许AS在需要时申请更多的资源,使用完毕后及时释放;
3.优化了AS的内部执行流程,尽量的降低磁盘和网络传输的IO操作;
4.在Hive宽表或者Hive Metastore非常庞大的情况下,改善了在AS管理页面上创建HCatalog类型的数据源时的性能。
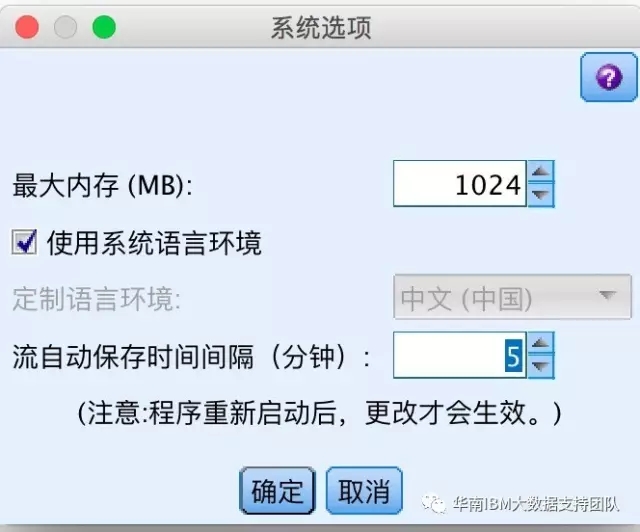
3.自动保存功能
为了防止由于突然宕机造成的文件未保存的情况,默认情况下,系统自动5分钟保存一次,可以工具-->选项-->系统选项中更改。
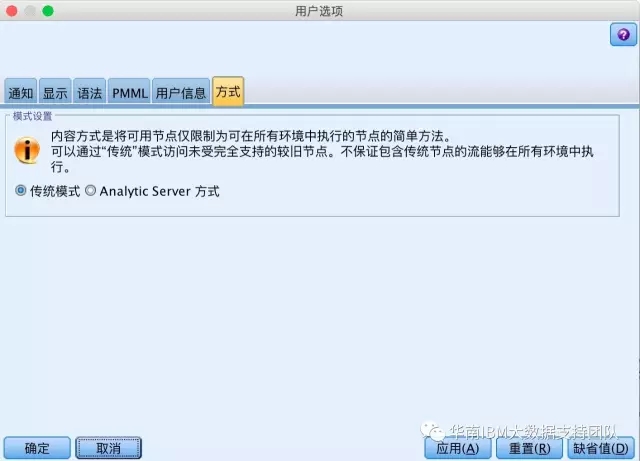
4.灵活的功能节点模式设置
为了更好地区分哪些功能节点运行于Hadoop分布式文件系统上,哪些运行于传统关系型数据库或文本文件上,用户可以在工具-->选项-->用户选项的【方式】面板中,选择【传统模式】或者是【Analytic Server方式】,如果是前者,则所有功能节点都显示出来,如果选择的是后者,则只显示能够在Hadoop平台上运行的功能节点,这样可以避免在使用Hadoop数据源时候,搞不清楚哪些节点能够运行,哪些节点不能够运行的情况出现。
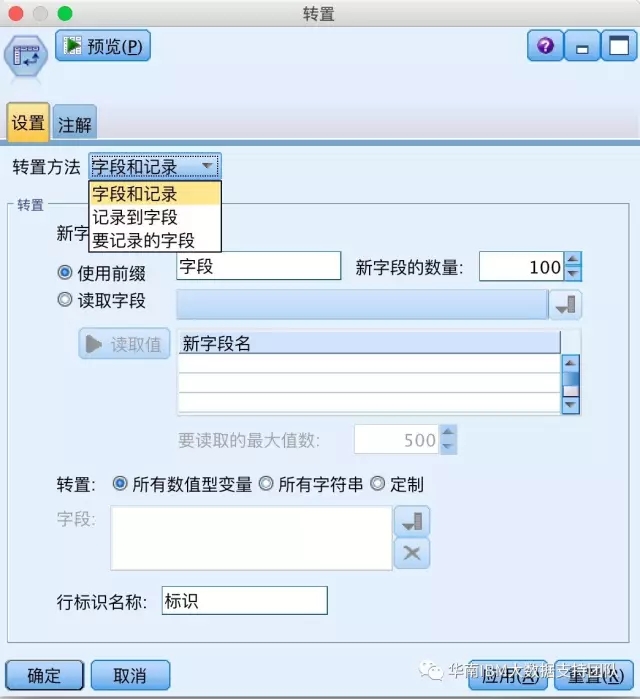
5.增强某些节点的功能
比如:
【转置】节点增加了转置方法选项,可以更灵活地处理数据。
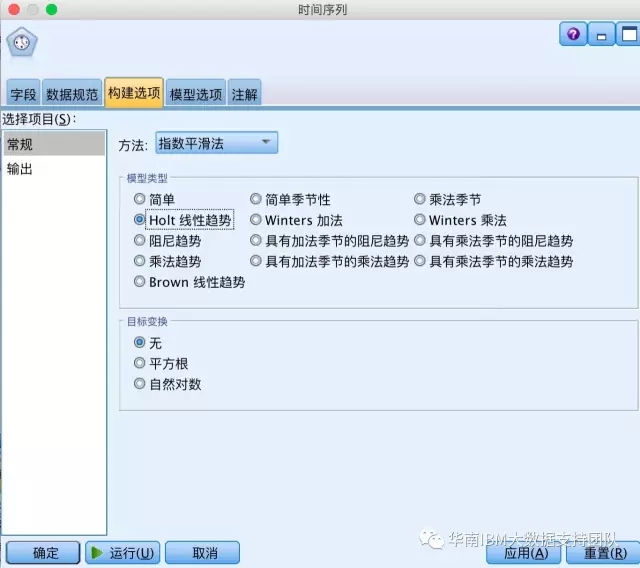
【时间序列】节点增加了算法选项
以上就是IBM SPSS Modeler 18.1最新版本的功能介绍,感兴趣的朋友,可点击下方的链接在我们的官网上下载最新试用版。
最新试用版下载:https://www.evget.com/product/3729/download
IBM SPSS Modeler 18.1最新版本正式发布 | 附下载相关推荐
- 解决SPSS Modeler 18 过期
SPSS Modeler 18 如果已经过期,破解就没法用了.破解程序只能在IBM SPSS Modeler 没有结束试用其实才可以起作用. 附上,试用过期后,重新试用的方法: 在临时许可过期之后, ...
- SPSS Modeler 18.0 新功能权威解读(文末附下载地址)
在今年,IBM SPSS Modeler发布了新版本18.0,那么在这次新版本的更新中,我们可以看到更新的幅度还是比较大的.接下来,浩彬老撕将给大家介绍18.0版本中一些新的功能,同时也将为大家详细介 ...
- php 集成 spss,〖SPSS Modeler〗 IBM SPSS Modeler 整合不同数据库之间的数据
来自IBM DEVELOPERWORKS 简介 由于目前企业客户的业务量和数据量都在不断的提高,随着企业的发展,很多企业的数据存储都不局限于同一个数据库上,如果要对这些存储在不同数据库上的数据进行处理 ...
- IBM SPSS Modeler 14.1下载安装及注册详细教程
下载IBM SPSS Modeler 14.1软件,包含IBM SPSS Modeler14.1 32位及IBM SPSS Modeler 14.1 64位版本及注册文件(破解补丁lservrc,32 ...
- IBM SPSS Modeler 【2】 两步聚类
IBM SPSS Modeler 实验 1.2."两步"聚类分析实验 接下来,继续进行"两步聚类分析模型"的实验. (1) SPSS Mode ...
- 《IBM SPSS Modeler数据与文本挖掘实战》之常用数据挖掘软件
根据数据挖掘软件的开发目的和用途,一般可以分为专业型和通用型两种.专业型数据挖掘软件一般是针对某个特定领域的问题提供解决方案,在设计算法的时候充分考虑到数据的规模.类型以及研究者的需求等特点,并作了优 ...
- 非常值得收藏的 IBM SPSS Modeler 算法简介
IBM SPSS Modeler以图形化的界面.简单的拖拽方式来快速构建数据挖掘分析模型著称,它提供了完整的统计挖掘功能,包括来自于统计学.机器学习.人工智能等方面的分析算法和数据模型,包括如关联.分 ...
- 《IBM SPSS Modeler数据与文本挖掘实战》之文本挖掘算法
随着文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术.现代文本分类和聚类领域面临巨大的挑战,而且随着学者研究的不断深入,其中的一些深层次问题也逐渐暴露出来,一些问题也已经成为本学科进一 ...
- IBM SPSS Modeler使用技巧 ----参数及全局变量的使用
在使用IBM SPSS Modeler过程中,有一些小技巧可能容易被大家忽略,而它们却是可以帮助我们更加高效.方便地实现我们需要的功能,今天给大家介绍参数及全局变量的使用. 什么时候需要用到参数? 在 ...
最新文章
- java表单 mysql 乱码_java web当中表单提交到后台出现乱码的解决方法
- JavaScript 输出
- spark官方文档_Apache Spark 文档传送门
- 使用DispatchAction类,为你的系统减肥!
- java paysign_微信支付签名算法java版本-其他地方都可通用
- LANGUAGE MODELS ARE OPEN KNOWLEDGE GRAPHS —— 读后总结
- 网络协议之:加密传输中的NPN和ALPN
- 1. ansible-playbook 变量定义与引用
- 25 The Go image/draw package go图片/描绘包:图片/描绘包的基本原理
- STL 标准容器的选择
- java js加密_JS加密解密
- 传统蓝牙协议栈 串口协议SPP(Serial Port Profile)概念介绍
- Navicat导入mdf文件(用导入向导)
- (八) 项目干系人管理
- 计算机的任务管理器不显示不出来,开机后桌面不显示图标,也调不出任务
- 数字化转型,有你有我
- 网络数据包发送工具PacketSender中文源码
- 面试前夕,我建议你还是先来看看阿里和京东面试都问些啥?
- SCons教程 (2) SConstruct 文件介绍
- C++ 类Pimpl手法