lstm预测单词_从零开始理解单词嵌入| LSTM模型|
lstm预测单词
Yo reader! I am Manik. What’s up?.
哟读者! 我是曼尼克 。 这是怎么回事?。
Hope you’re doing great and working hard for your goals. If not, it’s never late. Start now, at this very moment.
希望您做得很好,为实现目标而努力。 如果没有,那就永远不会晚。 从这一刻开始。
With this piece of information, you’ll walk away with a clear explanation on Sequence and Text processing for Deep Neural Networks which includes:
掌握了这些信息后,您将获得有关深度神经网络的序列和文本处理的清晰说明,其中包括:
- What’s one-hot Encoding?
什么是一键编码? - OneHot Encoding with keras.
用keras进行OneHot编码。 - What are word embeddings and their advantage over One-Hot encoding?
什么是词嵌入及其相对于一键编码的优势? - What are word embeddings trying to say?
单词嵌入试图说什么? - A complete example of converting raw text to word embeddings in keras with an LSTM and GRU layer.
使用LSTM和GRU层在keras中将原始文本转换为单词嵌入的完整示例。
if you want to learn about LSTMs, you can go here
如果您想了解LSTM,可以点击这里
让我们开始吧。 (Let’s get started.)
“Yours and mine ancestors had run after a mastodons or wild boar, like an olympic sprinter, with a spear in hand covering themselves with leaves and tiger skin, for their breakfast” — History
“您和我的祖先曾像奥林匹克短跑运动员一样追捕过猛兽或野猪,手拿长矛遮住自己的叶子和老虎皮作为早餐” –历史
The above sentence is in textual form and for neural networks to understand and ingest it, we need to convert it into some numeric form. Two ways of doing that are One-hot encoding and the other is Word embeddings.
上面的句子是文本形式的,为了让神经网络理解和吸收它,我们需要将其转换为某种数字形式。 两种方法是一种热编码 ,另一种是Word嵌入 。
一站式 (One-Hot)
This is a way of representing each word by an array of 0s and 1. In the array, only one index has ‘1’ present and rest all are 0s.
这是一种用0和1的数组表示每个单词的方法。在该数组中,只有一个索引存在'1',其余所有索引均为0。
Example: The following vector represents only one word, in a sentence with 6 unique words.
示例:以下向量在一个包含6个唯一单词的句子中仅表示一个单词。

与numpy一热 (One-Hot with numpy)
Let’s find all the unique words in our sentence.
让我们找到句子中所有独特的词。
array(['Yours', 'a', 'after', 'an', 'ancestors', 'and', 'boar,', 'breakfast', 'covering', 'for', 'had', 'hand', 'in','leaves', 'like', 'mastodons', 'mine', 'olympic', 'or', 'run', 'skin,', 'spear', 'sprinter,', 'their', 'themselves', 'tiger', 'wild', 'with'], dtype='<U10')shape: (28,)Now, give each of them an index i.e. create a word_index where each word has an index attached to it in a dictionary.
现在,给每个单词一个索引,即创建一个word_index,其中每个单词在字典中都附有一个索引。
You might have observed above in the code that 0 is not assigned to any word. It’s a reserved index in Keras(We’ll get here later).
您可能在上面的代码中注意到没有将0分配给任何单词。 这是Keras中的保留索引(稍后我们会在这里)。
{'Yours': 1, 'a': 2, 'after': 3, 'an': 4, 'ancestors': 5, 'and': 6, 'boar,': 7, 'breakfast': 8, 'covering': 9, 'for': 10, 'had': 11, 'hand': 12, 'in': 13, 'leaves': 14, 'like': 15, 'mastodons': 16, 'mine': 17, 'olympic': 18, 'or': 19, 'run': 20, 'skin,': 21, 'spear': 22, 'sprinter,': 23, 'their': 24, 'themselves': 25, 'tiger': 26, 'wild': 27, 'with': 28}Now, let’s create one-hot encoding for them.
现在,让我们为它们创建一键编码。
Example output: This is how “yours” is represented.
输出示例:这就是“您的”的表示方式。
Yours [0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]一口热喀拉拉邦的例子 (One-hot keras example)
text_to_matrix is the method used to return one-hot encoding.
text_to_matrix是用于返回一键编码的方法。
You can see that, to represent a word, we are actually wasting a lot of memory to just set 0s(sparse matrix). These one-hot encodings also doesn’t reflect any relation between similar words. They are just representation of some word with ‘1’. Two similar words such as “accurate” and “exact” might be at very different positions in one-hot encodings.
您可以看到,为了表示一个单词,我们实际上是在浪费大量内存来仅将0设置为(稀疏矩阵)。 这些一键编码也不能反映相似词之间的任何关系。 它们只是某个带有“ 1”的单词的表示。 在“一键编码”中,两个类似的词(例如“准确”和“精确”)可能位于非常不同的位置。
What if we can represent a word with less space and have a meaning of its representation with which we can learn something.
如果我们可以用更少的空间来表示一个单词,并且具有可以用来学习某些东西的表示含义,该怎么办。
词嵌入 (Word Embeddings)
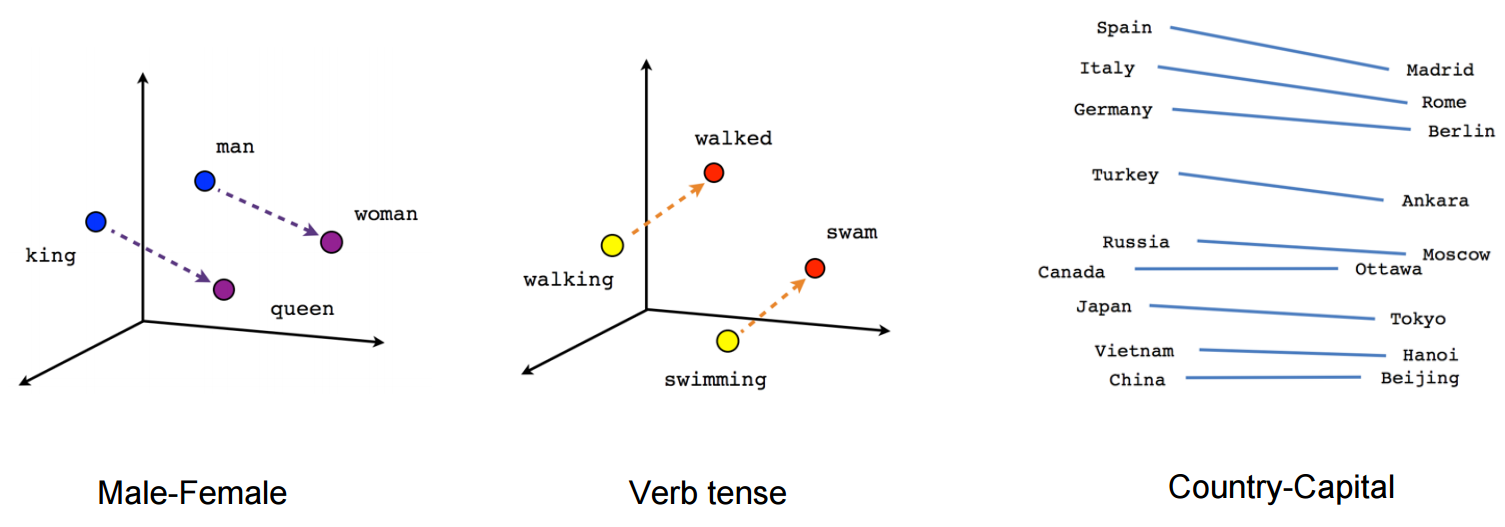
- Word embeddings also represent words in an array, not in the form of 0s and 1s but continuous vectors.
词嵌入还表示数组中的词,而不是0和1的形式,而是连续的向量。 - They can represent any word in few dimensions, mostly based on the number of unique words in our text.
它们可以在几个维度上表示任何单词,主要是基于文本中唯一单词的数量。 - They are dense, low dimensional vectors
它们是密集的低维向量 - Not hardcoded but are “learned” through data.
不进行硬编码,而是通过数据“学习”。
单词嵌入试图说什么? (What are word embeddings trying to say?)
- Geometric relationship between words in a word embeddings can represent semantic relationship between words. Words closer to each other have a strong relation compared to words away from each other.
词嵌入中的词之间的几何关系可以表示词之间的语义关系。 与彼此远离的单词相比,彼此靠近的单词具有很强的关系。 - Vectors/words closer to each other means the cosine distance or geometric distance between them is less compared to others.
向量/词彼此靠近意味着它们之间的余弦距离或几何距离小于其他向量。 - There could be vector “male to female” which represents the relation between a word and its feminine. That vector may help us in predicting “king” when “he” is used and “Queen” when she is used in the sentence.
可能存在向量“男对女”,代表一个单词与其女性味之间的关系。 当在句子中使用“他”时,该向量可以帮助我们预测“国王”,而在句子中使用“女王”时,该向量可以帮助我们预测。
单词嵌入的外观如何? (How word Embeddings look like?)
Below is a single row of embedding matrix representing the word ‘the’ in 100 dimensions from a text having 100K unique words.
下面是单行嵌入矩阵,表示具有100K个唯一单词的文本在100个维度中代表单词“ the” 。
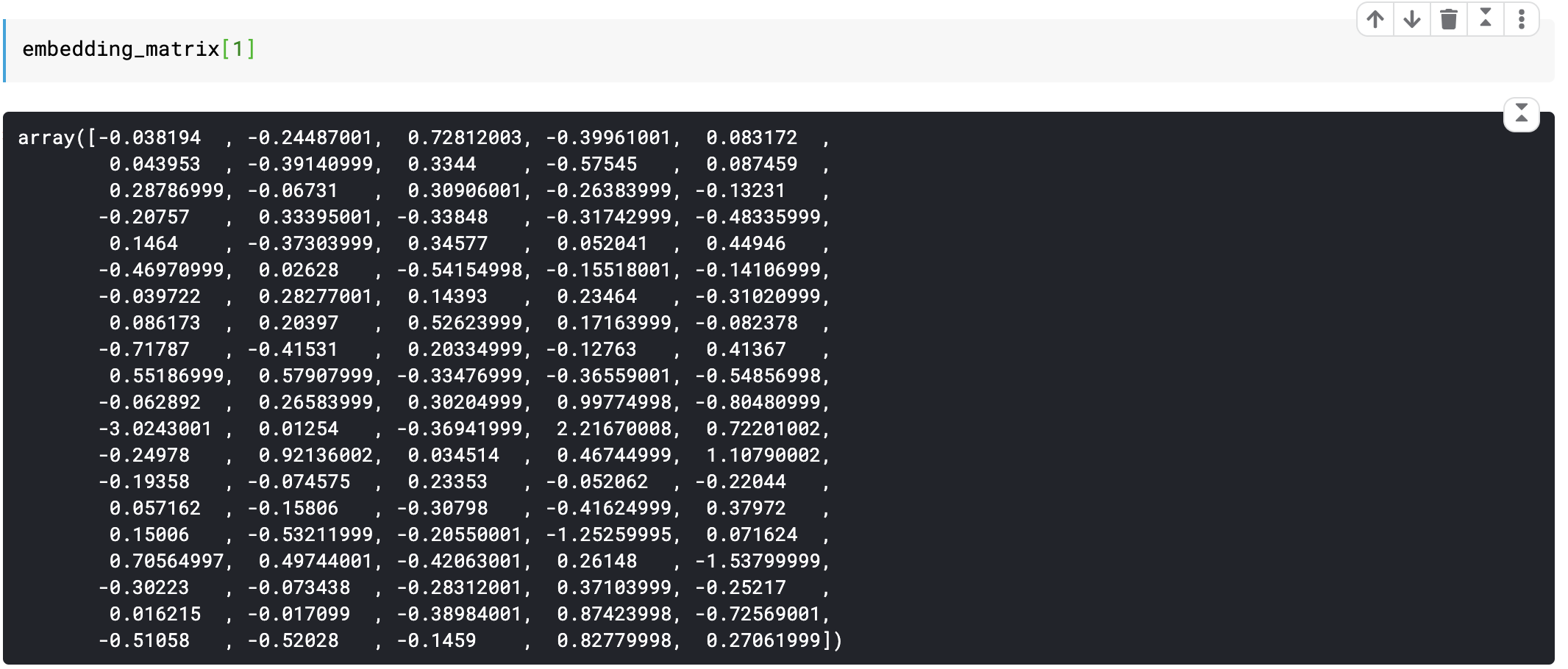
Such matrices are learned from data and can represent any text with millions of words in 100, 200, 1000 or more dimensions (The same would require 1MM dimensions if one-hot encoding is used).
此类矩阵可从数据中学习,并且可以表示100、200、1000或更多个维度中具有数百万个单词的任何文本(如果使用一键编码,则同样需要1MM维度)。
Let’s see how to create embeddings of our text in keras with a recurrent neural network.
让我们看看如何使用递归神经网络在keras中创建文本的嵌入。
将原始数据转换为嵌入的步骤如下: (Steps to follow to convert raw data to embeddings:)
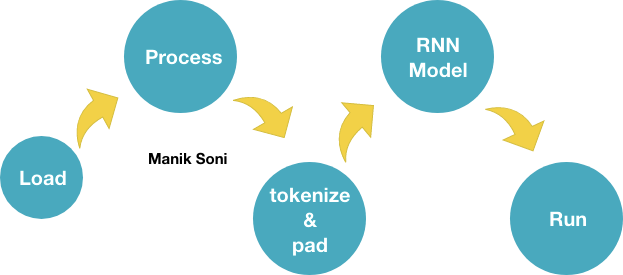
- Load text data in array.
将文本数据加载到数组中。 - Process the data.
处理数据。 - Convert the text to sequence and using the tokenizer and pad them with keras.preprocessing.text.pad_sequences method.
将文本转换为序列,并使用标记器,并使用keras.preprocessing.text.pad_sequences方法对其进行填充。 Initialise a model with Embedding layer of dimensions (max_words, representation_dimensions, input_size))
使用尺寸 (最大字数,表示尺寸 ,输入尺寸)的嵌入层初始化模型
max_words: It is the no. of unique words in your data
max_words :否。 数据中的独特单词
representation_dimension: It is the no. of dimensions in which you want to represent a word. Usually, it is number of (unique words)^(1/4)
presentation_dimension :否。 您想要代表一个单词的维度。 通常,它是(唯一词)^(1/4)的数量
input_size: size of your padded sequence(maxlen)
input_size:填充序列的大小( maxlen )
5 . Run the model
5。 运行模型
Let’s follow the above steps for IMDB raw data. All the code below is present in my Kaggle notebook.
让我们按照上述步骤处理IMDB原始数据。 我的Kaggle笔记本中包含以下所有代码。
步骤1.必要的进口 (Step 1. Necessary imports)
步骤2.加载文本数据。 (Step 2. Load the text data.)
loading the text data with pandas.
用熊猫加载文本数据。
步骤3:处理数据。 (Step 3: Process the data.)
Marking 1 for positive movie review and 0 for negative review.
标记1表示正面电影评论,标记0表示负面电影评论。
步骤4:创建和填充序列。 (Step 4: Creating and padding the sequence.)
Creating an instance of keras’s Tokenizer class and padding the sequence to ‘maxlen’.
创建keras的Tokenizer类的实例,并将序列填充到' maxlen '。
步骤5.初始化我们的模型 (Step 5. Initialise our model)
A simple recurrent neural network with embedding as first layer.
一个简单的以嵌入为第一层的递归神经网络。
步骤6:运行模型! (Step 6: Run the model!)
产出 (Outputs)
使用GRU: (With GRU:)
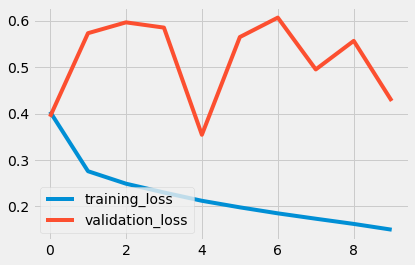
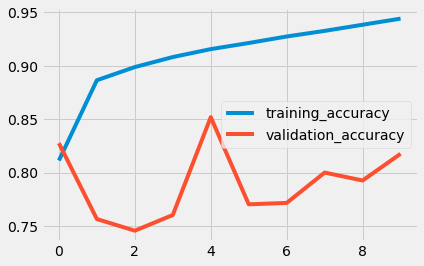
使用LSTM: (With LSTM:)
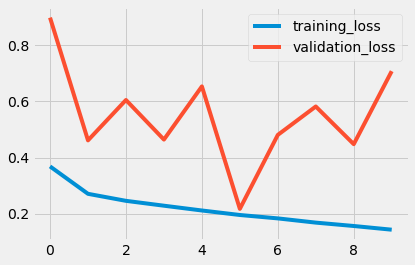
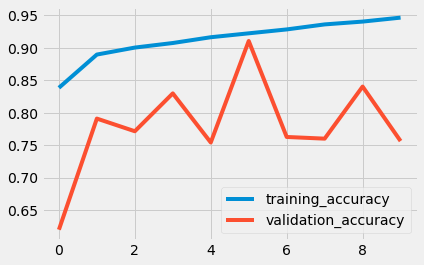
All the above code is present here.
以上所有代码均在此处提供 。
If this piece of writing helped you in any way, do share your knowledge with others!
如果这篇文章对您有任何帮助,请与他人分享您的知识!
Thanks for reaching till here! Great!
感谢您到达这里! 大!
翻译自: https://towardsdatascience.com/word-embeddings-and-the-chamber-of-secrets-lstm-gru-tf-keras-de3f5c21bf16
lstm预测单词
相关文章:
- 动态瑜伽 静态瑜伽 初学者_使用计算机视觉对瑜伽姿势进行评分
- 全自动驾驶论文_自动驾驶汽车:我们距离全自动驾驶有多近?
- ocr图像识别引擎_CycleGAN作为OCR图像的去噪引擎
- iphone 相机拍摄比例_在iPhone上拍摄:Apple如何解决Deepfakes和其他媒体操纵问题
- 机器学习梯度下降举例_举例说明:机器学习
- wp-autoblog_AutoBlog简介
- 人脸识别 特征值脸_你的脸值多少钱?
- 机器学习算法的差异_我们的机器学习算法可放大偏差并永久保留社会差异
- ai人工智能_AI破坏已经开始
- 无监督学习 k-means_无监督学习-第5部分
- 负熵主义者_未来主义者
- ai医疗行业研究_我作为AI医疗保健研究员的第一个月
- 梯度离散_使用策略梯度同时进行连续/离散超参数调整
- 机械工程人工智能_机械工程中的人工智能
- 遗传算法是机器学习算法嘛?_基于遗传算法的机器人控制器方法
- ai人工智能对话了_对话式AI:智能虚拟助手和未来之路。
- mnist 转图像_解决MNIST图像分类问题
- roc-auc_AUC-ROC技术的局限性
- 根据吴安德(斯坦福大学深度学习讲座),您应该如何阅读研究论文
- ibm watson_使用IBM Watson Assistant构建AI私人教练-第1部分
- ai会取代程序员吗_机器会取代程序员吗?
- xkcd目录_12条展示AI真相的XKCD片段
- 怎样理解电脑评分_电脑可以理解我们的情绪吗?
- ai 数据模型 下载_为什么需要将AI模型像数据一样对待
- 对话生成 深度强化学习_通过深度学习与死人对话
- 波普尔心智格列高利心智_心智与人工智能理论
- 深度学习计算机视觉的简介_商业用途计算机视觉简介
- slack 聊天机器人_使用Node.js和Symanto的Text Analytics API在Slack中创建情感机器人
- c语言八数码问题启发式搜索_一种快速且简单的AI启发式语言学习方法
- 机器学习库线性回归代码_PyCaret回归:更好的机器学习库
lstm预测单词_从零开始理解单词嵌入| LSTM模型|相关推荐
- 如何运用计算机巧记英语词汇,如何运用计算机巧记英语单词_记英语单词的技巧...
如何运用计算机巧记英语单词_记英语单词的技巧 下载地址: 内容预览 如何巧记英语单词siege.mp4 如何巧记英语单词sieve.mp4 如何巧记英语单词sift.mp4 如何巧记英语单词sigh. ...
- lstm预测单词_下一个单词预测完整指南
lstm预测单词 As part of my summer internship with Linagora's R&D team, I was tasked with developing ...
- lstm预测股票_股票相关性与lstm预测误差
lstm预测股票 When trying to look at examples of LSTMs in Keras, I've found a lot that focus on using the ...
- java事件处理模型_从零开始理解JAVA事件处理机制(3)
我们连续写了两小节的教师-学生的例子,必然觉得无聊死了,这样的例子我们就是玩上100遍,还是不知道该怎么写真实的代码.那从本节开始,我们开始往真实代码上面去靠拢. 事件最容易理解的例子是鼠标事件:我们 ...
- lstm 根据前文预测词_干货 | Pytorch实现基于LSTM的单词检测器
Pytorch实现 基于LSTM的单词检测器 字幕组双语原文: Pytorch实现基于LSTM的单词检测器 英语原文: LSTM Based Word Detectors 翻译: 雷锋字幕组(Icar ...
- 定位到某个单词_【侃侃单词】词根词缀记单词-loc
知乎视频www.zhihu.com loc=place地方 local loc表示地方,al是个形容词后缀,当地的,地方性的:局部的:作名词可以表示当地人 localism ism表示-主义,地方主 ...
- c++怎么打印出句子中的各个单词_小学英语单词汇总篇 身体 食品、饮料 蔬菜...
身体英语名称 hair头发 head头 eye眼睛 face脸 neck脖子 arm手臂 leg腿 hand手 foot脚 toe脚趾 finger手指 ear耳朵 nose鼻子 mouth嘴巴 to ...
- c语言倒序输出单词_洛谷 || 单词覆盖还原(C语言)
点击上方「蓝字」关注"程序员Bob" 每天与你不见不散! 每日一句,送给最珍贵的你: 诱人的机会总是转瞬即逝的.真正好的投资机会不会经常有,也不会持续很长的时间,所以你必须做好行动 ...
- mysql需要记住的单词_巧记单词——用like记住10个单词
本篇罗列一下单词like衍生出的单词.like [laɪk] vt. 喜欢:(与 would 或 should 连用表示客气)想:想要:喜欢做 | prep. (表示属性)像:(表示方式)如同:(询问 ...
- python做马尔科夫模型预测法_隐马尔可夫模型的前向算法和后向算法理解与实现(Python)...
前言 隐马尔可夫模型(HMM)是可用于标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型. 马尔可夫模型理论与分析 参考<统计学习方法>这本书,书上已经讲得 ...
最新文章
- TensorFlow练习25: 使用深度学习做阅读理解+完形填空
- mongodb 导出指定数据库文件大小_大数据技术之将mongodb 数据指定字段导出,然后指定字段导入mysql 实例 及相关问题解决...
- 【Kotlin】Kotlin 单例 ( 懒汉式 与 恶汉式 | Java 单例 | Kotlin 单例 | 对象声明 | 伴生对象 | get 方法 | ? 与 !! 判空 )
- Flex布局(一)flex-direction
- MySQL 中一个双引号的错位引发的血案
- oracle闪回保存多久,CSS_oracle 中关于flashback闪回的介绍, 1、必须设定undo保留时间足 - phpStudy...
- docker Harbor
- awt jtable 多线程加载图片_Java项目实战之天天酷跑(三):缓冲加载游戏界面
- 码农即将被淘汰?未来10年,这样的程序员才值钱!
- 数据科学 IPython 笔记本 8.1 matplotlib
- Linux(ARM glibc)使用libhybris调用Android(ARM bionic)
- 2055D打印机打印报错
- 增量式编码器和绝对式编码器的介绍
- 如何写一篇五彩斑斓的博客.append(可爱)
- 威纶通触摸屏232脚位_威纶通触摸屏使用手册
- 圣诞节儿童什么礼物好呢?精选实用型的圣诞护眼小台灯
- 7-35 猴子吃桃问题 (15 分) 一只猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个;第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半加一个。到
- 索尼x91l和x91k区别 索尼x91l和索尼x91k哪个好
- 工作中如何时间管理?
- 1道动态规划(搬箱子)、KMP算法、图(Prim算法)、1道哈夫曼树
热门文章
- Ubuntu 汉化及kate汉化和使用自带终端的解决方式
- Flexsim在固定资源类中没有分拣传送带?
- 190923每日一句
- Atitit mybatis topic file list Total 300ge (9+条消息)MyBatis框架核心之(五)注解使用resultMap及多表查询 - 弱弱的猿 - CSD
- Atitit webdav应用场景 提升效率 小型数据管理 目录 1.1. 显示datalist 1 1.2. Ajax填充数据 1 1.3. 编辑数据 2 1.1.显示datalist
- Atitit 防烫伤指南与规范 attilax总结
- Atitit.atijson 类库的新特性设计与实现 v3 q31
- atitit.获取connection hibernate4
- BOMRemover v2.0 去除代码中的UTF-8 BOM
- 理财子公司成长的烦恼